1.使用方法及效果
我这里使用过v8和v10,相信其他系列都是类似的,我使用的是一张信号图片来做预测。
a. 前置条件
- 将自己的模型训练好,得到权重文件,如best.pt。
- 在做预测的时候,往其中添加一个超参数 visualize=True ,如下所示:
pth_path=r"F:\ultralytics-main\runs\detect\trainNewAttention\best.pt"
# test_path = r"F:\ultralytics-main\pric"
model = YOLO(pth_path) # load a custom model
metrics = model.predict(test_path,conf=0.5,save=True,visualize=True)
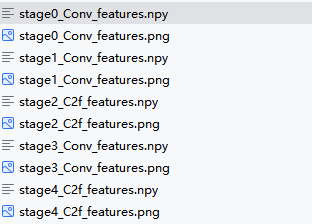
- 运行后即可得到特征图
b. 结果展示
- 对于预测的图片,他会产生该图片的经历yolov8每个模块后的特征可视化图像,以及预测的结果图片,如下图所示,这里仅展示部分
- 经过v8第一个模块后展示如下,固定为一张图片16个子图,后面会说明为什么。
3.后面的特征图可视化如下所示,这是v8第5个模块C2f输出的结果,之后的每个模块输出的图片都包含32个子图,具体原因后面解释。


2. 原理部分
yolov8是通过两段代码来进行上述特征可视化的,其他yolo系列应该也是类似。
a. 疑问
对于上述的特征可视化图片,存在几个问题,这也是我debug查看对应代码的原因,如下:
- 为什么经过一个模块后输出的特征可视化图片中包含这么多的子图,而且固定为第一张16个,后面都是32个?一张可视化图片中每个子图之间是什么关系?
- 这些特征图是怎么产生的?
b. 解答
- 做特征可视化的这个过程是在模型的推理过程中产生的(inference),地址为:ultralytics\engine\predictor.py
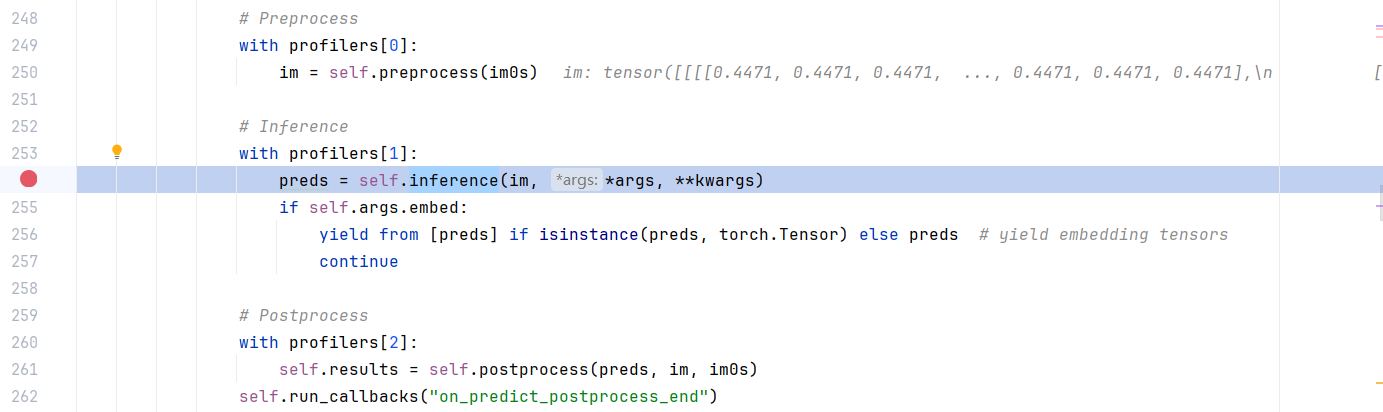
#yolo外层调用可视化的部分
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
for m in self.model:
if m.f != -1: # if not fro m previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x
我这里说明一下这段代码的意思:
- self.model存储的是整个v8的所有模块,我在文章末尾会展示,这里便是遍历v8的每一个模块
- 随后关于m.f这个if的作用就是判断是否来自前一层,因为我们知道v8在后面的concat的时候使用的不仅仅是前一层输出作为输入,还包括其他层,这里是计算这个x,x意思是待预测图片的特征图。初始的x输入即为预测图片的张量。
- x = m(x)是经历当前模块后的结果。
- feature_visualization将步骤3的结果进行特征可视化,即绘图,m.type意思是当前经历的模块类型,m.i表示当前经历的阶段为第几个模块。save_dir为可视化图片保存的地址。
v8中进行特征可视化的代码段,地址为:ultralytics\nn\task.py
#yolo系列特征可视化绘图部分
def feature_visualization(x, module_type, stage, n=32, save_dir=Path("runs/detect/exp")):
"""
Visualize feature maps of a given model module during inference.
Args:
x (torch.Tensor): Features to be visualized.
module_type (str): Module type.
stage (int): Module stage within the model.
n (int, optional): Maximum number of feature maps to plot. Defaults to 32.
save_dir (Path, optional): Directory to save results. Defaults to Path('runs/detect/exp').
"""
for m in {"Detect", "Segment", "Pose", "Classify", "OBB", "RTDETRDecoder"}: # all model heads
if m in module_type:
return
if isinstance(x, torch.Tensor):
_, channels, height, width = x.shape # batch, channels, height, width
if height > 1 and width > 1:
f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
n = min(n, channels) # number of plots
_, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
ax = ax.ravel()
plt.subplots_adjust(wspace=0.05, hspace=0.05)
for i in range(n):
ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
ax[i].axis("off")
LOGGER.info(f"Saving {f}... ({n}/{channels})")
plt.savefig(f, dpi=300, bbox_inches="tight")
plt.close()
np.save(str(f.with_suffix(".npy")), x[0].cpu().numpy()) # npy save
该段代码基本上可以说明上述的疑问了:
- 首先判断当前层是否为检测头,当碰到检测头了肯定退出了。
- 如果x不属于tensor张量的话就不会进行特征可视化了,限制x张量的尺寸
- 使用 torch.chunk 将批次索引为0的特征图按通道分割。 x经过第一个Conv后得到的channel为16,这里n默认为32,而x经过后续模块channel远不止32,这就说明了上述的疑问。
- 后面就是设置绘图的一些参数了,包括设置一张图片显示n/8行子图,每行显示8张子图,子图间距,坐标轴显示等。
3. 总结
yolo系列集成的特征可视化方法是通过原图片张量每经过一个模块计算后就输出该特征张量对应的特征图,该图片包含多张特征子图,这些子图是按不同的通道来进行展示的,默认一张图片最多展示32张,即32个不同的通道对应的特征图。
4.附录
self.model的内容显示如下:
Sequential(
(0): Conv(
(conv): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): C2f(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(48, 32, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(3): Conv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(4): C2f(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0-1): 2 x Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(5): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(6): C2f(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0-1): 2 x Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(7): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(8): C2f(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(384, 256, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(9): SPPF(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(10): BSAM(
(channel_attention): BiLevelRoutingAttention(
(lepe): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(router): TopkRouting(
(emb): Identity()
(routing_act): Softmax(dim=-1)
)
(kv_gather): KVGather()
(qkv): QKVLinear(
(qkv): Linear(in_features=256, out_features=768, bias=True)
)
(wo): Linear(in_features=256, out_features=256, bias=True)
(kv_down): Identity()
(attn_act): Softmax(dim=-1)
)
(spatial_attention): SpatialAttention(
(cv1): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(act): Sigmoid()
)
)
(11): Upsample(scale_factor=2.0, mode='nearest')
(12): Concat()
(13): C2f(
(cv1): Conv(
(conv): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(14): Upsample(scale_factor=2.0, mode='nearest')
(15): Concat()
(16): C2f(
(cv1): Conv(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(96, 64, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(17): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(18): Concat()
(19): C2f(
(cv1): Conv(
(conv): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(20): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(act): SiLU(inplace=True)
)
(21): Concat()
(22): C2f(
(cv1): Conv(
(conv): Conv2d(384, 256, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(384, 256, kernel_size=(1, 1), stride=(1, 1))
(act): SiLU(inplace=True)
)
(m): ModuleList(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
)
)
)
(23): Detect(
(cv2): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
)
)
(cv3): ModuleList(
(0): Sequential(
(0): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
)
(1): Sequential(
(0): Conv(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
)
(2): Sequential(
(0): Conv(
(conv): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(1): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(act): SiLU(inplace=True)
)
(2): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
)
)
(dfl): DFL(
(conv): Conv2d(16, 1, kernel_size=(1, 1), stride=(1, 1), bias=False)
)
)
)