目录
一、概述

该论文提出一种大型空间模型(Larget Spatial Model,LSM)的统一框架,可以直接从无姿态的RGB图像中重建神经辐射场。LSM可以单次前向传递中同时估计几何、外观和语义,统一了多个三维视觉任务,首次实现实时的语义3D重建和渲染,无需显式的相机参数。
(1)提出统一的三维表示的端到端框架,并实现3D语义分割,以及直接从无显式相机参数的新视图中合成,无需额外的SfM步骤,可以同时执行多个任务,通过统一的方法扩展多种视觉任务,并超过当前SOTA基线。
(2)利用跨视图注意力的Transformer来进行几何预测,并结合分层跨模态注意力来丰富几何特征。
(3)引入预训练的2D语义网络模型来增强3D语义理解。
(4)通过点级的局部上下文聚合,实现细粒度的特征集成,并预测各向异性的3DGS分布和RGB,深度,语义的图像输出。
二、相关工作
1、SfM和可微神经表示
SfM(运动恢复结构)从多视角图像中估计相机姿态和重建稀疏3D结构,传统的pipeline通常不是端到端的,一般分为描述子提取,对应关系估计,增量的捆绑调整。
近期深度学习的发展提供了SfM的准确率和有效性,而这种方法也广泛的应用与3D视觉中,而可微的神经表示也就是从SfM计算的精确的相机姿态作为前提而来。NeRF方法依赖于COLMAP离线估计的相机姿态而来,3DGS使用SfM生成的3D点作为初始化,并逐渐应用到机器人,健康医疗等多领域。
另外最新的工作就是该论文提出的,利用2D特征来上升到3D任务中。
2、端到端的Image-to-3D
3D重建包含很多传统的工作比如SfM,MVS,SDF等。最近的工作包含显式和隐式来生成3D模型,语义理解工作一般通过额外的优化步骤或者在重建预处理中进行。
大多数方法依赖于预处理工作,比如估计相机姿态,生成稀疏点云,最后在test-time中进行优化,但是这种依赖限制了大尺度数据的可伸缩性。
最新的无姿态的前馈方法,如Scene Representation Transformers将多个图像表示为潜在场景表示,即使存在不准确的相机姿态或无相机姿态也可以生成新视角图像,但该方法很难建立显式的几何图形。
DUSt3R考虑使用密集点云来生成标准尺度下的点对齐的几何预测,但是密集点云限制了可扩展性。
InstantSplat集成了DUSt3R的优势,考虑利用几何约束来进行点云对齐,优化姿态。(该作者也是InstantSplat的作者)
而该论文考虑引入三维注释(三维语义分割),通过引入语义各向异性高斯函数,在没有注释的情况下,将二维特征映射到三维语义嵌入,利用这种较为轻量的annotations在一个统一框架中解决3D感知问题。
三、LSM
LSM(大型语义模型)分为五个模块:密集几何预测3D点并生成深度图,2D信息特征提取,点特征增强,可微渲染。
首先输入两张无姿态图像经过分块,正弦编码,采用双目ViT架构利用跨视角注意力机制预测像素对齐的几何点图,另外输入无姿态图像到已训练好的2D多模态模型中来获得2D特征,3D特征与3D点坐标和2D特征进行点特征融合并通过一个特定的局部Transformer(Decoder部分也是跨视角的)经两组MLP分别输出5个参数(带有RGB的,和带有语义信息的),并经过可微渲染生成三维语义重建和RGB的一般新视角合成。

1、密集几何预测
首先输入两张无姿态图像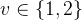
之后通过点图可以利用DPT Head回归得到深度图。
此处有两个损失:深度损失和置信度图损失。
深度损失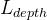

其中归一化因子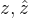
置信度图损失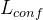

其中M是像素对齐置信度图,类似于DUSt3R,D表示坐标点集合,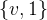
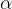
2、2D信息特征提取
LSM框架中利用一个预训练的2D多模态模型LSeg(未提及)来提取2D特征信息,通过引入多模态的特征嵌入,可能引入了文本特征嵌入,之后通过分词模块将特征映射到潜在空间,最终输出语义特征图。
这里引入一个Dist特征损失:
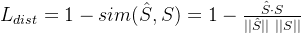
其中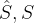
3、点特征融合
首先输入密集几何预测得到的点图,经部分Point Transformer的encoder部分得到中间层点特征,之后将密集几何预测中的encoder输出与LSeg中的特征信息concat到中间层,并经过Decoder部分(含跨视角交叉注意力机制,也是保证视角一致性的),分别经过两个并行MLP分支得到不同的4个参数,一个是RGB高斯参数用于一般三维重建,一个是语义信息高斯参数用于三维语义重建。
连带密集几何预测的输出点坐标(用于高斯分布的中心位置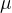


4、可微渲染
可微渲染部分根据上述的两组高斯分布,经过快速光栅化来进行渲染,生成语义高斯场和RGB高斯场。最后通过新视角生成语义图和RGB图。
5、损失函数
因为该框架是端到端的,所以可以直接定义一个完整的损失函数,在原有的三个损失函数的基础上,新增了对于RGB图像和语义的损失(两者的L2范数)

四、实验
通过无姿态图像进行新视角语义图生成。

对于一般的RGB三维重建,相较于pixelsplat,我们不再需要获得相机姿态。

三维语义信息的分割,相较于以往的方法以及只使用LSeg更为细节。

参考项目:Large Spatial Model