论文标题:SWIFTSAGE: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks
作者:Bill Yuchen Lin, Yicheng Fu, Karina Yang, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Prithviraj Ammanabrolu, Yejin Choi, Xiang Ren
期刊:37th Conference on Neural Information Processing Systems (NeurIPS 2023)
DOI:10.1007/s11704-024-40231-1

email:[email protected]
创作不易,恳请大家点赞收藏支持:)
---------------------------------------------------------------------------------------------------------------------------------
在人工智能领域,如何让智能体在复杂的互动任务中具备类似人类的推理和解决问题的能力是一个重大挑战。本文介绍了一种名为 SWIFTSAGE 的新型智能体框架,它灵感来自于人类认知的双重过程理论,通过结合行为克隆和大型语言模型(LLM)来提高任务完成的效率和效果。该框架由两个主要模块组成:SWIFT 模块(代表快速和直觉的思维)和 SAGE 模块(代表深思熟虑的推理)。
SWIFTSAGE 简介
SWIFTSAGE 的目标是通过结合快思与慢思两个模块,来实现复杂交互任务的高效解决。
-
SWIFT 模块:这是一个小型的编码-解码语言模型,通过模仿学习对其进行微调,用于模拟人类的直觉思维。它能够快速解码出下一个动作,适合简单且直接的任务。
-
SAGE 模块:使用类似于 GPT-4 的大型语言模型,模拟深度分析的推理过程。SAGE 模块分为两个阶段:规划阶段和执行阶段。规划阶段负责生成高层次的任务建议,执行阶段则将这些建议转化为可执行的具体操作。
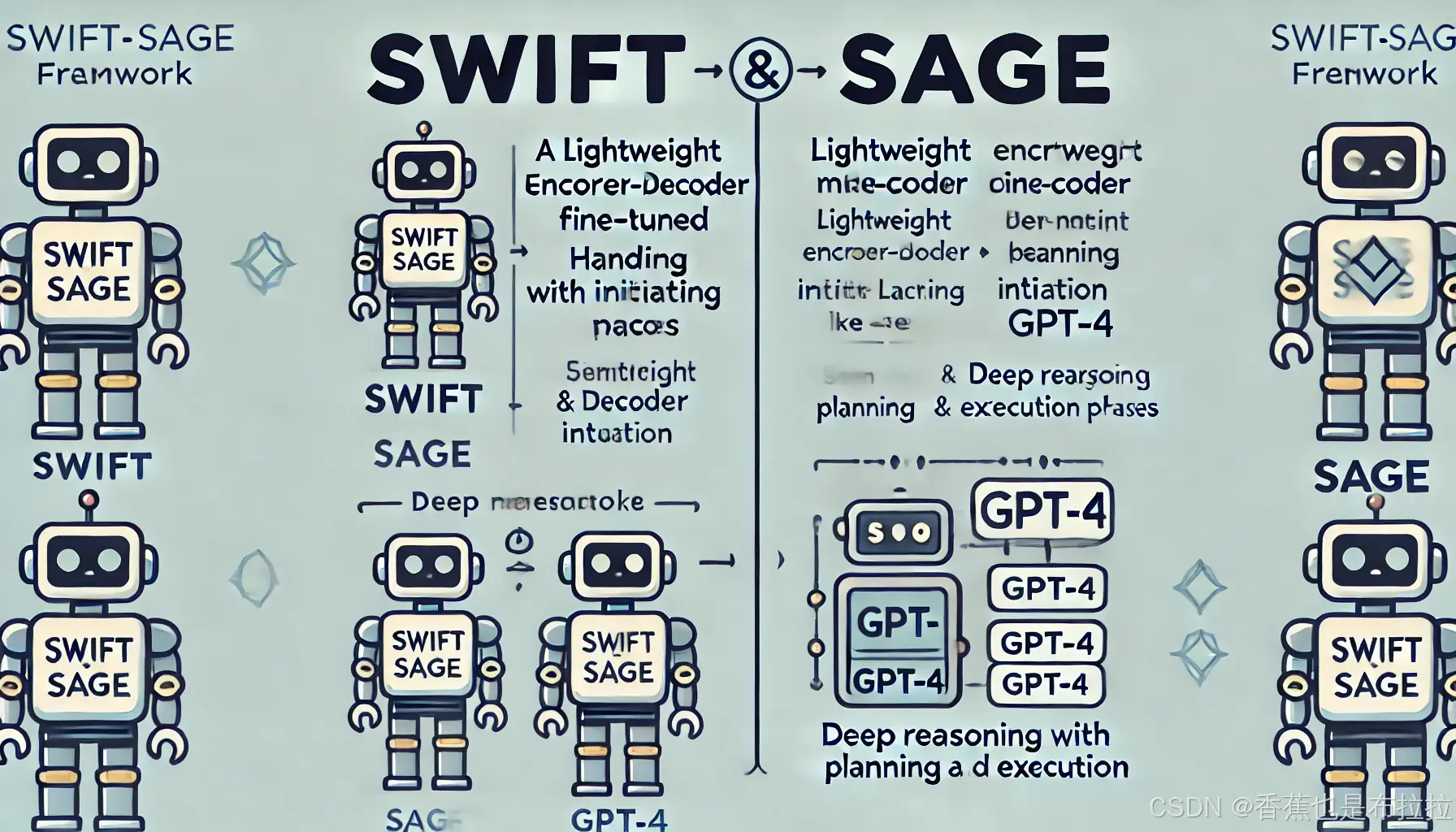
SWIFTSAGE 的创新之处在于使用启发式算法在这两个模块之间进行切换,以此来实现高效的任务执行。例如,SWIFT 模块在处理简单任务时快速出击,而当遇到复杂或意外情况时,系统会自动切换到 SAGE 模块进行深思熟虑的规划。
SWIFT 模块详细介绍
1. 模仿学习
SWIFT 模块是通过模仿学习来构建的智能体,旨在学习模仿各种训练场景中的“专家”或“神谕”智能体的行为。具体来说,模仿学习通过序列到序列(seq2seq)学习方式,让 SWIFT 模块能够在不同情境下生成相应的动作。
以往的方法,例如 TDT(Text Decision Transformer),通常只利用一跳历史(one-hop history)作为输入上下文,学习输出后续动作。虽然这种方法能够适应部分任务,但由于其动作历史上下文的限制,以及由于数据不平衡引起的有害偏差,导致表现存在一定局限性。
为了解决这些问题,SWIFT 模块采用了如下改进:
2. 扩展历史上下文及实际案例
我们将传统的一跳行为克隆(one-hop BC)扩展为多跳行为克隆(multi-hop BC),引入了一个滑动窗口机制来包含最近 K = 10 个动作的观测和奖励。除了最近的历史信息外,我们还包括了一个特殊字段,用于记录访问过的房间(且无重复)。这种方法的目标是为智能体提供更长的上下文,避免不必要的房间导航行为。
为了更好地理解 SWIFT 模块的运行机制,我们通过一个简单的案例来展示其模仿学习和多跳历史的使用。
案例描述:假设智能体的任务是“准备早餐”,其具体步骤包括从储物柜中取出盘子,从冰箱中取出鸡蛋,打开炉灶并煎鸡蛋,最后将煎好的鸡蛋装盘。
运行过程中的 Prompt:在这个任务中,SWIFT 模块需要处理多跳行为历史,以更好地理解任务的上下文和环境。以下是用于模仿学习的输入 Prompt 示例:
任务:准备早餐
时间:上一时间步
得分:上一时间步的得分
动作历史:[第 10 步动作 (+ 第 10 步奖励) -> 第 10 步观测, 第 9 步动作 (+ 第 9 步奖励) -> 第 9 步观测, ..., 第 1 步动作 (+ 第 1 步奖励) -> 第 1 步观测]
当前房间:厨房
物品库存:无
访问过的房间:{厨房, 储物柜, 冰箱}在这个 Prompt 中,模型需要根据最近 10 步的动作历史(例如从储物柜取出盘子、打开冰箱等)以及当前的环境状态来预测下一个动作。例如,模型可能会选择“从冰箱中取出鸡蛋”作为下一个动作。
通过这种多跳历史的使用,SWIFT 模块可以综合考虑多个步骤的上下文,避免重复访问已经访问过的房间,优化任务的执行路径。
3. 平衡的模仿学习
为了避免因数据不平衡导致的偏差,在 seq2seq 学习中,我们对特定类型的任务和动作进行了下采样,以实现更平衡的训练数据集。最终,使用了具有 7.7 亿参数的 T5-large 模型,该模型具有指令跟随能力,构建了一个名为 SWIFT 的高效代理。尽管 SWIFT 模块的参数量仅为 TDT 的 1/15,但其表现却明显优于 TDT(11 亿参数),表现出了强大的模仿学习能力。
SAGE 模块详细介绍
1. 规划阶段
在 规划阶段,SAGE 模块通过向 LLM 提问来制定高层次计划。这些提问的目的是帮助智能体了解当前环境、任务要求以及潜在的挑战。具体包括五个关键问题:
-
Q1: 定位物体 (Locate Objects)
-
问题:为了完成任务,我需要收集哪些物品?请逐一列出它们及其可能的位置。
-
解释:这一问题帮助模型确定任务中涉及的所有物体,以及它们在环境中的可能位置。这是任务规划的基础,因为了解需要收集的物体可以帮助模型制定更好的执行计划。
-
-
Q2: 跟踪物体 (Track Objects)
-
问题:是否有尚未收集的物体?
-
解释:通过跟踪物体,模型能够判断当前任务的进展情况,确保所有必需的物体都已准备好,从而避免遗漏重要步骤。
-
-
Q3: 规划子目标 (Plan Subgoals)
-
问题:为了最有效地完成任务,重要的子目标是什么?请逐一列出。
-
解释:将复杂任务分解为多个子目标可以提高任务的可执行性。通过逐步实现每个子目标,模型能够更好地管理任务的复杂性。
-
-
Q4: 跟踪进度 (Track Progress)
-
问题:根据这些子目标,我已经完成了哪些?我现在应该集中在哪个子目标上?
-
解释:这一问题帮助模型跟踪任务的进展,明确哪些子目标已经完成,并指导模型集中精力完成接下来的子目标。
-
-
Q5: 处理异常 (Handle Exceptions)
-
问题:我是否犯了任何错误,可能会妨碍我有效完成下一个子目标?如果有,我应该如何修复?
-
解释:这一问题用于处理任务执行过程中可能出现的错误或异常情况,确保模型能够及时修正错误,从而避免任务失败。
-
实际运行中的 Prompt 示例:
假设智能体的任务是“清理厨房”,模型需要根据环境状态回答上述五个问题。以下是一个完整的 prompt 示例:
任务:清理厨房
时间:当前时间步 t
得分:当前得分 S(t)
动作历史:[第 5 步动作 (+ 第 5 步奖励) -> 第 5 步观测, 第 4 步动作 (+ 第 4 步奖励) -> 第 4 步观测, ..., 第 1 步动作 (+ 第 1 步奖励) -> 第 1 步观测]
当前房间:厨房
物品库存:{扫帚, 垃圾袋}
访问过的房间:{厨房, 储物柜, 客厅}
问题列表:
Q1: 为了完成清理厨房的任务,我需要收集哪些物品?
Q2: 是否有尚未收集的物体?
Q3: 为了最有效地完成清理厨房的任务,重要的子目标是什么?
Q4: 根据这些子目标,我已经完成了哪些?我现在应该集中在哪个子目标上?
Q5: 我是否犯了任何错误,可能会妨碍我有效完成下一个子目标?如果有,我应该如何修复?在这个 prompt 中,SAGE 模块需要根据任务描述、当前的环境状态和动作历史,回答五个关键问题,从而制定一个高效的计划来完成清理厨房的任务。这样做有助于智能体更好地理解任务的整体情况,并进行合理的任务规划。
这些问题被设计为一个单一的 prompt,一次性提供给 LLM,确保 LLM 可以在综合考虑所有上下文信息后给出详细的高层次任务建议。这种一次性询问的方式比逐步交互更为高效。
2. 执行阶段
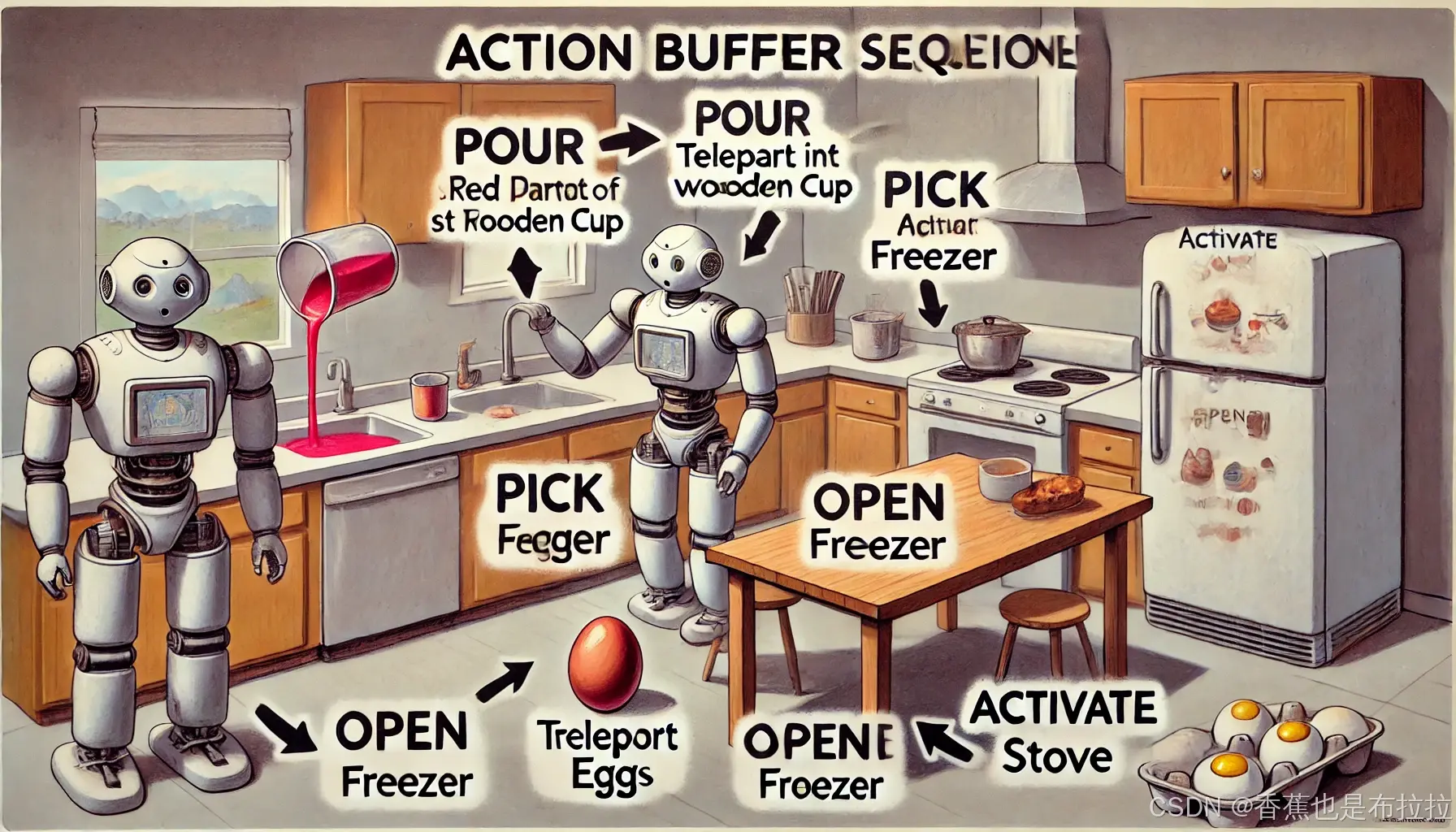
在 执行阶段,规划阶段生成的高层次目标比较抽象,需要将其转化为具体的操作。为了实现这一点,执行阶段使用了一套事先定义好的标准化动作模板,例如:
-
POUR(X, Y):将物体 X 倒入容器 Y,例如“将红色油漆倒入木杯中”。
-
TELEPORT(room):直接移动到某个房间,例如“TELEPORT(kitchen)”表示移动到厨房。
-
PICK(object):拾取某个物品并放入背包,例如“PICK(egg)”表示捡起鸡蛋。
-
OPEN(object):打开某个物体,例如“OPEN(freezer)”表示打开冰柜。
-
ACTIVATE(object):激活/打开某个物体,例如“ACTIVATE(stove)”表示打开灶台。
-
DEACTIVATE(object):关闭某个物体,例如“DEACTIVATE(light)”表示关闭灯光。
-
EXAMINE(object):仔细查看某个物体,例如“EXAMINE(light bulb)”表示检查灯泡。
-
MOVE(object, place):将某个物体移动到指定位置,例如“MOVE(pan, stove)”表示将平底锅移动到灶台上。
这些标准化动作模板使得模型能够将规划阶段的子目标转换为可直接执行的具体动作序列,并将这些动作存储在一个“动作缓冲区”中(称为 B = {Ât, Ât+1, ...}),这样模型可以一次性执行多个具体动作,减少了与 LLM 的交互频率,从而提高了执行效率。
SWIFT 与 SAGE 的集成
SWIFTSAGE 通过启发式算法有效地集成了 SWIFT 和 SAGE 两个模块。通常,SWIFT 模块因其快速的直觉推理能力,适合在任务初期进行高效探索,而当遇到以下几种情况时会切换到 SAGE 模块:
-
卡住:连续多步没有获得奖励。
-
无效:SWIFT 的预测动作在当前环境中无效。
-
关键决策:例如需要给出实验结果的最终答案。
-
意外情况:执行动作的观察结果与预期不符。
通过这种方式,SWIFTSAGE 能够在需要时无缝切换到深度规划模式,并在任务缓解后切换回快速反应模式,以实现更高效的任务解决。

评估与对比
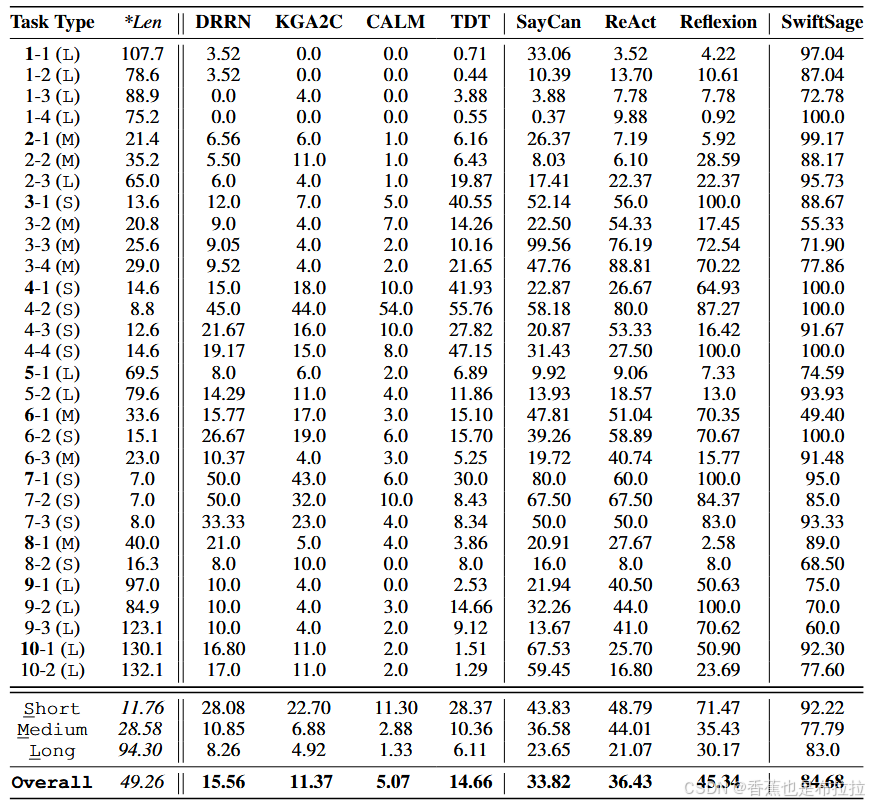
在 30 项来自 ScienceWorld 基准测试的任务中,SWIFTSAGE 的表现显著优于其他方法,平均得分达到 84.7。相比之下,其他基准方法(如 SAYCAN、REACT 和 REFLEXION)的得分分别为 33.8、36.4 和 45.3。
-
整体表现:SWIFTSAGE 在所有类型的任务(短、中、长)中表现出色,尤其是在较长和复杂任务中的表现尤为突出。
-
有效性和效率:与基于 LLM 的其他方法相比,SWIFTSAGE 在推理过程中需要更少的计算资源。SAGE 模块通过一次生成多个动作,减少了 LLM 的调用次数,使得整个过程更加经济高效。
-
异常处理:SWIFTSAGE 能够有效应对任务中的异常情况,例如在遇到故障设备时会重新规划,而不像其他方法一样陷入重复无效操作。
结论
SWIFTSAGE 通过结合 SWIFT 和 SAGE 两个模块,成功实现了复杂任务中的快速反应与深思熟虑的深度推理。这种结合了快思与慢思的框架为复杂交互任务提供了一种高效且具成本效益的解决方案,并展示了在任务解决效率和效果上的显著提升。SWIFTSAGE 的成功展示了结合小型语言模型和大型语言模型在复杂推理任务中的潜力,小型模型擅长识别特定模式,大型模型具有零样本泛化能力。然而,其评估环境仅限于模拟器,无法完全代表现实场景,且缺乏安全措施。未来需要开发更开放的环境、探索其在其他领域的泛化性,并研究更轻量的方法和智能切换机制。
未来的研究方向包括将 SWIFTSAGE 应用到更开放和复杂的环境中,并探索如何更好地在真实世界的物理环境中执行其生成的计划。结合小型语言模型的快速反应与大型语言模型的深度规划,SWIFTSAGE 为构建更通用的人工智能体提供了一个重要的方向。