目录
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
# 数据加载和预处理
gstock_data = pd.read_csv(r'D:\lstm-cnn\lstm-snn\000001_SZSE.csv')
gstock_data = gstock_data[['date', 'open', 'close']]
gstock_data['date'] = pd.to_datetime(gstock_data['date'])
gstock_data.set_index('date', drop=True, inplace=True)
# 数据缩放
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(gstock_data)
scaled_df = pd.DataFrame(scaled_data, index=gstock_data.index, columns=gstock_data.columns)
# 划分训练集和测试集
training_size = int(len(scaled_df) * 0.50)
train_data = scaled_df.iloc[:training_size]
test_data = scaled_df.iloc[training_size:]
# 创建序列和标签
def create_sequence(dataset, seq_length=50):
X, y = [], []
for i in range(len(dataset) - seq_length):
X.append(dataset.iloc[i:i + seq_length][['open', 'close']].values)
y.append(dataset.iloc[i + seq_length][['open', 'close']].values)
return np.array(X), np.array(y)
train_seq, train_label = create_sequence(train_data)
test_seq, test_label = create_sequence(test_data)
# 重塑输入数据以符合LSTM的输入要求 [samples, time steps, features]
train_seq = np.reshape(train_seq, (train_seq.shape[0], train_seq.shape[1], 2))
test_seq = np.reshape(test_seq, (test_seq.shape[0], test_seq.shape[1], 2))
print("Train sequence shape:", train_seq.shape)
print("Test sequence shape:", test_seq.shape)
# 构建和训练模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(train_seq.shape[1], train_seq.shape[2])))
model.add(Dropout(0.1))
model.add(LSTM(units=50))
model.add(Dense(2)) # 假设输出是'open'和'close'价格
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(train_seq, train_label, epochs=80, batch_size=32, validation_data=(test_seq, test_label), verbose=1)
# 预测并逆变换结果
test_predicted = model.predict(test_seq)
test_inverse_predicted = scaler.inverse_transform(test_predicted)
seq_length = 10 # 假设你想要跳过前10个数据点
test_data_inverse = scaler.inverse_transform(test_data.values[seq_length:])
# 考虑到seq_length,确保索引对齐
predicted_index = test_data.index[seq_length:seq_length + len(test_predicted)]
# 创建包含预测和实际数据的DataFrame
gs_slic_data = pd.DataFrame(test_inverse_predicted, columns=['open_predicted', 'close_predicted'],
index=predicted_index)
test_data_inverse = scaler.inverse_transform(test_data.iloc[seq_length:].values)
# 假设 test_predicted 是你的模型预测结果,test_data_inverse 是逆变换后的测试数据
# 确定预测结果的长度
predicted_length = len(test_predicted)
# 裁剪 test_data_inverse 以匹配预测结果的长度
# 注意,我们已经跳过了前 seq_length 个数据点,因此从 seq_length 开始裁剪
test_data_inverse_cropped = test_data_inverse[:predicted_length, :]
# 现在你可以将裁剪后的数据添加到 gs_slic_data DataFrame 中
gs_slic_data[['open_actual', 'close_actual']] = test_data_inverse_cropped[:, :2]
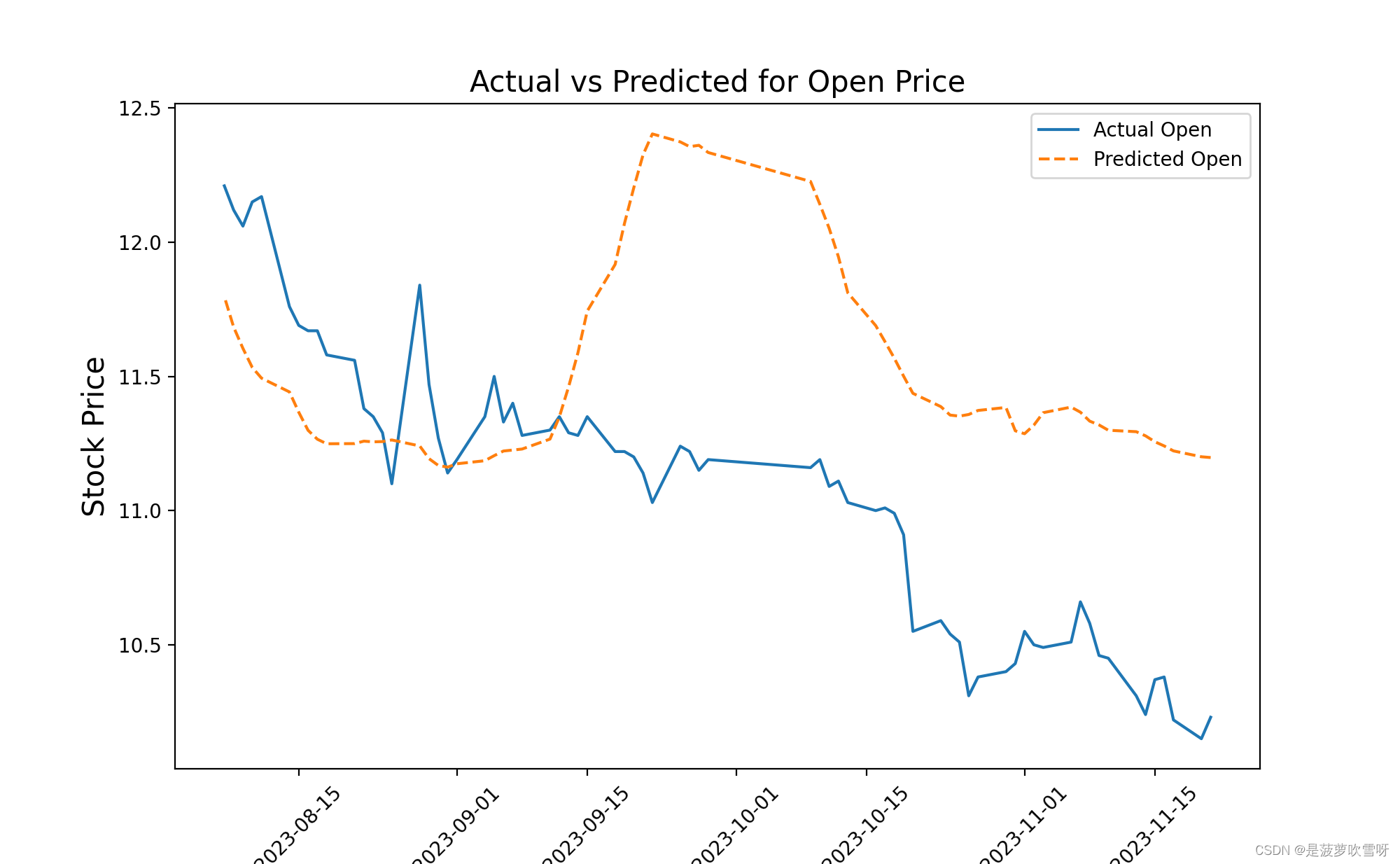
# 绘制实际与预测的价格对比图(仅绘制'open'价格作为示例)
plt.figure(figsize=(10, 6))
plt.plot(gs_slic_data.index, gs_slic_data['open_actual'], label='Actual Open')
plt.plot(gs_slic_data.index, gs_slic_data['open_predicted'], label='Predicted Open', linestyle='--')
plt.xticks(rotation=45)
plt.xlabel('Date', size=15)
plt.ylabel('Stock Price', size=15)
plt.title('Actual vs Predicted for Open Price', size=15)
plt.legend()
plt.show()