目录
引言
随机森林(Random Forest)是一种集成学习算法,它通过构建多个决策树并将它们的预测结果进行汇总来提高整体模型的预测准确率、稳定性和泛化能力。随机森林属于“bagging”(Bootstrap Aggregating)方法的一种实现,它结合了决策树的强大分类能力和集成学习的优势。
核心思想
-
构建多棵决策树:随机森林通过自助抽样法(bootstrap sampling)从原始数据集中随机抽取多个样本集,每个样本集都是原始数据集的一个有放回抽样版本。然后,基于每个样本集独立地训练一棵决策树。由于是有放回抽样,原始数据集中的某些样本可能会在多个样本集中出现,而有些样本则可能一次都不出现。
-
随机选择特征:在构建每棵决策树的过程中,不是使用数据集中的所有特征来寻找最佳划分,而是随机选择一部分特征(通常是总特征数的一个子集)来进行节点划分。这种特征选择的随机性进一步增加了模型的多样性,有助于减少过拟合并提高模型的泛化能力。
-
集成预测:对于分类问题,随机森林中的每棵决策树都会给出一个预测结果(即类别的投票)。最终,随机森林的预测结果是所有决策树预测结果的众数(即出现次数最多的类别)。对于回归问题,则取所有决策树预测结果的平均值作为最终预测。
优点
- 准确率高:由于集成了多棵决策树的预测结果,随机森林通常比单棵决策树具有更高的预测准确率。
- 鲁棒性强:随机森林对噪声和异常值具有较好的容忍度,不易受单个样本或特征的影响。
- 易于使用:随机森林算法实现简单,参数较少,容易在各种数据集上应用。
- 能够评估特征重要性:随机森林在训练过程中可以评估每个特征对预测结果的重要性,有助于特征选择和解释模型。
应用场景
随机森林广泛应用于各种分类和回归任务中,包括但不限于:
- 客户流失预测
- 欺诈检测
- 图像识别
- 文本分类
- 医学诊断
- 股票价格预测
建模步骤
- 数据预处理:
- 清洗数据:处理缺失值、异常值和重复项。
- 转换数据类型:如将
TotalCharges从字符串转换为浮点数。 - 编码分类变量:使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)处理分类变量(如
gender,InternetService,Contract等)。
- 特征选择:
- 识别与流失预测相关的特征。
- 可能需要进行特征工程,如创建新特征(如服务年限的类别、费用等级等)。
- 划分数据集:
- 将数据集划分为训练集和测试集(或进一步划分为训练集、验证集和测试集)。
- 选择模型:
- 根据问题的性质(二分类问题),可以选择逻辑回归、决策树、随机森林、梯度提升树(如XGBoost、LightGBM)、神经网络等模型。
- 训练模型:
- 使用训练集数据训练选定的模型。
- 评估模型:
- 使用测试集评估模型的性能,常用指标包括准确率、召回率、F1分数、AUC-ROC等。
数据集
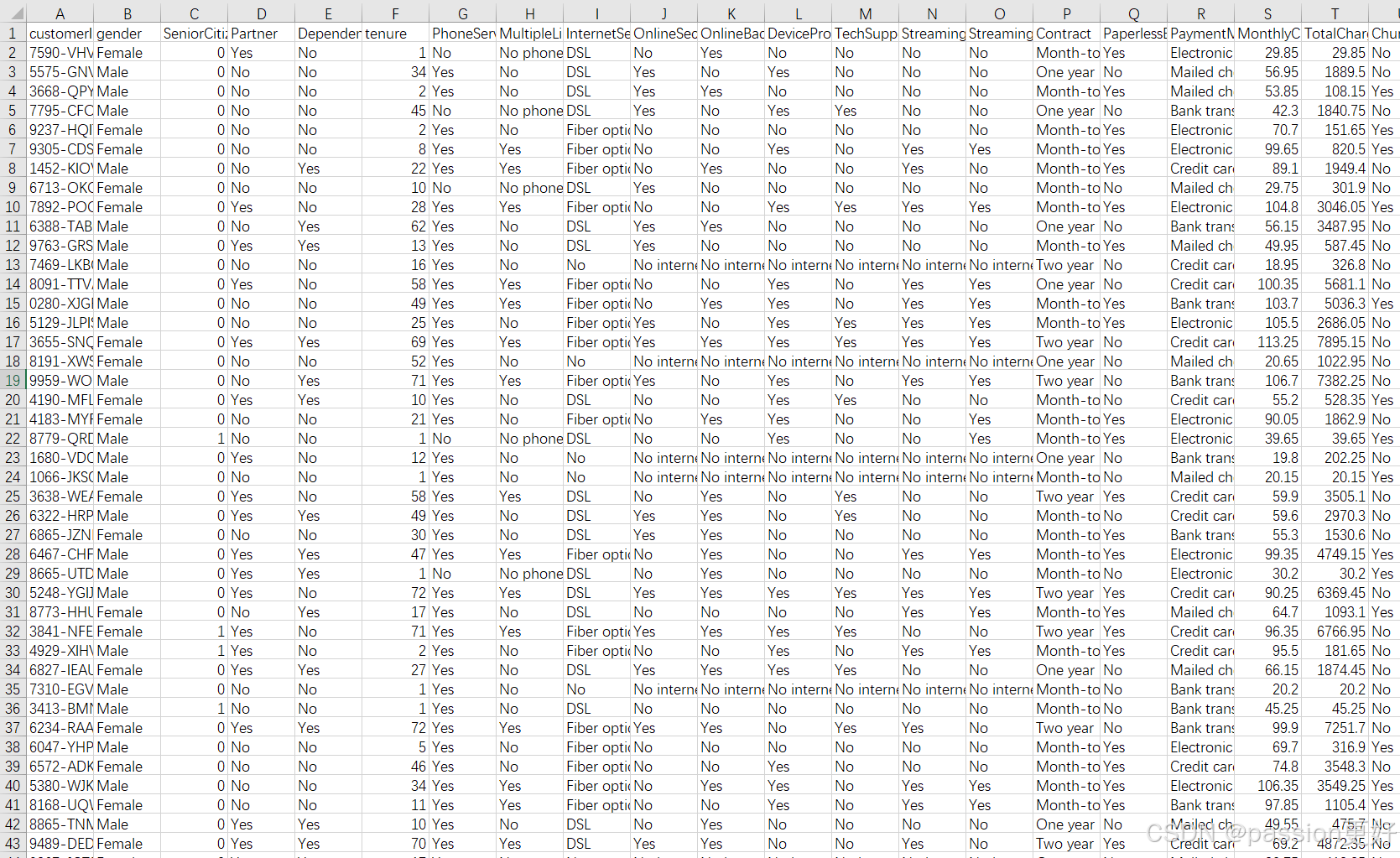
数据集如下图所示:
- customerID: 客户的唯一标识符
- gender: 性别
- SeniorCitizen: 是否为老年人
- Partner: 是否有伴侣
- Dependents: 是否有受抚养人
- tenure: 客户服务年限(通常以月为单位)
- PhoneService: 是否订阅了电话服务
- MultipleLines: 是否有多条电话线
- InternetService: 互联网服务提供商类型
- OnlineSecurity: 是否订阅了在线安全服务
- OnlineBackup: 是否订阅了在线备份服务
- DeviceProtection: 是否订阅了设备保护服务
- TechSupport: 是否订阅了技术支持服务
- StreamingTV: 是否订阅了流媒体电视服务
- StreamingMovies: 是否订阅了流媒体电影服务
- Contract: 合同类型(如月付、年付等)
- PaperlessBilling: 是否采用无纸化账单
- PaymentMethod: 支付方式
- MonthlyCharges: 每月费用
- TotalCharges: 总费用
- Churn: 是否流失
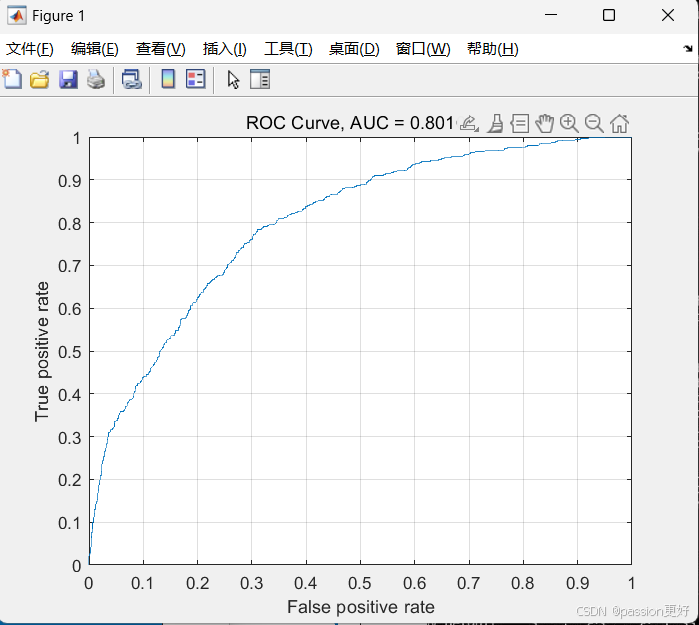
结果

代码实现
% 数据加载
data = readtable('WA_Fn-UseC_-Telco-Customer-Churn.csv');
% 转换二分类特征为数值型
data.Churn = strcmp(data.Churn, 'Yes'); % 'Yes'为1,'No'为0
data.gender = strcmp(data.gender, 'Male');
data.Partner = strcmp(data.Partner, 'Yes');
data.Dependents = strcmp(data.Dependents, 'Yes');
data.PhoneService = strcmp(data.PhoneService, 'Yes');
data.PaperlessBilling = strcmp(data.PaperlessBilling, 'Yes');
% 填充缺失值
data.TotalCharges(isnan(data.TotalCharges)) = 0;
% % 独热编码列
% categoricalVars = {'MultipleLines', 'OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies',...
% 'InternetService', 'Contract', 'PaymentMethod'};
% 提取特征列
allFeatures = data{:, {'SeniorCitizen', 'tenure', 'MonthlyCharges', 'TotalCharges', 'gender', 'Partner', 'Dependents', 'PhoneService', 'PaperlessBilling'}};
% 提取目标变量
target = data.Churn;
target = table(target, 'VariableNames', {'Churn'});
% 划分数据集为训练集和测试集
cv = cvpartition(height(allFeatures), 'HoldOut', 0.3); % 70%训练,30%测试
idx = cv.test;
XTrain = allFeatures(~idx, :);
YTrain = target(~idx, :);
XTest = allFeatures(idx, :);
YTest = target(idx, :);
% 训练随机森林模型回归预测
rfModel = TreeBagger(50, XTrain, YTrain.Churn, 'Method', 'classification');
% 预测
YTestPredicted = predict(rfModel, XTest);
% 评估模型
YTestPredicted = str2double(YTestPredicted);
accuracyRF = sum(YTestPredicted == YTest.Churn) / numel(YTest.Churn);
fprintf('Random Forest Accuracy: %.2f%%\n', accuracyRF * 100);
% 获取概率预测
[~, scores] = predict(rfModel, XTest);
% 绘制ROC曲线
[X,Y,T,AUC] = perfcurve(YTest.Churn, scores(:,2), 1); % 假设scores(:,2)是正类的预测概率
figure;
plot(X,Y);
xlabel('False positive rate'); ylabel('True positive rate');
title(['ROC Curve, AUC = ', num2str(AUC)]);
grid on;
% 转换预测结果为逻辑值
YTestPredicted_logical = logical(YTestPredicted);
% 计算混淆矩阵
confMat = confusionmat(YTest.Churn, YTestPredicted_logical);
% 显示混淆矩阵
figure;
confusionchart(confMat, {'Not Churn', 'Churn'});
title('Confusion Matrix - Random Forest');
% 预测图
figure;
gscatter(XTest(:,1), XTest(:,2), YTestPredicted);
xlabel('Feature 1');
ylabel('Feature 2');
title('Random Forest Predicted Classes');
legend('Class 0', 'Class 1', 'Location', 'best');