文章目录
原文章
0. 写在前面
0.1. 预备知识
1️⃣最邻近搜索:给定数据库 U U U中的 n n n个对象(子集),以及输入的查询点 q q q
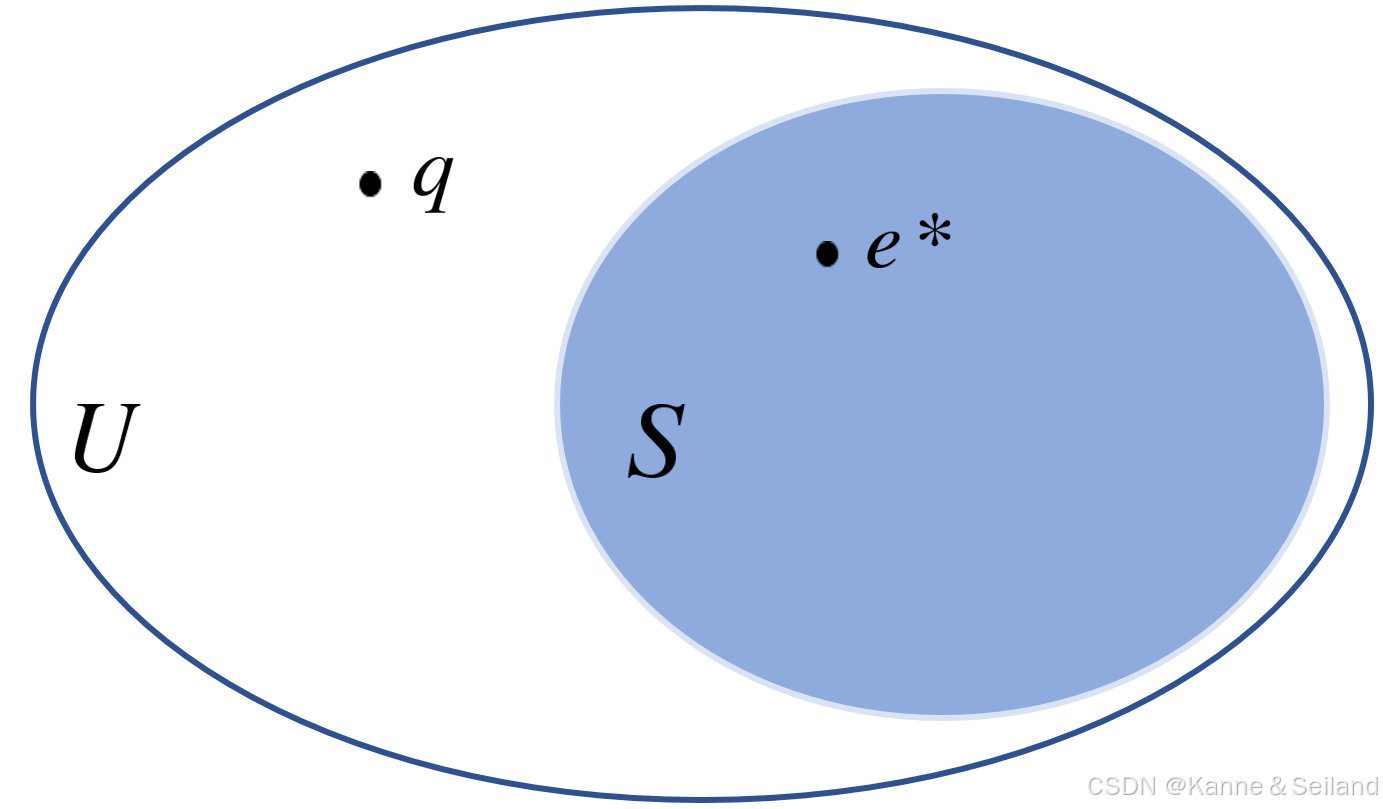
- 精确定义( NN \text{NN} NN):返回 e ∗ ∈ S e^*\in{S} e∗∈S满足 dist ( q , e ∗ ) = min e ∈ S dist ( q , e ) \text{dist}(q, e^*) = \min\limits_{e \in S} \text{dist}(q, e) dist(q,e∗)=e∈Smindist(q,e)
- 近似定义( c-ANN \text{c-ANN} c-ANN):返回 e ∈ S e\in{S} e∈S满足 dist ( q , e ) ≤ c ∗ dist ( q , e ∗ ) \text{dist}(q, e)\leq{}c*\text{dist}(q, e^*) dist(q,e)≤c∗dist(q,e∗)
2️⃣倍增维度
- 直径:点集中距离最远的两点的距离,即 diam ( X ) = sup e 1 , e 2 ∈ X dist ( e 1 , e 2 ) \text{diam}(X)=\displaystyle\sup_{e_1, e_2 \in X} \text{dist}\left(e_1, e_2\right) diam(X)=e1,e2∈Xsupdist(e1,e2)
- 2 λ - 2^{\lambda}\text{-} 2λ-分割: X X X可被分为 m m m个子集 X 1 X 2 . . . X m X_1X_2...X_m X1X2...Xm,且满足 { m ≤ 2 λ diam ( X i ) ≤ 1 2 diam ( X ) \begin{cases}m\leq{}2^{\lambda}\\\\\text{diam}(X_i)\leq{}\cfrac{1}{2}\text{diam}(X)\end{cases} ⎩ ⎨ ⎧m≤2λdiam(Xi)≤21diam(X)
- 倍增维度:就是 λ m i n \lambda_{min} λmin,即用最少 2 λ m i n 2^{\lambda_{min}} 2λmin个半径不超过 1 2 r X \cfrac{1}{2}r_{_X} 21rX的球体填满 X X X
3️⃣球体的一个性质:任何球体 B ( e , r ) B(e, r) B(e,r) 都可被至多 O ( k d ) O\left(k^d\right) O(kd) 个半径为 r c \cfrac{r}{c} cr 的球体覆盖
0.2. 一些记号
符号 含义 ( X , D ) (X, D) (X,D) 基础度量空间, X X X为点集 D D D为距离类型 D ( u , v ) D(u, v) D(u,v) P = { x 1 , … , x n } P = \{x_1, \ldots, x_n\} P={x1,…,xn}中的俩点 x u x_u xu和 x v x_v xv的距离 B ( p , r ) B(p, r) B(p,r) 以 p ∈ X p \in X p∈X为球心 r r r为半径的球 Δ \Delta Δ 点集中最远俩点 / 最近俩点的比值 d d d 倍增维度 0.3. 本文的研究概述
1️⃣背景:很多 c-ANN \text{c-ANN} c-ANN算法比如 HNSW/NSG/DiskANN \text{HNSW/NSG/DiskANN} HNSW/NSG/DiskANN在基准数据集上性能不错,但其下界不可知
2️⃣研究成果
- 最坏情况上界:对于 DiskANN \text{DiskANN} DiskANN慢处理版,可在 O ( log α Δ ( α − 1 ) ϵ ) O\left(\log _\alpha \cfrac{\Delta}{(\alpha-1) \epsilon}\right) O(logα(α−1)ϵΔ)步返回 ( α + 1 α − 1 + ϵ ) -ANN \left(\cfrac{\alpha+1}{\alpha-1}+\epsilon\right)\text{-ANN} (α−1α+1+ϵ)-ANN
- 但值得注意, DiskANN \text{DiskANN} DiskANN慢处理的图构建复杂度高达 O ( n 3 ) O(n^3) O(n3)
- 最坏情况下界:对于 DiskANN \text{DiskANN} DiskANN块预处理版/ HNSW \text{HNSW} HNSW/ NSG \text{NSG} NSG,算法找到 5 5 5个最邻近前至少要走 0.1 n 0.1n 0.1n步
3️⃣未来的研究方向:有没有一种算法,预处理和查询都低于线性复杂度 ? ? ?
1. DiskANN \text{DiskANN} DiskANN回顾
1.0. Intro
🤔是个啥:基于邻近图的贪婪搜索的,一种解决 c-ANN \text{c-ANN} c-ANN的算法
🙉基本思路
- 在数据库中的点集 P P P上创建有向图 G = ( V , E ) G=(V, E) G=(V,E),其中 V V V与 P P P关联
- 给定带查询点 q q q,从起始点 s ∈ V s\in{}V s∈V开始对图 G G G执行搜索
- 预期搜索返回 q q q的最邻近点
1.1. DiskANN \text{DiskANN} DiskANN的基本操作
1️⃣连接操作 RobustPruning ( v , U , α , R ) \text{RobustPruning}(v, U, \alpha, R) RobustPruning(v,U,α,R),用于图的构建过程
- 参数含义
符号 含义 v v v 当前处理的图中的顶点 U U U v v v的备选邻居(预计最终与 v v v连接的点) α \alpha α 修剪参数,一定大于 1 1 1 R R R 结点出度的限制,即 v v v至多有几个邻居 - 连接过程
- 排序:将 U U U所有元素按离 v v v的距离从近到远排序
- 遍历:开始遍历并处理每个 u ∈ U u\in{}U u∈U
- 修剪:对 u ∈ U u\in{}U u∈U,删除满足 D ( u , u ′ ) ⋅ α < D ( v , u ′ ) D(u, u^{\prime}) \cdot \alpha < D(v, u^{\prime}) D(u,u′)⋅α<D(v,u′)的点 u ′ u^{\prime} u′,余下的点总体离 v v v更近
- 连接:让 v v v与所有 U U U中所有剩下点连接
2️⃣搜索操作 GreedySearch ( s , q , L ) \text{GreedySearch}(s, q, L) GreedySearch(s,q,L)
- 参数含义
符号 含义 s s s 图 G G G中,搜索的起始点 q q q 给定带查询点 q q q L L L 维护队列的最大长度,这也是搜索算法扫描结点数量的下界 - 辅助数据结构:当前队列 A A A,已访问点集 U U U
- 搜索过程
- 初始化: A = { s } A=\{s\} A={s}, U = ∅ U=\varnothing U=∅
- 扫描与剪裁:循环执行访问 + + +剪裁,直到 A A A中所有点都被访问
- 访问:选取 A A A中距离 q q q最近的未访问点 v → { A = A ∪ N o u t ( v ) , 将邻居全部加入 A U = U ∪ v , 表示 v 已经被访问 v\to\begin{cases}A=A\cup{}N_{out}(v)\,,将邻居全部加入A\\\\U=U\cup{}v\,,表示v已经被访问\end{cases} v→⎩ ⎨ ⎧A=A∪Nout(v),将邻居全部加入AU=U∪v,表示v已经被访问
- 裁剪:当 A A A队列长度超出 L L L后,保留其中 L L L个与 q q q最近的点
- 排序输出:输出 A A A排序后的前 k k k个点
1.2. DiskANN \text{DiskANN} DiskANN的构建操作
1️⃣慢预处理:对所有 v ∈ V v\in{}V v∈V执行 RobustPruning ( v , V , α , ∣ V ∣ ) \text{RobustPruning}(v, V, \alpha, |V|) RobustPruning(v,V,α,∣V∣)
2️⃣快预处理操作
- 初始化:对所有结点 V V V执行 R R R重构建,即每个点随意连接 R R R个顶点
- 第一遍遍历
- 起始:任选一 s s s开始,随机访问其后继 v v v
- 搜索:对 v v v执行 U = GreedySearch ( s , v , L ) U=\text{GreedySearch}(s, v, L) U=GreedySearch(s,v,L)得到 U U U(可能与 v v v最邻近的点集)
- 修剪:对得到的 U U U执行 RobustPruning ( v , U , α , n ) \text{RobustPruning}(v, U, \alpha, n) RobustPruning(v,U,α,n)修剪其中离 v v v较远的点
- 连接:将 v v v与修剪后 U U U的所有结点相连
- 再修剪:如果 u ∈ U u\in{}U u∈U度数超过 R R R,则执行 RobustPruning ( u , N out ( u ) , α , R ) \text{RobustPruning}(u, N_{\text{out}}(u), \alpha, R) RobustPruning(u,Nout(u),α,R)修剪 u u u邻居
- 第二遍遍历:对第一次遍历所得结果,同样的操作在遍历一次
2. 对于慢处理 DiskANN \text{DiskANN} DiskANN的理论分析
2.1. 预处理分析
1️⃣ α - \alpha\text{-} α-捷径可达性
- 顶点 α - \alpha\text{-} α-捷径可达 ⇔ \xLeftrightarrow{} 满足二者之一 ∀ q ∈ V → { 直连: ( p , q ) ∈ E 捷径连接: ∃ p ′ 满足 { ( p , p ′ ) ∈ E D ( p ′ , q ) ≤ D ( p , q ) α \forall{}q\in{}V\to{}\begin{cases}直连\text{: }(p, q) \in E\\\\捷径连接\text{: }\exist{}p^{\prime}满足\begin{cases}(p, p') \in E\\\\D(p', q) \leq \cfrac{D(p, q)}{\alpha}\end{cases}\end{cases} ∀q∈V→⎩ ⎨ ⎧直连: (p,q)∈E捷径连接: ∃p′满足⎩ ⎨ ⎧(p,p′)∈ED(p′,q)≤αD(p,q)
- ∀ p ∈ G \forall{}p\in{}G ∀p∈G都具有 α - \alpha\text{-} α-捷径可达性,则称 G G G具有 α - \alpha\text{-} α-捷径可达性
2️⃣预处理分析
- 时间复杂度: O ( n 3 ) O\left(n^3\right) O(n3)
- 捷径可达性:慢处理构建的图具有捷径可达性
- 稀疏性:
- 记 p p p执行 RobustPruning ( p , V , α , n ) \text{RobustPruning}(p, V, \alpha, n) RobustPruning(p,V,α,n)后 p p p所连接点数量为 ∣ U ( p ) ∣ |U(p)| ∣U(p)∣则 ∣ U ( p ) ∣ ⩽ O ( ( 4 α ) d log Δ ) |U(p)|\leqslant O\left((4 \alpha)^d \log \Delta\right) ∣U(p)∣⩽O((4α)dlogΔ)
- 证明思路大致为:引入环形区域 → \to →覆盖 → \to →剩余点范围受限于倍增维度
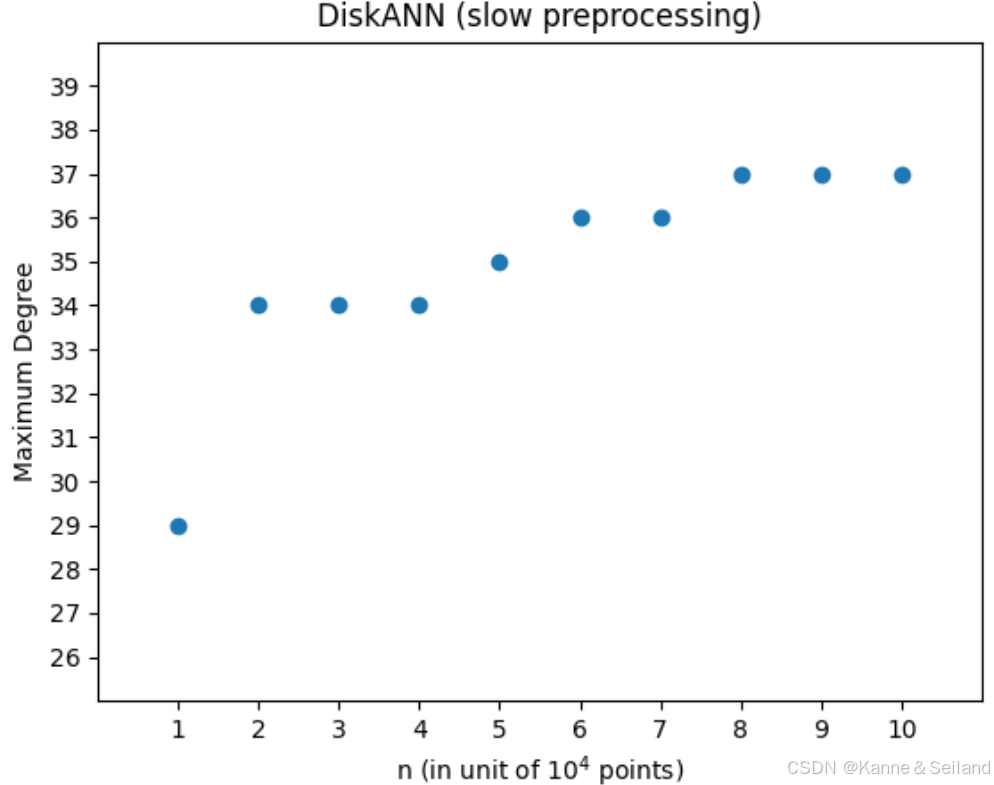
- 在后续实验中,可以看出慢预处理的 DiskANN \text{DiskANN} DiskANN相当稀疏
2.2. 查询分析
1️⃣结论:从 G G G中任一点 s s s开始执行 GreedySearch ( s , q , 1 ) \text{GreedySearch}(s, q, 1) GreedySearch(s,q,1)
- 能在 O ( log α Δ ( α − 1 ) ϵ ) O\left(\log _\alpha \cfrac{\Delta}{(\alpha-1) \epsilon}\right) O(logα(α−1)ϵΔ)步内返回 ( α + 1 α − 1 + ϵ ) - \left(\cfrac{\alpha+1}{\alpha-1}+\epsilon\right)\text{-} (α−1α+1+ϵ)-近似邻居
- P.s. \text{P.s. } P.s. 每步最多检查 ∣ U ∣ ⩽ O ( ( 4 α ) d log Δ ) |U|\leqslant O\left((4 \alpha)^d \log \Delta\right) ∣U∣⩽O((4α)dlogΔ) 个邻居,即每步最多 O ( ( 4 α ) d log Δ ) O\left((4 \alpha)^d \log \Delta\right) O((4α)dlogΔ)时间
2️⃣证明思路大致为
- 通过三角不等式和 α - \alpha\text{-} α-捷径可达性,得出每一步的距离 d i d_i di 的上界
- 分析三种情况的查询步数
D ( s , q ) D(s, q) D(s,q) D ( a , q ) D(a, q) D(a,q) 分析思路 远 远 + + +近 通过初步不等式得出 d i d_i di与 D ( a , q ) D(a, q) D(a,q) 关系 → \to →算法在 log α 2 ϵ \log _\alpha \cfrac{2}{\epsilon} logαϵ2步内结束 近 远 通过上下界 → \to{} →算法在 O ( log α Δ ( α − 1 ) ϵ ) O\left(\log _\alpha \frac{\Delta}{(\alpha-1) \epsilon}\right) O(logα(α−1)ϵΔ)步内结束 近 近 通过不等式结合 D min D_{\min} Dmin和 D max D_{\max} Dmax → \to{} →算法在 O ( log α Δ ) O\left(\log _\alpha \Delta\right) O(logαΔ)步内结束
- 注意 D ( a , q ) D(a, q) D(a,q)中 a a a表示 q q q的最邻近点
3️⃣后续实验中,慢处理的 DiskANN \text{DiskANN} DiskANN在难例上,甚至只需要两步就找到最邻近
2.3. 对复杂度的紧致性分析
1️⃣收敛率的严格下界:在 O ( log α Δ ( α − 1 ) ϵ ) O\left(\log _\alpha \cfrac{\Delta}{(\alpha-1) \epsilon}\right) O(logα(α−1)ϵΔ)步中不可将 log Δ \log \Delta logΔ换为 log n \log n logn,证明思路如下
- 构造一个一维度量空间满足 ∣ P ∣ = n = 2 k − 1 |P|=n=2k-1 ∣P∣=n=2k−1且 Δ = O ( α n ) \Delta=O(\alpha^n) Δ=O(αn)
- 证明:给定查询点 q q q并执行 GreedySearch \text{GreedySearch} GreedySearch,找到 q q q的 O ( 1 ) -ANN O(1)\text{-ANN} O(1)-ANN至少要扫描 Ω ( log Δ ) \Omega(\log \Delta) Ω(logΔ)或 O ( n ) O(n) O(n)个点
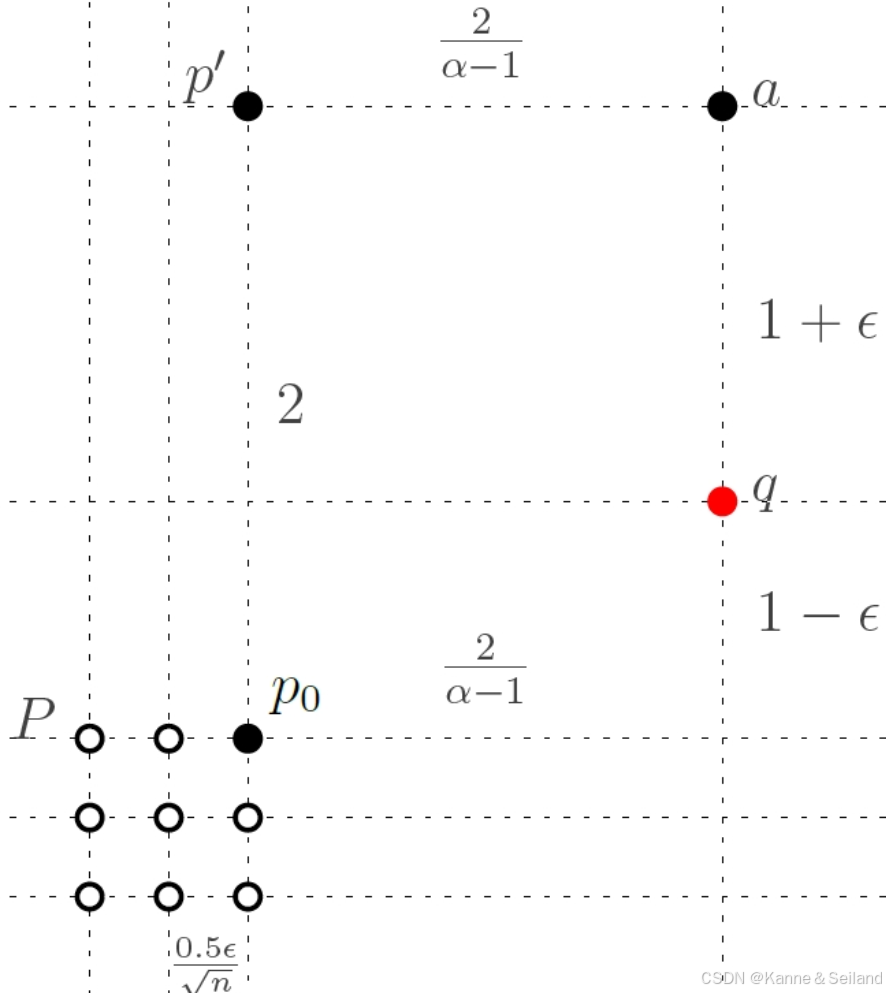
2️⃣紧密的近似下限: α + 1 α − 1 -ANN \cfrac{\alpha+1}{\alpha-1}\text{-ANN} α−1α+1-ANN的比例具有紧,证明思路如下
- 构建一个简单实例
- 证明在上述实例中,执行 DiskANN \text{DiskANN} DiskANN慢预处理版至少要扫描 n n n个点,才能找到一个 α + 1 α − 1 -ANN \cfrac{\alpha+1}{\alpha-1}\text{-ANN} α−1α+1-ANN
- 思路:从 s ∈ P s\in{}P s∈P开始扫描 → n \to{}n →n步贪婪搜索后出不了 P P P → \to →无法接近最邻近 a → a\to a→至少扫描 n n n点
3. 对于快处理 DiskANN \text{DiskANN} DiskANN(及其他算法)的实验
3.1. 快处理 DiskANN \text{DiskANN} DiskANN的实验
1️⃣构建的难实例
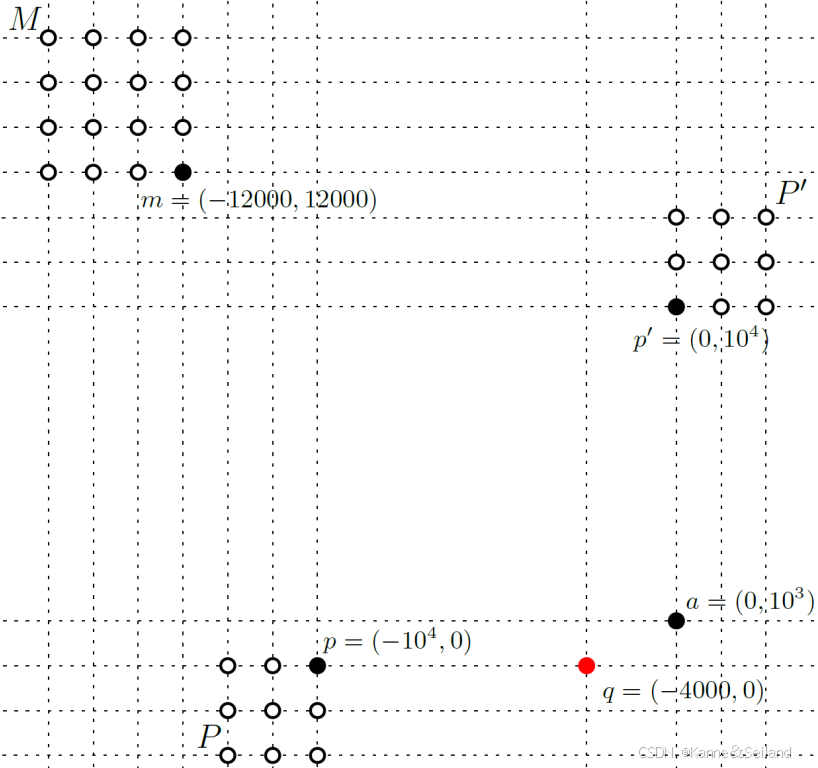
2️⃣实验结果:执行查询试图输出 5 5 5个最邻近
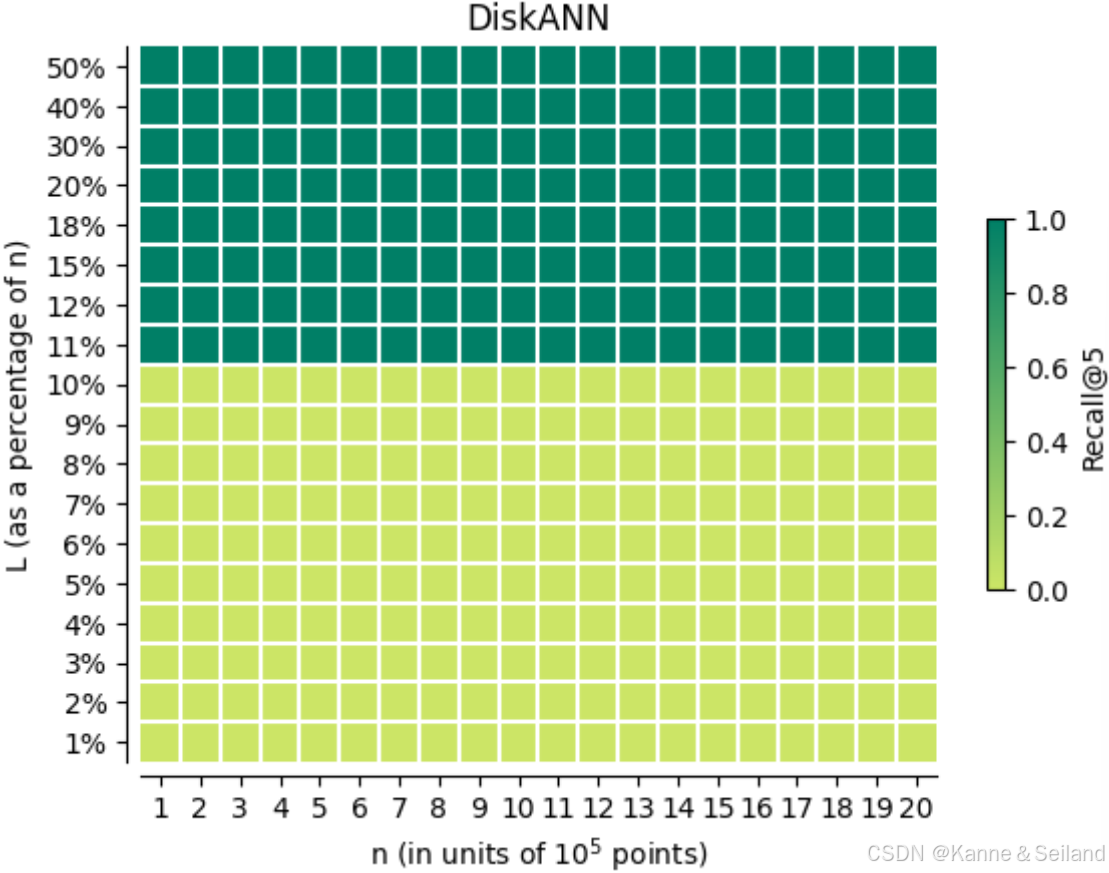
- 召回率(结果中实际最邻近点的比率)在 L ≈ 10 % L \approx 10 \% L≈10%处发生剧变
- 至少需要扫描 10 % 10\% 10%的点才能使召回率非 0 0 0,即查询的时间复杂度为 O ( 0.1 n ) O(0.1n) O(0.1n)
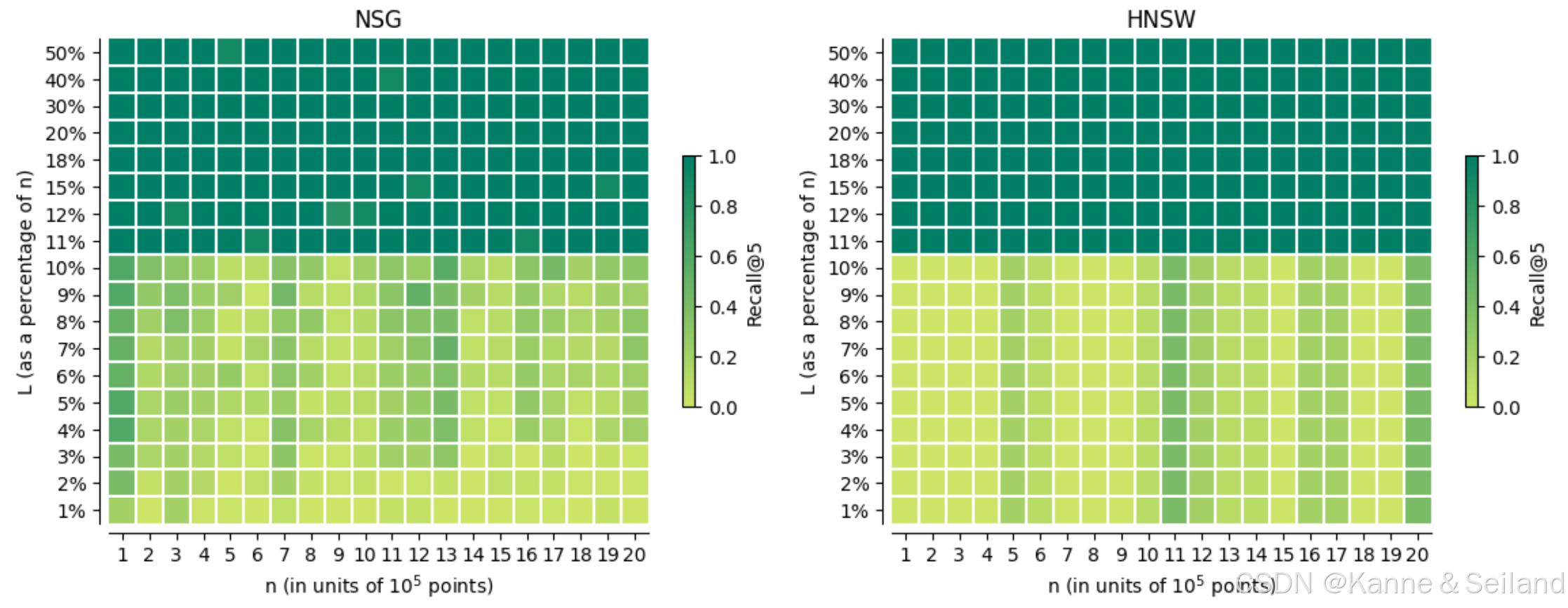
3.2. NSG/HNSW \text{NSG/HNSW} NSG/HNSW算法的实验
1️⃣构建的难例:
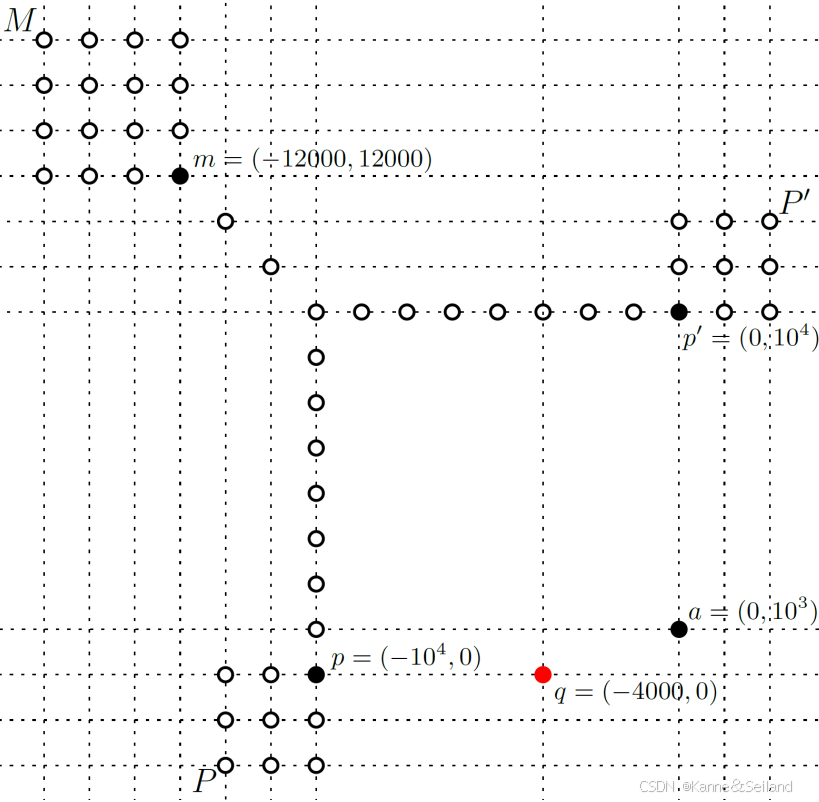
2️⃣同样也是,至少要扫描 10 % 10\% 10%的点才能使召回率达标
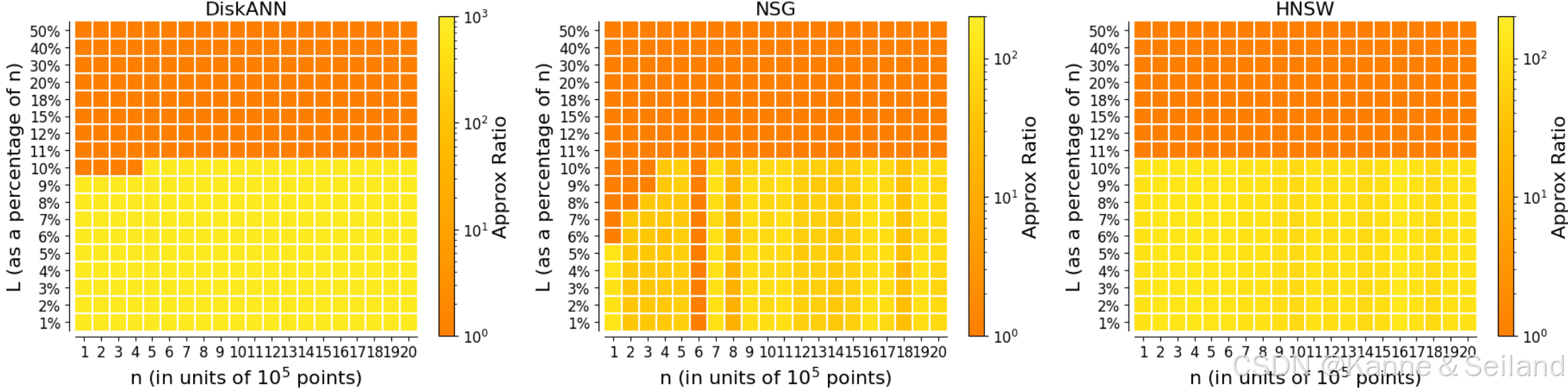
3.3. 交叉对比
1️⃣为三个算法构建同样的难例
2️⃣结果:依然是需要扫描至少 0.1 n 0.1n 0.1n个点
3.4. 其它算法上的实验
1️⃣构建难例,给定 L = 0.1 n L=0.1n L=0.1n,运行结果(召回率)如下表(截取)
DiskANN NSG HNSW NGT SSG KGraph 0.0 0.0 0.0 0.27 0.27 0.27 0.1 0.1 0.1 0.05 0.05 0.05 0.16 0.16 0.16 0.42 0.42 0.42 2️⃣分析:说明 0.1 n 0.1n 0.1n很可能就是这些算法的下界