1 所用模型
代码中用到了以下模型:
1. LSTM(Long Short-Term Memory):长短时记忆网络,是一种特殊的RNN(循环神经网络),能够解决传统RNN在处理长序列时出现的梯度消失或爆炸的问题。LSTM有门控机制,可以选择性地记住或忘记信息。
2. FC-LSTM:全连接的LSTM,与传统的LSTM相比,其细胞单元之间采用全连接的方式。
3. Coupled LSTM:耦合LSTM,是一种特殊的LSTM结构,其中每个LSTM单元被分解为两个交互的子单元。
4. GRU(Gated Recurrent Unit):门控循环单元,与LSTM类似,但结构更简单,参数更少,通常训练更快,但可能不如LSTM准确。
5. ConvLSTM:卷积LSTM,将卷积神经网络(CNN)与LSTM结合,可以捕捉时空特征,常用于处理图像和视频数据。
6. Deep LSTM:深层LSTM,包含多个LSTM层的堆叠,可以捕捉更复杂的模式。
7. DB-LSTM(Bidirectional LSTM):双向LSTM,有两个方向的LSTM层,一个按时间顺序,一个逆序,可以同时获取过去和未来的信息。
8. SRU(SimpleRNN):简单循环神经网络,是最基本的RNN形式。
9. TPA-LSTM:时间感知LSTM,通过改变LSTM的内部计算方式,使其更加关注时间序列的特性。
10. ConvGRU:卷积GRU,与ConvLSTM类似,但使用GRU代替LSTM。
这些模型都是用于处理序列数据的深度学习模型,特别适用于时间序列预测、自然语言处理等领域。
2 运行结果
左边是Epoch=50次的效果,右边是Epoch=15次的效果:
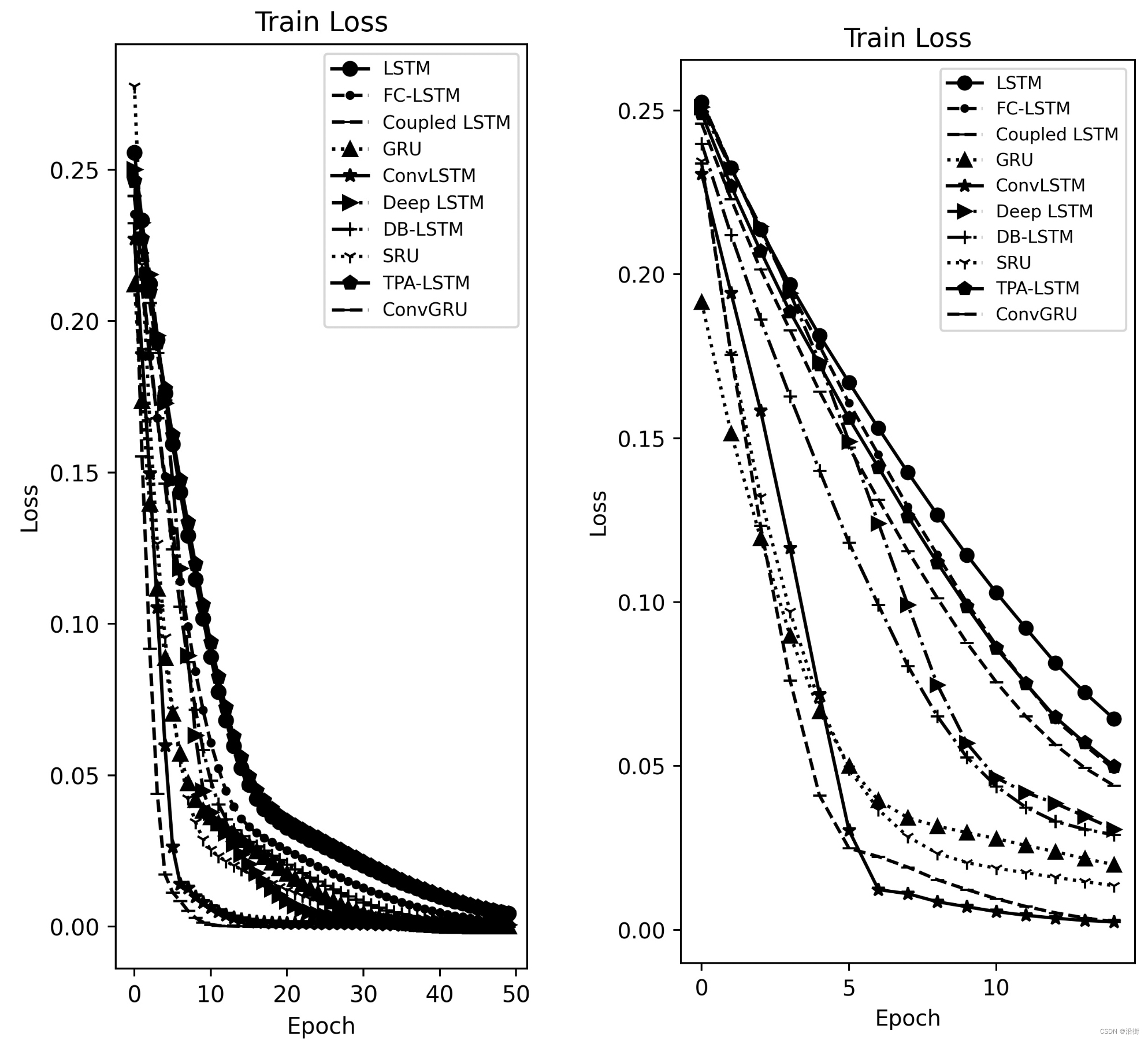
图2-1 训练损失
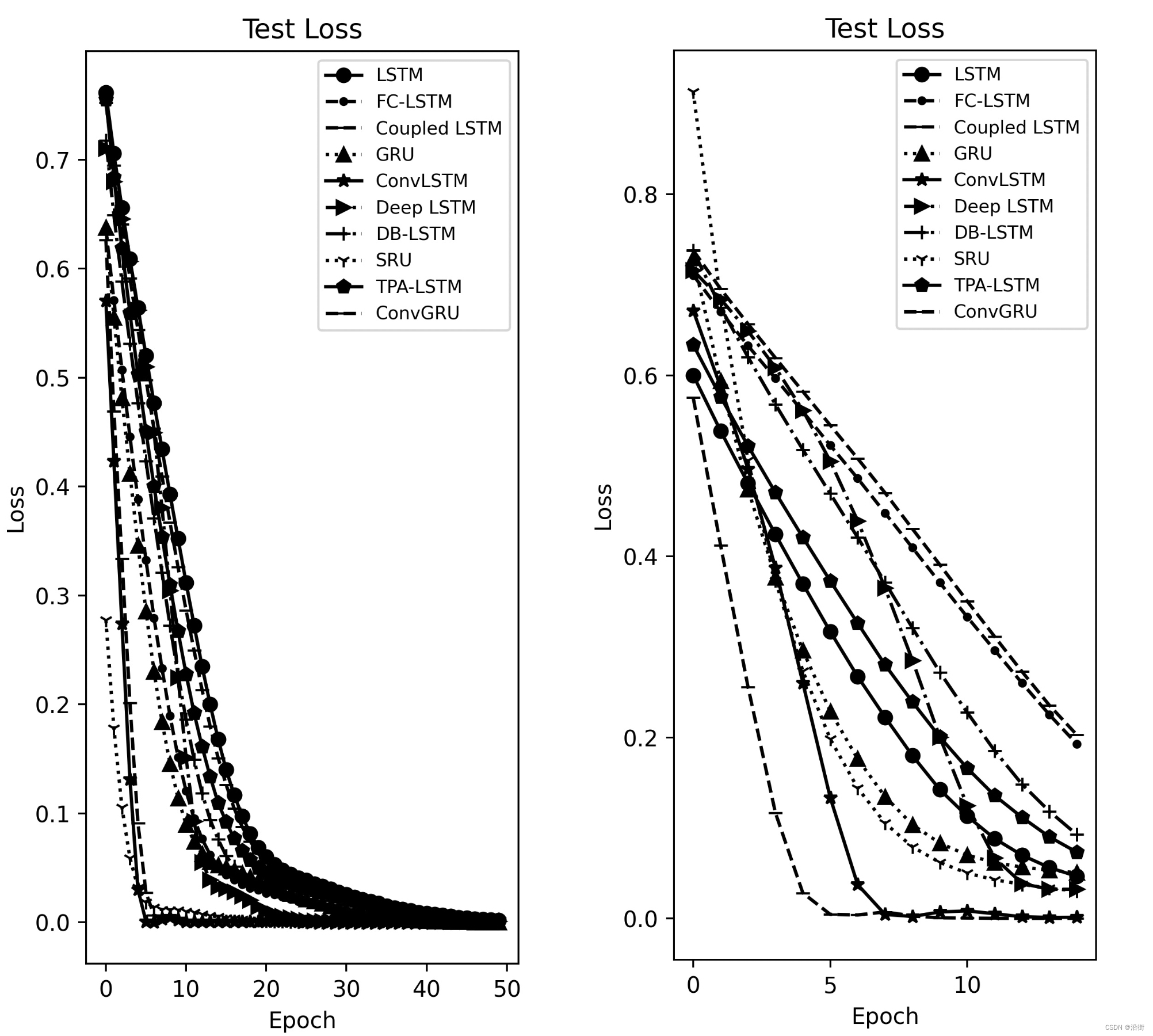
图2-2 测试损失
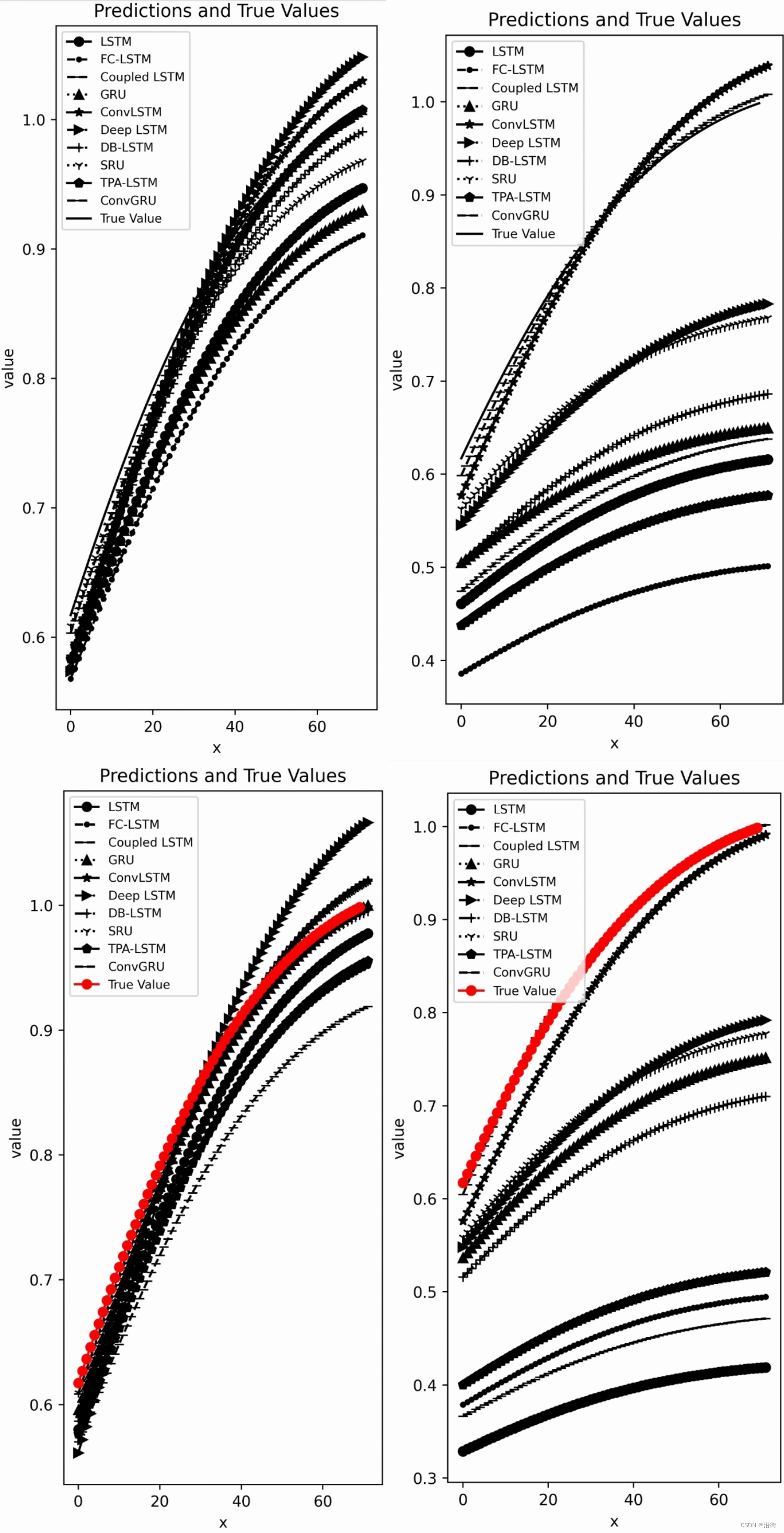
图2-3 预测结果
3 代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense, LSTM, GRU, SimpleRNN, Bidirectional, TimeDistributed, Conv1D, Attention
from keras.layers import Flatten, Dropout, BatchNormalization
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.layers import Conv1D
# 读取数据
data = pd.read_excel('A.xlsx')
data=data.dropna()
data = data['A'].values.reshape(-1, 1)
# 数据预处理
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
# 划分训练集和测试集
train_size = int(len(data) * 0.8)
train, test = data[:train_size], data[train_size:]
# 转换数据格式以适应LSTM输入
def create_dataset(dataset, look_back=1):
X, Y = [], []
for i in range(len(dataset) - look_back - 1):
X.append(dataset[i:(i + look_back), 0])
Y.append(dataset[i + look_back, 0])
return np.array(X), np.array(Y)
look_back = 1
X_train, y_train = create_dataset(train, look_back)
X_test, y_test = create_dataset(test, look_back)
# 重塑输入数据的维度以适应LSTM模型
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
X_test = np.reshape(X_test, (X_test.shape[0], 1, X_test.shape[1]))
# 定义模型函数
def create_model(name):
model = Sequential()
if name == 'LSTM':
model.add(LSTM(50, activation='relu', input_shape=(1, 1)))
elif name == 'FC-LSTM':
model.add(LSTM(50, activation='relu', input_shape=(1, 1), recurrent_activation='sigmoid'))
elif name == 'Coupled LSTM':
model.add(LSTM(50, activation='relu', input_shape=(1, 1), implementation=2))
elif name == 'GRU':
model.add(GRU(50, activation='relu', input_shape=(1, 1)))
elif name == 'ConvLSTM':
model.add(Conv1D(filters=64, kernel_size=1, activation='relu', input_shape=(1, 1)))
model.add(LSTM(50, activation='relu'))
elif name == 'Deep LSTM':
model.add(LSTM(50, return_sequences=True, activation='relu', input_shape=(1, 1)))
model.add(LSTM(50, activation='relu'))
elif name == 'DB-LSTM':
model.add(Bidirectional(LSTM(50, activation='relu'), input_shape=(1, 1)))
elif name == 'SRU':
model.add(SimpleRNN(50, activation='relu', input_shape=(1, 1)))
elif name == 'TPA-LSTM':
model.add(LSTM(50, activation='relu', input_shape=(1, 1), unroll=True))
elif name == 'ConvGRU':
model.add(Conv1D(filters=64, kernel_size=1, activation='relu', input_shape=(1, 1)))
model.add(GRU(50, activation='relu'))
model.add(Dense(1))
model.compile(optimizer=Adam(), loss='mse')
return model
# 训练模型并绘制损失图
names = ['LSTM', 'FC-LSTM', 'Coupled LSTM', 'GRU', 'ConvLSTM', 'Deep LSTM', 'DB-LSTM','SRU', 'TPA-LSTM', 'ConvGRU']
train_losses = []
test_losses = []
predictions = []
for name in names:
model = create_model(name)
history = model.fit(train, train, epochs=15, batch_size=32, validation_data=(test, test), verbose=0)
train_losses.append(history.history['loss'])
test_losses.append(history.history['val_loss'])
pred = model.predict(test)
predictions.append(pred)
import matplotlib.pyplot as plt
# 设置不同的marker
markers = ['o', '.', '_', '^', '*', '>', '+', '1', 'p', '_', '8']
linestyles = ['-', '--', '--', ':', '-', '-.', '-.', ':', '-', '--']
# 绘制训练损失图
plt.figure(figsize=(16, 20))
for i, loss in enumerate(train_losses):
plt.plot(loss, color='black',label=names[i], marker=markers[i], linestyle=linestyles[i])
plt.title('Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(fontsize=8,loc='best')
plt.show()
# 绘制测试损失图
for i, loss in enumerate(test_losses):
plt.plot(loss, color='black',label=names[i], marker=markers[i], linestyle=linestyles[i])
plt.title('Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(fontsize=8,loc='best')
plt.show()
# 绘制预测结果折线图
for i, pred in enumerate(predictions):
plt.plot(pred, color='black',label=names[i], marker=markers[i], linestyle=linestyles[i])
# 绘制真实值折线图
plt.plot(y_test, color='black', label='True Value')
plt.title('Predictions and True Values')
plt.xlabel('x')
plt.ylabel('value')
plt.legend(fontsize=8, loc='best')
# 显示图像
plt.show()