1. 实现通用打印泛型类,可以打印各个集合中的值,方便调试。
PrintCollection是一个泛型方法,它接受实现了IEnumerable<T>接口的任何集合,并遍历打印出每个元素。using System; using System.Collections; using System.Collections.Generic; public static class PrintHelper { public static void PrintCollection<T>(IEnumerable<T> collection) { if (collection == null) { Console.WriteLine("Collection is null."); return; } Console.WriteLine($"Collection of type {typeof(T).Name} contains:"); foreach (var item in collection) { Console.WriteLine(item); } } } class Program { static void Main() { List<int> numbers = new List<int> { 1, 2, 3, 4, 5 }; List<string> words = new List<string> { "Hello", "World", "C#" }; PrintHelper.PrintCollection(numbers); PrintHelper.PrintCollection(words); } }
拓:ICollection<T>和IEnumerable<T>在C#中都是非常重要的泛型接口,上述代码中IEnumerable<T>也可以用ICollection<T>替换
ICollection<T>:这同样是一个泛型接口,也定义在
System.Collections.Generic命名空间中。ICollection<T>不仅继承了IEnumerable<T>接口,还继承了非泛型的IEnumerable接口。因此,ICollection<T>不仅具备枚举集合的能力,还提供了一系列用于操作集合的方法,如添加、删除元素,以及获取集合中元素的数量等。这使得ICollection<T>比IEnumerable<T>在功能上更加强大。虽然从功能上来看,
ICollection<T>比IEnumerable<T>更加强大,但在某些情况下,使用IEnumerable<T>可能会带来更好的性能。这是因为IEnumerable<T>表示一种“延迟执行”的集合,即在调用GetEnumerator()或在foreach循环中迭代之前,不会执行任何实际的集合操作或数据检索。这种延迟执行的行为可以显著提高性能,特别是在处理大型数据集或复杂查询时。然而,这也意味着在需要多次迭代集合或对集合进行修改时,使用ICollection<T>可能更为直接和高效。
2. 计算遍历目录的耗时。
使用
System.Diagnostics.Stopwatch类。这个类提供了简单的方法来测量运行时的性能
Directory.GetDirectories(directorypath)获取路径path下的所有子目录,并通过foreach循环遍历这些子目录。对于每个子目录,都调用TraverseDirectory方法来递归地遍历它。在字符串字面量前加上
@符号,如@"C:\Users\曹鑫蕊\Pictures",可以告诉编译器这是一个原始字符串,其中的反斜杠不会被当作转义字符处理。using System; using System.IO; using System.Diagnostics; class Program { static void Main() { // 指定要遍历的目录 string directoryPath = @"C:\Users\曹鑫蕊\Pictures"; // 创建Stopwatch实例 Stopwatch stopwatch = Stopwatch.StartNew(); // 遍历目录 TraverseDirectory(directoryPath); // 停止计时 stopwatch.Stop(); // 输出耗时 Console.WriteLine($"遍历目录耗时: {stopwatch.ElapsedMilliseconds} 毫秒"); } static void TraverseDirectory(string path) { // 打印当前遍历的目录名字 Console.WriteLine(path); // 遍历目录及其所有子目录 foreach (string directory in Directory.GetDirectories(path)) { TraverseDirectory(directory); } } }
注:如果目录中包含大量的子目录或文件,递归遍历可能会很慢,甚至导致堆栈溢出。所以我们有又使用了一个栈来存储待遍历的目录。
开始时,我们将起始目录推入栈中。然后,我们进入一个循环,在循环中我们弹出栈顶的目录,处理它(打印它的名称),并将它的所有子目录推入栈中。这个过程会一直重复,直到栈为空,即所有目录都已经被遍历过。
try-catch语句被用于异常处理。当你预见到代码块可能会抛出异常时,你可以将该代码块置于try部分,并在catch部分捕获并处理这些异常,本代码也可以不用。
Message是Exception类的一个内置属性,本代码可以通过ex.Message访问到异常的消息,而无需进行任何额外的声明。using System; using System.IO; using System.Collections.Generic; using System.Diagnostics; class Program { static void Main() { // 指定要遍历的目录 string directoryPath = @"C:\Users\曹鑫蕊\Pictures"; // 使用栈来存储待遍历的目录 Stack<string> stack = new Stack<string>(); stack.Push(directoryPath); Stopwatch sw = new Stopwatch(); sw.Start(); // 遍历目录 while (stack.Count > 0) { string currentDirectory = stack.Pop(); try { // 在这里处理当前目录,例如打印目录名 Console.WriteLine(currentDirectory); // 获取当前目录下的所有子目录,并将它们推入栈中 foreach (string directory in Directory.GetDirectories(currentDirectory)) { stack.Push(directory); } } catch (Exception ex) { // 处理异常,例如访问被拒绝 Console.WriteLine($"无法访问目录 {currentDirectory}: {ex.Message}"); } } sw.Stop(); Console.WriteLine($"遍历目录耗时: {sw.ElapsedMilliseconds} 毫秒"); } }它不会导致堆栈溢出,因为.NET的栈大小是有限的,而递归调用可能会消耗大量的栈空间。使用非递归方法,我们可以避免这个问题,并且可以更灵活地控制遍历过程。
3. 有哪些算术运算符,有哪些关系运算符,有哪些逻辑运算符,有哪些位运算符,有哪些赋值运算符。
运算符类型 运算符 示例 算术运算符 +(加) int a = 5; int b = 3; int sum = a + b; // 结果为8-(减) int difference = a - b; // 结果为2*(乘) int product = a * b; // 结果为15/(除) double division = (double)a / b; // 结果为1.6666666666666667%(取模) int remainder = a % b; // 结果为2++(自增) int count = 0; count++; // 结果为1或int count = 0; ++count; // 结果也为1--(自减) int count = 5; count--; // 结果为4或int count = 5; --count; // 结果也为4关系运算符 ==(等于) int x = 5; int y = 5; bool isEqual = (x == y); // 结果为true!=(不等于) bool isNotEqual = (x != y); // 结果为false<(小于) bool isLessThan = (x < y); // 结果为false>(大于) bool isGreaterThan = (x > y); // 结果为false<=(小于等于) bool isLessThanOrEqual = (x <= y); // 结果为true>=(大于等于) bool isGreaterThanOrEqual = (x >= y); // 结果为true逻辑运算符 &&(逻辑与) bool result = true && false; // 结果为false||(逻辑或) bool result = true || false; // 结果为true!(逻辑非) bool result = !true; // 结果为false位运算符 &(按位与) int a = 60; // 0011 1100 int b = 13; // 0000 1101 int c = a & b; // 0000 1100|(按位或) int c = a | b; // 0011 1101^(按位异或) int c = a ^ b; // 0011 0001~(按位取反) int c = ~a; // 对a的每一位取反<<(左移) int c = a << 2; // 将a的二进制表示向左移动2位>>(右移) int c = a >> 2; // 将a的二进制表示向右移动2位赋值运算符 =(简单赋值) int a = 5;+=(复合赋值) a += 3; // 等同于 a = a + 3;-=, *=, /=, %=(其他复合赋值) a -= 2; // 等同于 a = a - 2;等&=, |=, ^=, <<=, >>=(位赋值) a &= b; // 等同于 a = a & b;等
注:
&(按位与):对于每一位,只有两个操作数都是1时,结果才是1,否则是0。int a = 60; // 0011 1100 int b = 13; // 0000 1101 int c = a & b; // 0000 1100,即 c = 12
|(按位或):对于每一位,只要有一个操作数是1,结果就是1。int a = 60; // 0011 1100 int b = 13; // 0000 1101 int c = a | b; // 0011 1101,即 c = 61
^(按位异或):对于每一位,如果两个操作数不同,则结果是1;如果相同,则结果是0。int a = 60; // 0011 1100 int b = 13; // 0000 1101 int c = a ^ b; // 0011 0001,即 c = 49
4. 三目表达式举例
三目表达式,通常也被称为三元运算符(Ternary Operator),在C#中三元运算符包含三个操作数,并且通常用于基于布尔表达式的结果选择两个值中的一个。
三元运算符的一般形式是:
条件 ? 表达式1 : 表达式2;如果条件为真(
true),则计算并返回表达式1的结果;如果条件为假(false),则计算并返回表达式2的结果。在这个例子中,
a > b是条件,a是表达式1,b是表达式2。因为a不大于b,所以条件为假,因此max被赋值为b的值,即10。int a = 5; int b = 10; int max = a > b ? a : b; Console.WriteLine(max); // 输出:10与if-else语句相比
1. 语法结构
- 三目表达式:具有简洁的语法结构,形式为“条件 ? 表达式1 : 表达式2”。如果条件为真,则计算并返回表达式1的结果;如果条件为假,则计算并返回表达式2的结果。
- if-else语句:语法结构相对复杂,包含明确的条件判断块和执行块。基本形式为“if (条件) {执行块1} else {执行块2}”。如果条件为真,则执行块1的代码被执行;如果条件为假,则执行块2的代码被执行。
2. 返回值
- 三目表达式:必须有一个返回值。无论条件真假,三目表达式都会计算并返回一个值。
- if-else语句:不一定有返回值。if-else语句主要用于控制程序的流程,其内部可以执行任何操作,包括没有返回值的操作。
3. 使用场景
- 三目表达式:适用于简单的条件判断,特别是在需要基于条件选择两个值之一时。由于其简洁性,它通常用于赋值操作或作为更大表达式的一部分。
- if-else语句:适用于更复杂的条件判断逻辑,包括需要执行多个操作或嵌套条件判断的情况。if-else语句提供了更大的灵活性和可读性。
4. 性能
- 关于三目表达式和if-else语句的性能差异,一般来说,在大多数现代编译器和解释器中,两者在性能上的差距非常微小,甚至可以忽略不计。这是因为编译器通常会对代码进行优化,以减少执行时的开销。然而,在某些特定情况下(如大量使用且条件判断较为简单时),三目表达式可能由于其简洁性而略微优于if-else语句,但这种差异通常不足以成为选择使用哪种结构的决定性因素。
5. 可读性和维护性
- 可读性:三目表达式由于其简洁性,在单行或简单条件判断时可能更容易阅读。然而,对于更复杂的条件逻辑,if-else语句通常提供了更好的可读性。
- 维护性:随着代码库的增长和条件的复杂化,if-else语句通常更容易维护和扩展。它允许开发者添加更多的条件分支、注释和文档,以提高代码的可维护性。
5. 优先级口诀:有括号先括号,后乘除再加减,然后位移再关系,逻辑完后再条件。
有括号先括号:
这意味着在计算表达式时,应首先计算括号内的内容。括号用于改变运算的默认优先级。后乘除再加减:
这表示在没有括号的情况下,应首先执行乘法和除法运算,然后再执行加法和减法运算。然后位移再关系:
在编程中,位移运算符(如左移<<和右移>>)的优先级高于关系运算符(如等于==、不等于!=、大于>、小于<等)。逻辑完后再条件:
逻辑运算符(如逻辑与&&、逻辑或||、逻辑非!)的优先级高于条件运算符(如三元运算符?:)。目录
1. 实现通用打印泛型类,可以打印各个集合中的值,方便调试。
3. 有哪些算术运算符,有哪些关系运算符,有哪些逻辑运算符,有哪些位运算符,有哪些赋值运算符。
5. 优先级口诀:有括号先括号,后乘除再加减,然后位移再关系,逻辑完后再条件。
6. 写个例子展示break、continue、ruturn的区别
6. 写个例子展示break、continue、ruturn的区别
6.1
break作用:
break用于完全结束一个循环,跳出循环体,不再执行循环体中剩余的代码。- 当
break出现在嵌套循环中的内循环时,它仅终止内循环的执行,对外层循环不产生影响。但可以通过给外层循环设置标签,并在内循环中使用带标签的break语句来跳出多层循环。
6.2continue作用:
continue用于跳过当前循环的剩余语句,直接进入下一次循环的条件判断。- 它不会结束循环,只是忽略当前循环的剩余部分,继续执行下一次循环。
6.3return作用:
return用于结束函数的执行,并可选择性地返回一个值给调用者。- 当
return语句在函数体内执行时,该函数将立即结束,并将控制权返回给调用者。如果return语句带有参数,则将该参数的值返回给调用者。return结束的是整个函数的执行,而不仅仅是循环。总结
- 结束对象不同:
break结束的是循环,continue结束的是循环中的某一次迭代,而return结束的是整个函数。- 使用场景不同:
break和continue通常用于循环结构中,而return用于函数或方法中。- 返回值:
break和continue不返回值,而return可以返回一个值给调用者。
using System; class Program { static void Main() { for (int i = 1; i <= 10; i++) { if (i == 5) { Console.WriteLine("找到数字5,即将退出循环。"); break; // 当找到数字5时,退出循环 } if (i % 2 == 0) { Console.WriteLine("跳过偶数: " + i); continue; // 跳过偶数,继续下一次循环 } Console.WriteLine("当前数字: " + i); // 假设我们在找到数字7时就完成了任务 if (i == 7) { Console.WriteLine("找到数字7,即将返回。"); return; // 结束方法的执行,并退出 } } Console.WriteLine("循环结束,但未找到目标数字7(。"); // 注意:这行代码实际上在找到数字7时是不会执行的,因为return语句已经结束了方法的执行。 } }这个代码中
break关键字用于在找到数字5时退出循环。
continue关键字用于跳过偶数,不执行循环中剩余的代码,而是继续下一次循环。
return关键字用于在找到数字7时结束Mian方法的执行,并立即退出该方法。注意,这时
break关键字用于在找到数字5,找到5后break用于完全结束一个循环,跳出循环体,不再执行循环体中剩余的代码,但还会运行后面的代码(即“循环结束,但未找到目标数字7。”)结果如下图:
若将break前的i改为9,则会执行return,
return结束的是整个函数的执行,而不仅仅是循环。由于
return语句的存在,循环后面的代码(即“循环结束,但未找到目标数字7。”)实际上是不会执行的。结果图如下:


7. 写个冒泡排序
BubbleSort方法实现了一个带有排序完成提前跳出的冒泡排序算法。它使用了一个布尔变量swapped来跟踪在每一轮排序过程中是否发生了交换。如果在某一轮排序中没有发生任何交换,那么说明数组已经是有序的,因此可以提前结束排序过程。using System; class Program { static void Main(string[] args) { int[] arr = { 5, 1, 4, 2, 8 }; BubbleSort(arr); Console.WriteLine("Sorted array:"); foreach (int i in arr) { Console.Write(i + " "); } Console.ReadKey(); } // 带有排序完成提前跳出的冒泡排序方法 static void BubbleSort(int[] arr) { int n = arr.Length; bool swapped; for (int i = 0; i < n - 1; i++) { swapped = false; for (int j = 0; j < n - i - 1; j++) { if (arr[j] > arr[j + 1]) { // 交换arr[j]和arr[j + 1] int temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; swapped = true; } } // 如果在这一轮中没有发生交换,说明数组已经有序,可以提前结束排序 if (!swapped) break; } } }
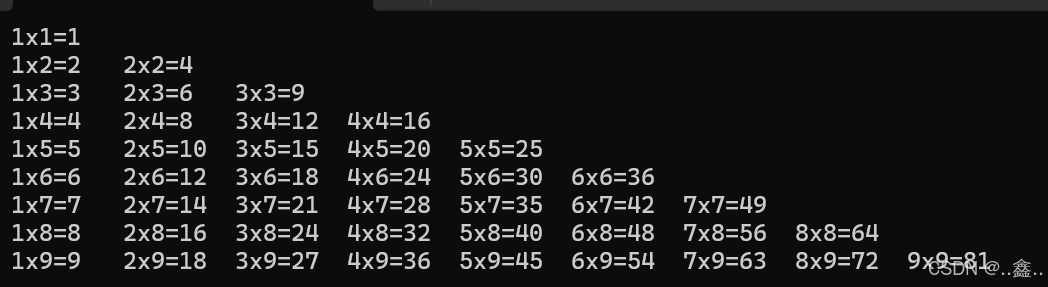
8. 写个九九乘法表
定义了一个
PrintMultiplicationTable方法,该方法使用两个嵌套的for循环来遍历1到9之间的所有数字,并打印出它们之间的乘法关系。外层循环控制行,内层循环控制列,确保乘法表的左侧对齐。Console.Write用于在同一行中打印乘法表达式,而Console.WriteLine则用于在每打印完一行后换行。using System; class Program { static void Main(string[] args) { PrintMultiplicationTable(); } static void PrintMultiplicationTable() { for (int i = 1; i <= 9; i++) { for (int j = 1; j <= i; j++) { Console.Write($"{j}x{i}={j * i}\t"); // 使用制表符分隔每个乘法表达式 } Console.WriteLine(); // 每打印完一行后换行 } } }结果如图:
9. 实现文件找不到抛出异常
当尝试访问或操作一个不存在的文件时,通常会遇到
FileNotFoundException或DirectoryNotFoundException异常。这些异常属于System.IO命名空间,我使用了try-catch块来捕获这些异常。
FileNotFoundException:
这个异常通常发生在尝试访问一个不存在的文件时。例如,如果您尝试使用
File.ReadAllText方法读取一个不存在的文件,就会抛出这个异常。DirectoryNotFoundException:
这个异常发生在尝试访问一个不存在的目录时。例如,如果您尝试使用
Directory.GetFiles方法获取一个不存在目录中的文件列表,就会抛出这个异常。using System; using System.IO; class Program { static void Main() { string filePath = @"D:\cxr"; try { // 尝试读取文件 string fileContent = File.ReadAllText(filePath); Console.WriteLine("文件内容:"); Console.WriteLine(fileContent); } catch (FileNotFoundException) { // 当文件不存在时捕获异常 Console.WriteLine("未找到文件。"); } catch (Exception ex) { // 捕获其他所有可能的异常 Console.WriteLine($"发生了一个异常:{ex.Message}"); } } }因为我的代码中,
File.ReadAllText是用于读取文件的,它期望路径指向一个文件,而不是一个目录。因此,当它无法找到该文件时(无论是因为文件不存在还是因为其所在的目录不存在),它都会抛出FileNotFoundException,所以当我的目录不存在时也会输出“未找到文件”
(异常信息“发生了一个异常:Access to the path 'D:' is denied.”时,这表示您的程序试图访问
D:\这个路径,但是没有足够的权限。)

补充:Exception类包含了一些重要的属性和方法,用于获取关于异常的信息和进行异常处理。其中一些重要的属性和方法包括:
Message:一个字符串,包含关于异常的简短描述。StackTrace:一个字符串,包含异常发生时的堆栈跟踪信息,这对于调试程序非常有用。InnerException:一个Exception对象,包含导致当前异常发生的内部异常(如果有的话)。这对于理解异常的根本原因非常有帮助。GetType():一个方法,返回当前异常的Type对象,这对于确定异常的具体类型非常有用。