第一点:特征选择的原因,方式以及区别?





第二点:强化学习的五元组,与监督学习的不同,如何解决探索-利用窘境







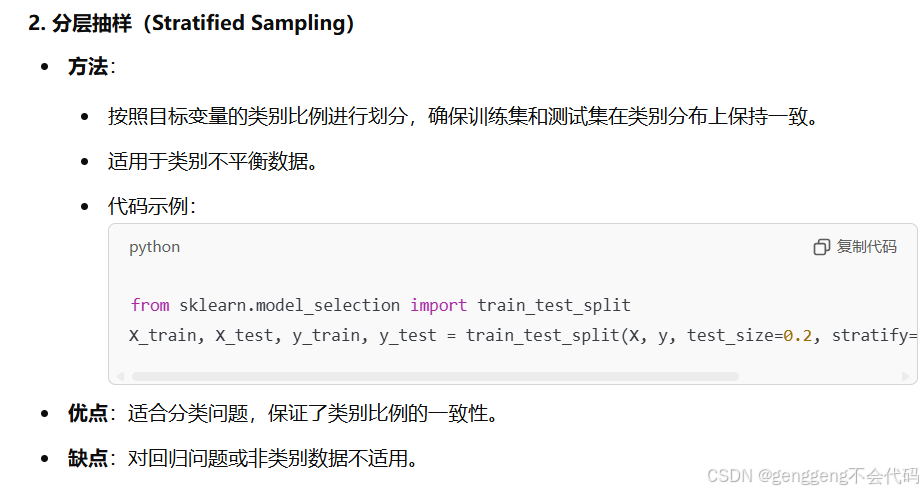
第三点:如何产生测试集?





第四点:朴素贝叶斯的建模过程,困难及解决方法



二、朴素贝叶斯的困难及解决方法
1. 条件独立性假设不成立
- 困难:朴素贝叶斯假设特征在条件 y 下相互独立,但在实际问题中,特征通常是相关的。例如,文本分类中,词语共现频率可能很高。
- 解决方法:
- 引入特征选择或降维:通过选择重要特征或使用降维技术(如 PCA)减少冗余特征。
- 采用增强模型:如联合特征建模(考虑特征交互)。
- 使用更复杂的模型:如逻辑回归或决策树。

3. 连续特征处理
- 困难:朴素贝叶斯对连续特征通常假设为高斯分布,但实际分布可能偏离高斯。
- 解决方法:
- 非参数方法:如用直方图法或核密度估计 P(xi∣y)。
- 离散化:将连续特征离散化(分箱处理)后按离散型特征处理。
4. 类别不平衡问题
- 困难:当某类别样本数量远大于其他类别时,先验概率 P(y) 会偏向大类别,导致模型偏向主导类别。
- 解决方法:
- 调整类别权重:人为加大小类别的权重。
- 过采样/欠采样:通过 SMOTE 等技术对数据集重新平衡。
5. 多模态数据
- 困难:不同类型的数据(如数值型和文本型)同时存在时,如何统一处理。
- 解决方法:
- 对每种特征单独建模,组合计算总概率。
- 对不同模态的数据预处理成相同类型后统一处理。
6. 数据分布偏离先验假设
- 困难:训练数据分布与测试数据分布不同(分布漂移)。
- 解决方法:
- 使用贝叶斯网络或条件随机场等更灵活的模型。
- 使用域适配(Domain Adaptation)技术调整模型。
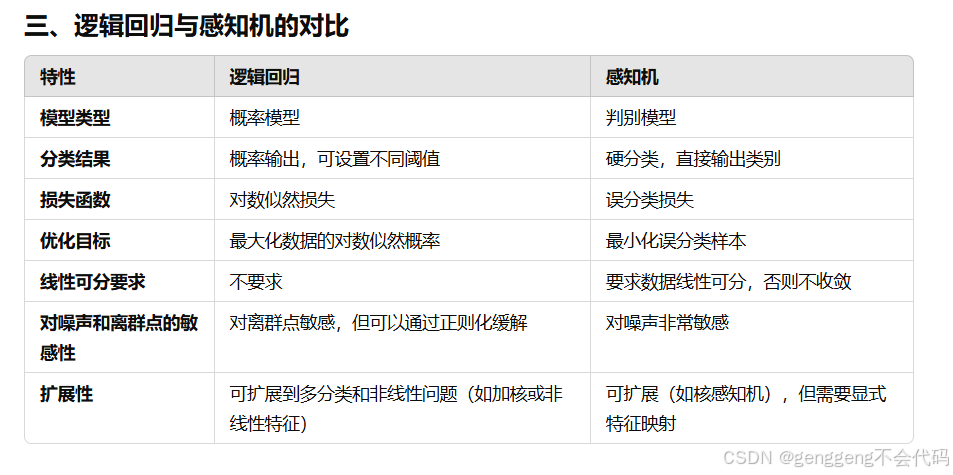
第五点:逻辑回归,感知机的分类方法







第六点:线性回归,主成分分析的方法
主成分分析(PCA)是一种常用的降维技术,用于将高维数据映射到低维空间,同时尽可能保留数据的方差。
PCA与线性回归结合的过程


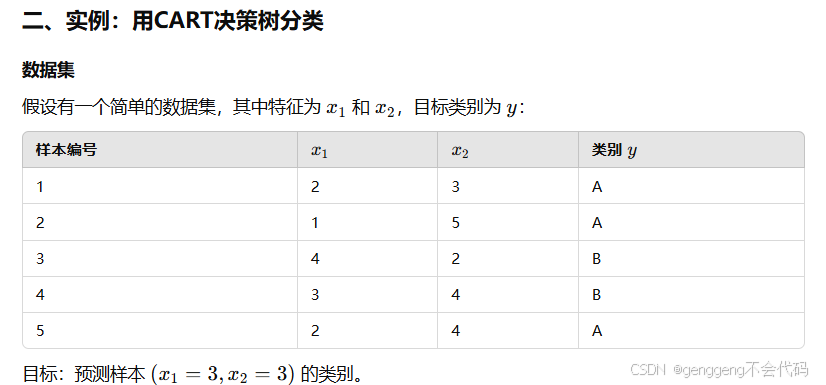
第七点:如何利用CART决策树计算预测某样本属于哪个类别,要求会计算?
CART(Classification And Regression Tree)决策树是一种基于二叉树结构的分类或回归算法。在分类任务中,CART决策树使用**基尼系数(Gini Index)**作为划分节点的准则。





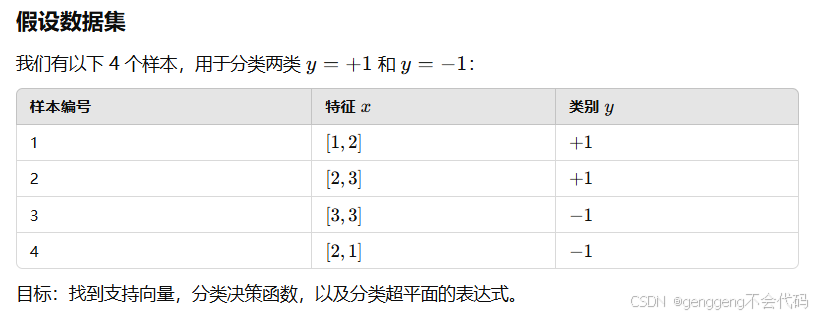
第八点:已知对偶方式,如何计算支持向量机的支持向量、分类决策函数和分类超平面方程
支持向量机(SVM)的核心是找到一个决策边界(超平面)来最大化分类间隔。通过对偶方式,我们可以高效计算支持向量、分类决策函数和分类超平面方程。











第九点:采用神经网络进行预测时,构造什么模型,采用什么算法优化,可能会出现什么现象,该如何解决



三、可能出现的现象及解决方法
1. 过拟合
- 现象:
- 训练集误差低,测试集误差高。
- 模型在训练集上表现很好,但泛化能力差。
- 解决方法:
- 数据层面:
- 增加训练数据量。
- 数据增强(如图像旋转、翻转、缩放)。
- 模型层面:
- 添加正则化(L1/L2 或 Dropout)。
- 减小网络深度或宽度。
- 训练层面:
- 提前停止训练(Early Stopping)。
- 使用更少的训练轮次。
- 数据层面:
2. 欠拟合
-
现象:
- 训练集误差高,测试集误差也高。
- 模型未能学习到数据的规律。
-
解决方法:
- 数据层面:
- 检查数据是否有误(如标注错误、噪声过多)。
- 特征工程(增加更多有意义的特征)。
- 模型层面:
- 增大模型复杂度(增加网络层数、每层神经元数量)。
- 使用更复杂的模型架构(如从简单 MLP 升级为 CNN)。
- 训练层面:
- 增加训练轮次。
- 更换优化算法(如从 SGD 换为 Adam)。
- 使用更小的学习率。
- 数据层面:
3. 梯度消失或梯度爆炸
-
现象:
- 梯度消失:网络的梯度逐渐趋近于零,导致训练停滞。
- 梯度爆炸:网络的梯度变得极大,导致参数更新失控。
-
解决方法:
- 数据层面:
- 归一化输入数据(如标准化到 [0,1][0, 1][0,1] 或均值为 0、方差为 1)。
- 模型层面:
- 替换激活函数:ReLU 替换 Sigmoid 或 Tanh。
- 使用梯度裁剪(Gradient Clipping)防止梯度爆炸。
- 使用批归一化(Batch Normalization)缓解梯度消失或爆炸。
- 训练层面:
- 减小初始学习率。
- 数据层面:
4. 收敛慢
-
现象:
- 模型训练需要大量时间才能收敛。
-
解决方法:
- 数据层面:
- 增加数据量或进行数据增强。
- 模型层面:
- 初始化权重时使用更好的方法(如 Xavier 或 He 初始化)。
- 训练层面:
- 使用更快的优化算法(如 Adam)。
- 调整学习率,尝试学习率调度。
- 数据层面:
5. 局部最优
-
现象:
- 模型训练停滞在局部最优解。
-
解决方法:
- 数据层面:
- 增加数据量。
- 模型层面:
- 使用更复杂的网络结构(如深层网络)。
- 训练层面:
- 使用带动量的优化算法(如 Momentum、Adam)。
- 增大模型的初始化权重范围。
- 数据层面:

第十点:集成学习的现象,思想,和泛化策略
集成学习:现象、思想和泛化策略
集成学习是一种通过组合多个模型来提高预测性能的机器学习方法。以下详细分析其核心概念、背后的思想以及如何通过泛化策略提升模型性能。
一、集成学习的现象
集成学习的显著现象是:
-
性能提升:
- 单个模型的预测能力有限,但通过结合多个模型,可以显著提高整体的预测精度。
- 适合解决高偏差(欠拟合)或高方差(过拟合)问题。
-
稳定性增强:
- 单个模型对训练数据的扰动可能敏感,但集成模型对噪声和异常值的鲁棒性更强。
-
适应性:
- 不同模型对不同类型的数据有各自的优势,通过集成可以利用多种模型的优点。
现象示例
- 在分类问题中,集成学习方法(如随机森林)比单颗决策树有更低的误差率。
- 在回归问题中,基于多个弱回归模型(如梯度提升树)的集成方法往往能捕捉更复杂的数据模式。
二、集成学习的思想
集成学习的核心思想是通过多个模型的组合提高泛化性能,其理论基础主要包括以下几点:
1. 弱学习器到强学习器
- 单个弱学习器的性能略优于随机猜测,但通过合适的组合方式,可以构造出一个强学习器。
- 例子:Adaboost 算法通过逐步改进错误样本的权重,使多个弱分类器形成强分类器。

3. 多样性与互补性
- 基学习器之间的差异性是集成学习成功的关键:
- 如果所有基学习器完全相同,集成效果与单个模型无异。
- 不同模型在不同样本或特征上表现出互补性,可以提升整体效果。
4. 减少方差与偏差
- 方法:
- 偏差减少: 通过加权平均(如 Adaboost)聚焦难分类样本。
- 方差减少: 通过随机抽样(如随机森林)减少对训练数据的过拟合。
三、集成学习的泛化策略
集成学习的泛化能力(即在未见数据上的表现)直接决定了模型的实用性。以下是常用的泛化策略:
1. 模型集成方法
-
Bagging(Bootstrap Aggregating):
- 核心思想:通过对训练数据进行随机重采样,生成多个子数据集,分别训练多个基学习器,最后通过平均或投票得到最终预测。
- 特点:
- 主要用于降低方差,防止过拟合。
- 典型方法:随机森林。
-
Boosting:
- 核心思想:逐步训练多个弱学习器,每个模型都聚焦于前一个模型错分类的样本,最后进行加权投票。
- 特点:
- 主要用于降低偏差,提升预测精度。
- 典型方法:Adaboost、梯度提升树(GBDT)、XGBoost。
-
Stacking:
- 核心思想:使用多个基学习器生成预测结果,再通过一个元模型(如线性回归或神经网络)对这些结果进行组合。
- 特点:
- 提供更灵活的模型组合方式。
- 适合各种基学习器,不要求它们同质。
-
Voting(简单投票):
- 将多个模型的预测结果直接通过多数投票(分类)或加权平均(回归)合并。
- 适合模型较少且差异性较大的场景。
2. 提高模型多样性的策略
-
数据多样性:
- 对训练数据进行随机抽样(如 Bagging)。
- 进行数据增强(如图像数据中的旋转、翻转)。
-
模型多样性:
- 使用不同的模型(如决策树、逻辑回归、神经网络)。
- 使用不同的超参数设置(如随机森林中树的深度、分裂准则)。
-
特征多样性:
- 对特征进行随机选择(如随机森林)。
- 提取不同的特征子集进行训练。
3. 防止过拟合的策略
- 正则化:
- 在 Boosting 方法中,限制模型复杂度(如 XGBoost 的正则化参数)。
- 提前停止:
- 通过监控验证集误差,提早结束训练以避免过拟合。
- 模型剪枝:
-
减少复杂度过高的基学习器。
-
4. 模型评估与选择
- 使用交叉验证(Cross-Validation)评估模型的泛化性能。
- 如果基模型的性能差异过大,可以使用加权投票或对差异较大的模型进行筛选。