目录
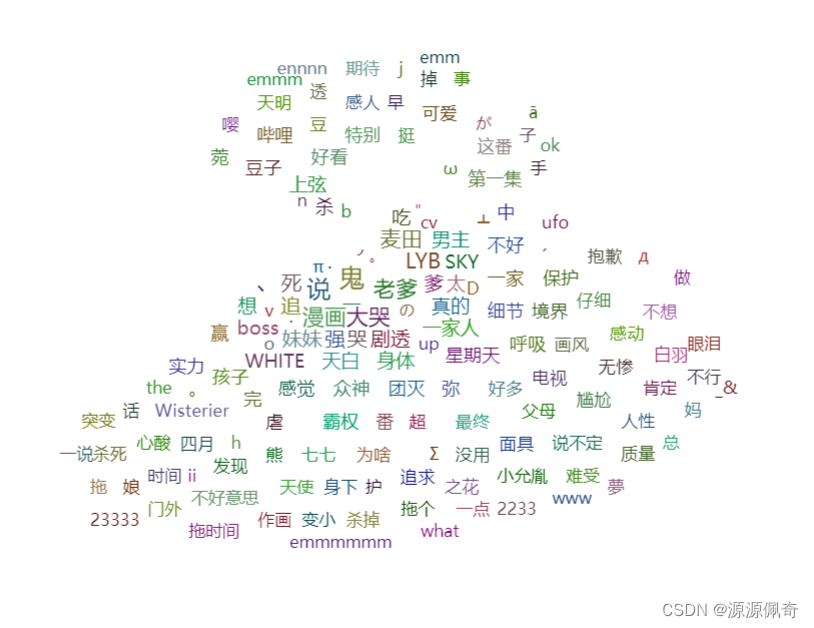
先来看看结果
第一步:分析网页
不管是什么样的爬虫项目,第一步要做的就是分析网页结构,以及数据来源,和数据结构。只有当你了解后,你才能知道你的代码具体该怎么去写。
这里我就部多说了,以前的文章里面有讲过:python 爬虫爬取疫情数据,爬虫思路和技术你全都有哈(一)_源源佩奇的博客-CSDN博客
我就直接说了,这是一个动态加载的数据,并且数据结构是json格式
第二步:了解json数据
找到你想要爬取视频评论的链接
嗯....嗯
就用鬼灭的吧
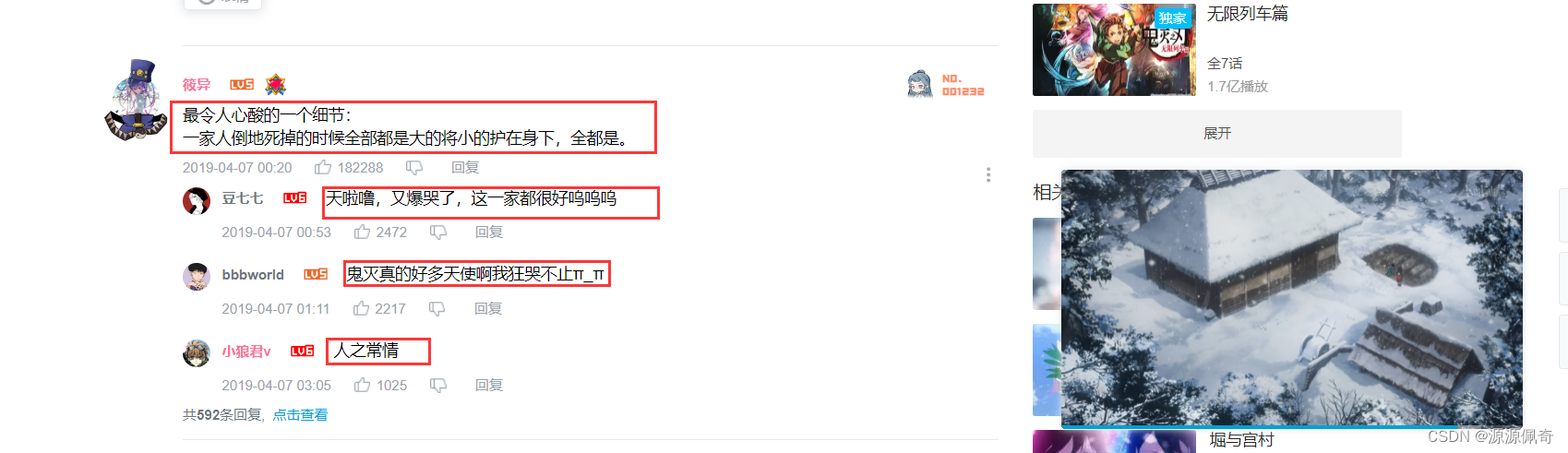
这些红色框框里的数据就是我们想要的
按 F12 键,打开开发工具,然后刷新一下页面
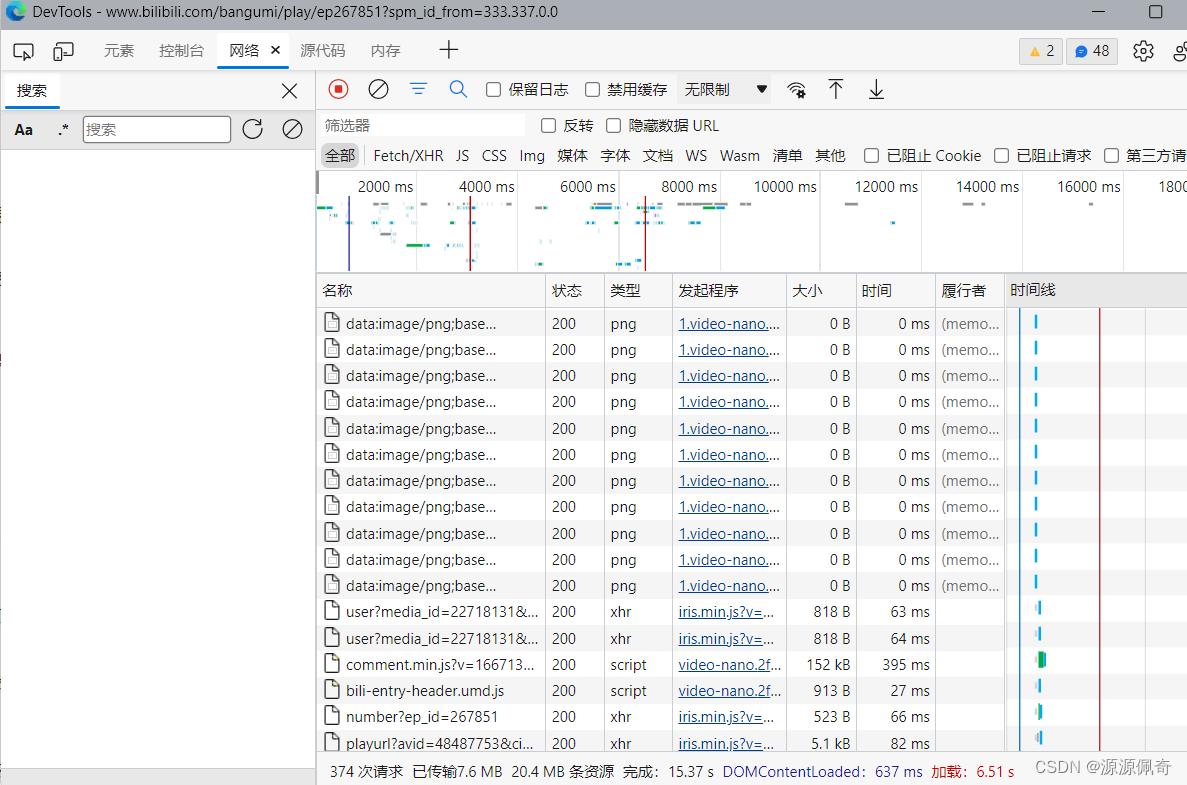
你就会得到这些数据包,在这些数据包里面就有需要我们的数据,我们只需要
复制一条评论的内容
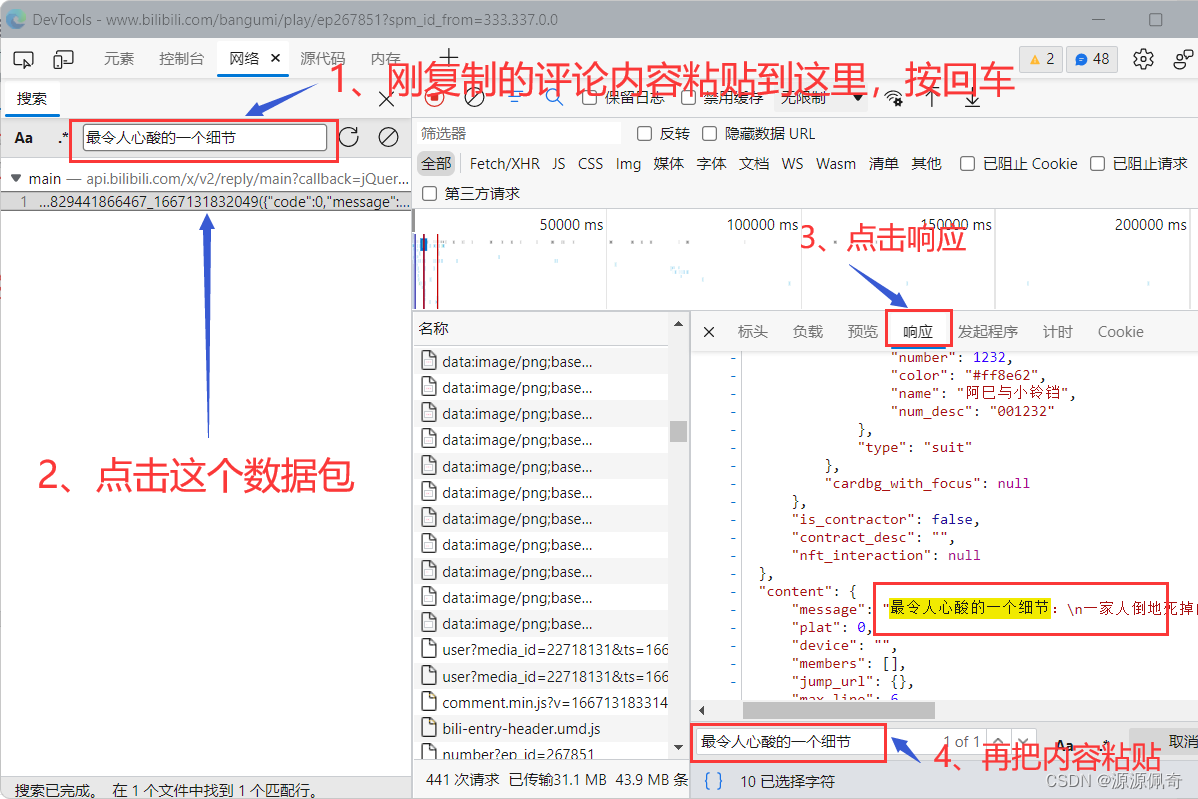
这样操作就成功找到我们想要的评论数据了。
点击标头,把url 复制下来
在浏览器重新打开这个url

出现了这个页面,是因为在这段url里面,有些参数是不需要的,所以没有请求到真正的数据。
一个一个参数删掉进行测试
删掉这个参数:callback=jQuery172014925829441866467_1667131832049&
把这个删掉之后再进行请求,就能得到我们想要的数据了
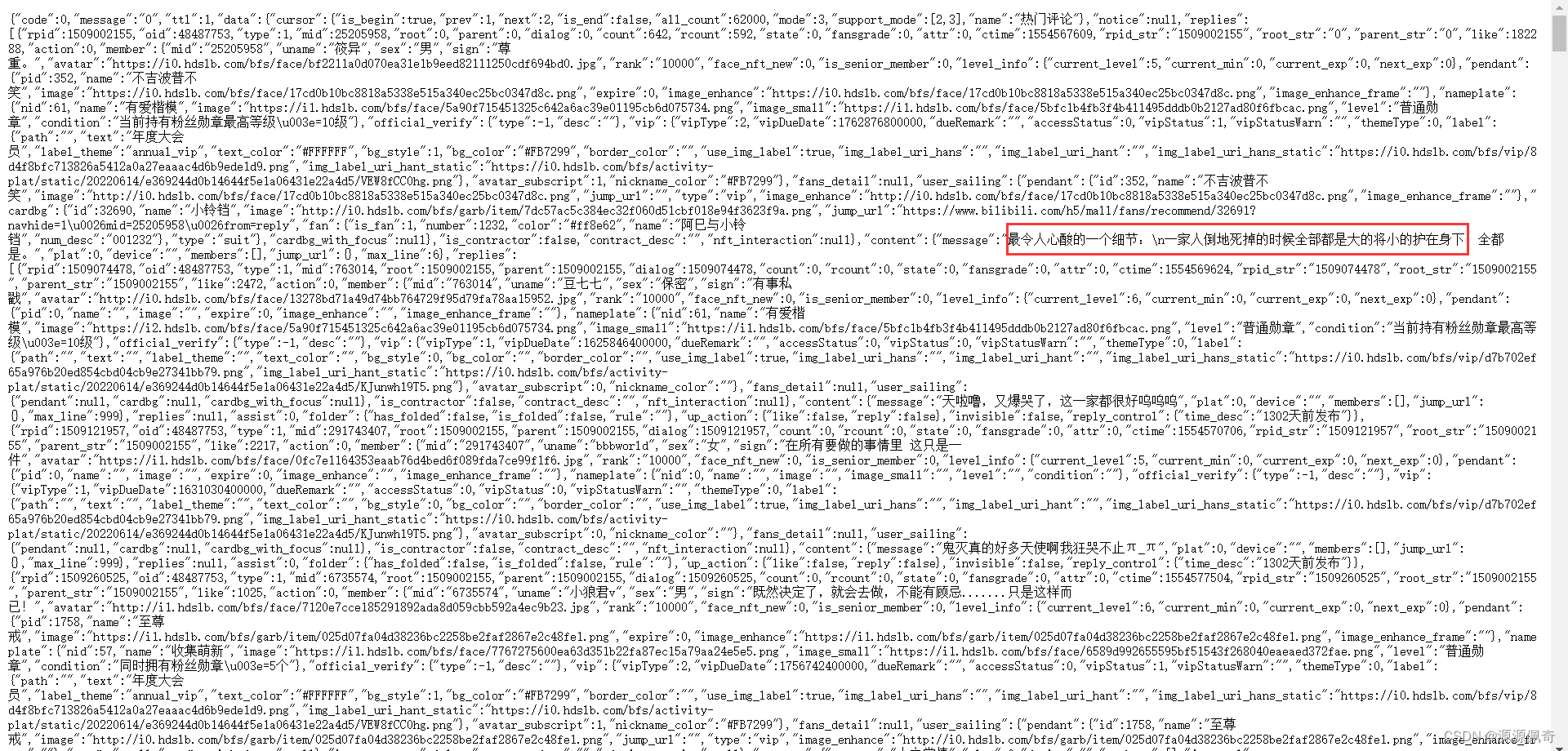
这么看着很乱,结构一点也看不清,复制内容,创建一个json文件,用pycharm打开
打开后,按ctrl + ail + l,格式化文档
结果如下:

我们所需要的数据就是再 data 下的 replies 里面,我们需要:
rpid(评论id),
rcount(页数),
content下的message(评论内容)
数据得到了,就开始写代码了。
第三步:请求和数据清洗代码
请求主评论的内容
import requests
import jieba
import time
import csv
from pyecharts.charts import WordCloud
# 得到csv这个对象,一遍下面的存储使用
cfile = open('bilibili评论数据.csv','w+',encoding='utf8')
csv_file = csv.writer(cfile)
url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=48487753&mode=3&plat=1&_=1667131834151'
resp = requests.get(url).json()
# 声明一个变量进行计数,我只需要获得200条数据就可以了
count = 0
# 数据清洗得到主评论
for i in resp['data']['replies']:
# 获取评论id和页数,用作自评的请求参数
rpid = i['rpid']
rcount = i['rcount']
# 获得评论内容
content = i['content']['message']
csv_file.writerow([content])
print(rpid,content)依据上面的代码,我们需要请求子评论的内容
第四步:分析子评论
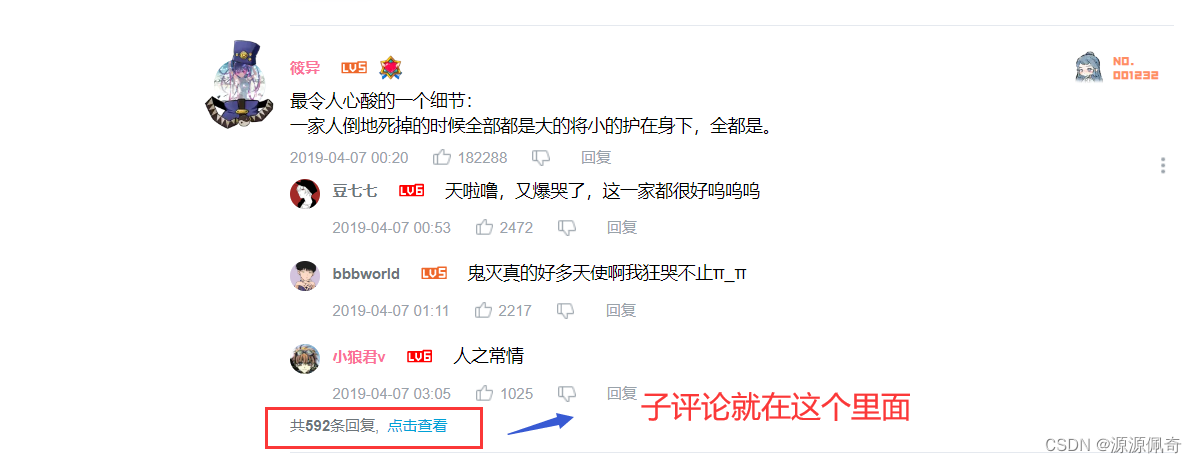
和上面的操作一项,按 F12 打开开发者工具
点击【点击查看】
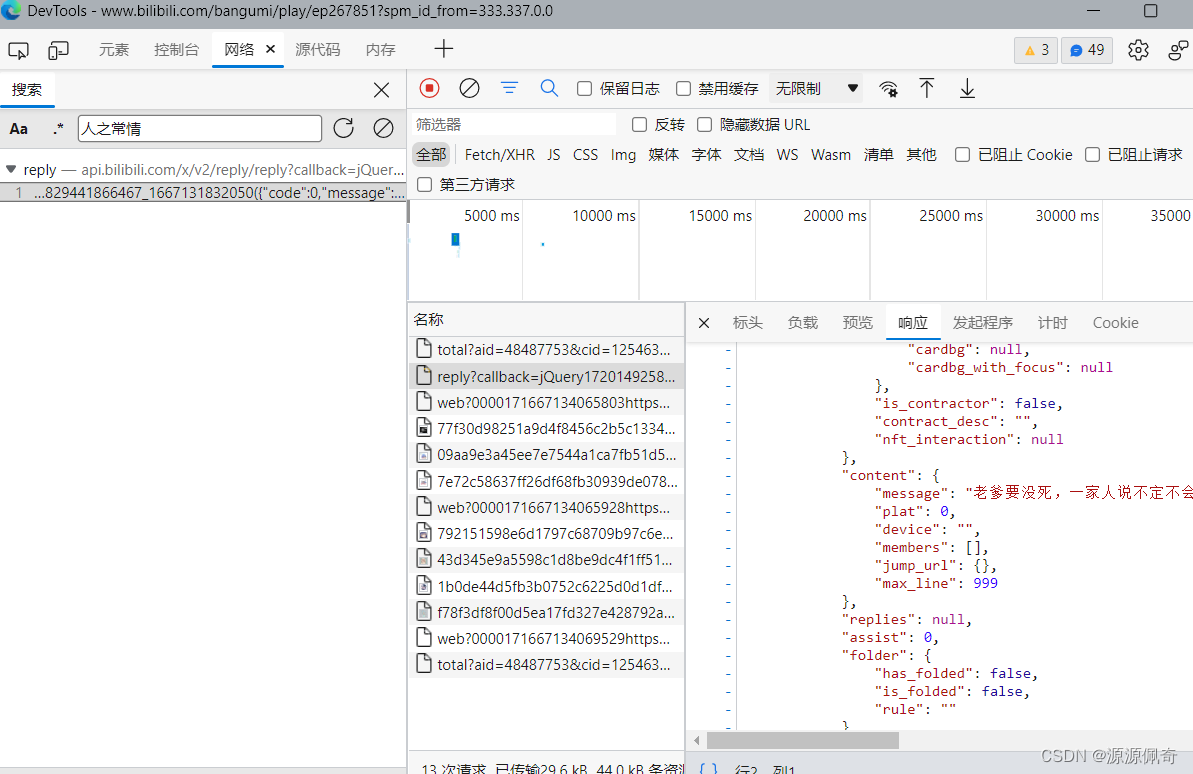
操作完成之后就会得到子评论的数据包
然后复制子评论的url
删除掉不用的参数
删掉这个参数:callback=jQuery172014925829441866467_1667131832049&
结构也与主评论的结构一样
接下来就是结合上面的代码,进行请求
第五步:子评论数据获取
import requests
import jieba
import time
import csv
from pyecharts.charts import WordCloud
# 得到csv这个对象,一遍下面的存储使用
cfile = open('bilibili评论数据.csv','w+',encoding='utf8',newline='')
csv_file = csv.writer(cfile)
url = 'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next=0&type=1&oid=48487753&mode=3&plat=1&_=1667131834151'
resp = requests.get(url).json()
# 声明一个变量进行计数,我只需要获得200条数据就可以了
count = 0
# 数据清洗得到主评论
for i in resp['data']['replies']:
# 获取评论id和页数,用作自评的请求参数
rpid = i['rpid']
rcount = i['rcount']
# 获得评论内容
content1 = i['content']['message']
# 写入csv文件中
csv_file.writerow([content1])
print(rpid,content1)
count += 1
""" 请求子评论 """
# 循环页数发送请求
for j in range(1,rcount):
print(j)
# root 参数为主评论id
# pn 参数为页数
url=f'https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={j}&type=1&oid=48487753&ps=10&root={rpid}&_=1667134065802'
resp = requests.get(url).json()
# 这里可能会得到没有子评论的主评论,要进行为空处理
if resp['data']['replies'] !=None:
# 有数据之后在进行循环获取,不然会报错
for m in resp['data']['replies']:
# 获得评论内容
content2 = m['content']['message']
# 写入csv文件中
csv_file.writerow([content2])
count += 1
# 当数据大于200条时,我们就退出程序
if count > 200:
exit()
# 每发送子评论请求,进行休眠2秒钟,不然ip会被禁掉
time.sleep(2)看一下csv数据:

第六步:制作词云图
import pandas as pd
from pyecharts.charts import WordCould
df = pd.read_csv('bilibili评论数据.csv')
print(df.head())
# 导入停词文件
stopword = open('stopword.txt', encoding='utf8').read().split('\n')
# 进行分词
data = jieba.lcut(''.join(df.content))
# 统计词频
word = {}
for i in data:
if i not in stopword:
word[i] = word.get(i, 0) + 1
# 绘制词云图
wc = WordCloud()
wc.add('', word.items(), shape='triangle')
wc.render('Ciyun.html')运行后或出现 html文件,打开html文件就行,结果如下:、

这样不是很开看,既然是鬼灭的评论,就用鬼灭人物做一个词云图吧

就用这个了。
作为掩膜的图像需要透明的图片,这个有点难找
找的难,自己造一个不就可以了。用opencv轻轻松松搞定
呦西!!!
添加mask_image参数,然后把刚刚用opencv生成的照片imgcy,png,添加进这个参数
wc.add('', word.items(), shape='triangle',mask_image='imgcy.png')
效果不是太明显,好歹样子还是出来了,哈哈哈!
告辞,盆友们!!