目录
2、confusion_matrix_normalized.png、confusion_matrix.png






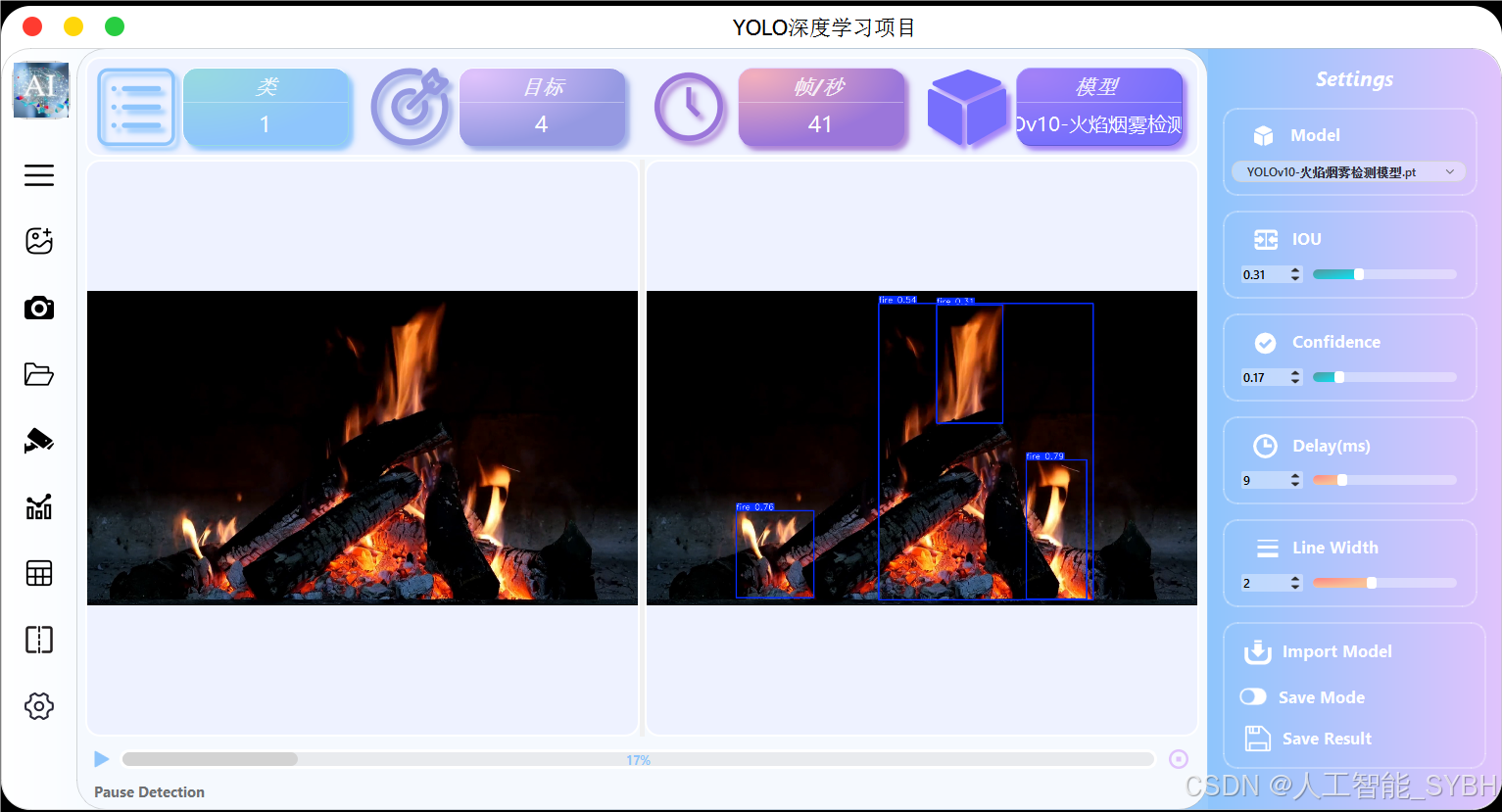
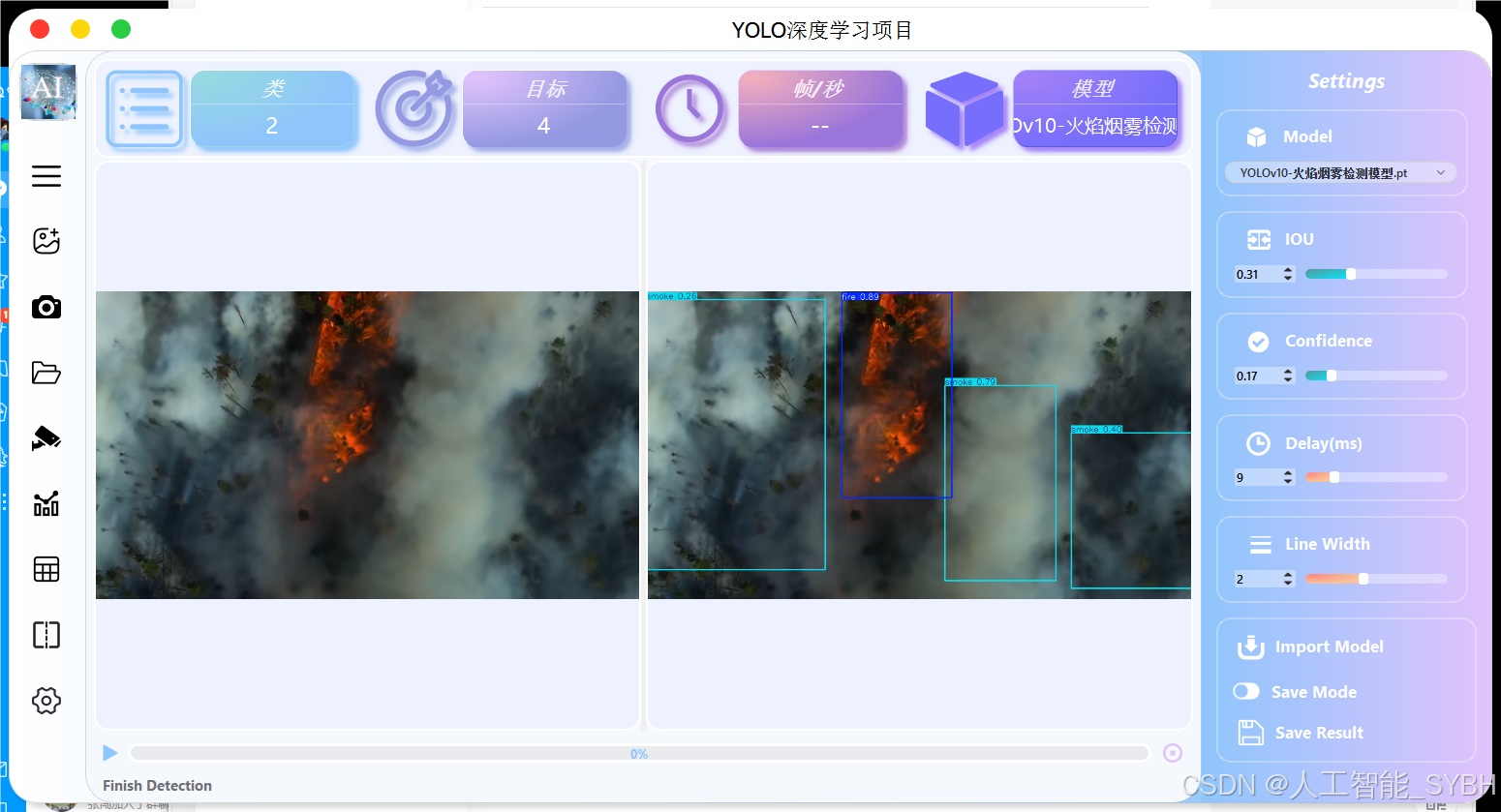
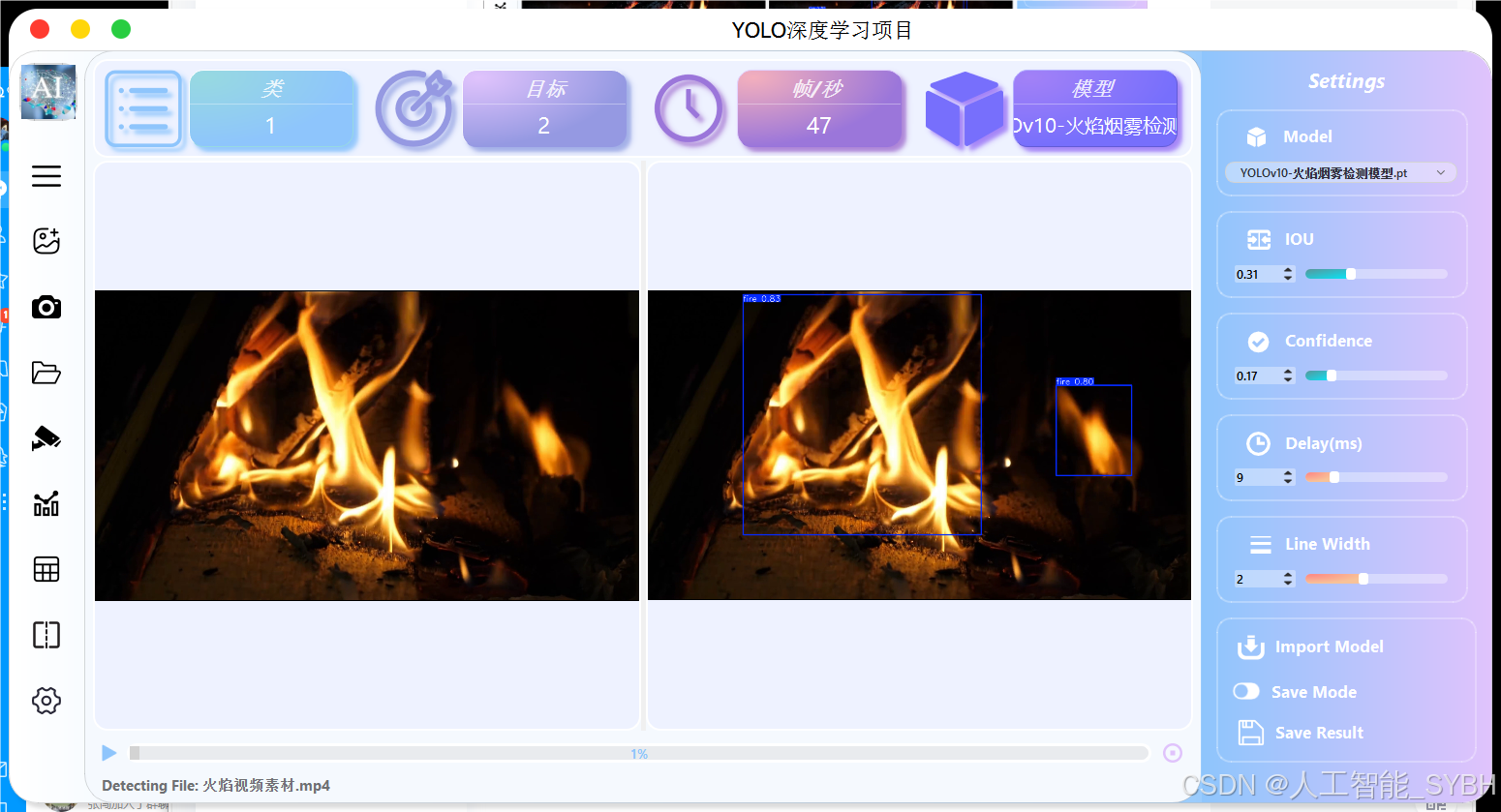
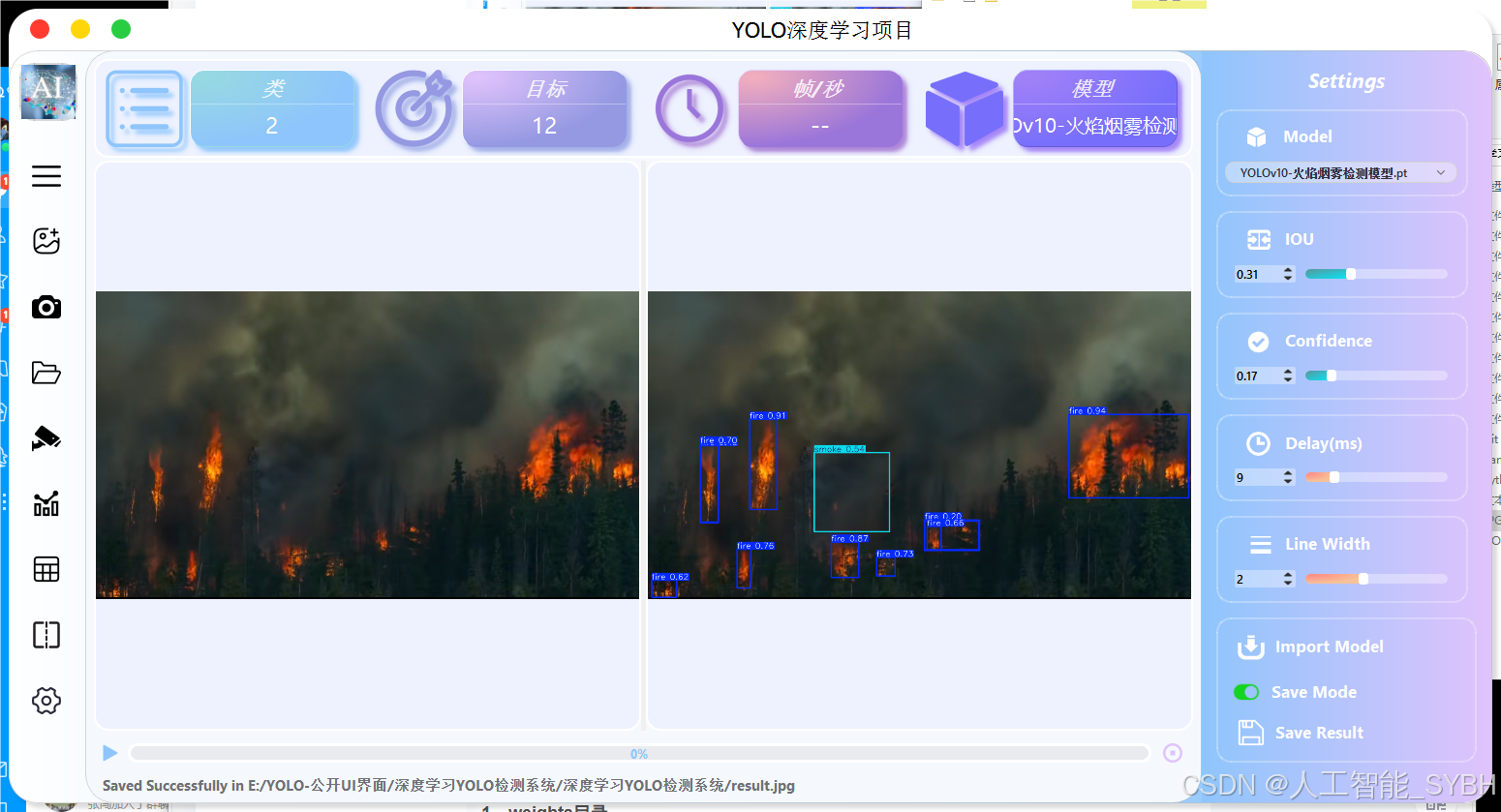
UI界面
(采用开源ui界面,界面不收取任何费用,下方链接领取开源界面,如有侵权请联系及时删除)
通过网盘分享的文件:深度学习YOLO检测系统.rar
链接: https://pan.baidu.com/s/1djUQGeabjziXkgip8xXY4g?pwd=8888 提取码: 8888
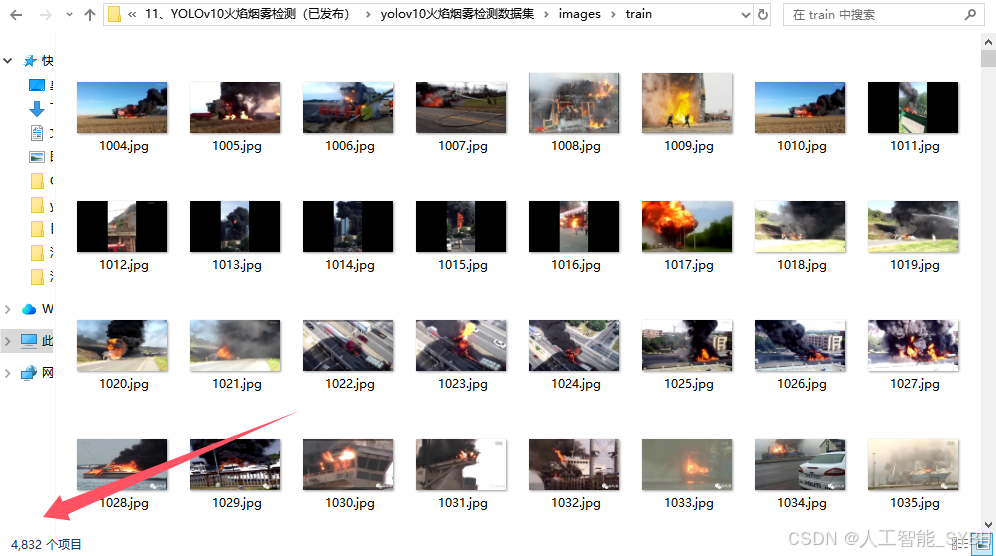
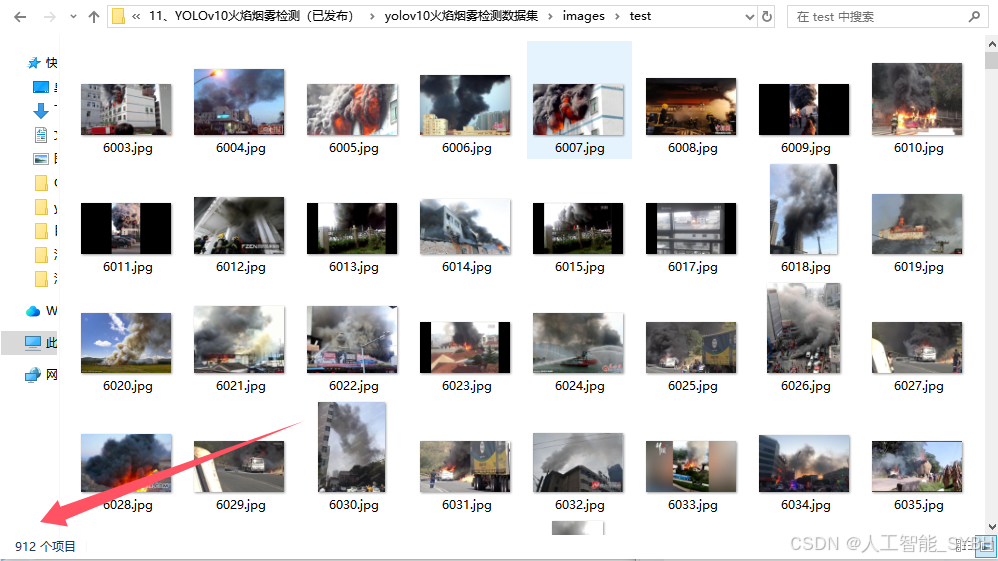
数据集(6744张)
训练结果
1、weights目录
该目录下保存了两个训练时的权重:

last.pt:
“last.pt” 一般指代模型训练过程中最后一个保存的权重文件。在训练过程中,模型的权重可能会定期保存,而 “last.pt” 就是最新的一次保存的模型权重文件。这样的文件通常用于从上一次训练的断点继续训练,或者用于模型的推理和评估。
best.pt:
“best.pt” 则通常指代在验证集或测试集上表现最好的模型权重文件。在训练过程中,会通过监视模型在验证集上的性能,并在性能提升时保存模型的权重文件。“best.pt” 可以被用于得到在验证集上表现最好的模型,以避免模型在训练集上过拟合的问题。
2、confusion_matrix_normalized.png、confusion_matrix.png
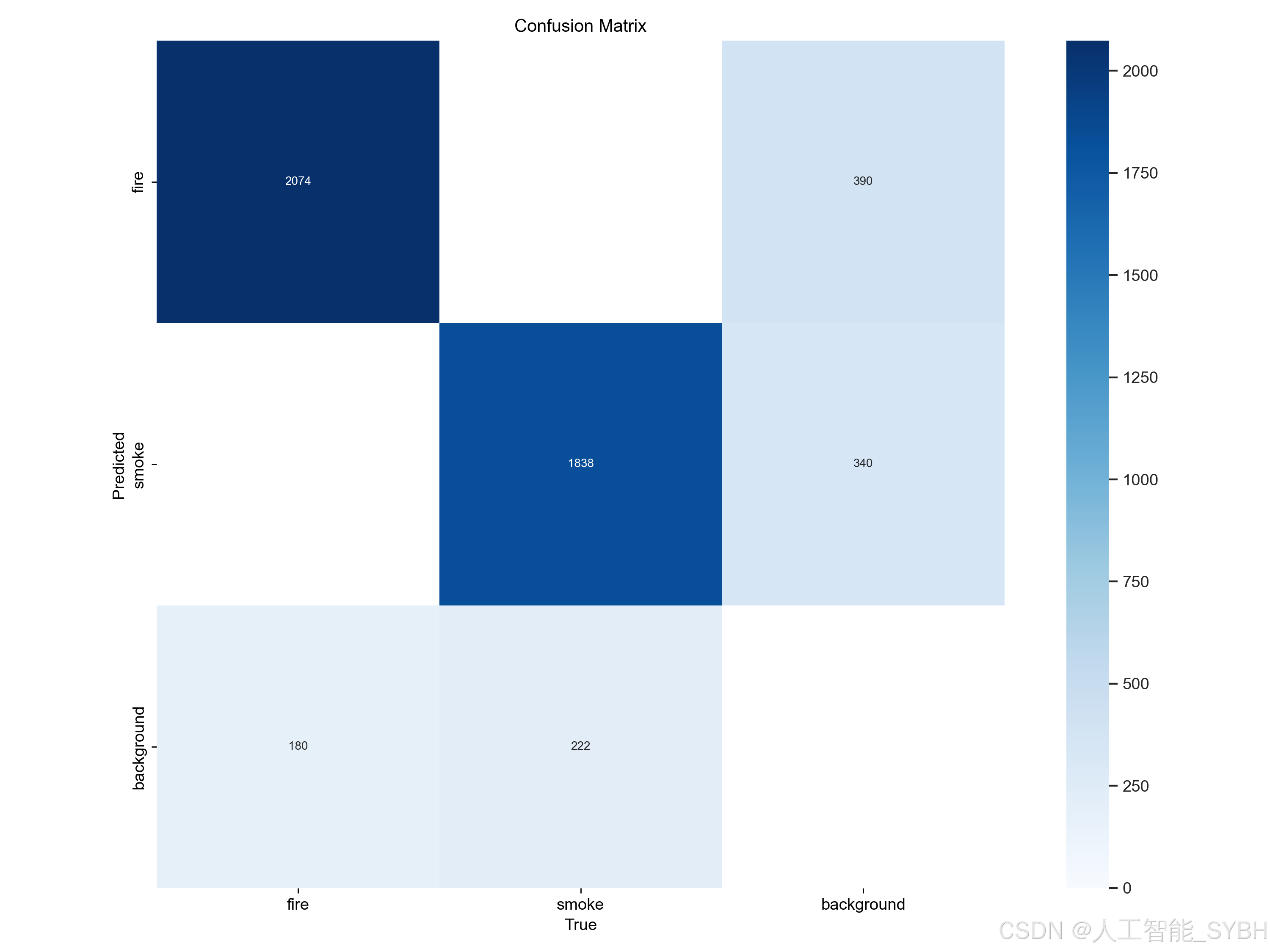
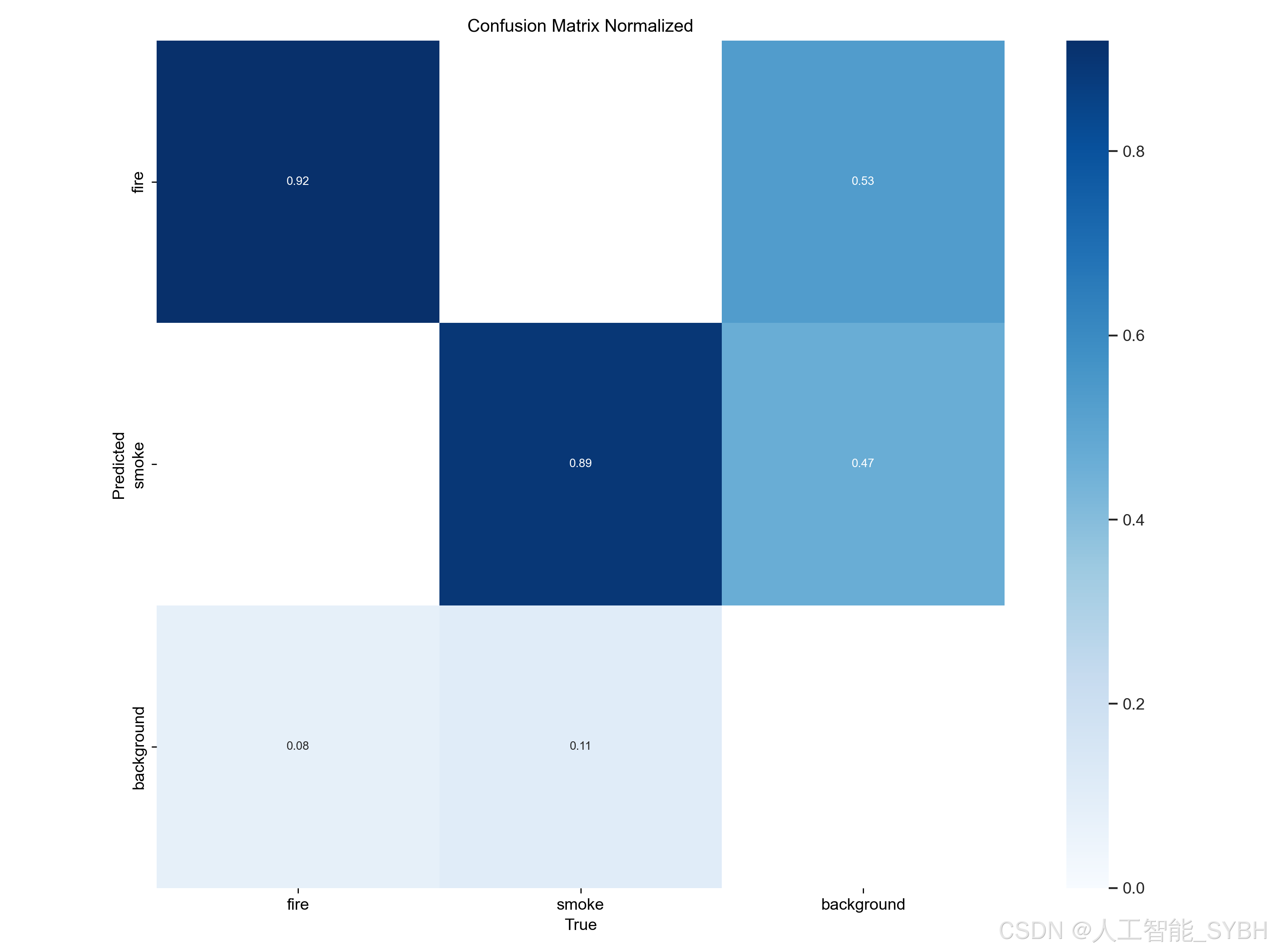
混淆矩阵是对分类问题预测结果的总结,通过计数值汇总正确和不正确预测的数量,并按每个类别进行细分,展示了分类模型在进行预测时对哪些部分产生混淆。该矩阵以行表示预测的类别(y轴),列表示真实的类别(x轴),具体内容如下:
| Predicted 0 | Predicted 1 |
------------|---------------|---------------|
Actual 0 | TN | FP |
------------|---------------|---------------|
Actual 1 | FN | TP |
其中:
TP(True Positive)表示将正类预测为正类的数量,即正确预测的正类样本数。
FN(False Negative)表示将正类预测为负类的数量,即错误预测的正类样本数。
FP(False Positive)表示将负类预测为正类的数量,即错误预测的负类样本数。
TN(True Negative)表示将负类预测为负类的数量,即正确预测的负类样本数。
混淆矩阵的使用有助于直观了解分类模型的错误类型,特别是了解模型是否将两个不同的类别混淆,将一个类别错误地预测为另一个类别。这种详细的分析有助于克服仅使用分类准确率带来的局限性。
精确率(Precision)和召回率(Recall)是常用于评估分类模型性能的指标,其计算方法如下:
精确率(Precision):
公式:Precision = TP / (TP + FP)
解释:精确率是指在所有被模型预测为正例(Positive)的样本中,实际为正例的比例。它衡量了模型在正例预测中的准确性。
召回率(Recall):
公式:Recall = TP / (TP + FN)
解释:召回率是指在所有实际为正例的样本中,模型成功预测为正例的比例。它衡量了模型对正例的识别能力。
3、F1_curve.png
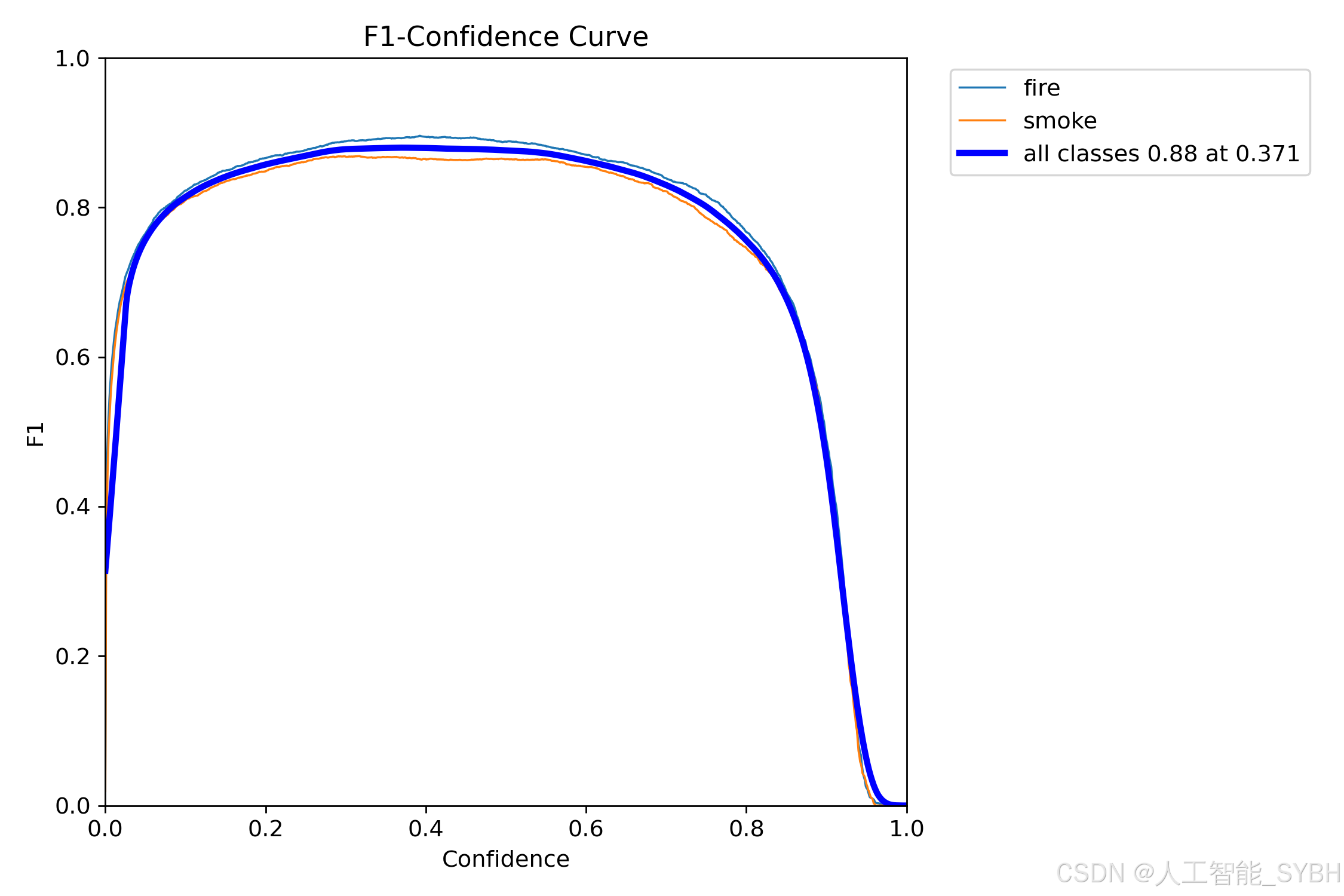
为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1曲线是一种多分类问题中常用的性能评估工具,尤其在竞赛中得到广泛应用。它基于F1分数,这是精确率和召回率的调和平均数,取值范围介于0和1之间。1代表最佳性能,而0代表最差性能。
通常情况下,通过调整置信度阈值(判定为某一类的概率阈值),可以观察到F1曲线在不同阈值下的变化。在阈值较低时,模型可能将许多置信度较低的样本判定为真,从而提高召回率但降低精确率。而在阈值较高时,只有置信度很高的样本才被判定为真,使得模型的类别判定更为准确,进而提高精确率。
4、labels.jpg
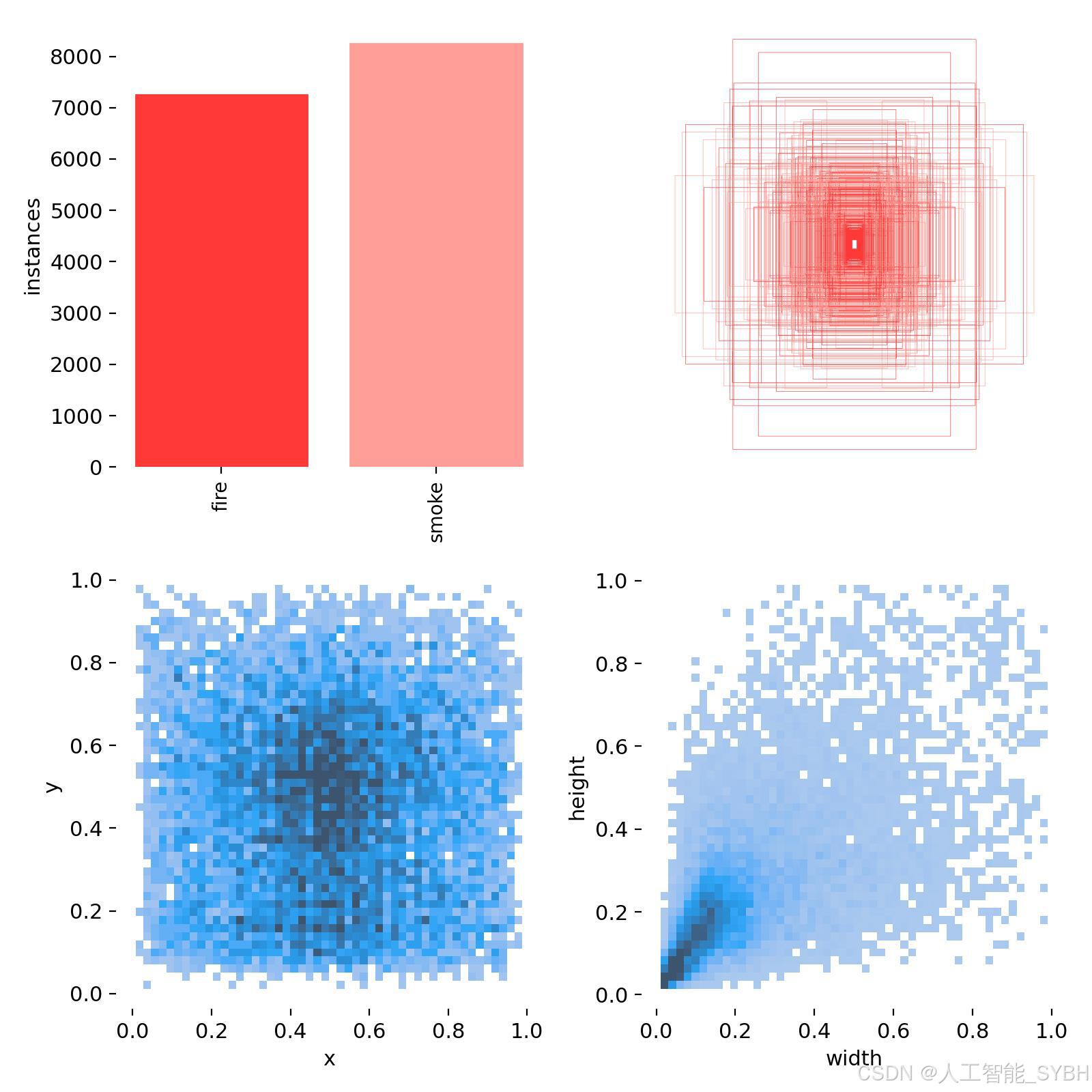
从左往右按顺序排列:
宫格1:训练集的数据量,显示每个类别包含的样本数量。
宫格2:框的尺寸和数量,展示了训练集中边界框的大小分布以及相应数量。
宫格3:中心点相对于整幅图的位置,描述了边界框中心点在图像中的位置分布情况。
宫格4:图中目标相对于整幅图的高宽比例,反映了训练集中目标高宽比例的分布状况。
5、labels_correlogram.jpg
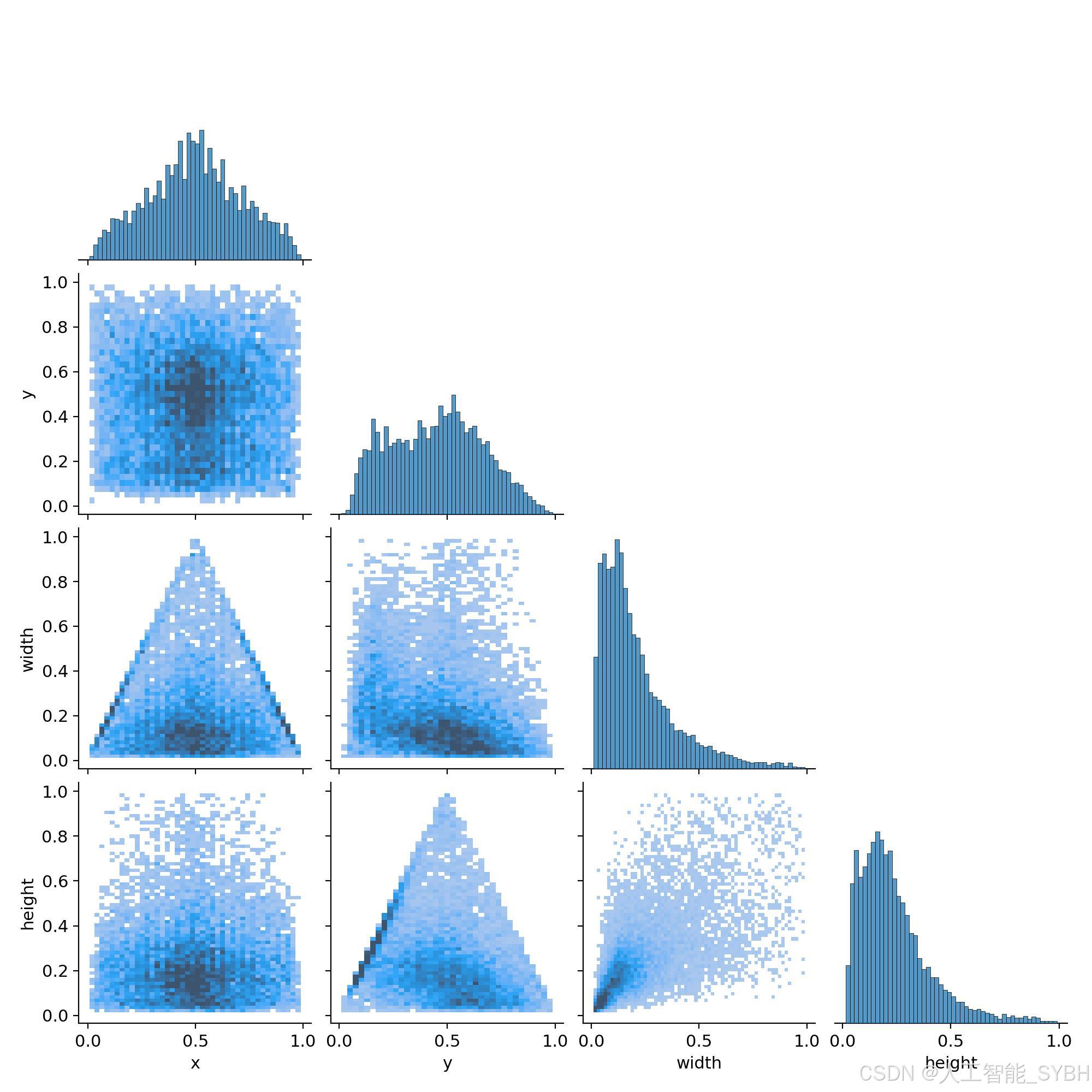
展示了目标检测算法在训练过程中对标签之间相关性的建模情况。每个矩阵单元代表模型训练时使用的标签,而单元格的颜色深浅反映了对应标签之间的相关性。
深色单元格表示模型更强烈地学习了这两个标签之间的关联性。
浅色单元格则表示相关性较弱。
对角线上的颜色代表每个标签自身的相关性,通常是最深的,因为模型更容易学习标签与自身的关系。
可以直观识别到哪些标签之间存在较强的相关性,这对于优化训练和预测效果至关重要。如果发现某些标签之间的相关性过强,可能需要考虑合并它们,以简化模型并提高效率。最上面的图(0,0)至(3,3)分别表示中心点横坐标x、中心点纵坐标y、框的宽和框的高的分布情况。
6.P_curve.png
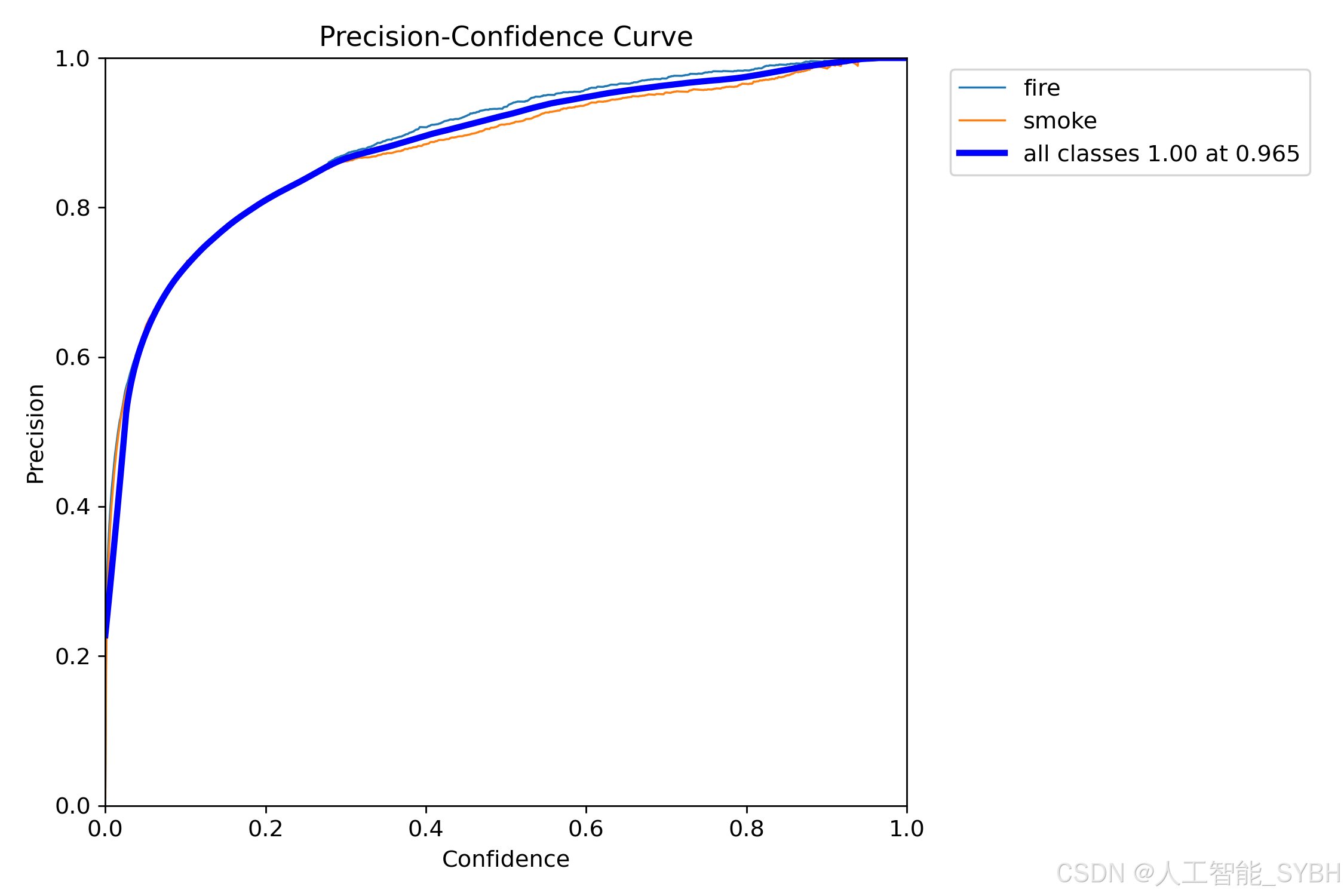
PCC图的横坐标表示检测器的置信度,纵坐标表示精度(或召回率)。曲线的形状和位置反映了检测器在不同信心水平下的性能。
在PCC图中,当曲线向上并向左弯曲时,表示在较低置信度下仍能保持较高的精度,说明检测器在高召回率的同时能够保持低误报率,即对目标的识别准确性较高。
相反,当曲线向下并向右弯曲时,说明在较高置信度下才能获得较高的精度,这可能导致漏检率的增加,表示检测器的性能较差。
因此,PCC图对于评估检测器在不同信心水平下的表现提供了有用的信息。在图中,曲线向上并向左弯曲是期望的效果,而曲线向下并向右弯曲则表示改进的空间。
7、R_curve.png
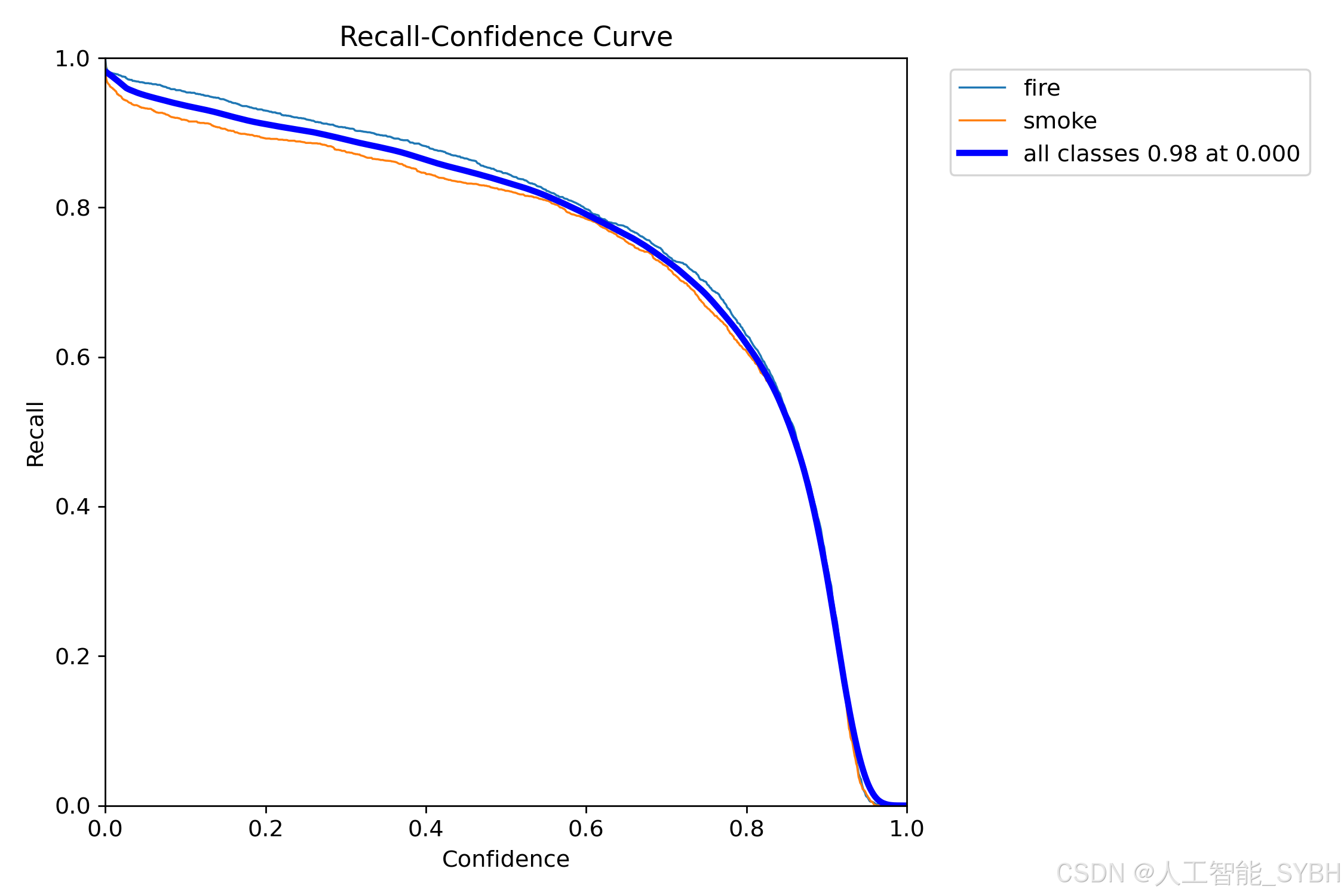
在理想情况下,希望算法在保持高召回率的同时能够保持较高的精度。
在RCC图中,当曲线在较高置信度水平下呈现较高召回率时,说明算法在目标检测时能够准确地预测目标的存在,并在过滤掉低置信度的预测框后依然能够维持高召回率。这反映了算法在目标检测任务中的良好性能。
值得注意的是,RCC图中曲线的斜率越陡峭,表示在过滤掉低置信度的预测框后,获得的召回率提升越大,从而提高模型的检测性能。
在图表中,曲线越接近右上角,表示模型性能越好。当曲线靠近图表的右上角时,说明模型在保持高召回率的同时能够维持较高的精度。因此,RCC图可用于全面评估模型性能,帮助找到平衡模型召回率和精度的合适阈值。
8、PR_curve.png
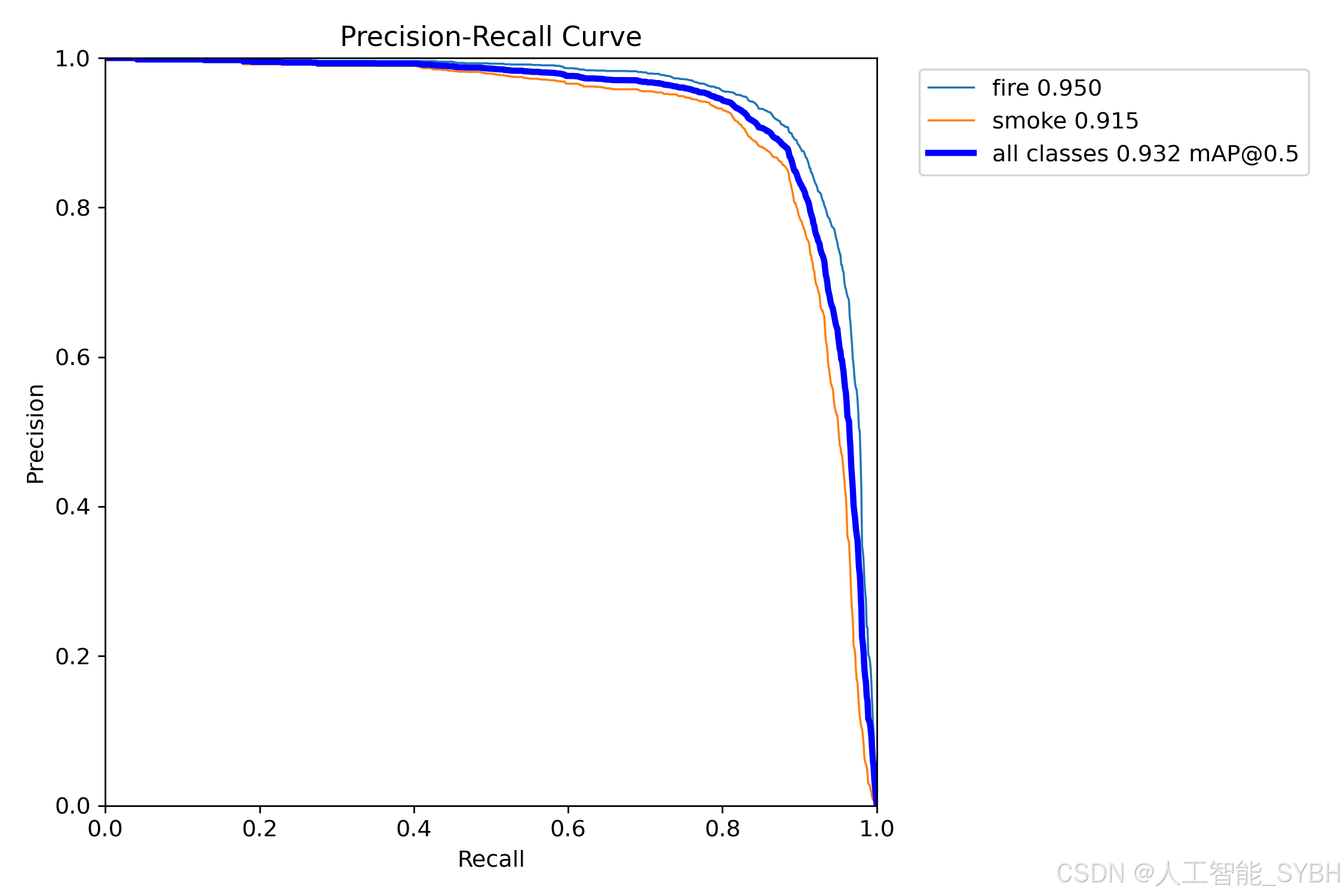
PR_curve是精确率(Precision)和召回率(Recall)之间的关系。精确率表示预测为正例的样本中真正为正例的比例,而召回率表示真正为正例的样本中被正确预测为正例的比例。
在PR Curve中,横坐标表示召回率,纵坐标表示精确率。通常情况下,当召回率升高时,精确率会降低,反之亦然。PR Curve反映了这种取舍关系。曲线越靠近右上角,表示模型在预测时能够同时保证高的精确率和高的召回率,即预测结果较为准确。相反,曲线越靠近左下角,表示模型在预测时难以同时保证高的精确率和高的召回率,即预测结果较为不准确。
通常,PR Curve与ROC Curve一同使用,以更全面地评估分类模型的性能。 PR Curve提供了对模型在不同任务下性能表现的更详细的洞察。
9、results.png
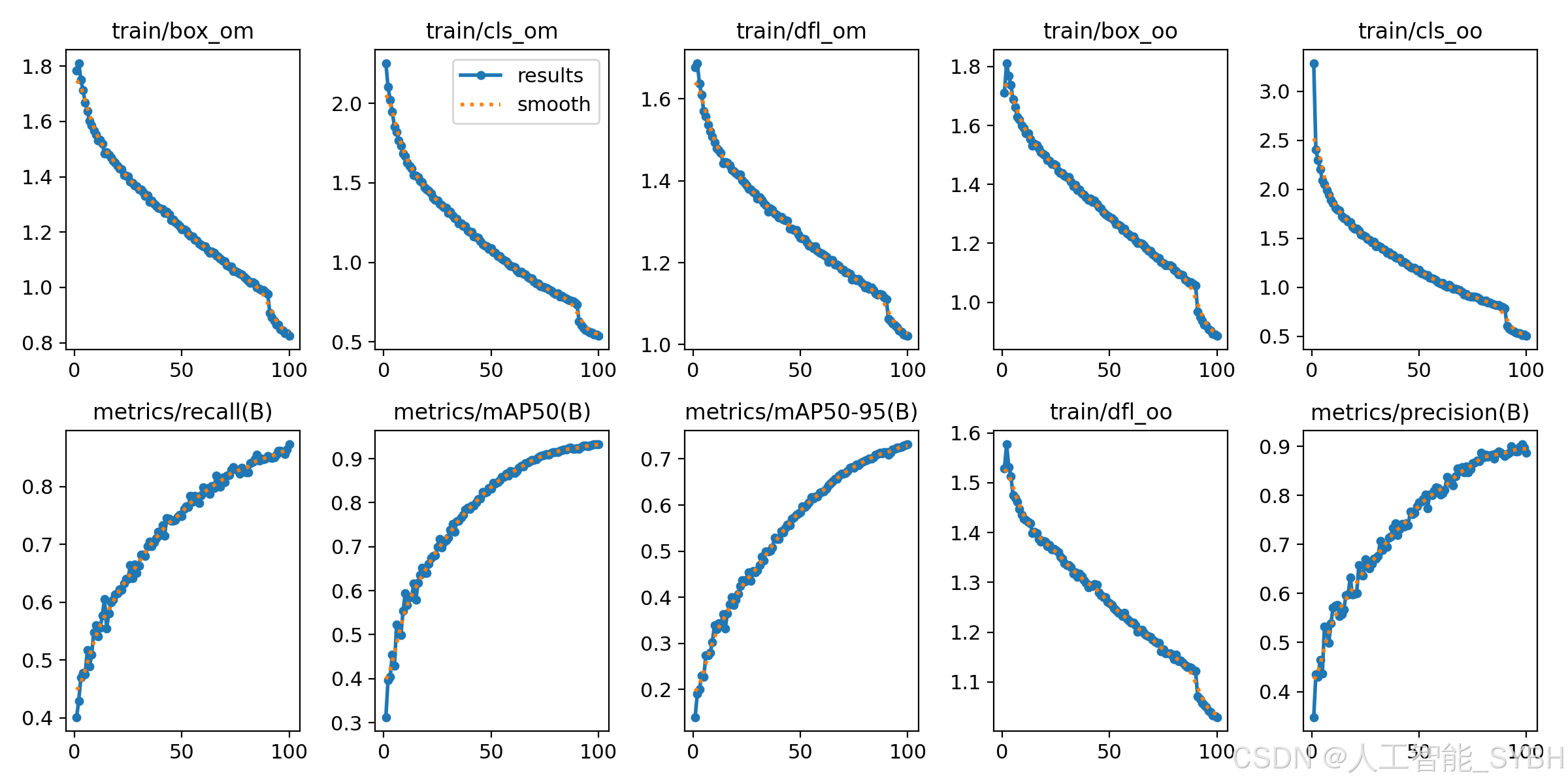
损失函数在目标检测任务中扮演关键角色,它用于衡量模型的预测值与真实值之间的差异,直接影响模型性能。以下是一些与目标检测相关的损失函数和性能评价指标的解释:
定位损失(box_loss):
定义: 衡量预测框与标注框之间的误差,通常使用 GIoU(Generalized Intersection over Union)来度量,其值越小表示定位越准确。
目的: 通过最小化定位损失,使模型能够准确地定位目标。
置信度损失(obj_loss):
定义: 计算网络对目标的置信度,通常使用二元交叉熵损失函数,其值越小表示模型判断目标的能力越准确。
目的: 通过最小化置信度损失,使模型能够准确判断目标是否存在。
分类损失(cls_loss):
定义: 计算锚框对应的分类是否正确,通常使用交叉熵损失函数,其值越小表示分类越准确。
目的: 通过最小化分类损失,使模型能够准确分类目标。
Precision(精度):
定义: 正确预测为正类别的样本数量占所有预测为正类别的样本数量的比例。
目的: 衡量模型在所有预测为正例的样本中有多少是正确的。
Recall(召回率):
定义: 正确预测为正类别的样本数量占所有真实正类别的样本数量的比例。
目的: 衡量模型能够找出真实正例的能力。
mAP(平均精度):
定义: 使用 Precision-Recall 曲线计算的面积,mAP@[.5:.95] 表示在不同 IoU 阈值下的平均 mAP。
目的: 综合考虑了模型在不同精度和召回率条件下的性能,是目标检测任务中常用的评价指标。
在训练过程中,通常需要关注精度和召回率的波动情况,以及 [email protected] 和 mAP@[.5:.95] 评估训练结果。这些指标可以提供关于模型性能和泛化能力的有用信息。
10.args.yaml
训练时的超参数:
task: detect
mode: train
model: yolov10s.pt
data: datasets/data.yaml
epochs: 100
time: null
patience: 100
batch: 8
imgsz: 640
save: true
save_period: -1
val_period: 1
cache: false
device: '0'
workers: 0
project: runs/detect
name: exp5
exist_ok: false
pretrained: true
optimizer: auto
verbose: true
seed: 0
deterministic: true
single_cls: false
rect: false
cos_lr: false
close_mosaic: 10
resume: false
amp: true
fraction: 1.0
profile: false
freeze: null
multi_scale: false
overlap_mask: true
mask_ratio: 4
dropout: 0.0
val: true
split: val
save_json: false
save_hybrid: false
conf: null
iou: 0.7
max_det: 300
half: false
dnn: false
plots: true
source: null
vid_stride: 1
stream_buffer: false
visualize: false
augment: false
agnostic_nms: false
classes: null
retina_masks: false
embed: null
show: false
save_frames: false
save_txt: false
save_conf: false
save_crop: false
show_labels: true
show_conf: true
show_boxes: true
line_width: null
format: torchscript
keras: false
optimize: false
int8: false
dynamic: false
simplify: false
opset: null
workspace: 4
nms: false
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5
cls: 0.5
dfl: 1.5
pose: 12.0
kobj: 1.0
label_smoothing: 0.0
nbs: 64
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
bgr: 0.0
mosaic: 1.0
mixup: 0.0
copy_paste: 0.0
auto_augment: randaugment
erasing: 0.4
crop_fraction: 1.0
cfg: null
tracker: botsort.yaml
save_dir: runs\detect\exp5
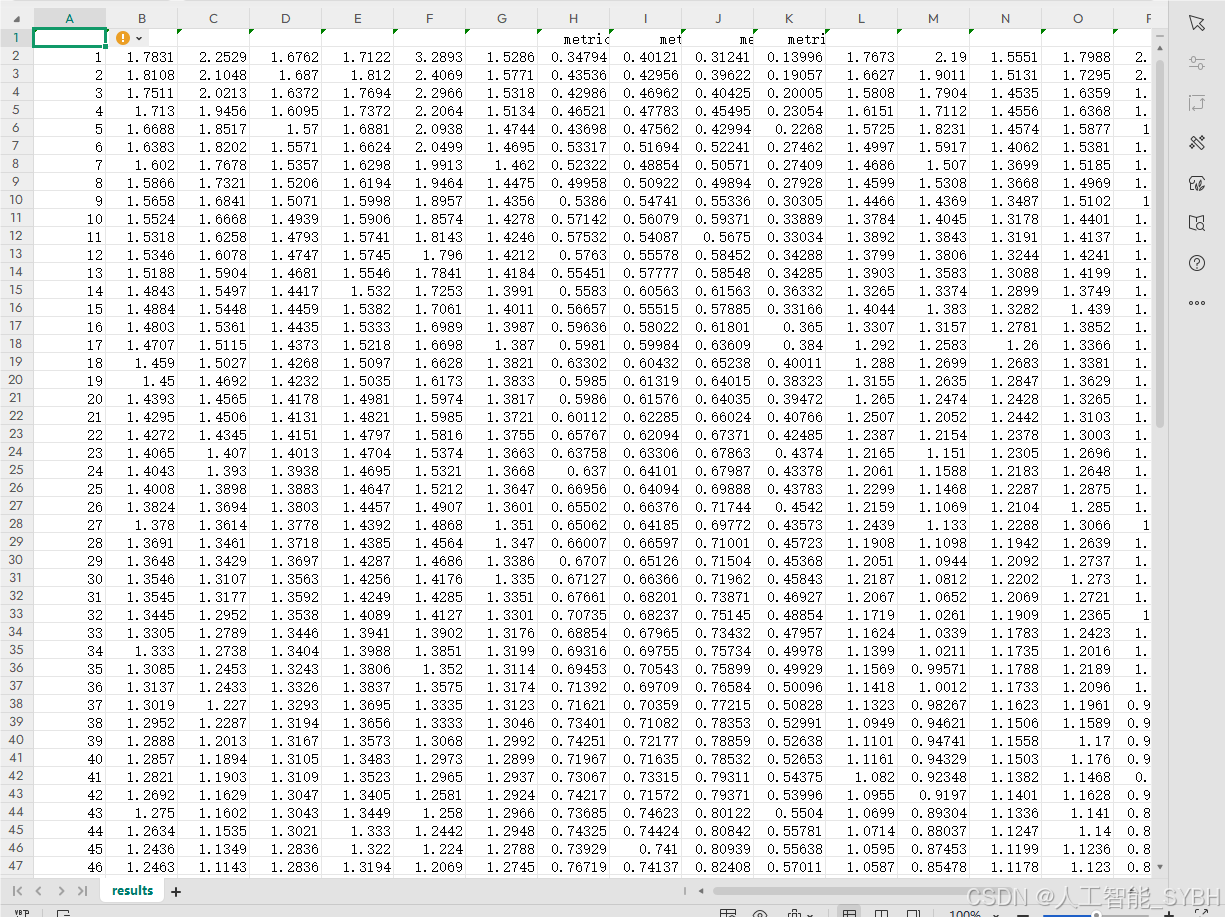
11.results.csv
模型训练时每次迭代结果:
12.train_batch(N).jpg
对应batch_size这个超参,这里设置为8所以一次读取8张图片:






13、val_batch(N)_labels.jpg 和 val_batch(N)_pred.jpg
通过网盘分享的文件:深度学习YOLO检测系统.rar
链接: https://pan.baidu.com/s/1djUQGeabjziXkgip8xXY4g?pwd=8888 提取码: 8888
YOLOv10介绍
在过去的几年里,YOLO 已成为实时目标检测领域的主要范式,因为它们在计算成本和检测性能之间取得了有效的平衡。研究人员探索了 YOLO 的架构设计、优化目标、数据增强策略等,取得了显著进展。但是,对非极大值抑制 (NMS) 进行后处理的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。此外,YOLO 中各种组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。它使效率不理想,并且具有相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构进一步推进 YOLO 的性能-效率边界。为此,我们首先提出了 YOLO 的无 NMS 训练的一致双分配,它同时带来了有竞争力的性能和低推理延迟。此外,我们还引入了 YOLO 的整体效率-精度驱动的模型设计策略。我们从效率和准确率两个角度对 YOLO 的各个组件进行了全面优化,大大降低了计算开销,增强了能力。我们努力的成果是用于实时端到端对象检测的新一代 YOLO 系列,称为 YOLOv10。大量实验表明,YOLOv10 在各种模型尺度上实现了最先进的性能和效率。例如,我们的 YOLOv10-S 为 1.8×比 COCO 上同类 AP 下的 RT-DETR-R18 更快,同时享受 2.8×参数和 FLOP 数量较少。与 YOLOv9-C 相比,YOLOv10-B 在同等性能下延迟降低了 46%,参数减少了 25%。
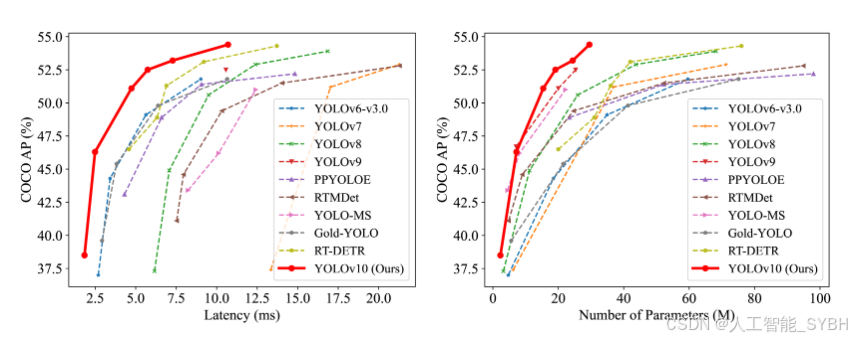
1介绍
实时物体检测一直是计算机视觉领域的研究重点,其目的是在低延迟下准确预测图像中物体的类别和位置。它被广泛用于各种实际应用,包括自动驾驶[3]、机器人导航[12]和对象跟踪[72]等。近年来,研究人员专注于设计基于 CNN 的对象检测器以实现实时检测[19,23,48,49,50,57,13].其中,YOLO 因其在性能和效率之间的巧妙平衡而越来越受欢迎[2,20,29,20,21,65,60,70,8,71,17,29].YOLO 的检测管道由模型前向处理和 NMS 后处理两部分组成。然而,它们仍然存在缺陷,导致精度-延迟边界次优。
具体来说,YOLO 在训练过程中通常采用一对多标签分配策略,即一个真实对象对应于多个正样本。尽管产生了卓越的性能,但这种方法需要 NMS 在推理过程中选择最佳的正预测。这会降低推理速度,并使性能对 NMS 的超参数敏感,从而阻止 YOLO 实现最佳的端到端部署[78].解决此问题的一种方法是采用最近推出的端到端 DETR 架构[4,81,73,30,36,42,67]. 例如,RT-DETR[78]提供高效的混合编码器和不确定性最小的查询选择,将 DETR 推向实时应用程序领域。尽管如此,当只考虑部署过程中模型的正向过程时,与 YOLO 相比,DETR 的效率仍有改进的空间。另一条路线是探索基于 CNN 的检测器的端到端检测,它通常利用一对一分配策略来抑制冗余预测[6,55,66,80,17].但是,它们通常会引入额外的推理开销或实现 YOLO 的次优性能。
此外,模型架构设计仍然是 YOLO 面临的根本挑战,对准确性和速度具有重要影响[50,17,71,8].为了实现更高效和有效的模型架构,研究人员探索了不同的设计策略。为骨干网络提供了各种初级计算单元,以增强特征提取能力,包括 DarkNet[48,49,50]、CSPNet[2]、EfficientRep[29]和 ELAN[62,64]等。对于颈部,PAN[37]、BiC[29]、GD[60]和 RepGFPN[71]等。,以增强多尺度特征融合。此外,还对扩展策略进行建模[62,61]和重新参数化[11,29]还研究了技术。虽然这些努力取得了显着进展,但仍然缺乏从效率和精度角度对 YOLO 中各种组件的全面检查。因此,YOLO 中仍然存在相当大的计算冗余,导致参数利用率低下和效率欠佳。此外,由此产生的约束模型能力也会导致性能不佳,为提高精度留下了充足的空间。
在这项工作中,我们的目标是解决这些问题并进一步推进 YOLO 的准确性-速度界限。我们在整个检测管道中同时针对后处理和模型架构。为此,我们首先解决了后处理中的冗余预测问题,为无 NMS 的 YOLO 提出了一种具有双标签分配和一致匹配度量的一致双分配策略。它允许模型在训练过程中享受丰富和谐的监督,同时在推理过程中无需 NMS,从而以高效率获得有竞争力的性能。其次,通过对 YOLO 中的各个组件进行综合检查,我们提出了模型架构的整体效率-精度驱动的模型设计策略。为了提高效率,我们提出了轻量级分类头、空间通道解耦下采样和秩导向块设计,以减少显现的计算冗余并实现更高效的架构。为了提高准确性,我们探索了大核卷积,并提出了有效的部分自我注意模块来增强模型能力,利用低成本下性能改进的潜力。
基于这些方法,我们成功地实现了具有不同模型规模的新型实时端到端检测器系列,即, YOLOv10-N / S / M / B / L / X。对对象检测的标准基准进行广泛实验,即可可[35],证明我们的 YOLOv10 在各种模型尺度的计算精度权衡方面可以明显优于以前的先进模型。如图 1 所示。 1、 我们的 YOLOv10-S / X 是 1.8×/ 1.3×分别比 RT-DETR-R18 / R101 更快,在性能相似的情况下。与 YOLOv9-C 相比,YOLOv10-B 在性能相同的情况下,延迟降低了 46%。此外,YOLOv10 表现出高效的参数利用。我们的 YOLOv10-L / X 比 YOLOv8-L / X 高出 0.3 AP 和 0.5 AP,为 1.8×和 2.3×参数数量较少。与 YOLOv9-M / YOLO-MS 相比,YOLOv10-M 实现了相似的 AP,参数分别减少了 23%/31%。我们希望我们的工作可以激发该领域的进一步研究和进步。
2相关工作
实时对象检测器。实时对象检测旨在以低延迟对对象进行分类和定位,这对于实际应用至关重要。在过去几年中,人们投入了大量精力来开发高效的探测器[19,57,48,34,79,75,32,31,41]. 特别是 YOLO 系列[48,49,50,2,20,29,62,21,65]作为主流脱颖而出。 YOLOv1、YOLOv2 和 YOLOv3 确定了典型的检测架构,由三部分组成,即、 脊椎、 颈部 和 头部[48,49,50].YOLOv4[2]和 YOLOv5[20]介绍 CSPNet[63]取代 DarkNet 的设计[47],再加上数据增强策略、增强的 PAN 和更多种类的模型规模等。 YOLOv6[29]分别介绍用于颈部和主干的 BiC 和 SimCSPSPPF,具有锚定辅助训练和自我蒸馏策略。 YOLOv7 版本[62]介绍了用于丰富梯度流路的 E-ELAN,并探索了几种可训练的免费赠品袋方法。YOLOv8[21]介绍用于有效特征提取和融合的 C2f 构建块。 金奖-YOLO[60]提供先进的 GD 机制,以提升多尺度特征融合能力。YOLOv9[65]建议 GELAN 改进架构,并建议 PGI 以增强训练过程。
端到端对象检测器。端到端对象检测已成为传统管道的范式转变,提供简化的架构[53].DETR 公司[4]引入 transformer 架构,采用匈牙利 loss 实现一对一匹配预测,从而省去了手工制作的组件和后处理。从那时起,人们提出了各种 DETR 变体来提高其性能和效率[42,67,56,30,36,28,5,77,82].可变形 - DETR[81]利用多尺度可变形注意力模块加速收敛速度。 恐龙[73]将对比降噪、混合查询选择和展望两次方案集成到 DETR 中。RT-DETR 系列[78]进一步设计了高效的 Hybrid 编码器,并提出了 Uncertainty-Minimal 查询选择,以提高准确性和延迟。实现端到端对象检测的另一条线路是基于 CNN 检测器。可学习的 NMS[24]和关系网络[26]提供另一个网络以删除检测器的重复预测。OneNet 公司[55]和 DeFCN[66]提出一对一匹配策略,以使用全卷积网络实现端到端对象检测。 FCOSPSS [80]引入了正样本选择器,用于选择最佳样本进行预测。
3方法论
3.1一致的双重任务,实现无 NMS 的培训
在训练期间,YOLO[21,65,29,70]通常利用 TAL[15]为每个实例分配多个正样本。采用一对多分配会产生丰富的监控信号,从而促进优化并实现卓越的性能。但是,它需要 YOLO 依赖 NMS 后处理,这会导致部署的推理效率欠佳。虽然以前的作品[55,66,80,6]探索一对一匹配以抑制冗余预测,它们通常会引入额外的推理开销或产生次优性能。在这项工作中,我们提出了一种无 NMS 的 YOLO 训练策略,具有双标签分配和一致的匹配指标,实现了高效率和有竞争力的性能。
双标签分配。与一对多分配不同,一对一匹配仅为每个真实值分配一个预测,从而避免了 NMS 后处理。然而,它会导致监管薄弱,从而导致精度和收敛速度欠佳[82].幸运的是,这种不足可以通过一对多分配来弥补[6].为了实现这一目标,我们为 YOLO 引入了双标签分配,以结合两种策略的优点。具体来说,如图 1 所示。 2.(a) 中,我们为 YOLO 合并了另一个一对一的 head。它保留了与原来的一对多分支相同的结构,并采用了相同的优化目标,但利用了 1 对 1 的匹配来获得标签分配。训练过程中,两个头与模型共同优化,让 backbone 和 neck 享受到一对多任务提供的丰富监督。在推理过程中,我们丢弃一对多头,利用一对一头进行预测。这使 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用 top one 选择,达到了与匈牙利匹配相同的性能[4]额外的训练时间更少。
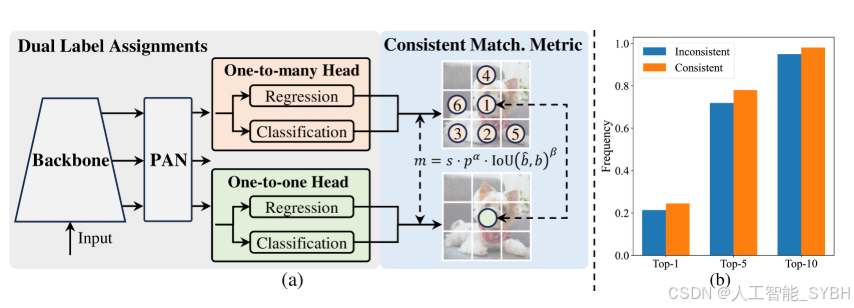

3.2整体效率-精度驱动的模型设计
除了后处理之外,YOLO 的模型架构也对效率-精度的权衡提出了巨大的挑战[50,8,29].尽管以前的工作探索了各种设计策略,但仍然缺乏对 YOLO 中各种组件的全面检查。因此,模型架构表现出不可忽视的计算冗余和受限能力,这阻碍了其实现高效率和性能的潜力。在这里,我们的目标是从效率和准确性的角度对 YOLO 进行整体模型设计。
效率驱动的模型设计。YOLO 中的组件包括 stem、下采样层、具有基本构建块的阶段和 head。茎产生的计算成本很小,因此我们对其他三个部分进行效率驱动的模型设计。
(1) 轻量化分级头。分类头和回归头通常在 YOLO 中共享相同的架构。但是,它们在计算开销方面表现出显著差异。例如,分类头 (5.95G/1.51M) 的 FLOPs 和参数计数为 2.5×和 2.4×YOLOv8-S 中回归头 (2.34G/0.64M) 的差异。然而,在分析了分类误差和回归误差的影响(见表 9)之后,我们发现回归头对 YOLO 的性能承担了更大的意义。因此,我们可以减少 classification head 的开销,而不必担心会极大地损害性能。因此,我们简单地对分类头采用轻量级架构,它由两个深度可分离的卷积组成[25,9]内核大小为 3×3 后跟 1×1 卷积。
(2) 空间通道解耦下采样。YOLO 通常利用常规 3×3 个标准卷积,步幅为 2,实现空间下采样(从H×W自H2×W2) 和通道转换 (从C自2C) 同时进行。这引入了不可忽略的计算成本𝒪(92HWC2)和参数计数为𝒪(18C2).相反,我们建议将 spatial reduction 和 channel increase 操作解耦,以实现更高效的下采样。具体来说,我们首先利用逐点卷积来调制通道维度,然后利用深度卷积来执行空间下采样。这将计算成本降低到𝒪(2HWC2+92HWC)将参数 count 设置为𝒪(2C2+18C).同时,它可以在降采样期间最大限度地提高信息保留率,从而在减少延迟的同时实现有竞争力的性能。
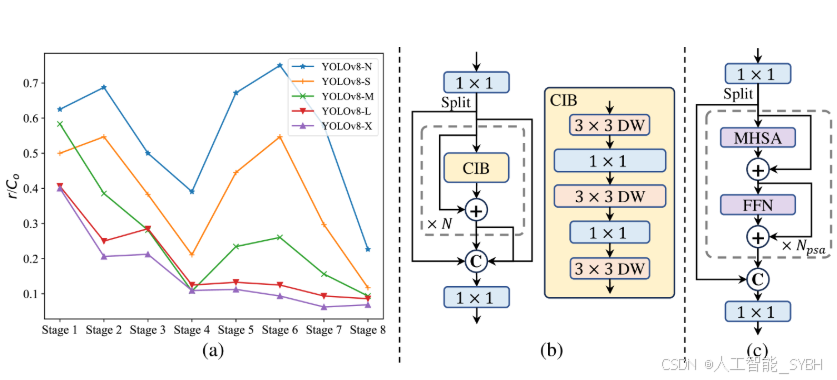
(3) 等级导向的区组设计。YOLO 通常对所有阶段使用相同的基本构建块[29,65],例如,YOLOv8 中的瓶颈块[21].为了彻底检查 YOLO 的这种齐次设计,我们利用了 intrinic rank[33,16]分析冗余1每个阶段。具体来说,我们计算每个阶段中最后一个基本块中最后一个卷积的数字秩,它计算大于阈值的奇异值的数量。无花果。 3.(a) 展示了 YOLOv8 的结果,表明深阶段和大型模型容易表现出更多的冗余。这一观察结果表明,简单地对所有阶段应用相同的块设计对于最佳容量-效率权衡来说是次优的。为了解决这个问题,我们提出了一种等级导向的块设计方案,旨在降低使用紧凑架构设计被证明是冗余的阶段的复杂性。我们首先提出了一种紧凑的倒块 (CIB) 结构,它采用廉价的深度卷积进行空间混合,采用经济高效的逐点卷积进行通道混合,如图 1 所示。 3.它可以作为高效的基本构建块,例如,嵌入在 ELAN 结构中[64,21] (无花果。 3.然后,我们提倡一种排名导向的区块分配策略,以在保持有竞争力的容量的同时实现最佳效率。具体来说,给定一个模型,我们根据其内部排名升序对它的所有阶段进行排序。我们进一步检查了用 CIB 替换前导阶段的基本块的性能变化。如果与给定模型相比没有性能下降,我们将继续替换下一阶段,否则停止该过程。因此,我们可以跨阶段和模型规模实现自适应紧凑模块设计,在不影响性能的情况下实现更高的效率。由于页数限制,我们在附录中提供了算法的详细信息。

4实验
4.1实现细节
我们选择 YOLOv8[21]作为我们的基准模型,因为它具有值得称道的延迟-准确性平衡,并且在各种模型大小中可用。我们采用一致的双重分配进行无 NMS 训练,并在此基础上执行整体效率精度驱动的模型设计,这带来了我们的 YOLOv10 模型。YOLOv10 具有与 YOLOv8 相同的变体,即、N / S / M / L / X。此外,我们通过简单地增加 YOLOv10-M 的宽度比例因子,得出了一个新的变体 YOLOv10-B。我们在 COCO 上验证了所提出的检测器[35]在相同的 train-from-scratch 设置下[21,65,62].此外,所有模型的延迟都在 T4 GPU 上使用 TensorRT FP16 进行了测试,如下所示[78].
4.2与最先进的技术进行比较
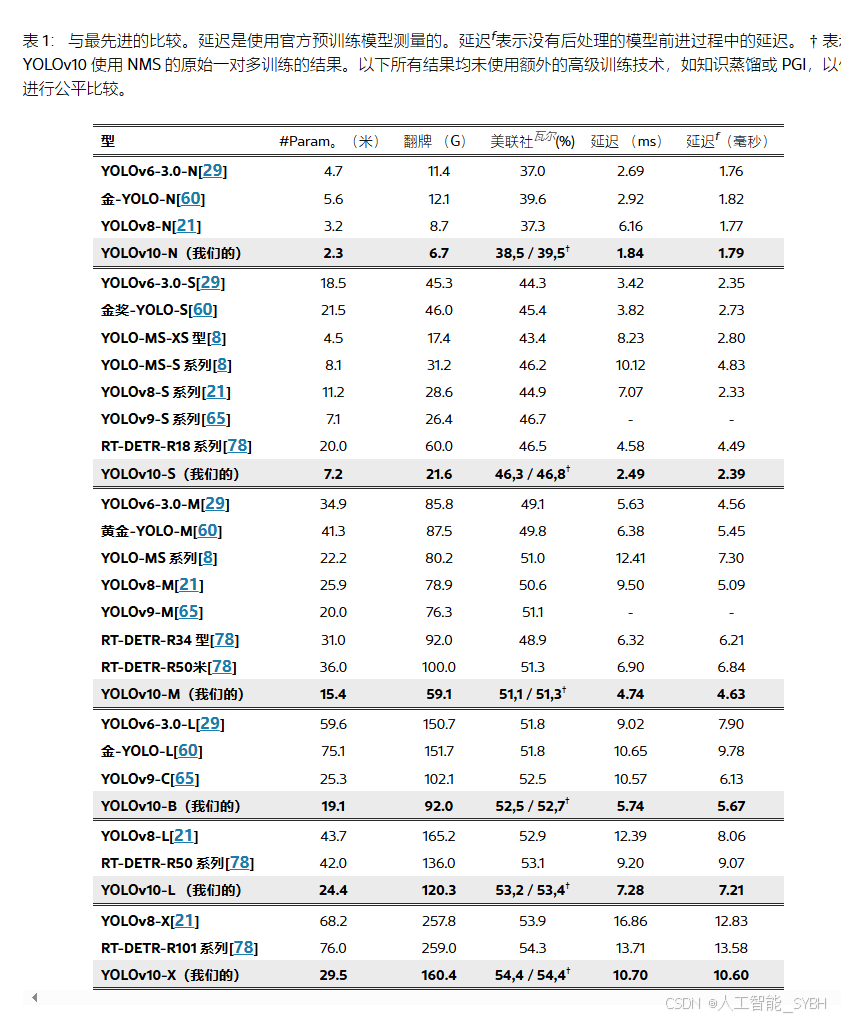
如表 1 所示,我们的 YOLOv10 在各种模型规模上实现了最先进的性能和端到端延迟。我们首先将 YOLOv10 与我们的基线模型进行比较,即,YOLOv8。在 N / S / M / L / X 五种变体上,我们的 YOLOv10 实现了 1.2% / 1.4% / 0.5% / 0.3% / 0.5% 的 AP 改进,参数减少了 28% / 36% / 41% / 44% / 57%,计算减少了 23% / 24% / 25% / 27% / 38%,延迟降低了 70% / 65% / 50% / 41% / 37%。与其他 YOLO 相比,YOLOv10 在精度和计算成本之间也表现出了卓越的权衡。具体来说,对于轻量级和小型模型,YOLOv10-N / S 的性能比 YOLOv6-3.0-N / S 高出 1.5 AP 和 2.0 AP,参数减少 51% / 61%,计算量分别减少 41% / 52%。对于中型机型,与 YOLOv9-C / YOLO-MS 相比,YOLOv10-B / M 在相同或更好的性能下分别享受了 46% / 62% 的延迟降低。对于大型模型,与 Gold-YOLO-L 相比,我们的 YOLOv10-L 的参数减少了 68%,延迟降低了 32%,AP 显着提高了 1.4%。此外,与 RT-DETR 相比,YOLOv10 在性能和延迟方面都有了显著的提升。值得注意的是,YOLOv10-S / X 达到 1.8×和 1.3×在相似的性能下,推理速度分别比 RT-DETR-R18 / R101 更快。这些结果很好地证明了 YOLOv10 作为实时端到端检测器的优势。
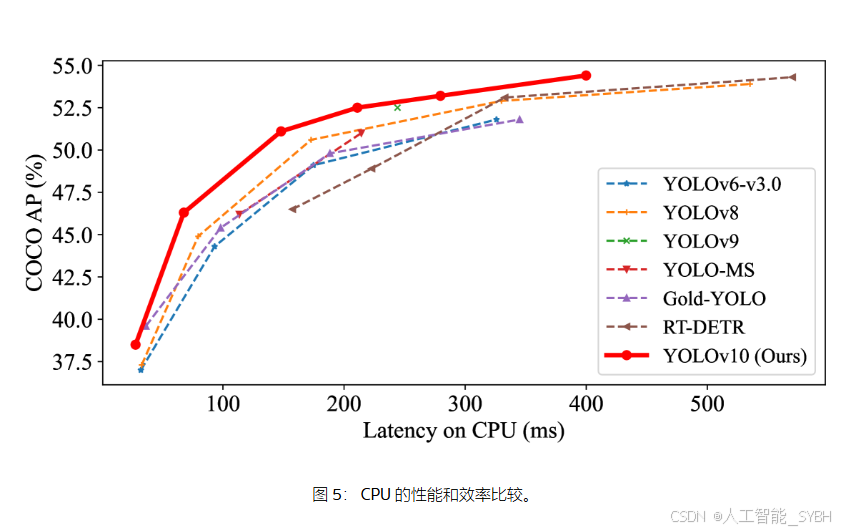
我们还将 YOLOv10 与使用原始一对多训练方法的其他 YOLO 进行了比较。我们考虑了模型正向过程的性能和延迟(Latencyf),则遵循[62,21,60].如表 1 所示,YOLOv10 在不同模型尺度上也展示了最先进的性能和效率,表明了我们建筑设计的有效性。
4.3模型分析
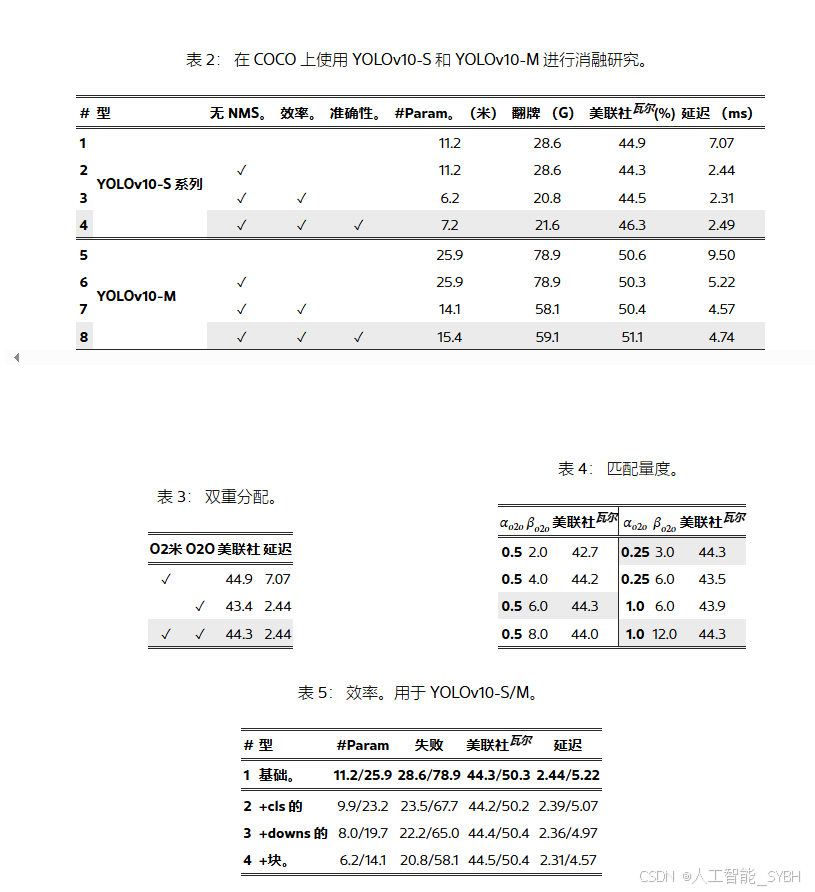
消融研究。我们在表 2 中展示了基于 YOLOv10-S 和 YOLOv10-M 的消融结果。可以观察到,我们的无 NMS 训练和一致的双任务显着降低了 YOLOv10-S 的端到端延迟 4.63ms,同时保持了 44.3% AP 的竞争性能。此外,我们的效率驱动模型设计减少了 11.8 M 参数和 20.8 GFlOPs,YOLOv10-M 的延迟大幅降低了 0.65ms,很好地显示了其有效性。此外,我们的精度驱动模型设计在 YOLOv10-S 和 YOLOv10-M 上实现了 1.8 AP 和 0.7 AP 的显著提升,分别只有 0.18ms 和 0.17ms 的延迟开销,很好地证明了它的优越性。
无 NMS 训练的分析。
- •
双标签分配。我们提出了无 NMS 的 YOLO 的双标签分配,它既可以在训练期间带来对一对多 (o2m) 分支的丰富监督,也可以在推理过程中带来对一 (o2o) 分支的高效。我们基于 YOLOv8-S 验证其优势,即,表 2 中的 #1。具体来说,我们分别引入了仅使用 o2m 分支和仅使用 o2o 分支的训练基线。如表 5 所示,我们的双标签分配实现了最佳的 AP 延迟权衡。
- •
一致性匹配指标。我们引入了一致性匹配指标,使 1 对 1 头与一对多头更加和谐。我们基于 YOLOv8-S 验证其优势,即,表 2 中的 #1,在不同αo2o和βo2o.如表 5 所示,提出的一致性匹配指标,即、αo2o=r⋅αo2m和βo2o=r⋅βo2m可以实现最佳性能,其中αo2m=0.5和βo2m=6.0在一对多头中[21].这种改进可归因于监管差距的减少(方程 2),这改善了两个分支之间的监管一致性。此外,所提出的一致性匹配指标消除了对详尽的超参数调整的需求,这在实际场景中很有吸引力。
- •
与一对多培训相比的性能差距。尽管在无 NMS 训练下实现了卓越的端到端性能,但我们观察到,与使用 NMS 的原始一对多训练相比,仍然存在性能差距,如表 5 和表 1 所示。此外,我们注意到,随着模型大小的增加,间隙会减小。因此,我们合理地得出结论,这种差距可以归因于模型能力的局限性。值得注意的是,与最初使用 NMS 的一对多训练不同,无 NMS 训练需要更多的判别特征才能进行一对一匹配。在 YOLOv10-N 模型的情况下,其有限的容量导致提取的特征缺乏足够的可区分性,从而导致更明显的 1.0% AP 性能差距。相比之下,具有更强能力和更多判别特征的 YOLOv10-X 模型在两种训练策略之间没有表现出性能差距。在图 . 4,我们可视化每个锚点提取的特征与 COCO val 集上所有其他锚点的平均余弦相似性。我们观察到,随着模型大小的增加,锚点之间的特征相似性呈下降趋势,这有利于一对一匹配。基于这一见解,我们将在未来的工作中探索进一步缩小差距并实现更高端到端性能的方法。


5结论
在本文中,我们针对 YOLO 的整个检测管道中的后处理和模型架构。对于后处理,我们提出了一致的无 NMS 训练的双重分配,实现了高效的端到端检测。对于模型架构,我们引入了整体效率-精度驱动的模型设计策略,提高了性能-效率的权衡。这些带来了我们的 YOLOv10,一种新的实时端到端对象检测器。大量实验表明,与其他先进的检测器相比,YOLOv10 实现了最先进的性能和延迟,很好地展示了其优越性。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
通过网盘分享的文件:深度学习YOLO检测系统.rar
链接: https://pan.baidu.com/s/1djUQGeabjziXkgip8xXY4g?pwd=8888 提取码: 8888