1基本理论
1.1概念体系
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以按照我们设置的规则自动化爬取网络上的信息,这些规则被称为爬虫算法。是一种自动化程序,用于从互联网上抓取数据。爬虫通过模拟浏览器的行为,访问网页并提取信息。这些信息可以是结构化的数据(如表格数据),也可以是非结构化的文本。爬虫任务的执行流程通常包括发送HTTP请求、解析HTML文档、提取所需数据等步骤。
1.2技术体系
1请求库:用于向目标网站发送HTTP请求。常用的请求库包括requests、httplib、urllib等。这些库可以帮助我们模拟浏览器行为,发送GET、POST等请求,并处理响应内容。
2.解析库:用于解析HTML或XML文档,提取出我们需要的数据。常用的解析库包括BeautifulSoup、lxml、pyquery等。这些库可以帮助我们根据HTML文档的结构和标签,提取出我们需要的数据。
3.存储库:用于将爬取到的数据存储到本地或数据库中。常用的存储库包括sqlite3、mysql-connector-python、pymongo等。这些库可以帮助我们将数据存储到关系型数据库或非关系型数据库中,以便后续分析和利用。
2.代码编写流程
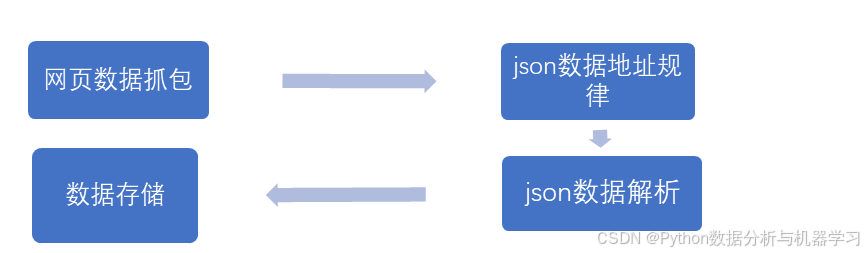
代码编写流程
代码共分为4部分,1网页数据抓包。2json数据地址规律,3json数据解析,数据存储。
2.1.网页抓包与地址规律
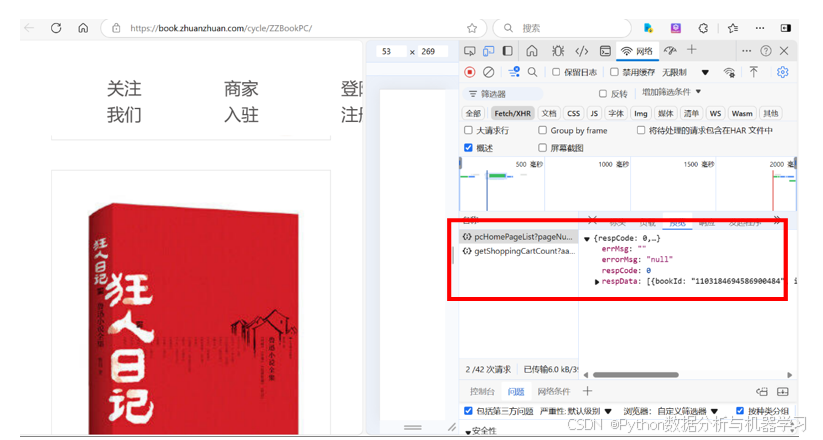
通过网页抓包,解析到json数据。
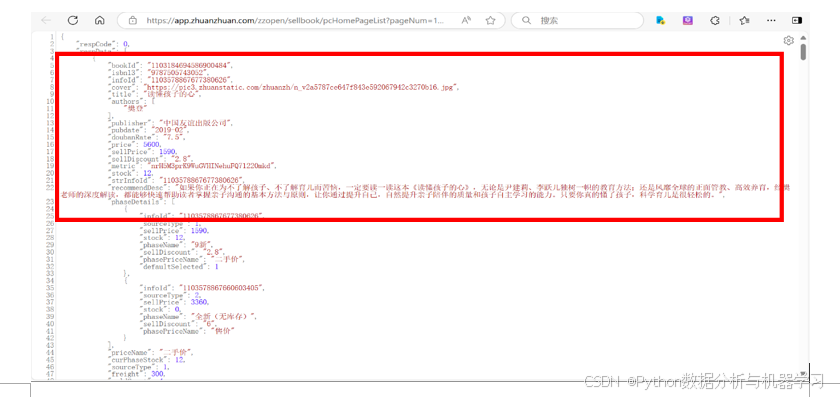
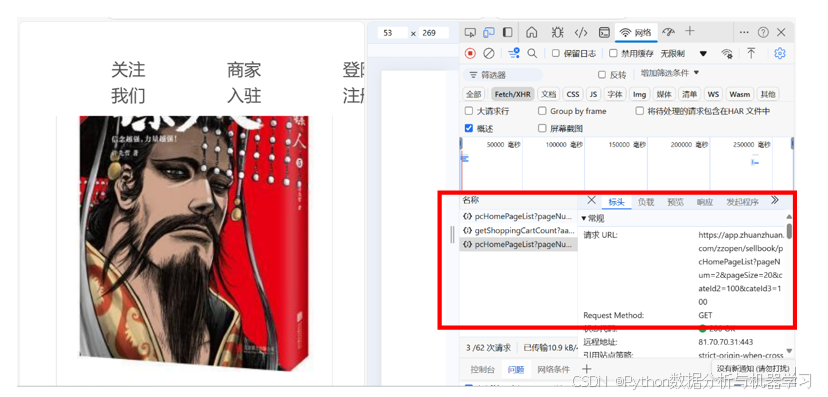
加入该网页,红色线框中的数据,是要爬取的数据
对网页刷新,发现抓包的数据增加,如下图
Json数据如下
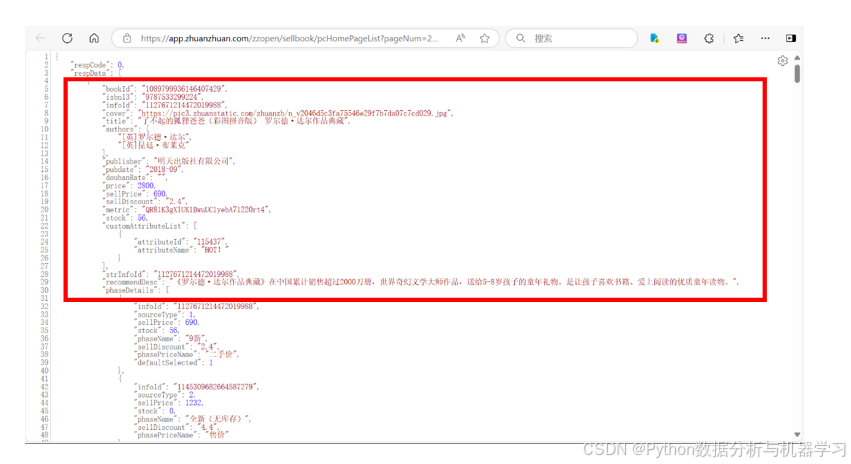
对上面地址分析,发现地址中pageNum数值发生改变,第一页位数为1,第二页位数为2
依次类推。
编写翻页函数

函数中为中pageNum页面地址位数
2.2.页面解析
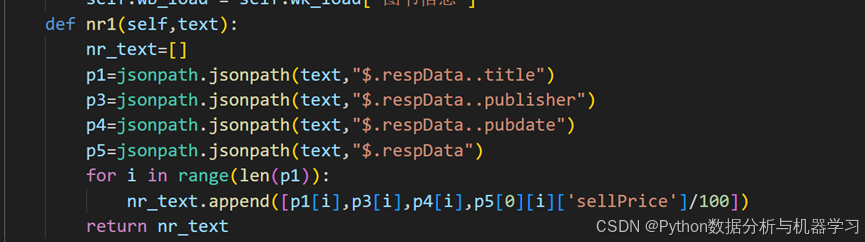
2.3.网页数据保存

3.应用举例
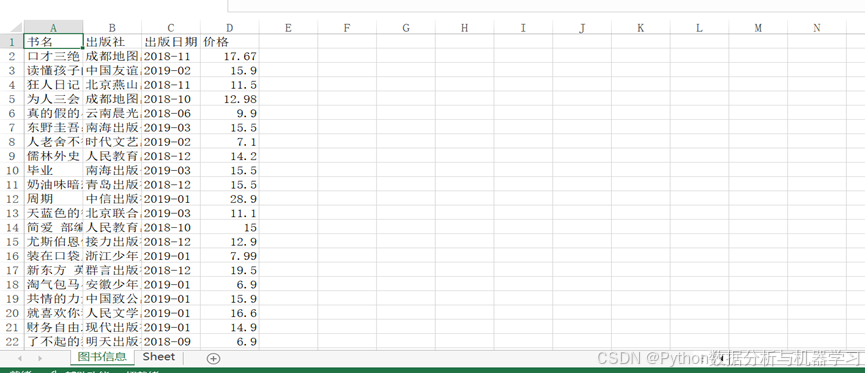
输出结果
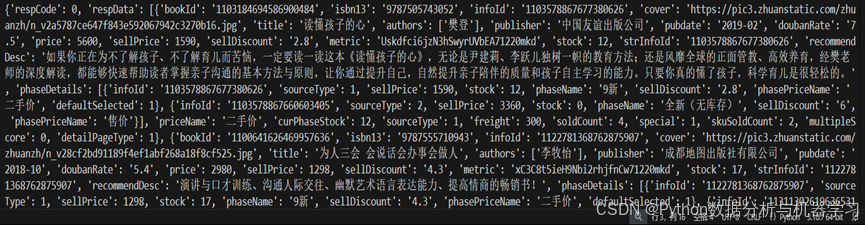
通过上面代码测试,输出结果为每本书的相关数据,利用json查找语法解析json数据,将书籍书籍写入excel数据表中
4.编写代码
import requests
from openpyxl import Workbook,load_workbook
import os
import jsonpath
import json
def wy_text(x):
res=requests.get(url='https://app.zhuanzhuan.com/zzopen/sellbook/pcHomePageList?pageNum={}&pageSize=20&cateId2=100&cateId3=100'.format(x))
sss=json.loads(res.text)
return sss
class Excel_write():
def __init__(self):
self.excel_file = "转转图书信息.xlsx"
if not os.path.exists(self.excel_file):
self.wk = Workbook();#创建excel工作薄
self.wk.create_sheet("图书信息",0);#sheet表名,位置(从0开始)
# 默认选择当前活跃选项卡
self.wb =self.wk['图书信息']
self.wb.append(["书名",'出版社','出版日期','价格']);#横向插入数据
self.wk.save(self.excel_file)
self.wk_load = load_workbook(filename=self.excel_file)
self.wb_load = self.wk_load['图书信息']
def nr1(self,text):
nr_text=[]
p1=jsonpath.jsonpath(text,"$.respData..title")
p3=jsonpath.jsonpath(text,"$.respData..publisher")
p4=jsonpath.jsonpath(text,"$.respData..pubdate")
p5=jsonpath.jsonpath(text,"$.respData")
for i in range(len(p1)):
nr_text.append([p1[i],p3[i],p4[i],p5[0][i]['sellPrice']/100])
return nr_text
def nr_write(self):
for i in range(1,40):
s=wy_text(i)#类中调用外部函数
list=Excel_write().nr1(s)#类中函数相互调用,注意外部或内部self参数都不用加
for k in range(len(list)):
self.wb_load.append(list[k])
self.wk_load.save(filename=self.excel_file)
if __name__=="__main__":
Excel_write().nr_write()
运行结果