FlinkCore
1、JavaAPI
1、创建一个Topic并写入数据
向Kafka写数据 如果topic不存在则会自动创建一个副本和分区数都是1的topic
package com.shujia.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Demo01KafkaProducer {
public static void main(String[] args) {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092");
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建Kafka 生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 向Kafka写数据 如果topic不存在则会自动创建一个副本和分区数都是1的topic
producer.send(new ProducerRecord<String,String>("topic02","1500100001,施笑槐,22,女,文科六班"));
producer.flush();
}
}
执行了两次的结果:

2、从一个.txt 的文件中读取数据,并写入到Topic中
package com.shujia.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
public class Demo02KafkaStuProducer {
// 将1000条学生数据写入Kafka
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092");
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建Kafka 生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 读取文件
BufferedReader br = new BufferedReader(new FileReader("kafka/data/stu/students.txt"));
String line;
while ((line = br.readLine()) != null) {
producer.send(new ProducerRecord<>("students1000", line));
}
producer.flush();
}
}
结果:
3、创建一个消费者,读取Topic中的数据
package com.shujia.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Properties;
public class Demo03KafkaConsumer {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
/*
* 消费者组的偏移量设定规则:
* earliest 相当于from-beginning 从头开始消费
* latest 从最新的数据开始消费
*/
properties.setProperty("auto.offset.reset", "earliest");
// 设置消费者组id,每一个grp02只能读一次,第二次再读取时,则不会出现数据!(结果显示)
properties.setProperty("group.id", "grp03");
// 创建Kafka的消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
ArrayList<String> topic = new ArrayList<>();
topic.add("students1000");
// 指定消费的topic
consumer.subscribe(topic);
// 加一个死循环,使其为无界流,一直读取
while (true){
ConsumerRecords<String, String> records = consumer.poll(10000);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.headers());
System.out.println(record.offset());
System.out.println(record.timestamp());
// 由于所读的Topic students1000中只有一个partition,所以结果中只显示有一个分区
// System.out.println(record.partition());
// 没有key,打印结果为null
System.out.println(record.key());
System.out.println(record.value());
}
// 防止执行太快,没有取完所有的数据;给它睡眠一会
Thread.sleep(5000);
}
}
}
2、FlinkAPI
1、从Topic中取出数据,并做相应处理
统计每个班级的学生人数:
package tfTest;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo01KafkaSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource
.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setGroupId("group001")
.setTopics("students1000")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
kafkaDS.map(line -> Tuple2.of(line.split(",")[4],1), Types.TUPLE(Types.STRING,Types.INT))
.keyBy(t2 -> t2.f0)
.sum(1)
.print();
env.execute();
/**
* 结果为:(数据流为无界流,会一直接收数据并处理)
* 13> (理科五班,17)
* 13> (理科四班,17)
* 13> (理科四班,18)
* 13> (理科四班,19)
* 13> (理科四班,20)
* 13> (理科五班,18)
* 13> (理科四班,21)
* 13> (理科四班,22)
* 13> (理科五班,19)
* 13> (理科四班,23)
*/
}
}
2、读取.json格式的数据,写入到Topic中
设置写入时的语义:
1、AT_LEAST_ONCE:保证数据至少被写入了一次,性能会更好,但是又可能会写入重复的数据
2、EXACTLY_ONCE:保证数据只会写入一次,不多不少,性能会有损耗
package com.shujia.flink.kafka;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo02KafkaSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> carDS = env.readTextFile("flink/data/cars_sample.json");
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema
.builder()
.setTopic("cars_json") // 不存在会自动创建
// 指定数据流的序列化方式
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
/**
设置写入时的语义:
1、AT_LEAST_ONCE:保证数据至少被写入了一次,性能会更好,但是又可能会写入重复的数据
2、EXACTLY_ONCE:保证数据只会写入一次,不多不少,性能会有损耗
*/
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
carDS.sinkTo(sink);
env.execute();
}
}
3、从写入json数据的Topic中读取数据,并求出各道路的平均车速
注:
TODO 将从Topic中读取的数据转换成自定义的Car对象,便于后续操作
SingleOutputStreamOperator carDS = carStrDS.map(carStr -> JSON.parseObject(carStr, Car.class));第三个参数:源名称的设置在Flink中主要用于提高日志、监控、元数据管理和代码可读性的目的
DataStreamSource carStrDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), “cars”);reduce中聚合操作
package com.shujia.flink.kafka;
import com.alibaba.fastjson.JSON;
import jdk.nashorn.internal.scripts.JO;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo03CarsAvgSpeed {
public static void main(String[] args) throws Exception {
// 基于Kafka Cars数据实时统计每条道路的平均车速
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 构建Kafka Source
KafkaSource<String> kafkaSource = KafkaSource
.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setGroupId("grp001")
.setTopics("cars_json")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// {"car":"皖AQLXL2","city_code":"340100","county_code":"340111","card":117331031812010,"camera_id":"01012","orientation":"西","road_id":34406326,"time":1614731906,"speed":47.86}
// 第三个参数:源名称的设置在Flink中主要用于提高日志、监控、元数据管理和代码可读性的目的
DataStreamSource<String> carStrDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "cars");
//TODO 将从Topic中读取的数据转换成自定义的Car对象,便于后续操作
SingleOutputStreamOperator<Car> carDS = carStrDS.map(carStr -> JSON.parseObject(carStr, Car.class));
carDS
// 只取Car对象属性中的road_id、speed,加上“1”,用于后续求平均值
.map(car-> Tuple3.of(car.road_id,car.speed,1), Types.TUPLE(Types.LONG,Types.DOUBLE,Types.INT))
.keyBy(t3->t3.f0,Types.LONG)
// 对整体进行聚合:
.reduce(new ReduceFunction<Tuple3<Long, Double, Integer>>() {
@Override
public Tuple3<Long, Double, Integer> reduce(Tuple3<Long, Double, Integer> value1, Tuple3<Long, Double, Integer> value2) throws Exception {
return Tuple3.of(value1.f0, value1.f1 + value2.f1, value1.f2 + value2.f2);
}
})
// 聚合后,求出各路段的平均车速
.map(t3 -> Tuple2.of(t3.f0, t3.f1 / t3.f2),Types.TUPLE(Types.LONG,Types.DOUBLE))
.print();
env.execute();
}
}
// 定义一个Car类型,使用注解的方式创建get、set、构造器方法; 前期处理:加入lombok依赖,下载lombok插件
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
class Car{
String car;
Integer city_code;
Integer county_code;
Long card;
String camera_id;
String orientation;
Long road_id;
Long time;
Double speed;
}
3、checkpoint
**当任务停止后,可以在HDFS上缓存任务中的结果数据。**再次启动任务时,输入数据得出的结果会算上上次运行的结果(实现故障恢复的效果)
checkpoint保存了算子运行后的结果状态:
package com.shujia.flink.state;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo02CheckPoint {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启CK,每 5000ms 开始一次 checkpoint
env.enableCheckpointing(5000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 开启实验性的 unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();
// 设置CK保存的路径,一般是HDFS的路径;端口号9000可以在HDFS UI上查看;地址中只会保存最新的checkpoint,之前的会进进行缓存
env.getCheckpointConfig().setCheckpointStorage("hdfs://master:9000/flink/checkpoint");
// Flink算子在计算时,实际上已经自带了状态,但是并没有主动进行CheckPoint
env
// 从一个开启的socket中获取数据
.socketTextStream("master", 8888)
.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT))
.keyBy(t2 -> t2.f0).sum(1)
.print();
env.execute();
}
}
再次启动时,需要指定checkpoint的存储路径:
hdfs://master:9000/flink/checkpoint/d882f9b4d726d7462573a3bee8ab4fcb/chk-14

4、使用状态
一般在keyBy计算之后之后进行状态存储,将状态保存得开启checkpoint,可以在配置文件中开启(就不用总是使用代码进行开启了)
使用状态
不同类型的状态:
ValueState:单值状态,包含两个方法:update更新状态、value获取状态
ListState :状态为多值
MapState : 状态为KV
ReducingState :状态需要聚合,最终还是单值状态
AggregatingState:状态需要聚合,最终还是单值状态
package com.shujia.flink.state;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Demo03ValueState {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> ds01 = env.socketTextStream("master", 8888);
// 在配置文件中开启了CK,则不需要通过env再设置了
SingleOutputStreamOperator<Tuple2<String,Integer>> wordDS = ds01.flatMap((line, out) -> {
for (String word : line.split(",")) {
out.collect(Tuple2.of(word, 1));
}
}, Types.TUPLE(Types.STRING, Types.INT));
KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordDS.keyBy(t2 -> t2.f0, Types.STRING);
// 基于分组之后的数据流同样可以调用process方法
keyedDS
.process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() {
// 定义一个ValueState单值状态,包含两个方法:update更新状态、value获取状态
// Flink会给每一个keyBy的key单独维护一个状态
/**
* 一般在keyBy计算之后之后进行状态存储,将状态保存得开启checkpoint,可以在配置文件中开启(就不用总是使用代码进行开启了)
* 使用状态
* 不同类型的状态:
* ListState :状态为多值
* MapState : 状态为KV
* ReducingState :状态需要聚合,最终还是单值状态
* AggregatingState:状态需要聚合,最终还是单值状态
*/
ValueState<Integer> valueState;
// 当KeyedProcessFunction构建时只会执行一次
@Override
public void open(Configuration parameters) throws Exception {
// 使用Flink Context来初始化状态
RuntimeContext context = getRuntimeContext();
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("count", Types.INT);
valueState = context.getState(descriptor);
}
// 每一条数据会执行一次
@Override
public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<String, Tuple2<String, Integer>, String>.Context ctx, Collector<String> out) throws Exception {
Integer cnt = valueState.value();
int count = 1;
// 如果是第一次处理某个单词,则返回null
if (cnt != null){
count = cnt + 1;
}
valueState.update(count);
out.collect(value.f0+","+count);
}
}).print();
env.execute();
}
}
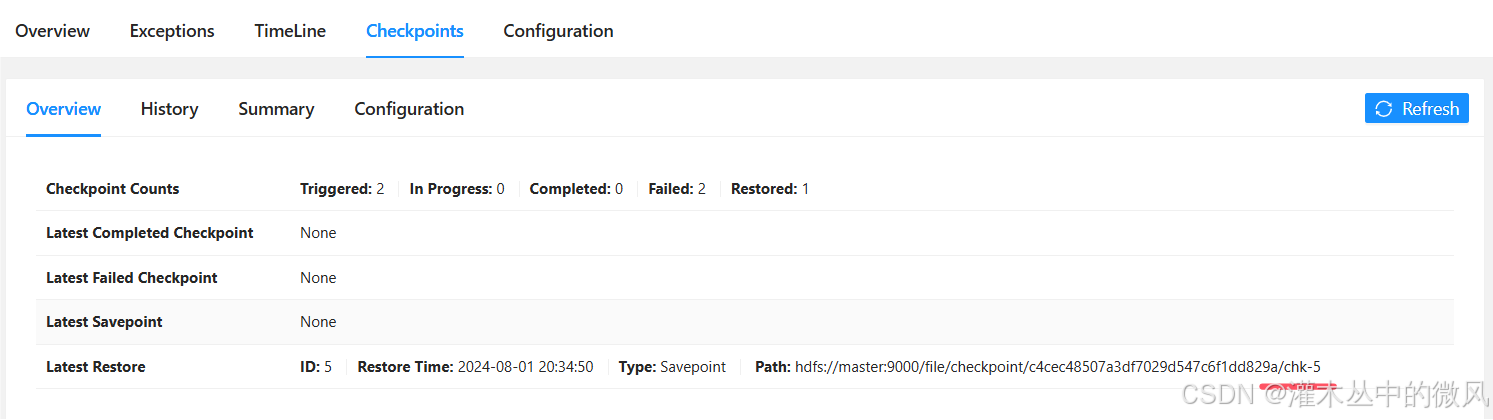
任务停止后,要想继续上一次的执行结果,再次启动时,需要指定checkpoint的存储路径:
再次执行时,checkpoint会从所指定的checkpoint开始,如下图:
案例:
对某个人的交易流水进行欺诈检测:如果有一笔交易小于一元,然后紧接着的一笔交易大于500,则判断有欺诈风险
package com.shujia.flink.state;
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class Demo04FraudCheck {
public static void main(String[] args) throws Exception {
// 对某个人的交易流水进行欺诈检测:如果有一笔交易小于一元,然后紧接着的一笔交易大于500,则判断有欺诈风险
/*
* 1,1000
* 1,500
* 1,200
* 1,0.1
* 1,1000
* 1,0.1
* 1,300
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> transDS = env.socketTextStream("master", 8888);
SingleOutputStreamOperator<MyTrans> myTransDS = transDS.map(line -> {
String[] split = line.split(",");
return new MyTrans(split[0], Double.parseDouble(split[1]));
});
myTransDS
.keyBy(MyTrans::getId)// 按照每个人的户号进行分组
.process(new KeyedProcessFunction<String, MyTrans, String>() {
// 创建状态:
ValueState<Boolean> flagState;
@Override
public void open(Configuration parameters) throws Exception {
RuntimeContext context = getRuntimeContext();
flagState = context.getState(new ValueStateDescriptor<Boolean>("flag", Types.BOOLEAN));
}
@Override
public void processElement(MyTrans value, KeyedProcessFunction<String, MyTrans, String>.Context ctx, Collector<String> out) throws Exception {
// 获取上一条纪录的状态,如果为true,则表示上一条记录是小于1的,则需要对当前记录进行是否大于500的判断
// 如果为false,则只需要判断当前记录中的金额是否小于1
Boolean flag = flagState.value();
if(flag==null){
// 默认值为false
flag = false;
}
// 获取每笔交易中的交易金额
Double trans = value.getTrans();
if (trans < 1) {
flagState.update(true);
}
// 如果上一次的flag为true,并且当前的trans>500,则会触发println执行
if (flag) {
if (trans > 500) {
System.out.println("存在交易风险");
}
// 大于500设置flagState为false
flagState.update(false);
}
}
});
// flink不需要action算子触发任务,由事件触发(数据流发生变化、所监控的文件发生变化时,会触发执行)
env.execute();
}
}
@Data
@AllArgsConstructor
class MyTrans {
String id;
Double trans;
}
5、Kafka的send操作及事务支持
要么都执行,要么都不执行
send操作,要么是提交事务后都执行,要么是都不执行
# 若通过事务的方式写Kafka,在读取时--isolation-level <String> :默认读取未提交的所以数据 read_uncommitted
# 若要读取提交了的数据,那么得使用 read_committed
kafka-console-consumer.sh --isolation-level read_committed --bootstrap-server master:9092,node1:9092,node3:9092 --from-beginning --topic trans_topic
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node3:9092 --from-beginning --topic trans_topic
package com.shujia.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class Demo03KafkaTransaction {
public static void main(String[] args) throws InterruptedException {
// 通过事务的方式写Kafka
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 若不加则会报错
properties.setProperty("transactional.id", "trans01");
// 创建Kafka 生产者
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// 开启一个事务,要么都执行,要么都不执行
producer.initTransactions();
producer.beginTransaction();
// 向Kafka写数据 如果topic不存在则会自动创建一个副本和分区数都是1的topic
producer.send(new ProducerRecord<String,String>("trans_topic","1500100001,施笑槐,22,女,文科六班"));
producer.send(new ProducerRecord<String,String>("trans_topic","1500100002,施笑槐,22,女,文科六班"));
producer.send(new ProducerRecord<String,String>("trans_topic","1500100003,施笑槐,22,女,文科六班"));
Thread.sleep(10000);
producer.send(new ProducerRecord<String,String>("trans_topic","1500100004,施笑槐,22,女,文科六班"));
producer.send(new ProducerRecord<String,String>("trans_topic","1500100005,施笑槐,22,女,文科六班"));
producer.flush();
// 提交事务之后才算写入完成
producer.commitTransaction();
}
}
6、ExactlyOnce
确保数据不重复也不丢失
案例一:
Flink作为消费端和处理端,从kafka中读取数据,将消费的偏移量和计算的结果通过checkpoint保存起来,以便故障的恢复。
如果需要提交到集群运行,记得在$FLINK_HOME/lib目录下添加flink-sql-connector-kafka-1.15.4.jar依赖
package com.shujia.flink.state;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Demo05ConsumeKafkaExactlyOnce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置CK的时间间隔
env.enableCheckpointing(15000);
// 如果需要提交到集群运行,记得在$FLINK_HOME/lib目录下添加flink-sql-connector-kafka-1.15.4.jar依赖
KafkaSource<String> kafkaSource = KafkaSource
.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setGroupId("grp001") // 第一次可以随便指定,如果需要恢复则必须和上一次同步
.setTopics("words001") //TODO 读取的时候如果不存在会报错(读取Topic时,若其不存在,不会为其创建)
// 如果是故障后从CK恢复,FLink会自动将其设置为committedOffsets,即从上一次失败的位置继续消费
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// 从KafkaSource接收数据变成DS 无界流
// Topic有几个分区,则KafkaSource有几个并行度去读取Kafka的数据
DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
// 统计班级人数
kafkaDS
.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT))
.keyBy(t2 -> t2.f0)
.sum(1)
.print();
env.execute();
}
}
案例二:
Flink从kafka接收数据,处理后再将结果写入到kafka
这种情况下:Flink会将需要做的checkpoint操作(将消费偏移量和计算的结果保存到HDFS上)和将结果写入到Kafka这两个操作构成一个事务,来保证ExactlyOnce
注:执行时报错
org.apache.flink.kafka.shaded.org.apache.kafka.common.KafkaException:
Unexpected error in InitProducerIdResponse;
The transaction timeout is larger than the maximum value allowed by the broker
(as configured by transaction.max.timeout.ms).原因:
transaction.max.timeout.ms : Kafka事务最大的超时时间,默认15分钟,即Broker允许的事务最大时间为15分钟 ,Flink的KafkaSink默认事务的超时时间为1小时。若不统一它们的时间,则会发生冲突。
transaction.timeout.ms :设置Kafka Sink的事务时间,只要小于15分钟即可
package com.shujia.flink.state;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
public class Demo06SinkKafkaExactlyOnce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置CK的时间间隔
env.enableCheckpointing(15000);
KafkaSource<String> kafkaSource = KafkaSource
.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setGroupId("grp001") // 第一次可以随便指定,如果需要恢复则必须和上一次同步
.setTopics("words001") // 读取的时候如果不存在会报错
// 如果是故障后从CK恢复,FLink会自动将其设置为committedOffsets,即从上一次失败的位置继续消费
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
/**
* 从KafkaSource接收数据变成DS 无界流
* Topic有几个分区,则KafkaSource有几个并行度去读取Kafka的数据
* 从kafka中读取数据,再对其进行处理,最后写入到kafka中的一个Topic中
*/
DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
Properties prop = new Properties();
/*
* org.apache.flink.kafka.shaded.org.apache.kafka.common.KafkaException:
* Unexpected error in InitProducerIdResponse;
* The transaction timeout is larger than the maximum value allowed by the broker
* (as configured by transaction.max.timeout.ms).
*
* transaction.max.timeout.ms : Kafka事务最大的超时时间,默认15分钟,即Broker允许的事务最大时间为15分钟
* Flink的Kafka Sink默认事务的超时时间为1小时。若不同意它们的时间,则会放生冲突。
*
* transaction.timeout.ms :设置Kafka Sink的事务时间,只要小于15分钟即可
*/
prop.setProperty("transaction.timeout.ms", 15 * 1000 + "");
KafkaSink<String> sink = KafkaSink
.<String>builder()
.setBootstrapServers("master:9092,node1:9092,node2:9092")
.setKafkaProducerConfig(prop)
.setRecordSerializer(
KafkaRecordSerializationSchema
.builder()
.setTopic("word_cnt01") // 写入数据时,Topic不存在会自动创建
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
/*
设置写入时的语义:
1、AT_LEAST_ONCE:保证数据至少被写入了一次,性能会更好,但是又可能会写入重复的数据
2、EXACTLY_ONCE:保证数据只会写入一次,不多不少,性能会有损耗
*/
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
// 统计班级人数
kafkaDS
.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT))
.keyBy(t2 -> t2.f0)
.sum(1)
// 将结果的二元组转换成String才能写入Kafka
.map(t2 -> t2.f0 + "," + t2.f1)
.sinkTo(sink);
env.execute();
}
}