训练神经网络实际上就是通过重复两个关键步骤来调整神经网络中的权重:前向传播和反向传播。
-
在前向传播中,我们将一组权重应用于输入数据,将其传递给隐藏层,对隐藏层计算后的输出使用非线性激活,通过若干个隐藏层后,将最后一个隐藏层的输出与另一组权重相乘,就可以得到输出层的结果。对于第一次正向传播,权重的值将随机初始化。
-
在反向传播中,尝试通过测量输出的误差,然后相应地调整权重以降低误差。神经网络重复正向传播和反向传播以预测输出,直到获得令误差较小的权重为止。
1.3 神经网络的应用
最近,神经网络在各种应用中的广泛采用。神经网络可以通过多种方式进行构建。以下是一些常见的构建方法:
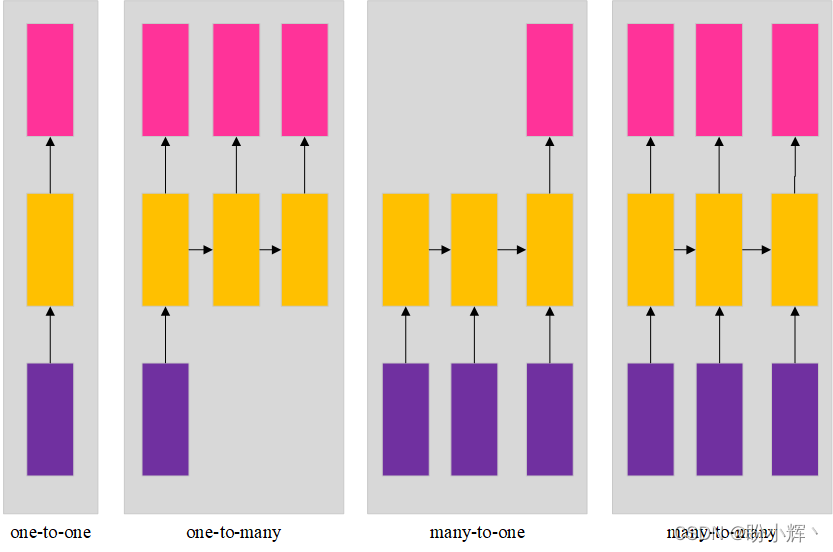
底部的紫色框代表输入,其后是隐藏层(中间的黄色框),顶部的粉色框是输出层。一对一的体系结构是典型的神经网络,在输入和输出层之间具有隐藏层。不同体系结构的示例如下:
| 架构 | 示例 |
| — | — |
| one-to-many | 输入是图像,输出是图像的预测类别概率 |
| many-to-one | 输入是电影评论,输出评论是好评或差评 |
| many-to-many | 将一种语言的句子使用神经网络翻译成另一种语言的句子 |
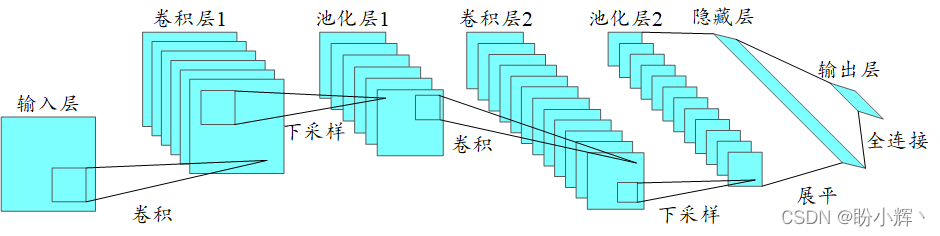
现代神经网络中经常用到的一种架构称为卷积神经网络 (Convolutional Neural Networks, CNN),可以用来理解图像中的内容并检测目标内容所在的位置,该体系架构如下所示(在之后的学习中会进行详细介绍):
神经网络在推荐系统,图像分析,文本分析和音频分析的都有着广泛的应用,神经网络能够灵活地使用多种体系结构解决问题,可以预料的是,神经网络的使用范围将会越来越广。
接下来,我们将根据神经网络训练的两个关键步骤——前向传播和反向传播——介绍神经网络模型的构建。
为了进一步了解前向传播的工作方式,我们将通过一个简单的示例来构建神经网络,其中神经网络的输入为 (1, 1),对应的输出为 0。
我们使用的神经网络具有一个隐藏层,一个输入层和一个输出层。由于要使输入层能够以更大的维度表示,因此隐藏层中的神经元数量多于输入层中的神经元。
2.1 计算隐藏层节点值
第一次进行正向传播时,首先需要为所有连接分配权重,这些权重是基于高斯分布随机选择的,但是神经网络训练过程之后的最终权重不需要服从特定分布,假定初始网络权重如下:
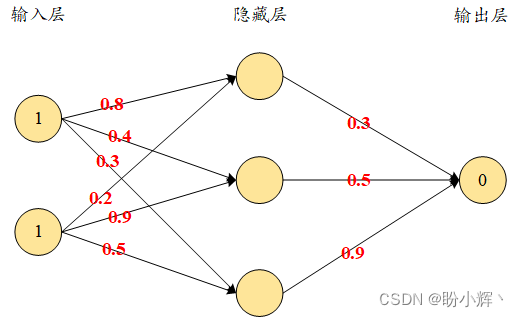
接下来,我们将输入与权重相乘以计算隐藏层中隐藏单元的值,隐藏层的节点单位值计算结果如下:
h 1 = 1 × 0.8 + 1 × 0.2 = 1 h 2 = 1 × 0.4 + 1 × 0.9 = 1.3 h 3 = 1 × 0.3 + 1 × 0.5 = 0.8 h_1=1\times 0.8+1\times 0.2 = 1\\ h_2=1\times 0.4+1\times 0.9 = 1.3\\ h_3=1\times 0.3+1\times 0.5 = 0.8 h1=1×0.8+1×0.2=1h2=1×0.4+1×0.9=1.3h3=1×0.3+1×0.5=0.8
下图展示了计算隐藏层的节点值后的网络示意图:
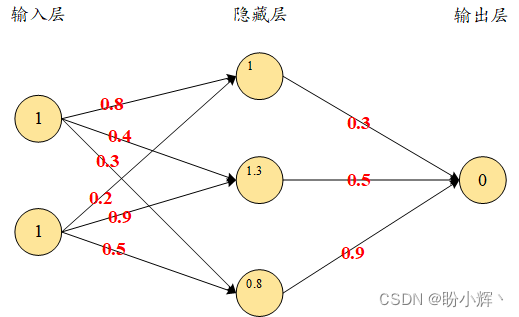
在以上步骤中,我们计算了隐藏节点的值。为简单起见,我们并未在隐藏层的节点中添加偏置项。接下来,我们将通过激活函数传递隐藏层的值,以便在输出中增加非线性。
NOTE:如果我们不在隐藏层中应用非线性激活函数,则神经网络本质上将成为从输入到输出线性连接。
2.2 应用激活函数
可以在网络中的多个网络层中应用激活函数,使用它们可以实现高度非线性,这对于建模输入和输出之间的复杂关系非常关键。在我们的示例中,使用 Sigmoid 激活函数如下所示:
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x)=\frac 1 {1+e^{-x}} sigmoid(x)=1+e−x1
通过将 Sigmoid 激活函数应用于隐藏层,我们得到以下结果:
f i n a l _ h 1 = s i g m o i d ( 1.0 ) = 0.73 f i n a l _ h 2 = s i g m o i d ( 1.3 ) = 0.78 f i n a l _ h 3 = s i g m o i d ( 0.8 ) = 0.69 final\_h_1 = sigmoid(1.0) = 0.73\\ final\_h_2 = sigmoid(1.3) = 0.78\\ final\_h_3 = sigmoid(0.8) = 0.69 final_h1=sigmoid(1.0)=0.73final_h2=sigmoid(1.3)=0.78final_h3=sigmoid(0.8)=0.69
下图展示了隐藏层的应用非线性激活函数后节点值的情况:
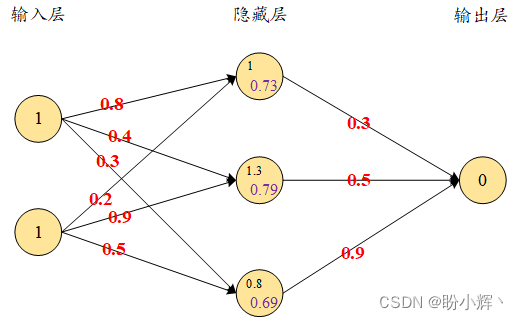
关于更多激活函数的介绍,参考《深度学习常用激活函数》。
2.3 计算输出层值
现在我们已经计算了隐藏层的值,最后将计算输出层的值。在下图中,我们将隐藏层值通过随机初始化的权重值连接到输出层。计算隐藏层值和权重值乘积的总和,得到输出值:
o u t p u t = 0.73 × 0.3 + 0.79 × 0.5 + 0.69 × 0.9 = 1.235 output = 0.73\times 0.3+0.79\times 0.5 + 0.69\times 0.9= 1.235 output=0.73×0.3+0.79×0.5+0.69×0.9=1.235
使用隐藏层值和权重值,我们可以得到网络的输出值,如下图所示:
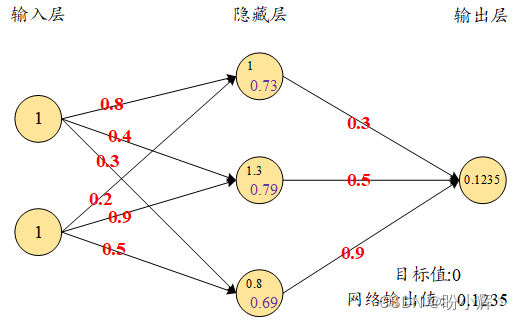
因为第一次正向传播使用随机权重,所以输出神经元的值与目标相差很大,相差为 +1.235 (目标值为0)。
2.4 计算损失值
损失值(也称为成本函数)是在神经网络中优化的值。为了了解如何计算损失值,我们分析以下两种情况:
-
连续变量预测
-
分类(离散)变量预测
2.4.1 在连续变量预测过程中计算损失
通常,当预测值为连续变量时,损失函数使用平方误差,也就是说,我们尝试通过更改与神经网络相关的权重值来最小化均方误差:
J ( θ ) = 1 m ∑ i = 1 m ( h ( x i ) − y i ) 2 J(\theta)=\frac 1 m \sum _{i=1} m(h(x_i)-y_i)2 J(θ)=m1i=1∑m(h(xi)−yi)2
其中, y i y_i yi 是实际值, h ( x ) h(x) h(x) 是我们对输入 x x x 进行变换以获得预测值 y y y 的网络模型, m m m 是输入数据集中的数据个数。
2.4.2 在分类(离散)变量预测中计算损失
当要预测的变量是离散变量时(也就是说,变量中只有几个类别),我们通常使用分类交叉熵损失函数。当要预测的变量具有两个不同的值时,损失函数为二分类交叉熵,而当要预测的变量具有多个不同的值时,损失函数为多分类交叉熵。
- 二分类交叉熵公式如下:
( y l o g ( p ) + ( 1 − y ) l o g ( 1 − p ) ) (ylog§+(1−y)log(1−p)) (ylog§+(1−y)log(1−p))
- 多分类交叉熵定义如下:
− ∑ i = 1 n y i l o g ( p n ) -\sum _{i=1} ^n y_i log(p_n) −i=1∑nyilog(pn)
其中, y y y 是输入实际对应的真实值, p p p 是输出的预测值, n n n 是数据量的总数。
2.4.3 计算网络损失值
由于我们在以上示例中预测的结果是连续的,因此损失函数值是均方误差,其计算方法如下:
e r r o r = 1.23 5 2 = 1.52 error = 1.235^2 = 1.52 error=1.2352=1.52
2.5 使用 Python 实现网络前向传播
通过以上学习,我们知道了通过在输入数据之上执行以下步骤以在前向传播中可以得出误差值:
-
随机初始化权重
-
通过将输入值乘以权重来计算隐藏层节点值
-
对隐藏层值执行激活
-
将隐藏层值连接到输出层
-
计算平方误差损失
计算所有数据点的平方误差损失值:
import numpy as np
def feed_forward(inputs, outputs, weights):
pre_hidden = np.dot(inputs,weights[0])+ weights[1]
hidden = 1/(1+np.exp(-pre_hidden))
out = np.dot(hidden, weights[2]) + weights[3]
squared_error = (np.square(pred_out - outputs))
return squared_error
在前面的函数中,我们将输入变量值、权重(如果是第一次迭代,则随机初始化)以及数据集中的实际输出作为 feed_forward 函数的输入。
我们通过对输入和权重进行矩阵乘法来计算隐藏层的值。此外,将偏置值添加到隐藏层中:
pre_hidden = np.dot(inputs,weights[0])+ weights[1]
其中 weights[0] 是权重值,weights[1] 是偏置值,利用此权重和偏置就可以将输入层连接到隐藏层。计算隐藏层的值后,就可以在隐藏层的值上使用激活函数:
hidden = 1/(1+np.exp(-pre_hidden))
通过将隐藏层的输出乘以将隐藏层连接到输出的权重,然后在输出上添加偏置项,来计算隐藏层的输出:
pred_out = np.dot(hidden, weights[2]) + weights[3]
一旦计算出输出,我们就可以计算出每一输入的平方误差损失,如下所示:
squared_error = (np.square(pred_out - outputs))
在前面的代码中,pred_out 是预测输出,而 outputs 是输入应对应的实际输出。通过以上简单的步骤,我们便可以在网络前向传播时计算损失值。
在正向传播中,我们将输入层与隐藏层连接到输出层。 在反向传播中,我们使用相反的过程。 每次将神经网络中的每个权重进行少量更改。权重值的变化将对最终损失值(增加或减少的损失)产生影响,我们需要朝着减少损失的方向更新权重。通过每次轻微更新权重并测量权重更新导致的误差变化,我们可以完成以下操作:
-
确定权重更新的方向
-
确定权重更新的幅度
在实施反向传播之前,我们首先了解神经网络的另一重要概念:学习率。学习率有助于我们建立更稳定的算法。例如,在确定权重更新的大小时,我们不会一次性就对其进行大幅度更改,而是采取更谨慎的方法来缓慢地更新权重。这使模型获得更高的稳定性;在之后的学习中,我们还将研究学习率如何帮助提高稳定性。
更新权重以减少误差的整个过程称为梯度下降技术,随机梯度下降是将误差最小化的手段。更直观地讲,梯度代表差异(即实际值和预测值之间的差异),而下降则表示差异减小;随机代表选择随机样本进行训练,并据此做出决策。除了随机梯度下降外,还有许多其他优化技术可以用于减少损失值。之后的学习中,还将讨论不同的优化技术。
反向传播的工作原理如下:
-
利用前向传播过程计算损失值。
-
略微改变所有的权重。
-
计算权重变化对损失函数的影响。
-
根据权重更新是增加还是减少了损失值,在损失减少的方向上更新权重值。
对数据集中的所有数据执行 1 次训练过程(前向传播+反向传播),称为 1 个 epoch。
为了进一步巩固我们对神经网络中反向传播的理解,让我们拟合一个已知的简单函数,查看如何得出权重。假设,待拟合函数为 y = 3 x y = 3x y=3x,我们期望得出权重值和偏置值(分别为 3 和 0)。
| x | 1 | 3 | 4 | 8 | 10 |
| — | — | — | — | — | — |
| y | 3 | 9 | 12 | 24 | 30 |
以上数据集可以表示为线性回归 y = a x + b y = ax + b y=ax+b,我们将尝试计算 a a a 和 b b b 的值(虽然我们已知它们分别是 2 和 0,但我们的目的是研究如何使用梯度下降获得这些值),将 a a a 和 b b b 参数随机初始化为 2.269 2.269 2.269 和 1.01 1.01 1.01 的值。接下来,我们将从零构建反向传播算法,以便清楚地了解如何在神经网络中计算权重。简单起见下,将构建一个没有隐藏层的简单神经网络。
- 初始化数据集,如下所示:
x = np.array([[1], [3], [4], [8], [10]])
y = np.array([[3], [9], [12], [24], [30]])
- 随机初始化权重和偏差值(在尝试确定 y = a x + b y = ax + b y=ax+b 方程中 a a a 和 b b b 的最优值时,只需要一个权重和一个偏置值):
w = np.array([[[2.269]], [[1.01]]])
- 定义神经网络并计算平方误差损失值:
import numpy as np
def feed_forward(inputs, outputs, weights):
out = np.dot(inputs, weights[0]) + weights[1]
squared_error = np.square(out - outputs)
return squared_error
在上述代码中,对输入与随机初始化的权重值进行了矩阵乘法,然后将其与随机初始化的偏置值相加。得到输出值后,便可以计算出实际值与预测值之差的平方误差值。
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!