今天的深度学习可谓是十分热门,好像各行各业的人都会一点。而且特别是Hinton获得诺奖后,更是给深度学习添了一把火。星主深知大家可能在平时仅仅将模型训练好后就不会去理会它了,至于模型的部署,很多人都没有相关经验。由于我最近在做一个关于模型部署的项目,面对以往缺乏这方面的经验,感到有些苦恼。因此,我决定先将学习的一部分内容记录下来,以便总结经验,帮助自己和他人更好地理解和实践模型的部署过程。希望这些记录能够为后续的项目提供指导,也能为同样面临挑战的人们带来一些帮助。
1.onnx格式和ONNX Runtime框架介绍
1.1 onnx格式介绍
ONNX (Open Neural Network Exchange) 是一个开放的深度学习模型文件格式,旨在促进不同深度学习框架之间的互操作性。它提供了一种标准的方式来表示机器学习模型,使得模型可以在多个框架之间进行共享和迁移。以下是一些关于 ONNX 格式的重要特点:
-
跨平台兼容性: ONNX 支持多种深度学习框架,如 PyTorch、TensorFlow、Keras 等,开发者可以在训练模型后将其导出为 ONNX 格式,从而在其他框架中进行推理或部署。
-
标准化: ONNX 提供了一个统一的模型描述,定义了模型的结构、参数和输入输出等信息,使得不同工具和框架能够理解模型。
-
优化支持: ONNX 模型可以通过不同的工具进行优化,以提升推理性能。这些工具包括 ONNX Runtime、TensorRT 等。
-
丰富的操作集: ONNX 包含了大量的操作(operators),支持常见的神经网络结构,允许开发者构建多样化的模型。
1.2 ONNX Runtime框架介绍
ONNX Runtime 是微软开发的一个高性能的推理引擎,用于执行 ONNX 格式的模型。它专为高效推理而设计,支持多种硬件平台,包括 CPU、GPU 和其他加速器。以下是 ONNX Runtime 的一些关键特性:
-
高性能: ONNX Runtime 提供了优化的推理引擎,能够有效利用硬件资源,支持并行计算,以提升推理速度。
-
多平台支持: ONNX Runtime 可以在多种操作系统和设备上运行,包括 Windows、Linux 和 macOS,支持各种硬件架构。
-
丰富的优化选项: 提供了图优化、量化和剪枝等多种优化手段,帮助开发者在不同设备上达到最佳的推理性能。
-
易于集成: ONNX Runtime 提供了简单易用的 API,支持 Python、C++、C# 和 Java 等多种编程语言,方便开发者将其集成到现有应用中。
至于为什么要使用 ONNX 格式的模型文件和 ONNX Runtime 框架,我认为有以下两点:
-
跨框架的兼容性: 不同深度学习框架训练出的模型文件格式一般不同,这给模型的推理和部署带来了不便。比如,你用 TensorFlow 训练一个模型,并用 TensorFlow 进行推理,而我用 PyTorch 训练的模型也要用 PyTorch 进行推理。在这样的情况下,大家的交流和协作就会变得不太方便。因此,ONNX 提供了一种统一的文件格式(.onnx),允许开发者将模型导出为 ONNX 格式,从而在不同的框架之间共享和使用模型。
-
简化依赖和环境配置: 在推理时,模型往往依赖于特定的深度学习框架。例如,如果我使用 PyTorch 训练好一个模型,之后再用 PyTorch 写一个推理脚本,而其他人想要使用这个模型进行推理,他们就必须安装 PyTorch(而且目前 PyTorch 的安装包越来越大)和其他一些相关的依赖包。这不仅增加了环境配置的复杂性,也给使用者带来了不便。通过使用 .onnx 格式文件,大家可以统一使用 ONNX Runtime 进行推理,从而简化了环境配置,让每个人都能方便地进行模型推理,无论他们最初使用的是哪个框架。这样一来,大家都能轻松实现模型的共享和使用,实现更高效的协作。这毕竟是你好,我好,他也好的好事。
2.库的安装
ONNX Runtime的Github地址:
要安装的库如下:
pip install onnx
pip install onnxruntime # 这个和下面的二选一安装即可
pip install onnxruntime-gpu安装 ONNX Runtime 时,是否需要安装 GPU 版本取决于你的具体需求。如果你希望利用 GPU 加速推理,以提高模型的执行速度,那么安装 GPU 版本是合适的选择。否则,CPU 版本已经足够满足大多数推理任务。
下面将介绍如何使用 Python 版本的 API 进行推理。同时,ONNX Runtime 也提供了 C++ 版本的 API,使用起来同样方便。对于 C++ 版本,用户不必进行复杂的安装,只需从 GitHub 下载编译好的版本,然后配置相关路径即可开始使用。这种方式不仅简化了安装过程,而且编译好的版本大小仅约 100 多 MB,相信大多数人都能接受。
注意:ONNX Runtime框架要与自己电脑中的CUDA版本相对应,否则会报错,下面是一个有些过时的参考:ONNXRuntime与CUDA版本对应_onnxruntime版本对应-CSDN博客
3.推理
使用ONNX Runtime框架进行推理的流程如下:
- 将模型导出为.onnx格式
- 检查导出的文件是否合法
- 配置一些日志、优化器、线程、运行设备等信息
- 将3中的配置应用到会话中
- 推理并对结果数据进行处理,得到自己想要的形式
3.1将.pth格式的模型导出为.onnx格式的模型
import torch
import onnx
model = AlexNet(num_classes=5)
# 加载训练好的权重
model.load_state_dict(torch.load('AlexNet.pth'))
# 模型推理模式
model.eval()
model.cpu()
# 定义一个输入
dummy_input = torch.randn(1, 3, 224, 224) # 1张3通道224x224的图片
# 将PyTorch模型转换为ONNX模型
torch.onnx.export(model,
dummy_input,
"AlexNet1.onnx", # 保存的ONNX模型路径和文件名
verbose=True,
input_names=['input'], # 输入名
output_names=['output'], # 输出名
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}, # 动态调整batch_size
opset_version=11) # 导出的onnx版本,这个要与ONNX Runtime框架兼容,否则会报错上面这段代码中的AlexNet模型可以参考这位博主:【图像分类】【深度学习】【Pytorch版本】AlexNet模型算法详解_alexnet pytorch-CSDN博客
AlexNet.pth模型文件和ONNX Runtime相关参数配置在这篇博客里:【深度学习】【OnnxRuntime】【Python】模型转化、环境搭建以及模型部署的详细教程_onnxruntime python-CSDN博客
3.2检查并可视化.onnx模型
import onnx
# 加载ONNX模型
onnx_model = onnx.load("AlexNet1.onnx")
onnx.checker.check_model(onnx_model) # 检查ONNX模型是否合法
print(onnx.helper.printable_graph(onnx_model.graph)) # 打印ONNX模型结构若导出的模型不正确,则上述代码会报错。上述代码运行结果如下:
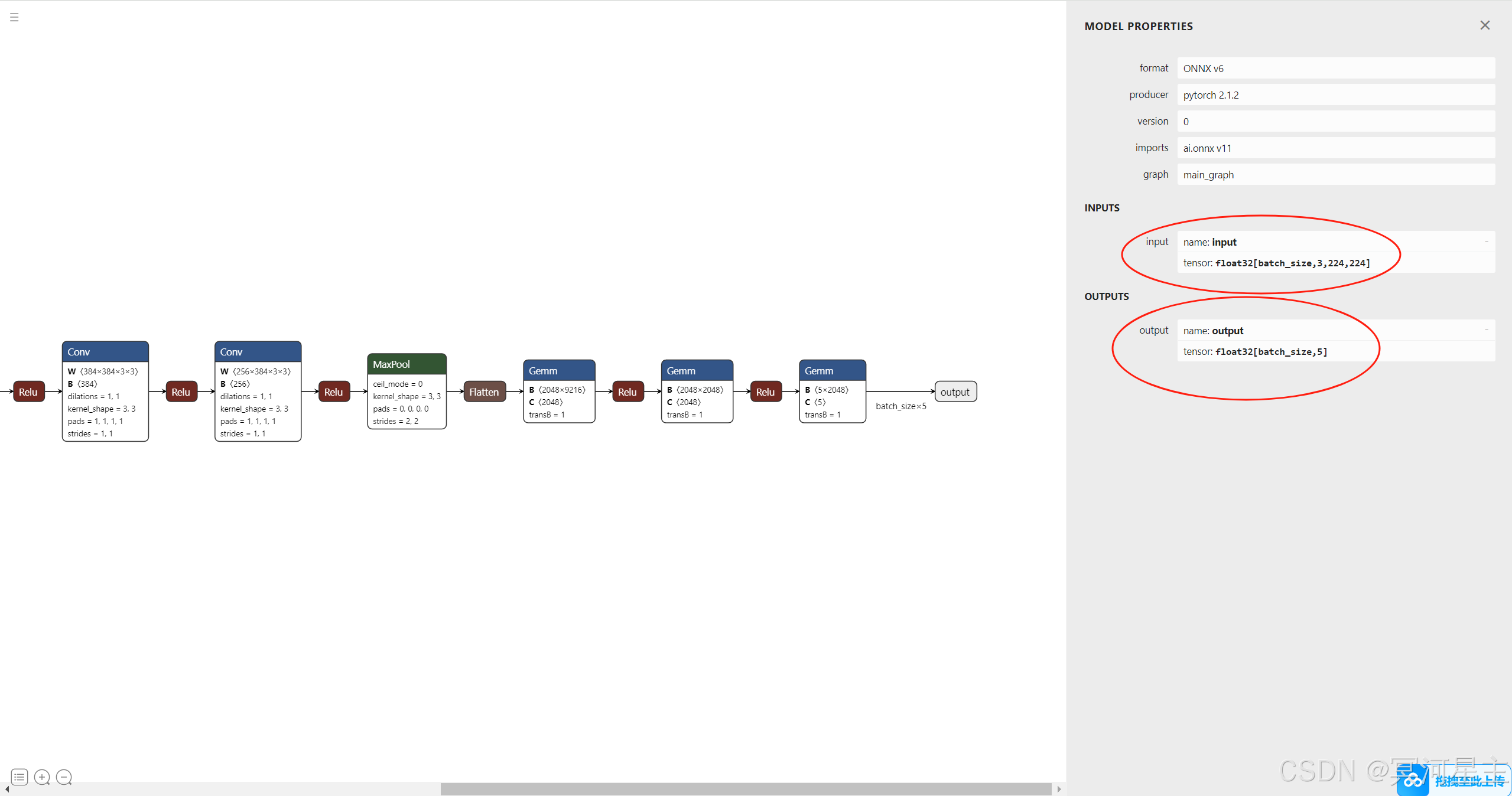
使用netron可视化我们导出的onnx格式的模型,netron网址:Netron,可视化结果如下,主要观察输入和输出的名称和形状。
3.3 推理
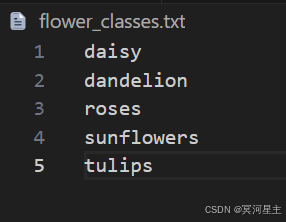
为了规范化我们写代码的习惯,我们将类别名称写入了flower_classes.txt文件中,如下:
代码如下:
import numpy as np
import cv2
import onnxruntime as ort
# 加载标签
class_names = []
with open('./flower_classes.txt', 'r') as f:
for line in f:
name = line.strip()
class_names.append(name)
print("类别名称:",class_names)
# onnx模型路径
onnx_model_path ='./AlexNet1.onnx'
# 配置一些环境,如日志,优化器,线程等等
session_options = ort.SessionOptions()
session_options.log_severity_level = 3
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_BASIC
session_options.intra_op_num_threads = 4
# 设置运行设备,列表中的顺序表示优先级
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
# 将上述配置应用到ONNX Runtime的session中
ort_session = ort.InferenceSession(onnx_model_path, sess_options=session_options, providers=providers)
# 获取输入名
input_name = ort_session.get_inputs()[0].name
print("输入名:",input_name)
print("输入形状:",ort_session.get_inputs()[0].shape)
input_h, input_w = ort_session.get_inputs()[0].shape[2:]
# 获取输出名
output_name = ort_session.get_outputs()[0].name
# 读取图片并进行预处理
image_path = './sunflower.jpg'
image = cv2.imread(image_path)
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (input_h, input_w))
img = img.astype(np.float32)
img /= 255.0
mean = np.array([0.485, 0.456, 0.406], dtype=np.float32)
std = np.array([0.229, 0.224, 0.225], dtype=np.float32)
img = (img - mean) / std
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0) # 形成一个batch
# 进行推理
result = ort_session.run(output_names=[output_name], input_feed={input_name: img})
print(result)
# 获取预测结果
probabilities = result[0][0]
print("预测概率:", probabilities)
predicted_class = np.argmax(probabilities)
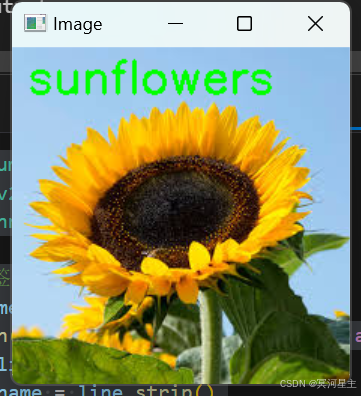
print("预测结果:", class_names[predicted_class])
# 在图片上绘制预测结果
cv2.putText(image, f'{class_names[predicted_class]}', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()运行结果如下:
目前,由于该项目星主正在努力赶工,所以这里只介绍了一些Python版本的API,C++版本等以后有机会再分享。具体一些ONNX Runtime中的参数见上面的参考链接。