目录
Pandas 是一个强大的 Python 库,主要用于数据分析和数据处理。它提供了两种主要的数据结构:Series 和 DataFrame。
Series
Series 是一个一维的标签数组,它可以容纳任何数据类型(整数、字符串、浮点数、Python对象等)。Series 的轴标签统称为索引
创建 Series
import pandas as pd
# 使用列表创建 Series
s = pd.Series([1, 3, 5, np.nan, 6, 8])
访问数据
# 访问第一个元素
print(s[0])
# 切片访问多个元素
print(s[0:3])
DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame 的轴索引包括行索引和列索引。
创建 DataFrame
data = {'Name': ['Tom', 'Nick', 'John', 'Tom'],
'Age': [20, 21, 19, 20]}
df = pd.DataFrame(data)
读取 CSV 文件
df = pd.read_csv('path/to/yourfile.csv')
写入 CSV 文件
df.to_csv('path/to/newfile.csv', index=False)
基本操作
查看前几行:
print(df.head())查看后几行:
print(df.tail())描述性统计:
print(df.describe())选择列:
print(df['Name'])选择行:
print(df[df['Age'] > 20])条件筛选:
mask = df['Name'] == 'Tom'
print(df[mask])排序:
print(df.sort_values(by='Age'))合并数据:
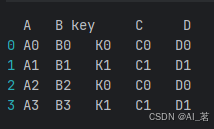
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']})
df2 = pd.DataFrame({'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])
result = pd.merge(df1, df2, left_on='key', right_index=True)