Ps:此项目在学习flask,前端,数据库设计相关知识的基础上,参考学习视频教程,并且已经编写相关基础代码和数据库,重点实现项目功能和整合,记录实现项目历程。
项目目录
ok让我们开始吧!
一、hello world!(工欲善其事必先利其器)
(程序猿,从哪里开始,从哪里结束,简单的两个单词是程序猿在冰冷的“0,1”世界里独有的浪漫,向世界的问候,hello world!……)我在写什么?
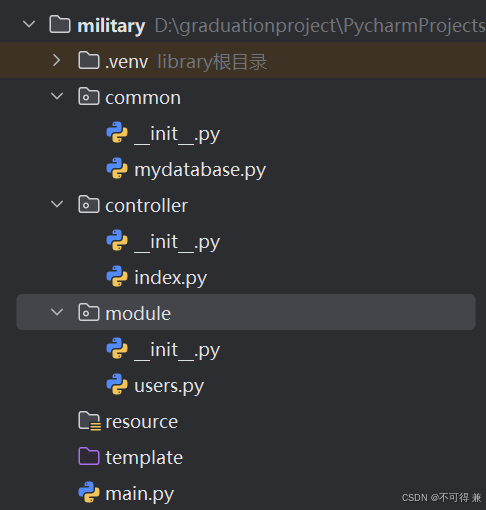
1.创建一个新的python项目(2.12)
新建两个目录文件和两个python软件包
(1)Resource用于存储静态资源、css、图片
(2)Template存放模版
(3)Common公共代码方便被模型、控制器等调用
(4)Module模型
2.一些小问题
因为本人大学期间对于python语言在大学期间学习的知识非常浅,更多的学习c、java,以及c++(c++是真没怎么学明白啊),所以在做项目前突击恶补了一些python知识,在实际操作中遇到的问题,采用的解决方案方式不是最好的或者正确的操作,所以把自己问题和解决问题的方式以引用的方式展示出来,穿插在文章中,仅供参考。
非常希望得到python老手的批评指教!!!
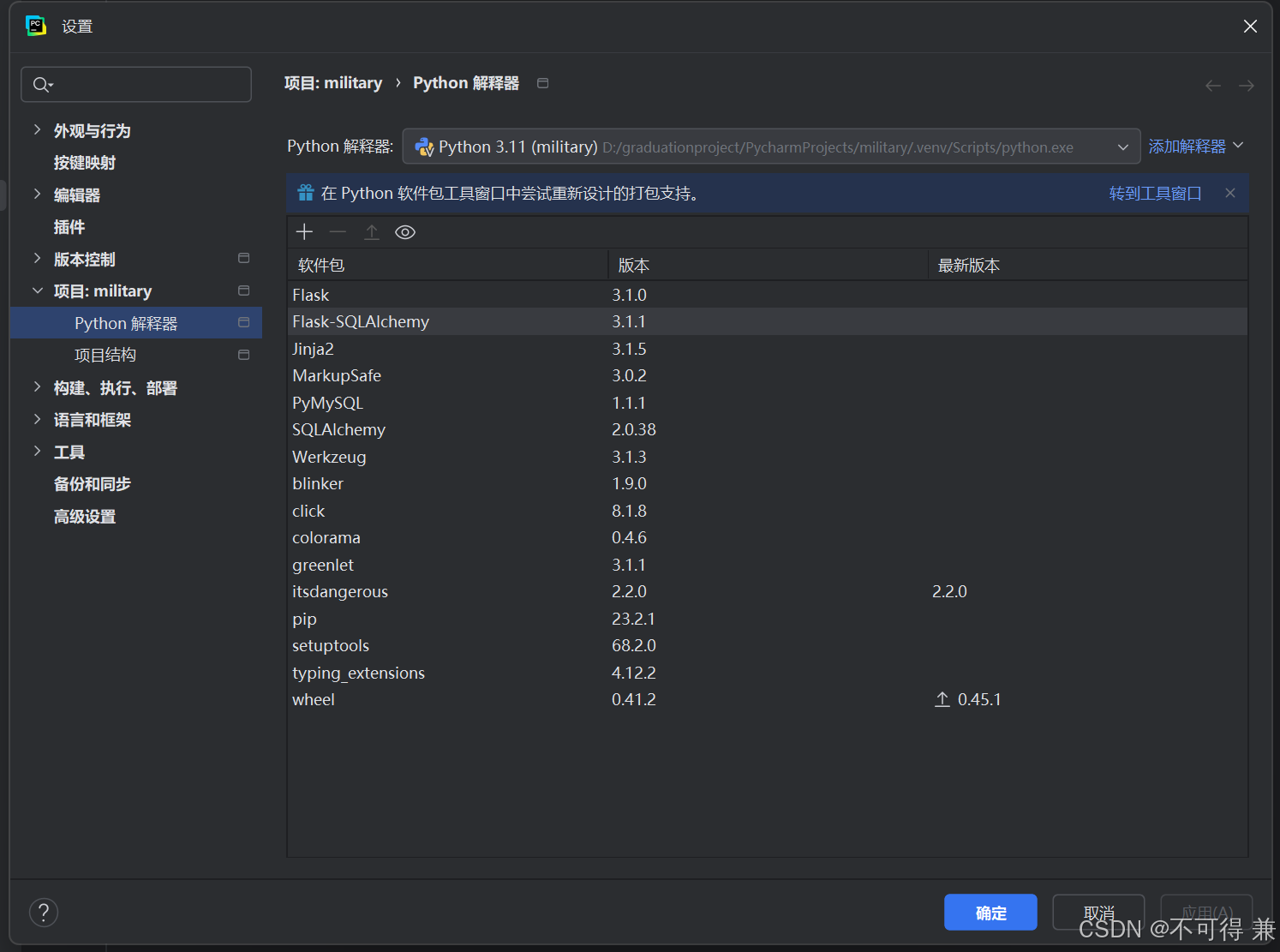
问题1.安装软件包需要手动添加
在代码中自动安装了缺失的安装包后依然报错,整个项目并没有引入安装包还需要手动引入,不知道是不是设置的问题,每次都要二次手动在设置添加。
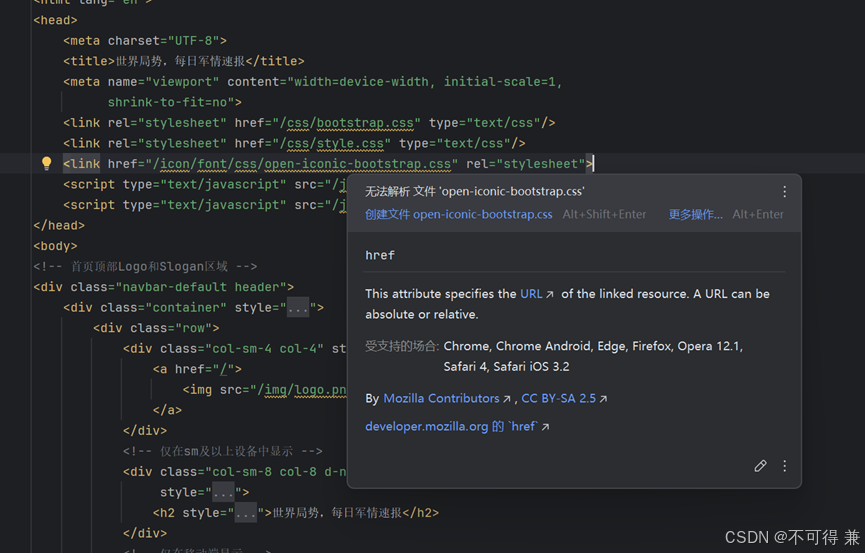
问题2.在设计前端页面时模版文件无法检索
个人推测python新版本需要手动设置文件夹或者目录类型?
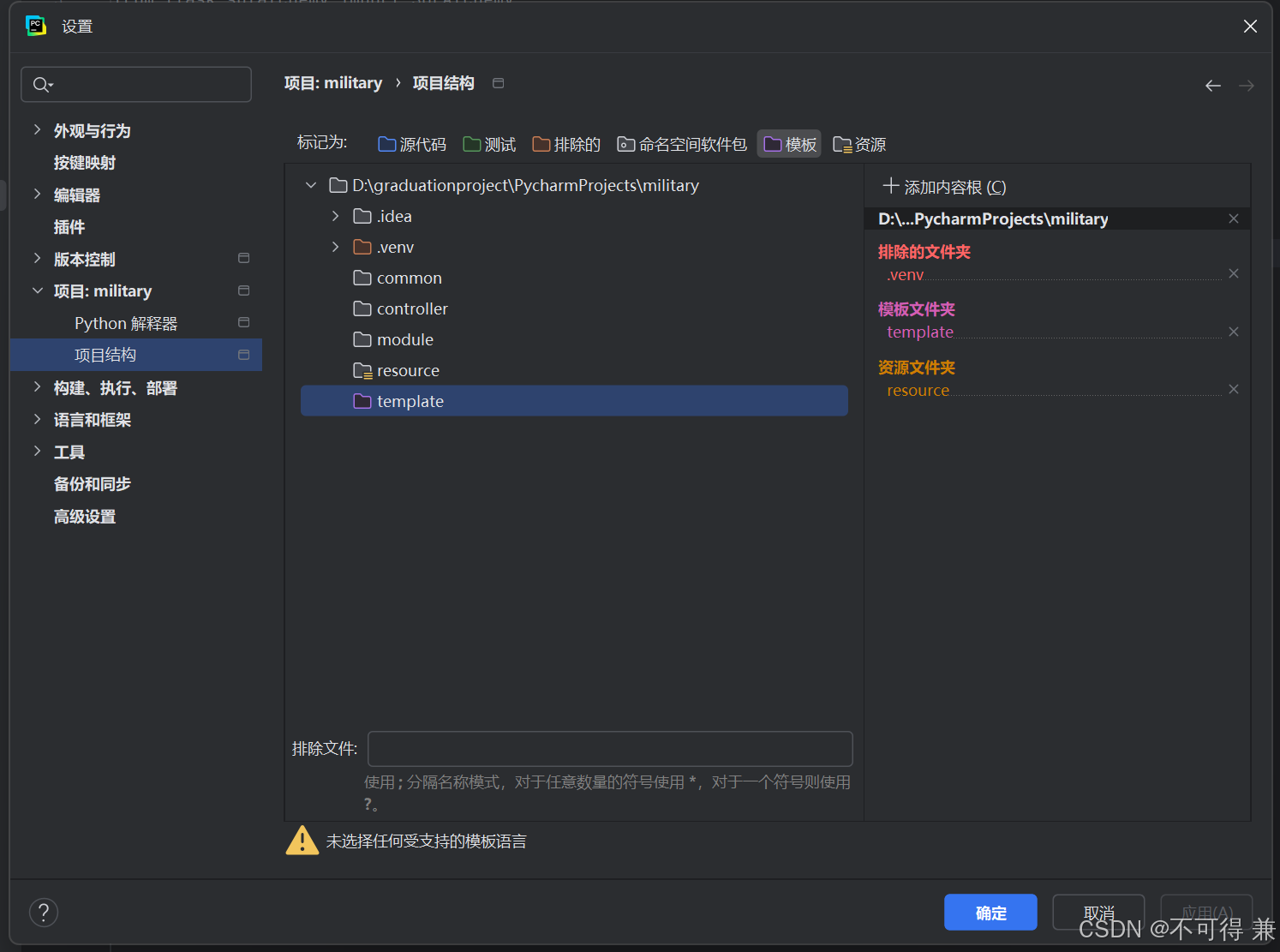
我在设置中无意找到了一个设置文件夹的地方
设置template和resource文件后,文件夹颜色也发生改变,同时也更醒目便于区分,之后就不会报错,静态资源文件也能找到了
二、导入已经编好的代码
1.前端页面,静态资源(2.14)
运行flask文件
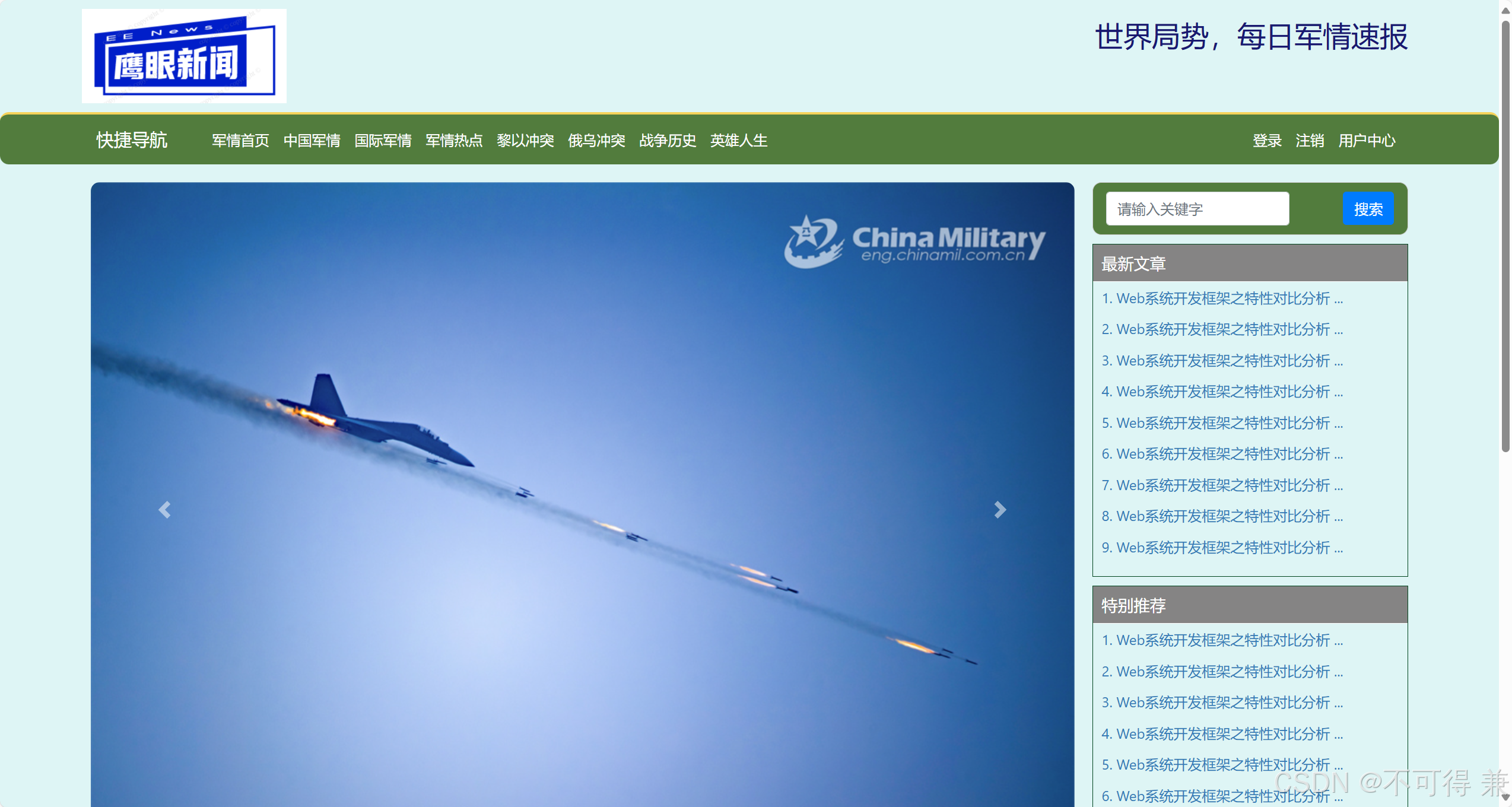
网页效果展示:有点粗糙XD,我要学设计!
2.MVC业务逻辑:
(1)Model层:根据业务需求,来封装数据库操作,用于操作相应数据。
(2)Controller层:接收请求,处理业务,返回响应(HTML,JSON,其他)。
(3)View层:由控制层发起模板页面的填充调用。
3.文章列表功能
先做页面数据库文章内容填充到首页,并以倒序排列:
M层:
#查询所有文章
def find_all(self):
result = dbsession.query(Article).all()
#根据id查询文章
def find_by_id(self,articleid):
row = dbsession.query(Article).filter(Article.id==articleid).first()
return row
#指定分页的limit和offset,同时与用户表做连接查询
def find_limited_with_user(self,start,count):
result = dbsession.query(Article,Users).join(Users,Users.userid==Article.userid)\
.order_by(Article.userid.desc()).limit(count).offset(start).all()
return result
V层:
@index.route('/')
def home():
article = Article()
result = article.find_limited_with_user(0,10)
return render_template('index.html',result=result)
C层:
先在首页循环显示一篇文章,看看效果:

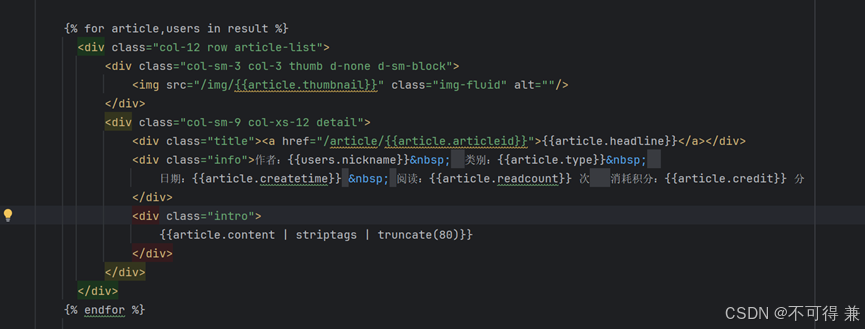
将之前html页面中固定的文章内容换成数据库内容
4.文章分页和分类(2.15)
(1)分页逻辑:根据路由地址参数,page1为第0-9共10篇文章,page2为10-19
使用math.ceil()库函数统计
学习python取数操作:https://blog.csdn.net/zuihongyan518/article/details/96978200
@index.route('/page/<int:page>')
def page(page):
start = (page - 1) * 10
article = Article()
result = article.find_limit_with_users(start,10)
return render_template('index.html',result=result)
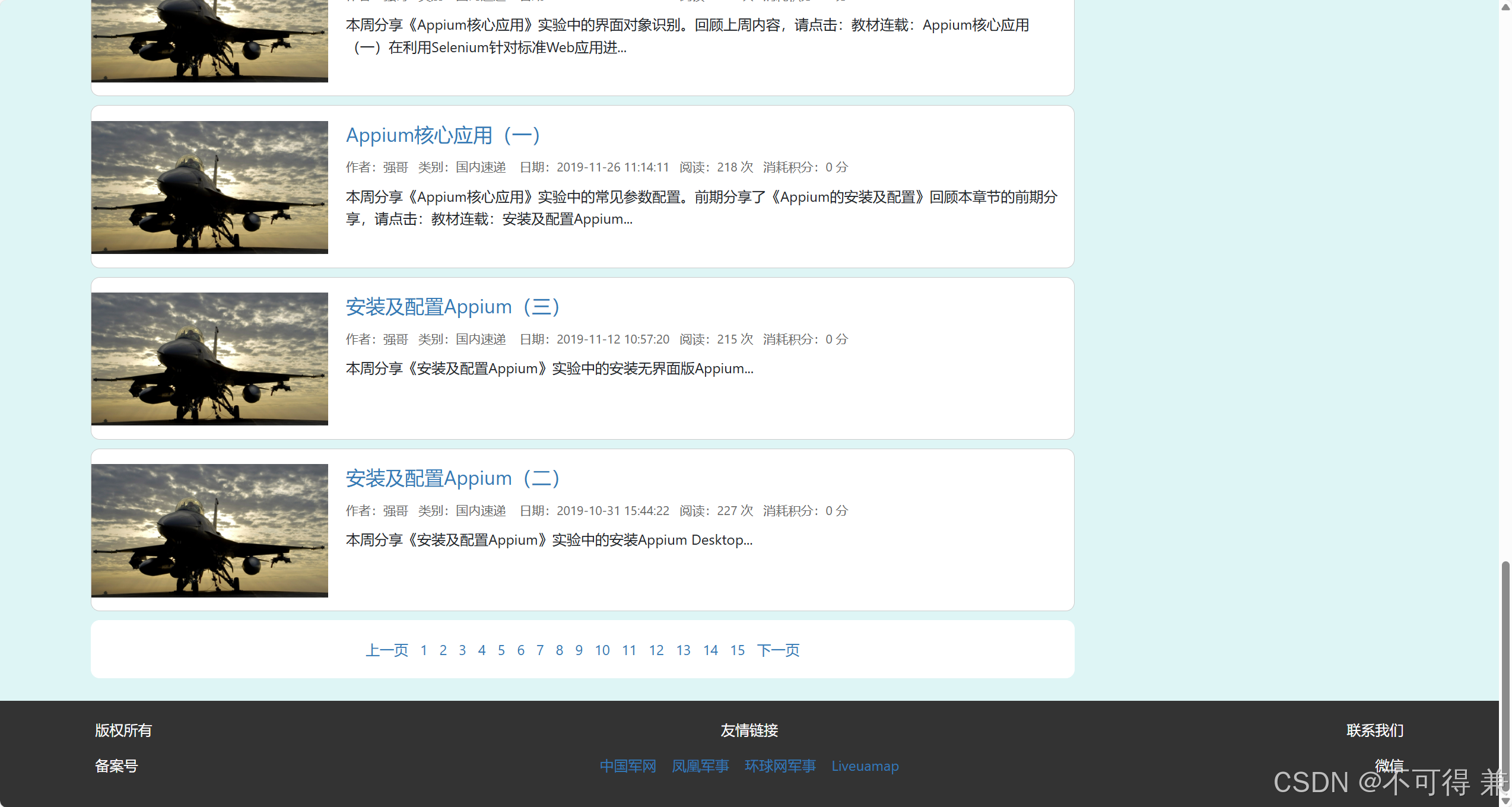
细节修改:分页栏修改
根据每页十篇,计算数据库文章总数,过滤掉草稿、隐藏和待审核文章,只计算发布文章总数文章,向上取整作为分页栏页数。
#统计当前文章总数
def get_total_count(self):
count = dbsession.query(Article).filter(Article.hidden==0,Article.drafted==0,Article.checked==1).count()
return count
(2)上下页功能
细节处理:第一页没有上一页,最后一页没有下一页,所以需要先获取当前页是第几页,再进行判断
<div class="col-12 paginate">
{% if page==1 %}
<a href="/page/1">上一页</a>
{% else %}
<a href="/page/{{page-1}}">上一页</a>
{% endif %}
{% for i in range(total) %}
<a href="/page/{{i+1}}">{{i+1}}</a>
{% endfor %}
{% if page==total%}
<a href="/page/{{total}}">下一页</a>
{% else %}
<a href="/page/{{page+1}}">下一页</a>
{% endif %}
</div>
(3)文章分类,首页标题跳转
添加新的路由地址,新建一个type.html页面,函数方法类似,增加type标签限制。
实现首页标签模块跳转,再对跳转上下页进行细节修改。
<div class="navbar-nav">
<!-- <a class="nav-item nav-link" href="#">军情首页</a>-->
<!-- <a class="nav-item nav-link" href="#">中国军情</a>-->
<!-- <a class="nav-item nav-link" href="#">国际军情</a>-->
<!-- <a class="nav-item nav-link" href="#">军情热点</a>-->
<!-- <a class="nav-item nav-link" href="#">黎以冲突</a>-->
<!-- <a class="nav-item nav-link" href="#">俄乌冲突</a>-->
<!-- <a class="nav-item nav-link" href="#">战争历史</a>-->
<!-- <a class="nav-item nav-link" href="#">英雄人生</a>-->
{% for k,v in article_type.items() %}
<a class="nav-item nav-link" href="/type/{{k}}-1">{{v}}</a>
{% endfor %}
</div>
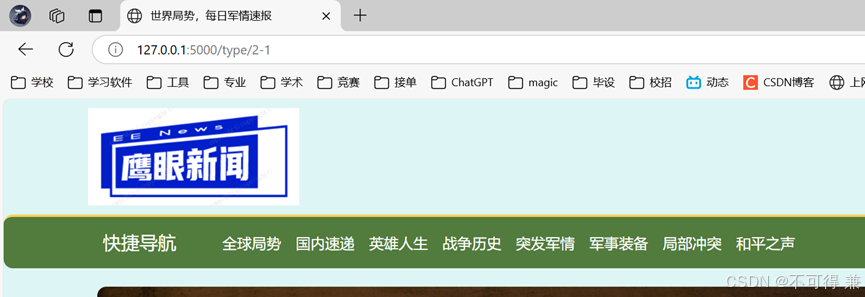
5.文章搜索和推荐功能(2.16)
同样逻辑对标题使用模糊搜索,统计获得的文章数量
#根据文章标题模糊搜索
def find_by_headline(self,headline,start,count):
result = dbsession.query(Article,Users.nickname).join(Users,Users.userid==Article.userid)\
.filter(Article.hidden==0,Article.drafted==0,Article.checked==1,Article.headline.like('%'+headline+'%'))\
.order_by(Article.articleid.desc()).limit(count).offset(start).all()
return result
#统计分页总数量
def get_count_by_headline(self,headline):
count = dbsession.query(Article).filter(Article.headline.like('%'+headline+'%'),
Article.drafted==0,
Article.checked==1,
Article.hidden==0
).count()
return count
搜索到三篇标题带有web的文章,观察路由地址正确显示
启用搜索按钮
<script>
function doSearch() {
var keyword = $("#search").val();
location.href = '/search/1-'+keyword;
}
</script>
三、优化前端页面
1.重写truncate(2.17)
为解决侧边栏文章标题在截取时,一个中文字符和一个英文字母都占一个字符,而导致长短不一的问题。
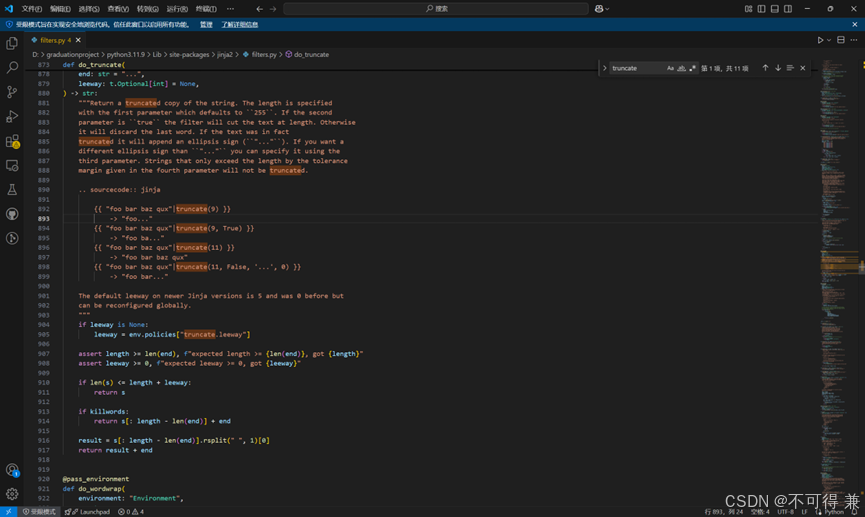
(1)改truncate库函数源代码
找到truncate函数:
修改第三方库源代码的弊端,在本地可以运行吗,但是无法移植,尽量采用自定义的方式
(2)自定义过滤器
#自定义过滤器truncate
def mytruncate(s,length, end='...'):
count = 0
new = ''
for c in s:
new += c
if ord(c) <128:
count += 0.5
else:
count += 1
if count > length:
break
return new + end
#注册mytruncate过滤器
app.jinja_env.filters.update(truncate=mytruncate)
正常显示

2.JavaScript渲染(2.18)
后端渲染,可以在html看到文内容,方便搜索引擎爬取文字进行搜索。
通过前端:使用JavaScript动态填充DOM元素(JSON)对搜索引擎不友好,但页面简洁代码可读性高且速度较快,分担服务器压力。
前后端分离可以有效的取舍,根据不同情境采用不同渲染方式,使效率达到最高
新建一个html页面
修改侧边栏的显示代码,增加一个id值便于前端找到
问题3:
flask2.2.2,jsonify序列化sqlalchemy返回的row对象时报:Object of type Row is not JSON serializable
Flask-SQLAlchemy3.0.3,还是返回row对象,而且flask2.2.3中的jsonify删除了sqlalchemy_jsonify模块,不能序列化row对象
新版本的flask需要通过row._asdict()转换成字典后再格式化为嵌套数组才能被jsonify序列化,这里卡了我很久,flask根本没有向下兼容
@index.route('/recommend')
def recommend():
article = Article()
last, most, recommended = article.find_last_most_recommended()
# 将每个结果集转换为字典列表
last_list = [row._asdict() for row in last]
most_list = [row._asdict() for row in most]
recommended_list = [row._asdict() for row in recommended]
formatted_last = [[item['articleid'], item['headline']] for item in last_list]
return jsonify(formatted_last)
此时查看网页源码发现没有文章标题,与后端jinja2渲染不同
同理可以写一个控制标题长度的前端truncate的函数

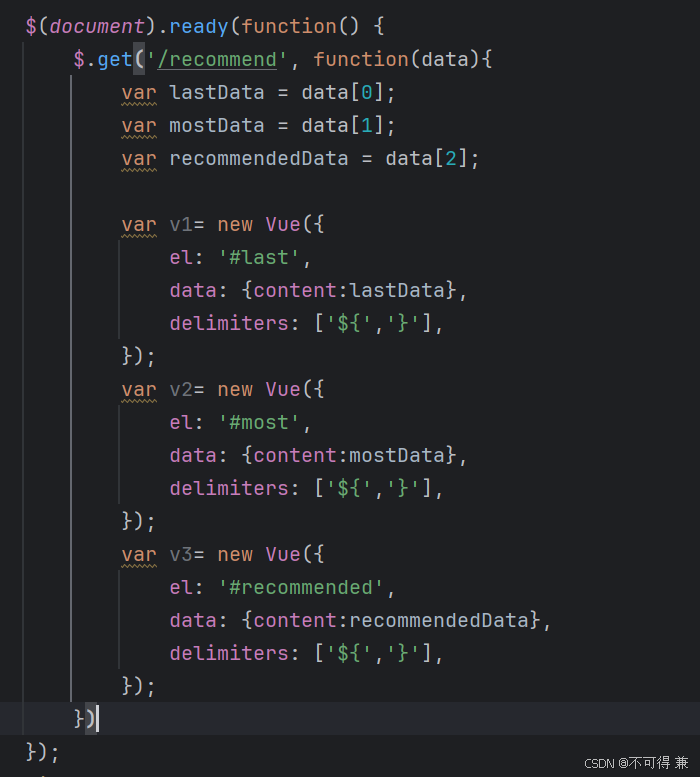
3.Vue渲染
类似于jinja2后台渲染逻辑,使用vue前端性能快,代码可读性强
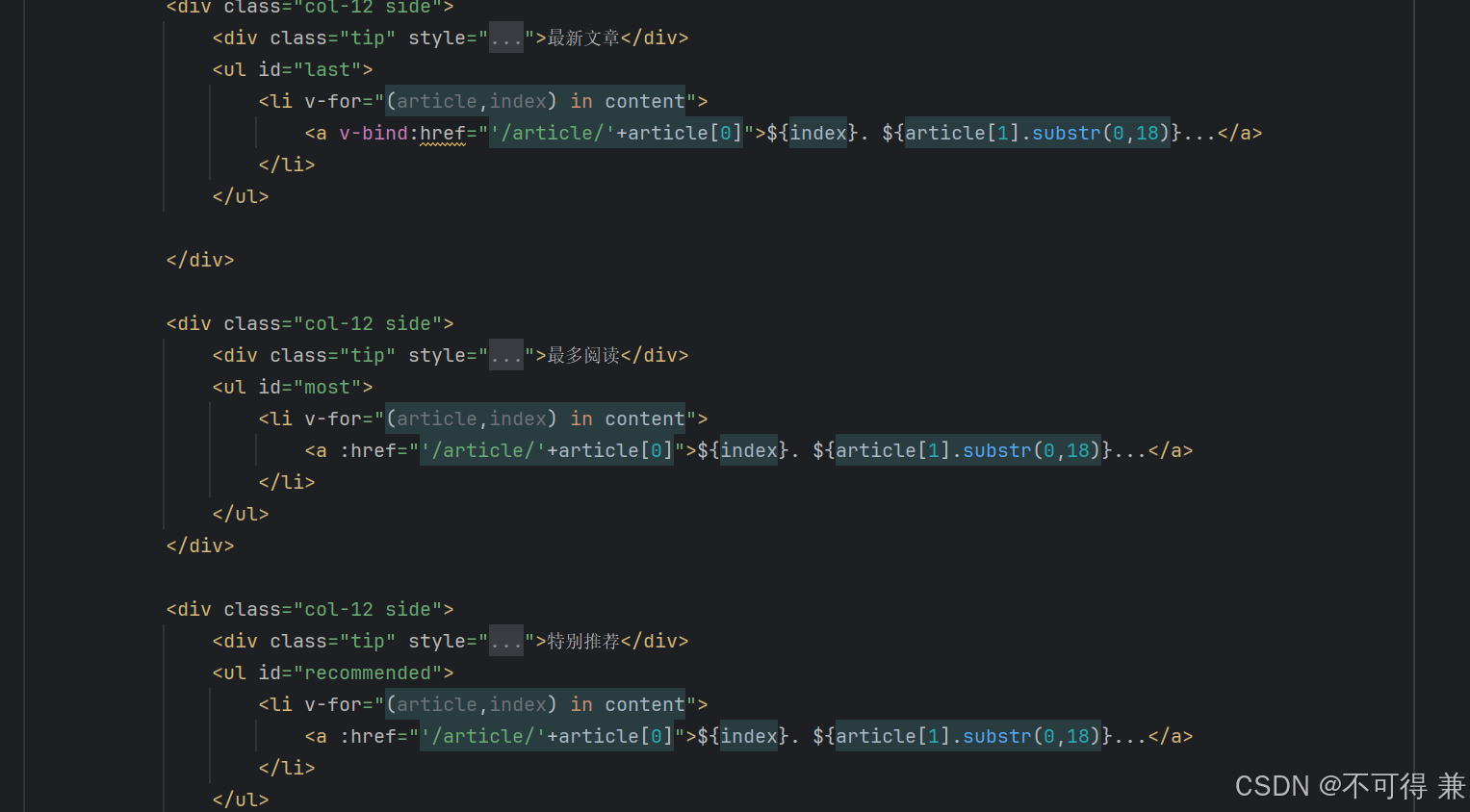
未完待续
目前part1进度大概30%