摘要:本文重新审视了在训练混合专家(Mixture-of-Experts, MoEs)模型时负载均衡损失(Load-Balancing Loss, LBL)的实现。具体来说,MoEs的LBL定义为N_E乘以从1到N_E的所有专家i的频率f_i与门控得分平均值p_i的乘积之和,其中N_E是专家的总数,f_i表示专家i被选择的频率,p_i表示专家i的平均门控得分。现有的MoE训练框架通常采用并行训练策略,以便在微批次(micro-batch)内计算f_i和LBL,然后在并行组之间进行平均。本质上,用于训练百亿级大规模语言模型(LLMs)的微批次通常只包含非常少的序列。因此,微批次的LBL几乎是在序列级别上进行的,这促使路由器在每个序列内均匀分配token。在这种严格约束下,即使是来自特定领域序列(例如代码)的token也会被均匀路由到所有专家,从而抑制了专家的专业化。在本文中,我们提出使用全局批次(global-batch)来计算LBL,以放宽这一约束。因为全局批次包含的序列比微批次更加多样,这将鼓励在语料库级别上进行负载均衡。具体来说,我们引入了一个额外的通信步骤来跨微批次同步f_i,然后使用它来计算LBL。通过在基于MoEs的大规模语言模型(总参数高达428亿,训练token数达4000亿)上的实验,我们惊讶地发现,全局批次LBL策略在预训练困惑度和下游任务方面都带来了显著的性能提升。我们的分析还表明,全局批次LBL也极大地提高了MoE专家的领域专业化能力。Huggingface链接:Paper page,论文链接:2501.11873
1. 引言
背景与动机:
- 混合专家(Mixture-of-Experts, MoEs)框架已成为扩展模型参数规模的一种流行技术。它通过路由器网络将输入分配给一组并行专家模块,实现了条件稀疏激活,从而提高了训练和推理效率。
- 训练MoE模型的一个关键因素是鼓励路由器以均衡的方式分配输入到专家,这既是为了保证训练的有效性(避免参数冗余),也是为了提高推理的效率(避免专家利用不均衡导致的推理速度减慢)。
- 负载均衡损失(Load-Balancing Loss, LBL)作为一种辅助损失函数,被广泛应用于MoE训练中以鼓励均衡的路由决策。然而,现有MoE训练框架在计算LBL时多采用微批次级别,这在训练大规模语言模型(LLMs)时存在局限性。
研究问题:
- 现有微批次级别的LBL计算方法在训练大规模MoE模型时,由于每个微批次包含的序列数量有限,导致路由器被推向在每个序列内均匀分配token,这抑制了专家的专业化,并可能损害模型性能。
研究目标:
- 本文旨在提出一种基于全局批次计算LBL的方法,以放宽微批次级别的严格约束,鼓励在语料库级别上进行负载均衡,从而提高模型性能和专家专业化能力。
2. 预备知识
混合专家(MoEs):
- MoEs由一组并行专家模块和一个路由器组成。路由器根据输入为每个专家分配权重,通常只激活得分最高的前K个专家。
- 输出是所有激活专家的加权和,权重由路由器根据输入为每个专家分配的得分决定。
负载均衡损失(LBL):
- LBL是一种正则化技术,用于鼓励专家利用的均衡性,防止专家崩溃。它通过对路由器过度将token路由到少数特定专家进行惩罚来实现。
- LBL的计算公式为N_E乘以所有专家i的频率f_i与门控得分平均值p_i的乘积之和,然后除以专家总数N_E。
3. 方法
全局批次LBL计算方法:
- 现有MoE训练框架在计算LBL时,通常在每个微批次内计算f_i和LBL,然后在并行组之间进行平均。这种方法在训练大规模LLMs时存在局限性,因为每个微批次包含的序列数量有限。
- 本文提出使用全局批次来计算LBL,以放宽微批次级别的严格约束。具体做法是引入一个额外的通信步骤来跨微批次同步f_i,然后使用同步后的f_i来计算LBL。
- 由于全局批次包含的序列比微批次更加多样,这将鼓励在语料库级别上进行负载均衡,从而促进专家的专业化。
针对计算节点数量有限的情况:
- 当训练LLMs时,全局批次大小可能非常大,而每个微批次大小可能相对较小。由于计算节点数量有限,所有微批次的总和可能小于全局批次大小。
- 在这种情况下,本文提出使用一个缓冲区来存储每个梯度累积(GA)步骤中同步的专家选择计数c_i。然后,在GA步骤中使用缓冲区中的信息来计算当前的f_i。完成GA后,重置缓冲区。
4. 实验
实验设置:
- 本文在三种不同大小的MoE模型上进行了实验,包括3.4B总参数(0.6B激活)、15B总参数(2.54B激活)和43B总参数(6.6B激活)的模型。
- 所有模型均采用细粒度专家和共享专家方法,并使用softmax门控、微批次LBL和z-loss。
- 训练数据包含1200亿和4000亿高质量token,涵盖多语言、数学和一般知识内容。
实验结果:
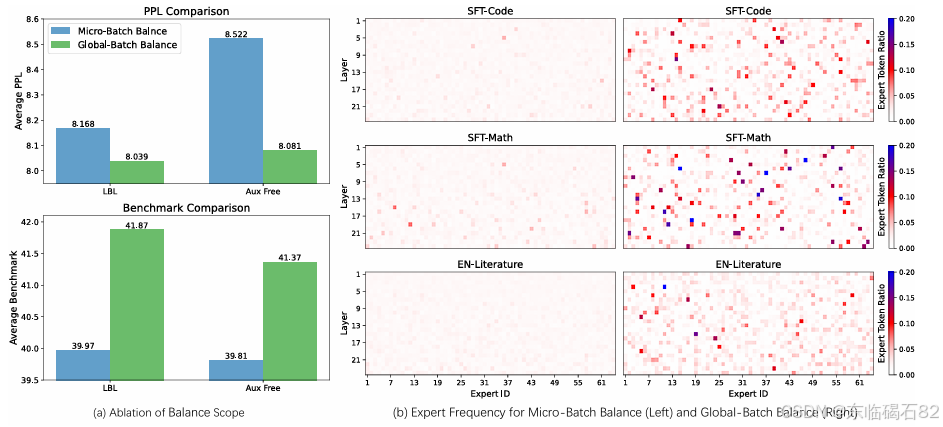
- 全局负载均衡提升模型性能:实验结果显示,随着计算LBL时考虑的token数量(Balance BSZ)的增加,所有指标均得到一致提升。特别是在4000亿token训练设置下,使用全局批次LBL的模型性能显著优于使用微批次LBL的模型。
- 全局负载均衡鼓励专家专业化:通过分析不同领域下每层专家的选择频率,发现使用全局批次LBL的模型在特定领域(如数学和代码)下出现了更多高频专家,表明全局批次LBL更有利于专家的专业化。
- 缓冲区机制的有效性:在计算节点数量有限的情况下,使用缓冲区机制可以近似全局批次LBL,从而在性能上接近使用全局批次LBL的模型,并显著优于使用微批次LBL的模型。
5. 分析
消融研究:
- 本文进行了消融研究以验证全局批次LBL相对于微批次LBL的优势。结果显示,即使在微批次内随机选择一批与全局批次具有相同token分布和数量的token来计算LBL(Shuffle LBL micro),其性能仍然接近全局批次LBL,并显著优于微批次LBL。这表明全局批次LBL的优势主要在于其更宽松的约束条件,而不是因为考虑了更多的token。
负载均衡损失和语言建模损失的变化:
- 通过分析训练过程中负载均衡损失和语言建模损失的变化,发现从微批次平衡切换到全局批次平衡后,负载均衡损失迅速下降并接近从头开始使用全局批次平衡的情况,而语言建模损失也保持较低水平。这表明全局批次平衡是一个更宽松的约束条件。
训练过程中改变Balance BSZ的影响:
- 实验结果显示,在训练过程中改变Balance BSZ会对最终结果产生影响。较早地切换到全局批次平衡可以获得更好的性能提升,而较晚地切换则提升有限。此外,从全局批次平衡切换到微批次平衡会导致性能下降,表明训练过程中专家选择的变化会显著影响模型性能。
全局批次平衡的计算成本和效率:
- 由于采用了无丢失策略,不同方法在计算浮点运算数(FLOPs)时是相同的。然而,由于局部平衡条件的不同,使用全局批次平衡的方法可能会经历局部计算不平衡。实验结果显示,使用全局批次平衡的方法在计算速度上比使用微批次平衡的方法慢约5.8%,但通过引入少量微批次平衡损失可以将其提高到接近使用微批次平衡的速度,同时仅对性能产生微小影响。
全局批次平衡带来的可解释性专业化:
- 通过分析使用全局批次平衡的模型在不同领域下的专家选择频率和路由得分,发现全局批次平衡促进了专家在不同领域下的专业化,并且路由得分与语言建模任务更加一致。
6. 相关工作
负载均衡:
- 现有的工作主要关注如何通过不同的方法来实现负载均衡,包括引入辅助损失函数、允许专家根据负载能力选择token等。然而,这些方法在计算专家选择频率时多采用微批次级别,存在局限性。
专家专业化:
- 初始的MoE设计旨在通过允许不同专家专注于特定任务来实现高效的参数利用。然而,由于微批次级别的负载均衡约束,大多数MoE模型并未展现出领域级别的专业化。本文提出的全局批次LBL方法有助于促进专家的专业化。
7. 结论
主要贡献:
- 本文提出了使用全局批次来计算LBL的方法,以放宽微批次级别的严格约束,从而促进专家的专业化和提高模型性能。
- 通过在多种规模的MoE模型上的实验,验证了全局批次LBL方法的有效性。
- 提供了对全局批次LBL方法如何影响模型性能和专家专业化的详细分析。
局限性:
- 本文主要关注分析预训练阶段微批次LBL对LLMs的影响,未进一步探讨其在微调阶段或在视觉和多模态领域的影响。
- 对专业化的分析主要集中在不同领域下的专家选择频率,未进行更严格的验证。
- 放宽微批次LBL可能引入一些延迟,未来工作可以考虑在每个微批次内包含更多样化的序列以减轻局部不平衡问题。
8. 未来工作
- 进一步研究全局批次LBL在微调阶段和在不同领域(如视觉和多模态)中的应用。
- 对专家专业化进行更严格的验证,例如通过人工评估专家在不同任务上的表现。
- 探索其他方法来减轻全局批次LBL可能引入的延迟问题。