目录
ZooKeeper的安装与配置
1、上传安装包到master并解压
tar -zxvf zookeeper-3.4.6.tar.gz
这里所使用的zooKeeper-3.4.6的压缩包版本中可能没有zookeeper中的一些操作命令,建议安装zookeeper-3.5.7版本或者更新版本,里面会有更多的一些操作命令
2、配置环境变量
vim /etc/profile
进入到profile中添加以下内容:
export ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
保存退出后,使环境变量生效:
source /etc/profile
3、修改配置文件
进入conf配置文件目录中:
cd conf
修改zookeeper的配置文件名称:
cp zoo_sample.cfg zoo.cfg
修改:
修改其中的dataDir后的选项为以下内容:
dataDir=/usr/local/soft/zookeeper-3.4.6/data
该data目录是用于存放节点编号,每个节点都需要创建,具体看后续操作
在配置文件的最后增加以下内容:
server.0=master:2888:3888
server.1=node1:2888:3888
server.2=node2:2888:3888
配置文件zoo.cfg内容解析:
# The number of milliseconds of each tick
# 心跳时间 ms 2秒一次心跳
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# 通信限时 当服务启动时 限定初始的心跳数
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# 超时心跳 数 syncLimit * tickTime = 10s
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/soft/zookeeper-3.4.6/data
# the port at which the clients will connect
clientPort=2181
4、同步到其它节点
scp -r zookeeper-3.4.6 root@node1:`pwd`
scp -r zookeeper-3.4.6 root@node2:`pwd`
配置node1和node2的环境变量
scp /etc/profile root@node1:/etc/profile
scp /etc/profile root@node2:/etc/profile
在所有节点执行
source /etc/profile
5、创建/usr/local/soft/zookeeper-3.4.6/data目录,所有节点都要创建
mkdir /usr/local/soft/zookeeper-3.4.6/data
在data目录下创建myid文件
vim myid
master,node1,node2分别加上0,1,2
6、启动zookeeper
zkServer.sh start 三台都需要执行
zkServer.sh status 查看状态当有一个leader的时候启动成功
连接zookeeper
zkCli.sh
zk 是一个目录结构 ,每个节点可以存数据,同时可以有子节点
zk shell
创建目录
create /test test
create /test/a 1
获取数据
get /test
ls /test
delete 只能删除没有子节点的节点
rmr /test 删除节点
1、重置zk
1、杀掉所有zk进程
kiil -9 pid
2、删除data目录下的version文件, 所有节点都要删除
rm -rf /usr/local/soft/zookeeper-3.4.6/data/version-2
2、启动zk
zkServer.sh start
Zookeeper的使用命令:
登录zookeeper:
bash zkcli.sh
默认连接 localhost:2181
登录到指定端口:
bash zkcli.sh -server master:2181
命令:
help:表示帮助命令
ls:表示查看指定路径节点下的节点信息
create /test abc:表示创建节点并赋值
get /test:表示获取指定节点位置的值
set /test cb :表示重新设置节点的值
delete /test/test1:表示删除一个空的节点
在Zookeeper3.5.7版本中可以有以下命令:
create /test:表示创建一个空节点
deleteall /test:表示可以删除一个不为空的节点
get -s /test:获取指定节点位置的值与其元信息
get -w /test:表示监听一个节点
ls -w /test:表示监听一个节点下的子节点变化
stat /test:返回一个节点的元信息
create -e /test:表示创建一个临时节点,临时节点表示当前客户端如果退出,则节点消失
create -s /test:表示创建一个带有编号的节点
注意:该节点的编号根据创建节点的次数来定,无论在创建该节点前创建的其他节点是否被删除或者是否创建的是带编号的节点,只要在此之前每有一个创建节点操作,该节点在创建时编号就会向后增加1。
Java连接Zookeeper
首先在IDEA中的pom.xml文件中导入Zookeeper依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>刷新maven让其下载依赖
连接到zookeeper:
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
public class Zookeeper1_Connect {
public static void main(String[] args) throws Exception{
/**
* 连接zookeeper需要传入参数
* 1、connectString:连接的主机名与端口号
* 2、session:任务超时时间
* 3、Watcher:监听器
*/
// 设置所连接的主机名与端口号
String connectString="master:2181,node1:2181,node2:2181";
// 设置超时时间为10秒
int sessionTimeout = 10 * 1000;
// 监听器是一个接口,需要有具体实现
// 创建连接,传入以上参数
ZooKeeper zkCli = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("监听正在执行");
}
});
// 查看zkCli信息
System.out.println("zkCli:"+zkCli);
// 关闭连接
zkCli.close();
}
}结果:
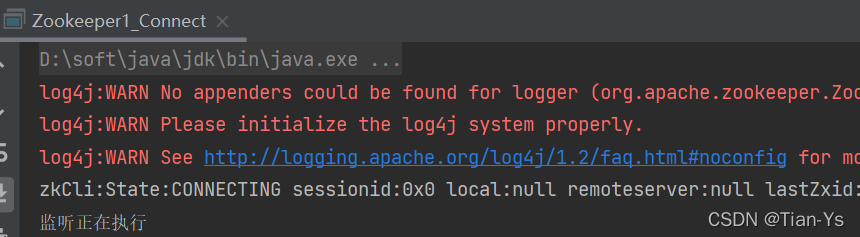
结果表明输出的第一行表示zkCli当前的状态
第二行表示process被执行了一次
创建普通节点:
在IDEA中创建一个普通的节点:
import org.apache.zookeeper.*;
public class Zookeeper2_Create {
public static void main(String[] args) throws Exception{
// 设置所连接的主机名与端口号
String connectString="master:2181,node1:2181,node2:2181";
// 设置超时时间为10秒
int sessionTimeout = 10 * 1000;
// 监听器是一个接口,需要有具体实现
// 创建连接,传入以上参数
ZooKeeper zkCli = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("监听正在执行");
}
});
/**
* String create(final String path, byte data[], List<ACL> acl,
* CreateMode createMode)
* path:所要创建的节点路径
* byte data[]:节点中的值
* List<ACL> acl:身份认证,可调用zookeeper中的枚举
* ZooDefs.Ids.OPEN_ACL_UNSAFE
* CreateMode.PERSISTENT 是指一个普通节点
* PERSISTENT_SEQUENTIAL 是序列化的持久化节点
* EPHEMERAL 表示临时节点
* EPHEMERAL_SEQUENTIAL 表示临时序列化节点
*/
// 设置所要创建的节点名称和路径
String path="/hadoop";
// 创建普通节点:
zkCli.create(path, "this is hadoop".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// Thread.sleep(Long.MAX_VALUE);
zkCli.close();
}
}
结果:
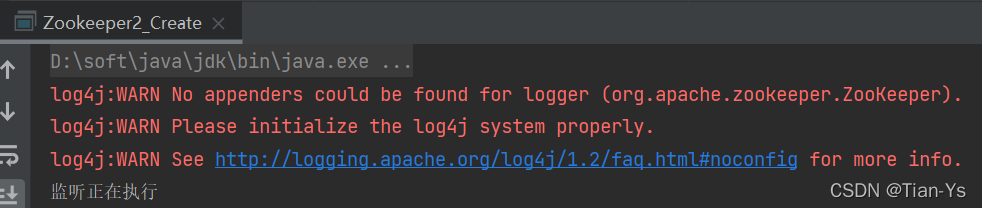

也可以通过其他命令创建不同的节点,比如临时节点和序列化节点
在创建临时节点时,由于临时节点是客户端关闭就会消失,在IDEA中连接被关闭后,该节点就会自动消失,此时为了防止他一创建就立马消失,可以添加一个睡眠时间
// 创建临时节点
zkCli.create("/hadoop/application","this is application".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);
// 加入睡眠时间防止其直接执行关闭操作导致节点直接消失
Thread.sleep(Long.MAX_VALUE);
zkCli.close();
}结果:

手动停止执行后会消失
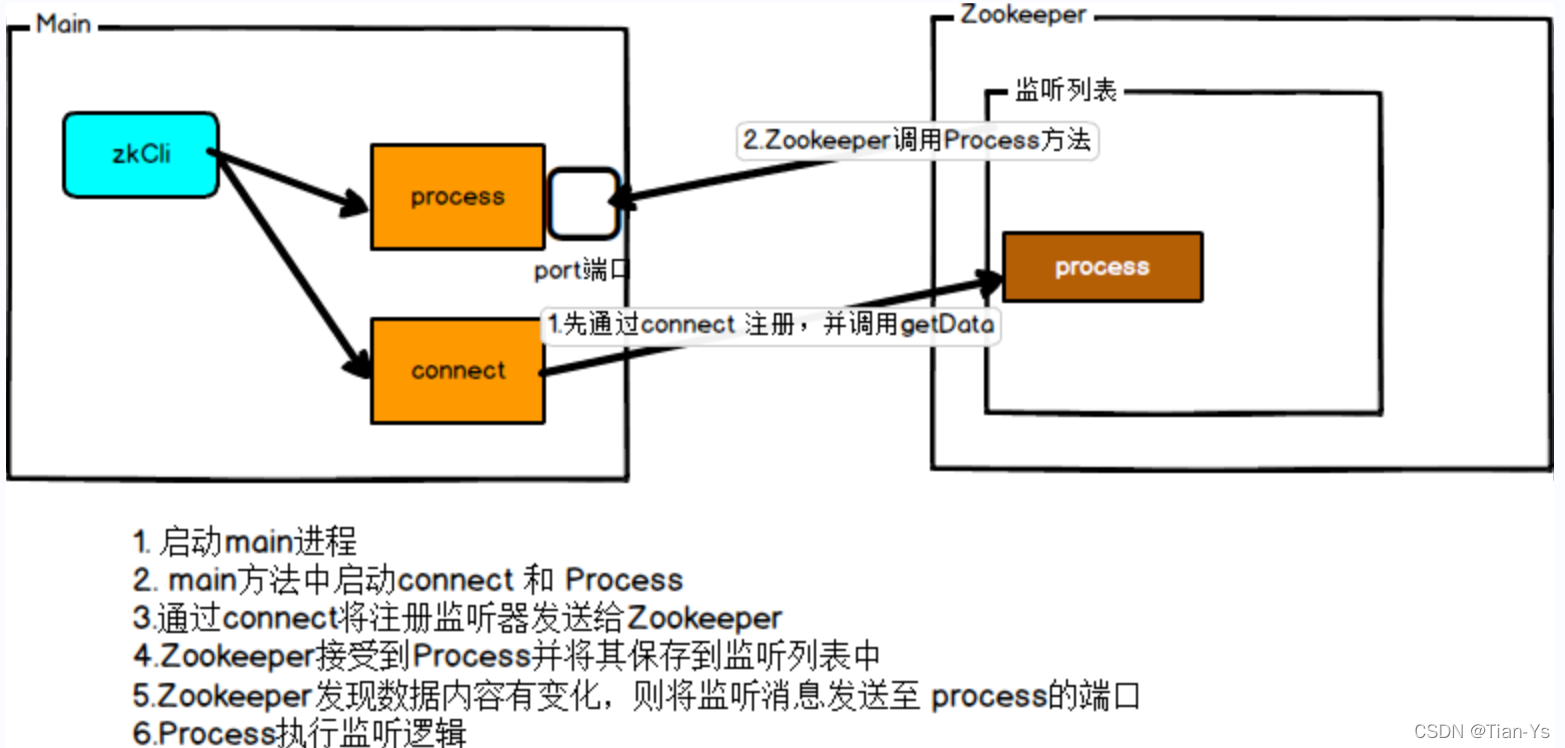
监听原理
监听原理如图:
选举机制
在Zookeeper搭建完毕并启动后,在各虚拟机上输入命令:
zkServer.sh status查看当前状态会发现node1虚拟机状态为leader,其他两台为follower,这是因为虚拟机之间存在选举机制导致的。
Zookeeper选举机制:当前节点的选票大于总节点数的一半时该节点被选举为leader
选举机制图示:

HA的搭建
注意: 操作前需要保存一下之前的快照
1、关闭防火墙
systemctl status firewalld 查看防火墙状态
若状态没有关闭,则关闭防火墙
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 禁用防火墙开机自启动
2、时间同步
一般情况下会自动同步,无需操作
date查看当前时间
3、免密钥 (远程执行命令)
在节点生成密钥文件
ssh-keygen -t rsa
ssh-copy-id ip
master-->master,node1,node2
node1-->master,node1,node2
注意:
需要保证hdfs相关的组件被关闭 在master节点执行 stop-dfs.sh
4、修改hadoop配置文件
进入到/usr/local/soft/hadoop-2.7.6/etc/hadoopz中修改以下两个文件中的内容:
core-site.xml中修改为:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
</configuration>
hdfs-site.xml中修改为:
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/datanode</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //以下为HDFS HA的配置// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 指定cluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node1:8020</value>
</property>
<!-- 配置nn1,nn2的http通信端口 -->
<property>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node1:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485/cluster</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/journal</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
同步到其它节点
首先进入到Hadoop目录下:cd /usr/local/soft/hadoop-2.7.6/etc/hadoop
分别执行以下命令:将两个文件分发到其他两台虚拟机中
scp hdfs-site.xml root@node1:`pwd`
scp hdfs-site.xml root@node2:`pwd`
scp core-site.xml root@node1:`pwd`
scp core-site.xml root@node2:`pwd`
5、删除hadoop数据存储目录下的文件 每个节点都需要删除 rm -rf /usr/local/soft/hadoop-2.7.6/tmp
6、启动zookeeper 三台都需要启动
zkServer.sh start
zkServer.sh status
7、启动JN 存储hdfs元数据
三台JN上执行 启动命令:
hadoop-daemon.sh start journalnode
8、格式化 在一台NN上执行(在master上执行)
hdfs namenode -format
启动当前的NN
hadoop-daemon.sh start namenode
9、执行同步 没有格式化的NN上执行 在另外一个namenode上面执行(在node1上执行)
hdfs namenode -bootstrapStandby
10、格式化ZK 在已经启动的namenode上面执行(在master上执行)
!!一定要先 把zk集群正常 启动起来
hdfs zkfc -formatZK
11、启动hdfs集群,在启动了namenode的节点上执行
start-dfs.sh
stop-dfs.sh
进入浏览器中分别输入master:50070和node1:50070,会在master:8020后出现active,node1:8020后出现standby
当杀死master的namenode节点后,node1节点自动变为active,且此时master界面刷新后无法连接
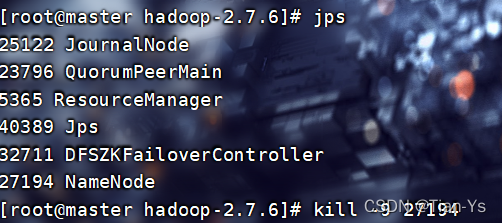
浏览器中:
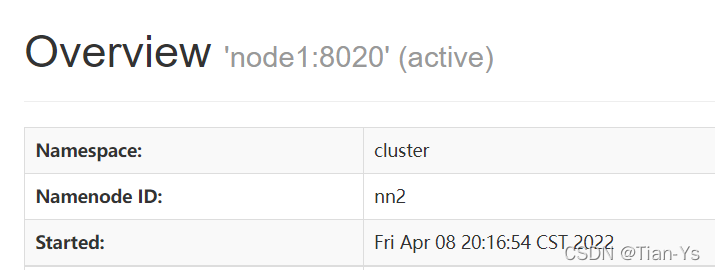
此时再次启动namenode,namenode会自动变为standby:
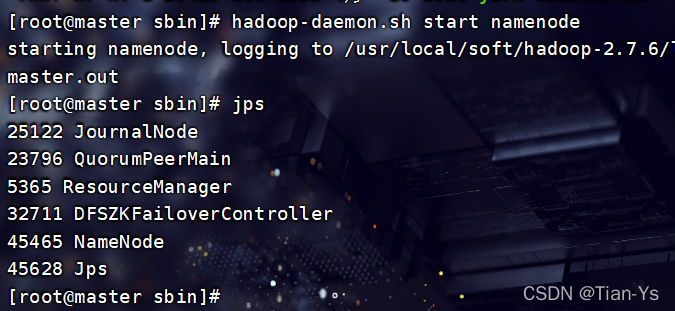
进入浏览器中查看:
yarn 高可用
1、修改配置文件
yarn-site.xml
mapred-site.xml
同步到所有节点
2、启动yarn 在master启动
start-yarn.sh
3、在另外一台主节点上启动RM(在node1上执行)
yarn-daemon.sh start resourcemanager
执行完以上命令,使用jps命令查看进程,可以看到三个节点共16个进程
此时,可以在master上进入zookeeper查看一下:
zkCli.sh
ls /
在浏览器上分别输入以下内容来访问HDFS
master:8088
node1:8088
关闭:直接关闭所有的集群
stop-dfs.sh
zkServer.sh stop
stop-yarn.sh
MapReduce框架
概述:
在MapReduce中的数据类型同Java不同,Java中的int类型为在MapReduce中被封装成了intWritable,byte封装成了byteWritable,特殊的,String类型为Text等。
MapReduce样例图:
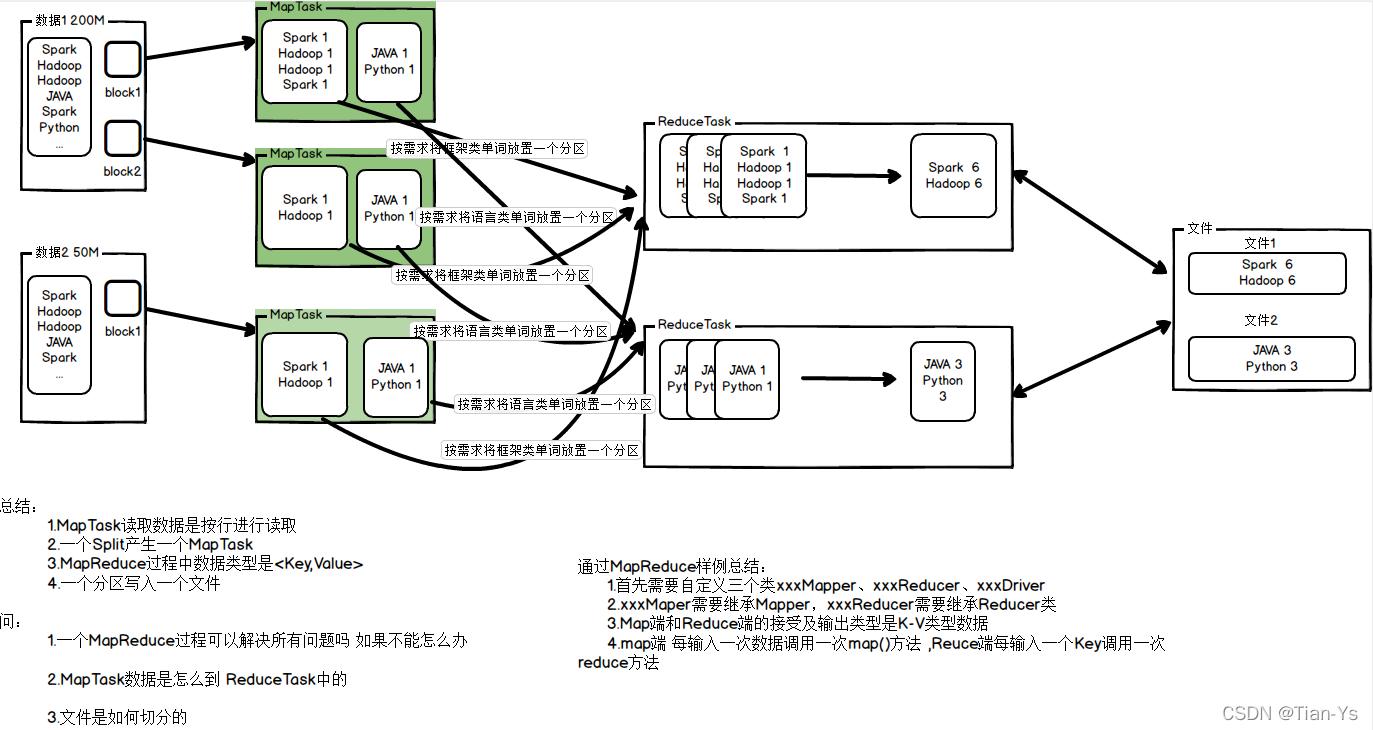
流程:
读取到两个数据,数据1大小为200M,数据2大小为50M,根据数据大小切分文件块,由于一个文件块的大小最大为128M,所以数据1切分为两个block块,数据2切分一个block块
一个block块生成一个MapTask任务,MapTask中对数据进行数据切分,切分为kv数据对,对数据进行分区进入到不同的ReduceTask中进行处理
ReduceTask中对分区的数据进行计算统计之后,进行一个汇总,将汇总结果输出到文件中。
总结:
1、MapTask读取数据时按行进行读取
2、一个Split切片产生一个Maptask
3、MapReduce过程中数据类型是<Key,Value>
4、一个分区写入一个文件
实现wordCount样例
之前在测试Hadoop样例时使用的时是wordcount样例,wordcount实际上是jar包中的一个类
wordcount中实现了该mapreduce样例过程
实现内容
使用IDEA演示wordcount实例,从map端到reduce端以及输出到文件中的处理过程:
Map端:
//Map端切分数据
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordMapper extends Mapper<LongWritable, Text, Text,IntWritable> {
// 实现Map端需要继承Mapper类,重写其中的map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 读取的文件中含有空格,以空格切分数据
String[] words = value.toString().split(" ");
// 遍历获取每一个数据,将数据以kv对的形式写入到ReduceTask中
for (String word : words) {
context.write(new Text(word),new IntWritable(1));
}
}
}参数解释:
LongWritable:对应Java中的long,表示的值为数据读取的偏移量
Text:表示读取的文件中的一行数据,对应Java中的String
Text:输出到MapTask中的key值的类型
IntWritable:输出到MapTask中的value值的类型,对应java中的int
这里注意:在写参数Text时,所导入的包应该是hadoop.io中的Text,其他包中的Text无法识别;在重写map方法时,不需要使用其父类的map方法,自己自定义逻辑重写map方法
Reduce端:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//用于统计map端传过来的数据,对数据进行统计计算并划分
public class WordReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 定义一个变量用于统计数据的个数
int count=0;
// 对每个key中的value值进行迭代遍历,当key相同时,将count值加上value值
for (IntWritable value : values) {
count+=value.get();
}
// 将结果写出到文件
context.write(key,new IntWritable(count));
}
}
参数解释:
reducer的四个参数:
Text:MapTask中的key,即mapper传来的Key值
IntWritable:MapTask中的value,即mapper端传出来的key对应的value的集合
context:整个mapreduce中的操作对象
由于value的值时IntWritable类型值,无法直接取出为int类型值,所以需要使用get方法取出其int类型的值
这里在写出到文件的时候,没有指定输出文件的路径,且没有指定输入文件的路径,且在wordcount源码中需要有一个job,进行任务提交,提交之后才可以生效map端和reduce端对数据的操作。
创建一个提交任务类,去进行设置输入输出路径以及任务的提交
wordDriver类:
//用于提交map和reduce所处理的任务使其生效
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordDriver{
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 获取配置文件
Configuration conf = new Configuration();
// 获取job的实例对象
Job job = Job.getInstance(conf);
// 设置驱动的类,表示该类为主入口
job.setJarByClass(WordDriver.class);
// 设置具体实现类,使其能成功识别
job.setMapperClass(WordMapper.class);
job.setReducerClass(WordReducer.class);
// 设置mapper端出入口和reduce端出入口类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// Reduce端
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job,"D:\\IdeaProjects\\HadoopCode\\input\\wordcount.txt");
FileOutputFormat.setOutputPath(job,new Path("D:\\IdeaProjects\\HadoopCode\\output"));
// job提交
// waitForCompletion:用于提交任务且等待其完成
boolean res = job.waitForCompletion(true);
}
}这其中有各种设置,均是为了使该任务在提交时能够成功识别到map端的类与reduce端的类从而调用其中的方法进行操作,并设置该类为提交任务主入口。
提交任务时调用了waitForCompletion方法,该方法返回值为boolean类型,表示若提交成功,返回true,所传入的参数表示是否将该进程输出到用户。
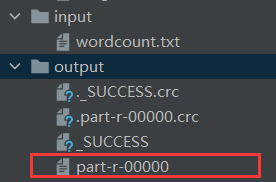
运行该类结果:

在输出目录output下查看:
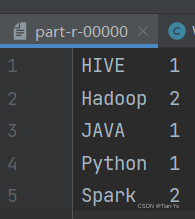
查看该文件内容:
运行报错:
这里在运行Driver类时可能会报错:
IOException:(null) entry in command string: null chmod 0700 D:\tmp\hadoop-user\mapre
原因:这是没有配置Hadoop本地运行环境所导致的问题
解决办法:
1、将Hadoop压缩包解压到指定路径:本机选择路径为D:\soft\Hadoop3.1.0\hadoop-3.1.0
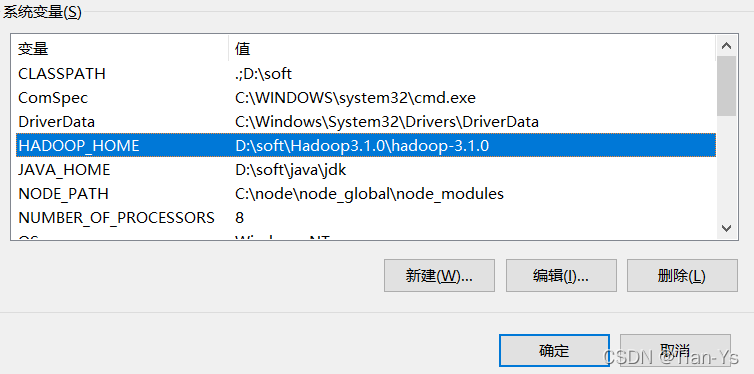
2、右击电脑-->属性-->高级系统设置-->环境变量,在系统变量中添加Hadoop环境变量,变量名为HADOOP_HOME,变量值为所解压的Hadoop的根目录路径
3、找到系统变量path,向其中添加一行:%HADOOP_HOME/bin,点击确定使其生效
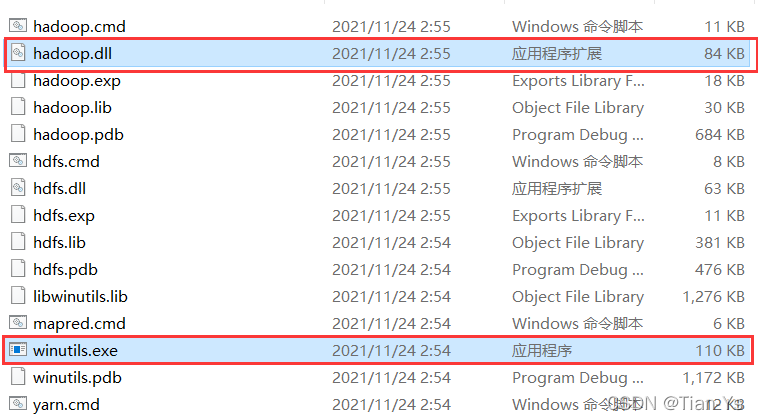
4、进入到Windows下的Hadoop目录中的bin目录中,将其中的hadoop.dll文件和winutils.exe文件复制到C:\Windows\System32目录下
5、重启电脑使其配置生效,重启后再次运行即可。