Apache Spark是用于大规模数据处理的统一分析引擎
简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据,Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。
而Python语言,则是Spark重点支持的方向。
Spark对Python语言的支持,重点体现在,Python第三方库PySpark之上。
PySpark是由Spark官方开发的Python语言第三方库。可以使用pip程序快速的安装PySpark并像其它三方库那样直接使用。

pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark

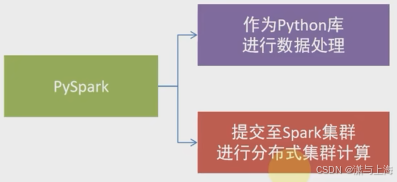
用pyspark写出来的库,既可以在电脑上简单运行作数据分析处理,又可以迁移到spark集群进行分布式集群计算
学pyspark的目的就是衔接大数据方向,学习路线:

构建PySpark执行环境入口对象
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境唯一入口对象是:类SparkContext的类对象
# 导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象:local表示本机(单机)运行,如果想用分布式集群则还要改参数,此处不涉及
conf = SparkConf().setMaster("1ocal[*]").\
setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象
sc=SparkContext(conf=conf)
#打印PySpark的运行版本
print(sc.version)
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
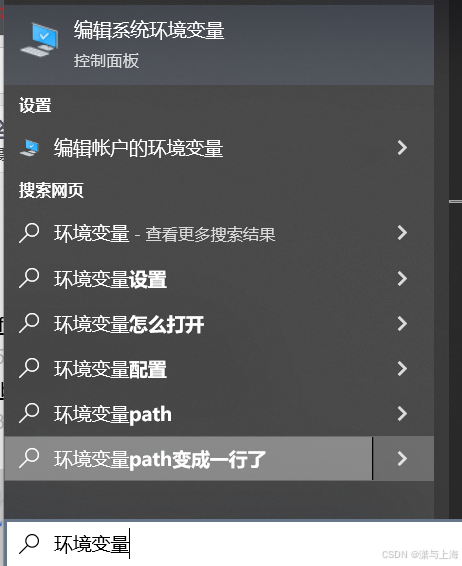
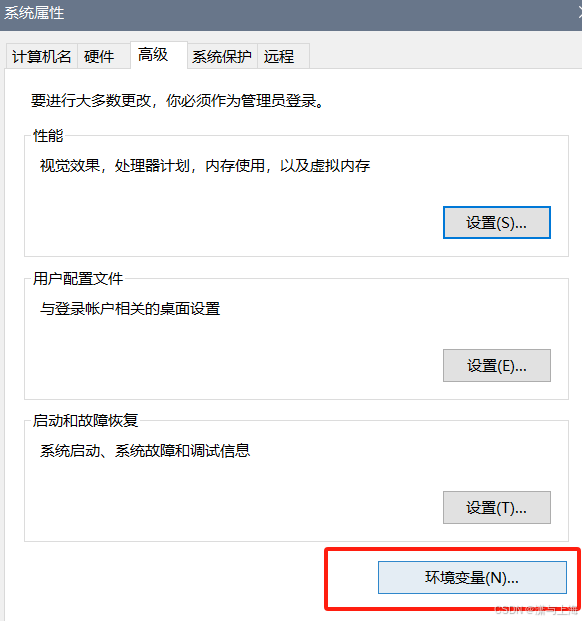
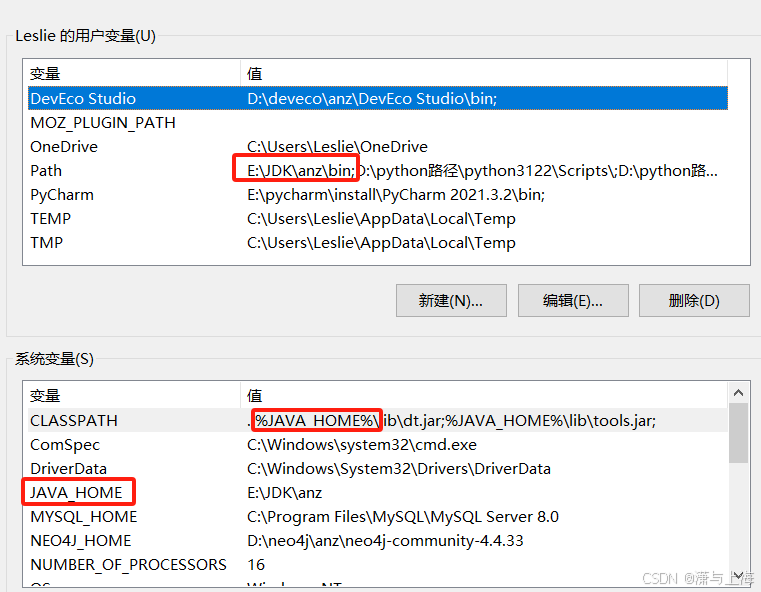
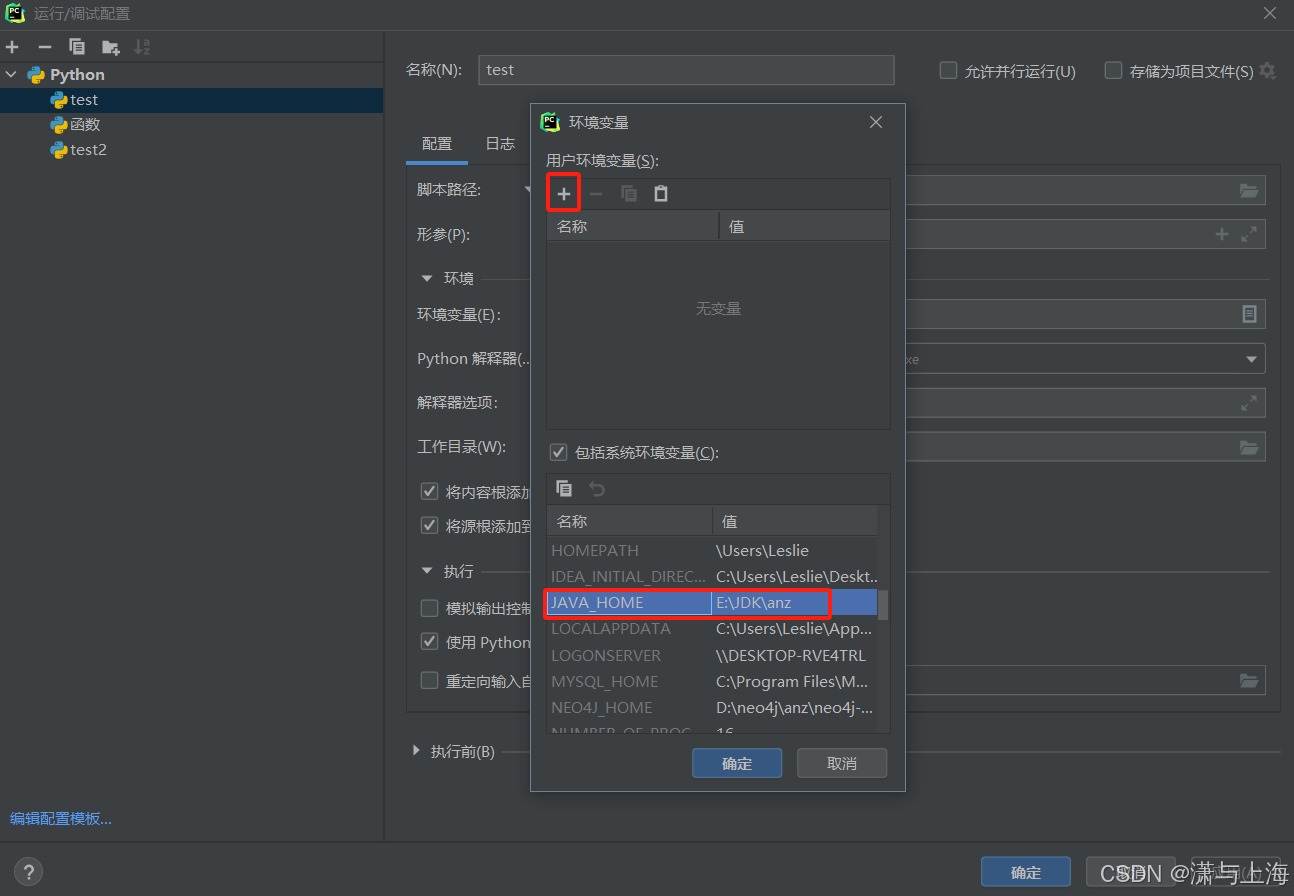
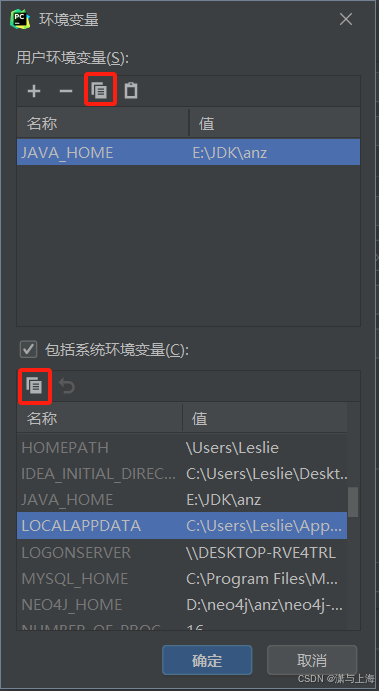
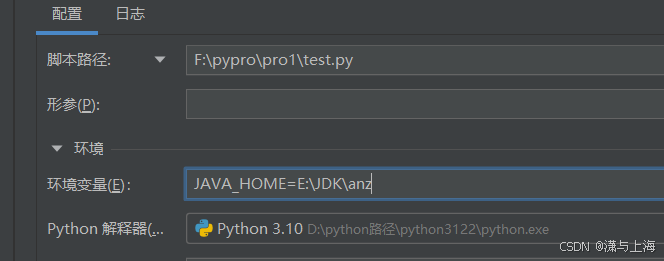
在pycharm中使用PySpark 出现Java gateway process exited before sending its port number.
(最新最全)pyspark报错Exception: Java gateway process exited before sending its port number