若尚未部署 YOLOv8,则可参考这篇博客:
1 处理数据集
1.1 数据集格式介绍
由于不同数据集的目录结构可能不同,因此在这里对本文所使用的示例数据集进行说明。
如上图所示,示例数据集的目录结构为:

- 存放图片的目录:China_Drone/train/images
- 存放标签的目录:China_Drone/train/annotations/xmls
图片文件为 .png 文件,而标签文件为采用 pascalVOC 格式的 .xml 文件:

注意:由于在划分数据集的代码中需要填写各种路径,因此在这里了解数据集的目录结构是很有必要的。
1.2 划分数据集
在 China_Drone/train 目录中新建 split_dataset.py 文件,用于编写划分数据集的代码:
写入如下代码,用于将原始数据集划分为训练集、验证集、测试集:

import os
import random
import shutil
# 定义目录
# 采用的是相对目录
root_dir = '.' # 原始数据集目录
image_dir = 'images' # 原始数据集目录下的图片目录
label_dir = 'annotations/xmls' # 原始数据集目录下的标签目录
# 划分比例
# 训练集 : 验证集 : 测试集 = 8 : 1 : 1
train_ratio = 0.8
valid_ratio = 0.1
test_ratio = 0.1
# 设置随机种子
random.seed(42)
# 创建各种目录(用于存放拆分后的数据集)
split_dir = './road' # 拆分后数据集目录
os.makedirs(os.path.join(split_dir, 'train/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'train/labels'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'valid/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'valid/labels'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'test/images'), exist_ok=True)
os.makedirs(os.path.join(split_dir, 'test/labels'), exist_ok=True)
# 获取图片和标签列表
image_files = os.listdir(os.path.join(root_dir, image_dir))
label_files = os.listdir(os.path.join(root_dir, label_dir))
# 随机打乱图片和标签列表
combined_files = list(zip(image_files, label_files)) # 将图片和标签转化为列表
random.shuffle(combined_files) # 打乱
image_files_shuffled, label_files_shuffled = zip(*combined_files) # 重新获取
# 根据比例计算划分的边界索引
train_bound = int(train_ratio * len(image_files_shuffled)) # 图片总数 * 训练集比例
valid_bound = int((train_ratio + valid_ratio) * len(image_files_shuffled))
# 将图片和标签复制到对应的目录当中
for i, (image_file, label_file) in enumerate(zip(image_files_shuffled, label_files_shuffled)):
if i < train_bound:
shutil.copy(os.path.join(root_dir, image_dir, image_file),
os.path.join(split_dir, 'train/images', image_file))
shutil.copy(os.path.join(root_dir, label_dir, label_file),
os.path.join(split_dir, 'train/labels', label_file))
elif i < valid_bound:
shutil.copy(os.path.join(root_dir, image_dir, image_file),
os.path.join(split_dir, 'valid/images', image_file))
shutil.copy(os.path.join(root_dir, label_dir, label_file),
os.path.join(split_dir, 'valid/labels', label_file))
else:
shutil.copy(os.path.join(root_dir, image_dir, image_file),
os.path.join(split_dir, 'test/images', image_file))
shutil.copy(os.path.join(root_dir, label_dir, label_file),
os.path.join(split_dir, 'test/labels', label_file))
运行结果如下图所示:
至此,数据集划分完成。
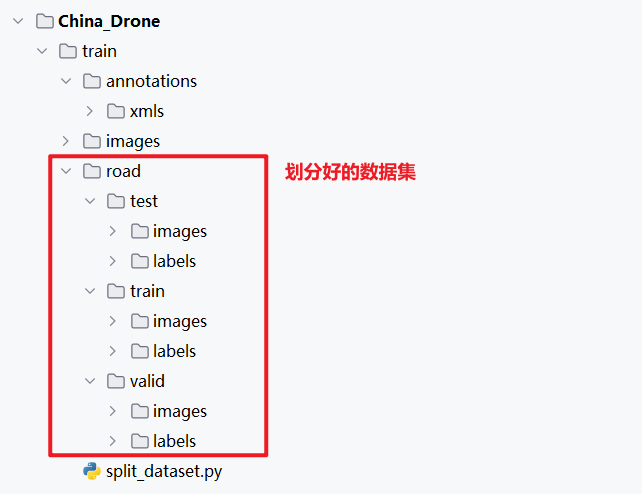
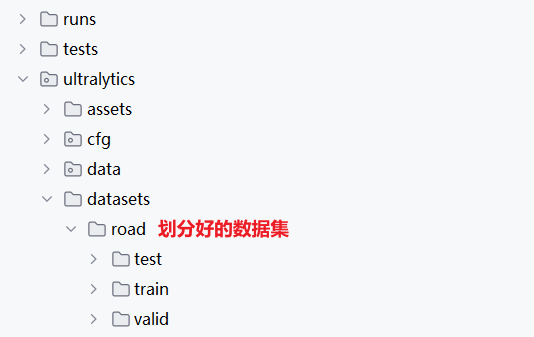
1.3 在 YOLOv8 中配置数据集
在 PyCharm 中打开 YOLOv8 项目。如果你还没有部署好,那么可以参考这篇博客:
在 /ultralytics 目录下新建 datasets 文件夹,再将划分好的数据集 road 复制粘贴过来:
除此之外,我们还需要新建一个 .yaml 文件来告诉 YOLOv8 数据集的信息:
需要在 .yaml 文件中配置如下信息,请注意:

- 将具体内容替换为自己数据集的绝对路径、类别个数、类别名称;
- 类别的编号必须从 0 开始,而不能从 1 开始,否则训练时会报错。
# road
train: D:\MyDocuments\Project\ultralytics-8.1.0\ultralytics\datasets\road\train
test: D:\MyDocuments\Project\ultralytics-8.1.0\ultralytics\datasets\road\test
val: D:\MyDocuments\Project\ultralytics-8.1.0\ultralytics\datasets\road\valid
# number of classes
nc: 8
# names of classes
names:
0: D00
1: D01
2: D10
3: D11
4: D20
5: D40
6: D43
7: D44
2 训练 YOLOv8 模型
2.1 模型训练代码
在与 /ultralytics 同级的目录中创建 train.py 用于训练模型:
from ultralytics import YOLO
if __name__ == '__main__':
# # 模型训练
# # 方法1:直接使用预训练模型创建模型
# model = YOLO('yolov8n.pt')
# model.train(**{'cfg': 'ultralytics/cfg/exp1.yaml',
# 'data': 'dataset/data.yaml'})
# 方法2:使用yaml配置文件创建模型,并导入预训练权重
model = YOLO('ultralytics/cfg/models/v8/yolov8.yaml')
model.train(cfg="ultralytics/cfg/default.yaml",
data="ultralytics/datasets/road.yaml",
epochs=200, batch=2, workers=2)
# # 模型验证
# model = YOLO('runs/detect/yolov8n_exp/weights/best.pt')
# model.val(**{'data': 'dataset/data.yaml'})
#
# # 模型推理
# model = YOLO('runs/detect/yolov8n_exp/weights/best.pt')
# model.predict(source='dataset/images/test', **{'save': True})
在需要训练模型时,直接运行上述代码即可。
2.2 开启 TensorBoard
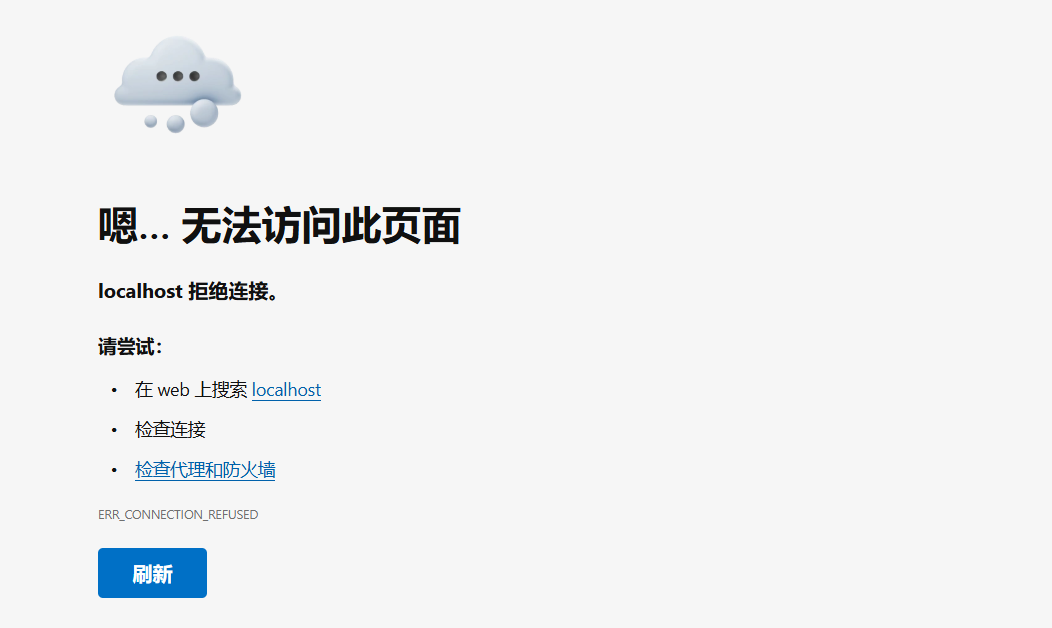
在开始模型训练时,可以看到 PyCharm 的运行中输出:
TensorBoard:
Start with 'tensorboard --logdir runs\detect\train3', view at http://localhost:6006/
但点击打开相应的网页却显示:
这是因为我们没有启动 TensorBoard!
为解决这一问题,我们需要先暂停当前的训练,接着在 PyCharm 的终端中输入:
tensorboard --logdir=D:\MyDocuments\Project\ultralytics-8.1.0\runs\detect\train3
然后重新开始训练,即可在相应的网页中查看训练过程。
注意:命令中写的是我的电脑中 runs\detect\train3 的路径,请你替换成自己的路径。