本文模均引用于y总的算法模板,网址:AcWing
(转载请注明出处,本文属于持续更新ing.......biubiubiu......)
本人码风比起y总真的差远了,所以敲一遍后,还是想把y总的搬上来,见笑了qaq...(模板更新的是我经常用到的,如有缺,留评)
目录
基础算法
C++常用便捷技巧
前言.1
基于平衡二叉树(红黑树)的存储方式,set, map, multiset, multimap 甚至vector等等容器他们都用一些共同的操作,哈希表实现的有unordered_map, unorder_set。
size()
empty()
clear()
begin()/end()
lower_bound/upper_bound
这两个二分查找操作可以在set,数组,vector,map中使用;
数组 或者 vector 中的语法:
序列是升序的(从小到大)
lower_bound(begin(),end(),x) //返回序列中第一个大于等于x的元素的地址
upper_bound(begin(),end(),x) //返回序列中第一个大于x的元素的地址
序列是降序的(从大到小)
lower_bound(begin(),end(),x,greater<tpye>()) //返回序列中第一个小于等于x的元素的地址
upper_bound(begin(),end(),x,greater<type>()) //返回序列中第一个小于x的元素的地址
set 或者 map 中的语法:
和数组差不多,只不过返回的是迭代器:
s.lower_bound(x) //返回序列中第一个大于等于x的元素的地址
s.upper_bound(x) //返回序列中第一个大于x的元素的地址
重点注意:如果当前序列中找不到符合条件的元素,那么返回end(),对于数组来说,返回查询区间的尾地址位置,对于set来讲,返回end()-1后面元素的迭代器,也就是end();set
set/multiset
前者去重后者不去重
intsert() 插入一个数
find() 查找一个数
count() 返回一个数的个数
erase()
(1) 输入是一个数x,删除所有x O(k + logn)
(2) 输入一个迭代器,删除这个迭代器map
map/multimap
(它们都是关联容器,增删效率为log级别,并且依据key能自动排序,默认小于,前者key不允许重复,后者允许)
insert() 插入的数是一个pair
erase() 输入的参数是pair或者迭代器
find()
[] 注意multimap不支持此操作。 时间复杂度是 O(logn)
lower_bound()/upper_bound()迭代器的使用
vector<type>::iterator iter;
map<type,type>::iterator iter;
set<type>::iterator iter;
等等.....
迭代器可以像指针一样,遍历STL时可以直接对迭代器 ++ -- ;
访问迭代器的值的形式:
*iter
iter->first iter->second
auto 访问map:
for(auto &iter:mp){
int x=iter->first,y=iter->second;
}
auto 访问set:
for(auto &iter:mp){
int x=iter;
}
map和set都是根据key值从小到大排好序的,带ordered的都不会排序,因为是基于哈希表实现的,但是查找效率非常高是O(1)unordered....
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
和上面类似,增删改查的时间复杂度是 O(1)
不支持 lower_bound()/upper_bound(), 迭代器的++,--
bitset
之前写过一篇博客介绍bitset:c++中Bitset用法
bitset, 圧位(存放一个十进制数的二进制,可以像数组一样来使用)
bitset<10000> s;
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0
set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反String
函数太多,详细版见:C++ string的常用函数用法总结
string 是一个很强大的字符串类
size()/length() 返回字符串的长度
reverse(s.begin(),s.end()); 将字符串的反转
s.append(str) 在字符串后面加上字符串str
支持对两个字符串的 ’ + ‘ 操作,实现字符串的拼接(s.append(str)比 + 要慢)
s.erase(0,s.find_first_not_of('0')); //利用string函数去除前导0
s1=s2.substr(起始下标,拷贝长度) //string的截取
pos = s.find('x') //返回string里面字符x的下标;
字符串转化为数字的库函数:
string str = "16";
int a = atoi(str.c_str());//能转换整数和小数,能报异常
int b = strtol(str.c_str(), nullptr, 10);//能指定进制
数字转化为字符串的函数:
int val=123456;
string s=to_string(val);
iterator erase(iterator p):删除字符串中p所指的字符
iterator erase(iterator first, iterator last):删除字符串中迭代器区间 [first, last) 上所有字符
string& erase(size_t pos, size_t len):删除字符串中从索引位置 pos 开始的 len 个字符__int128读写模板子
inline __int128 read(){
__int128 x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=x*10+ch-'0';
ch=getchar();
}
return x*f;
}
inline void print(__int128 x){
if(x<0){
putchar('-');
x=-x;
}
if(x>9)
print(x/10);
putchar(x%10+'0');
}快速排序
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
#万能模板
class Solution {
public:
int get_idx(int l,int r){
return l+rand()%(r-l+1); //采用随机中轴
// return (l+r)/2; //采用中间值作为中轴
// return l; //采用左端点作为中轴
// return r; //采用右端点作为中轴
}
void kuaipai(int l,int r,vector<int>& nums){
if(l>=r) return ;
int idx=get_idx(l,r);
int p=nums[idx];
int i=l,j=r;
while(i<=j){
while(i<=j&&nums[i]<p) i++;
while(i<=j&&nums[j]>p) j--;
if(i>j) break;
swap(nums[i++],nums[j--]);
}
kuaipai(l,j,nums);
kuaipai(i,r,nums);
}
vector<int> sortArray(vector<int>& nums) {
int n=nums.size();
kuaipai(0,n-1,nums);
return nums;
}
};归并排序
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] < q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
二分/三分模板
整数二分模板
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}浮点数二分模板
const double eps=1e-6; // eps 表示精度,取决于题目对精度的要求
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l,double r)
{
while (r-l>eps)
{
double mid = (l + r) / 2;//注意double类型不能用右移运算
if (check(mid)) r = mid;
else l = mid;
}
return l;
}整数三分模板
三分整数求极值的时候,往往不在 最后l 或者 r的地方取,而是遍历l~r之后取极值
//以凸函数位例子
int check(x){.....} //返回判断当前点对应的函数值
int bsearch_1(int l, int r)
{
while (l < r-1)
{
//三分的两个中点有两种写法
// m1 = l+(r-l)/3;
// m2 = r-(r-l)/3;
m1 = l+r>>1;
m2 = m1+r>>1;
if(check(m1) > check(m2)) r=m2;
else l=m1;
}
return l;
}
//对于极大值的求法我觉得有个技巧吧,就是while里面的范围,l和 r 差的 范围可以扩大一点点
//这样最后求极大值时可以遍历l到r,避免的精度不到位出现问题; 浮点数三分模板
//以凸函数位例子
double check(x){.....} //返回判断当前点对应的函数值
double bsearch_1(double l, double r)
{
while (r-l>eps)
{
//三分的两个中点有两种写法
// m1 = l+(r-l)/3;
// m2 = r-(r-l)/3;
m1 = (l+r)/2;
m2 = (m1+r)/2;
if(check(m1) > check(m2)) r=m2;
else l=m1;
}
return l;
}高精度加法
// 注意 A 和 B 是将两个数的每一位倒着放进了vector里面;
// C = A + B, A >= 0, B >= 0,也就是说A的长度要大于B;
vector<int> add(vector<int> &A, vector<int> &B)
{
if (A.size() < B.size()) return add(B, A);
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); i ++ )
{
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(t);
return C;
}高精度减法
// 注意 A 和 B 是将两个数的每一位倒着放进了vector里面;
// C = A - B, 满足A >= B, A >= 0, B >= 0
vector<int> sub(vector<int> &A, vector<int> &B)
{
vector<int> C;
for (int i = 0, t = 0; i < A.size(); i ++ )
{
t = A[i] - t;
if (i < B.size()) t -= B[i];
C.push_back((t + 10) % 10);
if (t < 0) t = 1;
else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();//消除前导零
return C;
}高精度乘低精度
// 注意 A 和 B 是将两个数的每一位倒着放进了vector里面;
// C = A * b, A >= 0, b > 0
vector<int> mul(vector<int> &A, int b)
{
vector<int> C;
int t = 0;
for (int i = 0; i < A.size() || t; i ++ )
{
if (i < A.size()) t += A[i] * b;
C.push_back(t % 10);
t /= 10;
}
return C;
}高精度除以低精度
//注意vector A,B是将每个数的每一位倒着存储在A,B里面了
// A / b = C ... r, A >= 0, b > 0
vector<int> div(vector<int> &A, int b, int &r)
{
vector<int> C;
r = 0;
for (int i = A.size() - 1; i >= 0; i -- )
{
r = r * 10 + A[i];
C.push_back(r / b);
r %= b;
}
reverse(C.begin(), C.end());
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}位运算模板
求n的二进制的第k位数字: n >> k & 1
返回n的二进制最后一位1所代表的十进制数:lowbit(n) = n & -n
###
当枚举状态时假设有n个点,每个点有两种状态,那么一共就有2^n个状态,所以可以用位运算来枚举每种方案里面的状态;1~2^n-1里面的所有的数都可以作为一种方案,比如n=5,那么枚举1~31,假设枚举到12,它的二进制为
01100 ,利用位运算判断12的哪一位是1,就证明对第几个点进行了相应的操作;子矩阵的和
S[i, j] = 第i行j列格子左上部分所有元素的和(也就是矩阵前缀和)
矩阵前缀和的求法:S[i, j] = S[i-1, j] + s[i, j-1] -s[i-1, j-1]
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
S[x2, y2] - S[x1 - 1, y2] - S[x2, y1 - 1] + S[x1 - 1, y1 - 1]差分矩阵
简单的区间差分插入操作:
void insert(int l,int r,int x)
{
b[l]+=x,b[r+1]-=x;
}给以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵中的所有元素加上c:
S[x1, y1] += c, S[x2 + 1, y1] -= c, S[x1, y2 + 1] -= c, S[x2 + 1, y2 + 1] += c双指针算法
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ;
// 具体问题的逻辑
}
常见问题分类:
(1) 对于一个序列,用两个指针维护一段区间
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作数据离散化
保序离散化
vector<int> alls; // 存储所有待离散化的值
sort(alls.begin(), alls.end()); // 将所有值排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重复元素
// 二分求出x对应的离散化的值
int find(int x) // 找到第一个大于等于x的位置
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; // 映射到1, 2, ...n
}非保序离散化
unordered_map<int,int> mp;//增删改查的时间复杂度是 O(1)
int res;
int find(int x)
{
if(mp.count(x)==0) return mp[x]=++res;
return mp[x];
}RMQ(ST表查询区间最值)
//以查询最大值为例
状态表示: 集合:f(i,j)表示从位置i开始长度为2^j的区间的最大值;
属性:MAX
状态转移: f(i,j)=max(f(i,j-1),f(i+(1<<(j-1)),j-1));
含义:把区间[i,i+2^j],分成两半,[i,i+2^(j-1)]和[i+(1<<(j-1)),2^j],整个区间最大值就是这两段区间最大值的最大值
const int N=2e5+7,M=20;
int dp[N][M]; //存储区间最大值
int a[N];//存放每个点的值
//dp求从位置i开始长度为2^j的区间的最大值
for(int j=0;j<M;j++)
{
for(int i=1;i+(1<<j)-1<=n;i++)
{
if(!j) dp[i][j]=a[i];
else dp[i][j]=max(dp[i][j-1],dp[i+(1<<(j-1))][j-1]);
}
}
//求任意区间的最大值;(可以预处理log)
int res=log(b-a+1)/log(2);
cout <<max(dp[a][res],dp[b-(1<<res)+1][res])<<endl;
}数学知识
试除法判定质数
bool is_prime(int x)
{
if (x < 2) return false;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
return false;
return true;
}试除法分解质因数
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
//当然求出来每个质因子的个数之后就可以求出来所以因子的个数以及因数之和了 朴素筛法求素数(质数)
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i + i; j <= n; j += i)
st[j] = true;
}
}线性筛法求素数
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}区间素数筛
做题的时候如果是多组查询,那么可以先把1~1e6的素数打表筛出来;
同时这个筛法不仅可以把素数的个数筛出来,也可以把区间素数和给求出来,以及每个素数是多少求出来
#define MAX_L 1000007
#define MAX_SORT_B 1000007
bool is_prime[MAX_L];
bool is_prime_small[MAX_SORT_B];
//对区间[a,b)内的整数执行筛法。isprime[i - a]=true <=> i是素数
void segment_sieve(LL a,LL b)
{
for(int i=0; (LL)i*i < b; i++)is_prime_small[i]=true;
for(int i=0; i<b-a; i++)is_prime[i]=true;
for(int i=2; (LL)i * i<b; i++)
{
if(is_prime_small[i])
{
for(int j=2*i; (LL)j * j < b; j += i)
{
is_prime_small[j]=false;//筛[2,sqrt(b))
}
for(LL j=max(2LL, (a+i-1)/i)*i ; j<b; j+=i) //(a+i-1)/i为[a,b)区间内的第一个数至少为i的多少倍.
{
is_prime[j - a] =false;//筛[a,b)
}
}
}
}
int main()
{
long long a,b;
while(~scanf("%lld %lld",&a,&b))
{
segment_sieve(a,b);
int cnt=0;
for(int j=0; j<b-a; j++)
{
if(is_prime[j])cnt++;
}
if(a==1)cnt--;
printf("%d\n",cnt);
}
return 0;
}
Min_25求1~n质数和
时间复杂度:
![[公式]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuL2ltZ19jb252ZXJ0L2FhYTBmMTYyYjU4MDU4Y2VjMmE4YzUxZmY4MTY0MGQ4LnBuZw%3D%3D)
const int N=1000010;
namespace Min25 {
int prime[N], id1[N], id2[N], flag[N], ncnt, m;
ll g[N], sum[N], a[N], T, n;
inline int ID(ll x) {
return x <= T ? id1[x] : id2[n / x];
}
inline ll calc(ll x) {
return x * (x + 1) / 2 - 1;
}
inline ll f(ll x) {
return x;
}
inline void init() {
//for(int i=0;i<=N;i++) prime[i]=id1[i]=id2[i]=flag[i]=g[i]=sum[i]=a[i]=0,ncnt=0,m=0;
ncnt=m=0;
T = sqrt(n + 0.5);
for (int i = 2; i <= T; i++) {
if (!flag[i]) prime[++ncnt] = i, sum[ncnt] = sum[ncnt - 1] + i;
for (int j = 1; j <= ncnt && i * prime[j] <= T; j++) {
flag[i * prime[j]] = 1;
if (i % prime[j] == 0) break;
}
}
for (ll l = 1; l <= n; l = n / (n / l) + 1) {
a[++m] = n / l;
if (a[m] <= T) id1[a[m]] = m; else id2[n / a[m]] = m;
g[m] = calc(a[m]);
}
for (int i = 1; i <= ncnt; i++)
for (int j = 1; j <= m && (ll)prime[i] * prime[i] <= a[j]; j++)
g[j] = g[j] - (ll)prime[i] * (g[ID(a[j] / prime[i])] - sum[i - 1]);
}
inline ll solve(ll x) {
if (x <= 1) return x;
return n = x, init(), g[ID(n)];
}
}
int main()
{
ll n;
cin >>n;
cout <<Min25::solve(n)<<endl;
}试除法求约数(求一个数的所有因子)
vector<int> get_divisors(int x)
{
vector<int> res;//存放所有因子
for (int i = 1; i <= x / i; i ++ )
if (x % i == 0)
{
res.push_back(i);
if (i != x / i) res.push_back(x / i);
}
sort(res.begin(), res.end());//将所有因子从小到大进行排序
return res;
}约数个数与约数之和
- 如果 N = p1^c1 * p2^c2 * ... *pk^ck
- 约数个数: (c1 + 1) * (c2 + 1) * ... * (ck + 1)
- 约数之和: (p1^0 + p1^1 + ... + p1^c1) * ... * (pk^0 + pk^1 + ... + pk^ck)
欧几里得算法
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
或者使用c++函数 __gcd();求欧拉函数
1 ~ N 中与 N 互质的数的个数被称为欧拉函数,记为ϕ(N);
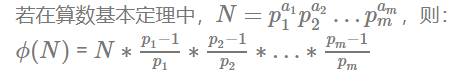
int phi(int x)
{
int res = x;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
res = res / i * (i - 1);
while (x % i == 0) x /= i;
}
if (x > 1) res = res / x * (x - 1);
return res;
}筛法求欧拉函数
int primes[N], cnt; // primes[]存储所有素数
int euler[N]; // 存储每个数的欧拉函数
bool st[N]; // st[x]存储x是否被筛掉
void get_eulers(int n)
{
euler[1] = 1;
for (int i = 2; i <= n; i ++ )
{
if (!st[i])
{
primes[cnt ++ ] = i;
euler[i] = i - 1;
}
for (int j = 0; primes[j] <= n / i; j ++ )
{
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0)
{
euler[t] = euler[i] * primes[j];
break;
}
euler[t] = euler[i] * (primes[j] - 1);
}
}
}卡特兰数
卡特兰数的应用都可以归结到一种情况:有两种操作,分别为操作一和操作二,它们的操作次数相同,都为 N,且在进行第 K 次操作二前必须先进行至少 K 次操作一,问有多少中情况?结果就Catalan(N)。
通项公式:




Catalan数的典型应用:
1.由n个+1和n个-1组成的排列中,满足前缀和>=0的排列有Catalan(N)种。
2.括号化问题。左括号和右括号各有n个时,合法的括号表达式的个数有Catalan(N)种。
3.有n+1个数连乘,乘法顺序有Catalan(N)种,相当于在式子上加括号。
4.n个数按照特定顺序入栈,出栈顺序随意,可以形成的排列的种类有Catalan(N)种。
5.给定N个节点,能构成Catalan(N)种种形状不同的二叉树。
6.n个非叶节点的满二叉树的形态数为Catalan(N)。
7.对于一个n*n的正方形网格,每次只能向右或者向上移动一格,不能穿越对角线,那么从左下角到右上角的不同种类有Catalan(N)种。
8.对于在n位的2进制中,有m个0,其余为1的catalan数为:C(n,m)-C(n,m-1)。
9.对凸n+2边形进行不同的三角形分割(只连接顶点对形成n个三角形)数为Catalan(N)。
10.将有2n个元素的集合中的元素两两分为n个子集,若任意两个子集都不交叉,那么我们称此划分为一个不交叉划分。此时不交叉的划分数是Catalan(N)。
11.n层的阶梯切割为n个矩形的切法数也是Catalan(N)。
12.在一个2*n的格子中填入1到2n这些数值使得每个格子内的数值都比其右边和上边的所有数值都小的情况数也是Catalan(N)。
模板
1、前三十项卡特兰数表
[1,1,2,5,14,42,132,429,1430,4862,16796,58786,
208012,742900,2674440,9694845,35357670,129644790,
477638700,1767263190,6564120420,24466267020,
91482563640,343059613650,1289904147324,
4861946401452,18367353072152,69533550916004,
263747951750360,1002242216651368,3814986502092304]
2、卡特兰数求模模板
const int C_maxn = 1e4 + 10;
LL CatalanNum[C_maxn];
LL inv[C_maxn];
inline void Catalan_Mod(int N, LL mod)
{
inv[1] = 1;
for(int i=2; i<=N+1; i++)///线性预处理 1 ~ N 关于 mod 的逆元
inv[i] = (mod - mod / i) * inv[mod % i] % mod;
CatalanNum[0] = CatalanNum[1] = 1;
for(int i=2; i<=N; i++)
CatalanNum[i] = CatalanNum[i-1] * (4 * i - 2) %mod * inv[i+1] %mod;
}
3.求n<=35以内的卡特兰数
ll h[36];
void init()
{
int i,j;
h[0]=h[1]=1;
for(i=2;i<36;i++)
{
h[i]=0;
for(j=0;j<i;j++)
h[i]=h[i]+h[j]*h[i-j-1];
}
}
printf("%lld\n",h[n]);
5.快速求第n位卡特兰数模板(mod1e9+7版)
const long long M=1000000007;
long long inv[1000010];
long long last,now=1;
void init()
{
inv[1]=1;
for(int i=2;i<=n+1;i++)inv[i]=(M-M/i)*inv[M%i]%M;
}
int main()
{
scanf("%lld",&n);
init();
for(int i=2;i<=n;i++)
{
last=now;
now=last*(4*i-2)%M*inv[i+1]%M;
}
printf("%lld\n",last);
return 0;
}6.Java大数打表卡特兰数模板
import java.io.*;
import java.math.BigInteger;
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner cin=new Scanner(System.in);
BigInteger s[]=new BigInteger[105];
s[1]=BigInteger.ONE;
for(int i=2;i<105;i++){
s[i]=s[i-1].multiply(BigInteger.valueOf((4*i-2))).divide(BigInteger.valueOf(i+1));
}
while(cin.hasNext()){
int n=cin.nextInt();
System.out.println(s[n]);
}
}
}
7.通用卡特兰数打表模板:
int a[105][250];
void ktl()
{
int i,j,yu,len;
a[1][0]=1;
a[1][1]=1;
len=1;
for(i=2;i<101;i++)
{
yu=0;
for(j=1;j<=len;j++)
{
int t=(a[i-1][j])*(4*i-2)+yu;
//如果是求考虑顺序的排列,如不同点敏感的n节点的二叉树种类则改成这句即可
//int t=(a[i-1][j])*(4*i-2)*i+yu;
yu=t/10;
a[i][j]=t%10;
}
while(yu)
{
a[i][++len]=yu%10;
yu/=10;
}
for(j=len;j>=1;j--)
{
int t=a[i][j]+yu*10;
a[i][j]=t/(i+1);
yu=t%(i+1);
}
while(!a[i][len])
{
len--;
}
a[i][0]=len;
}
}
int main()
{
ktl();
int n;
while(scanf("%d",&n)!=EOF)
{
for(int i=a[n][0];i>0;i--)
{
printf("%d",a[n][i]);
}
puts("");
}
return 0;
}快速幂
求 m^k mod p,时间复杂度 O(logk)。开long long是为了保险起见,防止溢出。实际用的时候注意类型转换
long long pow(long long m, long long k, long long p){
long long res = 1 % p, t = m;
while (k>0)
{
if ((k&1)>0) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res%p;
}位运算处理大数相乘(1e18)
//0 < a,b,p < 1e18 ;
//求a * b % p
//原理把乘法变成加法
ll quick_add(ll a,ll b,ll p)
{
ll res=0;
while(b)
{
if(b&1) res=(res+a)%p;
a=(a+a)%p;
b>>=1;
}
return res;
}扩展欧几里得算法
// 求x, y,使得ax + by = gcd(a, b)
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1; y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a/b) * x;
return d;
}
应用的时候可以同时求最大公倍数和二元一次方程的解;
比如:ax+by=k;
如果这个方程组有解,那么k%gcd(a,b)==0;假设有解的情况下去解这个方程;
那么先用exgcd解方程 ax+by=gcd(a,b); 设解为x0,y0;
通解形式:
x=x0+b/gcd(a,b) * n (相当于 x 每次可以增减:b/gcd 的整数倍)
y=y0+a/gcd(a,b) * n (相当于 y 每次可以增减:a/gcd 的整数倍)
《注意:x 求出来后,y 通常由 x 代入方程求得》
最小整数解;
x=(x+b/gcd*n)%(b/gcd) = x%(b/gcd) (b/gcd(a,b) 应取正)
若 x<=0,则 x+=b/gcd高斯消元
// a[N][N]是增广矩阵
int gauss()
{
int c, r;
for (c = 0, r = 0; c < n; c ++ )
{
int t = r;
for (int i = r; i < n; i ++ ) // 找到绝对值最大的行
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]); // 将绝对值最大的行换到最顶端
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; // 将当前上的首位变成1
for (int i = r + 1; i < n; i ++ ) // 用当前行将下面所有的列消成0
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n)
{
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps)
return 2; // 无解
return 1; // 有无穷多组解
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0; // 有唯一解
}求组合数
递归法求组合数(数据规模小)
// c[a][b] 表示从a个苹果中选b个的方案数
for (int i = 0; i < N; i ++ )
for (int j = 0; j <= i; j ++ )
if (!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
封装预处理C(x,z) 0<=z<=y
void init(int x,int y)
{
C[0][0]=C[1][0] = C[1][1] = 1;
for (int i = 2; i <=x; i++)
{
C[i][0] = 1;
for (int j = 1; j <=y; j++)
C[i][j] = (C[i - 1][j] + C[i - 1][j - 1])%mod;
}
}
通过预处理逆元的方式求组合数(数据规模上万)
首先预处理出所有阶乘取模的余数fact[N],以及所有阶乘取模的逆元infact[N]
如果取模的数是质数,可以用费马小定理求逆元
int qmi(int a, int k, int p) // 快速幂模板
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
// 预处理阶乘的余数和阶乘逆元的余数
fact[0] = infact[0] = 1;
for (int i = 1; i < N; i ++ )
{
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}Lucas定理(数据规模上亿)
若p是质数,则对于任意整数 1 <= m <= n,有:
C(n, m) = C(n % p, m % p) * C(n / p, m / p) (mod p)
int qmi(int a, int k) // 快速幂模板
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b) // 通过定理求组合数C(a, b)
{
int res = 1;
for (int i = 1, j = a; i <= b; i ++, j -- )
{
res = (LL)res * j % p;
res = (LL)res * qmi(i, p - 2) % p;
}
return res;
}
int lucas(LL a, LL b)
{
if (a < p && b < p) return C(a, b);
return (LL)C(a % p, b % p) * lucas(a / p, b / p) % p;
}分解质因数法求组合数(不取模求真实值)
当我们需要求出组合数的真实值,而非对某个数的余数时,分解质因数的方式比较好用:
1. 筛法求出范围内的所有质数
2. 通过 C(a, b) = a! / b! / (a - b)! 这个公式求出每个质因子的次数。 n! 中p的次数是 n / p + n / p^2 + n / p^3 + ...
3. 用高精度乘法将所有质因子相乘
int primes[N], cnt; // 存储所有质数
int sum[N]; // 存储每个质数的次数
bool st[N]; // 存储每个数是否已被筛掉
void get_primes(int n) // 线性筛法求素数
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int get(int n, int p) // 求n!中的次数
{
int res = 0;
while (n)
{
res += n / p;
n /= p;
}
return res;
}
vector<int> mul(vector<int> a, int b) // 高精度乘低精度模板
{
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i ++ )
{
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (t)
{
c.push_back(t % 10);
t /= 10;
}
return c;
}
get_primes(a); // 预处理范围内的所有质数
for (int i = 0; i < cnt; i ++ ) // 求每个质因数的次数
{
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p);
}
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i ++ ) // 用高精度乘法将所有质因子相乘
for (int j = 0; j < sum[i]; j ++ )
res = mul(res, primes[i]);几何模板
#include <bits/stdc++.h>
const double eps = 1e-8;
inline int dcmp(double x) {
return x < -eps ? -1 : x > eps;
}
struct Point;
using Vector = Point;
using Polygon = std::vector<Point>;
struct Point {
double x,y;
Point() {}
Point(double _x,double _y) : x(_x),y(_y) {}
Point operator + (const Point &rhs) const {
return Point(x + rhs.x,y + rhs.y);
}
Point operator - (const Point &rhs) const {
return Point(x - rhs.x,y - rhs.y);
}
Point operator * (double t) const {
return Point(x * t,y * t);
}
bool operator == (const Point &rhs) const {
return dcmp(x - rhs.x) == 0 && dcmp(y - rhs.y) == 0;
}
double length() const {
return hypot(x,y);
}
void read() {
scanf("%lf%lf",&x,&y);
}
// *this 绕 o 逆时针旋转 angle 角度
Point rotate(const Point &o,double angle) const {
Point t = (*this) - o;
double c = cos(angle),s = sin(angle);
return Point(o.x + t.x * c - t.y * s,o.y + t.x * s + t.y * c);
}
// *this 向量的单位法向量(左转90度,长度归一化)
Vector normal() const {
double L = length();
return Vector(-y / L,x / L);
}
};
double det(const Point &a,const Point &b) {
return a.x * b.y - a.y * b.x;
}
double dot(const Point &a,const Point &b) {
return a.x * b.x + a.y * b.y;
}
// 用于极角排序的cmp函数
bool polar_cmp(const Point &a,const Point &b) {
if (dcmp(a.y) * dcmp(b.y) <= 0) {
if (dcmp(a.y) > 0 || dcmp(b.y) > 0) return dcmp(a.y - b.y) < 0;
if (dcmp(a.y) == 0 && dcmp(b.y) == 0) return dcmp(a.x - b.x) < 0;
}
return dcmp(det(a,b)) > 0;
}
// 直线与直线的交点
Point intersection_line_line(Point p,Vector v,Point q,Vector w) {
Vector u = p - q;
double t = det(w,u) / det(v,w);
return p + v * t;
}
// 点到直线距离
double distance_point_line(Point p,Point a,Point b) {
Vector v1 = b - a,v2 = p - a;
return std::abs(det(v1,v2)) / v1.length();
}
// 点到线段距离
double distance_point_segment(Point p,Point a,Point b) {
if (a == b) return (p - a).length();
Vector v1 = b - a,v2 = p - a,v3 = p - b;
if (dcmp(dot(v1,v2)) < 0) return v2.length();
else if (dcmp(dot(v1,v3)) > 0) return v3.length();
else return std::abs(det(v1,v2)) / v1.length();
}
// 点在直线上的投影
Point projection_point_line(Point p,Point a,Point b) {
Vector v = b - a;
return a + v * (dot(v,p - a) / dot(v,v));
}
// 线段规范相交判定
bool intersection_proper_segment_segment(Point a1,Point a2,Point b1,Point b2) {
double c1 = det(a2 - a1,b1 - a1),c2 = det(a2 - a1,b2 - a1),
c3 = det(b2 - b1,a1 - b1),c4 = det(b2 - b1,a2 - b1);
return dcmp(c1) * dcmp(c2) < 0 && dcmp(c3) * dcmp(c4) < 0;
}
// 点在线段上判定(端点也算)
bool on_point_segment(Point p,Point a1,Point a2) {
return dcmp(det(a1 - p,a2 - p)) == 0 && dcmp(dot(a1 - p,a2 -p)) <= 0;
}
// 线段相交判定(交在点上也算)
bool intersection_segment_segment(Point a1,Point a2,Point b1,Point b2) {
if (intersection_proper_segment_segment(a1,a2,b1,b2)) return true;
return on_point_segment(a1,b1,b2) || on_point_segment(a2,b1,b2)
|| on_point_segment(b1,a1,a2) || on_point_segment(b2,a1,a2);
}
// 点在多边形内判定
bool in_point_polygon(Point o,const Polygon &poly,bool flag) {
// 传入flag表示在边界上算不算在里面
int t = 0;
Point a,b;
int n = poly.size();
for (int i = 0; i < n; ++ i) {
if (on_point_segment(o,poly[i],poly[(i + 1) % n]))
return flag;
}
for (int i = 0; i < n; ++ i) {
a = poly[i];
b = poly[(i + 1) % n];
if (dcmp(a.y - b.y) > 0) std::swap(a,b);
if (dcmp(det(a - o,b - o)) < 0 &&
dcmp(a.y - o.y) < 0 && dcmp(o.y - b.y) <= 0)
++ t;
}
return t & 1;
}
int main() {
}
数学公式
三角形面积公式:S=(x1y2+x2y3+x3y1-x1y3-x2y1-x3y2) /2
皮克定理:S=a+b÷2-1 (a为多边形内部整数点个数,b为多边形边界上整数点)
边界整数点定理:num=gcd( sx-ex , sy-ey )+1 s为起点,e为终点
海伦公式:
直线分割平面最多化:f(n) = n ( n + 1 ) / 2 + 1
折线分平面:f(n)=2n^2-n+1
封闭曲线分平面:f(n)=n^2-n+2
平面分割空间问题:f(n)=(n^3+5n)/6+1
给定n条直线求划分区域的个数:Sum= 1+(2-1)*两条直线交在一起的个数 + (3-1) * 三条直线交在一起的个数 + (N-1)*n条直线交在一起的个数 + N;

图论
有向图的拓扑序
bool topsort()
{
// inv存储点的入度
for(int i=1;i<=n;i++)
{
if(inv[i]==0) q.push(i);
}
while(!q.empty())
{
int res=q.front();
q.pop();
p.push(res);
for(int i=h[res];i!=-1;i=ne[i])
{
int j=e[i];
inv[j]--;
if(inv[j]==0) q.push(j);
}
}
if(p.size()==n) return true; //如果所有点都入队,说明存在拓扑序
else return false;
}树的直径
树的直径求法有很多:
- 两次BFS或者两次DFS;
- 树形DP
树形DP的基本思路:

int h[N],e[N<<1],ne[N<<1],w[N<<1],idx;
int d[2][N],dmax;//d[0]表示u到其子树中叶子节点的最长距离,d[1]表示次长
void add(int a,int b,int c)
{
e[idx]=b,ne[idx]=h[a],w[idx]=c,h[a]=idx++;
}
void dfs(int u,int fa)
{
for(int i=h[u];~i;i=ne[i])
{ int j=e[i];
if(j==fa) continue;
dfs(j,u);
if(d[0][u]<d[0][j]+w[i]) d[1][u]=d[0][u],d[0][u]=d[0][j]+w[i];
else if(d[1][u]<d[0][j]+w[i]) d[1][u]=d[0][j]+w[i];
dmax=max(dmax,d[0][u]+d[1][u]);
}
}最短路算法模板
前言.2
单源最短路,常用算法有:
- dijkstra,只有所有边的权值为正时才可以使用。在稠密图上的时间复杂度是 O(n^2),稀疏图上和堆优化版过后的时间复杂度是一样的为O(mlogn)。
- spfa,不论边权是正的还是负的,都可以做。算法平均时间复杂度是 O(km),k是常数。网格图以及过于稠密的图尽量不要使用;
多源最短路:一般用floyd算法。代码很短,三重循环,时间复杂度是 O(n^3)。
朴素版Dijkstra O(n^2)
时间复杂是 O(n^2+m), n 表示点数,m 表示边数
int g[N][N]; // 存储每条边
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ )
{
int t = -1; // 在还未确定最短路的点中,寻找距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
堆优化版Dijkstra O(mlogn)
typedef pair<int, int> PII;
int n; // 点的数量
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储所有点到1号点的距离
bool st[N]; // 存储每个点的最短距离是否已确定
// 求1号点到n号点的最短距离,如果不存在,则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0, 1}); // first存储距离,second存储节点编号
while (heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (st[ver]) continue;
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}spfa算法(带优化) O(km)
朴素版spfa:
int n, m;
int dist[N], q[N]; // dist表示每个点到起点的距离, q 是队列
int h[N], e[M], v[M], ne[M], idx; // 邻接表
bool st[N]; // 存储每个点是否在队列中
void add(int a, int b, int c)
{
e[idx] = b, v[idx] = c, ne[idx] = h[a], h[a] = idx++;
}
void spfa()
{
int hh = 0, tt = 0;
for (int i = 1; i <= n; i++) dist[i] = INF;
dist[1] = 0;
q[tt++] = 1, st[1] = 1;
while (hh != tt)
{
int t = q[hh++];
st[t] = 0;
if (hh == n) hh = 0;
for (int i = h[t]; i != -1; i = ne[i])
if (dist[e[i]] > dist[t] + v[i])
{
dist[e[i]] = dist[t] + v[i];
if (!st[e[i]])
{
st[e[i]] = 1;
q[tt++] = e[i];
if (tt == n) tt = 0;
}
}
}
}
其中数组模拟的循环队列可以用STL里面的queue代替;加SFA优化版的spfa:
void spfa(int root,int dist[])
{
memset(dist,0x3f,sizeof dis);
dist[root] = 0;
memset(st, false, sizeof st);
deque<int> q;
q.push_back(root);
st[root]=true;
while (q.size())
{
int res=q.front();
q.pop_front();
st[res]=false;
for(int i=h[res];i!=-1;i=ne[i])
{
int j=e[i];
if(dist[j]>dist[res]+w[i])
{
dist[j]=dist[res]+w[i];
if(!st[j])
{
st[j]=true;
if(dist[j]>dist[q.front()]) q.push_back(j);
else q.push_front(j);
}
}
}
}
}
SPFA判负环正环
判正环求最长路,判负环求最短路;有个玄学优化 (注释代码) 当点的更新次数大于总点数的2~5倍时,就可认为存在环
(或者把队列换成栈)
负环示例:
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N], cnt[N]; // dist[x]存储1号点到x的最短距离,cnt[x]存储1到x的最短路中经过的点数
bool st[N]; // 存储每个点是否在队列中
// 如果存在负环,则返回true,否则返回false
bool spfa()
{
// 原理:如果某条最短路径上有n个点(除了自己),那么加上自己之后一共有n+1个点,由抽屉原理一定有两个点相同,所以存在环。
memset(dis,0,sizeof dis);//如果求正环,则初始化为负无穷
memset(st,false,sizeof st);
memset(cnt,0,sizeof cnt);
queue<int> q;
for(int i=0;i<=n;i++) q.push(i),st[i]=true;//如果有虚拟超级源点和所有的点相连,那么只需加入源点即可
int count=0;
while(q.size())
{
int t=q.front();
st[t]=false;
q.pop();
for(int i=h[t];i!=-1;i=ne[i])
{
int j=e[i];
if(dis[j]>dis[t]+w[i])
{
dis[j]=dis[t]+w[i];
cnt[j]=cnt[t]+1;
//if(++count>4*N) return true; 当点的更新次数大于总点数的2~5倍时,就可认为存在环
if(cnt[j]>=n) return true;
if(!st[j])
{
q.push(j);
st[j]=true;
}
}
}
}
return false;
}floyd算法 O(n^3)
int n, m;
int d[N][N]; // 存储两点之间的最短距离
int main()
{
cin >> m >> n;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
d[i][j] = i == j ? 0 : INF;
for (int i = 0; i < m; i++)
{
int a, b, c;
cin >> a >> b >> c;
d[a][b] = d[b][a] = min(c, d[a][b]);
}
// floyd 算法核心
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
cout << d[1][n] << endl;
return 0;
}差分约束系统
注意超级虚拟源点的假设;差分条件一定要找全;变量的绝对值不能忘;

最长路径算法
(简而言之不用Dijkstra,板子SPFA直接上)
1. 肯定不能用dijkstra算法,这是因为,Dijkstra算法的大致思想是每次选择距离源点最近的结点加 入,然后更新其它结点到源点的距离,直到所有点都被加入为止。当每次选择最短的路改为每次选择最长路的时候,出现了一个问题,那就是不能保证现在加入的结 点以后是否会被更新而使得到源点的距离变得更长,而这个点一旦被选中将不再会被更新。例如这次加入结点u,最长路为10,下次有可能加入一个结点v,使得 u通过v到源点的距离大于10,但由于u在之前已经被加入到集合中,无法再更新,导致结果是不正确的。
如果取反用dijkstra求最短路径呢,记住,dijkstra不能计算有负边的情况。。。
2.可 以用 Bellman-Ford || SPFA算法求最长路径,。也可以用Floyd-Warshall 算法求每对节点之间的最长路经,因为最长路径也满足最优子结构性质,而Floyd算法的实质就是动态规划。但是,如果图中含有回路,Floyd算法并不能 判断出其中含有回路,且会求出一个错误的解;而Bellman-Ford算法则可以判断出图中是否含有回路。
3. 如果是有向无环图,先拓扑排序,再用动态规划求解。
最短路径计数
dijkstra拆点最短次短路计数
(只对最短路径计数时,不需要拆点,正常bfs或者dijkstra就可以了)
(注意,一定要先更新次短路点的信息,因为最短路没有更新的时候,次最短路可能更新;而次最短路更新的时候,最短路一定会更新;)
#define x first
#define y second
typedef pair<pair<int,int>,int> PII;
int n, m, S, F;
const int N=1010,M=20010;
int h[N], e[M], w[M], ne[M], idx;
int dis[N][2], cnt[N][2];//0表示最短路状态,1表示次短路状态
bool st[N][2];
void add(int a, int b, int c)
{
e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
}
int dijkstra(int root)
{
memset(dis,0x3f,sizeof dis);
memset(st,false,sizeof st);
memset(cnt,0,sizeof cnt);
dis[root][0]=0,cnt[root][0]=1;
priority_queue<PII,vector<PII>,greater<PII> > heap;
heap.push({{0,0},root});//依次存放最短距离,状态类型,点的id,注意,第一个一定要放最短距离
while(!heap.empty())
{
auto t=heap.top();
heap.pop();
int ver=t.y,type=t.x.y,distance=t.x.x,res=cnt[ver][type];
if(st[ver][type]) continue;
st[ver][type] = true;
for(int i=h[ver];i!=-1;i=ne[i])
{
int j=e[i];
if(dis[j][0]>distance+w[i])
{
dis[j][1]=dis[j][0],cnt[j][1]=cnt[j][0];
heap.push({{dis[j][1],1},j});
dis[j][0]=distance+w[i],cnt[j][0]=res;
heap.push({{dis[j][0],0},j});
}
else if(dis[j][0]==distance + w[i]) cnt[j][0]+=res;
else if(dis[j][1]>distance+w[i])
{
dis[j][1]=distance+w[i];
cnt[j][1]=res;
heap.push({{dis[j][1],1},j});
}
else if(dis[j][1]==distance + w[i])
{
cnt[j][1]+=res;
}
}
}
//dijkstra处理之后,要对终点的状态进行判断
int ans = cnt[F][0];
if (dis[F][0] + 1 == dis[F][1]) ans += cnt[F][1];
return ans;
}最小生成树
前言.3
最小生成树 : prim算法 kruskal算法
适用于无向图;两个算法都可以求最小生成树,最小生成森林,以及树或者森林中边的权重最大的一条边;一般处理有关连通块的生成树的题目时,用kruskal算法加上一些并查集的操作,bfs/dfs处理;其他情况两种算法一般都能够处理
次小生成树 定义:给一个带权的图,把图的所有生成树按权值从小到大排序,第二小的称为次小生成树。
方法1:先求最小生成树,再枚举删去最小生成树中的边求解。时间复杂度。O(mlogm + nm)
方法2:先求最小生成树,然后依次枚举非树边,然后将该边加入树中,同时从树中去掉一条边, 使得最终的图仍是一
棵树。则一定可以求出次小生成树。
设T为图G的一棵生成树,对于非树边a和树边b,插入边a,并删除边b的操作记为(+a, -b)。
如果T+a-b之后,仍然是一棵生成树, 称(+a,-b)是T的一 个可行交换。
称由T进行一次可行变换所得到的新的生成树集合称为T的邻集。
定理:次小生成树一定在最小生成树的邻集中。
prim算法
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ )
{
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
}
return res;
}kruskal算法
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}最小生成森林
prim算法修改
int n,k; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ )
{
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
if(i&&dist[t]==0x3f3f3f3f) continue;
if (i) res += dist[t];
}
return res;
}次最小生成树
const int N=510,M=(1e4+7)*2;
int dis1[N][N],dis2[N][N],n,m,idx;
int h[M],e[M],ne[M],w[M],p[N];
struct node
{
int a,b,c;
bool flag;
}egdes[M/2];
bool cmp(node a,node b)
{
return a.c<b.c;
}
void add(int a,int b,int c)
{
e[idx]=b,w[idx]=c,ne[idx]=h[a],h[a]=idx++;
}
int find(int x)
{
if(x!=p[x]) p[x]=find(p[x]);
return p[x];
}
void dfs(int u,int fa,int max_1d,int max_2d,int d1[],int d2[])
{
d1[u]=max_1d,d2[u]=max_2d;
for(int i=h[u];i!=-1;i=ne[i])
{
int j=e[i];
if(j==fa) continue;
int maxt1=max_1d,maxt2=max_2d;
if(w[i]>maxt1) maxt2=maxt1,maxt1=w[i];
else if(w[i]<maxt1&&w[i]>maxt2) maxt2=w[i];
dfs(j,u,maxt1,maxt2,d1,d2);
}
}
int main()
{
memset(h,-1,sizeof h);
cin >>n>>m;
for(int i=0;i<=n;i++) p[i]=i;
for(int i=0;i<m;i++)
{
int a,b,c;
cin >>a>>b>>c;
egdes[i]={a,b,c};
}
sort(egdes,egdes+m,cmp);
ll sum=0;
for(int i=0;i<m;i++)
{
int a=find(egdes[i].a),b=find(egdes[i].b),c=egdes[i].c;
if(a!=b)
{
p[a]=b;
sum+=c;
add(egdes[i].a,egdes[i].b,c),add(egdes[i].b,egdes[i].a,c);
egdes[i].flag=true;
}
}
for(int i=1;i<=n;i++) dfs(i,-1,-1,-1,dis1[i],dis2[i]);
ll ans=1e18;
for(int i=0;i<m;i++)
{
if(!egdes[i].flag)
{
int a=egdes[i].a,b=egdes[i].b,c=egdes[i].c;
if(c>dis1[a][b]) ans=min(ans,sum+c-dis1[a][b]);
else if(c>dis2[a][b]) ans=min(ans,sum+c-dis2[a][b]);
}
}
cout <<ans<<endl;最近公共祖先
前言.4

倍增在线算法
void bfs(int root)//从根节点开始处理每个点的深度并且进行fa的倍增
{
memset(depth,0x3f,sizeof depth);
queue<int> q;
q.push(root);
depth[0]=0,depth[root]=1;//设置哨兵
while(q.size())
{
int t=q.front();
q.pop();
for(int i=h[t];~i;i=ne[i])
{
int j=e[i];
if(depth[j]>depth[t]+1)
{
depth[j]=depth[t]+1;
fa[j][0]=t;
q.push(j);
for(int k=1;k<16;k++)//倍增里面的常数根据题目节点个数而定
fa[j][k]=fa[fa[j][k-1]][k-1];
}
}
}
}
int lca(int a,int b)
{
if(depth[a]<depth[b]) swap(a,b);//对深度大的点进行往上跳跃
for(int k=15;k>=0;k--)
if(depth[fa[a][k]]>=depth[b])
a=fa[a][k];
if(a==b) return a;
for(int k=15;k>=0;k--)//两个点同时跳跃,直到最近公共祖先的下面的节点
{
if(fa[a][k]!=fa[b][k])
{
a=fa[a][k];
b=fa[b][k];
}
}
return fa[a][0];//返回a的父亲,也就是最近公共祖先
}targin离线算法
vector<PII> query[N]; // first存查询的另外一个点,second存查询编号
void dfs(int u,int fa)//处理任一点到根的距离
{
for(int i=h[u];~i;i=ne[i])
{
int j=e[i];
if(j==fa) continue;
dis[j]=dis[u]+w[i];
dfs(j,u);
}
}
int find(int x)
{
if(x!=p[x]) p[x]=find(p[x]);
return p[x];
}
void targin(int u)
{
st[u]=1; //正在处理的点标记为1
for(int i=h[u];~i;i=ne[i])
{
int j=e[i];
if(!st[j]) //如果某个邻点未被遍历那么就加入递归
{
targin(j);
p[j]=u; //合并子父节点
}
}
//在回溯的过程中进行
for(auto it : quiry[u]) //查询关于u的询问中,有没有已经遍历且回溯过的点;
{
int x=u,y=it.first,id=it.second;
if(st[y]==2)
{
int lca=find(y);
ans[id]=dis[x]+dis[y]-2*dis[lca];
}
}
st[u]=2; //u已经回溯遍历过,所以进行标记
}有向图的强连通分量
设tarjan处理后的图中入度为0的点个数为 P ,出度为0的点的个数为 Q ;
处理后的图是有向无环图(DAG),满足拓扑序;
如果求起点的话就是P, 重点的话就是Q;如果把这个图变成强连通图需要加 max(P,Q) 条边;
如果跑图求最长最短路径,那么每个强连通分量可以看成一个点(缩点),并且要在缩点的时候建新边;
int h[N], e[M], ne[M], idx;
int dfn[N], low[N], timestamp;//当前节点的时间戳 当前节点的子树的时间戳的最小值
int stk[N], top;//栈
bool in_stk[N];//判断节点是否在栈里面
int id[N], scc_cnt;//标记每个节点属于哪个强连通块
int din[N], dout[N];//统计强连通块的入读和出度
int size_scc[N];//每个强连通块的大小
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
void tarjan(int u)
{
dfn[u] = low[u] = ++ timestamp;
stk[ ++ top] = u, in_stk[u] = true;
for (int i = h[u]; ~i; i = ne[i])
{
int j = e[i];
if (!dfn[j])
{
tarjan(j);
low[u] = min(low[u], low[j]);
}
else if (in_stk[j])
low[u] = min(low[u], dfn[j]);
}
if (dfn[u] == low[u])//如果记录的两个时间戳相等,则说明u为强连通块的最高点
{
++ scc_cnt;
int y;
do {
y = stk[top -- ];
in_stk[y] = false;
id[y] = scc_cnt;
//size_scc[scc_cnt]++;
} while (y != u);
}
}
for(int i=1;i<=n;i++)
{
if(!dfn[i])//当前节点未被遍历过时,时间戳为0
tarjan(i);
}
for(int i=1;i<=n;i++)//缩点
{
for(int j=h[i];~j;j=ne[j])
{
int k=e[j];
int a=id[i],b=id[k];//两个节点的强连通块不属于一个时,就建一条a—>b的边
if(a!=b) dout[a]++;
//或者是其他的建边操作
}
}无向图的点双连通分量
点双联通是一个联通图中去掉任意一点都不会影响图的连通性
const int N = 1010, M = 1010;
int n, m;
int h[N], e[M], ne[M], idx;
int dfn[N], low[N], timestamp;
int stk[N], top;
int dcc_cnt;
vector<int> dcc[N];//记录每个双连通块里的点
bool cut[N];
int root;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
void tarjan(int u)
{
dfn[u] = low[u] = ++ timestamp;
stk[ ++ top] = u;
if (u == root && h[u] == -1)
{
dcc_cnt ++ ;
dcc[dcc_cnt].push_back(u);
return;
}
int cnt = 0;
for (int i = h[u]; ~i; i = ne[i])
{
int j = e[i];
if (!dfn[j])
{
tarjan(j);
low[u] = min(low[u], low[j]);
if (dfn[u] <= low[j])
{
cnt ++ ;
if (u != root || cnt > 1) cut[u] = true;
++ dcc_cnt;
int y;
do {
y = stk[top -- ];
dcc[dcc_cnt].push_back(y);
} while (y != j);
dcc[dcc_cnt].push_back(u);
}
}
else low[u] = min(low[u], dfn[j]);
}
}
int main()
{
int T = 1;
while (cin >> m, m)
{
for (int i = 1; i <= dcc_cnt; i ++ ) dcc[i].clear();
idx = n = timestamp = top = dcc_cnt = 0;
memset(h, -1, sizeof h);
memset(dfn, 0, sizeof dfn);
memset(cut, 0, sizeof cut);
//以上为多组输入的初始化
while (m -- )
{
int a, b;
cin >> a >> b;
n = max(n, a), n = max(n, b);
add(a, b), add(b, a);
}
for (root = 1; root <= n; root ++ )
if (!dfn[root])
tarjan(root);
}
二分图
前言5
- 二分图一定可以染色成功,并且不存在奇数环,反推也成立;
- 匈牙利算法也称把妹算法(y总牛逼),可以进行求二分图的匹配,最大匹配,最大独立集 ,最小点覆盖问题;
- 关于棋盘问题,当棋盘的size大小比较小时,可以用状态压缩DP,大的时候可以考虑成二分图,按匈牙利算法求解;
- 最大匹配数 = 最小点覆盖 = 总点数 - 最大独立集 = 总点数 - 最小点覆盖
染色法
时间复杂度是 O(n+m), n 表示点数,m表示边数
就是用深度优先遍历整张图,遍历的同时染色就可;当二分图有奇数环时,就说明不能成功染色;反之亦然;(前提必须是二分图)
int n; // n表示点数
int h[N], e[M], ne[M], idx; // 邻接表存储图
int color[N]; // 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色
bool dfs(int u, int c)
{
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (color[j] == -1)
{
if (!dfs(j, !c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
bool check()
{
memset(color, -1, sizeof color);
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (color[i] == -1)
if (!dfs(i, 0))
{
flag = false;
break;
}
return flag;
}匈牙利算法(把妹算法)
匈牙利算法可以解决很多问题;(最大匹配,最大独立集,最小点覆盖,最小路径点覆盖(最小路径重复点覆盖));
nt n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数
int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边
int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个
bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点
int res = 0;
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st);
if (find(i)) res ++ ;
}数据结构
单链表
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在链表头插入一个数a
void insert(int a)
{
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 将头结点删除,需要保证头结点存在
void remove()
{
head = ne[head];
}双链表
// e[]表示节点的值,l[]表示节点的左指针,r[]表示节点的右指针,idx表示当前用到了哪个节点
int e[N], l[N], r[N], idx;
// 初始化
void init()
{
//0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在节点a的右边插入一个数x
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
l[r[a]] = idx, r[a] = idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
单调栈
常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}单调队列
单调队列是一种思想, 每次取队头,队头如果满足条件,那么一定是最优的(最小或最大的,最长最远的,数量最多的,潜力更大,拓展性更强,生存能力更高,节点入队时间短的,等等....);然后把队尾那些"劣质”的节点信息给弹出;(一般队列里都存放下标)
滑动窗口
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}最大子段和(限制区间长度)
for (int i = 1; i <= n; i ++ ) scanf("%d", &s[i]), s[i] += s[i - 1];
int res = -INF;
int hh = 0, tt = 0;
for (int i = 1; i <= n; i ++ )//核心代码
{
if (q[hh] < i - m) hh ++ ;
res = max(res, s[i] - s[q[hh]]);
while (hh <= tt && s[q[tt]] >= s[i]) tt -- ;
q[ ++ tt] = i;
}并查集
(1)朴素并查集:
int p[N]; //存储每个点的祖宗节点
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ ) p[i] = i;
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
(2)维护size的并查集:
int p[N], size[N];
//p[]存储每个点的祖宗节点, size[]只有祖宗节点的有意义,表示祖宗节点所在集合中的点的数量
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
size[i] = 1;
}
// 合并a和b所在的两个集合:
size[find(b)] += size[find(a)];
p[find(a)] = find(b);
(3)维护到祖宗节点距离的并查集:
int p[N], d[N];
//p[]存储每个点的祖宗节点, d[x]存储x到p[x]的距离
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x)
{
int u = find(p[x]);
d[x] += d[p[x]];
p[x] = u;
}
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
d[i] = 0;
}
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
d[find(a)] = distance; // 根据具体问题,初始化find(a)的偏移量
字符串哈希
核心思想:将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧:取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
KMP——字符串匹配
KMP最小循环节、循环周期:
定理:假设S的长度为 len,则S存在最小循环节,循环节的长度L为 len-next[len] ,子串为S[0…len-next[len]-1]。
(1)如果 len 可以被 len - next[len] 整除,则表明字符串S可以完全由循环节循环组成,循环周期 T=len/L。
(2)如果不能,说明还需要再添加几个字母才能补全。需要补的个数是循环个数 L-len%L=L-(len-L)%L=L-next[len]%L,L=len-next[len]。
(3) 循环节出现的长度就是当前位置的长度
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+7;
char p[N],s[N];//p是模式串(短),s是文本串(长)
int ne[N];//next[j]就是待匹配串从t[0]开始到t[j-1]结尾的这个子串中,前缀和后缀相等时对应前缀/后缀的最大长度
int main()
{
int n;cin >>n>>p+1; //字符串都从1开始
int m;cin >>m>>s+1;
for(int i=2,j=0;i<=n;i++)//先求模式串本身的next数组
{
while(j&&p[i]!=p[j+1]) j=ne[j];
if(p[i]==p[j+1]) j++;
ne[i]=j;
}
for(int i=1,j=0;i<=m;i++)
{
while(j&&s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;//当前能两个字符串能匹配的最大长度
//max_p=max(max_p,j);
if(j==n)//匹配成功
{
cout <<i-n<<" ";
j=ne[j];
}
}
}高级数据结构
线段树
最大连续子段和(单点修改)
int w[N];//区间里的数
int n,m;
struct node
{
int l,r; //当前结点所处区间
int sum; //当前区间的权值和
int lmax; //当前区间的最大前缀和
int rmax; //当前区间的最大后缀和
int tmax; //当前区间的最大连续子序列和
}tr[N*4];//注意对题中所给操作数量或者数据要开4倍大
void pushup(node &u,node &l,node &r)
{
u.sum=l.sum+r.sum;//父节点的和等于 左节点+右节点
u.lmax=max(l.lmax,l.sum+r.lmax); //父节点的最大前缀和等于max(左孩子最大前缀和,左孩子的和+右孩子的最大前缀和)
u.rmax=max(r.rmax,r.sum+l.rmax);//和上面同理
u.tmax=max(max(l.tmax,r.tmax),l.rmax+r.lmax);//包含三种情况,属于左孩子,属于有孩子,或者跨区间左边和右边
}
void pushup(int u)// 由子节点更新父节点
{
pushup(tr[u],tr[u<<1],tr[u<<1|1]);
}
void build(int u,int l,int r)
{
if(l==r) tr[u]={l,r,w[r],w[r],w[r],w[r]};//如果处理到叶结点了,就保存叶结点的信息
else
{ tr[u]={l,r}; //保存当前节点的区间信息
int mid=l+r>>1;
build(u<<1,l,mid); //递归左节点
build(u<<1|1,mid+1,r); // 递归右节点
pushup(u); //每次根据子节点更新父节点
}
}
void modify(int u,int x,int v)
{
if(tr[u].l==x&&tr[u].r==x) tr[u] = {x,x,v,v,v,v}; // //如果处理到叶结点了,就保存叶结点的信息
else
{
int mid=tr[u].l+tr[u].r>>1; //当前节点区间的中点
if(x<=mid) modify(u<<1,x,v); //如果要修改的地方处于中点的左端,则递归其左儿子
else modify(u<<1|1,x,v); // 如果要修改的地方处于中点的右端,则递归其右儿子
pushup(u); //修改完之后由子节点更新父节点的信息
}
}
node query(int u,int l,int r) //在区间l,r里面查询
{
if(tr[u].l>=l&&tr[u].r<=r) return tr[u]; // 如果当前区间在l~r里面,则直接返回想要的信息
else
{
int mid=tr[u].l+tr[u].r>>1; //取当前节点的区间中点
if(r<=mid) return query(u<<1,l,r); // 如果当前查询区间在当前区间的中点左端,则递归左儿子
else if(l>mid) return query(u<<1|1,l,r); //如果当前查询区间在当前节点区间的右端,则递归右儿子;
else //如果一部分在mid左边,一部分在mid右边
{
auto left=query(u<<1,l,r); //递归左儿子
auto right=query(u<<1|1,l,r); //递归右儿子
node res;
pushup(res,left,right); //由左儿子和右儿子的信息来更新当前父节点的信息
return res;
}
}
}区间整体加和乘(区间修改)
int w[N];//区间里的数
int n,m,p;
struct node
{
ll l,r; //当前结点所处区间
ll sum; //当前区间的权值和
ll add; //当前区间所具有加权值的懒标记
ll mul; //当前区间所具有倍数权值的懒标记
}tr[N*4];//注意对题中所给操作数量或者数据要开4倍大
void eval(node &root,int add,int mul)
{
//更新公式: (root.mul * root.sum + root.add)*mul+add
root.sum=(root.sum*mul+(root.r-root.l+1)*add)%p;
root.mul=root.mul*mul%p;
root.add=(root.add*mul+add)%p;
}
void pushup(int u)// 由子节点更新父节点
{
tr[u].sum=(tr[u<<1].sum+tr[u<<1|1].sum)%p;
}
void pushdown(int u)
{
eval(tr[u<<1],tr[u].add,tr[u].mul);
eval(tr[u<<1|1],tr[u].add,tr[u].mul);
tr[u].add=0,tr[u].mul=1;//恢复懒标记
}
void build(int u,int l,int r)
{
if(l==r) tr[u]={l,r,w[r],0,1};//如果处理到叶结点了,就保存叶结点的信息
else
{ tr[u]={l,r,0,0,1}; //保存当前节点的信息
int mid=l+r>>1;
build(u<<1,l,mid); //递归左节点
build(u<<1|1,mid+1,r); // 递归右节点
pushup(u); //每次根据子节点更新父节点
}
}
void modify(int u,int l,int r,int add,int mul)
{
if(tr[u].l>=l&&tr[u].r<=r)
{
eval(tr[u],add,mul);//当前树中区间被包含在修改区间时,直接修改即可;
}
else
{
pushdown(u);
int mid=tr[u].l+tr[u].r>>1; //当前节点区间的中点
if(l<=mid) modify(u<<1,l,r,add,mul); //如果要修改的地方处于中点的左端,则递归其左儿子
if(r>mid) modify(u<<1|1,l,r,add,mul); // 如果要修改的地方处于中点的右端,则递归其右儿子
pushup(u); //修改完之后由子节点更新父节点的信息
}
}
node query(int u,int l,int r) //在区间l,r里面查询
{
if(tr[u].l>=l&&tr[u].r<=r) return tr[u]; // 如果当前区间在l~r里面,则直接返回想要的信息
else
{
pushdown(u);
node res;
res.sum=0;
int mid=tr[u].l+tr[u].r>>1; //取当前节点的区间中点
if(l<=mid) res.sum+=query(u<<1,l,r).sum%p;//查询区间的和等于左右两个子树区间的和
if(r>mid) res.sum+=query(u<<1|1,l,r).sum%p;
pushup(u);
return res;
}
}树状数组的三个操作
int lowbit(int x)
{
return x&-x;
}
void modify(int x,int c)//修改树状数组x位置的值
{
for(int i=x;i<=n;i+=lowbit(i)) tr[i]+=c;
}
int query(int x)//查询区间1~x的区间和;
{
int res=0;
for(int i=x;i>=1;i-=lowbit(i)) res+=tr[i];
return res;
}Trie (字符串)
Trie可以用字符串建树也可以是对十进制数的二进制进行建树
const int N = 1e5 + 10, M=1e6+7;注意数中的边可能是点的倍数,所以开个大一点的 M
int son[M][26]; // 其中存放的是:子节点对应的idx。其中son数组的第一维是:父节点对应的idx,第第二维计数是:其直接子节点('a' - '0')的值为二维下标。
int cnt [M]; // 以“abc”字符串为例,最后一个字符---‘c’对应的idx作为cnt数组的下标。数组的值是该idx对应的个数。
int idx; // 将该字符串分配的一个树结构中,以下标来记录每一个字符的位置。方便之后的插入和查找。
char str[N];
void insert(char *str)
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - '0';
if (!son[p][u]) son[p][u] = ++idx;
p = son[p][u];
}
// 此时的p就是str中最后一个字符对应的trie树的位置idx。
cnt[p]++;
}
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i++)
{
int u = str[i] - '0';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}DP(模型)
最长上升子序列模型
前沿6
一个序列的最长上升子序列的长度==非上升子序列覆盖整个序列的个数O(N^2)
for(int i=1;i<=n;i++)
{
f[i]=1
for(int j=1;j<=i;j++)
{
if(a[j]<a[i]) f[i]=max(f[i],f[j]+1);
ans=max(ans,f[i]);
}
}O(NlogN)
int len=0;
for(int i=1;i<n;i++)
{
int pos=lower_bound(f, f+len, a[i]) - f;
len=max(len,pos+1);
f[pos]=a[i];
}
cout <<len<<endl;
求最长下降子序列也可以用相同的优化
int len=0;
for(int i=1;i<n;i++)
{
int pos=upper_bound(f, f+len, a[i], greater<int>()) - f;//更新序列结尾第一个小于a[i]的序列
len=max(len,pos+1);
f[pos]=a[i];
}
cout <<len<<endl;最长公共序列模型
int main()
{
int n,m;
cin >>n>>m;
for(int i=1;i<=n;i++) cin >>a[i];
for(int i=1;i<=m;i++) cin >>b[i];
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
f[i][j]=max(f[i-1][j],f[i][j-1]);
if(a[i]==b[j]) f[i][j]=max(f[i][j],f[i-1][j-1]+1);
}
}
cout <<f[n][m]<<endl;
}最长公共上升序列模型
//f[i][j]表示所有在a[0...i],b[0....j]中出现过,以b[j]结尾的序列的集合
int ans=0;
for(int i=1;i<=n;i++)
{
int temp=1;
for(int j=1;j<=n;j++)
{
f[i][j]=max(f[i-1][j],f[i][j]);
if(a[i]==b[j]) f[i][j]=max(temp,f[i][j]);
if(a[i]>b[j]) temp=max(temp,f[i-1][j]+1);
}
}
for(int i=1;i<=n;i++) ans=max(ans,f[n][i]);编辑距离
//f(i,j)表示a[1...i]和b[1....j]编辑成相同的需要的操作次数集合
cin >>n>>a+1;
cin >>m>>b+1;
for(int i=1;i<=n;i++) f[i][0]=i;
for(int i=1;i<=m;i++) f[0][i]=i;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
f[i][j]=min(f[i-1][j]+1,f[i][j-1]+1);//添加或者删除
if(a[i]==b[j]) f[i][j]=min(f[i][j],f[i-1][j-1]);
else f[i][j]=min(f[i][j],f[i-1][j-1]+1);//修改
}
}
cout <<f[n][m]<<endl;