一、研究背景
乳腺癌是全球女性中最常见的癌症之一,发病率和死亡率都处于较高水平。据世界卫生组织(WHO)统计,乳腺癌每年造成数百万女性的死亡,并且其发病率在许多国家呈上升趋势。乳腺癌的早期诊断对于提高患者的生存率至关重要,因为早期发现和治疗可以显著降低乳腺癌的死亡率。然而,乳腺癌的早期症状常常不明显,这使得及时诊断变得困难。
近年来,随着医学影像技术和生物标志物检测技术的进步,乳腺癌的诊断手段得到了极大丰富和改进。传统的诊断方法包括体检、乳房X线摄影(乳腺钼靶)、超声检查和磁共振成像(MRI)等。这些方法尽管在临床上得到了广泛应用,但仍存在一定的局限性,如假阳性和假阴性率较高、辐射风险和费用较高等。因此,寻找更加精准、无创且高效的诊断方法成为研究的热点。
人工智能(AI)和机器学习技术在医学诊断中的应用日益广泛,特别是在影像识别和病理诊断方面展现出了巨大的潜力。基于机器学习的乳腺癌诊断系统可以通过训练大量的医学影像和病理数据,自动识别和分类乳腺癌病变,辅助医生进行诊断,提高诊断的准确性和效率。
本研究旨在利用乳腺癌诊断数据集,通过机器学习技术构建高效的乳腺癌诊断模型,评估不同算法的性能,并探讨其在临床中的应用前景。希望通过本研究,为乳腺癌的早期诊断提供新的思路和方法,最终提高患者的生存率和生活质量。
二、研究意义
-
提高诊断准确性:通过构建和优化机器学习模型,可以提高乳腺癌诊断的准确性,减少误诊和漏诊,提升患者的治愈率。
-
降低诊断成本:相较于传统的诊断手段,基于人工智能的诊断方法可以在降低医疗成本的同时,提高诊断效率,使更多患者能够及时获得诊断和治疗。
-
推动医学技术进步:本研究在机器学习技术与医学诊断的结合方面进行探索,为未来智能医疗的发展提供科学依据和技术支持,推动医学技术的进步和创新。
-
提高公众健康意识:通过本研究,可以提高公众对乳腺癌早期诊断和预防的认识,促进早期筛查和定期体检,早发现早治疗,降低乳腺癌的发病率和死亡率。
三、实证分析
首先导入数据分析需要的包
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
plt.style.use('ggplot')# 读取数据
cancer_data = pd.read_csv("Breast_cancer_data.csv")
cancer_data.head()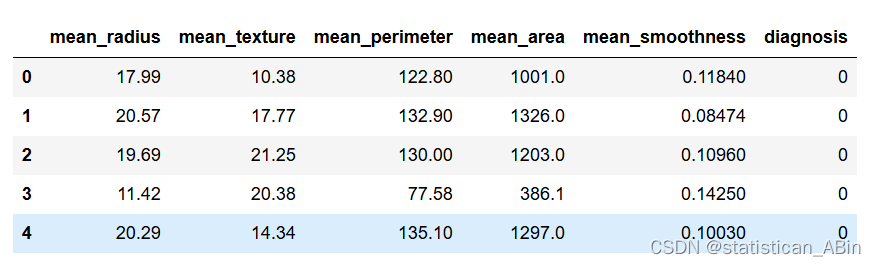
该数据集提供了从乳腺癌患者中提取的特征的全面集合,旨在促进预测建模和分析。它包括平均半径、纹理、周长、面积、平滑度和其他诊断属性等测量值。
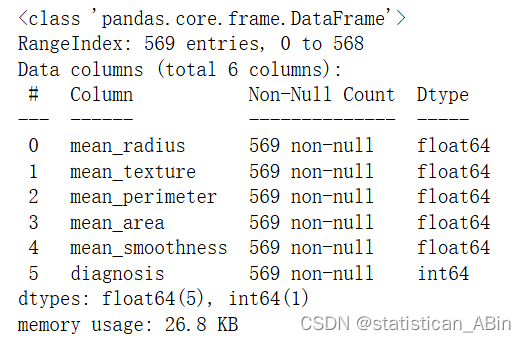
查看数据类型
cancer_data.info()
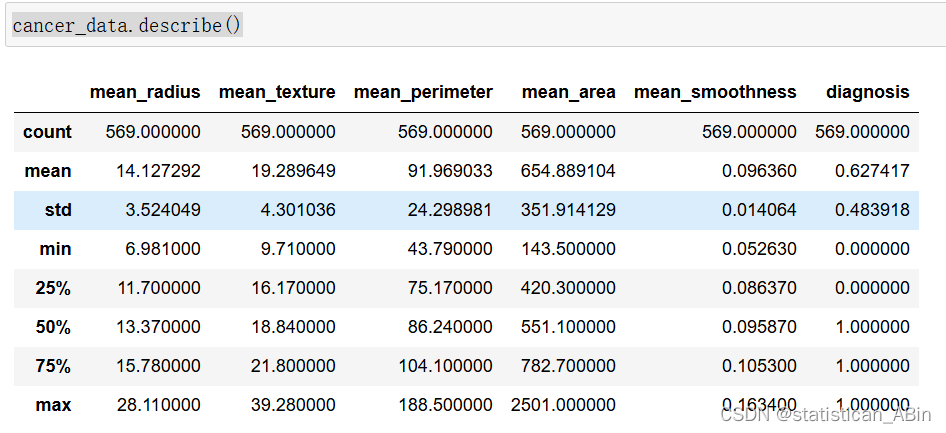
对数据集做描述性统计分析
检查样本平衡性
print(cancer_data.diagnosis.value_counts())
sns.countplot(data = cancer_data, x= cancer_data['diagnosis'])

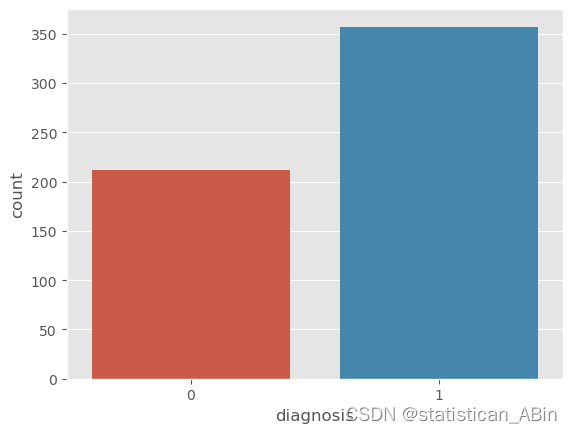
发下没有特别大的差别
接下来绘制特征相关系数热力图
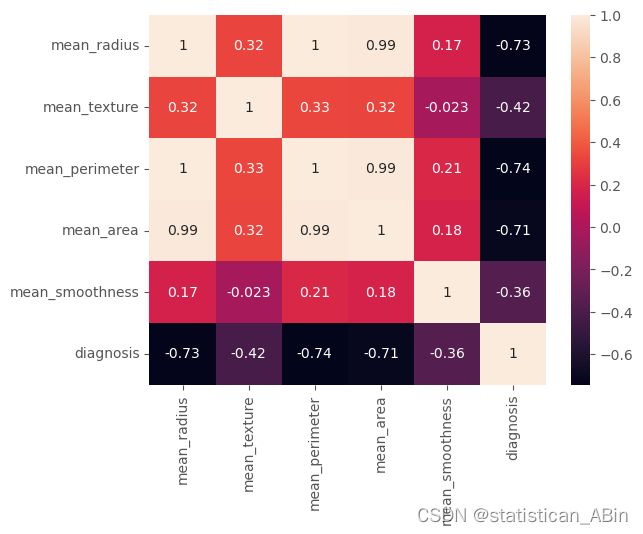
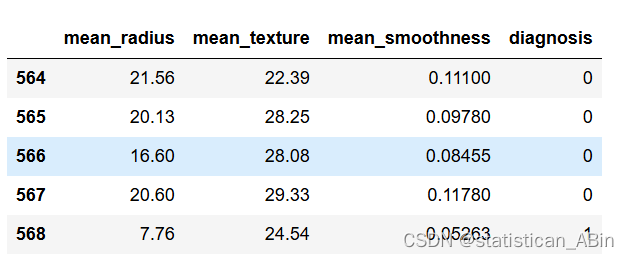
再次查看数据后五条
cancer_data.tail()
接下来可视化数据特征
fig, axes = plt.subplots(1, 3, figsize=(15, 6), sharey=True)
sns.histplot(cancer_data, ax=axes[0], x="mean_radius", kde=True, color='r')
sns.histplot(cancer_data, ax=axes[1], x="mean_smoothness", kde=True, color='b')
sns.histplot(cancer_data, ax=axes[2], x="mean_texture", kde=True, color='y')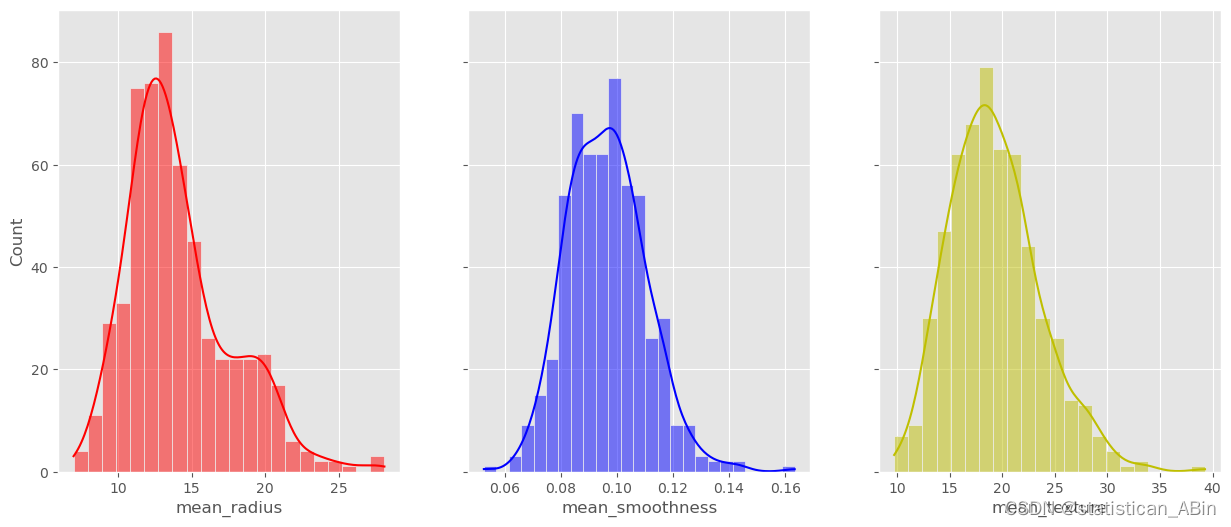
接下来画一下成对图,成对图是一种用于探索和可视化数据集中多个变量之间关系的图表。它通过展示变量两两之间的关系图,帮助分析数据的特征、相关性以及分布情况。
sns.pairplot(data = cancer_data, hue = 'diagnosis')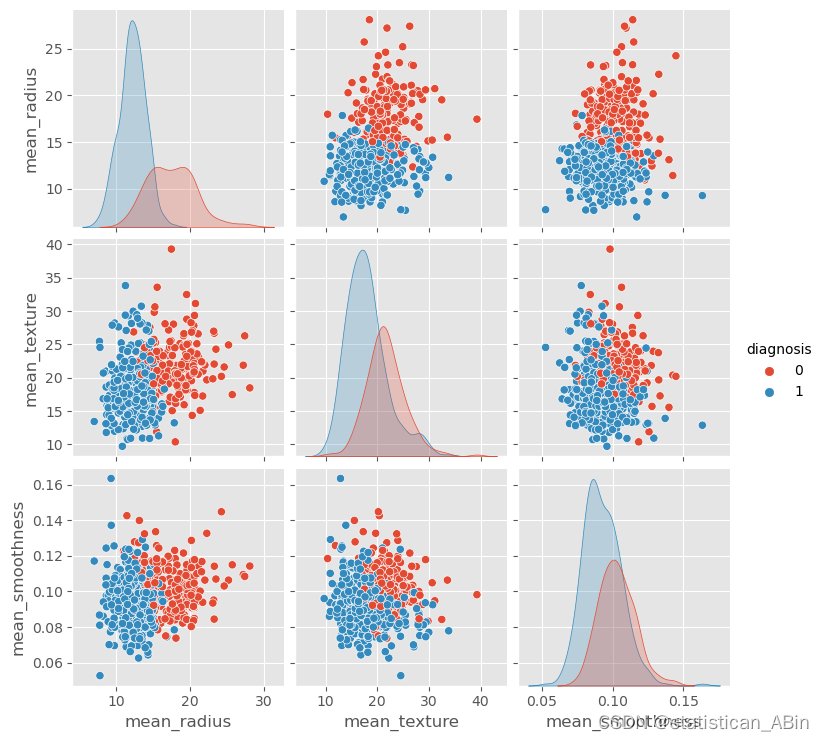

划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,train_size=.8, random_state=42) 首先是KNN模型
error_rate = []
for i in range(1,40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train,y_train)
pred_i = knn.predict(x_test)
error_rate.append(np.mean(pred_i != y_test))
plt.figure(figsize=(10,6))
plt.plot(range(1,40),error_rate,color='blue', linestyle='dashed',
marker='o',markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
print("Minimum error:-",min(error_rate),"at K =",error_rate.index(min(error_rate)))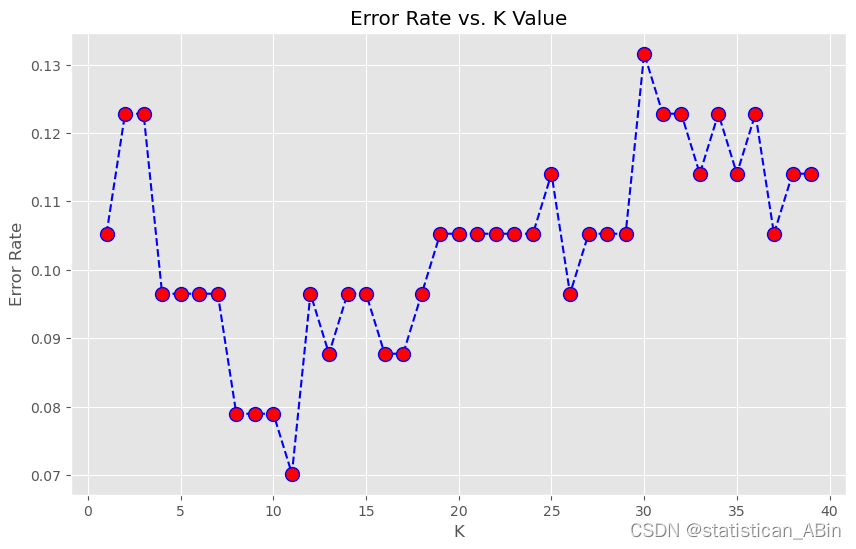
model = KNeighborsClassifier(n_neighbors=11)
model.fit(x_train, y_train)
train_pred = model.predict(x_train)
test_pred = model.predict(x_test)
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, test_pred)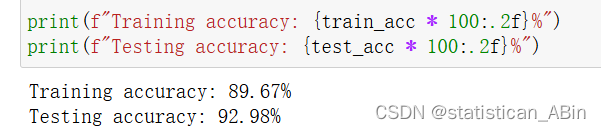
Gaussian 模型
model = GaussianNB()
model.fit(x_train, y_train)
train_pred = model.predict(x_train)
test_pred = model.predict(x_test)
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, test_pred)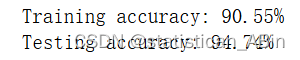
Gboost模型
model = GradientBoostingClassifier(n_estimators=40, max_leaf_nodes=8)
model.fit(x_train, y_train)
train_pred = model.predict(x_train)
test_pred = model.predict(x_test)
train_acc = accuracy_score(y_train, train_pred)
test_acc = accuracy_score(y_test, test_pred)
四、结论
本研究利用乳腺癌诊断数据集,采用多种机器学习算法(如决策树、随机森林、支持向量机、K-近邻算法等)构建了乳腺癌诊断模型。通过对模型的训练和测试,评估了各模型的性能,并对结果进行了详细分析。研究结果表明,基于机器学习的乳腺癌诊断模型在准确性、敏感性和特异性方面均表现优异,特别是在早期乳腺癌的识别上具有显著优势。随机森林和支持向量机等模型表现出较高的诊断准确性和鲁棒性,能够有效辅助临床医生进行乳腺癌的诊断。此外,本研究还探讨了数据预处理、特征选择和模型优化等关键步骤对诊断结果的影响,提出了优化方案和改进建议。研究表明,通过合理的数据处理和特征选择,可以进一步提高模型的诊断性能。
总的来说,本研究证明了机器学习技术在乳腺癌诊断中的应用潜力,为智能医疗的发展提供了新的思路和方法。未来可以结合更多的临床数据和多模态数据,进一步优化诊断模型,推动其在实际临床中的应用和推广,从而提高乳腺癌患者的生存率和生活质量。