样式传输的目的是从参考图像中再现具有样式的内容图像。现有的通用风格转换方法成功地以艺术或照片逼真的方式将任意风格传递给原始图像。然而,现有作品所定义的“任意风格”的范围由于其结构限制而在特定领域内受到限制。具体而言,根据预定义的目标域来确定内容保存和风格化的程度。因此,照片写实和艺术模型都难以为其他领域实现所需的风格转换。为了克服这一限制,我们提出了一种统一的体系结构,即领域感知风格传输网络(DSTN),它不仅从给定参考图像传输风格,还传输域的属性(即域性)。为此,我们设计了一种新的域性指标,该指标从参考图像的纹理和结构特征中捕获域性值。此外,我们引入了一个**具有领域感知跳过连接的统一框架,以自适应地将笔划和调色板转移到由领域性指标引导的输入内容。**我们的大量实验验证了我们的模型产生了更好的定性结果,并在艺术和照片真实风格化方面的代理度量方面优于先前的方法。所有代码和预训练权重均可在Kibeom-Hong/Domain-Aware-StyleTransfer

针对特定问题
由于其结构限制而在特定领域内受到限制。
用另一幅图像的风格重建一幅图像一直是一个长期的研究课题。作为一项开创性的工作,Gatys等人[5]提出了具有从预训练网络(即VGG-19)模型[25]中提取的深度特征的神经风格转移。之后,由于之前的一系列研究,我们可以看到几幅著名画家(如梵高)各种绘画风格的风格化图片。
现有的通用风格转换方法显示了在艺术或照片现实领域处理任意参考图像的能力。一方面,WCT[15]和AdaIN[10]变换内容图像的特征以匹配参考特征的二阶统计。在这些方法之后,一些艺术转移研究[24,33,3,28,9]试图从参考图像转移全球风格模式。同时,照片写实风格转移研究[19,16,31,1]侧重于在转移目标风格的同时保留原始结构。
然而,我们观察到“任意”的含义局限于特定领域(即,艺术或照片逼真),并且它来自于预定义目标领域的基本结构修改,如图2所示,艺术风格转移模型难以在解码器中保持清晰的细节,因为没有直接来自内容图像的线索。因此,当艺术风格转移方法与照片现实参考图像对抗时,内容图像会发生结构性失真(图1(b)-(f))。另一方面,照片逼真的风格转换模型严重限制了带有跳过连接的输入引用的转换。因此,他们缺乏表达艺术参考的精致图案(例如笔画图案)的能力(图1(g)-(h))。总之,当现有的任意样式传输模型接收其他域的样本作为参考时,它们会生成不希望的输出。
核心思想
为了克服这一限制,我们专注于从给定的参考图像中捕捉域特征,并自适应地调整风格化和结构保留的程度。为此,我们提出了域感知风格传输网络(DSTN),它是由具有域感知跳过连接的自动编码器和域性指示符组成的统一架构。首先,我们引入了领域感知跳过连接,以平衡内容保存和纹理风格化之间的关系,实现领域感知通用风格转移。与传递完整结构细节的传统跳过连接不同,所提出的跳过连接块根据域属性从样式化特征图调整高频分量的传输清晰度。
为了**从给定参考图像获得域属性(即,域性),我们设计了域性指示符。**我们的新指标通过利用从编码器的不同级别提取的纹理和结构特征图来分析域的特征。为了预测[0,1]范围内的连续域因子,我们建议使用混合样本来增加艺术和照片之间的中间空间。
通过提出的领域感知架构,DSTN分别提供语义和结构信息,实现艺术风格和照片真实风格的转换。因此,无论目标领域如何,DSTN都能为任意风格生成无可挑剔的风格化结果(图1(a))。
在实验中,我们使用Microsoft COCO[17]和WikiArt[23]数据集训练解码器和域性指示符。定性地说,我们表明DSTN能够在这两个领域产生可信的风格化结果。此外,通过定量代理度量和用户研究,我们证明了我们的方法在照片真实感和艺术风格转移方面优于先前的方法。
我们的贡献有三个方面:1)我们提出了新颖的端到端统一架构,即域感知风格传输网络(DSTN),用于多域风格传输。2) 利用所提出的域性指示符和域感知跳过连接,我们捕获域特征,并在内容保存和纹理转换之间自适应地平衡。3) DSTN在照片写实和艺术领域都取得了令人钦佩的表现,在保存和风格化方面优于以往的方法。
2. Related works
自从Gatys等人的开创性工作[5]开辟了一个名为神经风格转移的新研究领域以来,许多工作已经利用神经网络的表示能力探索了风格化方法。
艺术神经风格转移。Johnson等人[11]和Ulyanov等人[26]直接训练了前馈生成网络,与图像优化方法相比,实现了更快的风格转换。尽管如此,这些模特无论何时面对新风格,都需要接受训练。为了缓解这一限制,Li等人[15]提出了用于任意风格转换的白化和着色变换(WCT)。Huang等人[10]引入了自适应实例归一化(AdaIN),通过使用样式特征的均值和标准差来简化代价高昂的ZCA变换。 **同时,Chen等人[2]和Sheng等人[24]建议分别通过反褶积方法将内容特征和归一化特征的斑块与最相关的风格特征进行交换。**然而,艺术转移模型在生成照片真实风格时往往会导致空间失真。
照片真实感神经风格转移。由于艺术神经风格转移方法难以保存内容图像的原始结构,因此已经进行了许多照片真实感风格转移的尝试。Luan等人[19]提出了基于Matting Laplacian[13]的带有光感正则化项的深度照片风格转移。Li等人[16]用非冷却层替换解码器的上采样,并传递最大池的索引密钥。此外,它们还采用了额外的后处理步骤,例如平滑和滤波。Y oo等人[31]引入了小波变换来保留结构细节。然而,这些模型很难表达艺术画的纹理,因为它们严重限制了风格化的水平。
多领域神经风格转移。之前的一些研究能够在艺术和照片现实领域进行风格转移。Li等人[14]提出了具有可学习线性变换矩阵的线性风格转移(LST),用于通用风格转移。此外,他们还采用了空间传播网络[18]来进行照片逼真的风格转换。Chiu等人[4]为具有分析梯度下降的风格化特征引入了迭代变换。然而,这两个模型在推理过程中需要额外的信息,即给定引用的域,它们应该采用辅助模块或确定迭代步骤的数量。相比之下,我们的DSTN从给定的参考输入中捕获域相关特征,并在没有任何额外指导的情况下实现多域风格转换。
3. Method
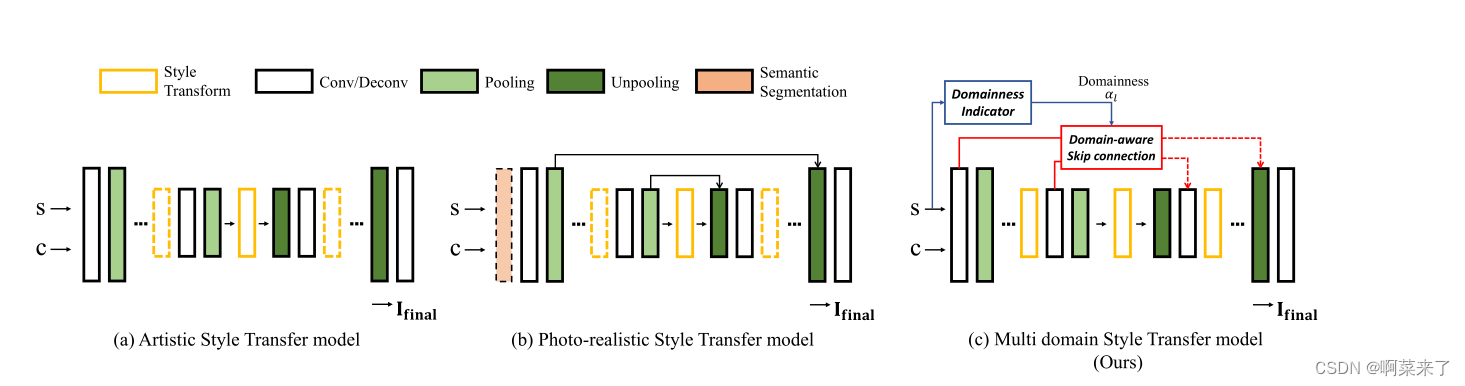
图2。以前的风格迁移模型和我们的模型(DSTN)之间的概念差异。艺术风格转移模型(a)采用编码器-解码器结构转移全局风格模式,但难以保留输入图像的原始上下文。通过跳跃式连接,逼真的风格传递模型(b)成功地保留了结构信息,但缺乏细腻风格的传递能力。与之前的方法不同,我们的网络©根据给定样式图像的域性自适应地传递内容样本的结构信息。样式转换和语义分割块的虚线表示可以省略。注意,给定内容C和样式S,每个模型输出最终的图像(如果是最终的)
在本节中,我们详细描述了所提出的领域感知风格传输网络(DSTN)。DSTN由具有域感知跳过连接的自动编码器和域指示器组成。值得注意的是,我们的目标是将任意参考图像的风格从艺术(IaS)或照片写实(IpS)领域转移到内容图像(IC)。
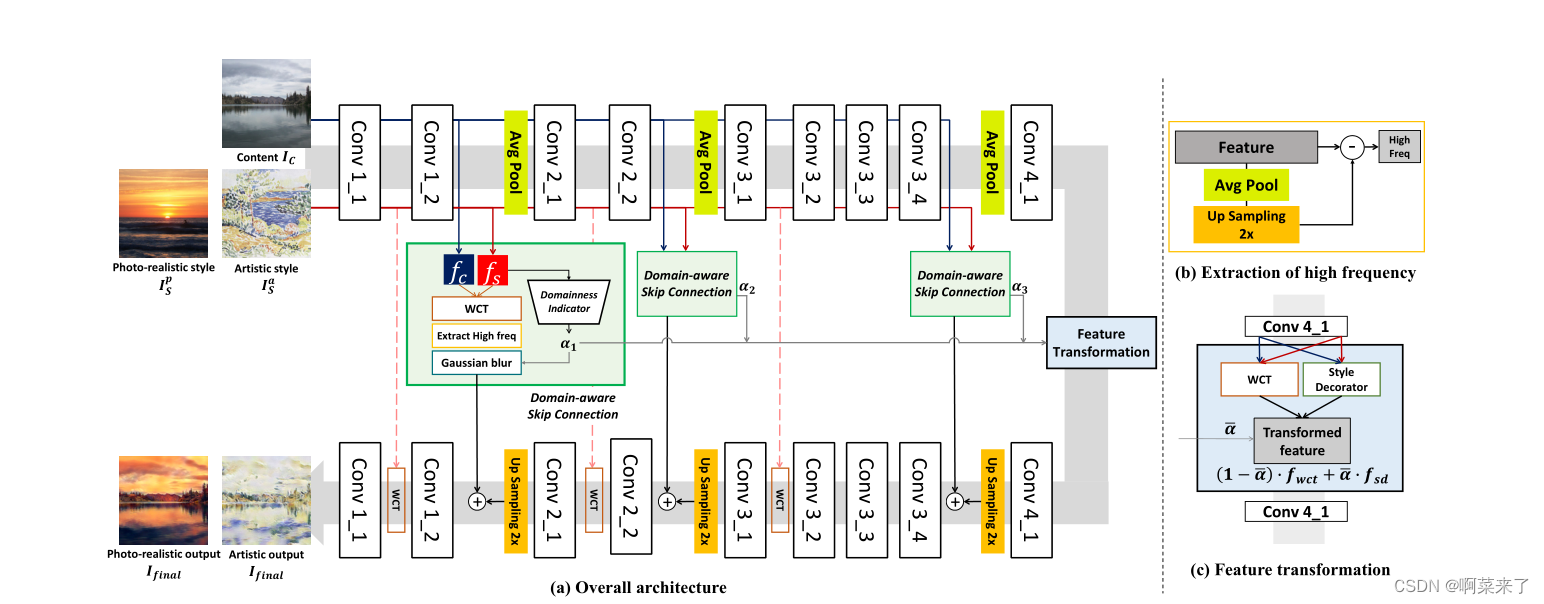
我们方法的概述如图3(a)所示。我们首先描述了所提出的用于多域风格传输的具有域感知跳过连接的自动编码器。此后,我们详细描述了所提出的域性指示符,该指示符从给定的参考图像中捕获域的属性。
图3。域感知风格传输网络(DSTN)概述。(b)为高频成分的提取过程,©为特征变换的细节。
3.1. Domain-aware Skip Connection
如前几节所述,跳跃连接是区分照片写实方法和艺术方法的根本区别。它在结构保存方面是有利的,但它限制了微妙的艺术表达。基于这一观察,我们提出了一种领域感知跳跃连接,以在照片现实和艺术领域进行领域感知通用风格转移。域感知跳过连接将内容特征fc转换为给定的参考特征fs。此后,我们提取了样式化特征的高频分量,如图3(b)所示。我们利用这个高频分量作为重建的关键,因为它包含Ic的结构信息。因此,解码器利用来自跳过连接的结构信息和来自特征变换块的纹理信息来重建图像。
通过这种架构设计,我们可以根据参考图像的域属性调整结构保存级别。对于艺术参考,我们故意模糊高频分量,以便我们的解码器根据深层纹理特征而不是结构细节重建图像。我们用σ=16的高斯核控制高频信息,核大小为⌊αl×8⌋ + 1.αl表示从提议的域性指标中获得的域属性,该指标将在下一节中详述。当模糊与内核大小成比例增加时,高αl的参考图像会导致艺术风格化。在低αl的相反情况下,解码器利用了清晰的高频分量,从而产生了逼真的结果。通过第4.3节中的消融研究,我们验证了所提出的域感知跳过连接中每个组件的有效性。
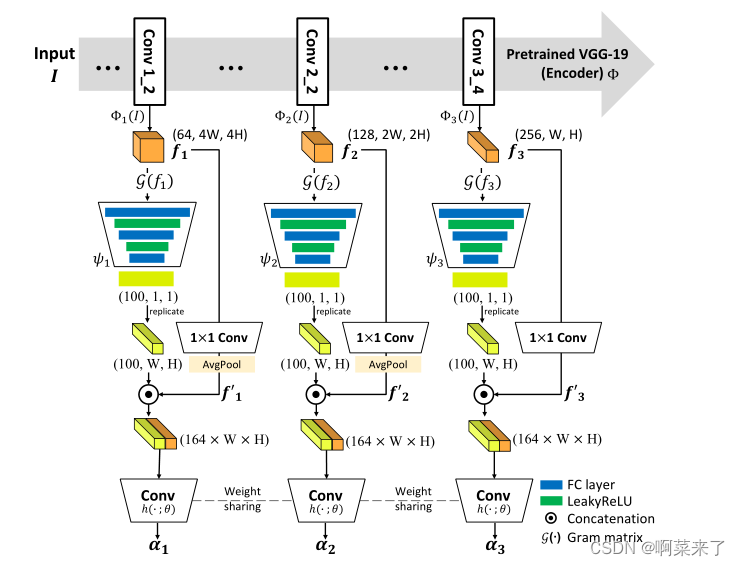
图4。所提议的领域指标概述。基于VGG层的多尺度特征表示来分析域性。对于多层次的特征,我们共享最后一个卷积层的权重。
3.2. Domainness Indicator**
为了捕获域属性(即域性),我们引入了利用结构特征和纹理特征的域性指标。如图4所示,我们的指示器从编码器的三个不同层Φl(即Conv1 2、Conv2 2和Conv3 4)获取特征图fl。然后,我们通过计算特征图fl的gram矩阵[5](G(fl))来获得纹理信息。此外,为了编码结构信息,我们通过1×1 Conv层在fl上应用信道池。最后,我们连接纹理和结构信息,这些信息通过权重共享卷积层h转发,以获得每个级别l的域性αl。这些步骤公式化为:
哪里⊙ 表示信道连接算子,ψ是全连通层,f′l是每个层的信道合并特征图,σ(·)是S形运算。我们采用f1和f2的空间平均池,以确保不同级别的特征的空间大小。
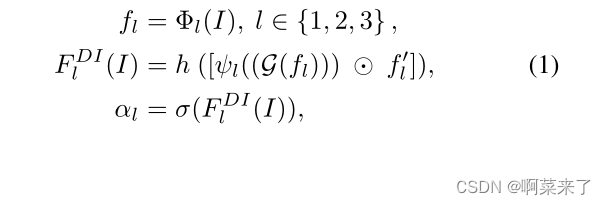
此外,我们采用了一种领域自适应方法[6]来利用照片真实性和艺术性之间的中间空间。我们对中间样本的定义如下:
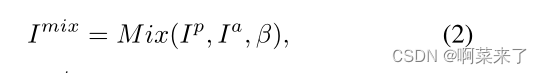
其中Ip、Ia和Imix分别表示照片写实、艺术和混合样本。M ix是混合[8]方法,β是β分布的插值强度,如[6]所示。
为了使所提出的指标学习域性,我们采用二元交叉熵,其公式如下:
其中L表示上述三层。
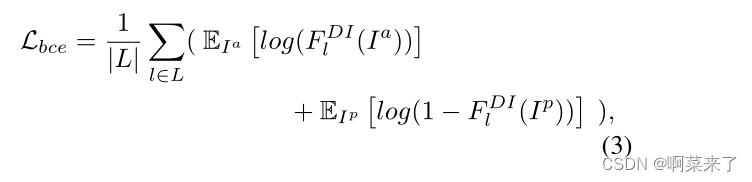
对于中间域的混合样本,我们根据β训练域性指示符以在两个域之间嵌入它们的特征
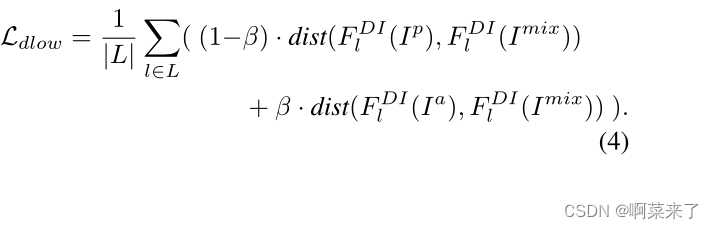
通过L1距离计算特征之间的距离(dist),如下所示:
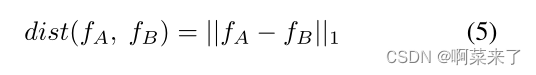
最后,我们得到域性指标的总损失函数为:
其中λbce和λdlow是损失的加权因子。
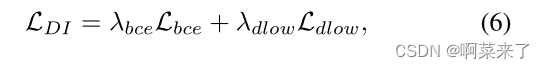
3.3. Overall Architecture and Training
我们采用预训练的VGG-19(高达conv4 1)作为编码器,并将其最大池化层替换为平均池化层。解码器镜像编码器,所有池化层被上采样层替换。然后,我们在编码器和解码器的Conv1 2、Conv2 2、Conv3 4层之间建立了域感知跳跃连接。受Avatar Net[24]的启发,我们在Conv1、Conv2和Conv3 1层添加了快捷连接链接,以实现更好的风格化。
根据先前的研究[15,10,24,30,21,27,29,32],我们使用αl(α)的平均值对编码器的最终特征进行变换,如图3(c)所示。在转换块中,我们控制了通用样式化特征[15](fwct)和样式修饰特征[24](fsd)之间的特征权重,前者擅长保持全局上下文,后者很好地代表了局部样式模式。
解码器被训练为执行重建,即,将特征映射反转为具有感知距离[11]和上下文相似性[20]的RGB图像,如下所示:
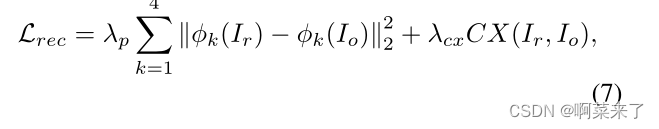
其中,k表示VGG-19的ReLU k 1层之后的激活图,CX是输入图像(Io)和重建图像(Ir)之间的上下文相似性[20]。λp和λcx分别表示用于加权感知距离和上下文相似性的超参数。
我们用上下文相似性替换传统的L2距离,以获得更好的风格化输出质量(特别是为了防止艺术风格化中出现的模糊问题)。我们在第4.3节中研究了这种修改对损失函数的影响。为了进一步提高风格化性能,我们利用了具有对抗性损失(Ladv)的多尺度鉴别器[7]。补充材料中描述了多尺度鉴别器和对抗性损失的细节。
最后,我们以端到端的方式训练网络,总体损失函数计算如下:
其中Ltv表示用于实施像素级平滑度的总变化损失。
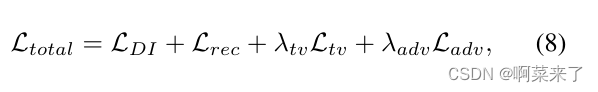
4. Experiments
实施细节。我们在MSCOCO[17]和WikiART[23]数据集上训练DSTN,每个数据集分别包含大约80000张真实照片和艺术图像。我们使用Adam[12]优化器来训练域性指示符以及批大小为6的解码器,学习率最初设置为1e-4。在整个实验中,我们将256×256设置为默认图像分辨率。损失函数的权重因子设置为:λp=0.1,λcx=1,λtv=1,λdlow=1,λadv=0.1,λbce=5。Ldlow的超参数设置为与[6]相同。我们的代码是用PyTorch[22]实现的,我们的模型是在单个GTX 2080Ti上训练的。代码和经过培训的模型将在网上公开。
4.1. Qualitative results
我们将我们的网络与几个最先进的模型在艺术和照片写实风格转移方面进行了定性比较。图5分别显示了真实感参考(第1、2行)和艺术参考(第3、4、5行)的风格化结果。AvatarNet[24]、AAMS[30]和Collaborative Distriction[27]显示出良好的艺术风格化输出,但在照片参考上显示出一些失真(例如,树叶或山脉天际线的细节)。另一方面,PhotoWCT[16]和WCT2[31]成功地生成了真实感输出,但它们无法表达艺术参考的特定绘画风格(例如,画笔图案或详细纹理)。换句话说,先前的方法根据预定义的目标域来风格化内容图像,而不考虑输入引用的域特性。
另一方面,我们的DSTN在两个领域都显示了合理的结果(图5(a))。这些样本表明,域性指示符很好地从给定的参考样本中提取域属性,并且解码器根据给定的域性自适应地将特征反转为图像。具体而言,DSTN在通过领域感知跳过连接而不是昂贵的注意力模块来保存语义信息的同时进行艺术风格转移[30,21]。此外,通过所提出的跳过连接提供的结构细节能够在照片真实风格转换中实现完整的内容表示和风格化。我们注意到,我们的网络不需要任何预处理或后处理步骤。
此外,我们将我们的方法与先前的多域神经风格转移模型[14,4]进行了比较,如图6所示.我们观察到,DSTN不仅很好地表达了参考图像的纹理,而且很好地表现了域特征。(更多定性比较包含在我们的补充材料中。)
4.2. Quantitative results
统计数字为了测量照片真实性和风格表现的程度,我们使用两个代理指标结构保存和风格化。图7显示了SSIM(X轴)与风格损失(Y轴)的定量结果图。我们在WCT2之后计算了内容图像的边缘响应和照片真实感风格化输出之间的结构相似性(SSIM)指数[31]。此外,我们计算了艺术风格化输出和参考样本之间的风格损失[5],这些样本来自五个分辨率为128×128的裁剪块。我们使用DPST[19]提供的60对内容和照片现实参考进行定量评估。此外,我们从WikiART数据集的测试分割中随机抽取了60个艺术参考。
如图7所示,艺术风格转移模型(左上角)获得了不错的风格损失分数,但它们无法保留具有los SSIM值的原始结构。另一方面,照片逼真的传递模型(右下)很好地保存了原始结构信息,但在表达参考图像的风格方面存在困难。尽管LST[14]在两方面都取得了良好的性能,但我们注意到,它们需要额外的空间传播网络(SPN)[18]以及用于传输的参考域信息。相比之下,我们的DSTN在没有任何预处理(例如,确定给定参考图像的域或语义分割)或后处理(例如平滑和滤波)的情况下进行风格转换,并且通过单个训练优于其他方法,包括多域模型[14,4]。值得注意的是,我们的DSTN在两个领域都实现了最先进的性能,甚至没有对抗性损失(Ladv)。用户研究。由于风格化是相当主观的,我们进行用户研究,以更好地评估我们的方法在照片现实主义和艺术标准方面。我们使用24对内容和参考图像,并将我们的DSTN与每个领域的代表性模型进行比较,即艺术[24,30,27]和照片写实[16,31]。此外,作为竞争对手,我们包括两个支持多域风格转换的先前模型[14,4]。风格化的结果与内容和风格图像一起以随机顺序提供给用户。在用户研究中,我们询问参与者关于内容保存、纹理表达和领域性的问题。因此,我们收集了来自65名受试者的2340份回答,结果如表1所示。总体而言,可以注意到,大多数参与者都喜欢我们的DSTN,而不是所有评估方法。
执行时间分析。表2显示了在不同分辨率下与其他方法的执行时间比较。使用单个NVIDIA RTX 2080Ti 11GB估计结果。由于DSTN可以转移照片和艺术领域的风格,我们为每个领域进行60次转移,并报告总共120次转移的平均时间。无论分辨率如何,我们的方法都能达到相当的执行时间。
4.3. Ablation studies
在本节中,我们对区域性、区域感知跳跃连接和重建损失进行了几项消融研究。
改变结构域α的影响。为了分析区域性α和风格化输出之间的关系,我们有意将每个层的αl设置为[0,1]范围内的相同值~α。如图8所示,输出在艺术风格和照片写实风格之间平滑变化。值得注意的是,DSTN控制风格化的水平,并以连续的域值处理中间域。
分析域感知跳过连接。我们的跳过连接将内容图像的高频分量从编码器传递到具有参考图像的自适应域值的解码器。在图9中,我们对域感知跳跃连接和高频组件进行了定性消融研究。如果没有域感知跳过连接,DSTN无法在照片真实风格转换时保留原始图像的结构细节,例如图9(a)中的窗口框架。尽管在整个编码特征上建立域感知跳过连接能够保持原始特征的结构,但艺术参考的转换程度是微不足道的,因为编码特征包含太多的特征,无法进行重建,如图9(b)所示。通过仅传递和转换高频分量,我们发现了内容保存和风格化之间的一个甜蜜点,如图9(c)所示。
重建损失分析。在DSTN中,来自高频分量的结构线索数量对于艺术图像来说,则更少,因此其重建结果变得模糊。因此,我们使用上下文相似性[20]代替像素级L2距离进行重建。如图10(b)所示,用L2距离训练的网络的风格化输出是模糊的,无法表达参考图像的详细纹理。相反,使用上下文相似性(CX)训练的拟议解码器有效地传递画布上油画的纹理(图10(c))。
5.结论
在这项工作中,我们提出了用于域感知通用风格转移的域感知风格转移网络(DSTN)。我们引入了一种新的域性指标,它从任意引用中捕获域特征(即域性)。此外,我们的域感知跳跃连接根据域性通过高斯模糊调整传输信息的清晰度。因此,DSTN在两个领域都产生了令人钦佩的风格化输出,而无需任何额外的用户指导。定性和定量实验证明,DSTN在照片写实和艺术领域都实现了最先进的风格化性能,而无需任何预处理或后处理。
6. Acknowledgements
该项目部分得到了韩国国家研究基金会(MSIT)资助的赠款(编号2019R1A2C2003760)和韩国政府资助的信息与通信技术规划与评估研究所(IITP)赠款(编号2020-0-01361:人工智能研究生院项目(永盛大学))的支持。我们衷心感谢所有参与者的用户研究。
References
[1] Jie An, Haoyi Xiong, Jun Huan, and Jiebo Luo. Ultrafast
photorealistic style transfer via neural architecture search.
AAAI, abs/1912.02398, 2020.
[2] Tian Qi Chen and Mark Schmidt. Fast patch-based style
transfer of arbitrary style. arXiv preprint arXiv:1612.04337,
2016.
[3] Jiaxin Cheng, Ayush Jaiswal, Y ue Wu, Pradeep Natarajan,
and Prem Natarajan. Style-aware normalized loss for im-
proving arbitrary style transfer. In CVPR, pages 134–143,
June 2021.
[4] Tai-Yin Chiu and Danna Gurari. Iterative feature transforma-
tion for fast and versatile universal style transfer. In ECCV,
pages 169–184, 2020.
[5] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Im-
age style transfer using convolutional neural networks. In
CVPR, pages 2414–2423, 2016.
[6] Rui Gong, Wen Li, Y uhua Chen, and Luc V an Gool. Dlow:
Domain flow for adaptation and generalization. In CVPR,
pages 2477–2486, 2019.
[7] Ian J. Goodfellow, Jean Pouget-Abadie, M. Mirza, Bing Xu,
David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and
Y oshua Bengio. Generative adversarial nets. In NeurIPS,
2014.
[8] Y ann N. Dauphin Hongyi Zhang, Moustapha Cisse and
David Lopez-Paz. mixup: Beyond empirical risk minimiza-
tion. ICLR, 2018.
[9] Zhiyuan Hu, Jia Jia, Bei Liu, Yaohua Bu, and Jianlong Fu.
Aesthetic-aware image style transfer. ACM MM, 2020.
[10] Xun Huang and Serge Belongie. Arbitrary style transfer in
real-time with adaptive instance normalization. In ICCV,
pages 1501–1510, 2017.
[11] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual
losses for real-time style transfer and super-resolution. In
ECCV, pages 694–711. Springer, 2016.
[12] Diederik P . Kingma and Jimmy Ba. Adam: A method for
stochastic optimization. ICLR, 2015.
[13] Anat Levin, Dani Lischinski, and Yair Weiss. A closed-form
solution to natural image matting. IEEE transactions on pat-
tern analysis and machine intelligence (PAMI), 30(2):228–
242, 2007.
[14] Xueting Li, Sifei Liu, Jan Kautz, and Ming-Hsuan Y ang.
Learning linear transformations for fast image and video
style transfer. In CVPR, pages 3809–3817, 2019.
[15] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu,
and Ming-Hsuan Y ang. Universal style transfer via feature
transforms. In NeurIPS, pages 386–396, 2017.
[16] Yijun Li, Ming-Y u Liu, Xueting Li, Ming-Hsuan Y ang, and
Jan Kautz. A closed-form solution to photorealistic image
stylization. In ECCV, pages 453–468, 2018.
[17] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,
Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence
Zitnick. Microsoft coco: Common objects in context. In
ECCV, pages 740–755. Springer, 2014.
[18] Sifei Liu, Shalini De Mello, Jinwei Gu, Guangyu Zhong,
Ming-Hsuan Y ang, and Jan Kautz. Learning affinity via spa-tial propagation networks. In NeurIPS, pages 1520–1530,
2017.
[19] Fujun Luan, Sylvain Paris, Eli Shechtman, and Kavita Bala.
Deep photo style transfer. In CVPR, pages 4990–4998,
2017.
[20] Roey Mechrez, Itamar Talmi, and Lihi Zelnik-Manor. The
contextual loss for image transformation with non-aligned
data. In ECCV, pages 768–783, 2018.
[21] Dae Y oung Park and Kwang Hee Lee. Arbitrary style trans-
fer with style-attentional networks. In CVPR, pages 5880–
5888, 2019.
[22] Adam Paszke, Sam Gross, Soumith Chintala, Gregory
Chanan, Edward Y ang, Zachary DeVito, Zeming Lin, Alban
Desmaison, Luca Antiga, and Adam Lerer. Automatic differ-
entiation in PyTorch. In NeurIPS Autodiff Workshop, 2017.
[23] Fred Phillips and Brandy Mackintosh. Wiki art gallery, inc.:
A case for critical thinking. Issues in Accounting Education,
26(3):593–608, 2011.
[24] Lu Sheng, Ziyi Lin, Jing Shao, and Xiaogang Wang. Avatar-
net: Multi-scale zero-shot style transfer by feature decora-
tion. In CVPR, pages 8242–8250, 2018.
[25] Karen Simonyan and Andrew Zisserman. V ery deep convo-
lutional networks for large-scale image recognition. arXiv
preprint arXiv:1409.1556, 2014.
[26] Dmitry Ulyanov, Andrea V edaldi, and Victor Lempitsky. Im-
proved texture networks: Maximizing quality and diversity
in feed-forward stylization and texture synthesis. In CVPR,
pages 6924–6932, 2017.
[27] Huan Wang, Yijun Li, Y uehai Wang, Haoji Hu, and Ming-
Hsuan Yang. Collaborative distillation for ultra-resolution
universal style transfer. In CVPR, pages 1860–1869, 2020.
[28] Pei Wang, Yijun Li, and Nuno V asconcelos. Rethinking and
improving the robustness of image style transfer. In CVPR,
pages 124–133, June 2021.
[29] Fuzhi Yang, Huan Y ang, Jianlong Fu, Hongtao Lu, and Bain-
ing Guo. Learning texture transformer network for image
super-resolution. In CVPR, pages 5790–5799, June 2020.
[30] Y uan Yao, Jianqiang Ren, Xuansong Xie, Weidong Liu,
Y ong-Jin Liu, and Jun Wang. Attention-aware multi-stroke
style transfer. In CVPR, pages 1467–1475, 2019.
[31] Jaejun Y oo, Y oungjung Uh, Sanghyuk Chun, Byeongkyu
Kang, and Jung-Woo Ha. Photorealistic style transfer via
wavelet transforms. In ICCV, pages 9036–9045, 2019.
[32] Y anhong Zeng, Jianlong Fu, and Hongyang Chao. Learning
joint spatial-temporal transformations for video inpainting.
In ECCV, 2020.
[33] Y ulun Zhang, Chen Fang, Y . Wang, Zhaowen Wang, Zhe Lin,
Y un Fu, and Jimei Y ang. Multimodal style transfer via graph
cuts. ICCV, pages 5942–5950, 2019.