常见得反爬机制及解决办法
1、针对请求头做出得反爬
简介:网站通过去检查headers中的User-Agent字段来反爬,如果我们没有设置请求头,那么headers默认是python这样就会出现访问失败、没有权限等原因,如果去伪造一个请求头是可以避开得,不过如果短时间内频繁使用同一个User-Agent访问可能会被检测出来导致被封掉爬虫
解决办法:通过fake_useragent构造随机请求头
第一步:下载fake_useragent
可以直接在cmd当中输入:
pip install fake-useragent接下来设置代码如下:
import requests
from fake_useragent import UserAgent
import random #随机模块
ua = UserAgent() # 创建User-Agent对象
useragent = ua.random
headers = {'User-Agent': useragent}
到这里得时候其实已经写好了,但肯定有小伙伴会想着去测试一下是不是真的自己使用了随机请求头那么我们去访问 http://httpbin.org/headers 看下返回得请求头数据
第二步:验证请求头
import requests
from fake_useragent import UserAgent
import random #随机模块
ua = UserAgent() # 创建User-Agent对象
useragent = ua.random #随机使用请求头
headers = {'User-Agent': useragent}
url='http://httpbin.org/headers'
renoes=requests.get(url,headers=headers)
print(renoes.text)运行两次结果如下
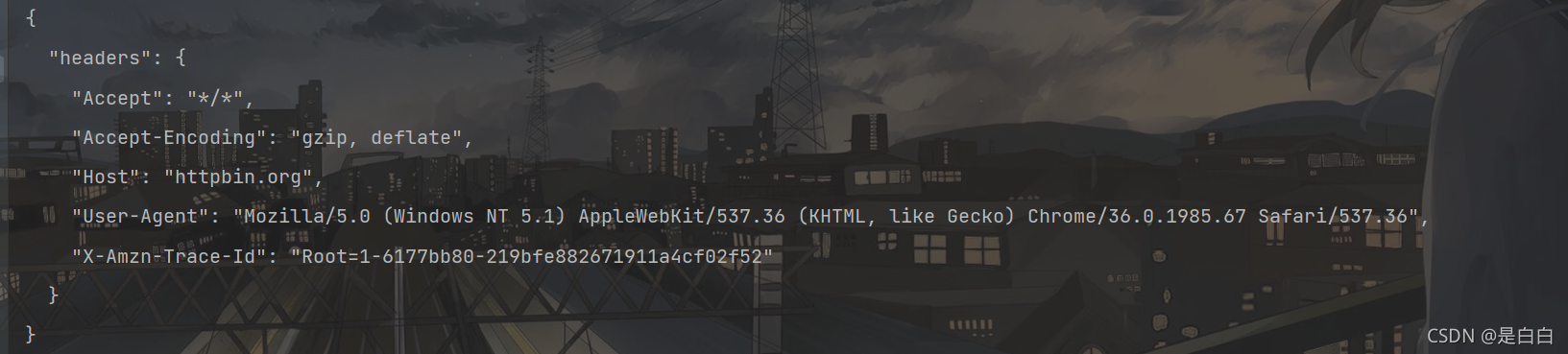

可以发现请求头已经发生了变化并且每次不一样
补充说明一点:
在使用fake_useragent有时候会报错第一个原因可能是UserAgent列表发生了变动,而本地UserAgent的列表未更新所导致
解决方法可以参考这篇文章