目录
4.Hive SQL-DML-select查询-语法书和环境准备
5.Hive SQL-DML-select查询-列表达式和distinct去重
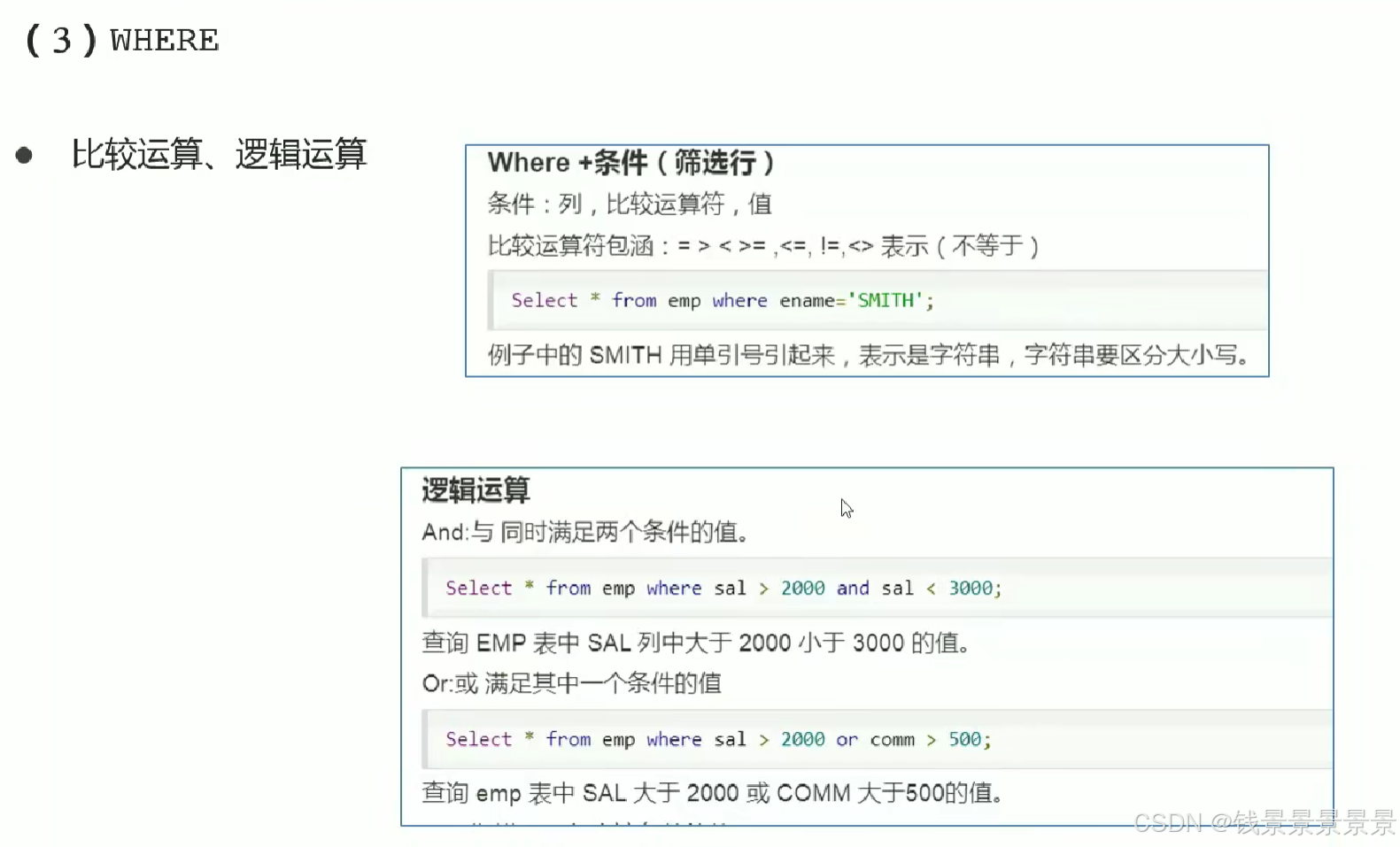
6.Hive SQL-DML-select查询-where条件过滤
7.Hive SQL-DML-select查询-聚合操作aggregate
8.Hive SQL-DML-select查询-group by分组及语法限制
9.Hive SQL-DML-select查询-having过滤操作
10.Hive SQL-DML-select查询-order by排序
11.Hive SQL-DML-select查询-limit限制语法
12.Hive SQL-DML-select查询-梳理执行顺序
6.基于hive数仓实现需求开发--SQL编写思路与指标计算part1
7.基于hive数仓实现需求开发--SQL编写思路与指标计算part2
8.基于hive数仓实现需求开发--SQL编写思路与指标计算part3
12.基于fineBI实现可视化报表-地图、雷达、柱状图构建
13.基于fineBI实现可视化报表-饼图、词云、趋势图构建
第五部分(Apache Hive DML语句和函数使用)
1.课程内容大纲和学习目标



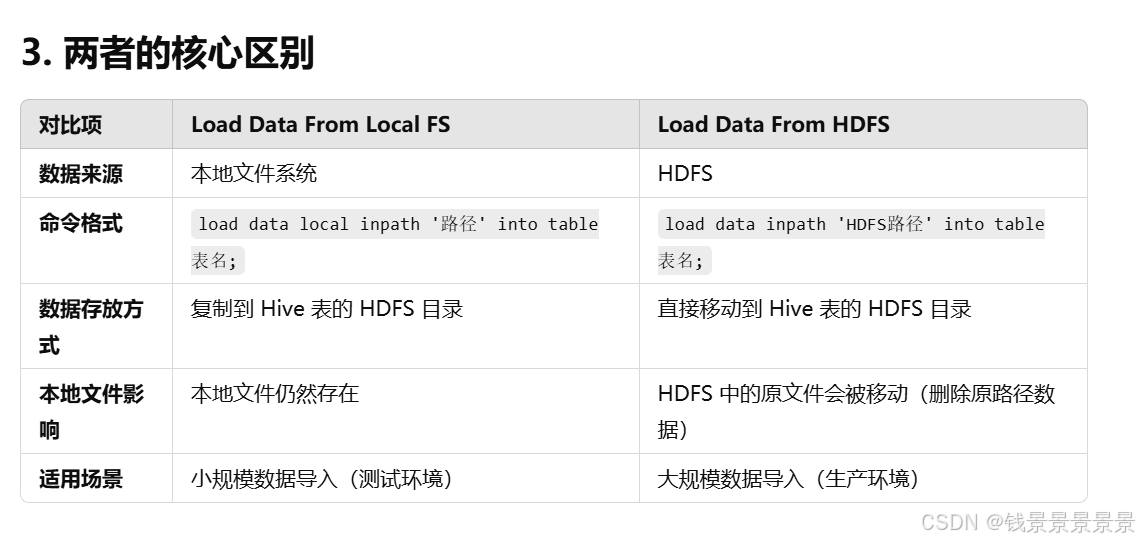
2.Hive SQL-DML-load加载数据操作

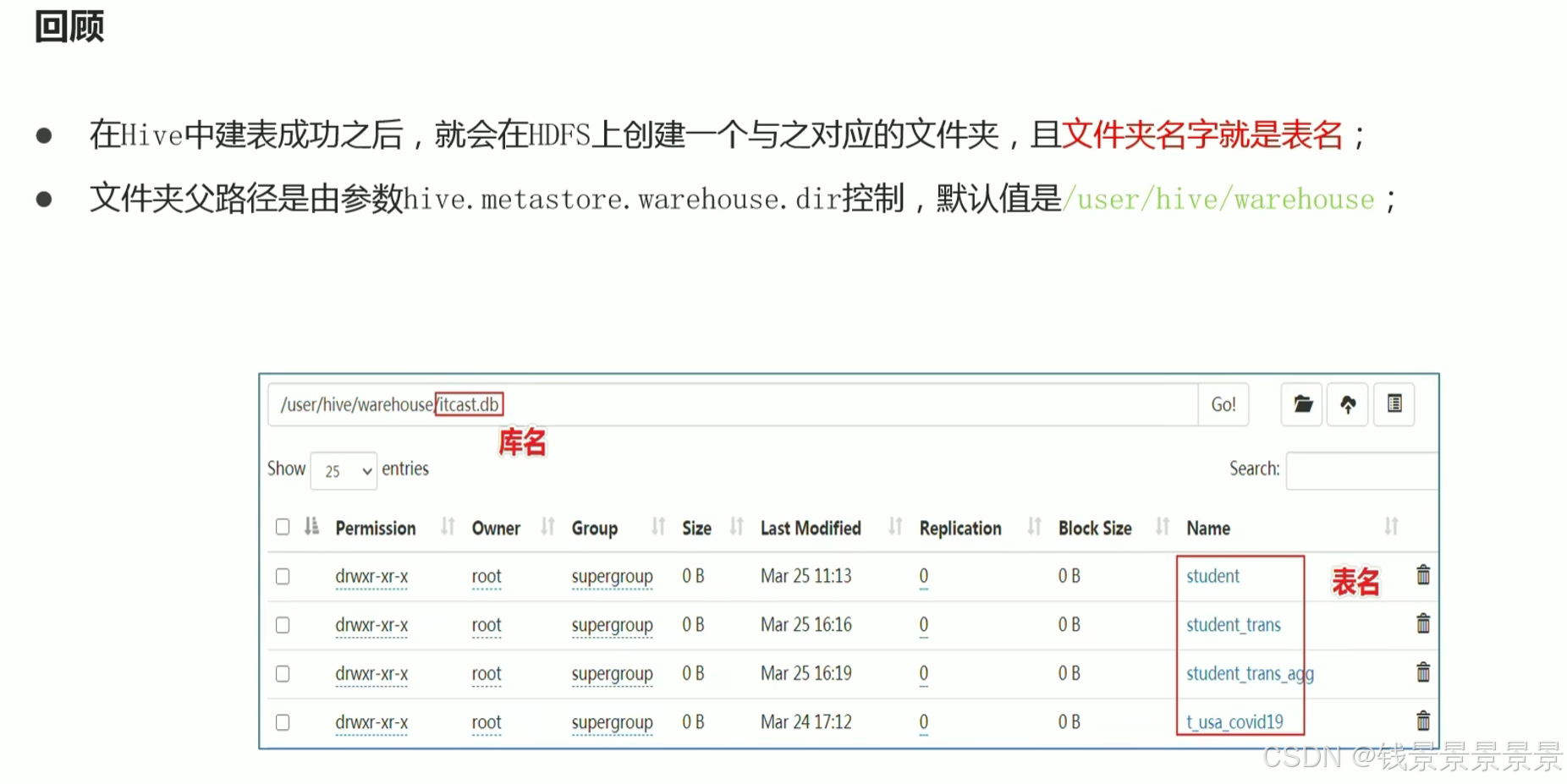
下面我们随机创建文件尝试一下
先创建一个hivedata文件夹
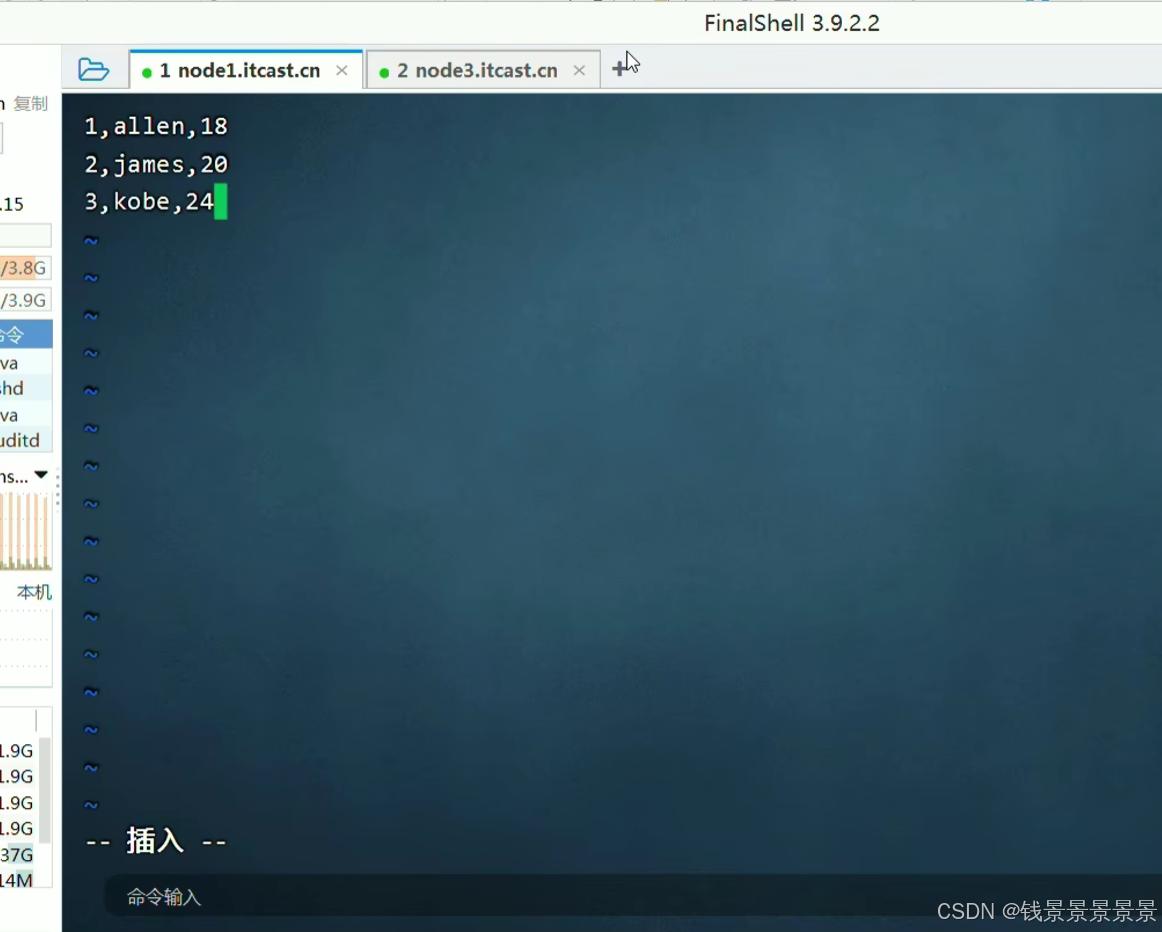
在这个文件夹中写一个1.txt文件
下面使用beeline创建一张表
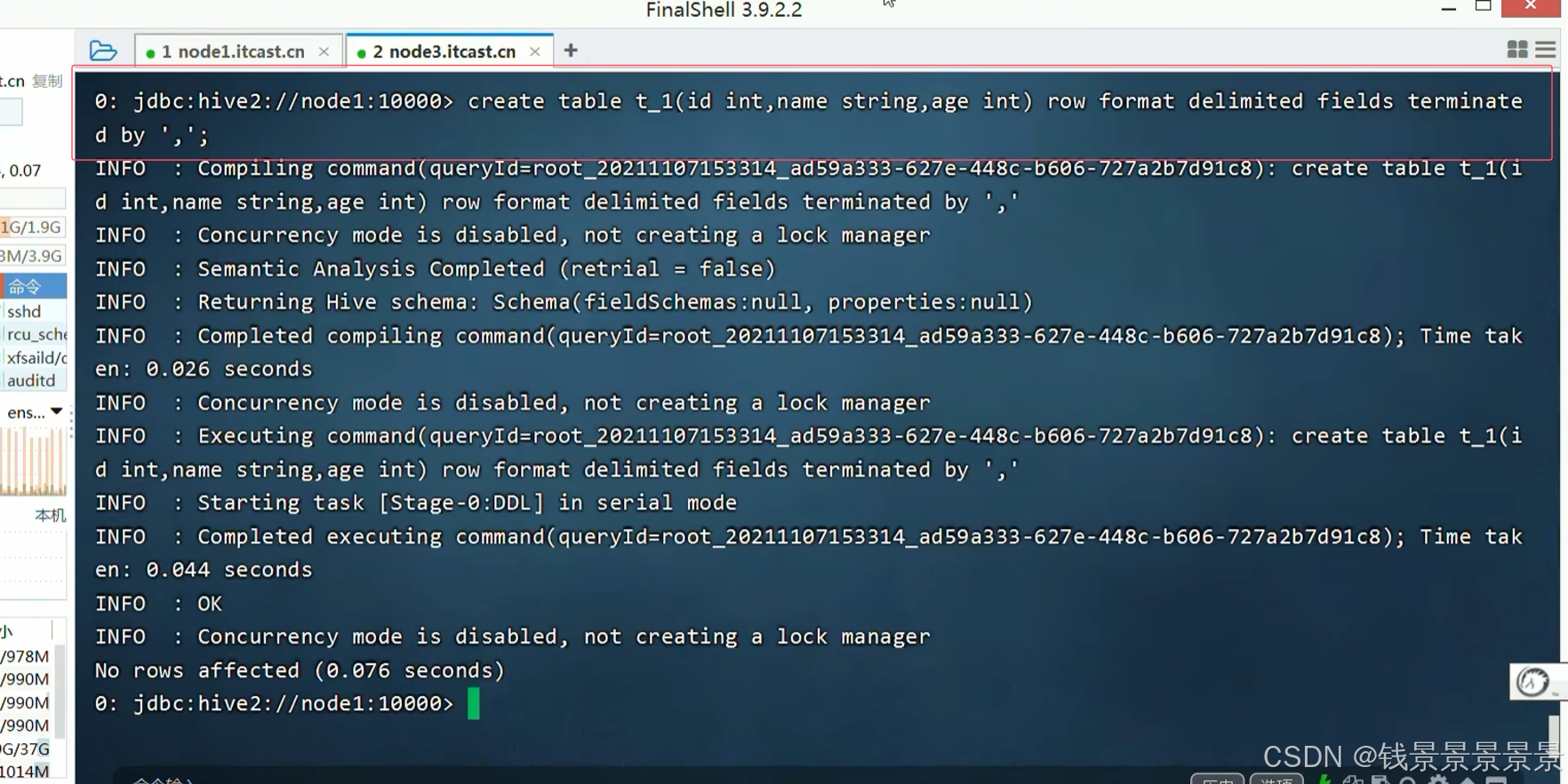
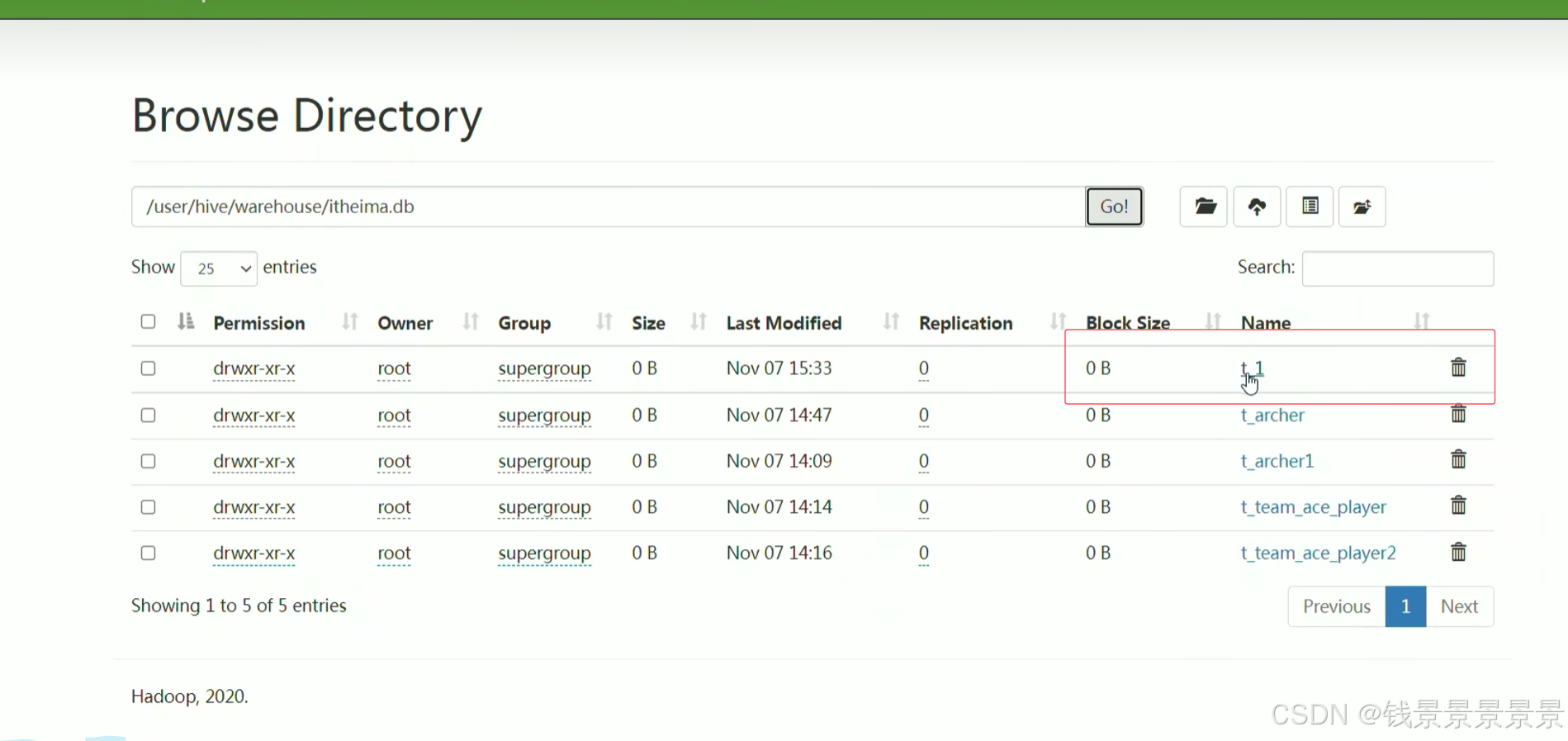
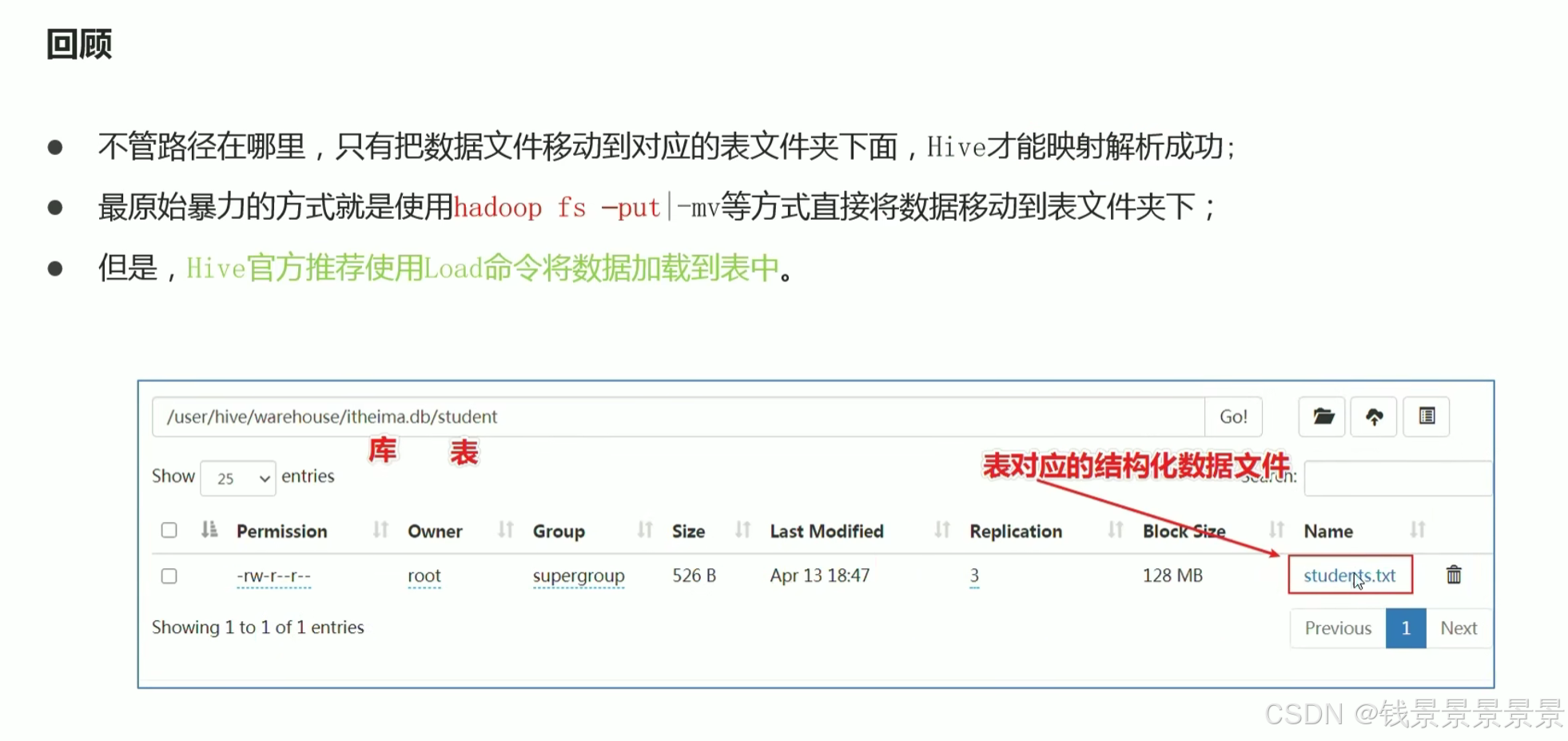
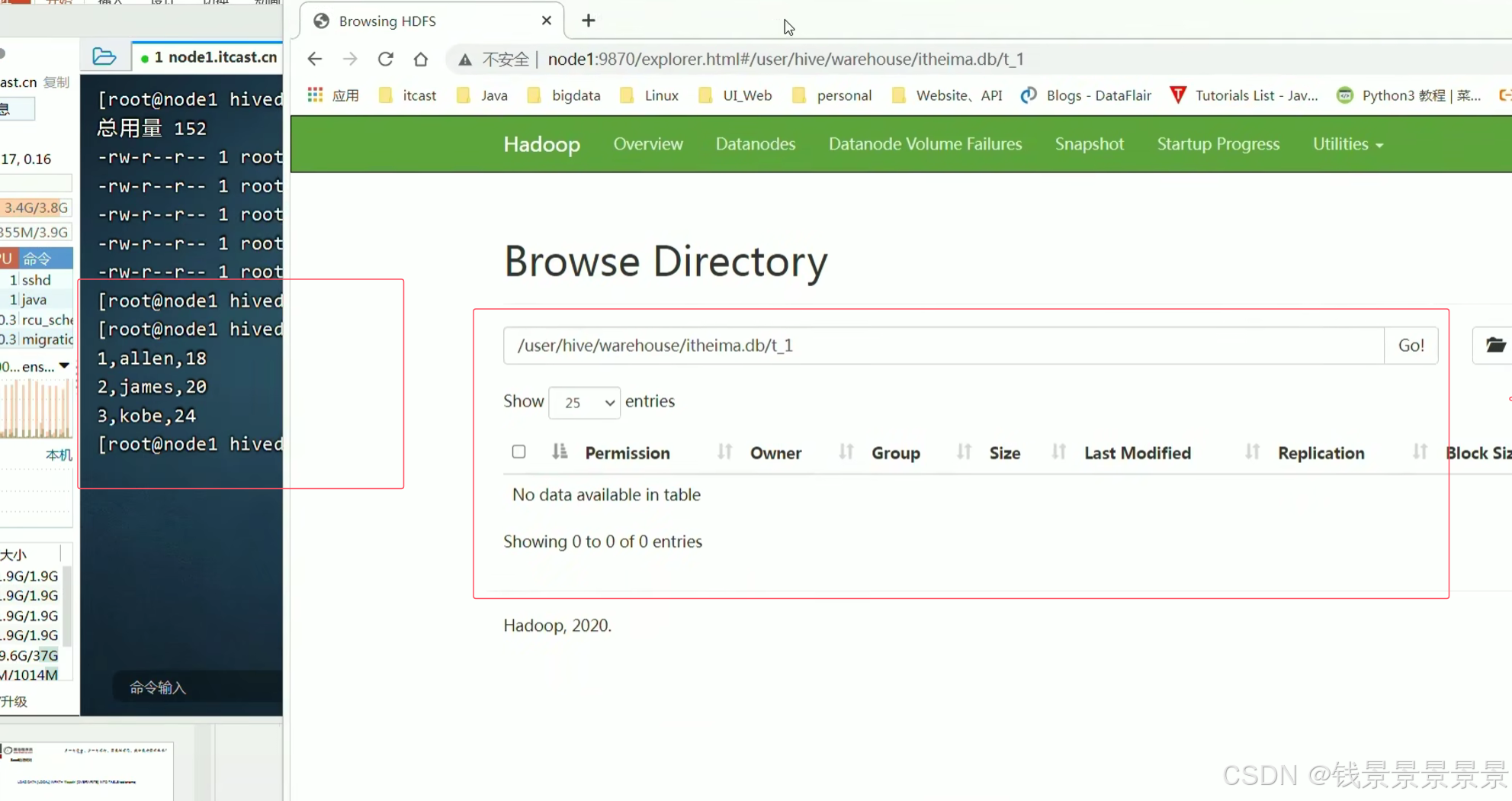
只要将1.txt文件放在t_1文件夹下,就能映射成功了
==================================================================================================================================================
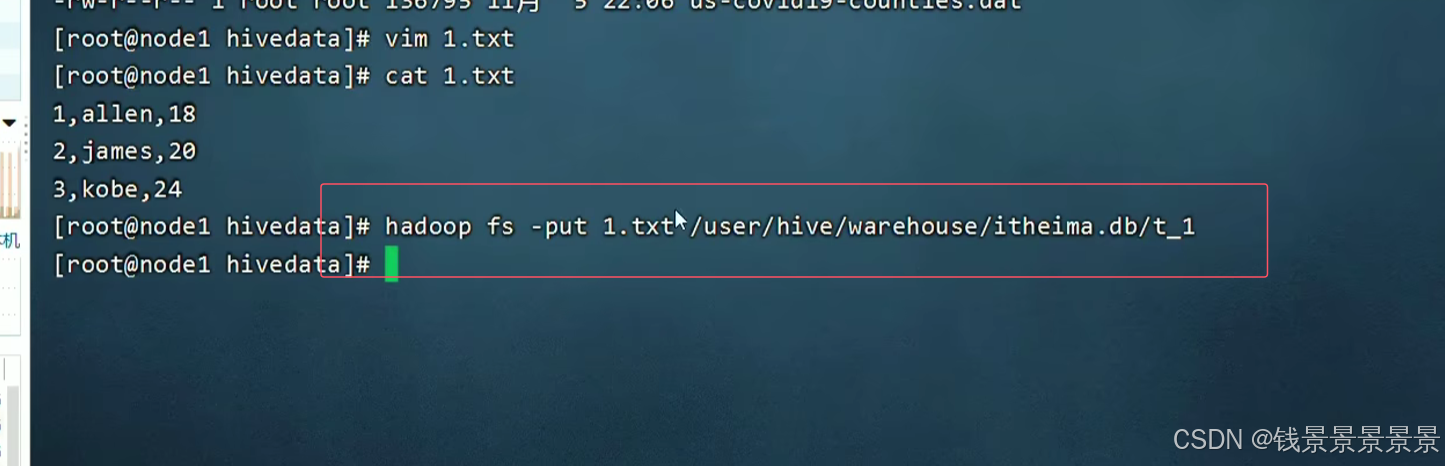
下面是第一种方法,直接put进去
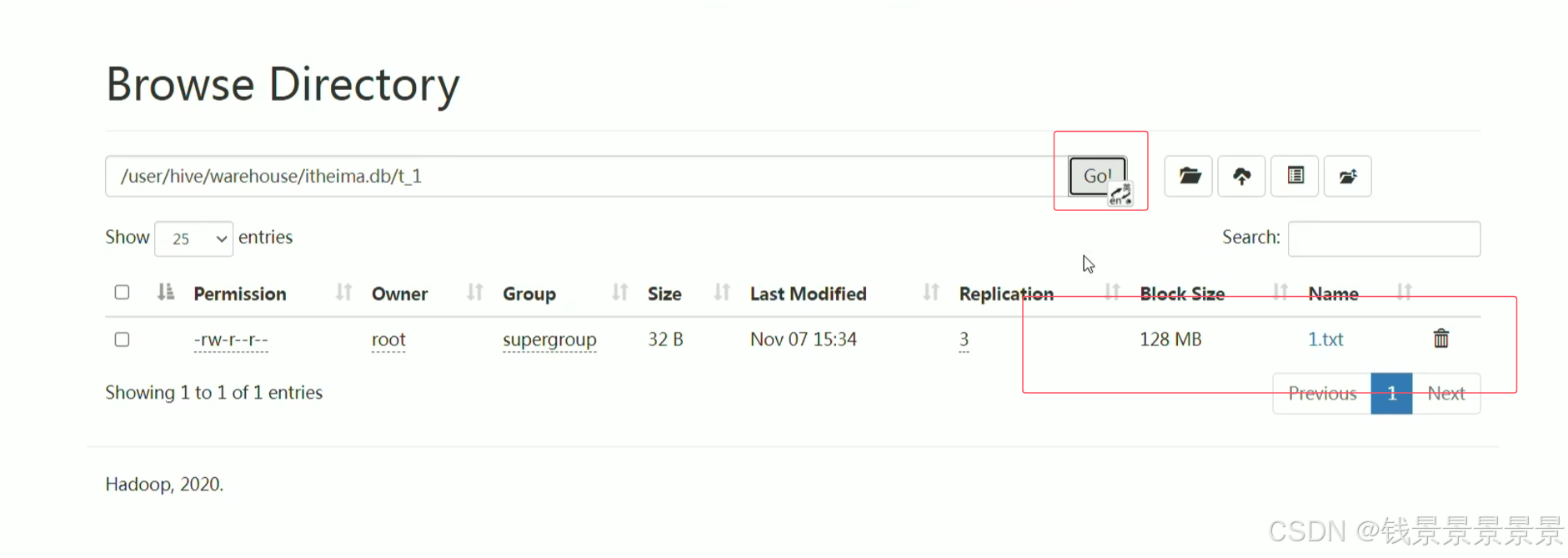
刷新一下
或者直接在web页面上传
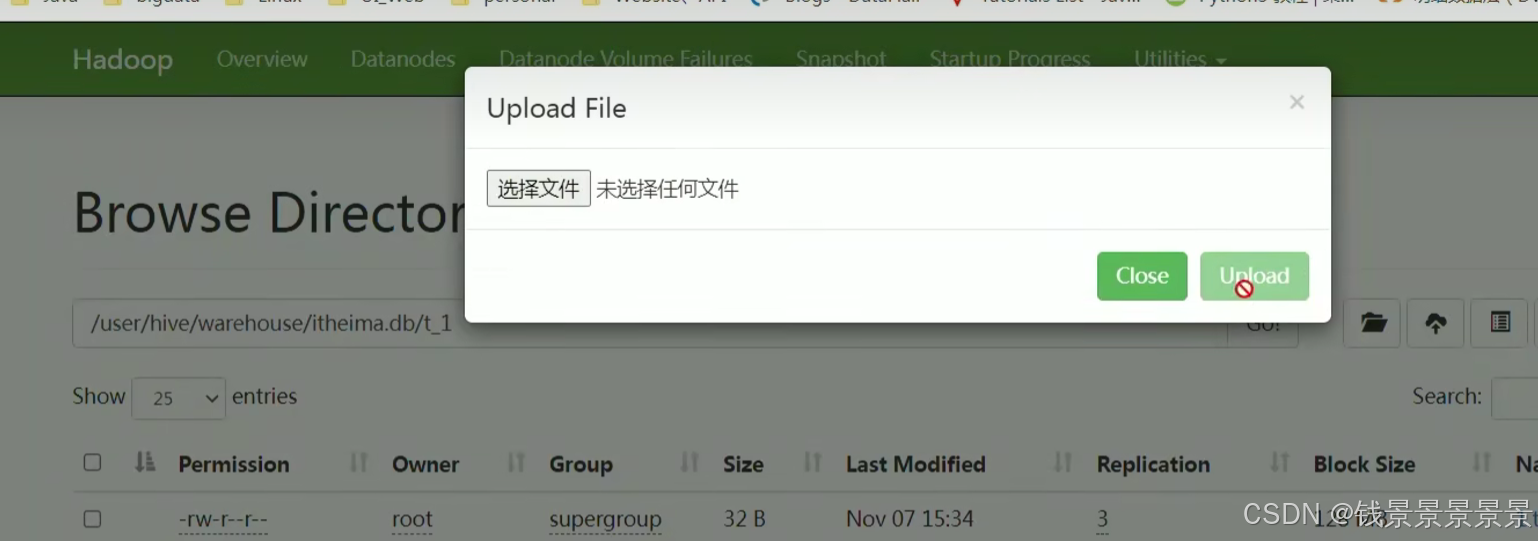
不管什么方法
将结构化的文件放在对应的目录下面就能成功
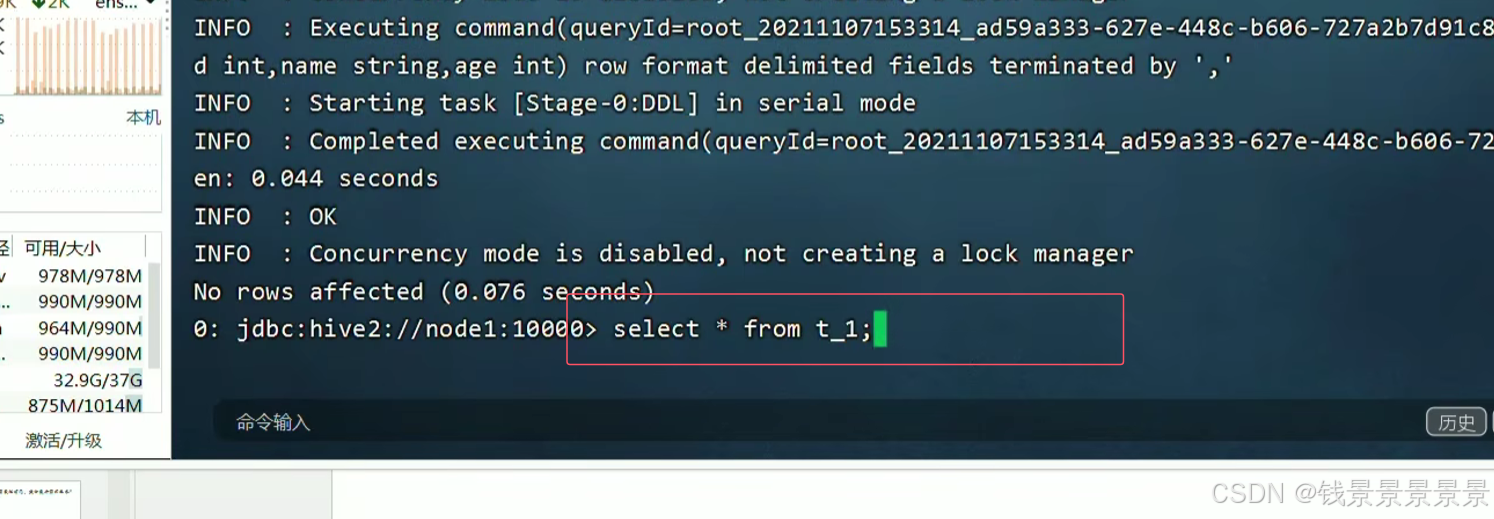
=================
上面的方法,hive官方是不推荐的(因为上面的都是跳过hive去操作的)




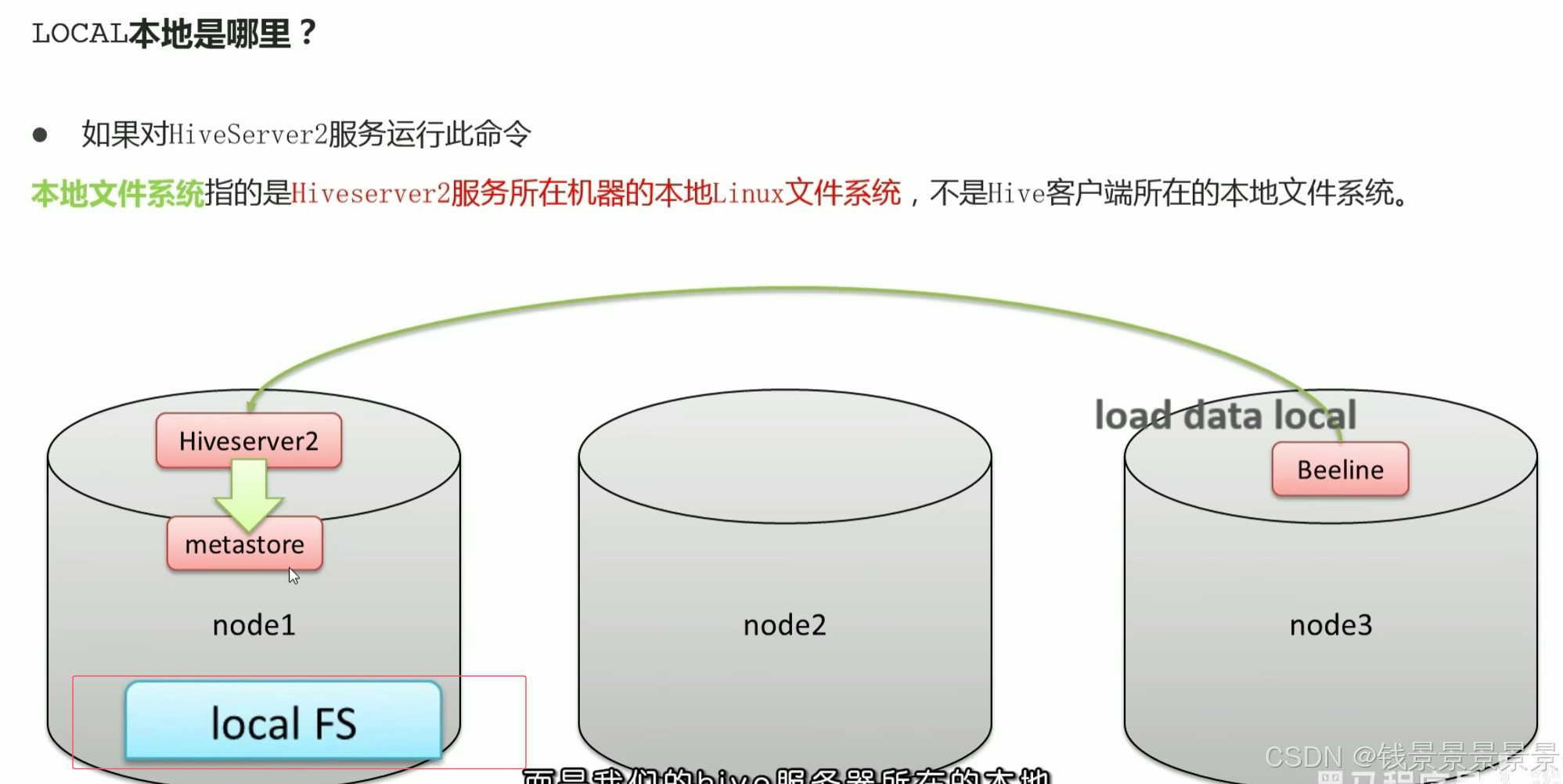
我们有三台机器
我们的hive是安装在node1上面的,node1上面启动了hiveserver2和metastore两个服务
我们是使用node3作为客户端的(包括第一代客户端和第二代beeline客户端),如果使用的是datagrip,则客户端在外面的Windows系统上。
但不管我们的客户端在哪,最终都是连接到node1的hiveserver2上进行操作的。
如果我们在客户端上敲一个命令,加载数据local,这个local是hiveserver2服务所在的机器




本课程的SQL已经写好了
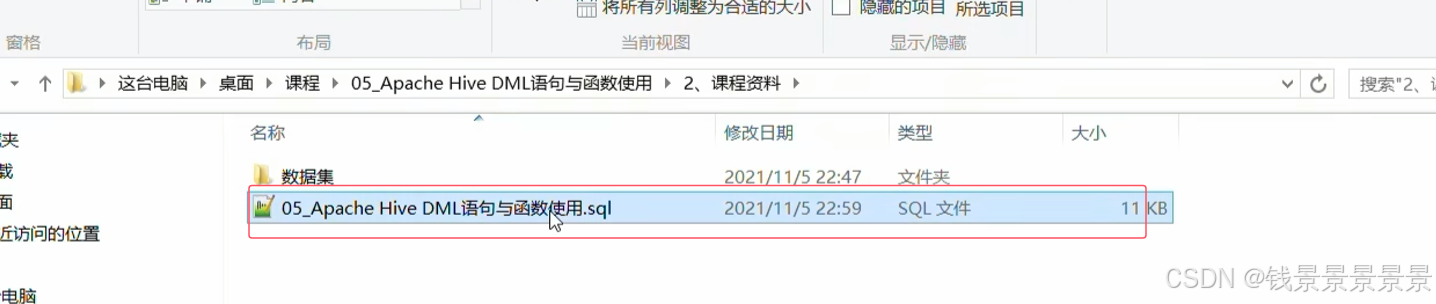
我们直接将其复制粘贴到datagrip
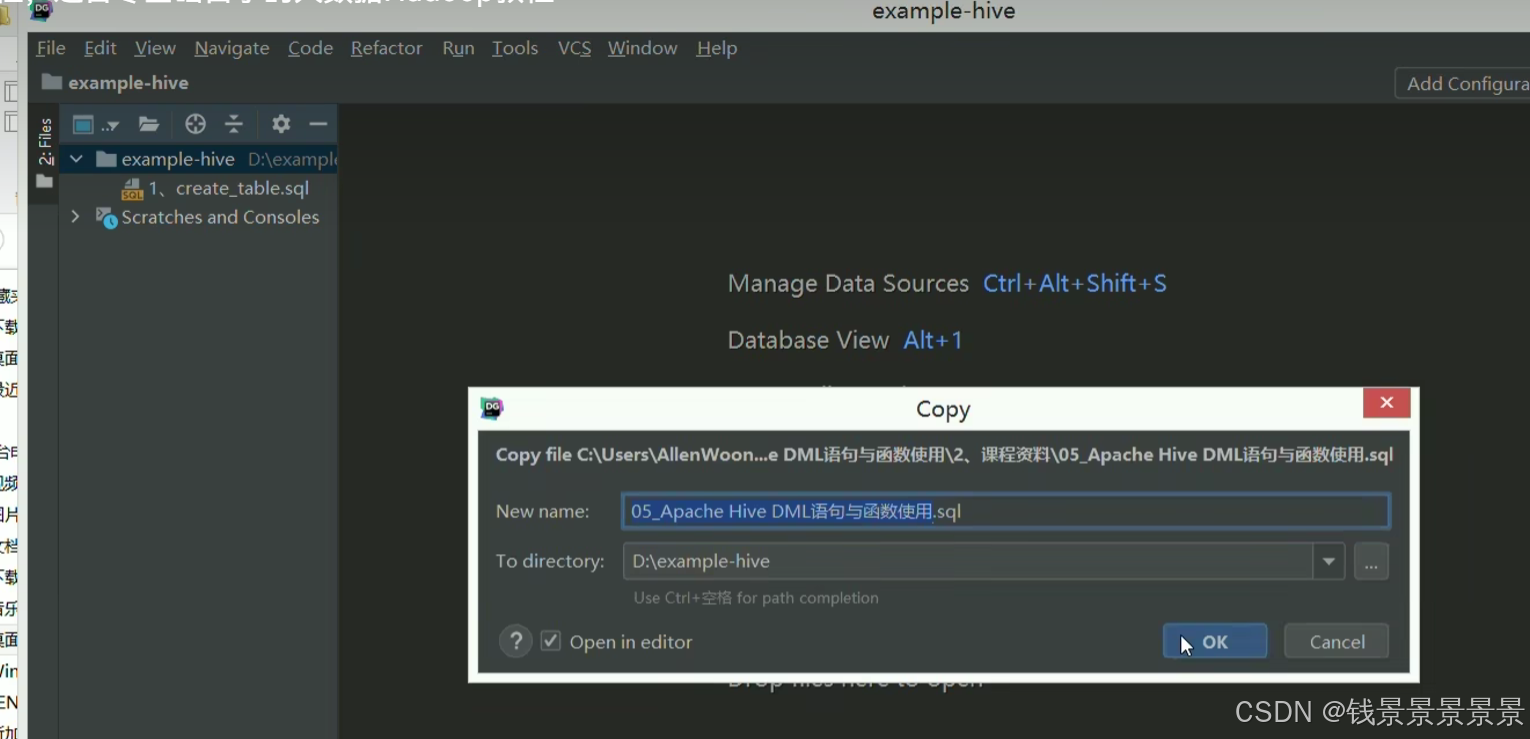
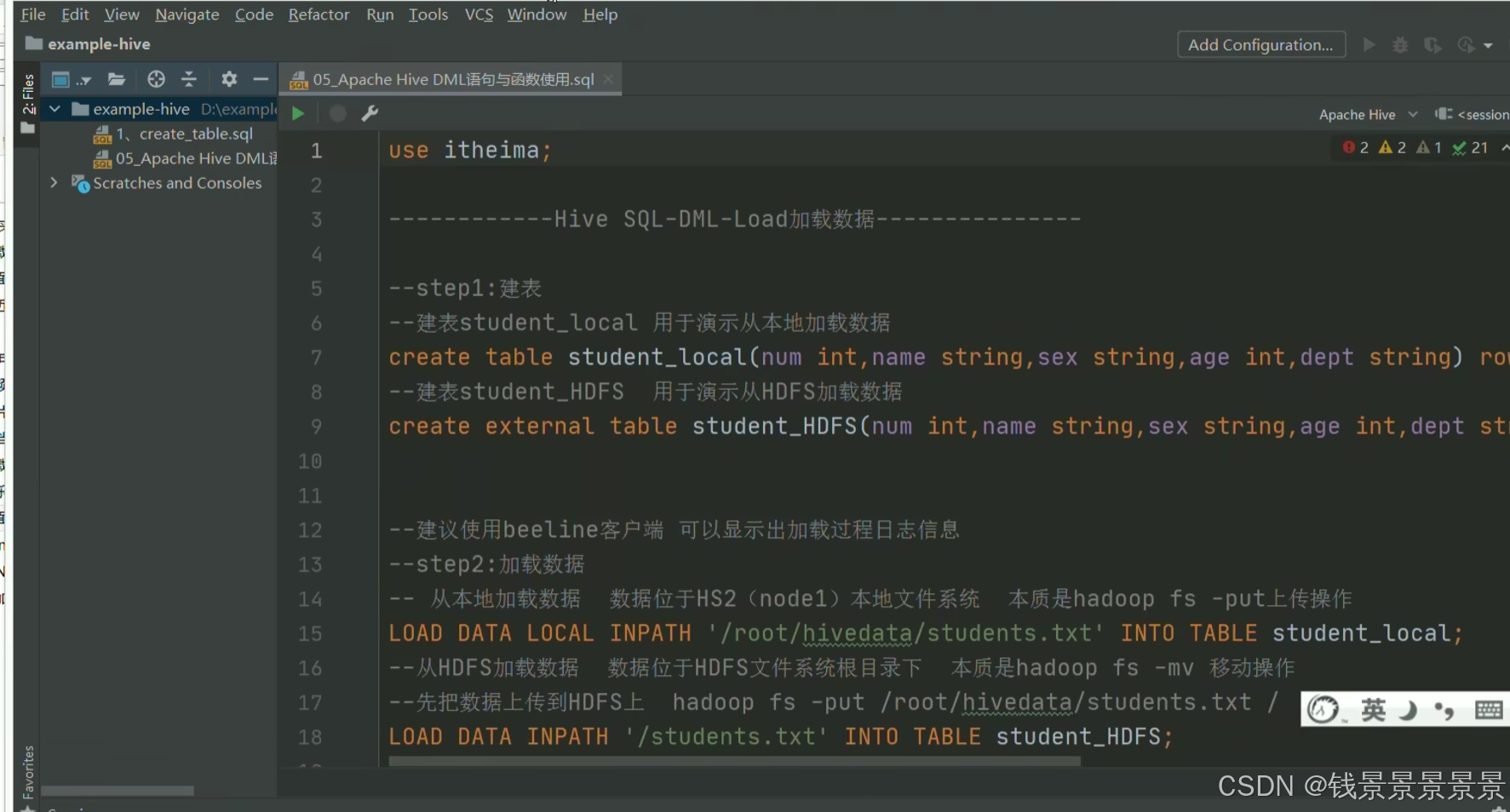
首先将我们当前的SQL语法切换为hive语法
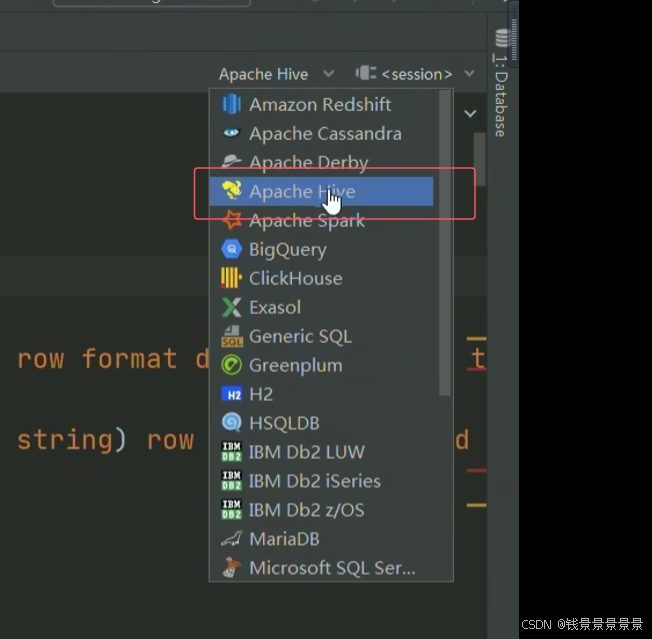
接着将我们的会话做一个绑定
如果有直接绑定即可,没有的话创建一个新的会话即可
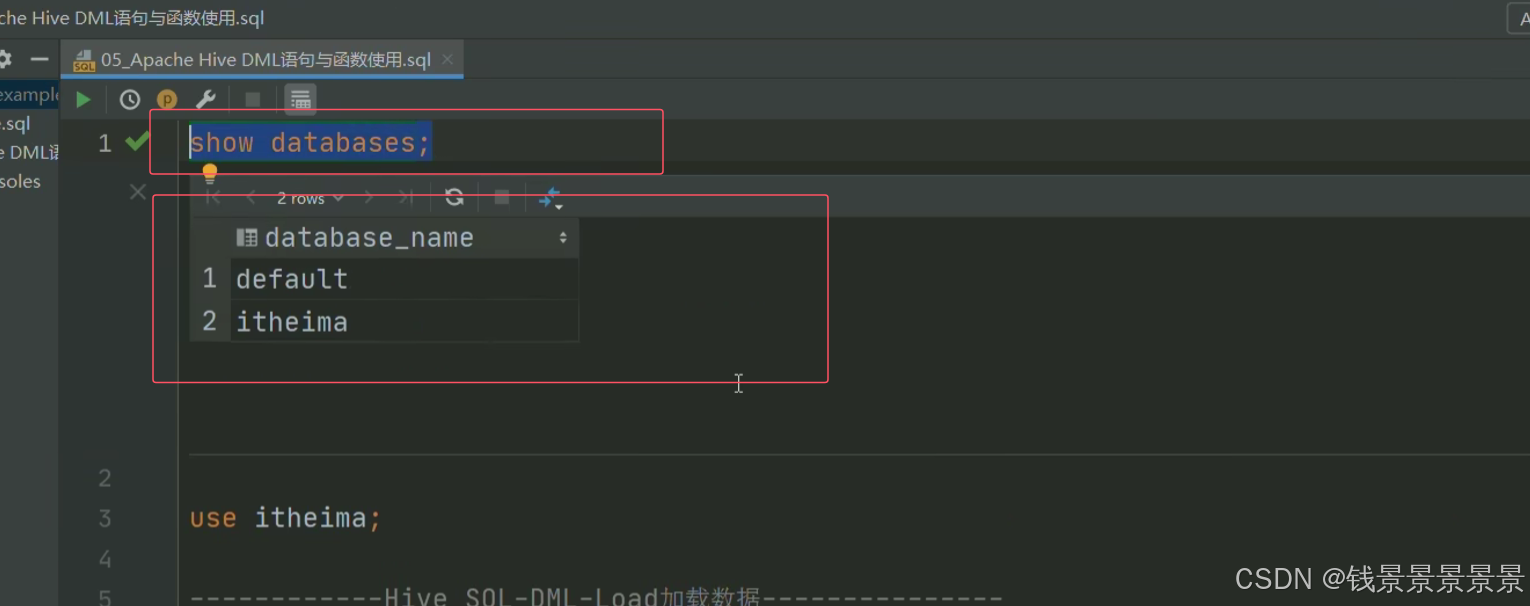
之后我们做一个验证
看是否与我们的hive集群连接上
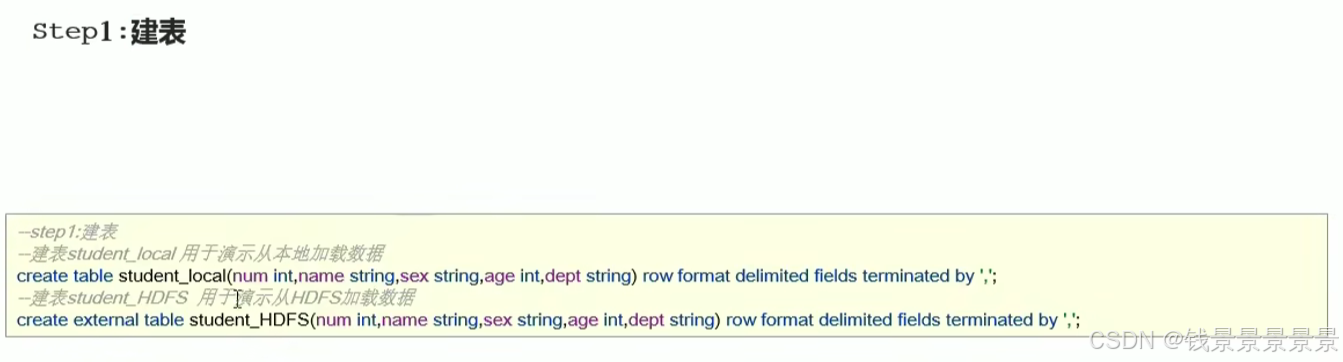
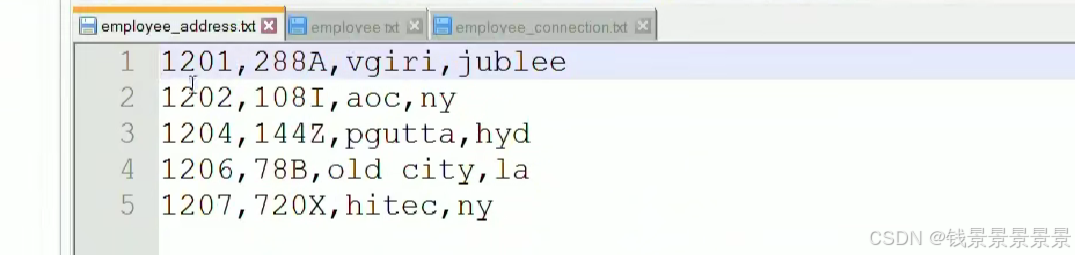
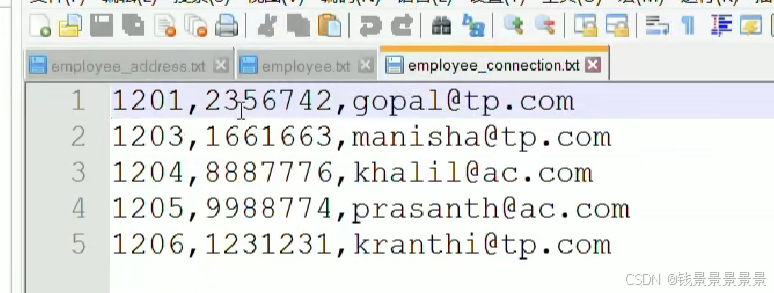
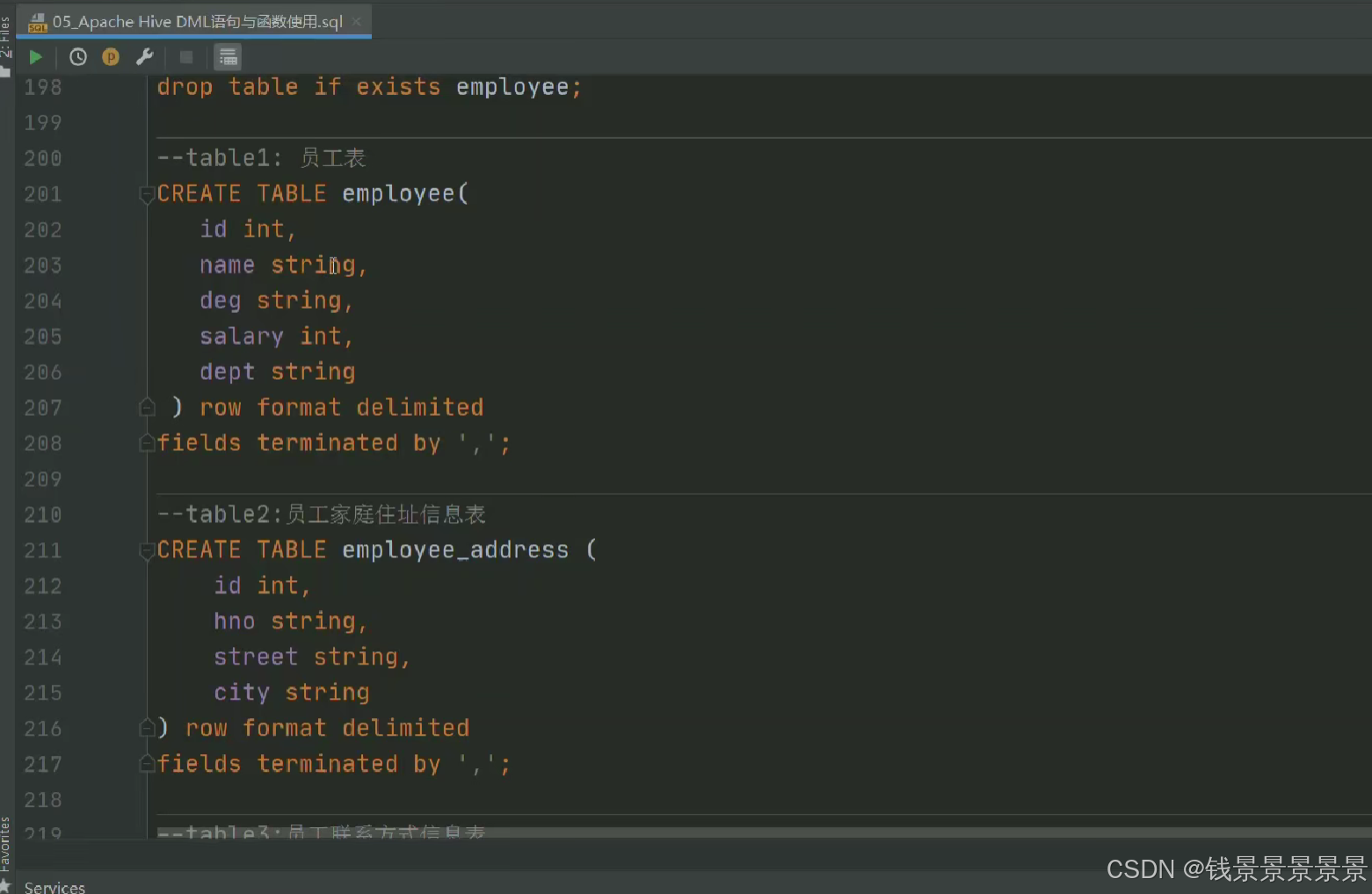
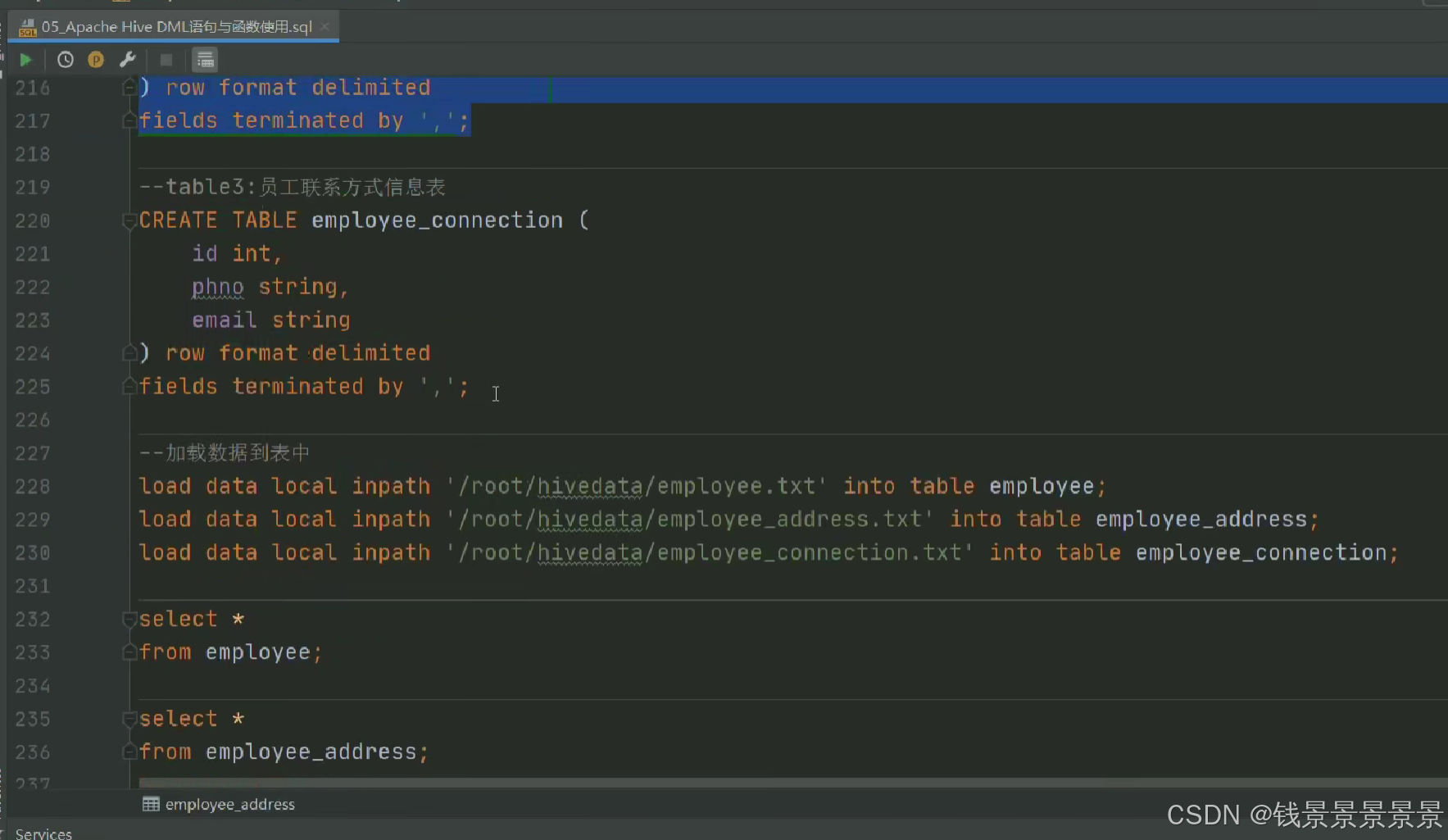
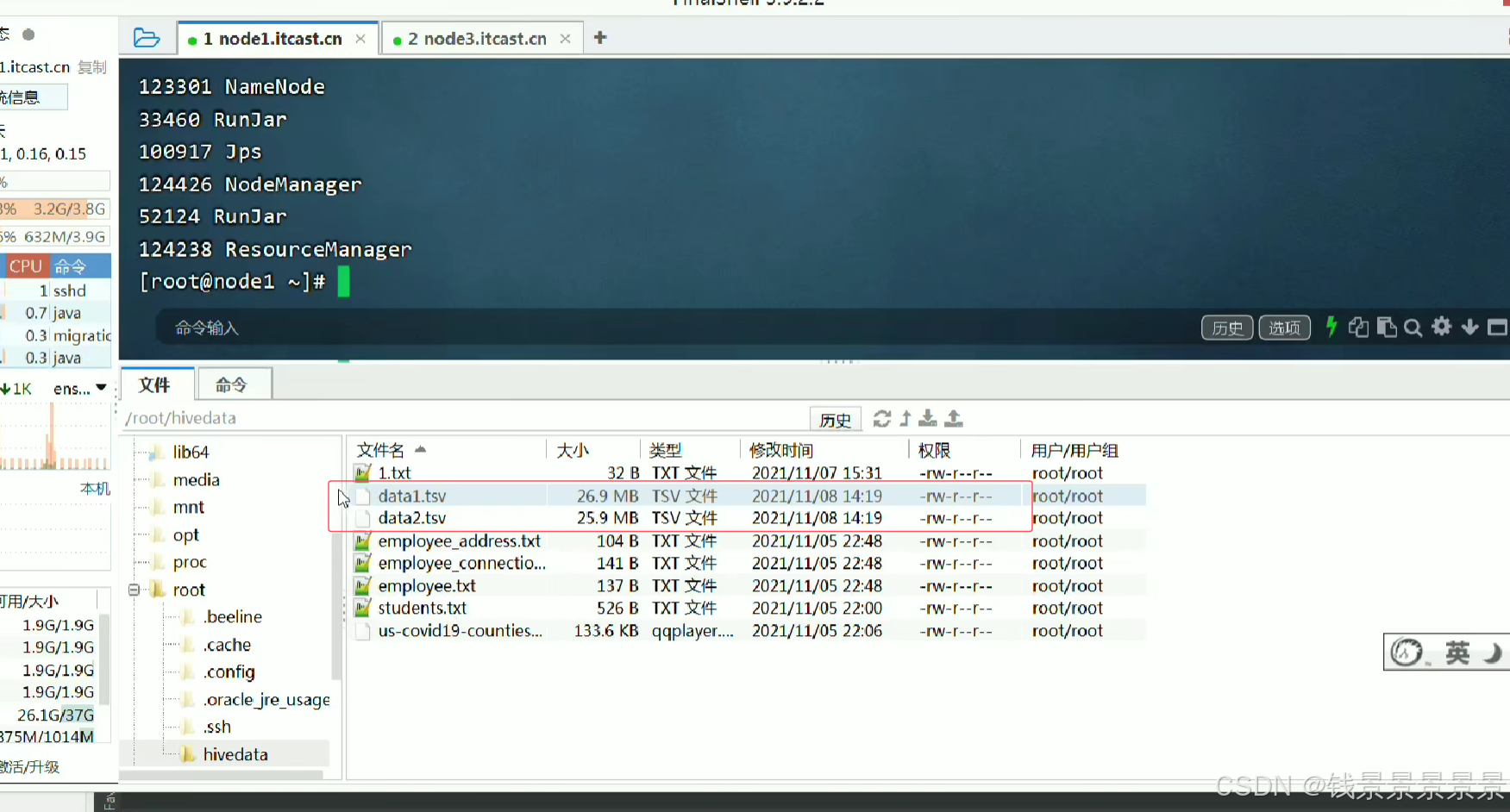
然后针对下面的文件
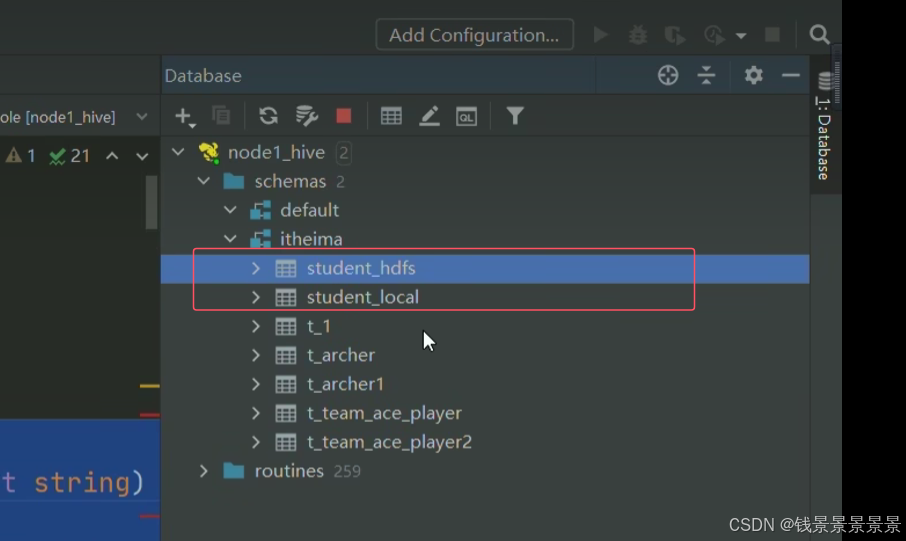
我们创建两张表
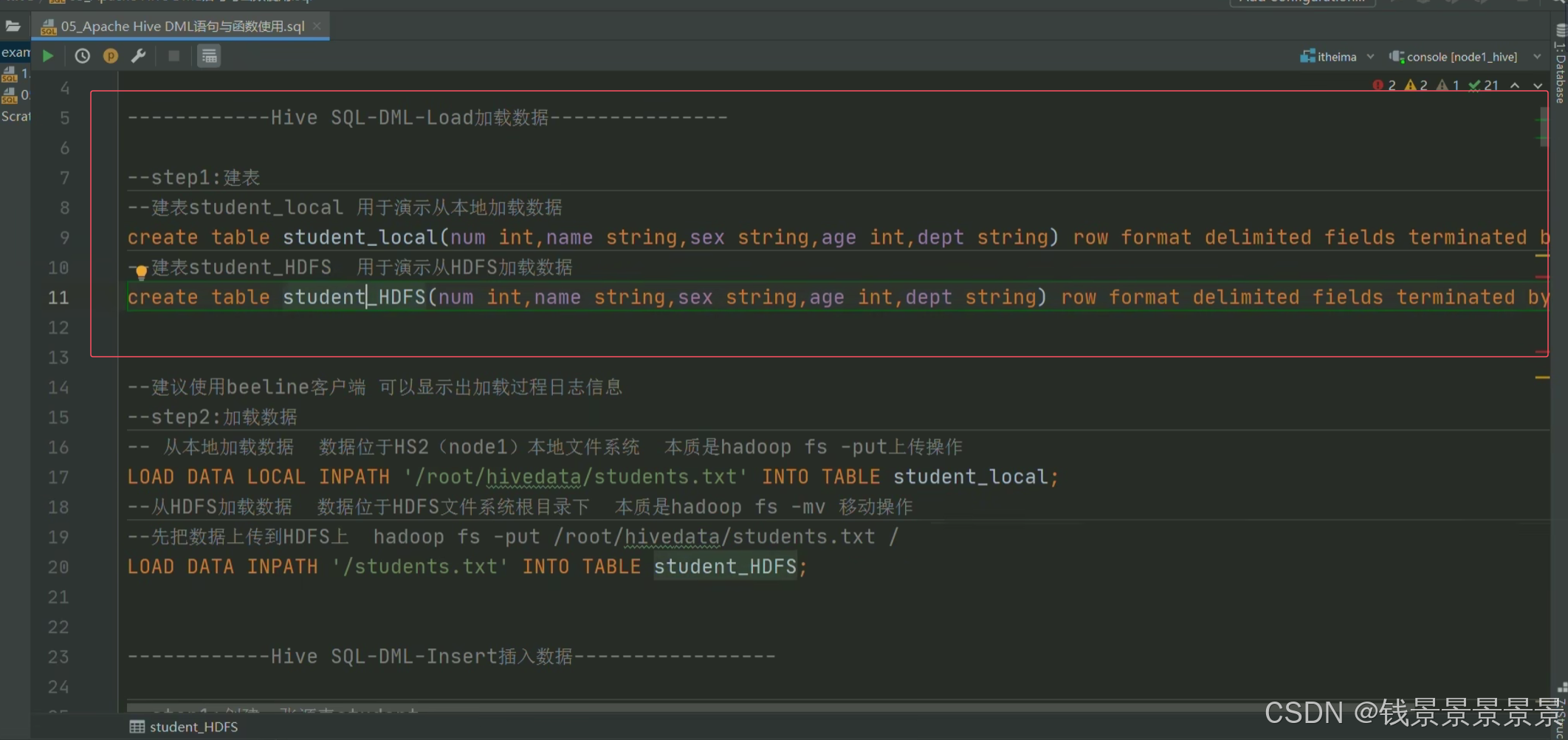
我们运行命令创建两张表
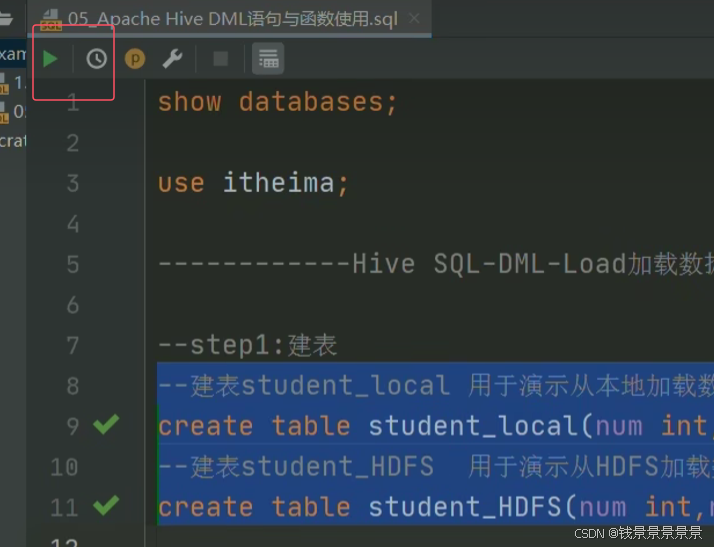
==================================================================================================================================================
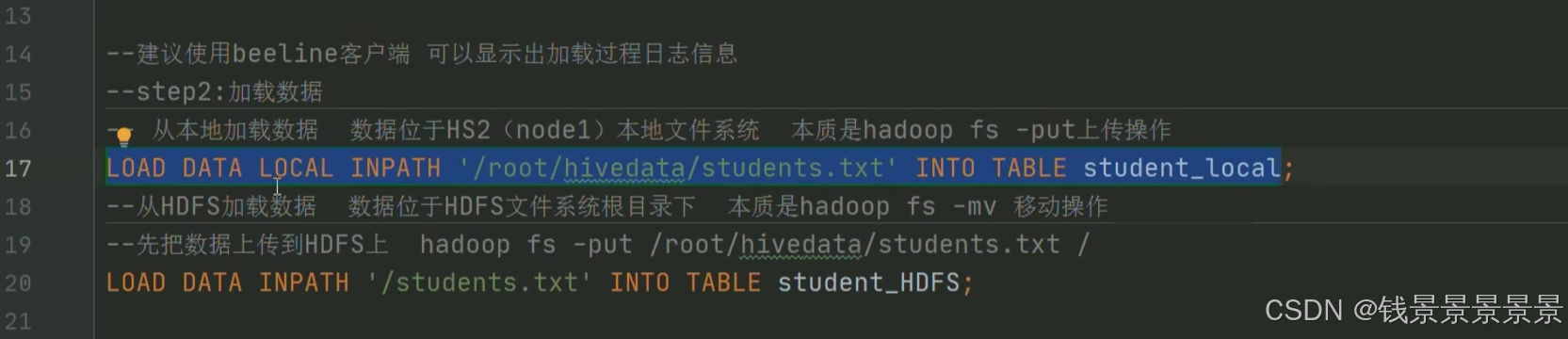
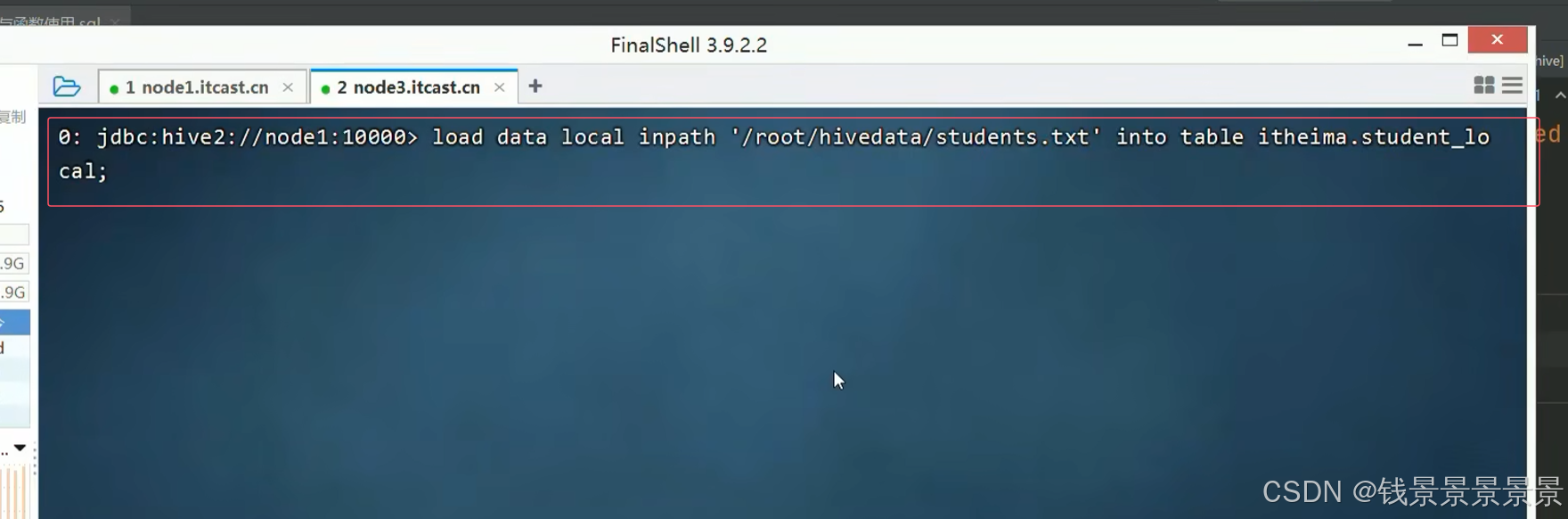
下面首先进行本地上传
文件首先存放到本地中

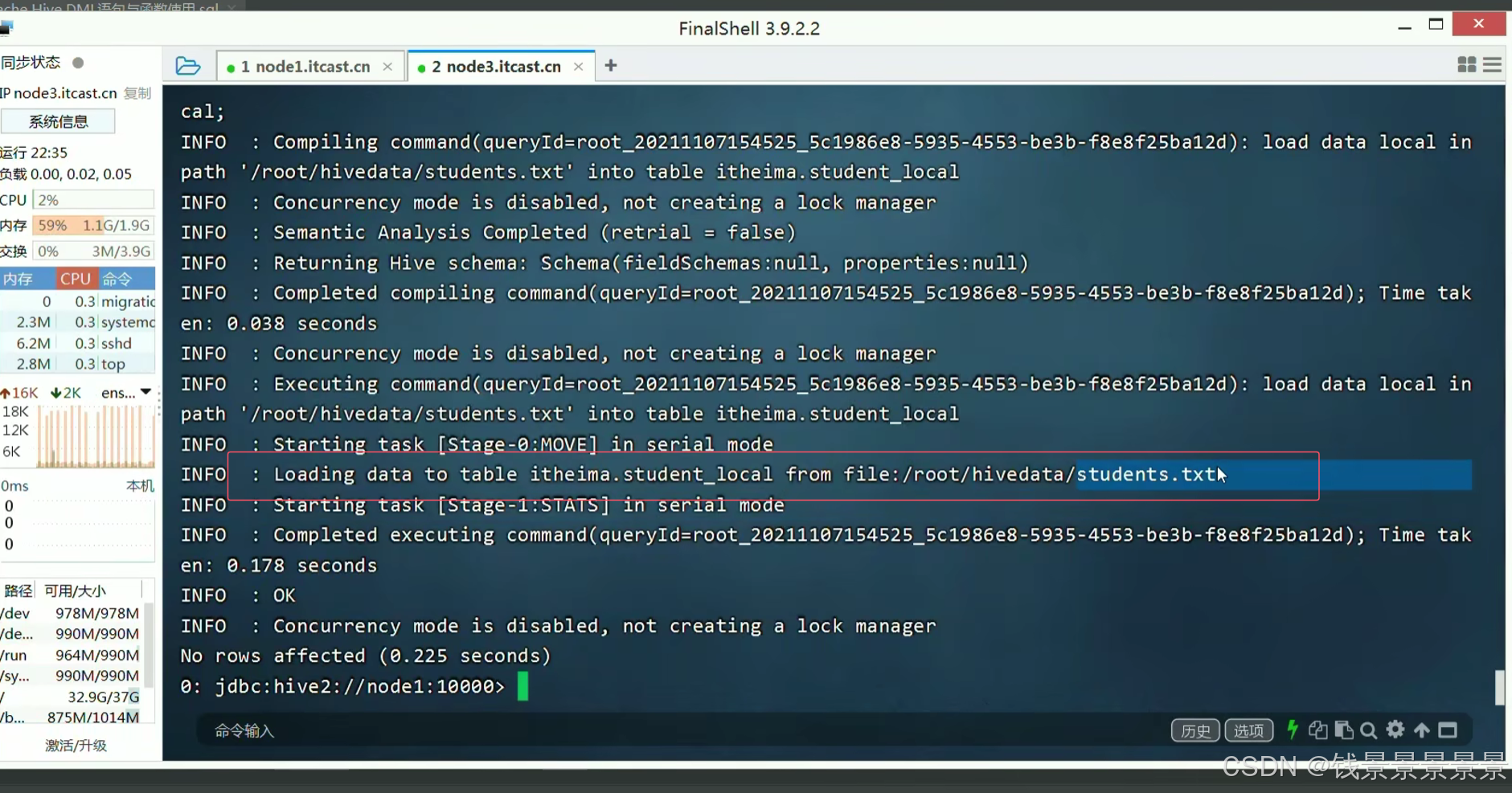
成功
红框中是关键的日志信息
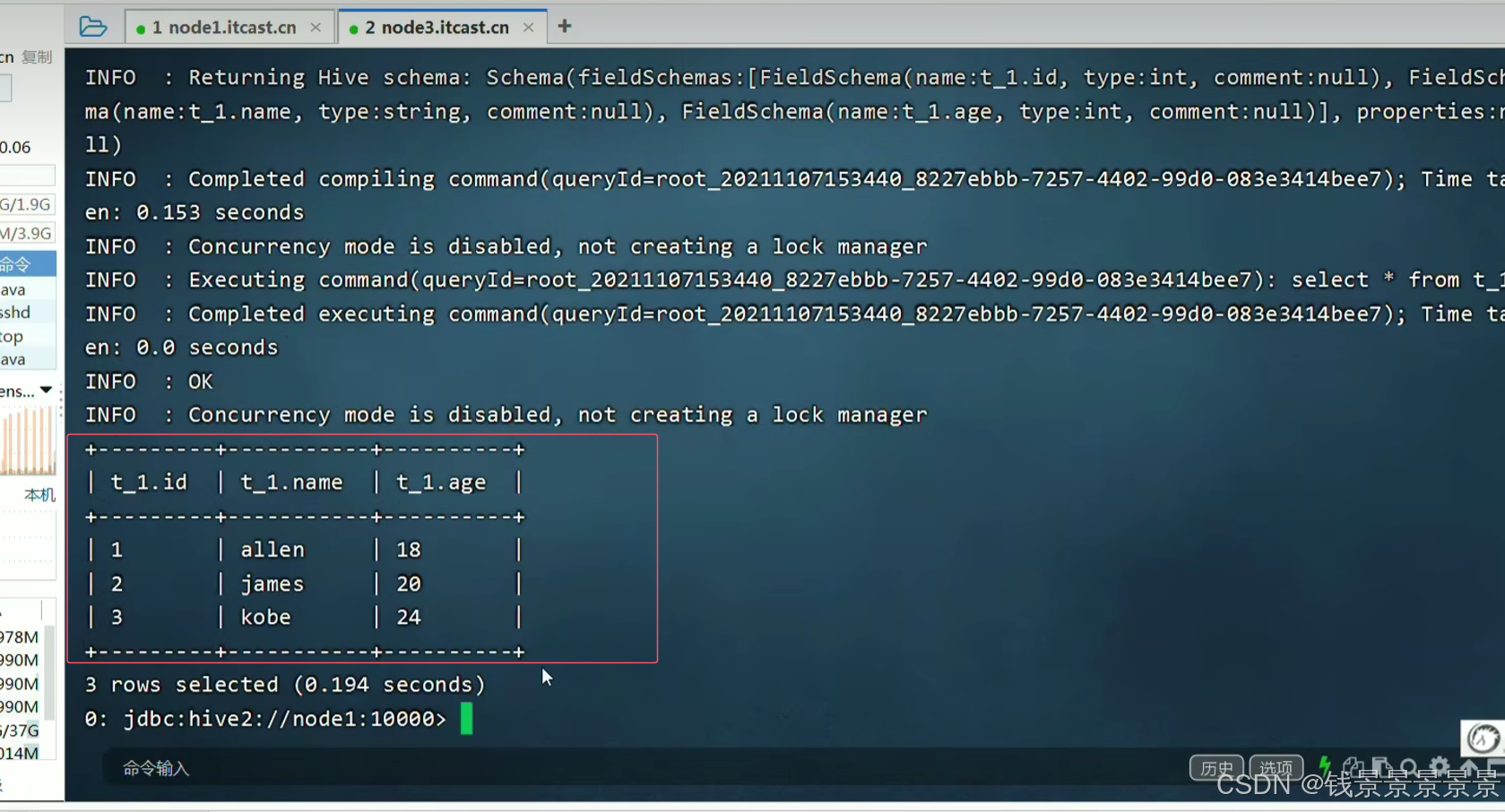
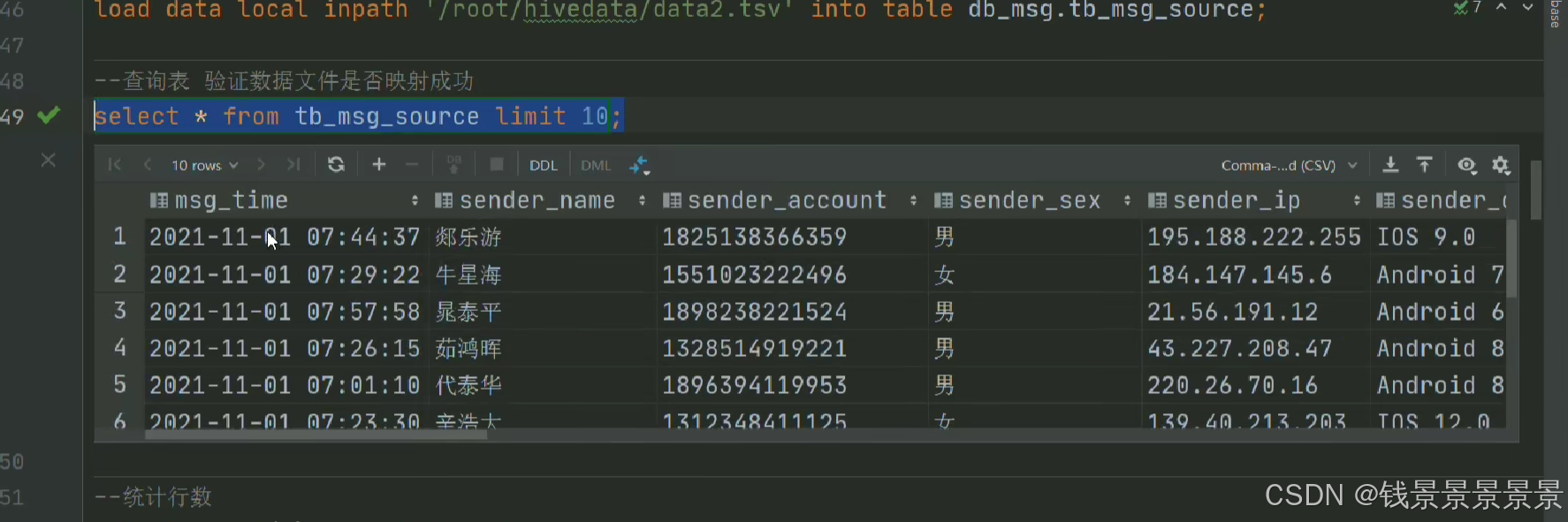
做一个查看
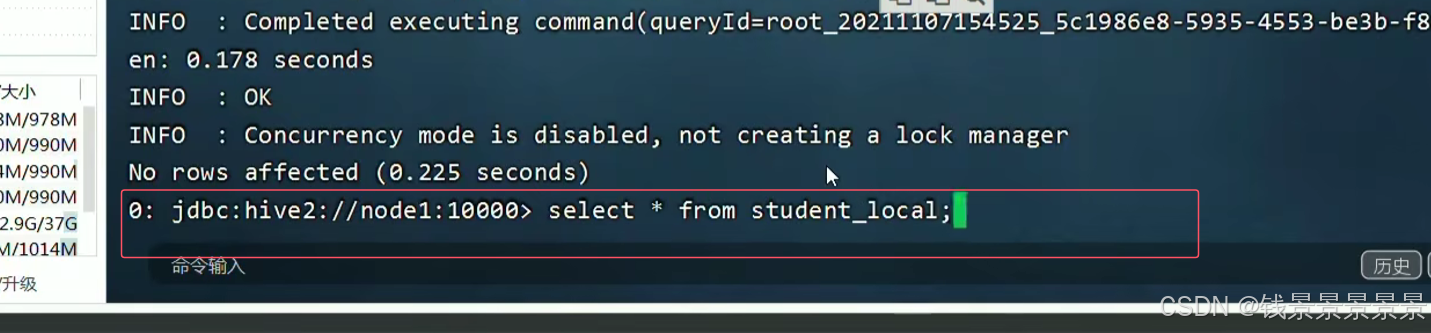
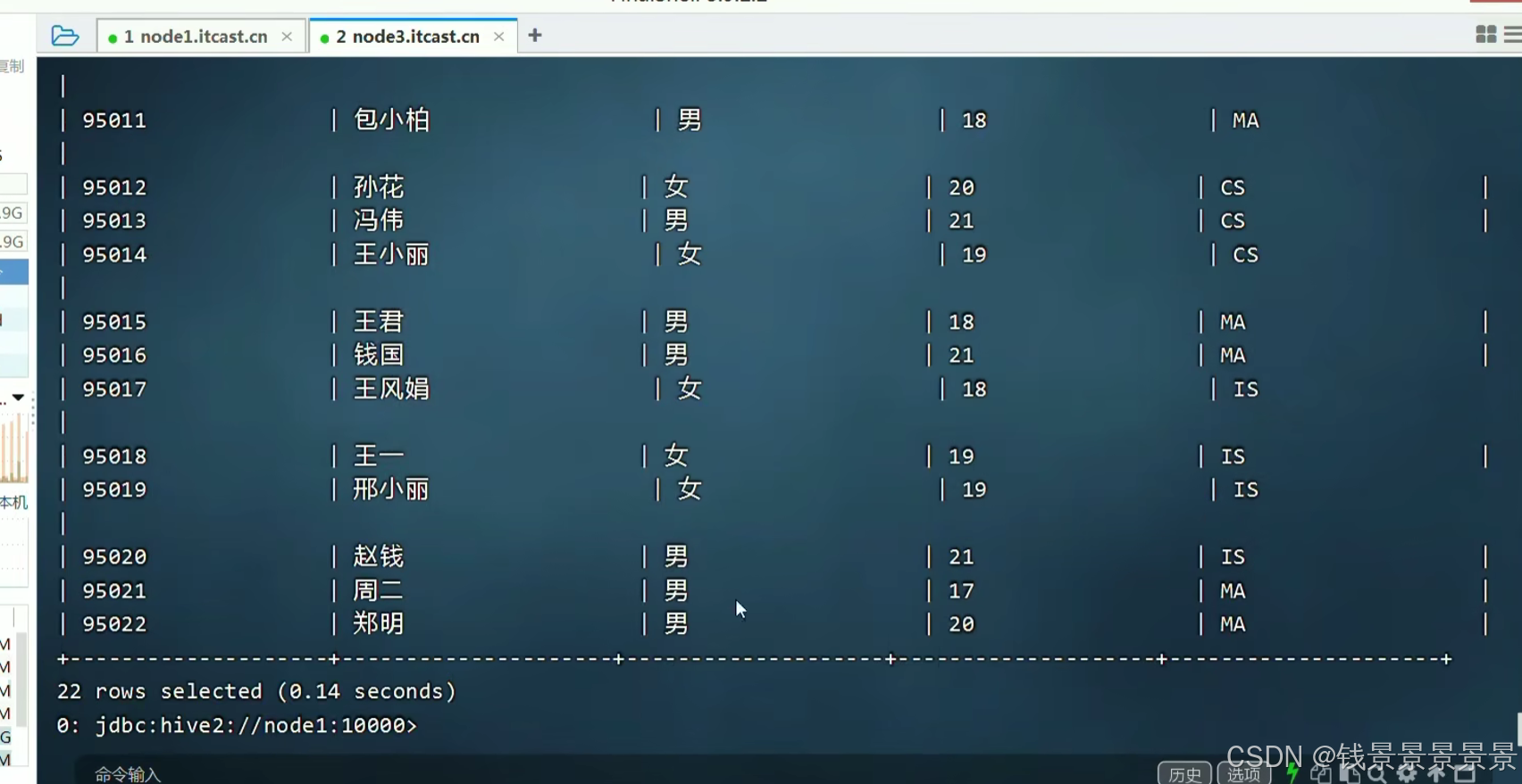
数据显示正常
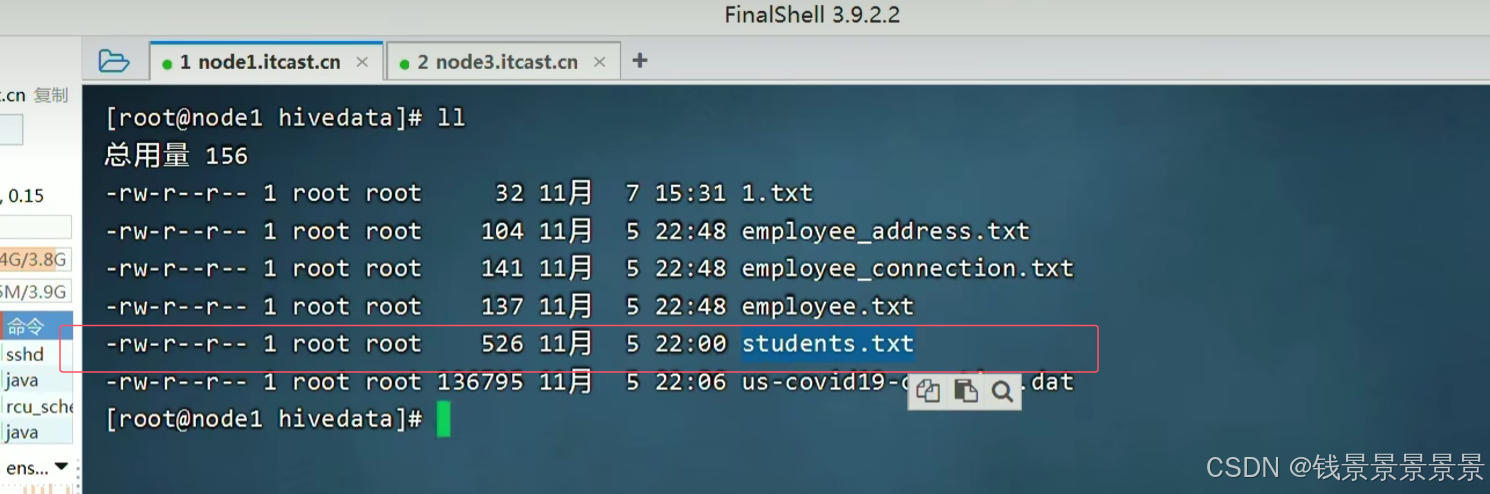
我们发现本地目录中的文件依旧存在
所以本地加载就是一个复制的过程
==================================================================================================================================================
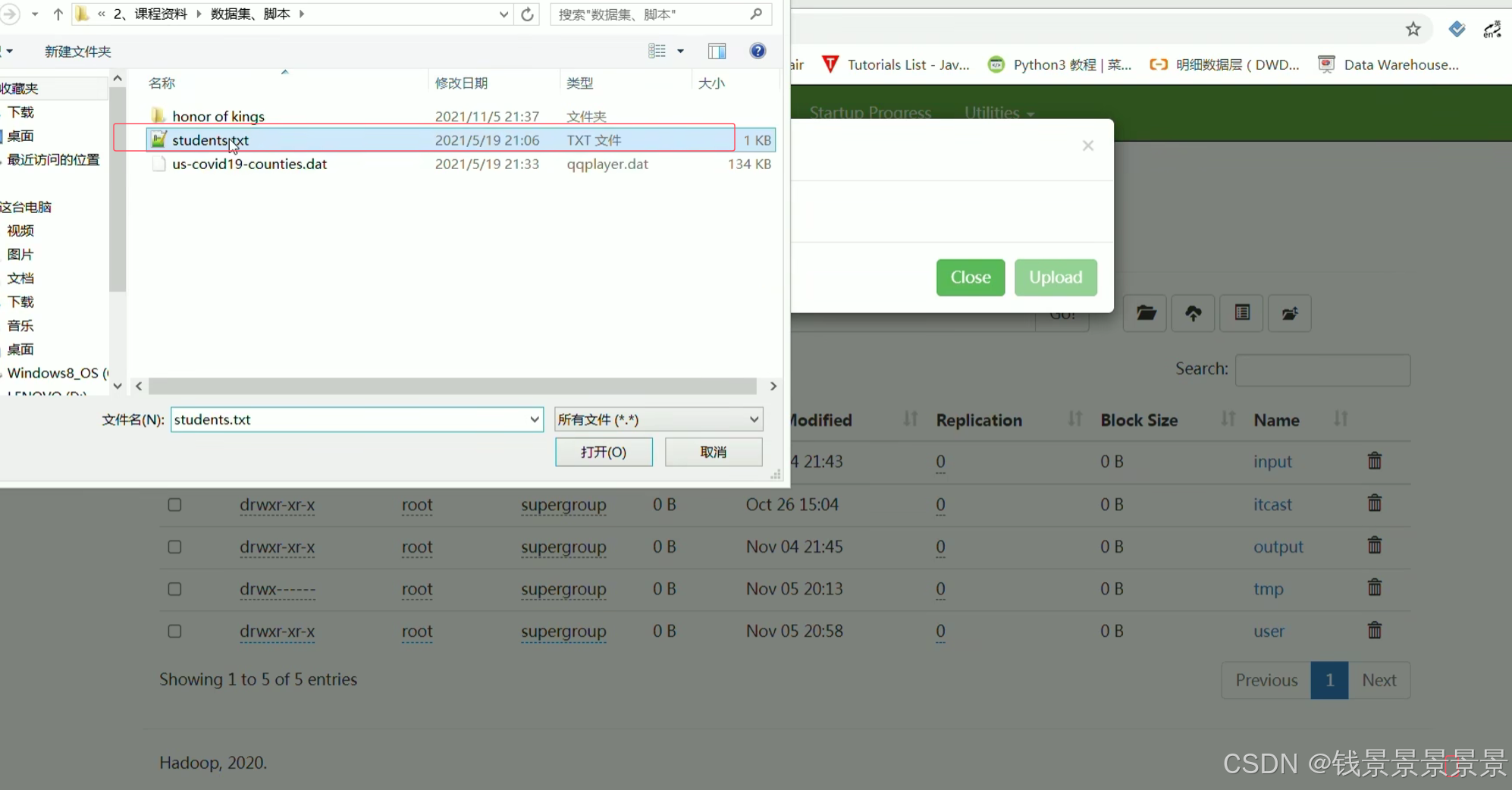
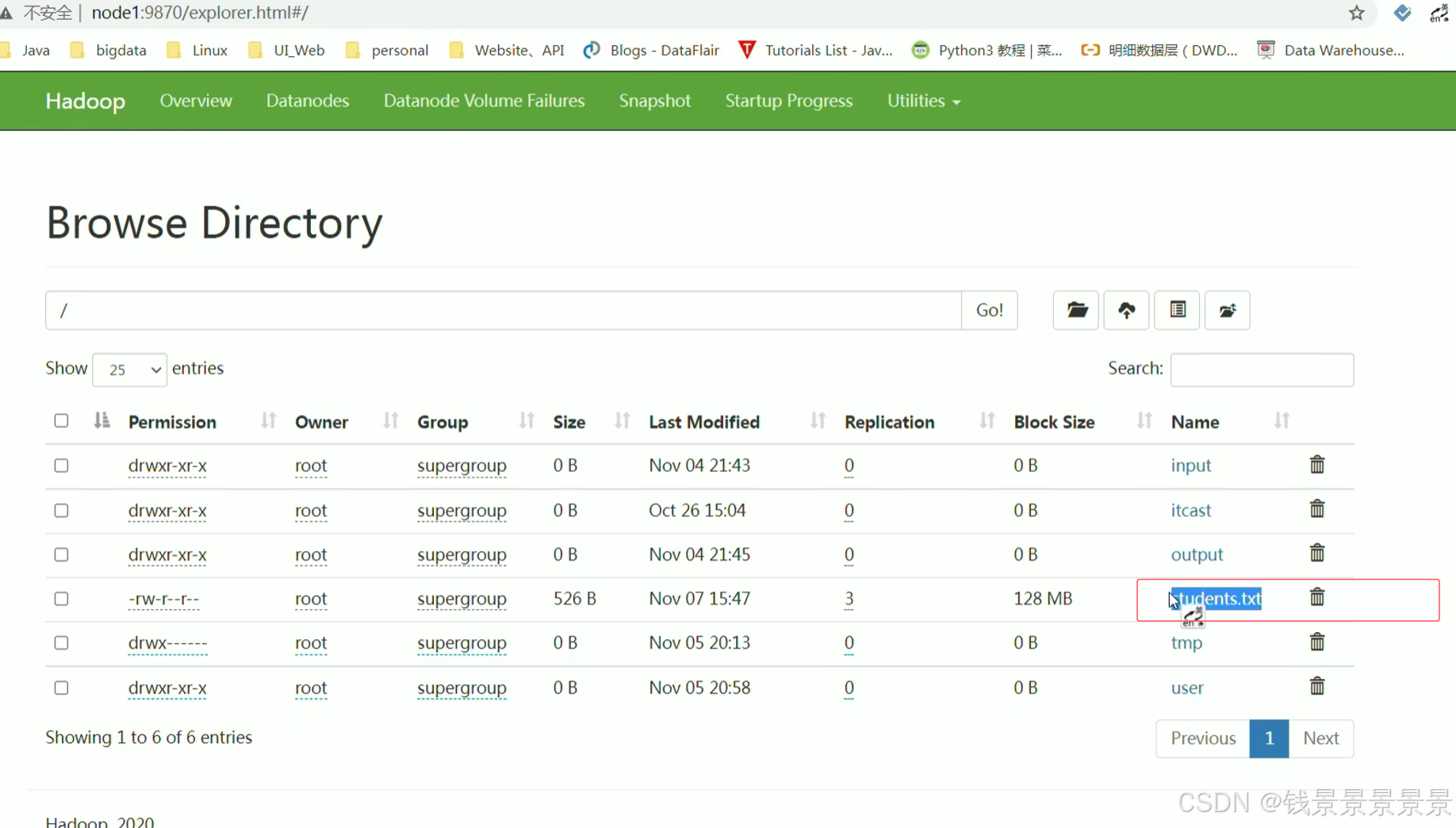
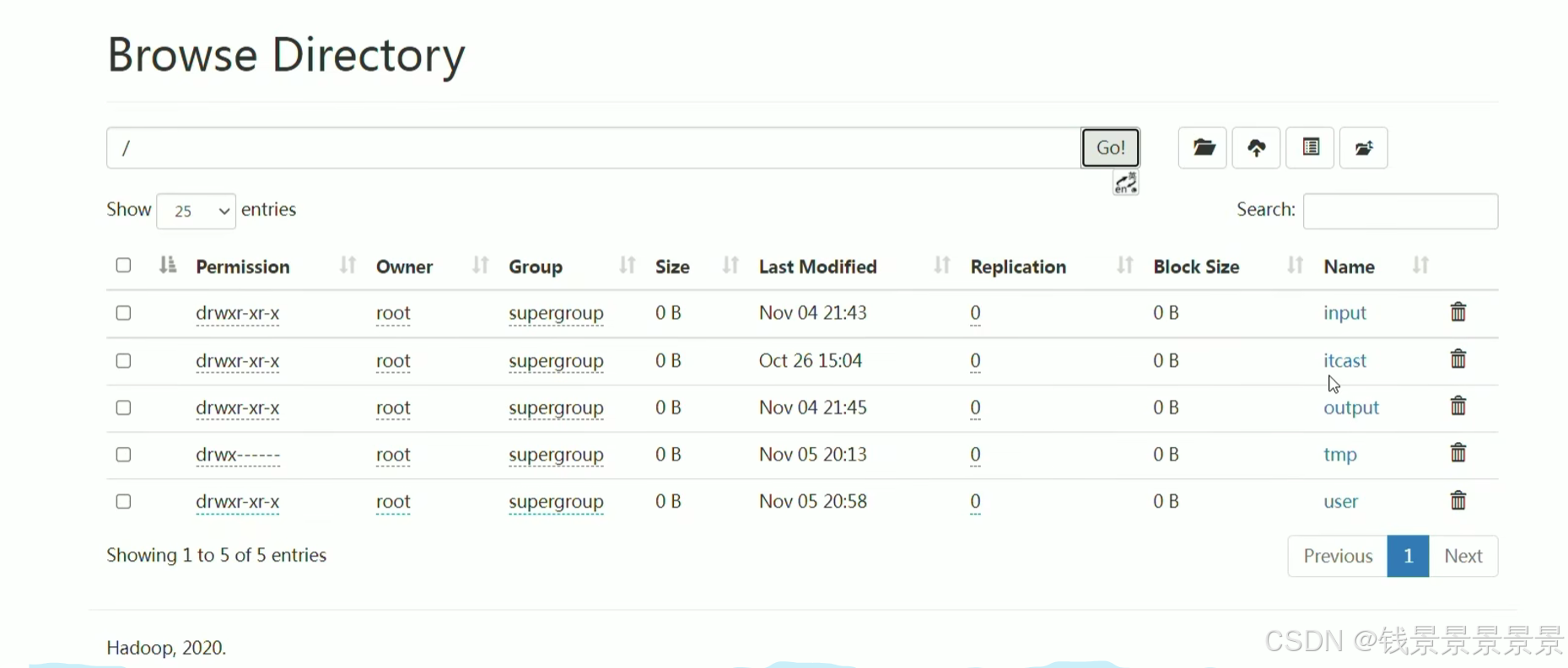
我们将刚刚的文件放在hdfs的根目录下面
我们刚刚建了两张表
我们看一下另外一张表
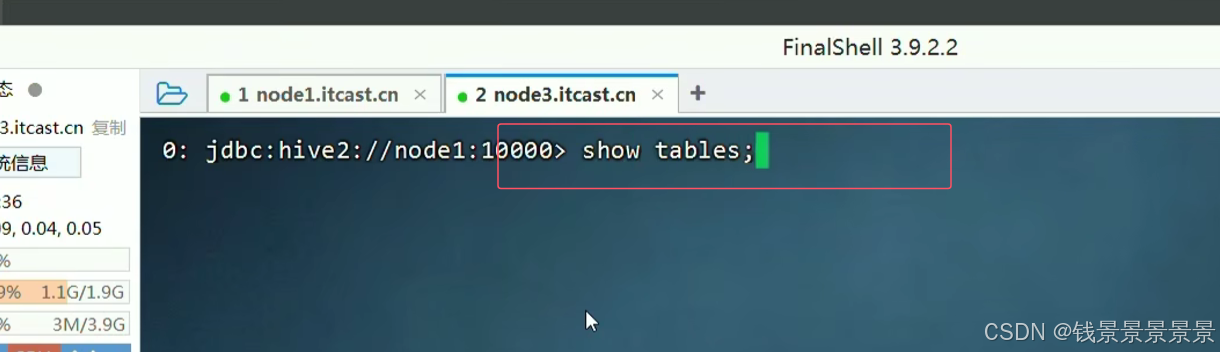
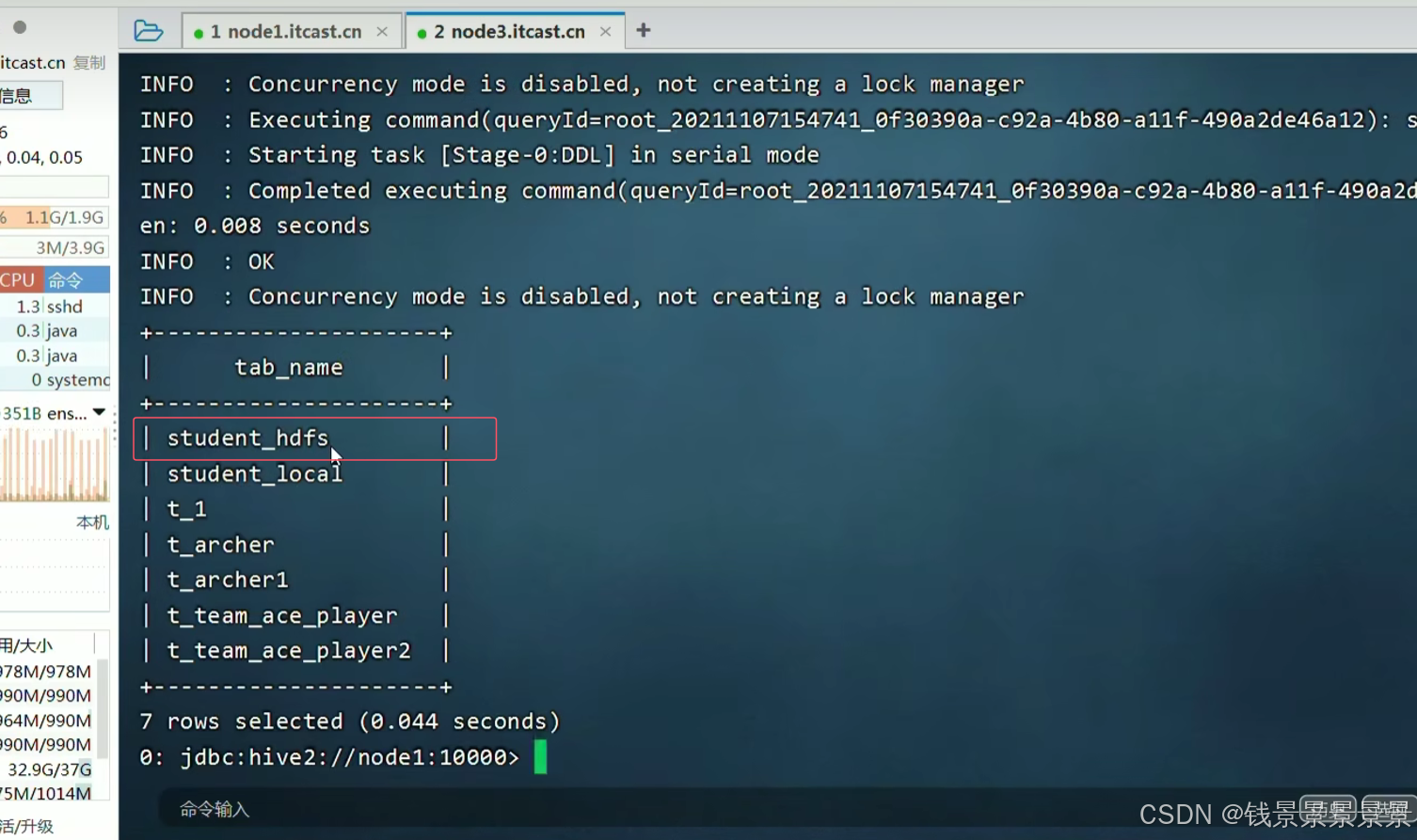
我们继续加载数据
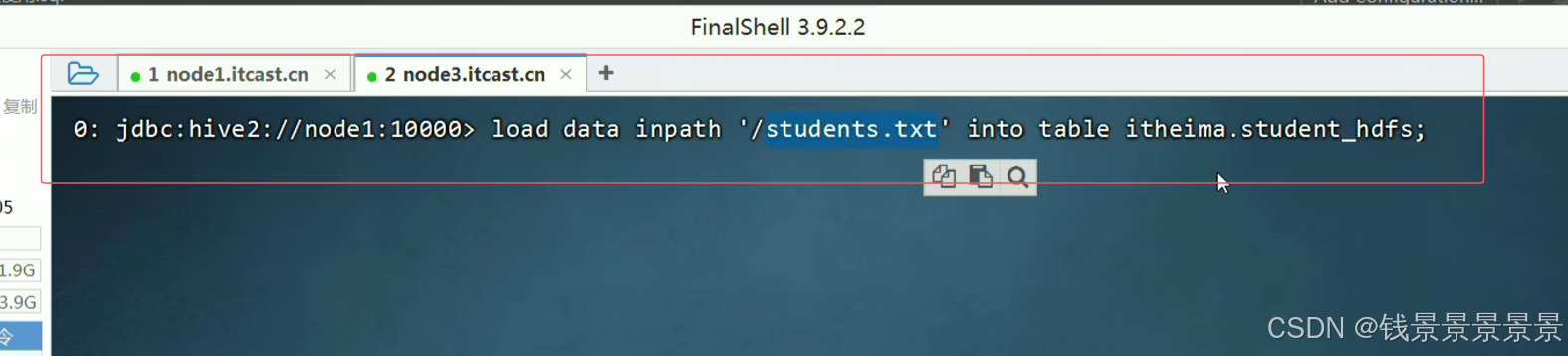
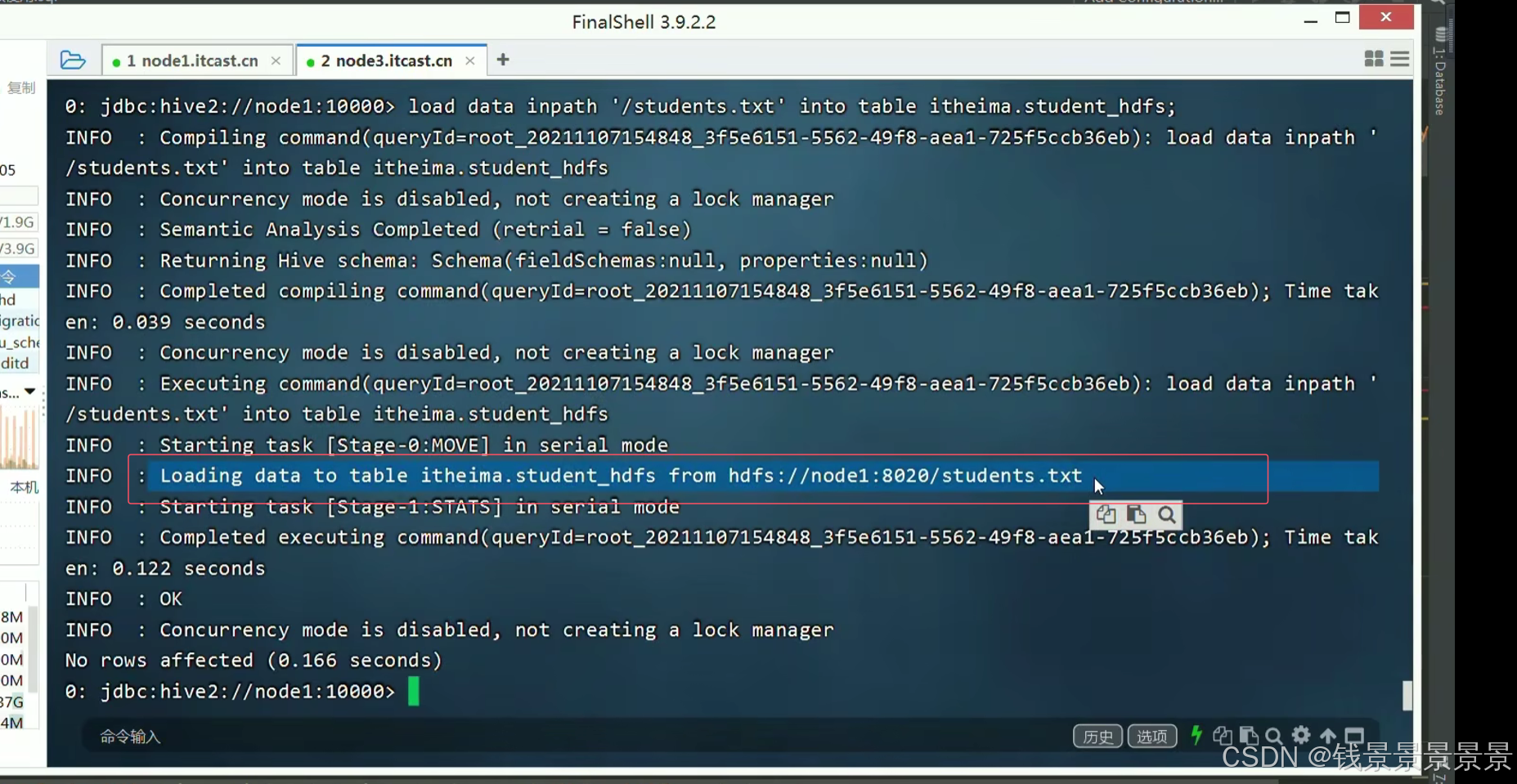
我们发现根目录下的文件没有了
3.Hive SQL-DML-insert插入数据


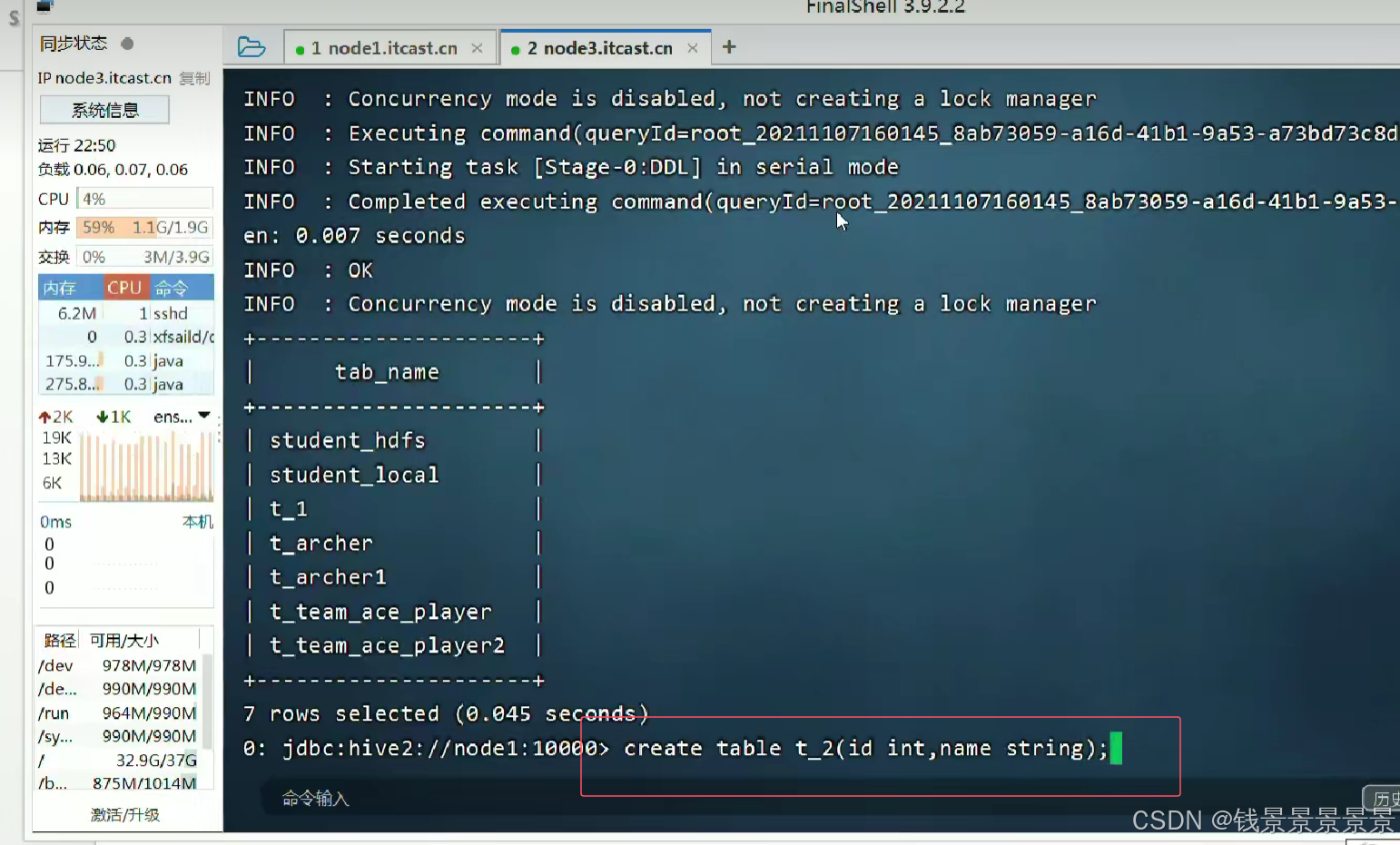
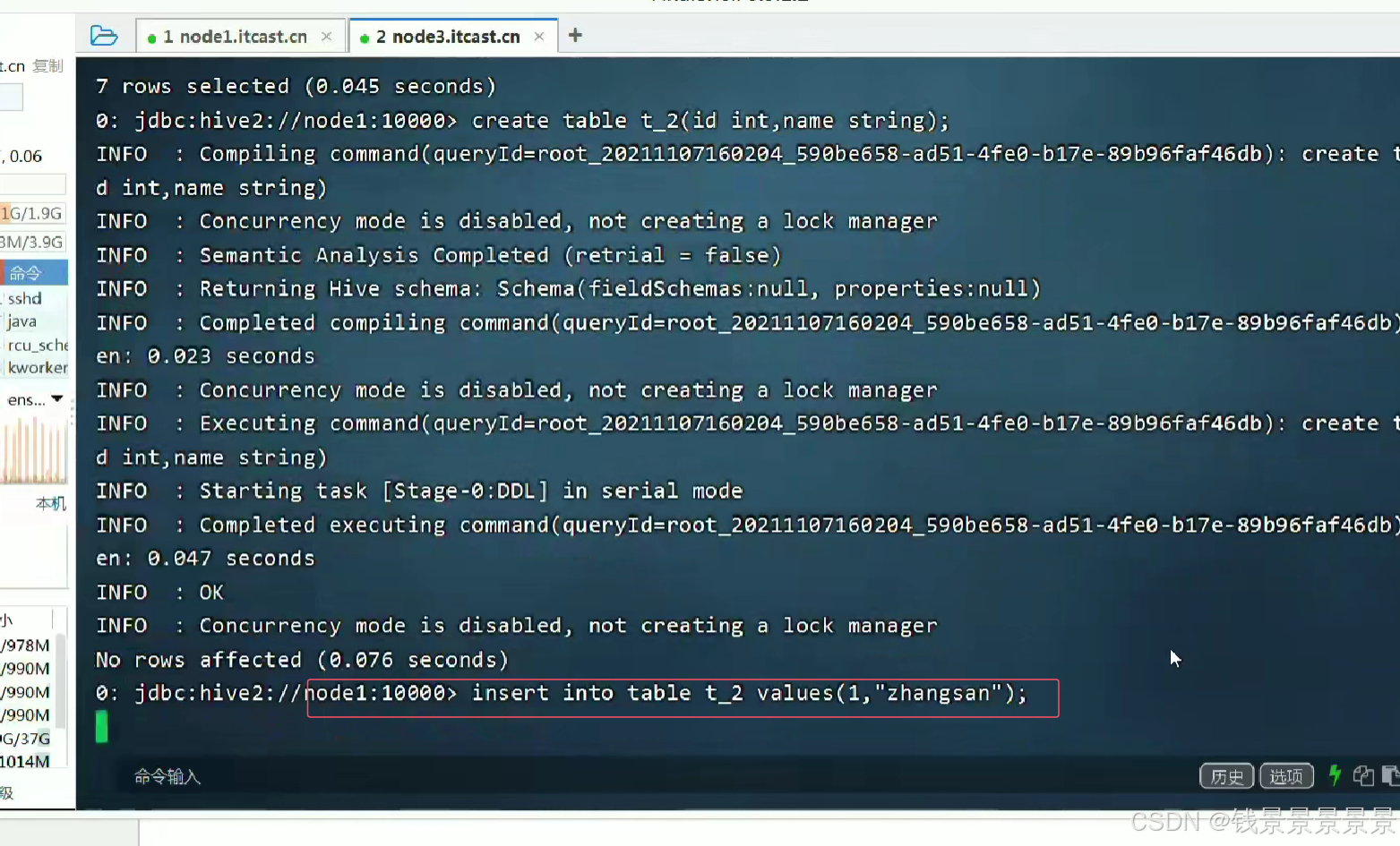

insert插了一条数据花了47秒
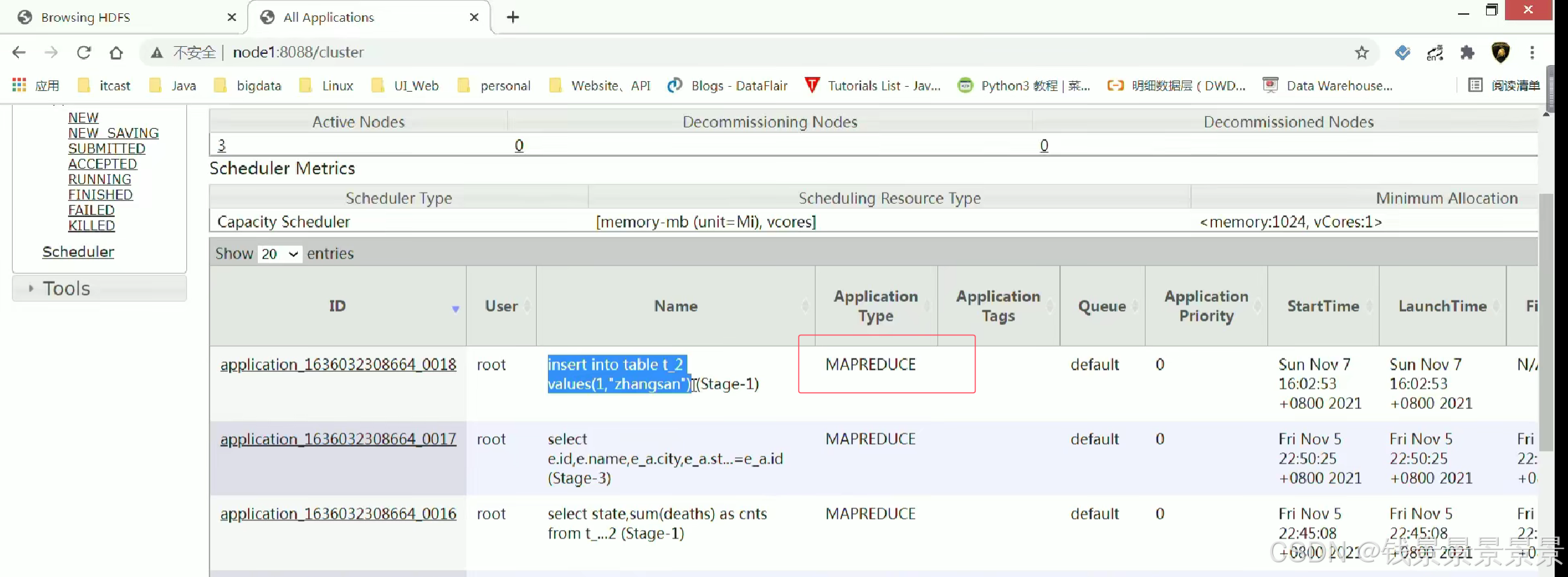
因为我们底层使用了Mr程序

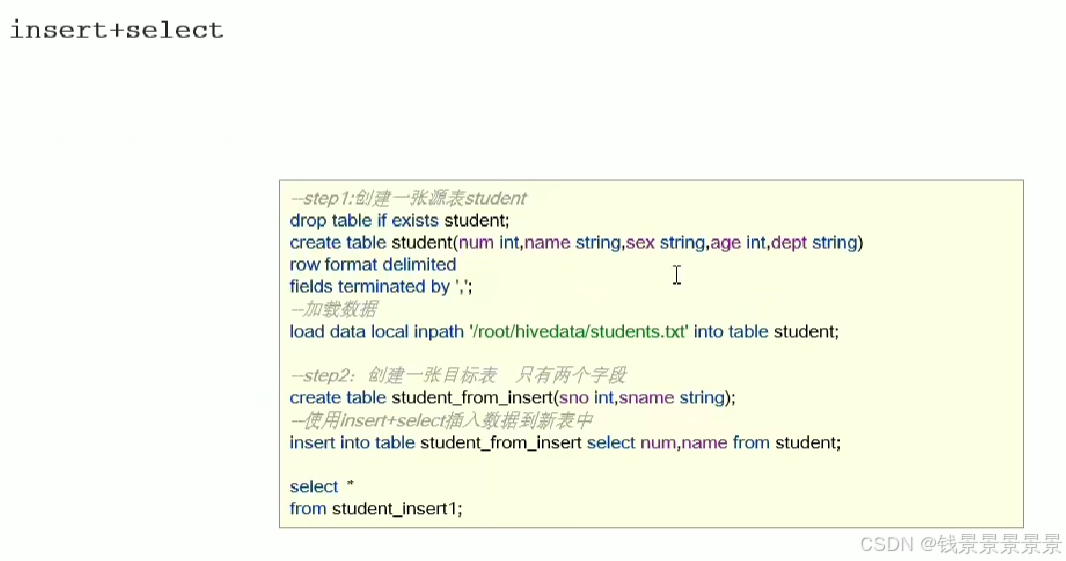
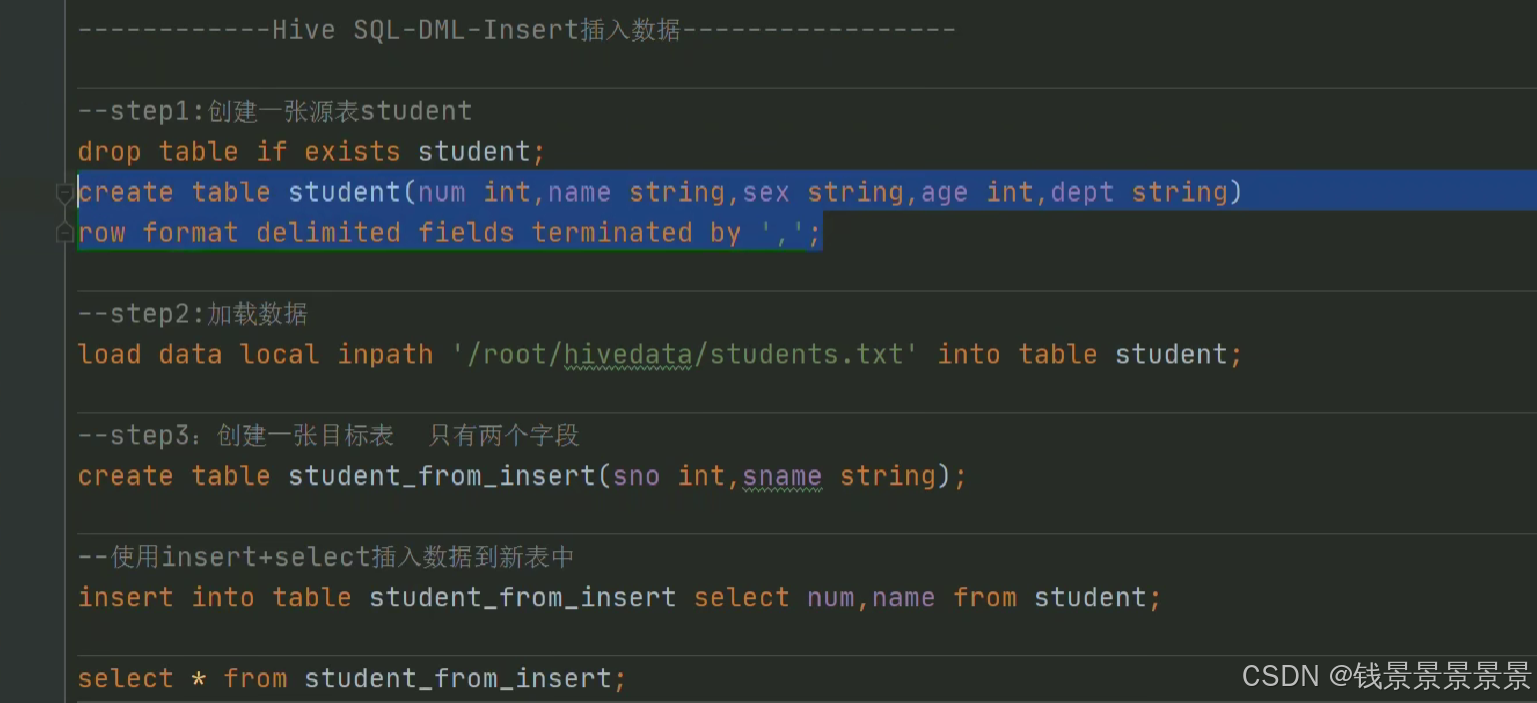
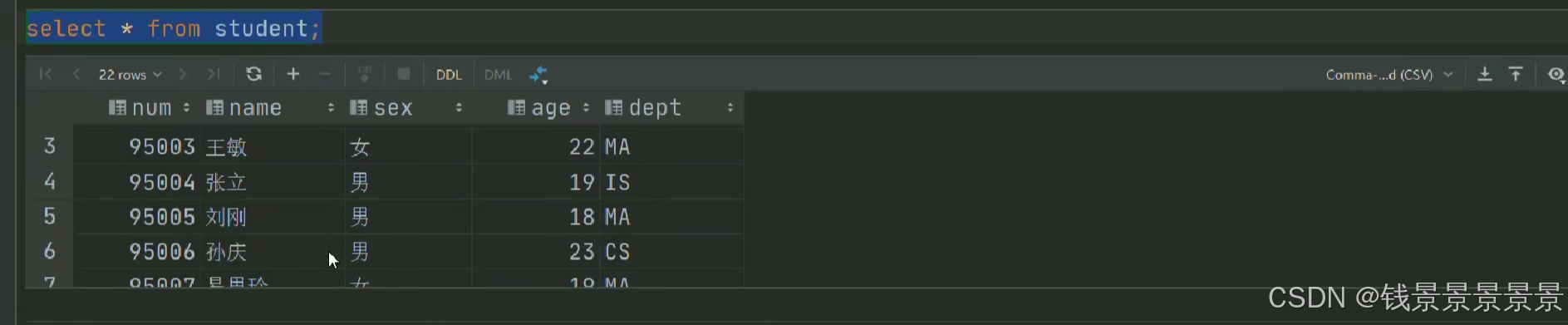
我们首先创建一个表student
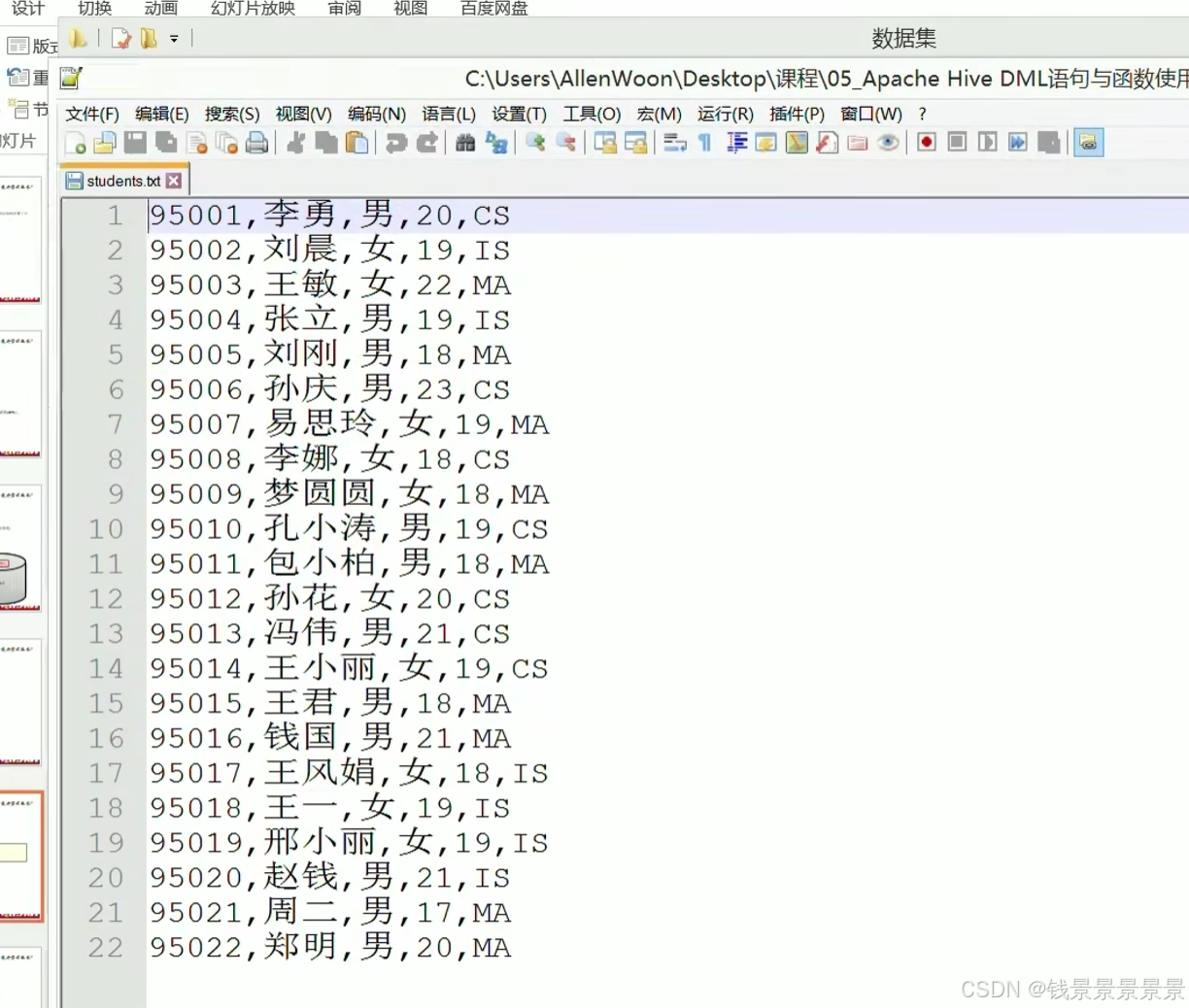
然后将student.txt加载到表student
再创建另外一个空表
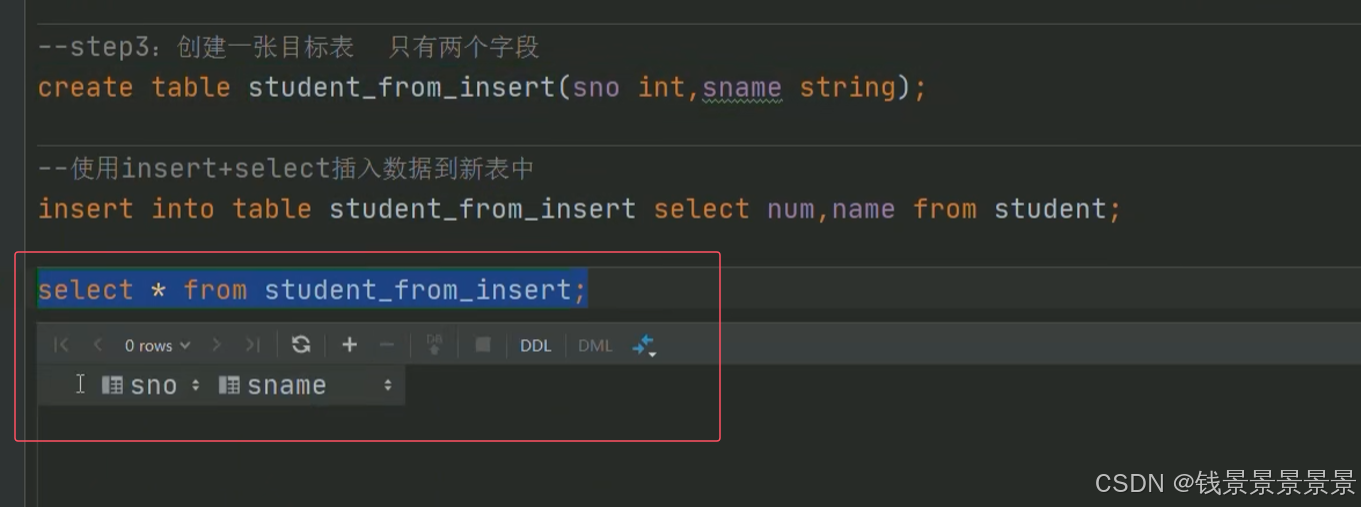
使用insert+select
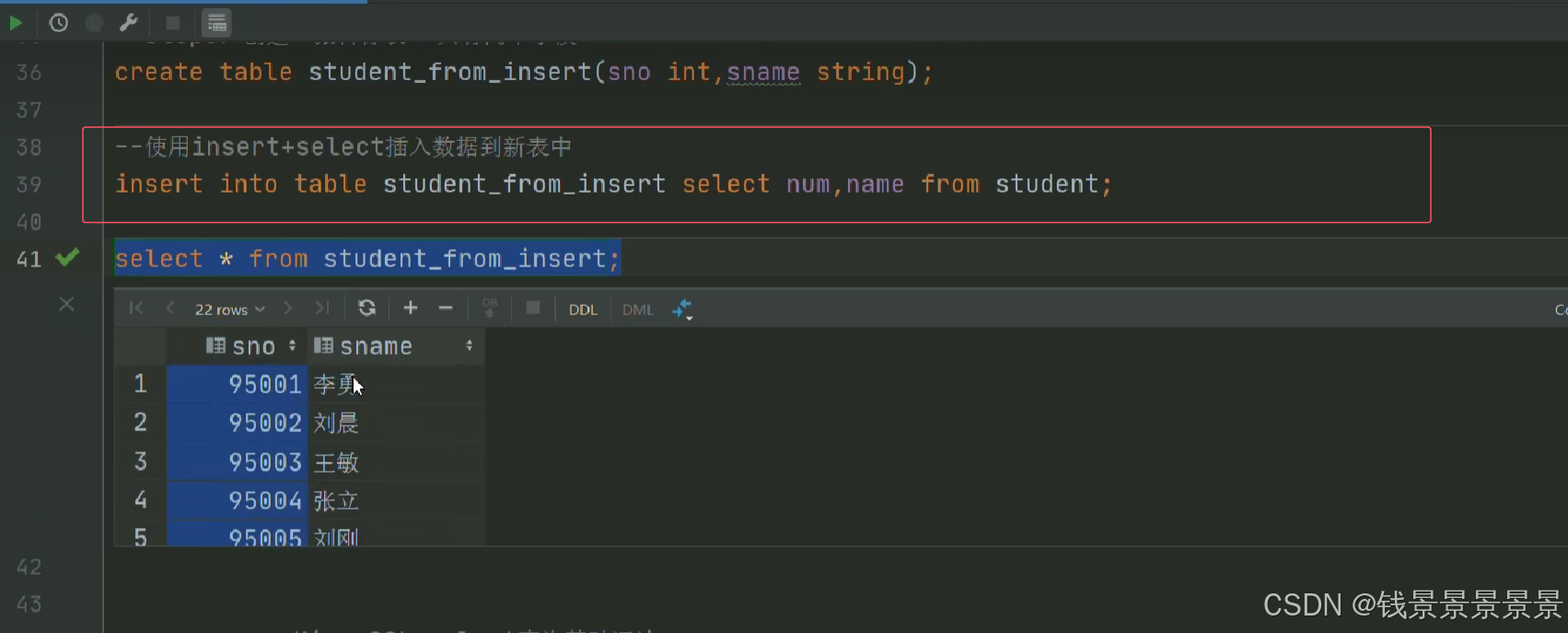
4.Hive SQL-DML-select查询-语法书和环境准备



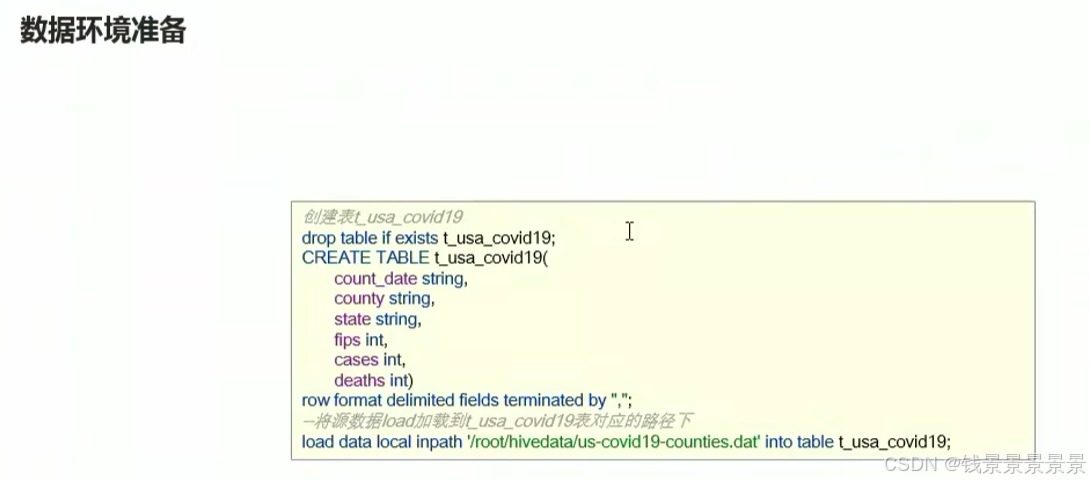
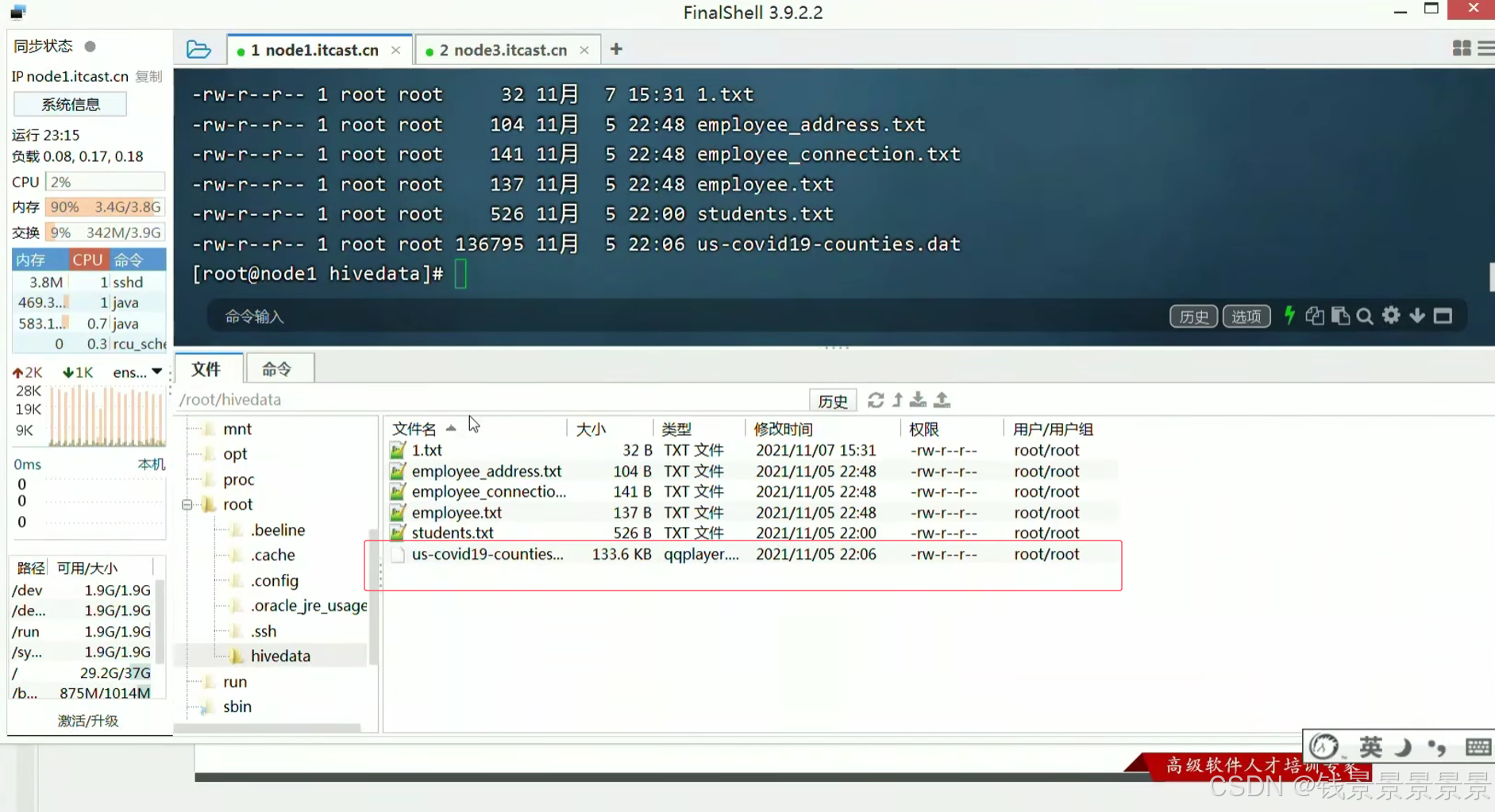
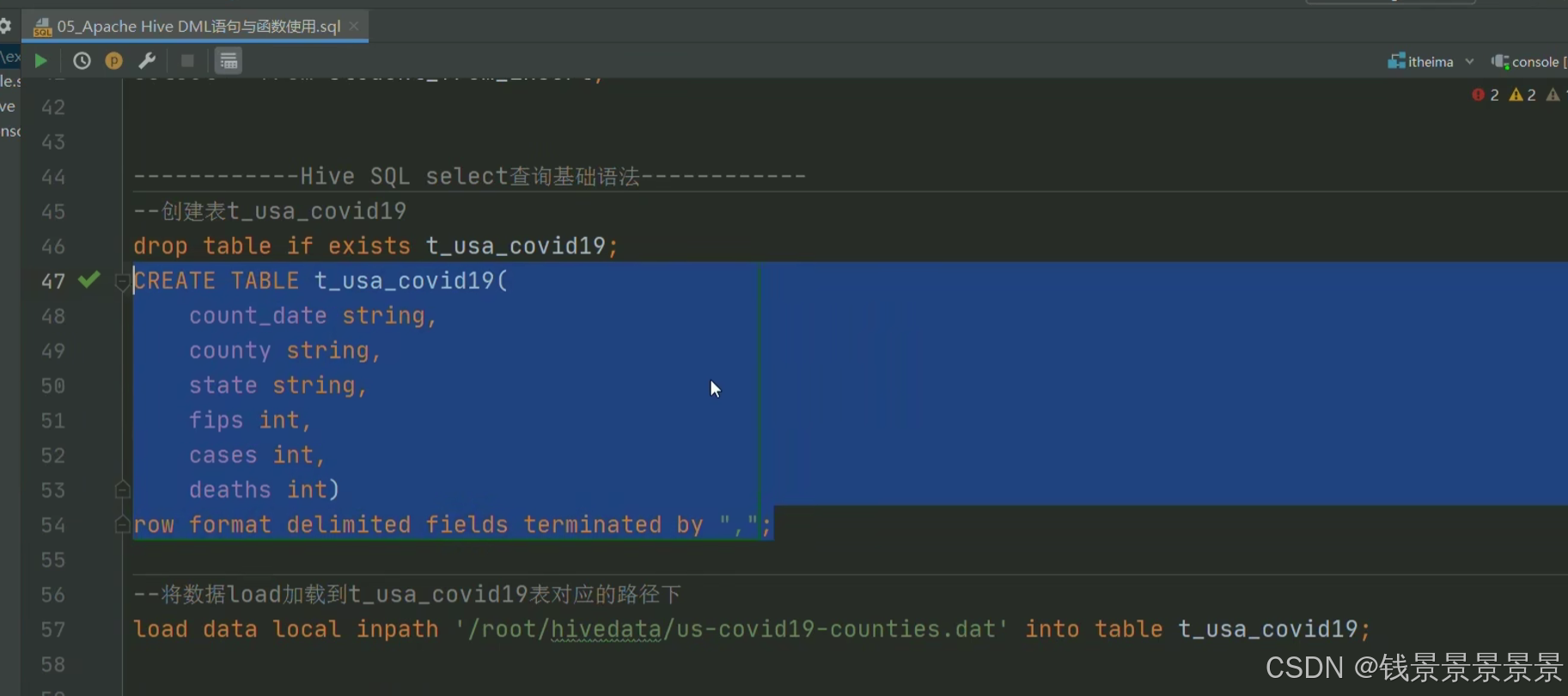
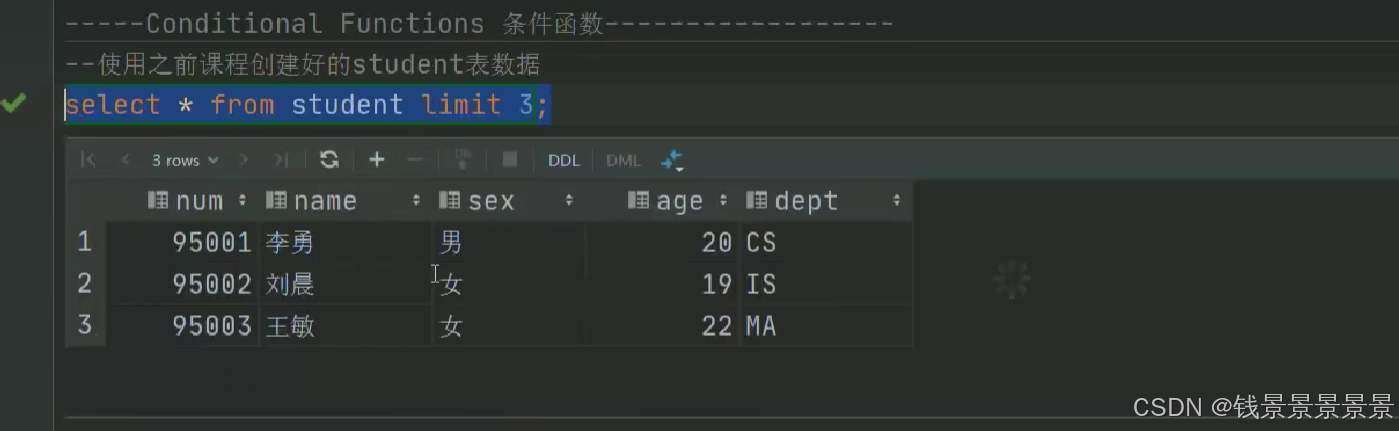
下面我们创建一个表
将这个数据映射成功
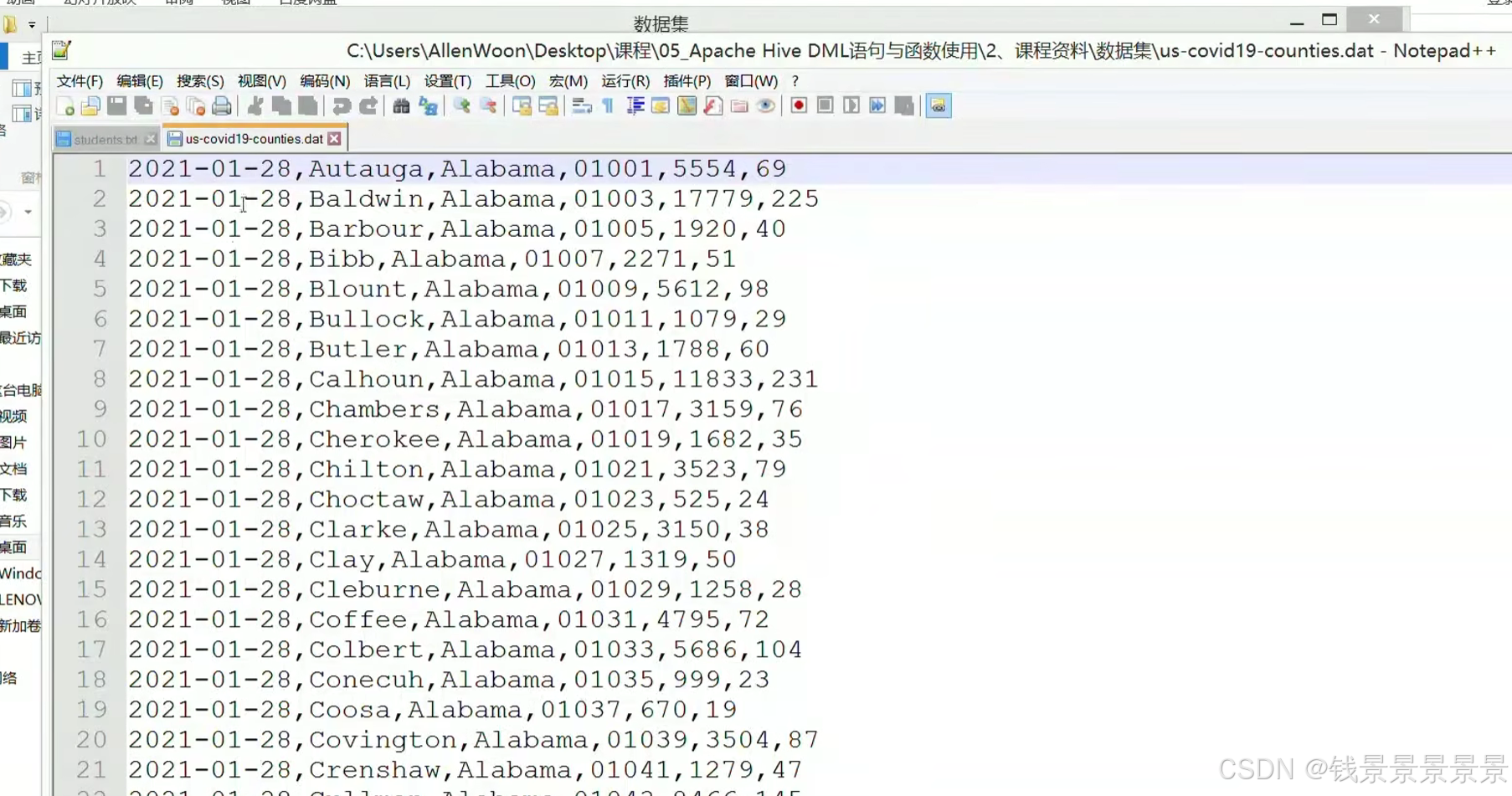
首先将我们的文件上传到Linux
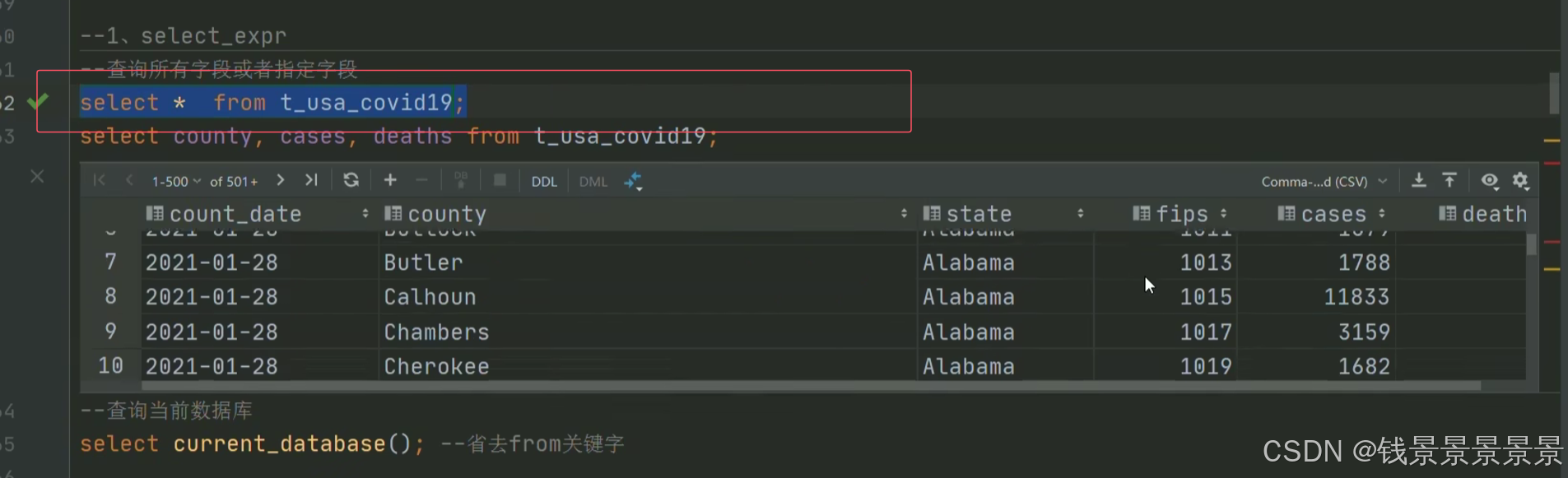
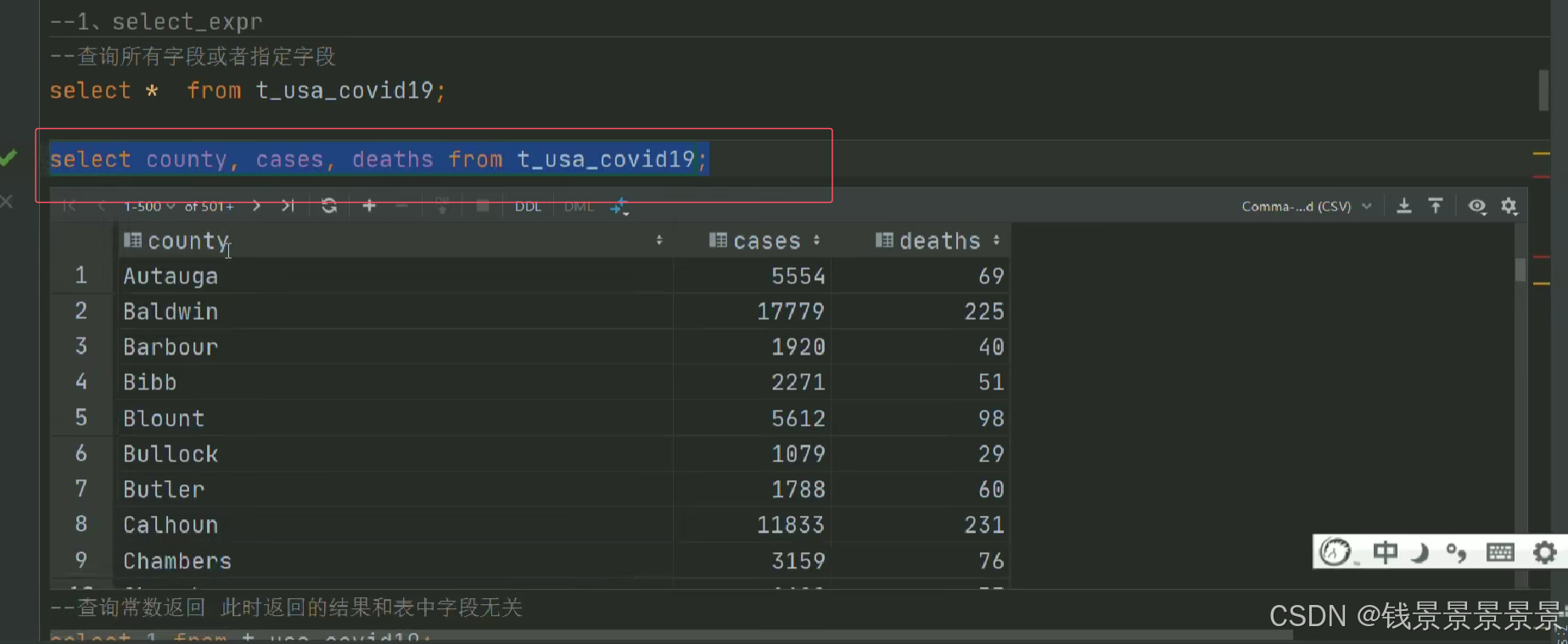
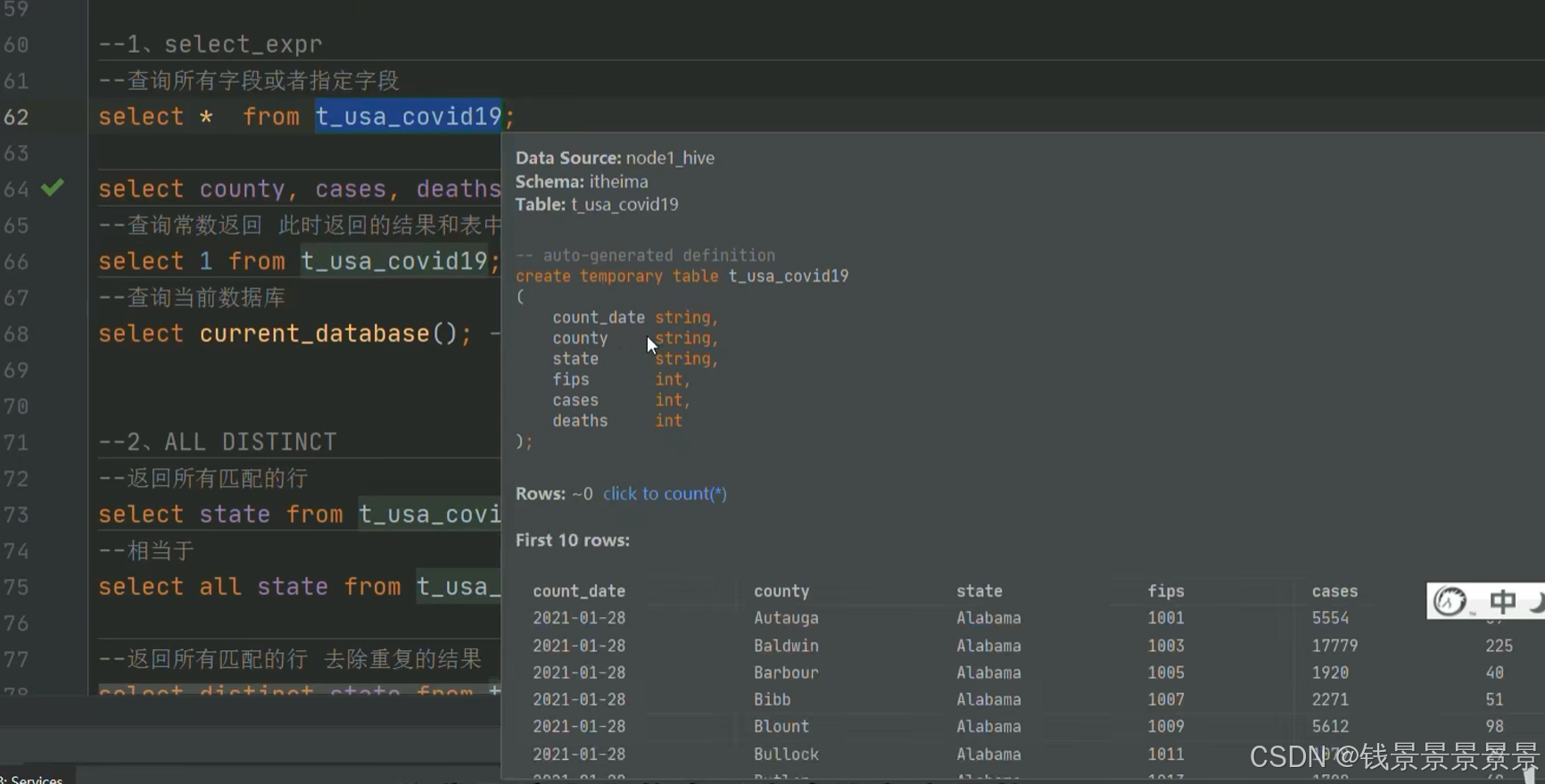
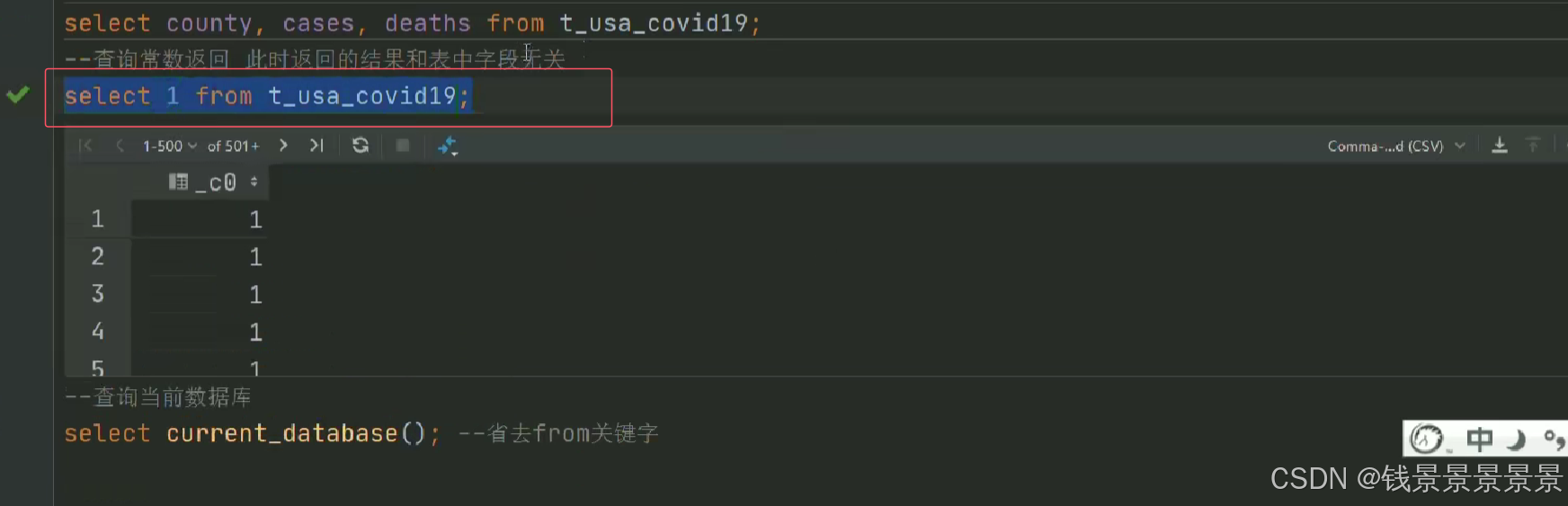
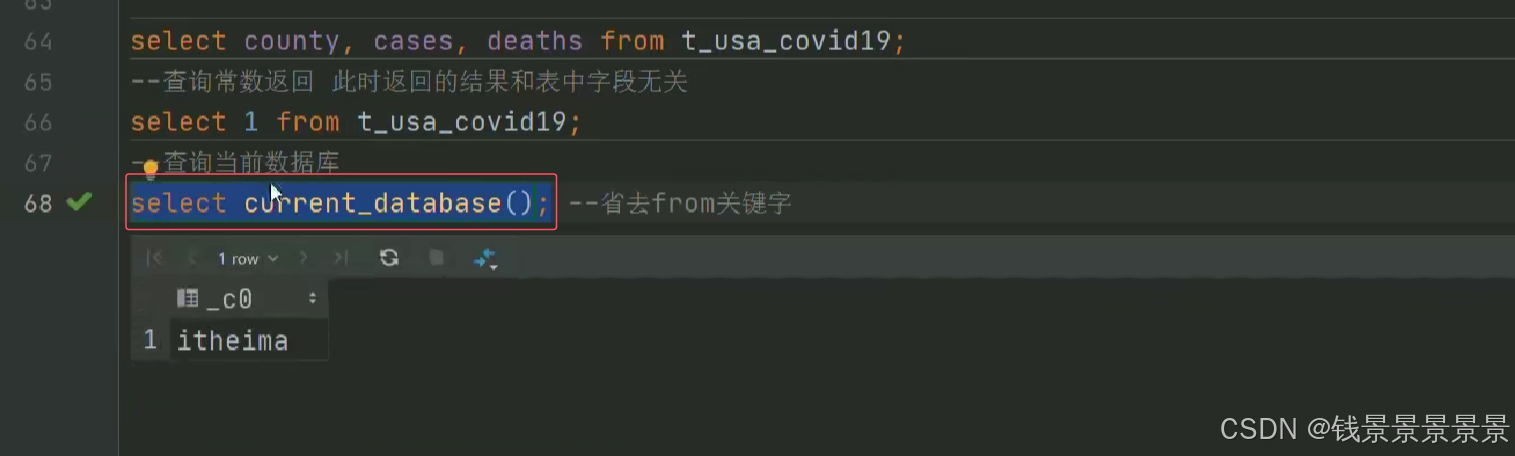
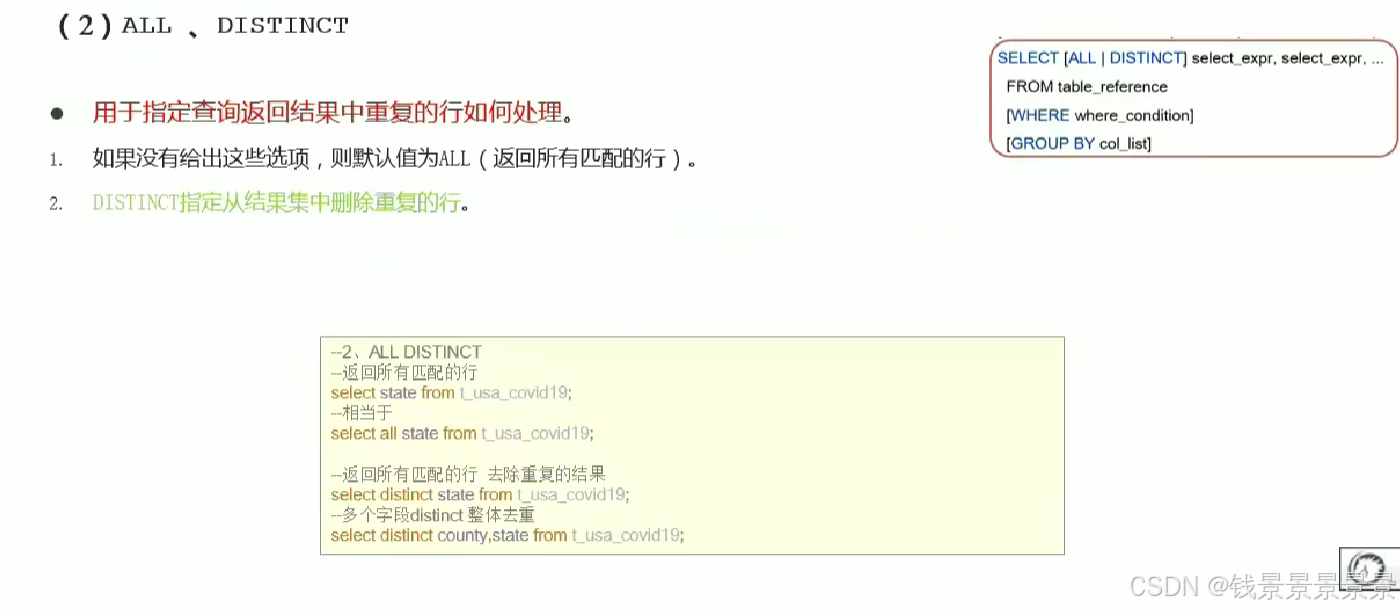
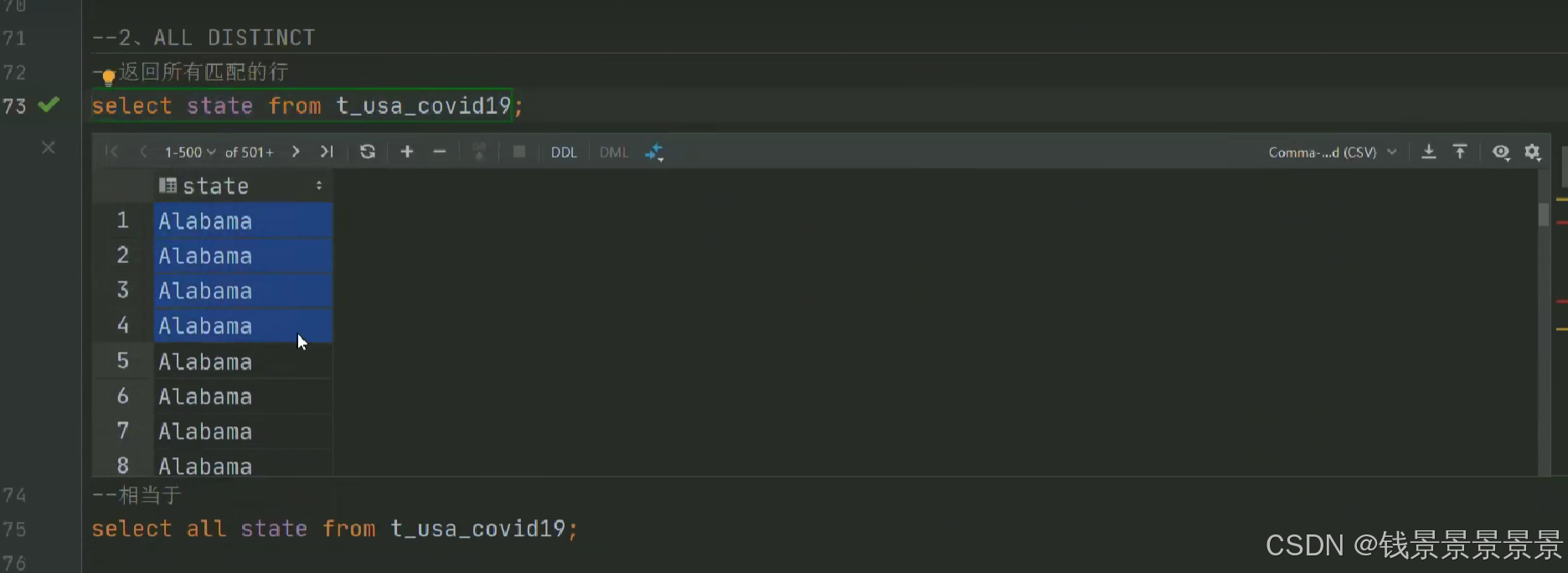
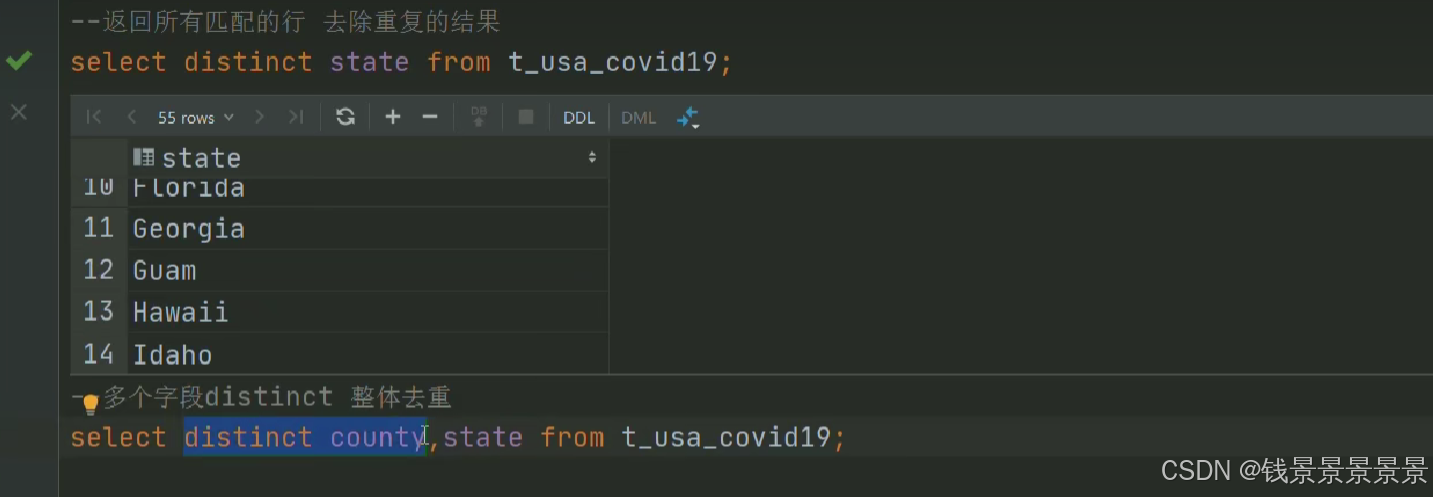
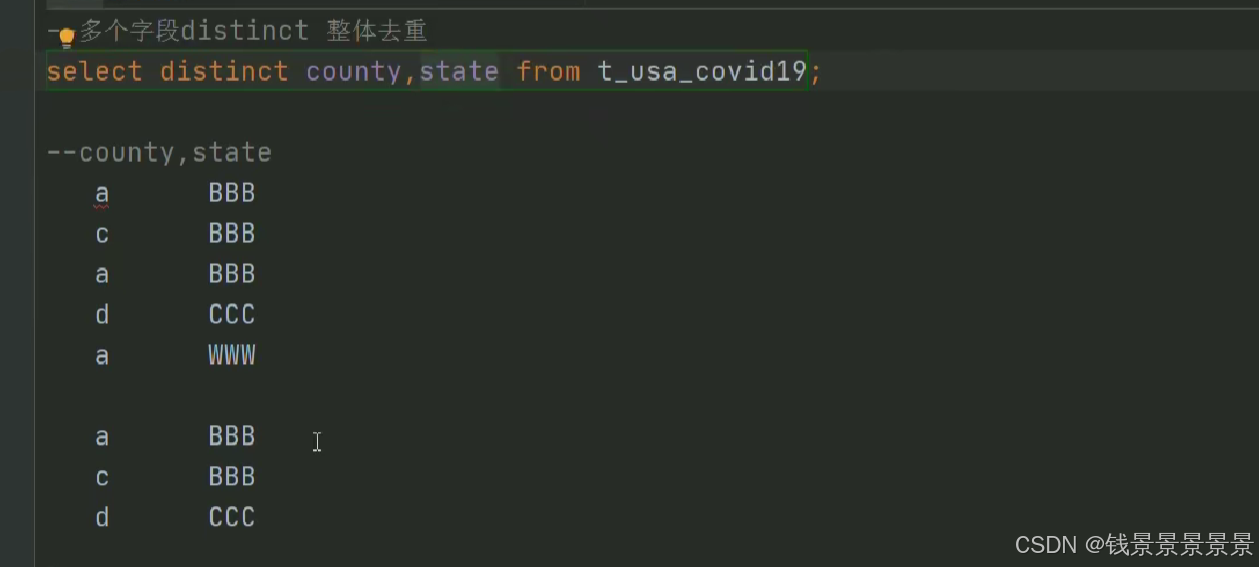
5.Hive SQL-DML-select查询-列表达式和distinct去重

选中表点击ctrl+q,可以查看表信息
6.Hive SQL-DML-select查询-where条件过滤


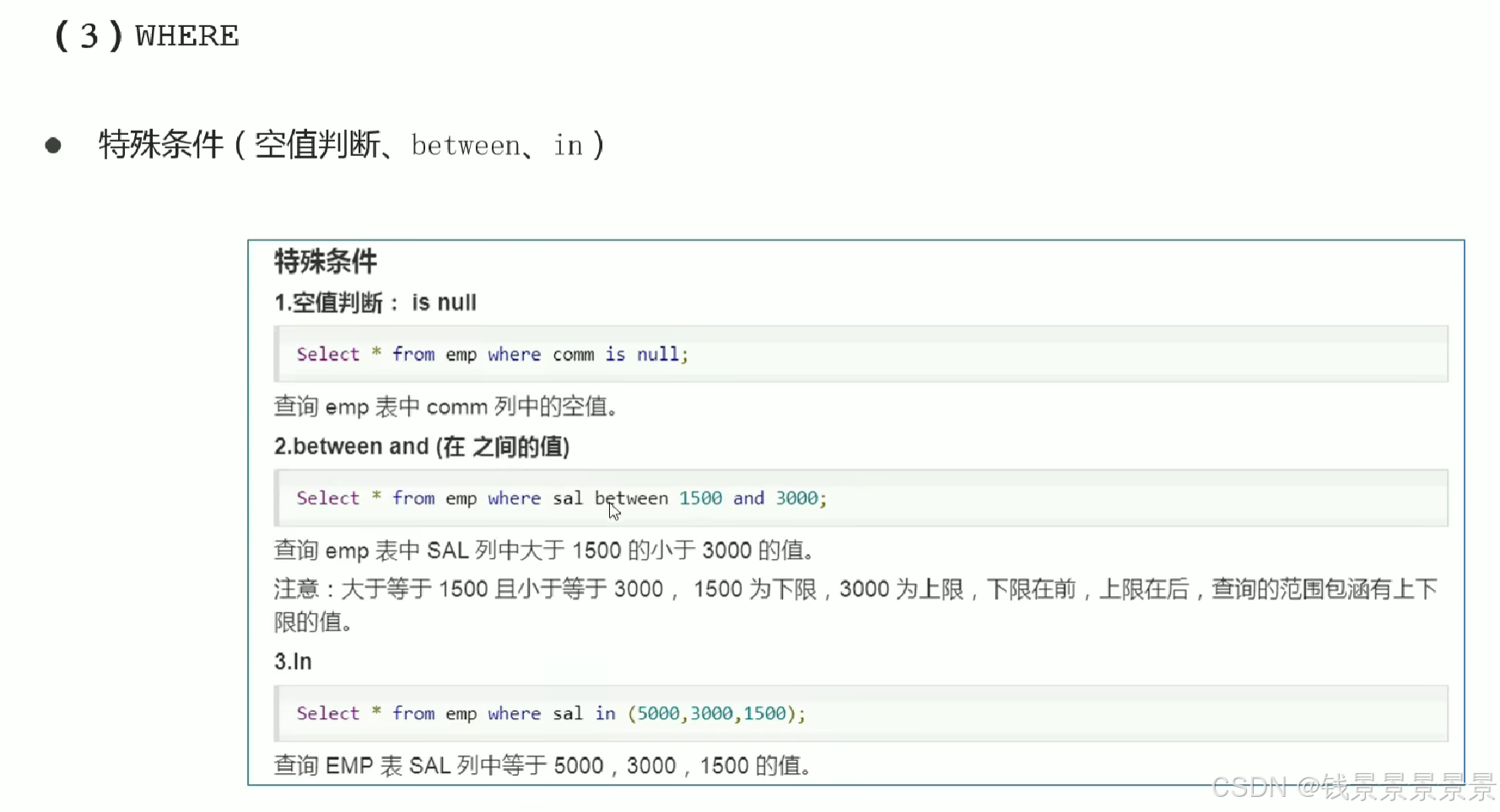
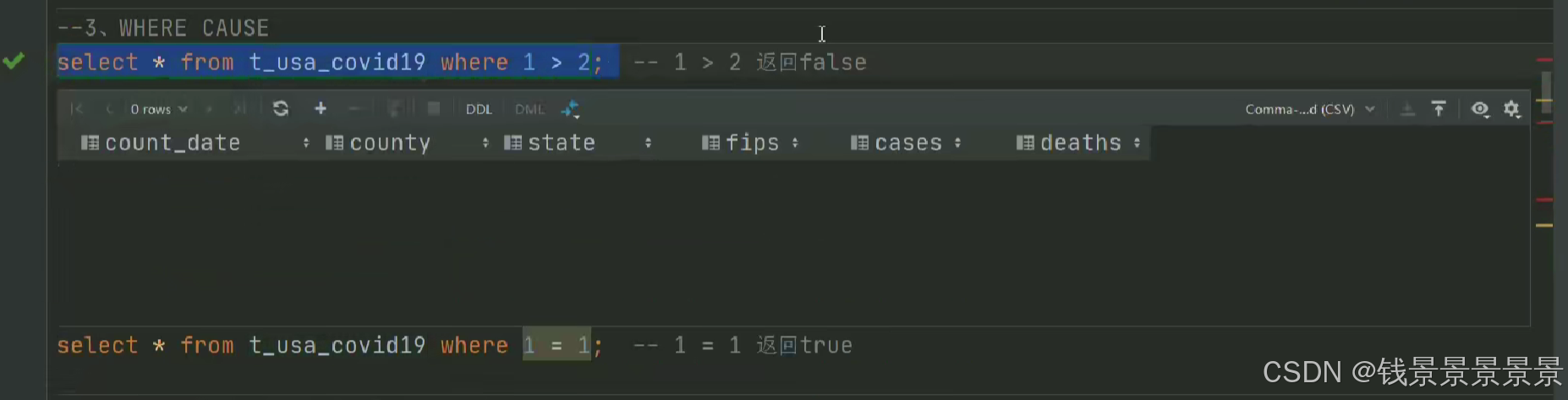
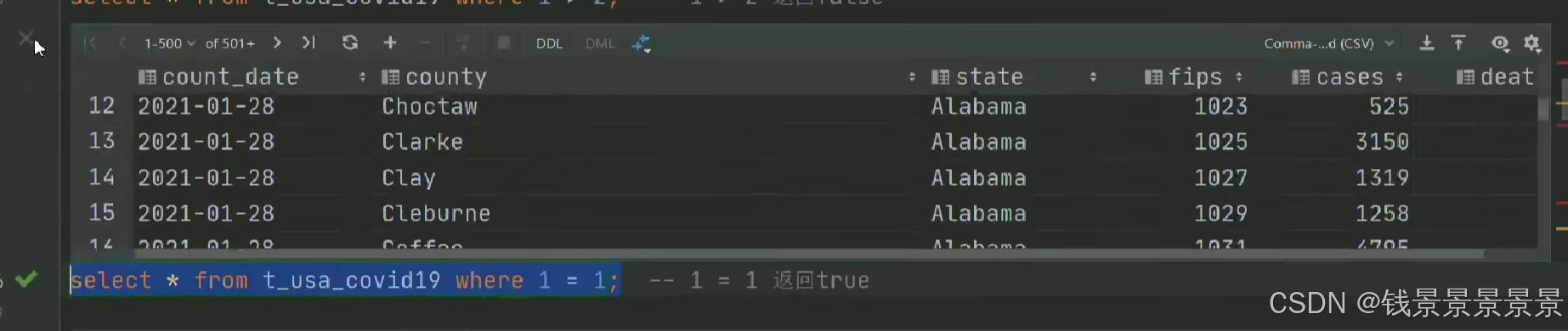
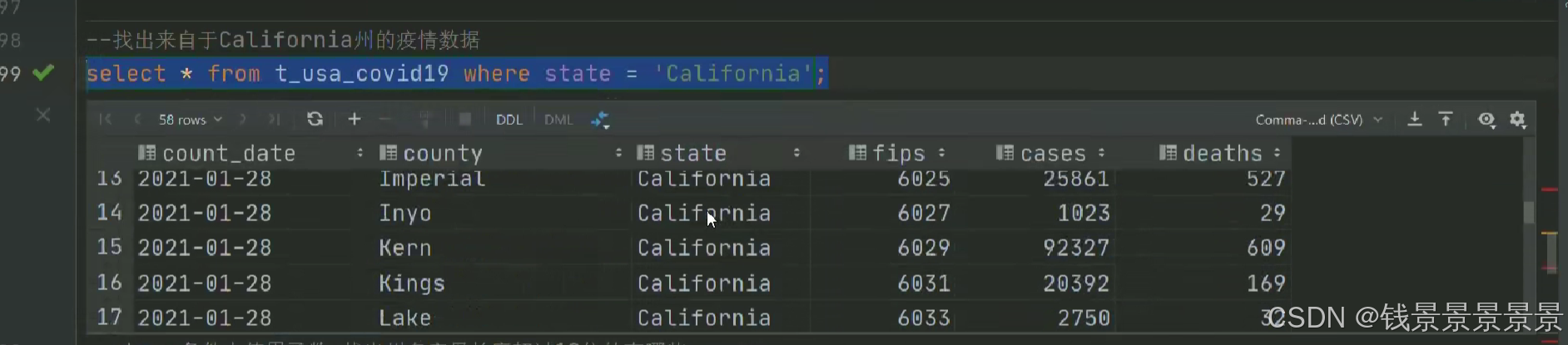

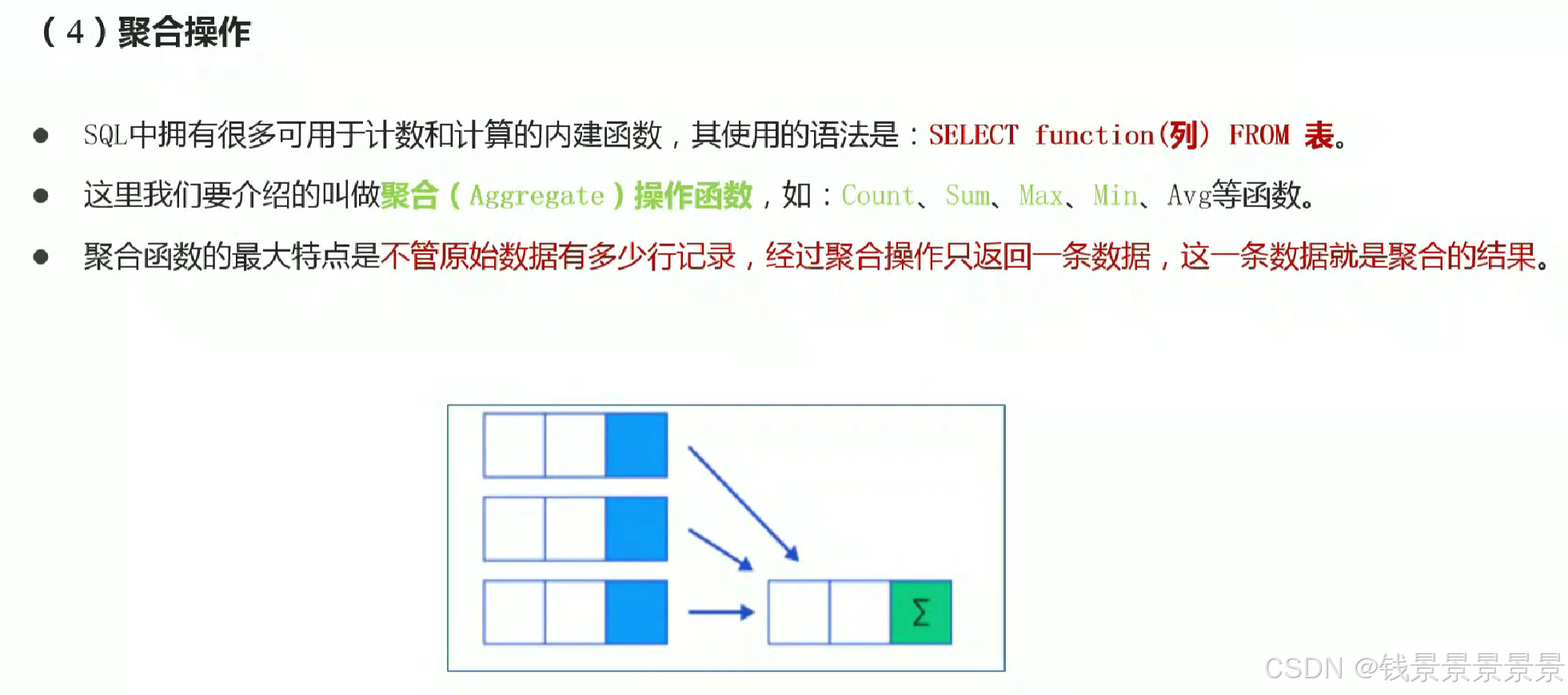
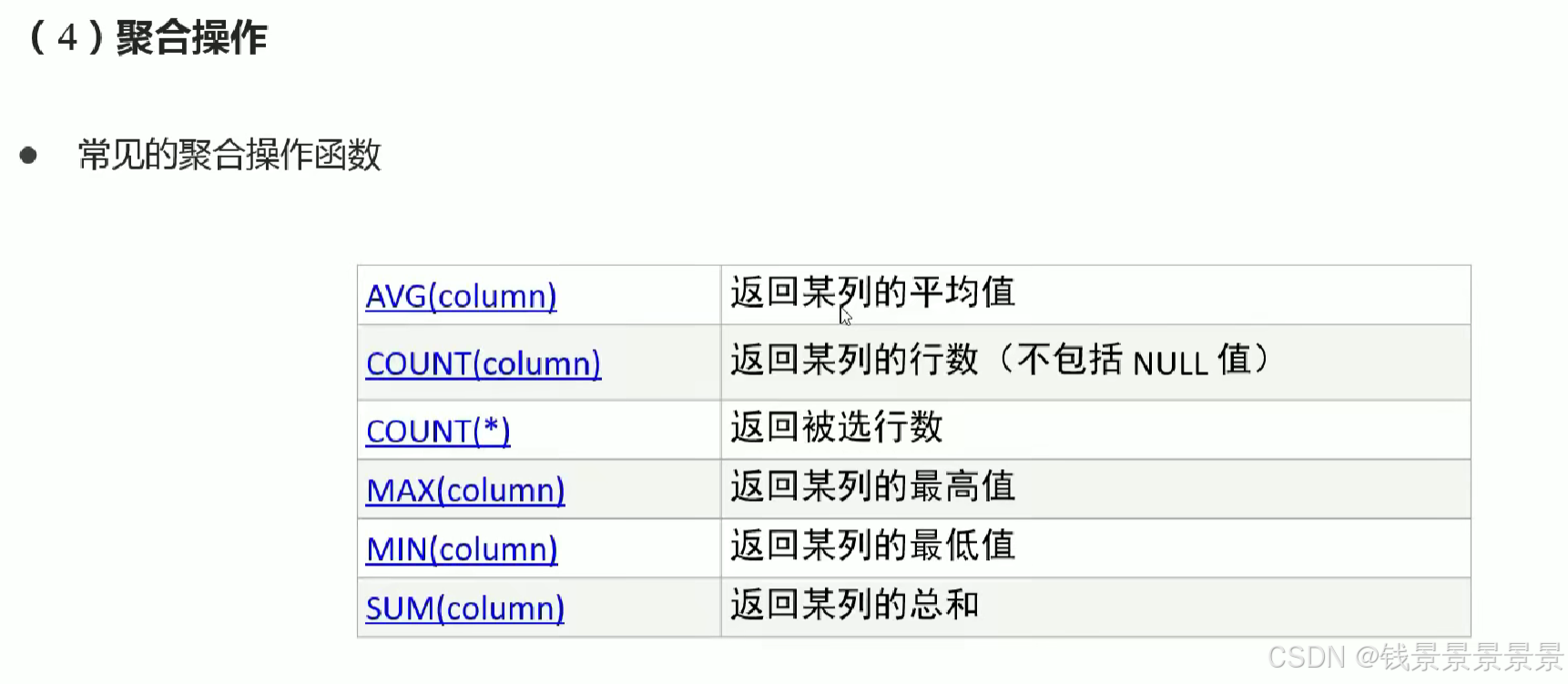
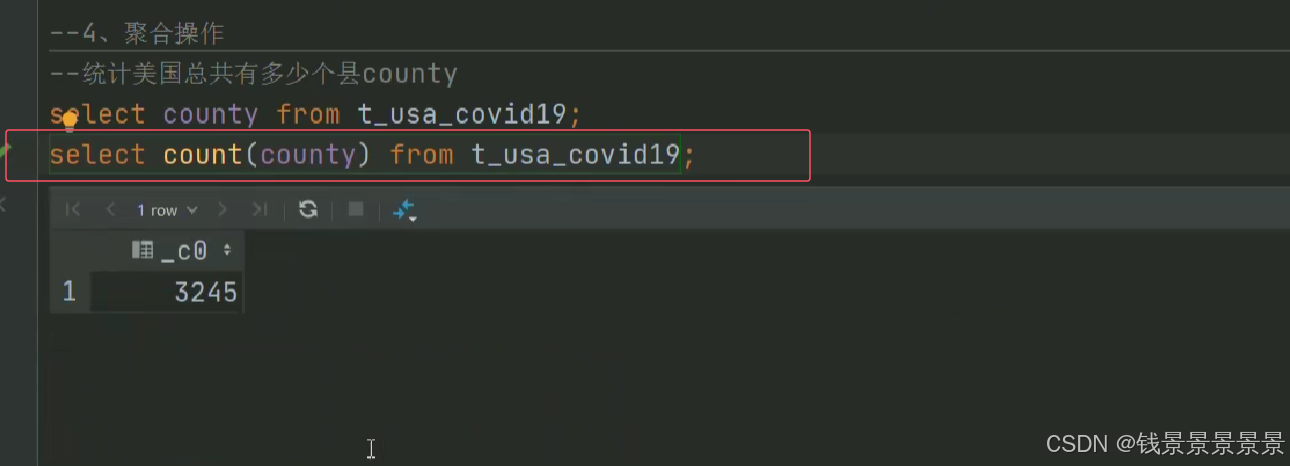
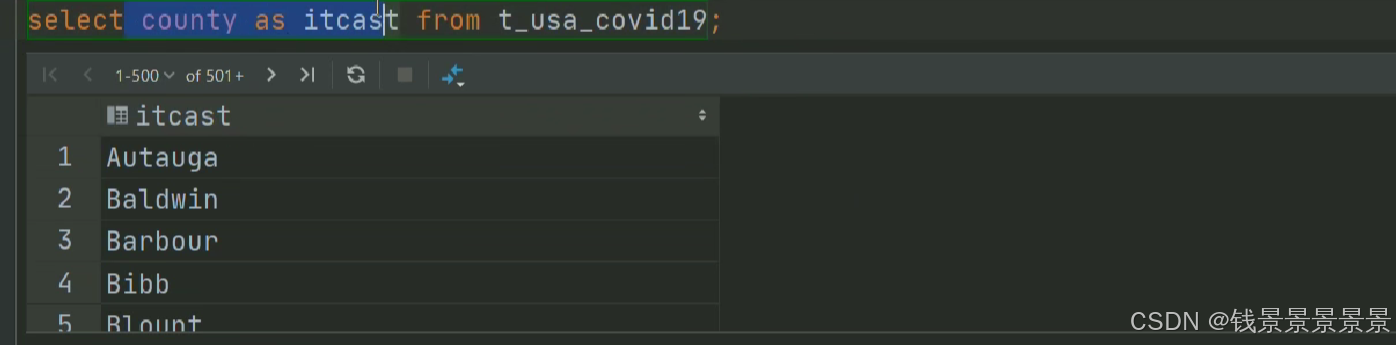
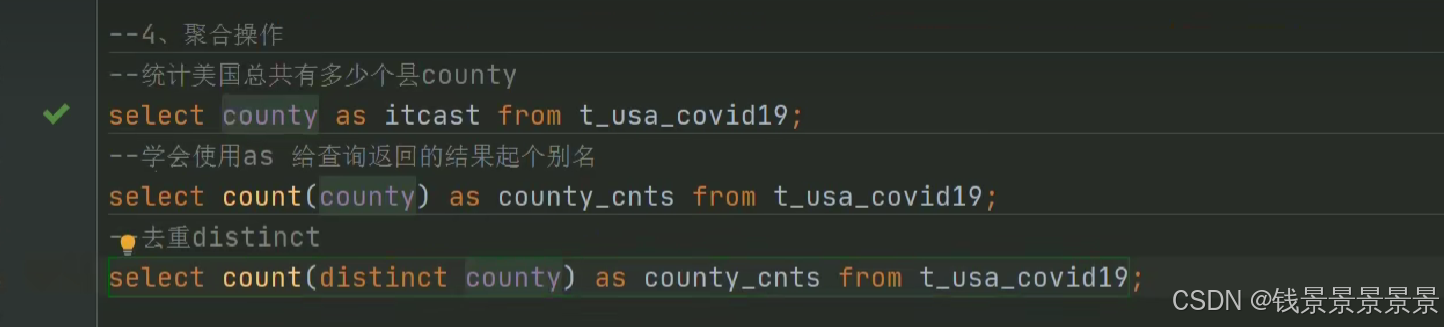
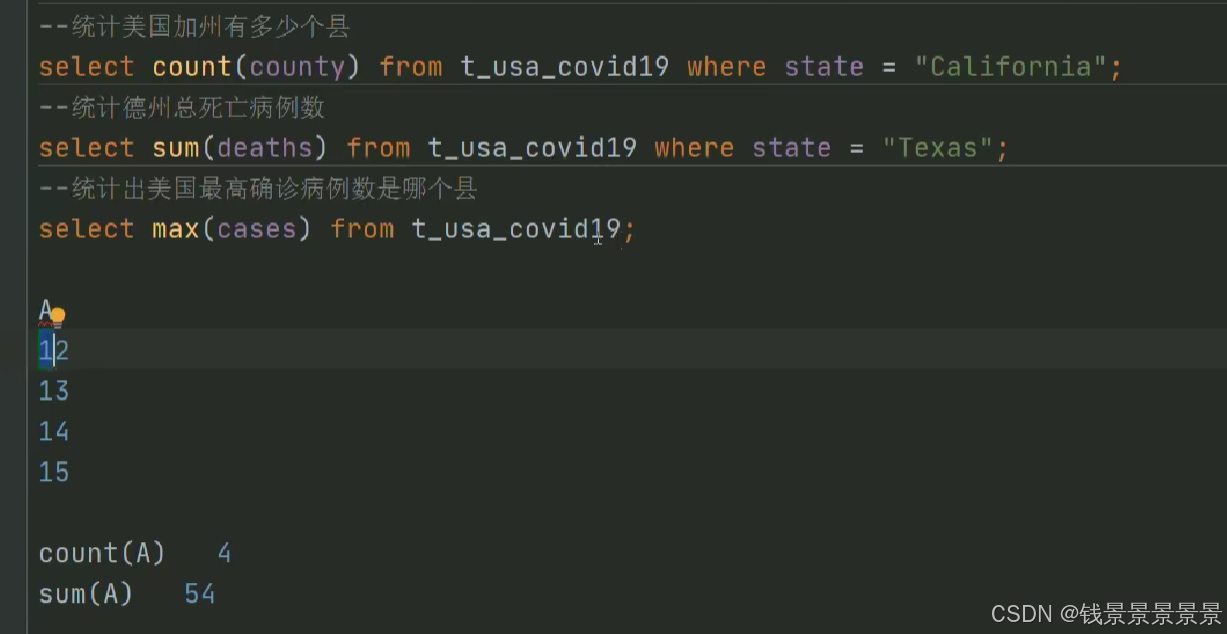
7.Hive SQL-DML-select查询-聚合操作aggregate
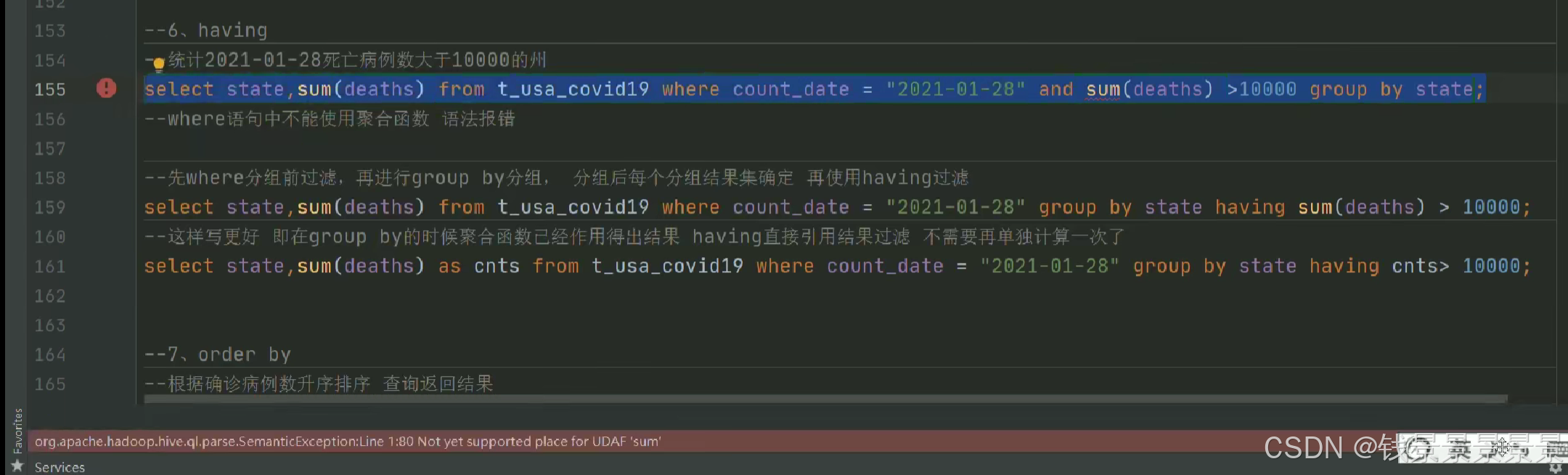
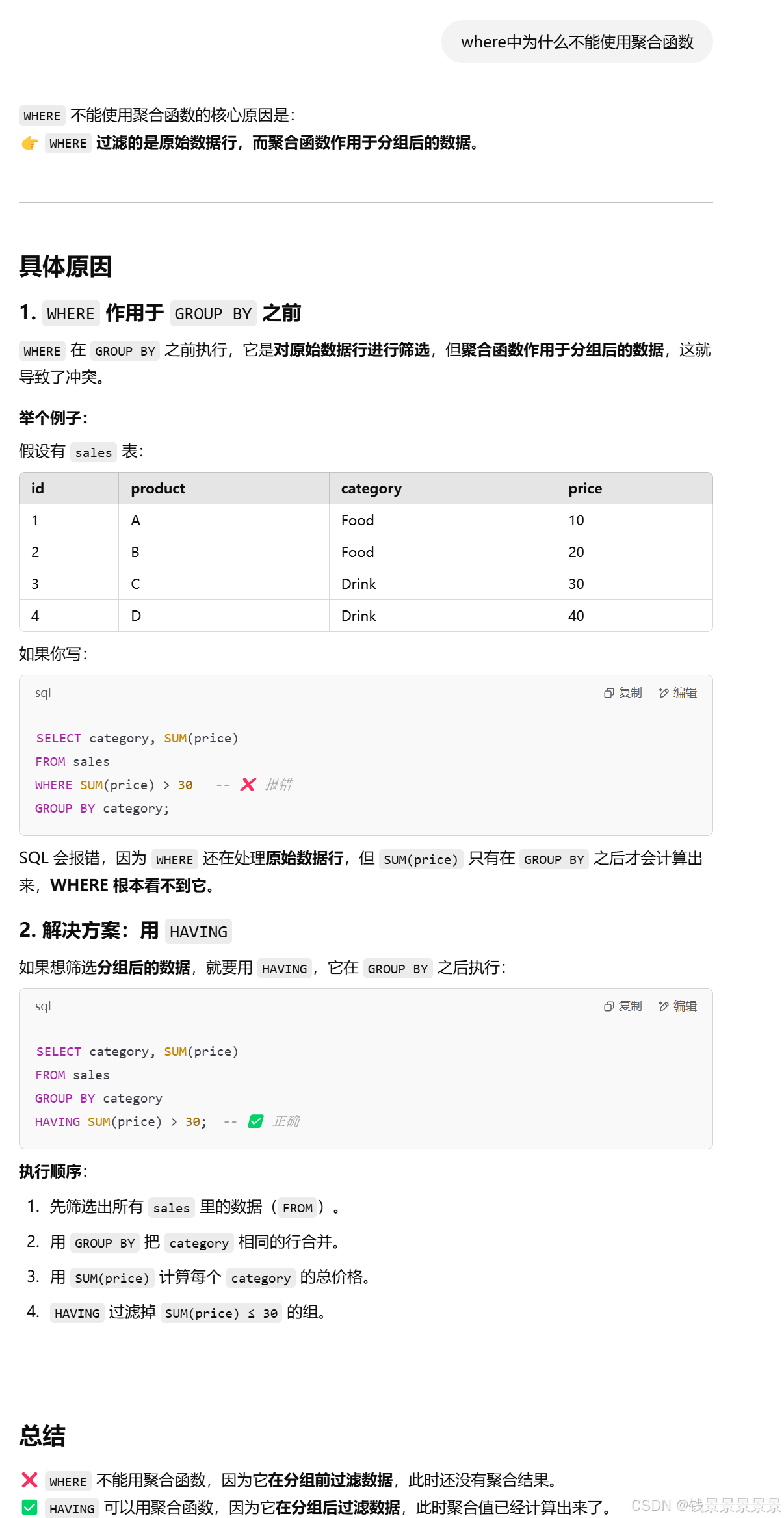
where中不能使用聚合函数

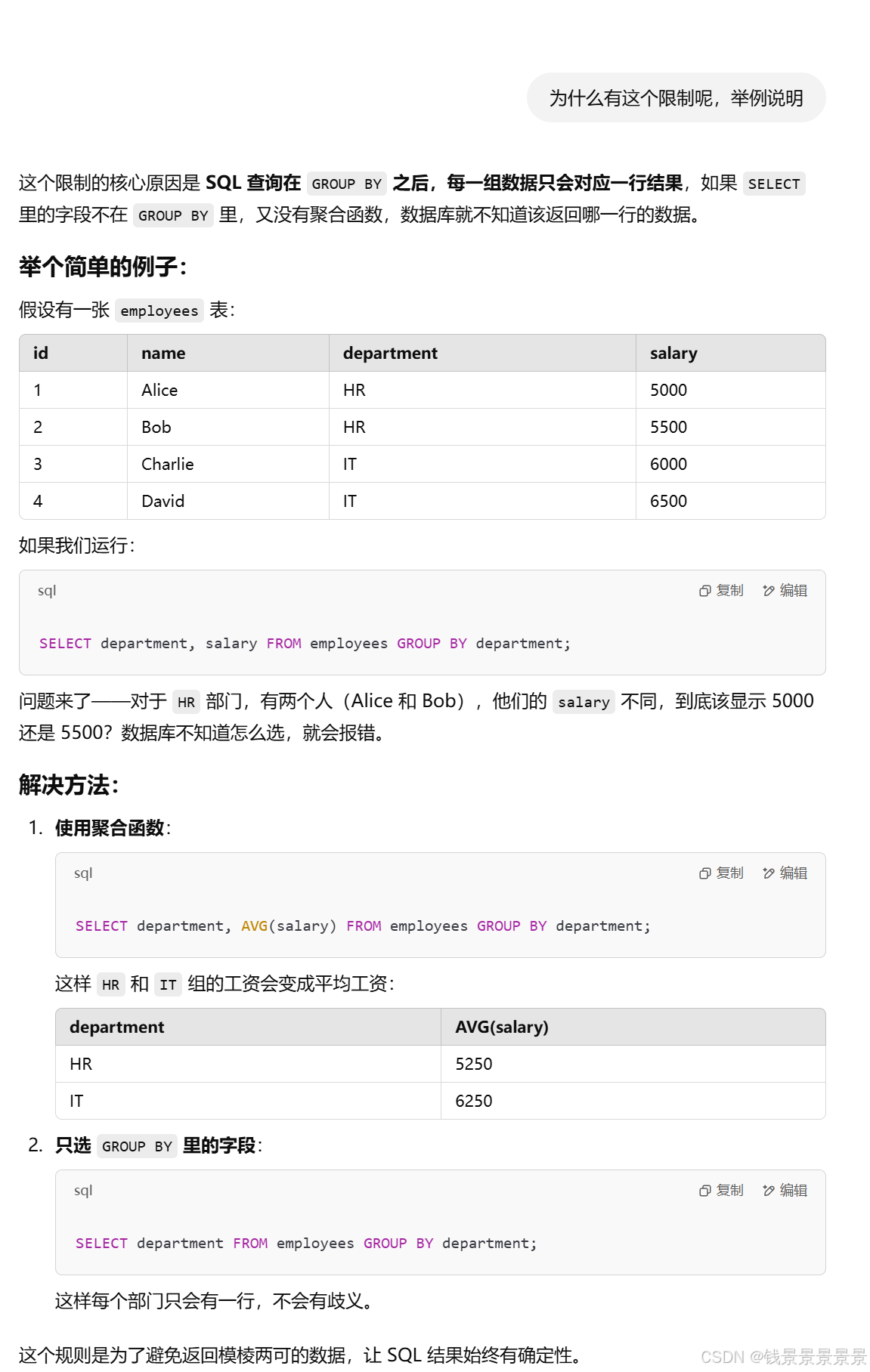
8.Hive SQL-DML-select查询-group by分组及语法限制


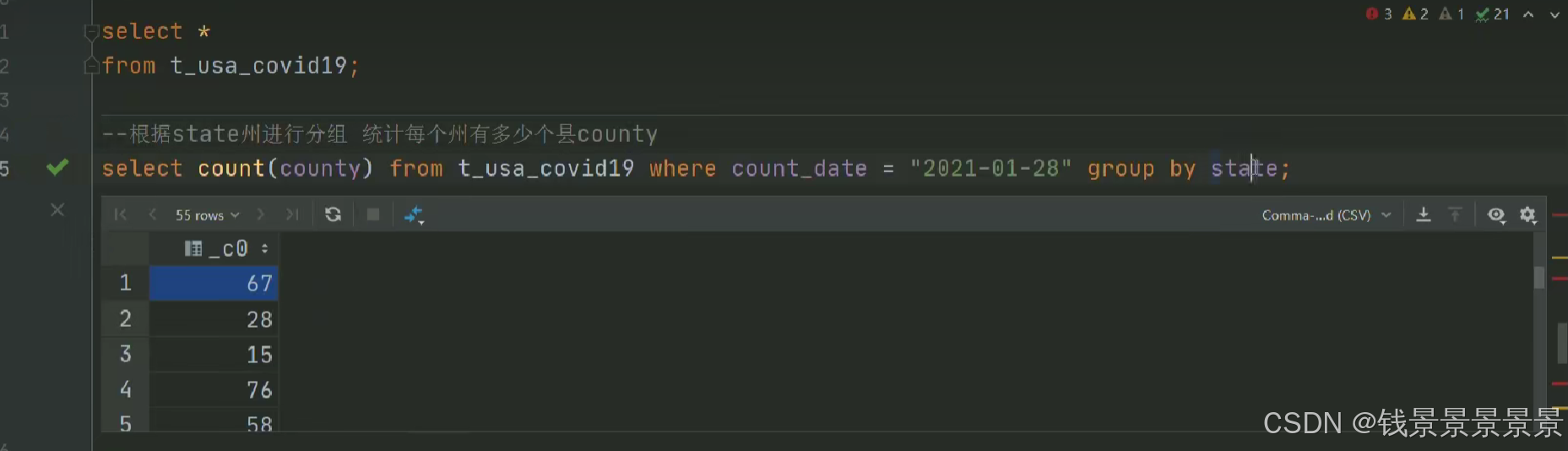
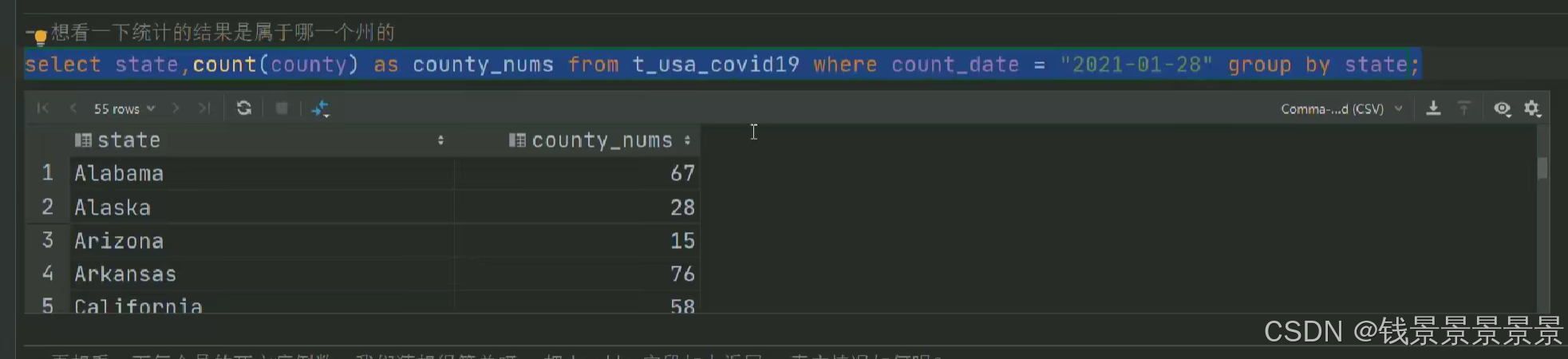
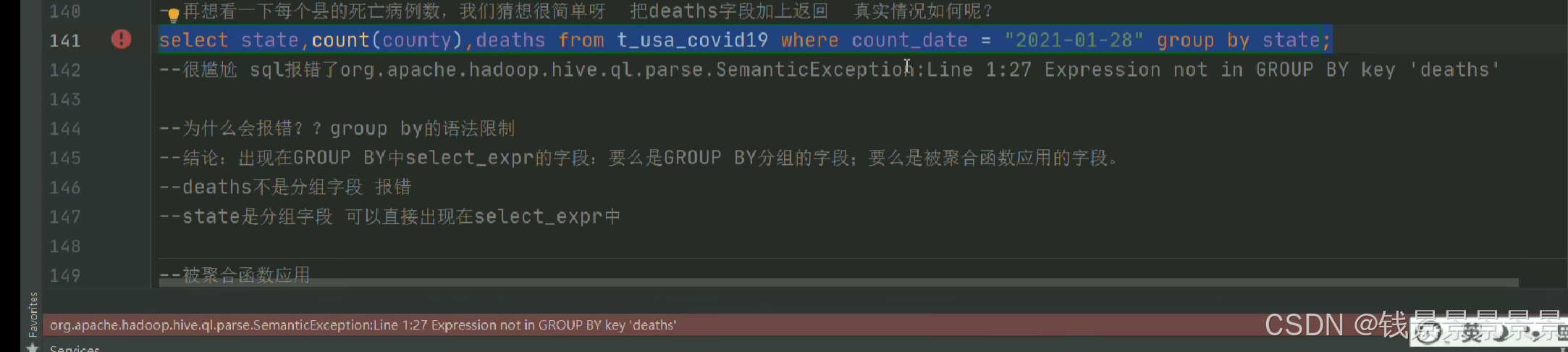
我们的state被group by分组
country被count聚合函数应用
但death什么都没有(系统不知道返回哪一行的death)


我们可以对报错做一个修改

9.Hive SQL-DML-select查询-having过滤操作
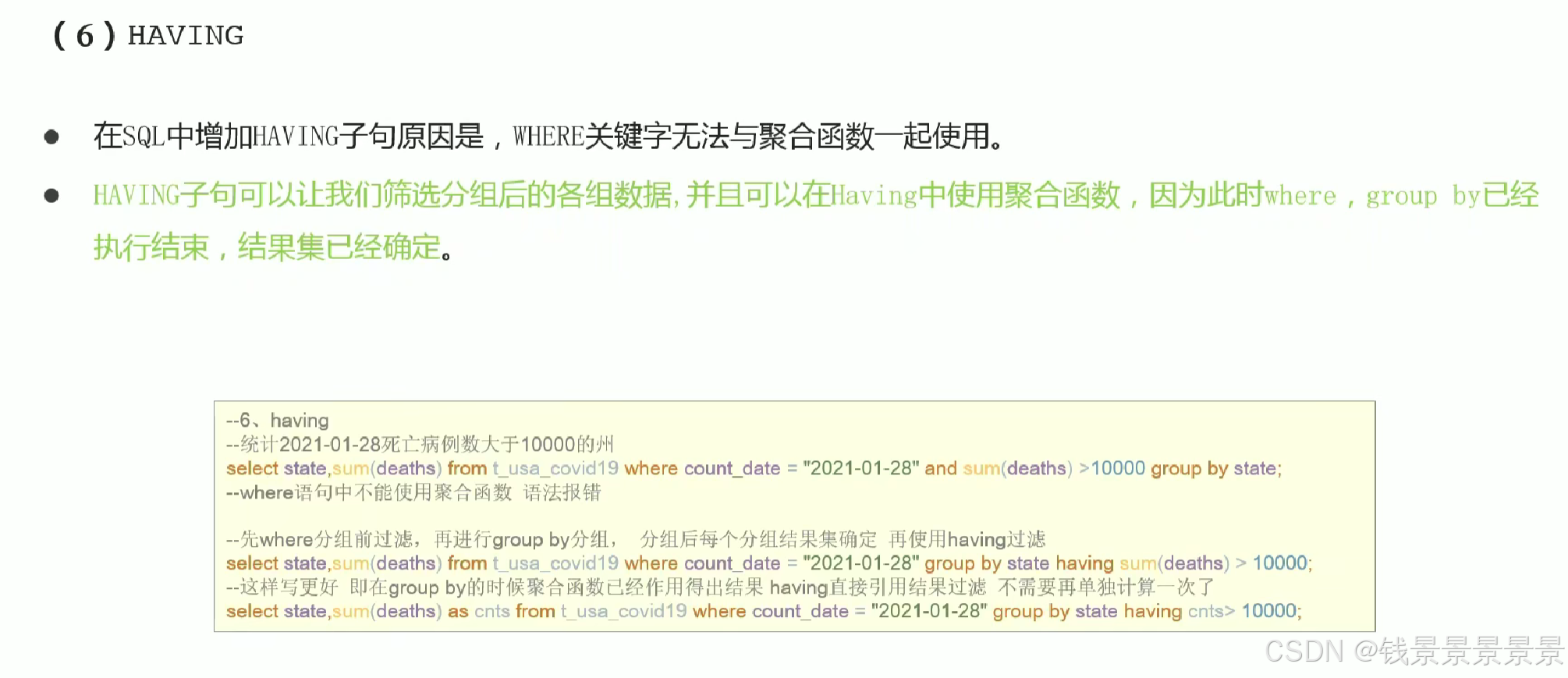
having主要为了解决where无法与聚合函数一起使用的弊端

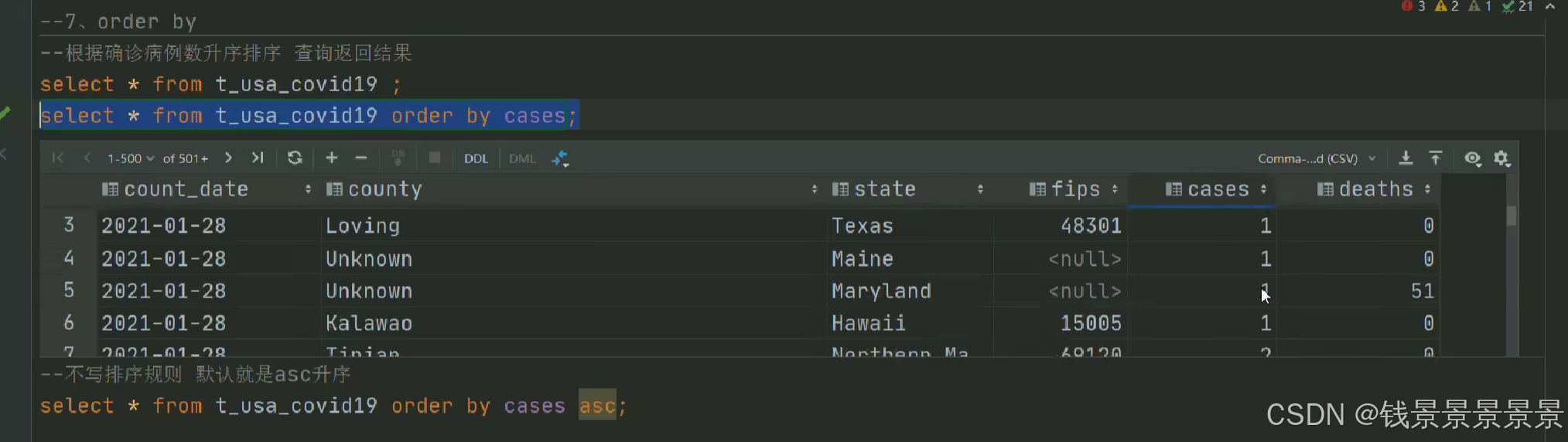
10.Hive SQL-DML-select查询-order by排序

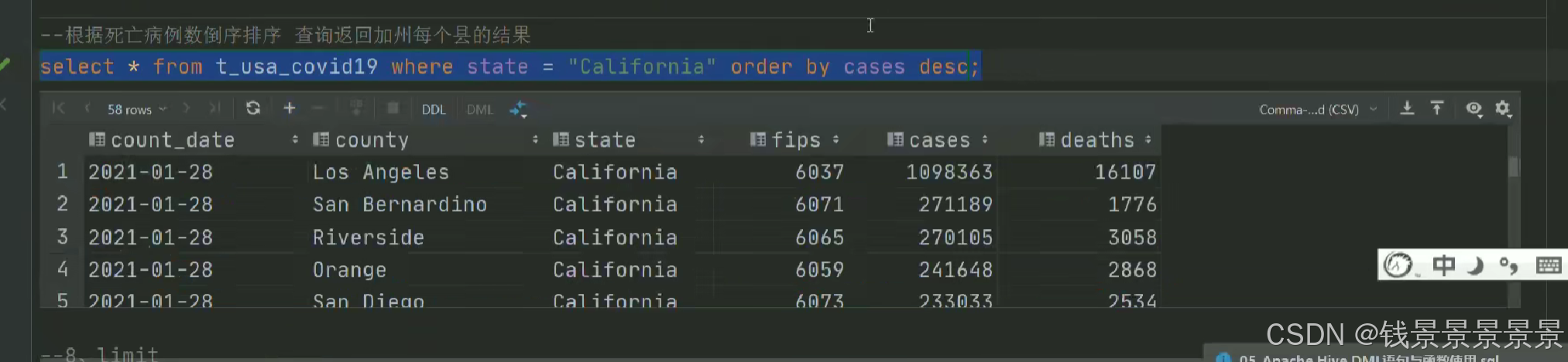
11.Hive SQL-DML-select查询-limit限制语法

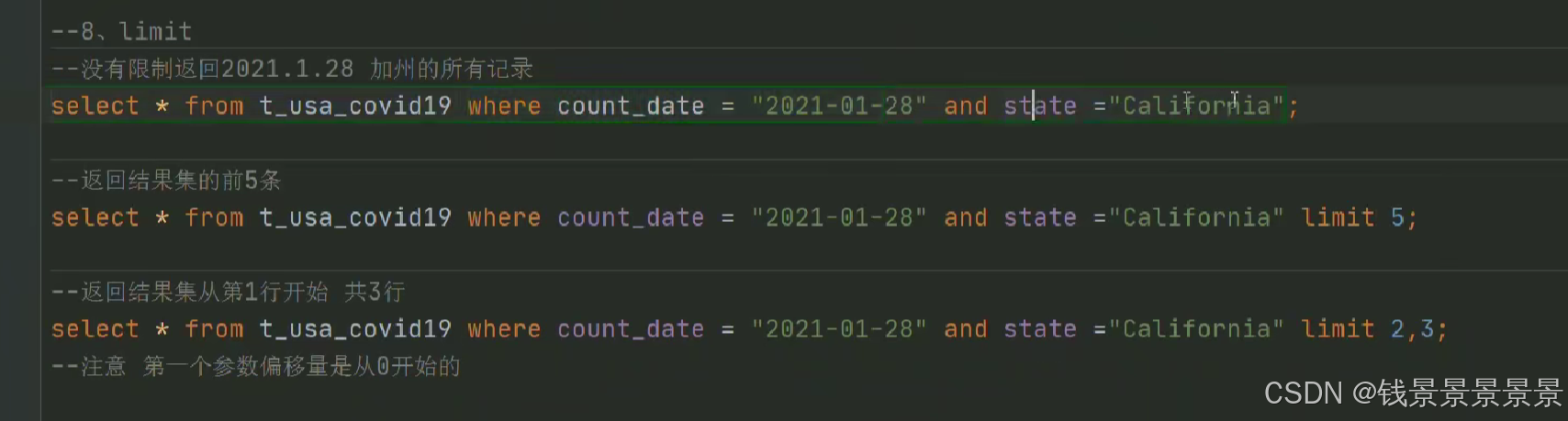
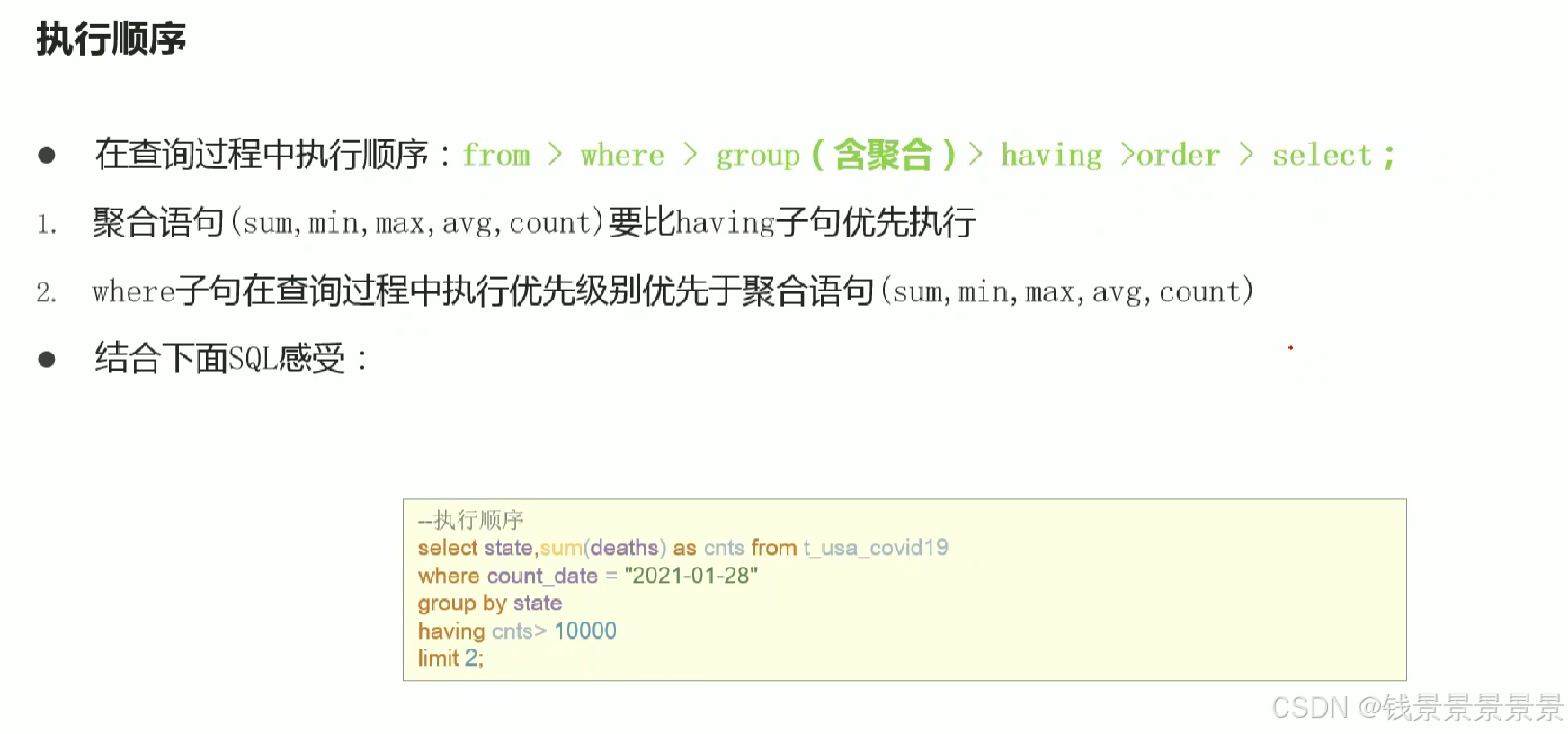
12.Hive SQL-DML-select查询-梳理执行顺序
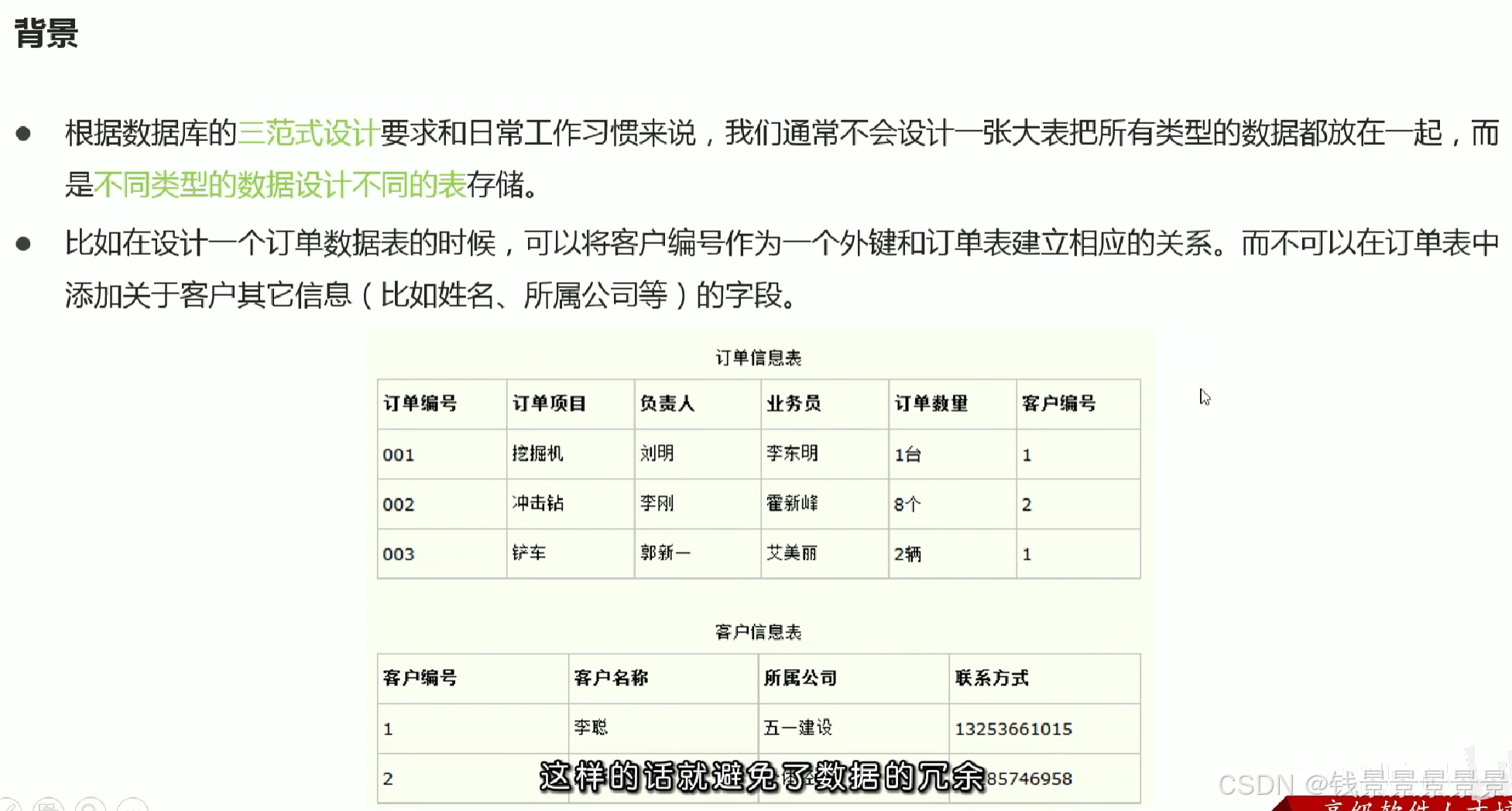
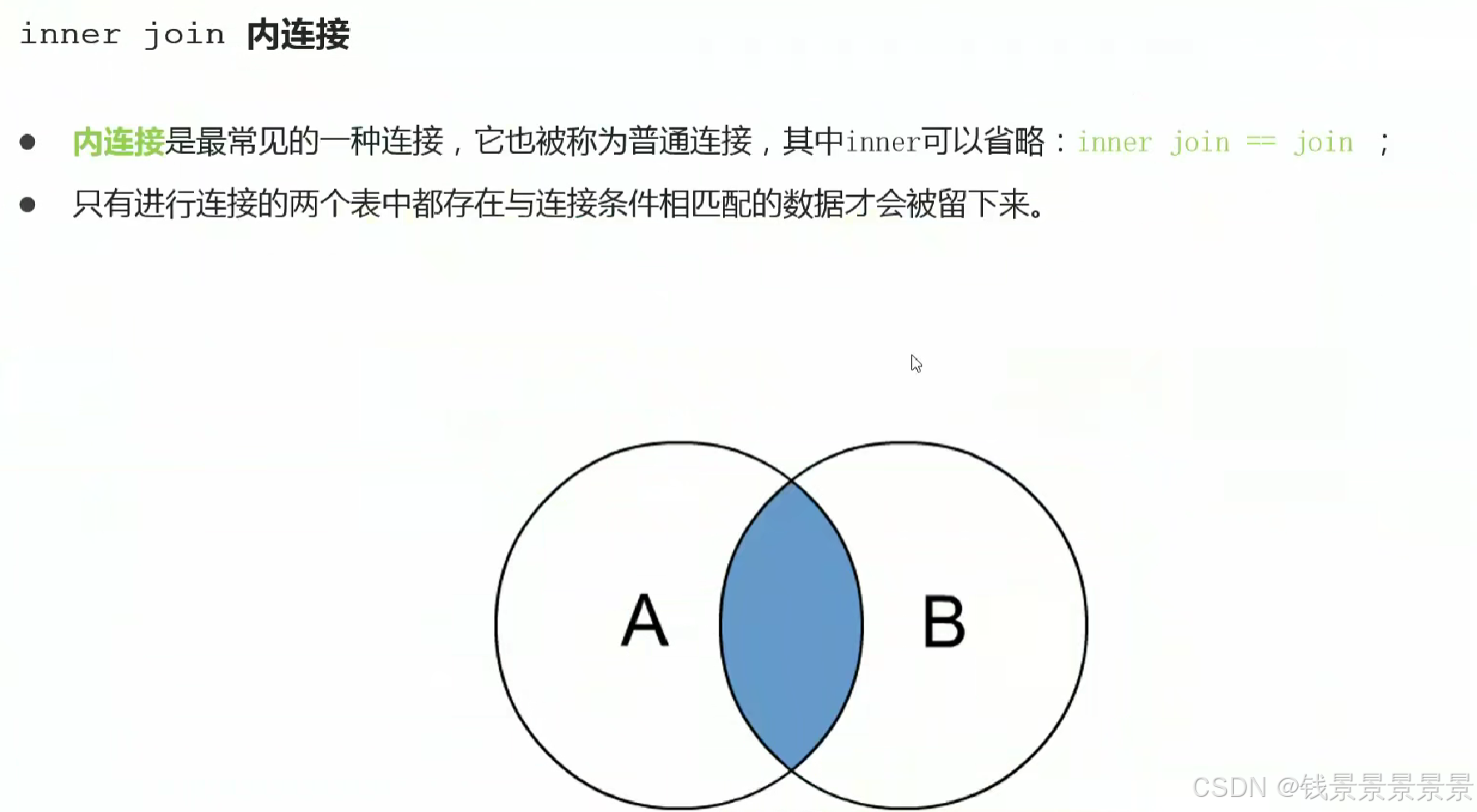
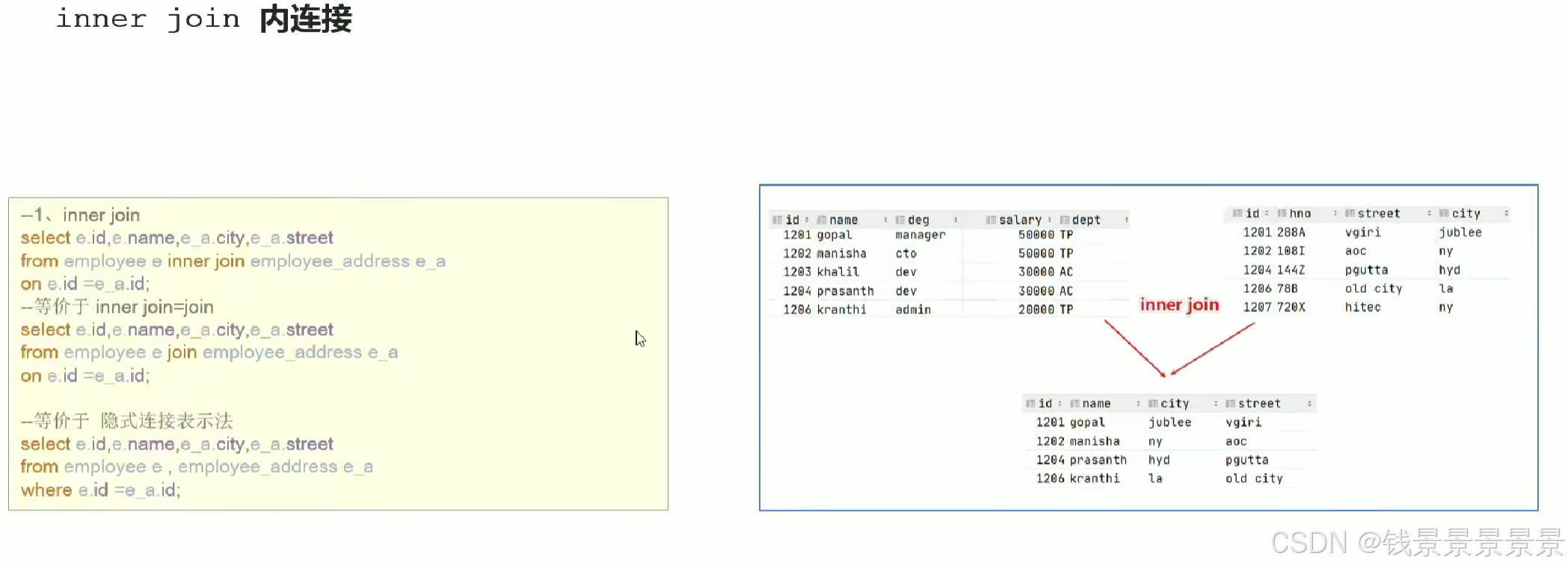
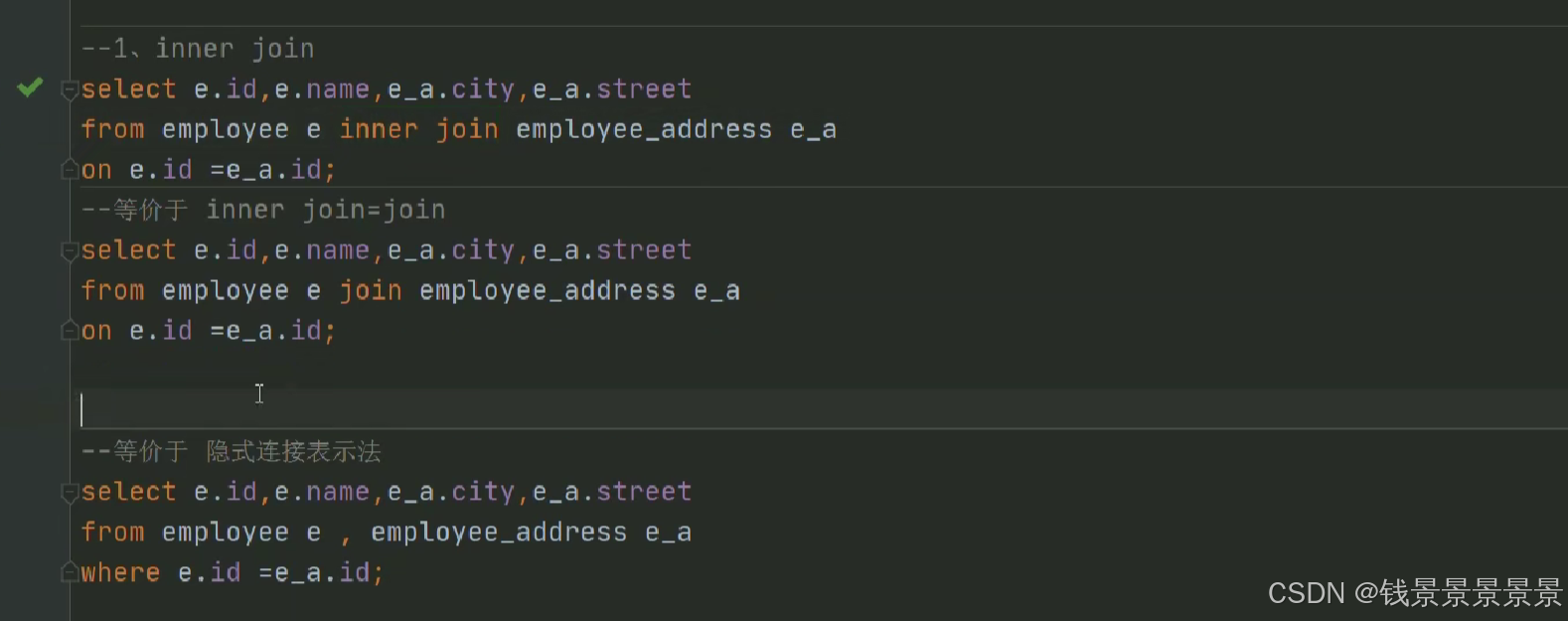
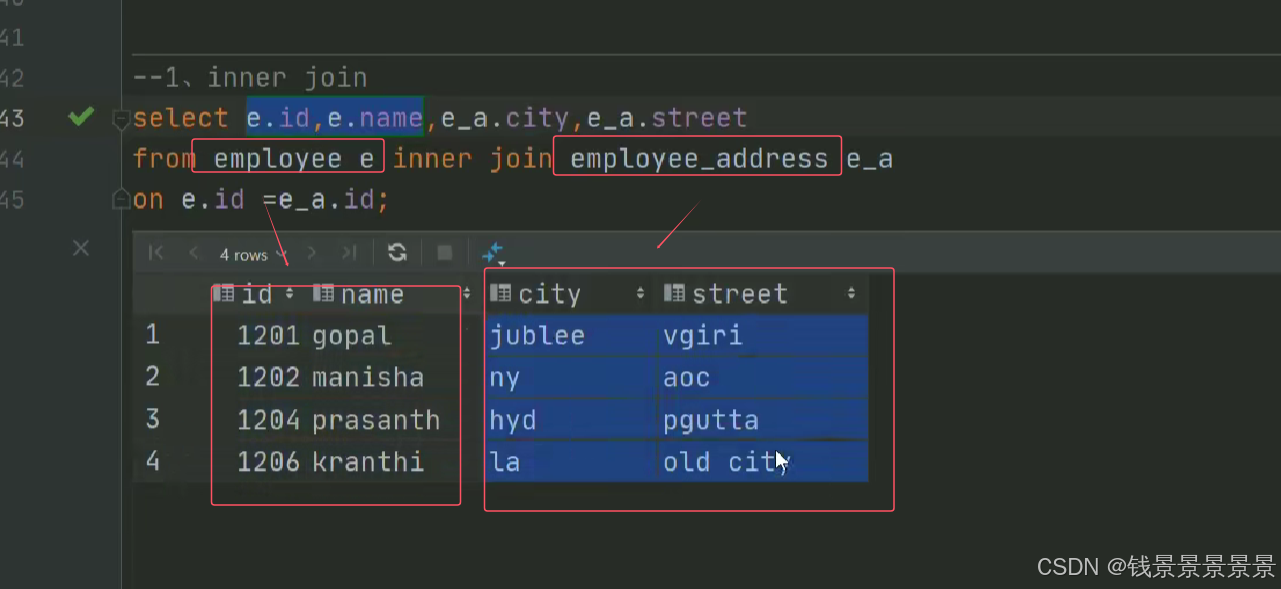
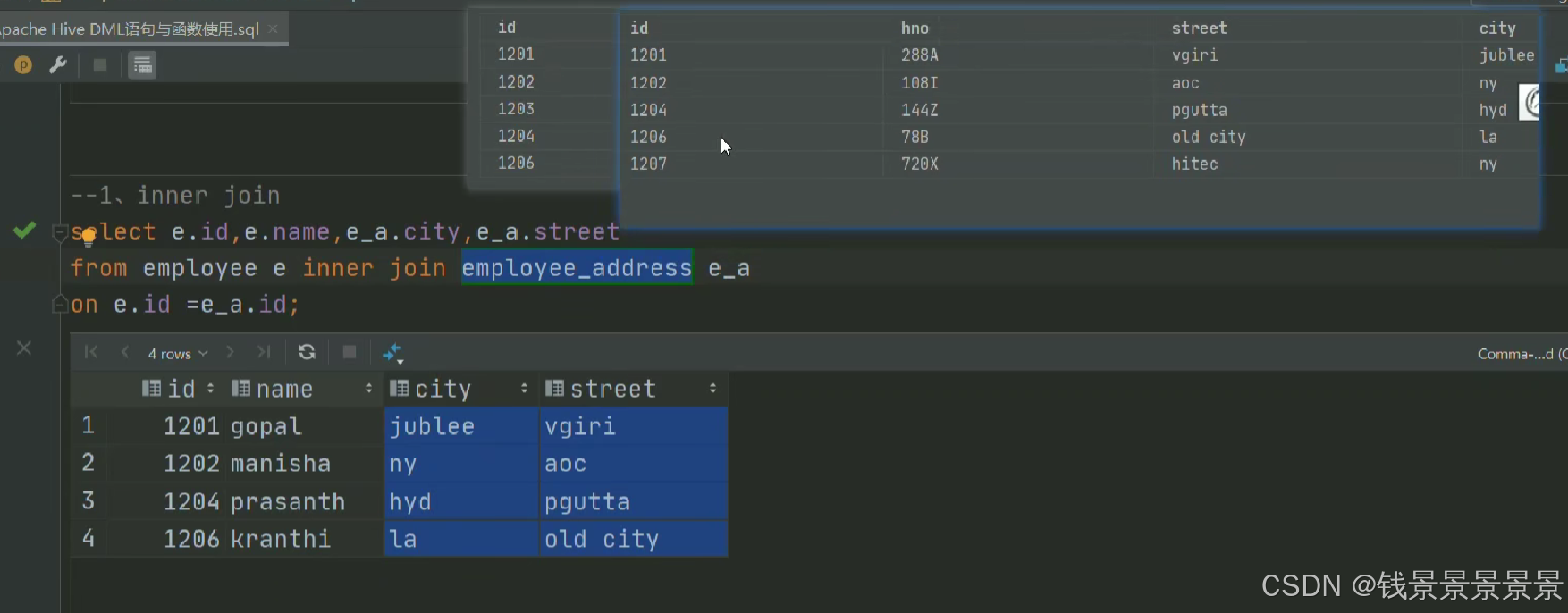
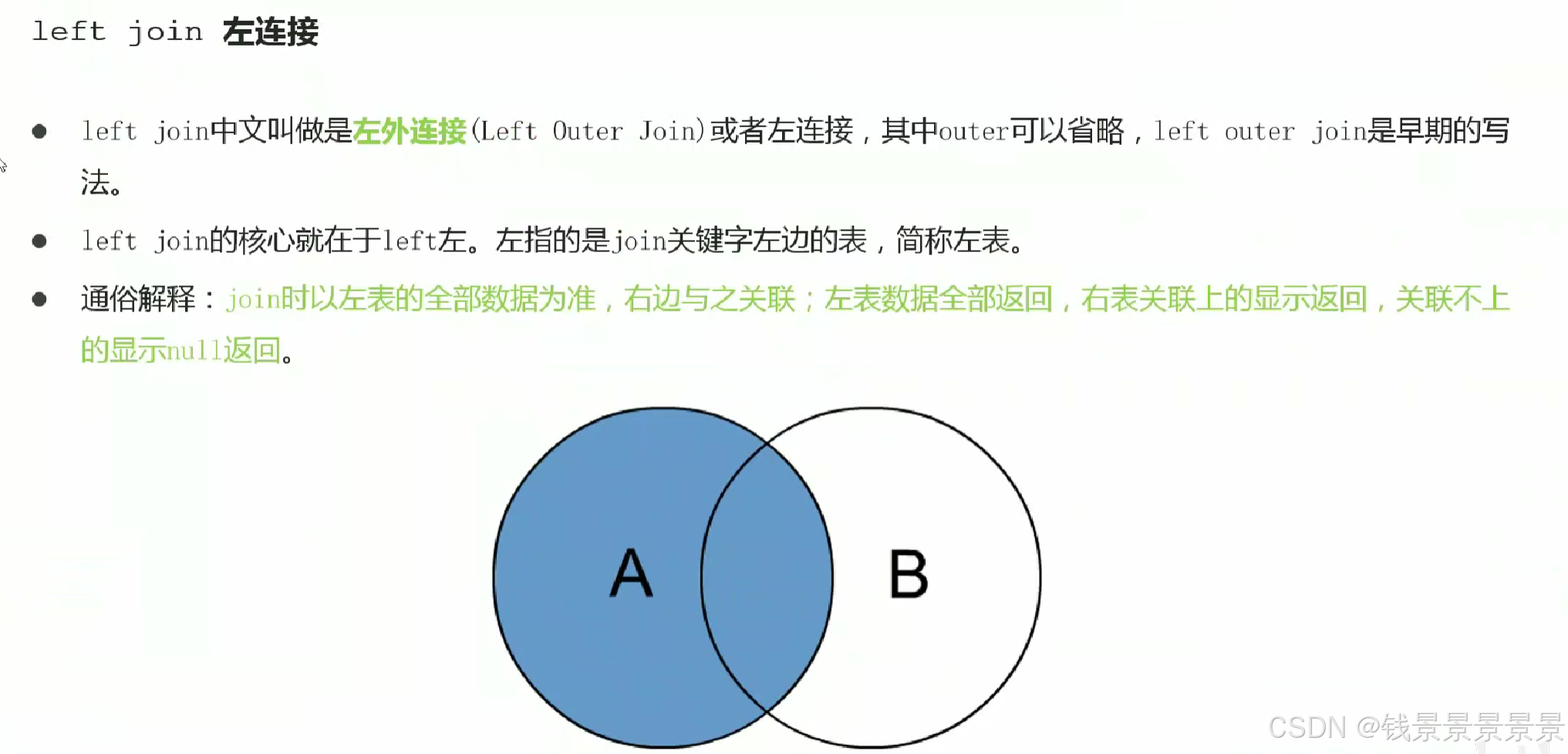
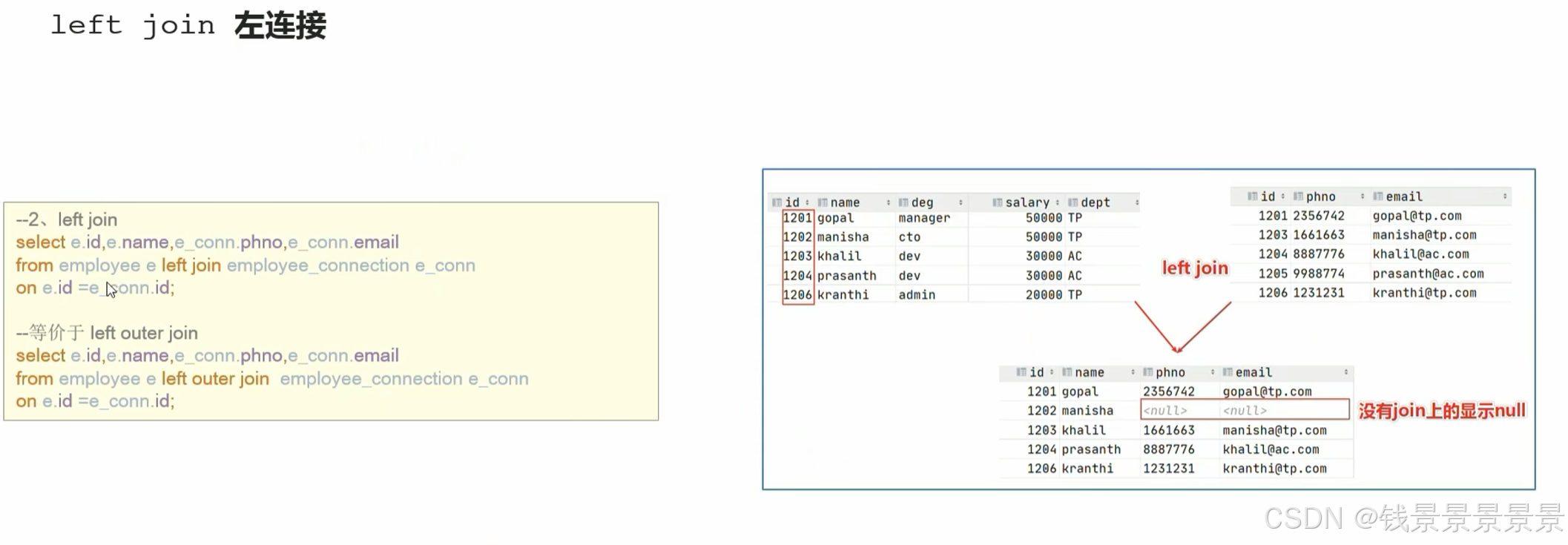
13.Hive SQL join关联查询




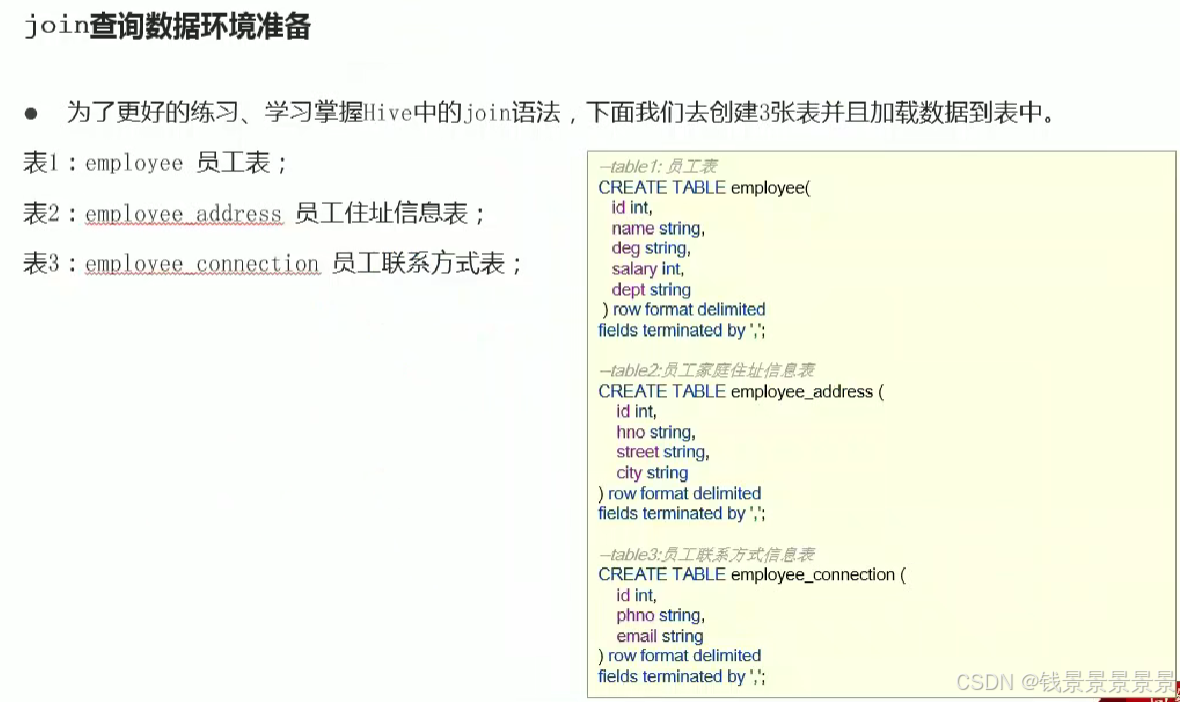
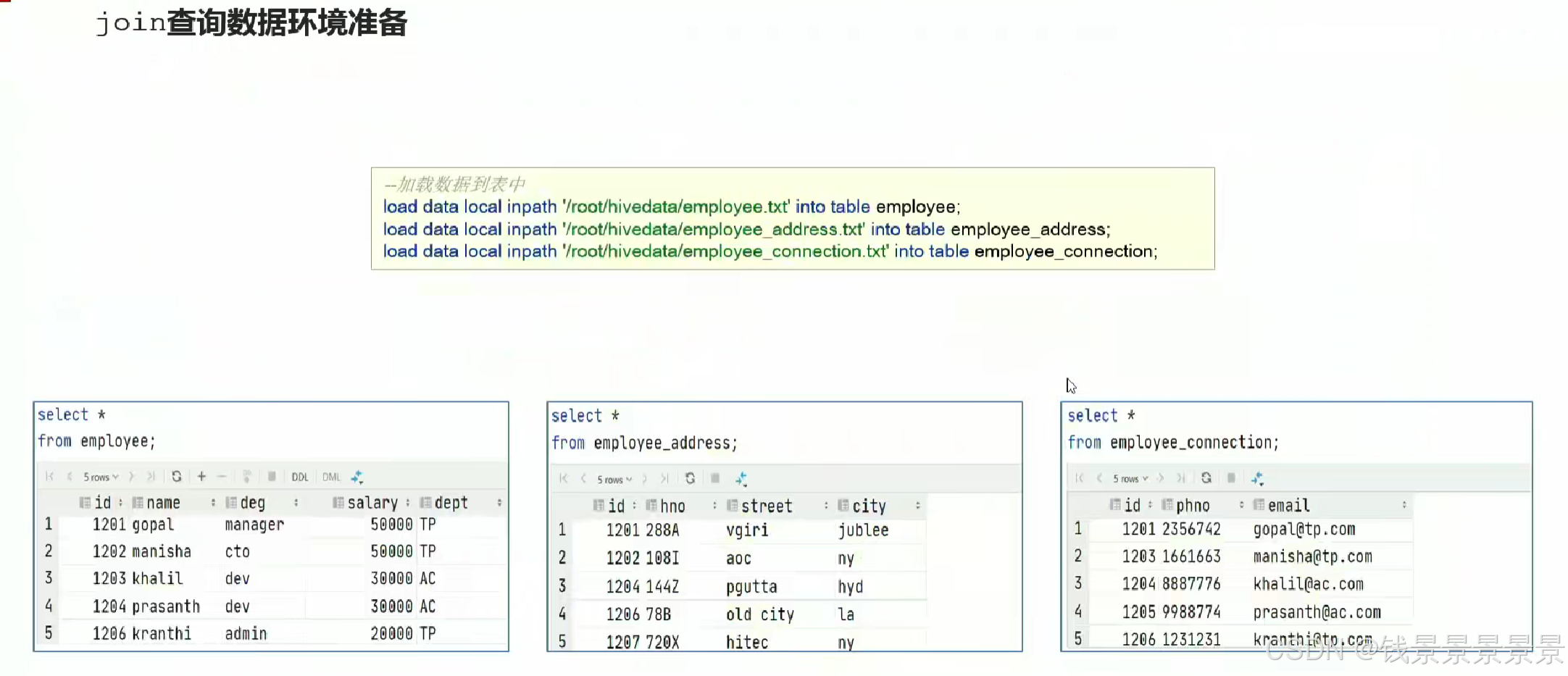
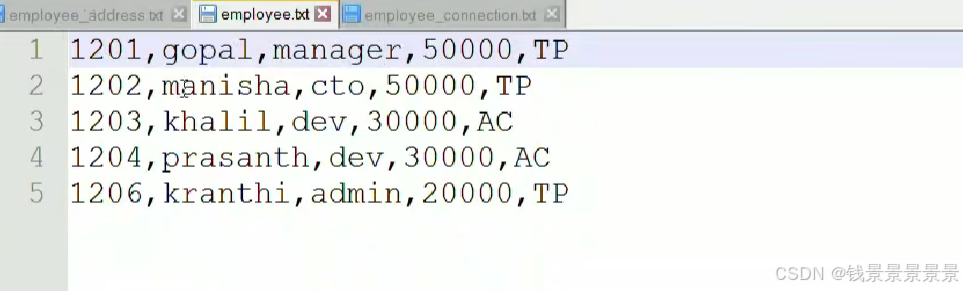
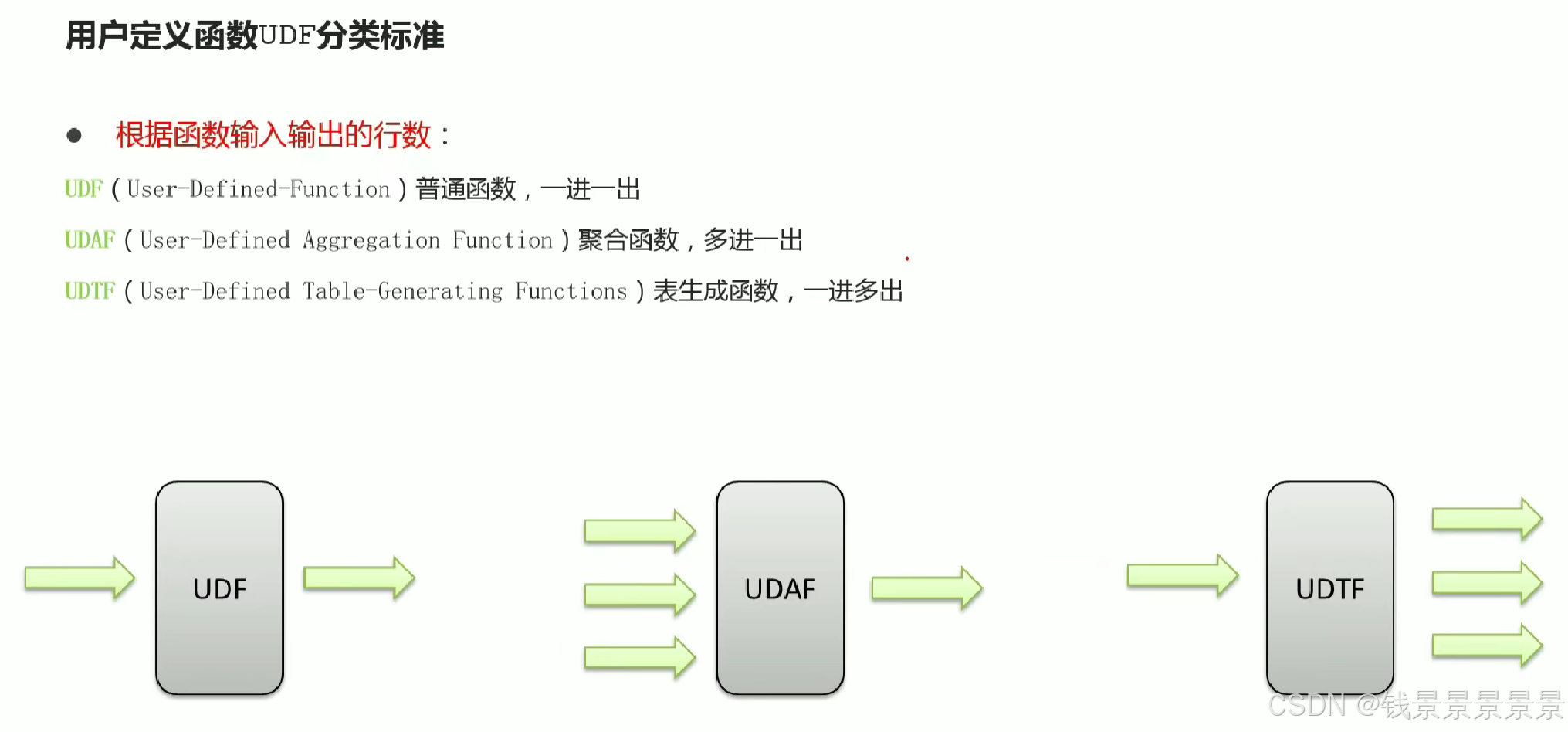
14.hive函数概述及分类标准

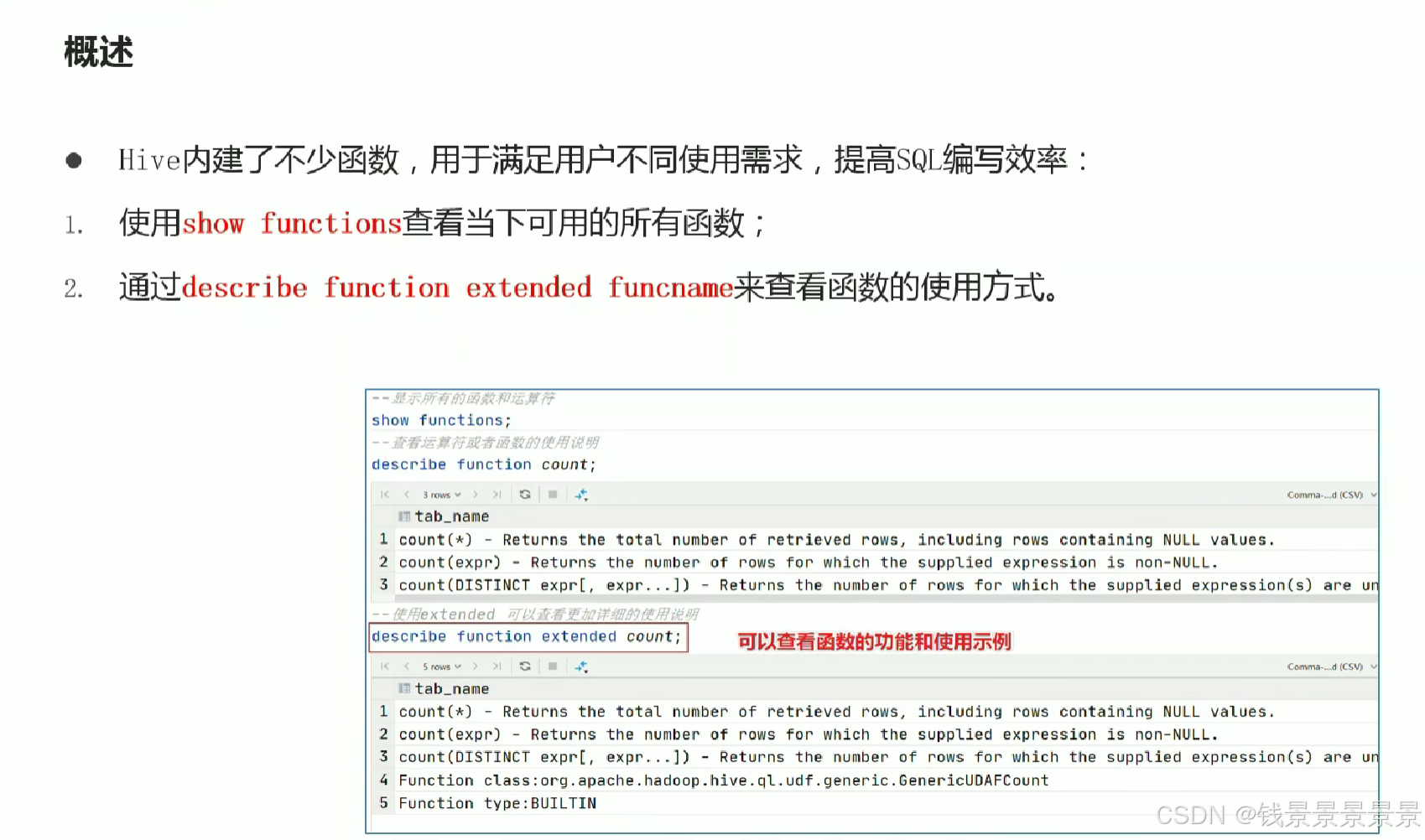
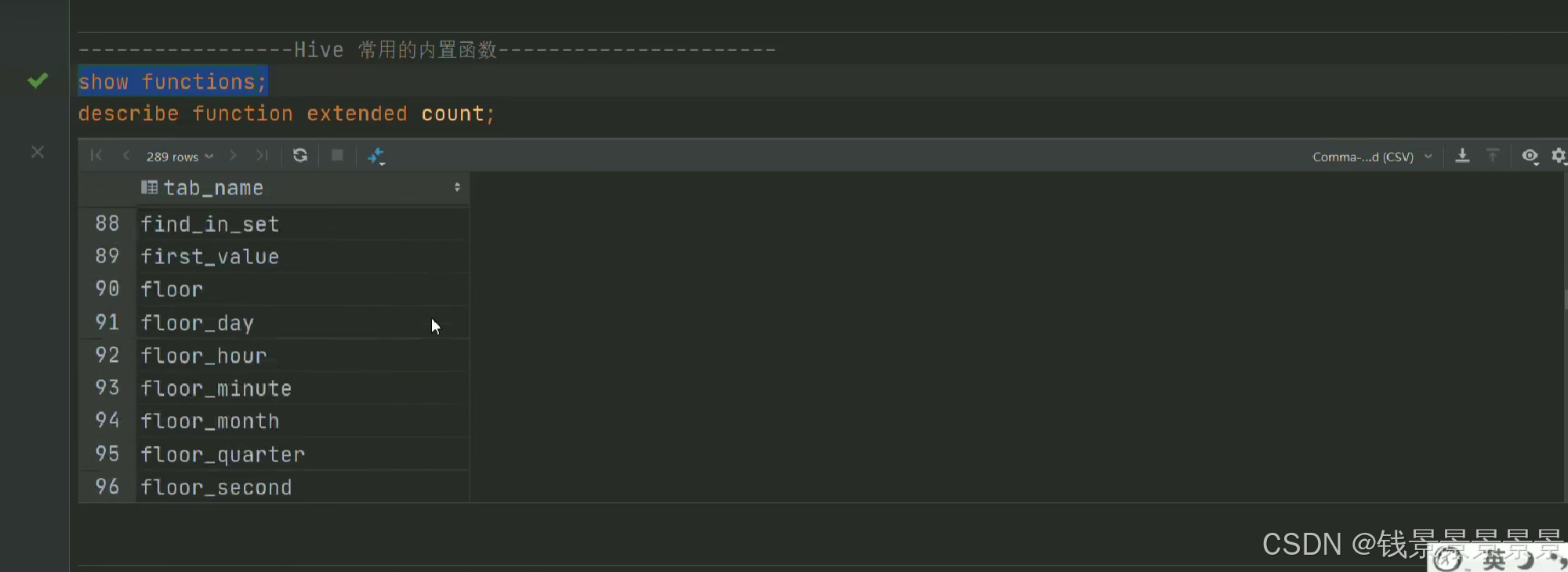
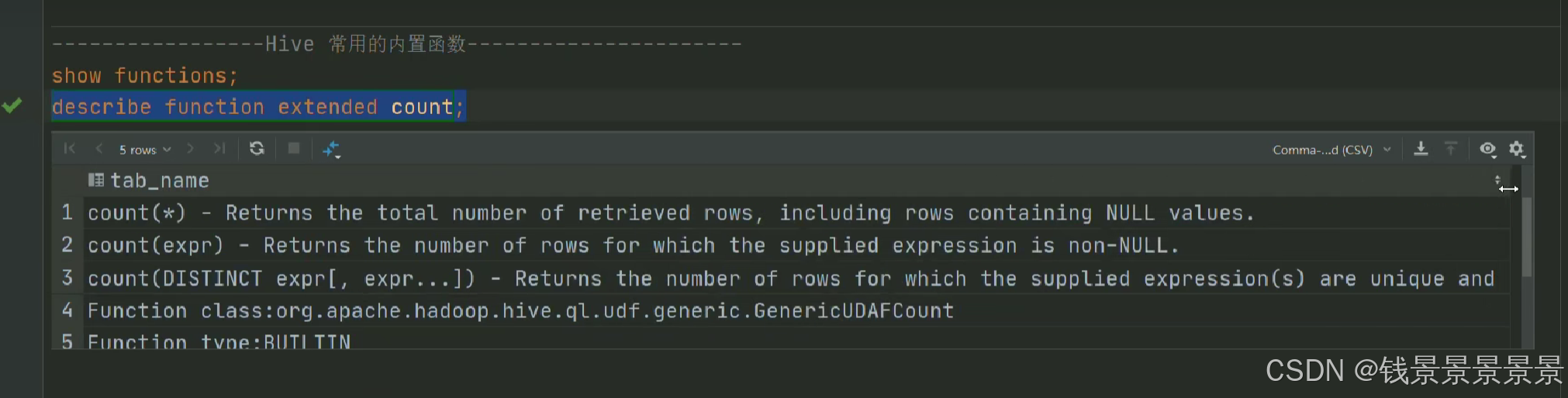


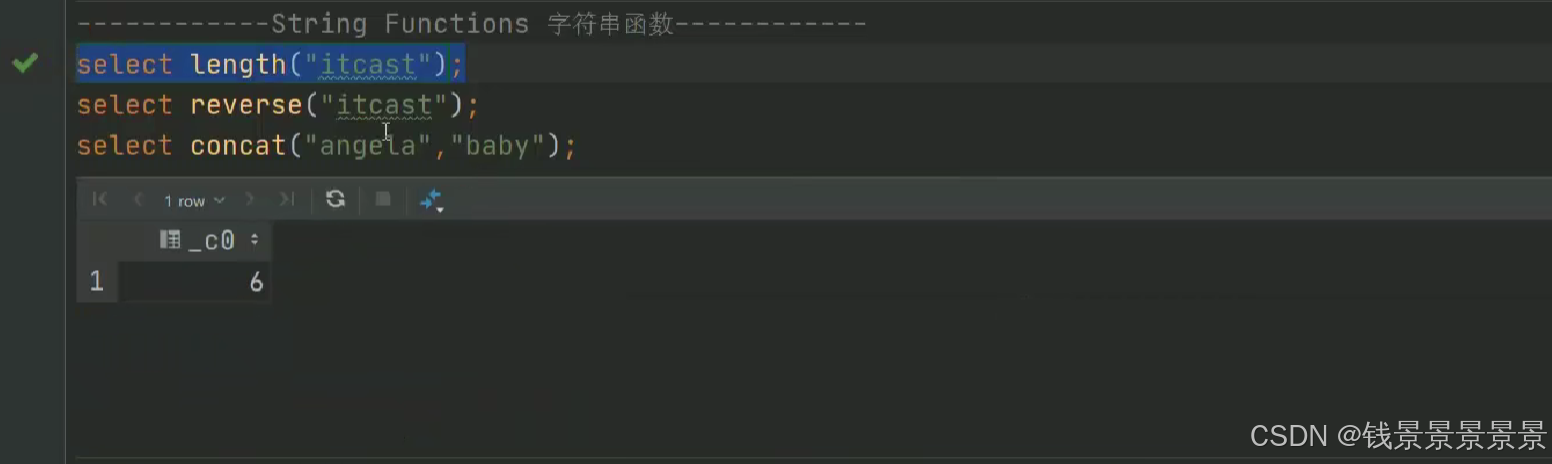
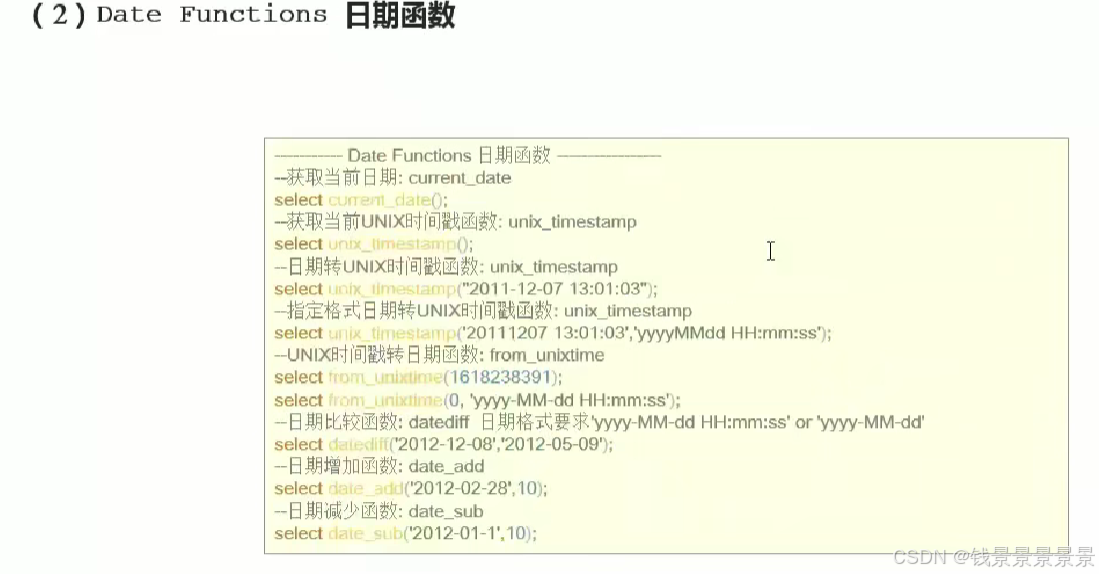
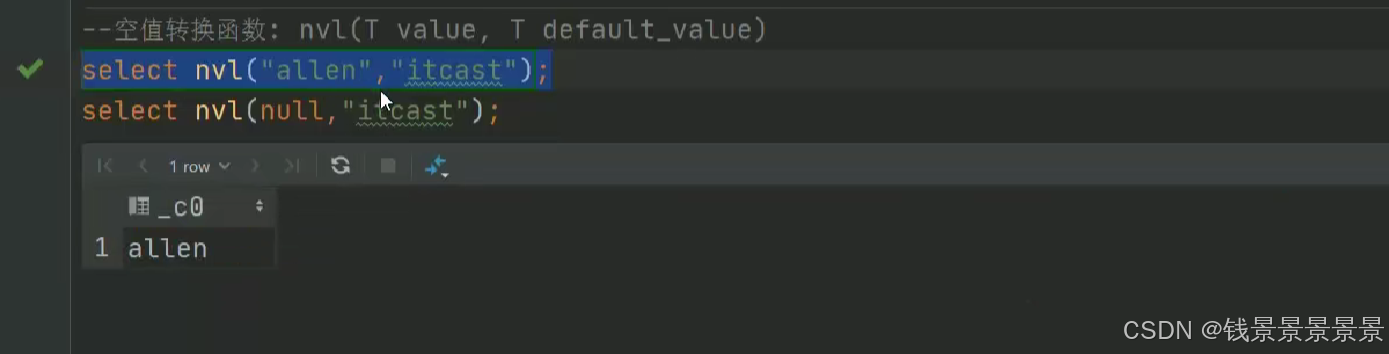
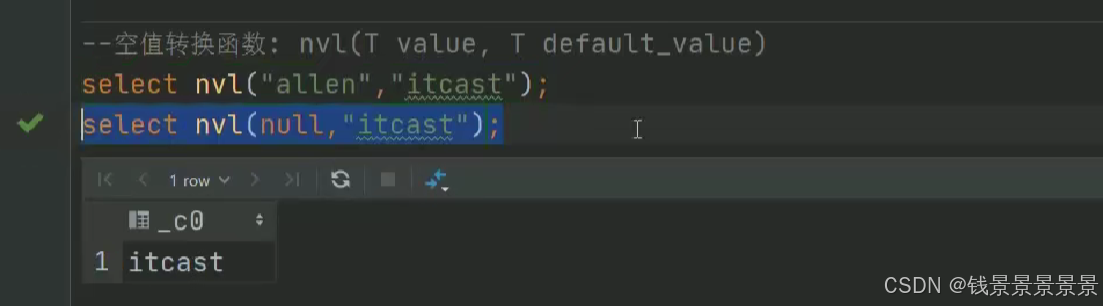
15.hive常用的内置函数



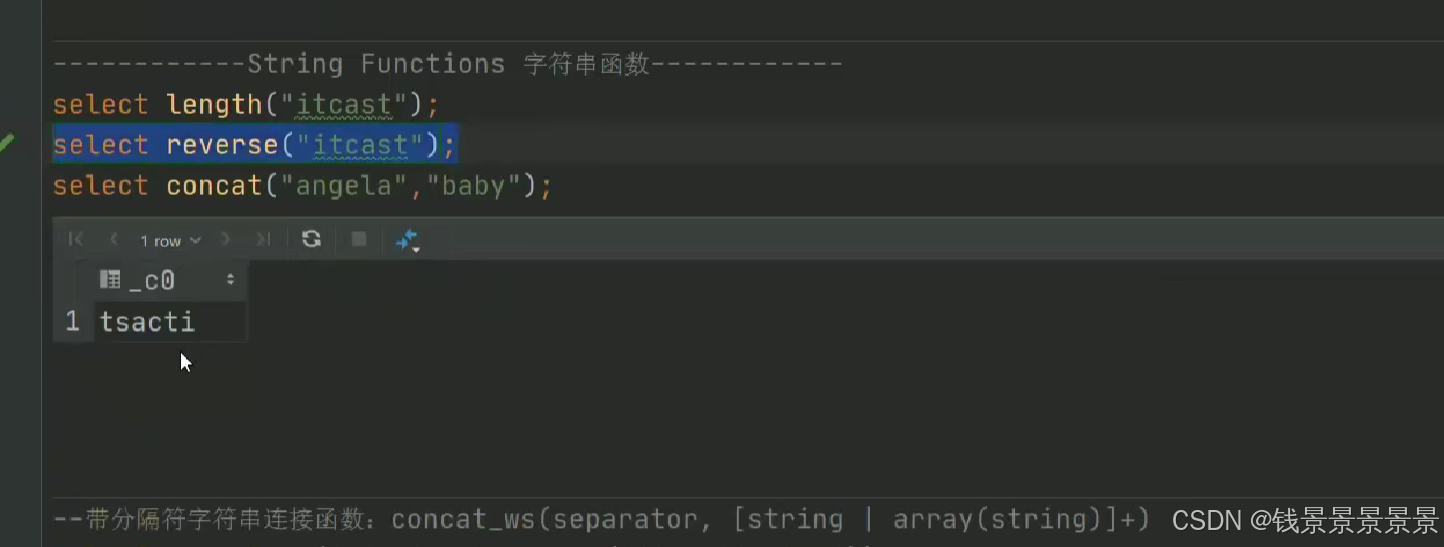
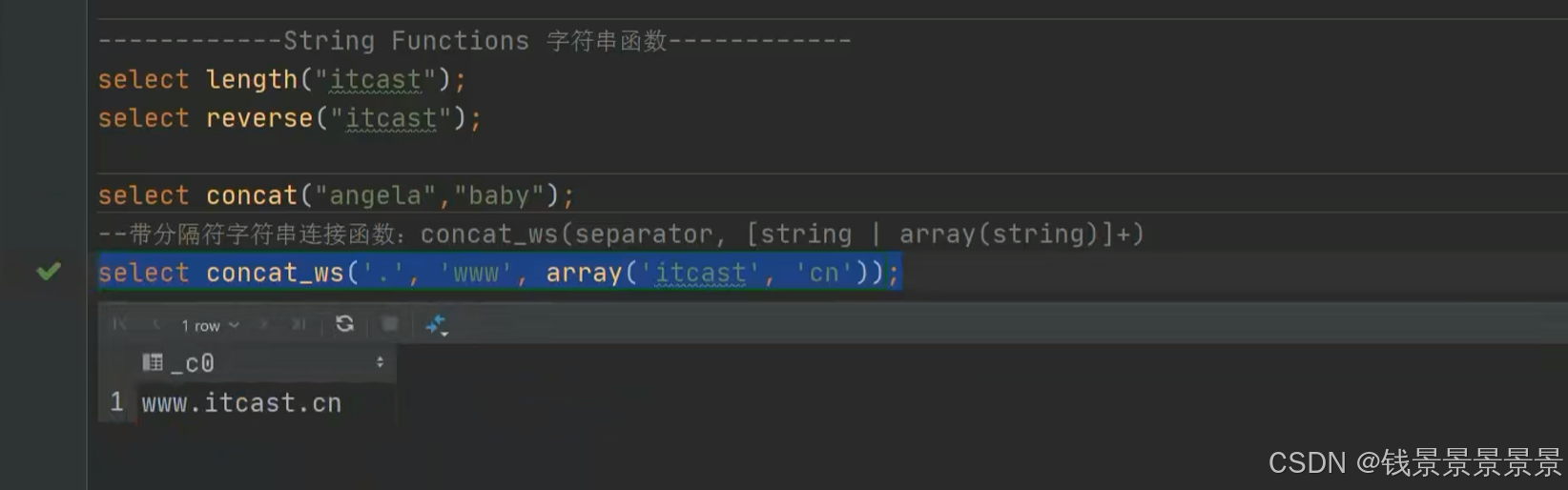
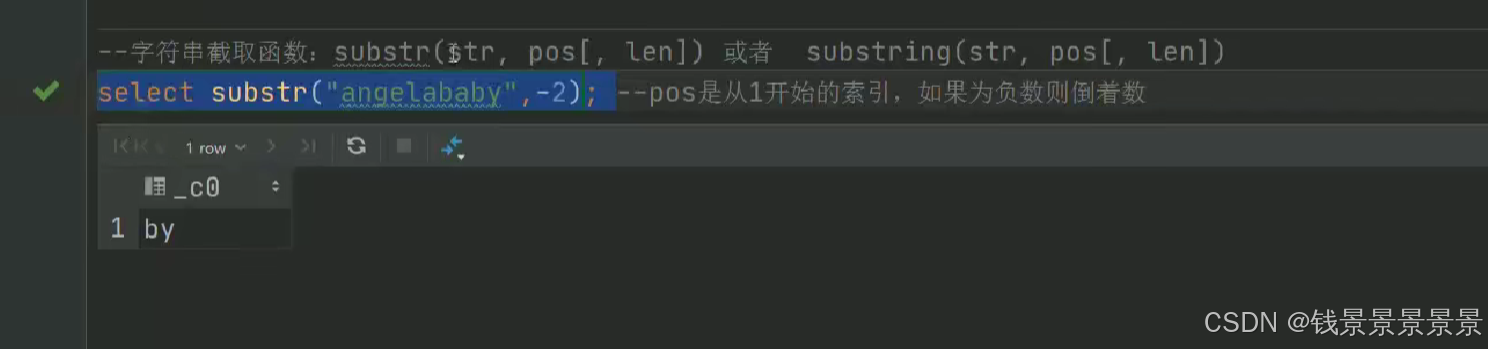
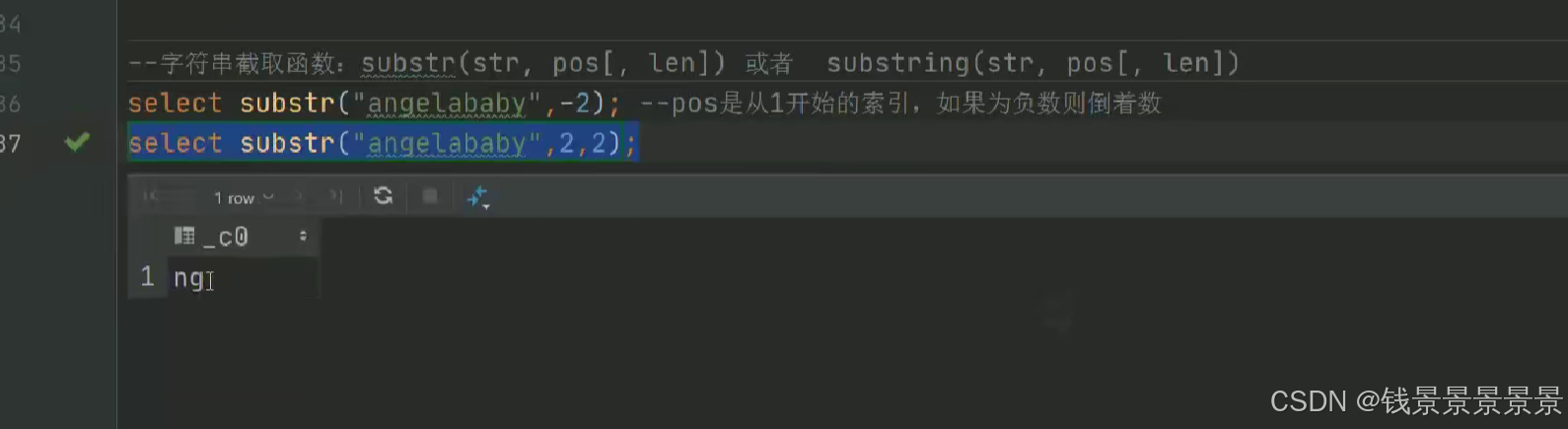
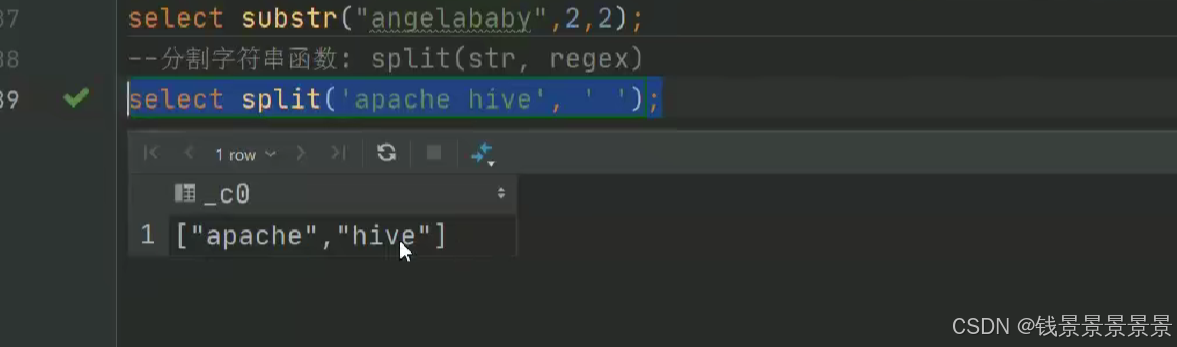
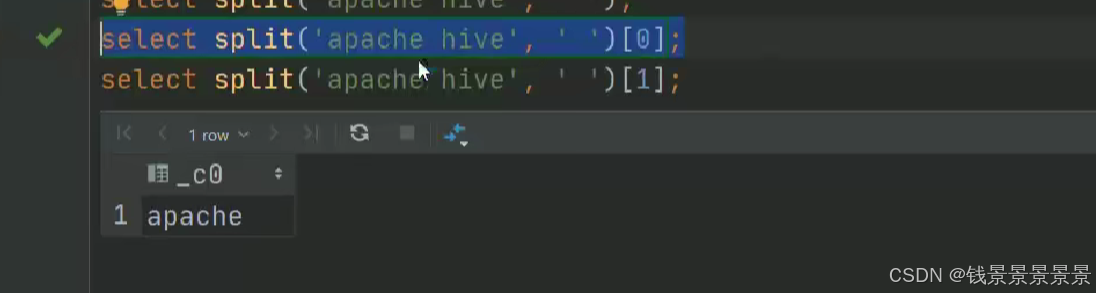
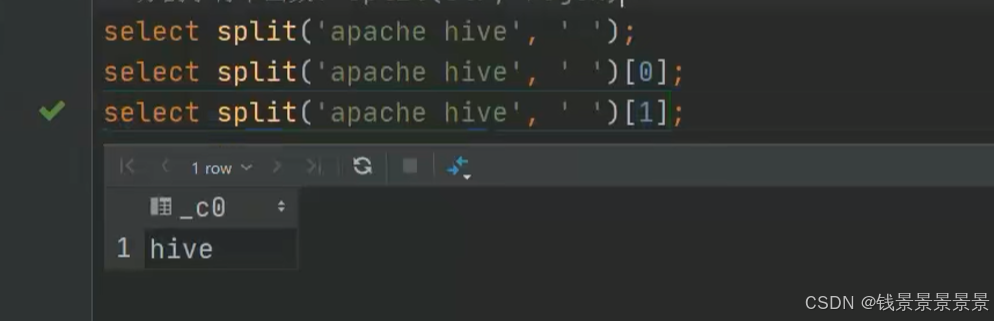

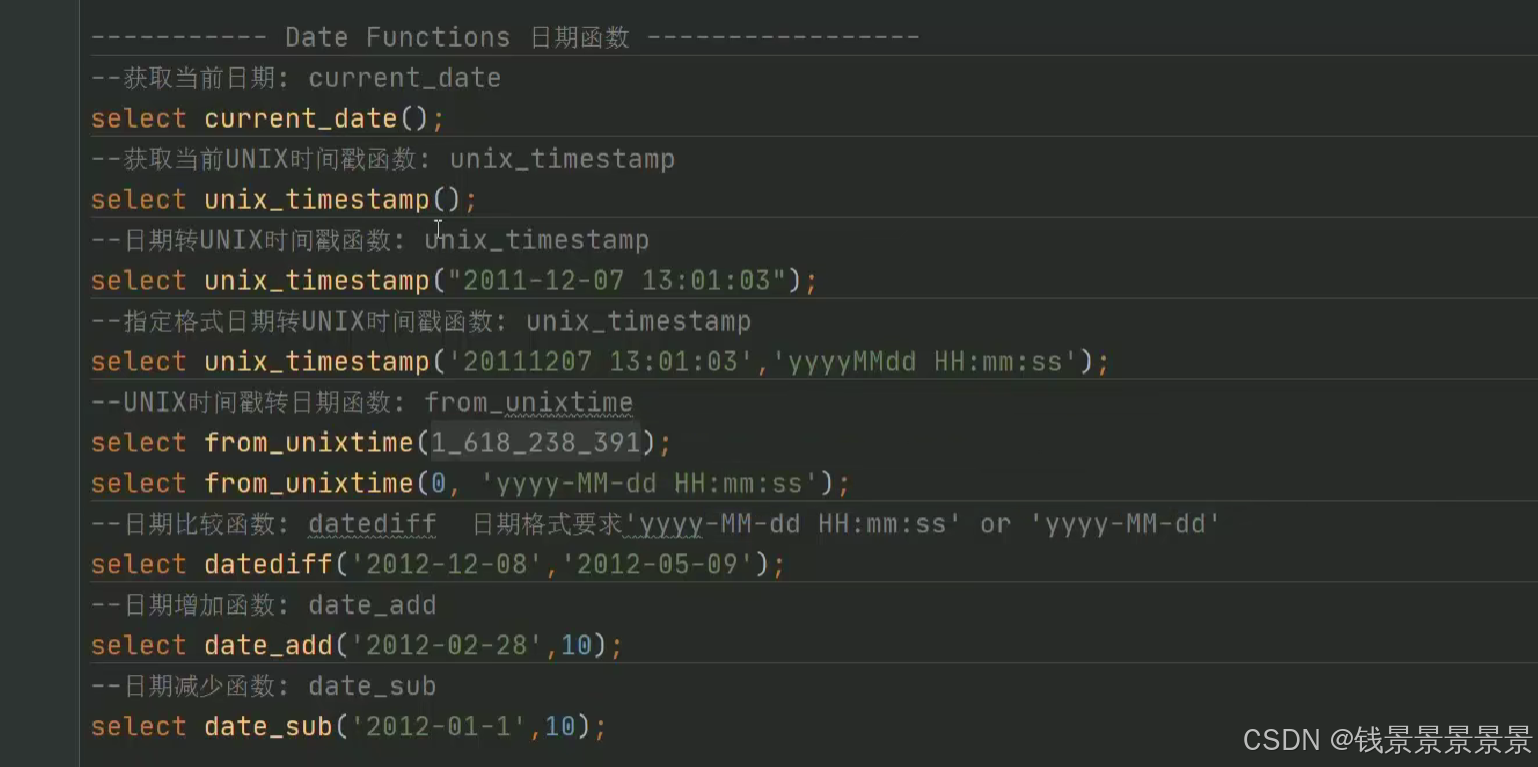
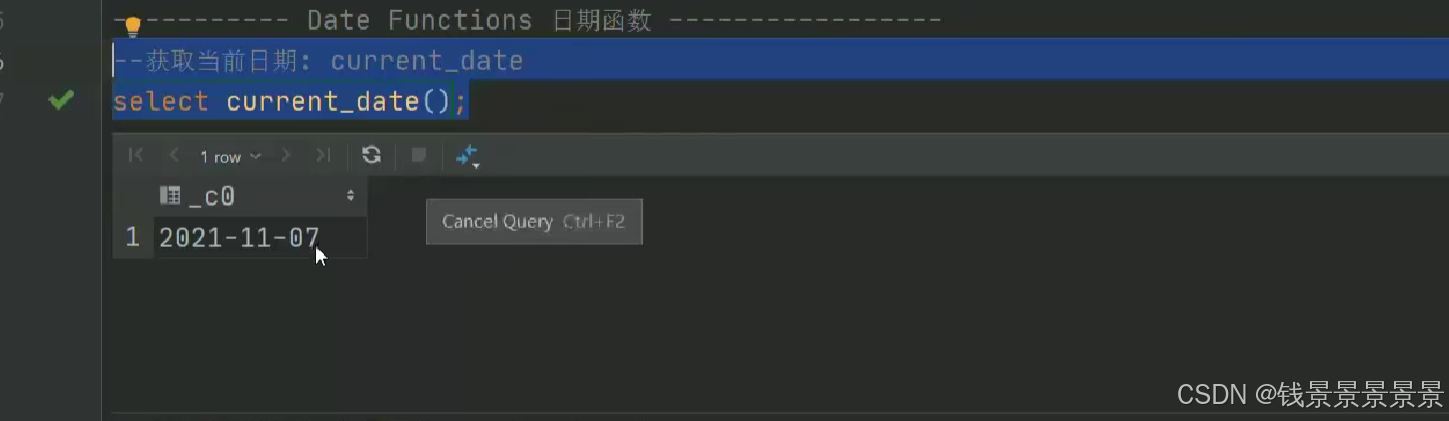
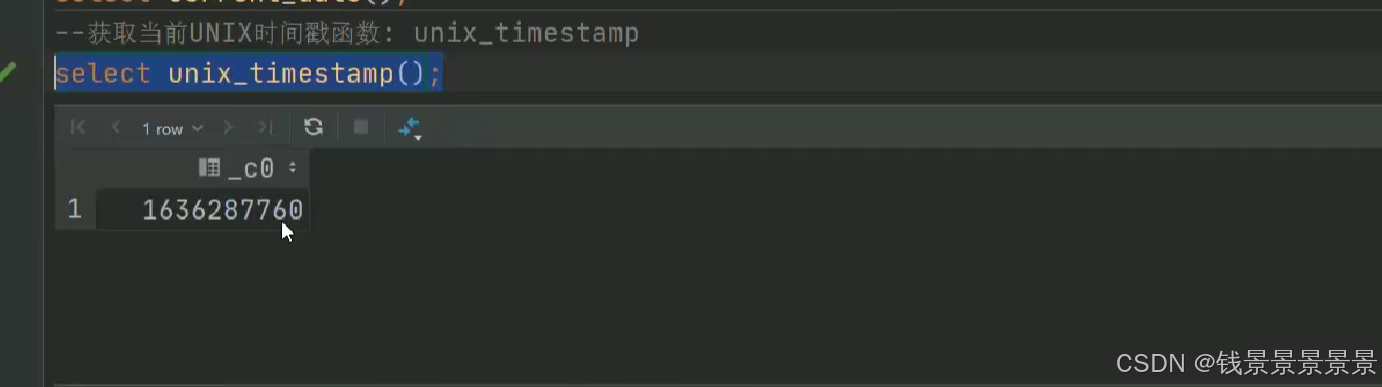
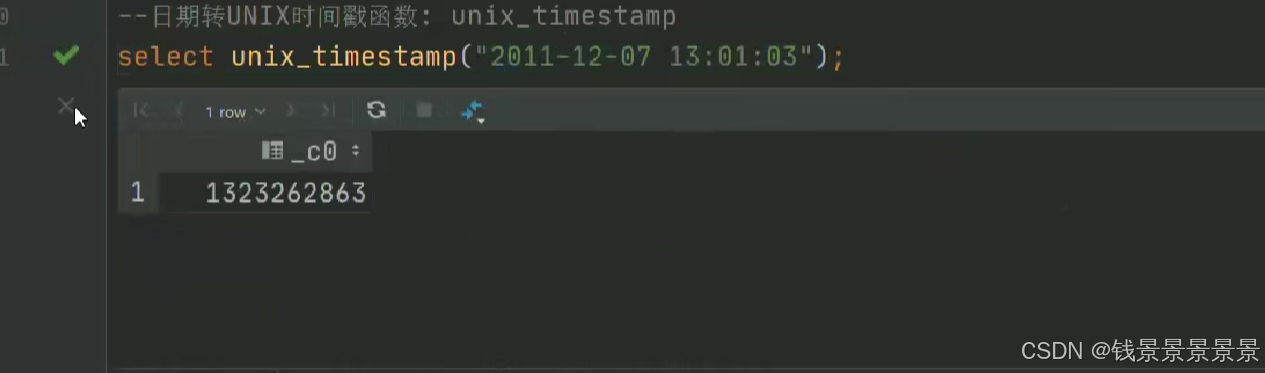
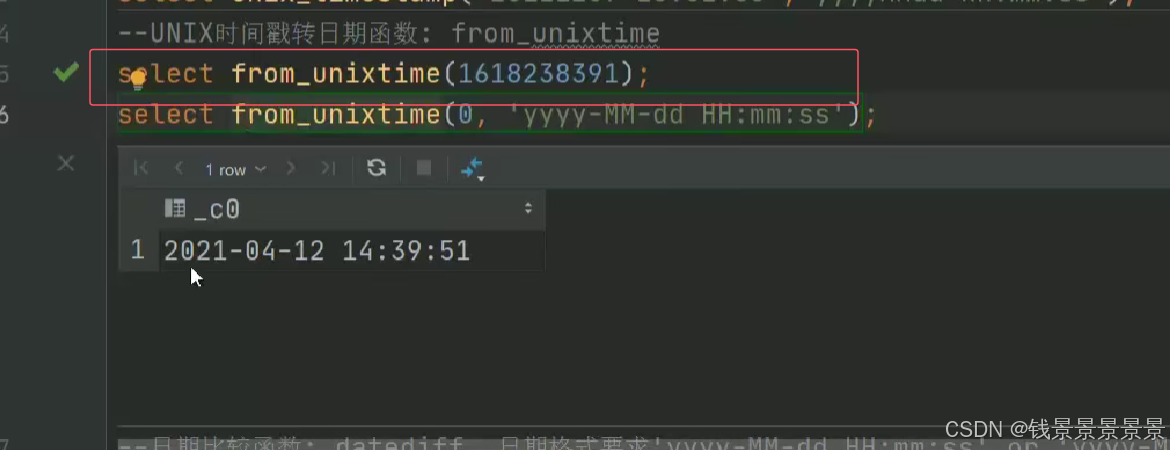
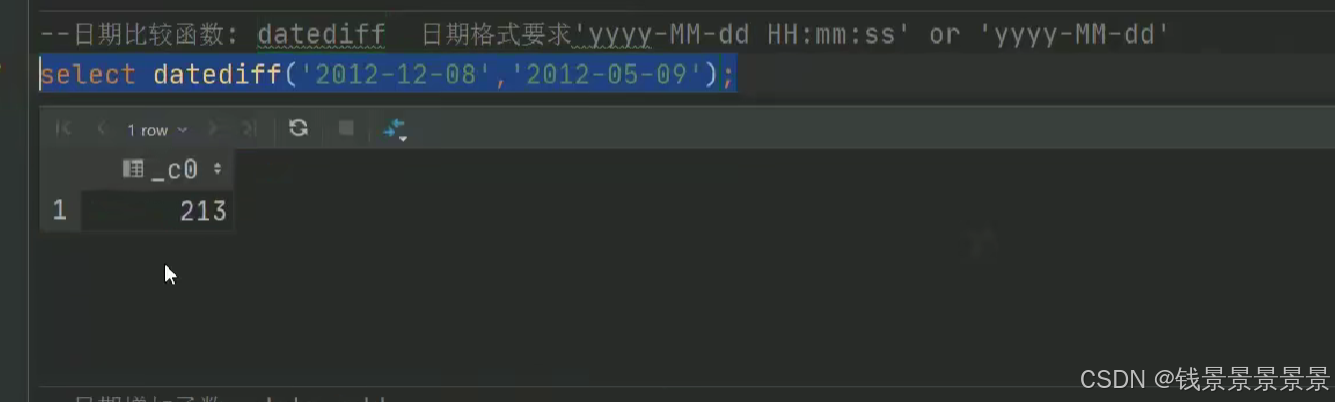
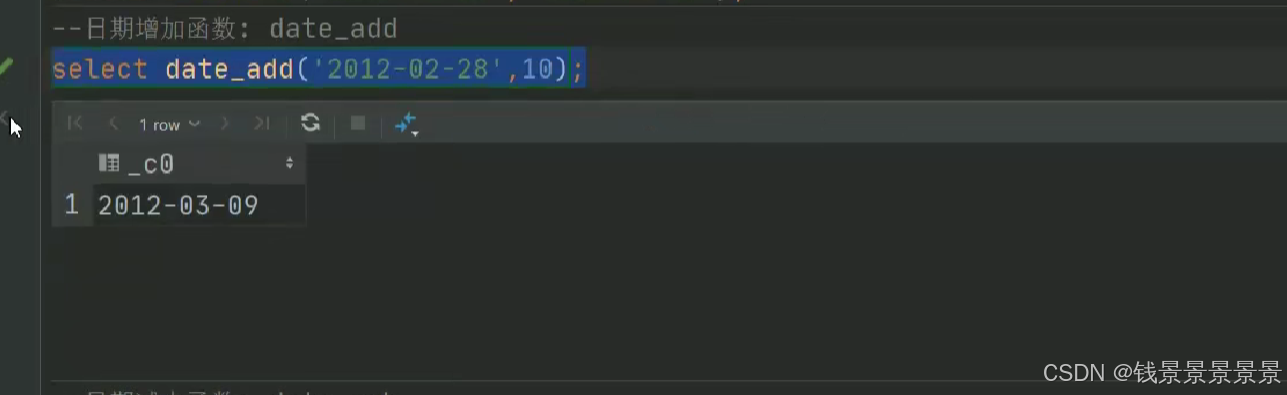
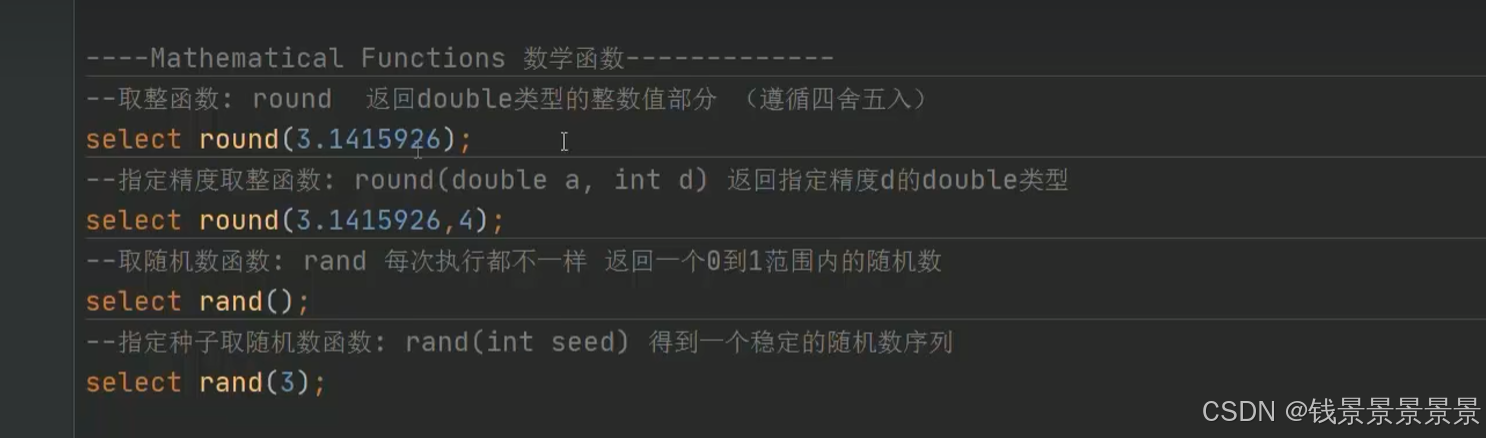
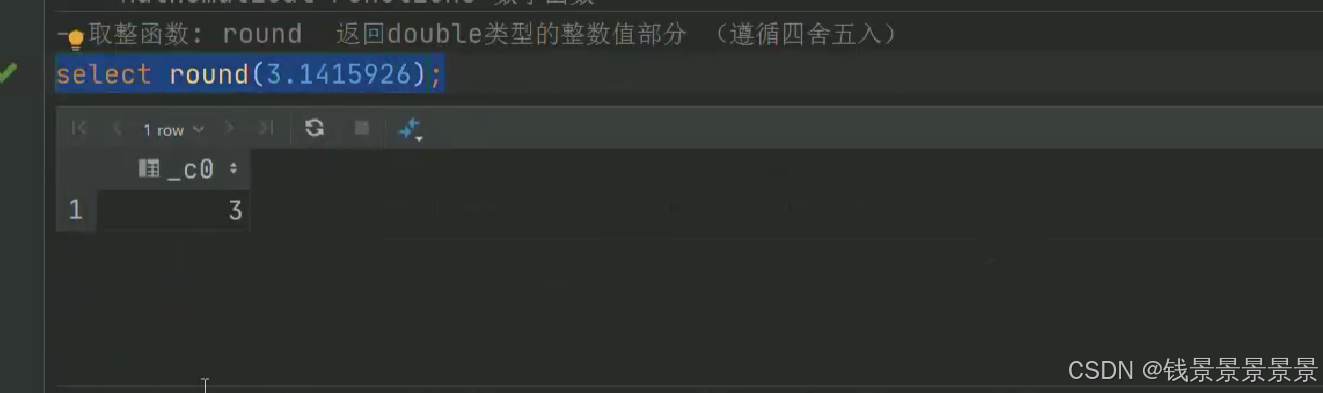
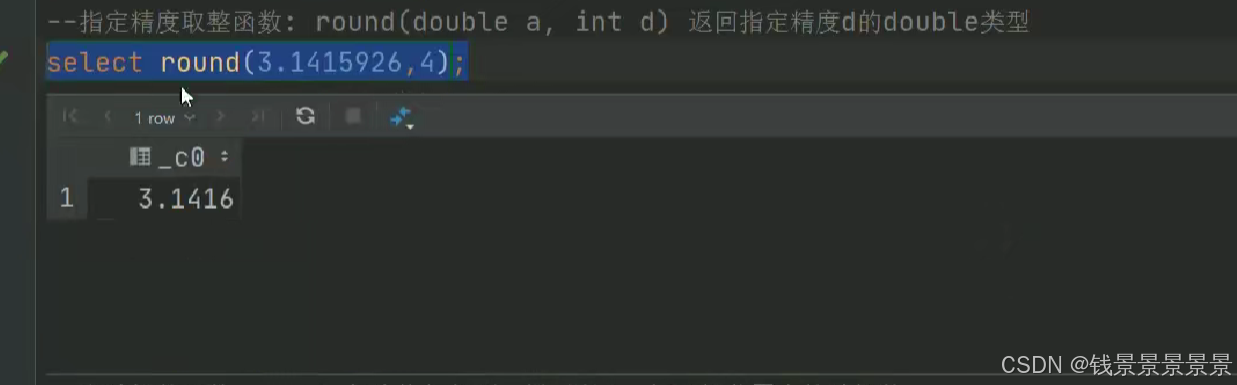
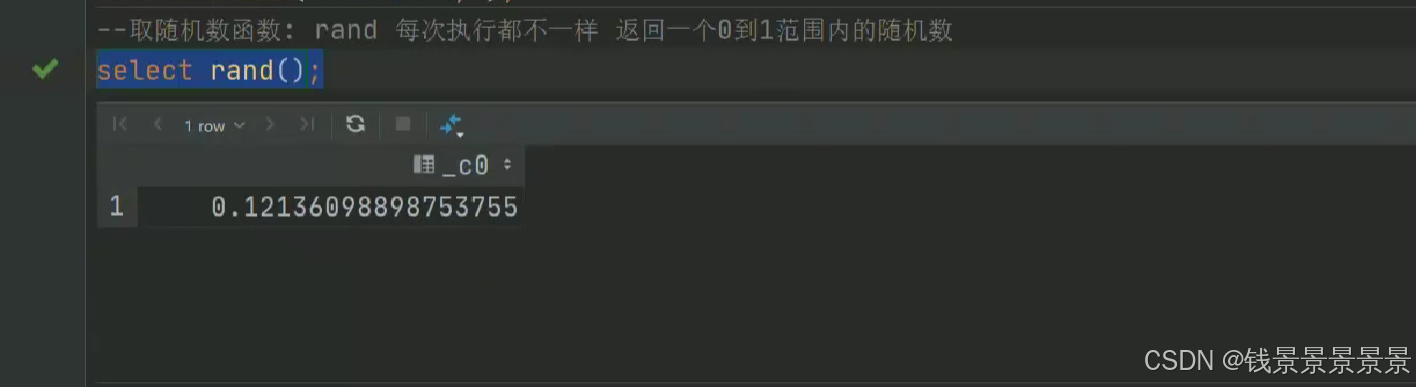
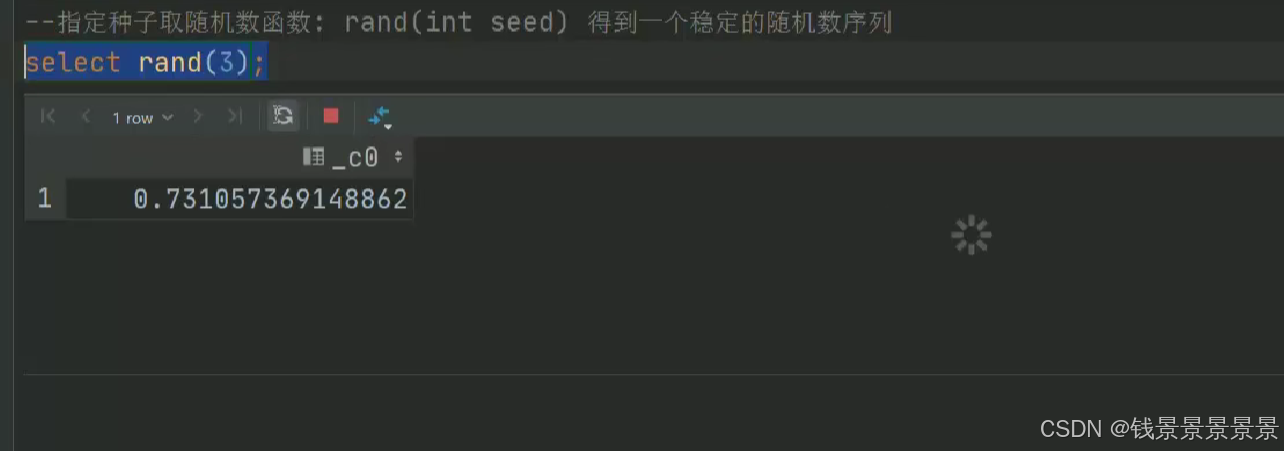
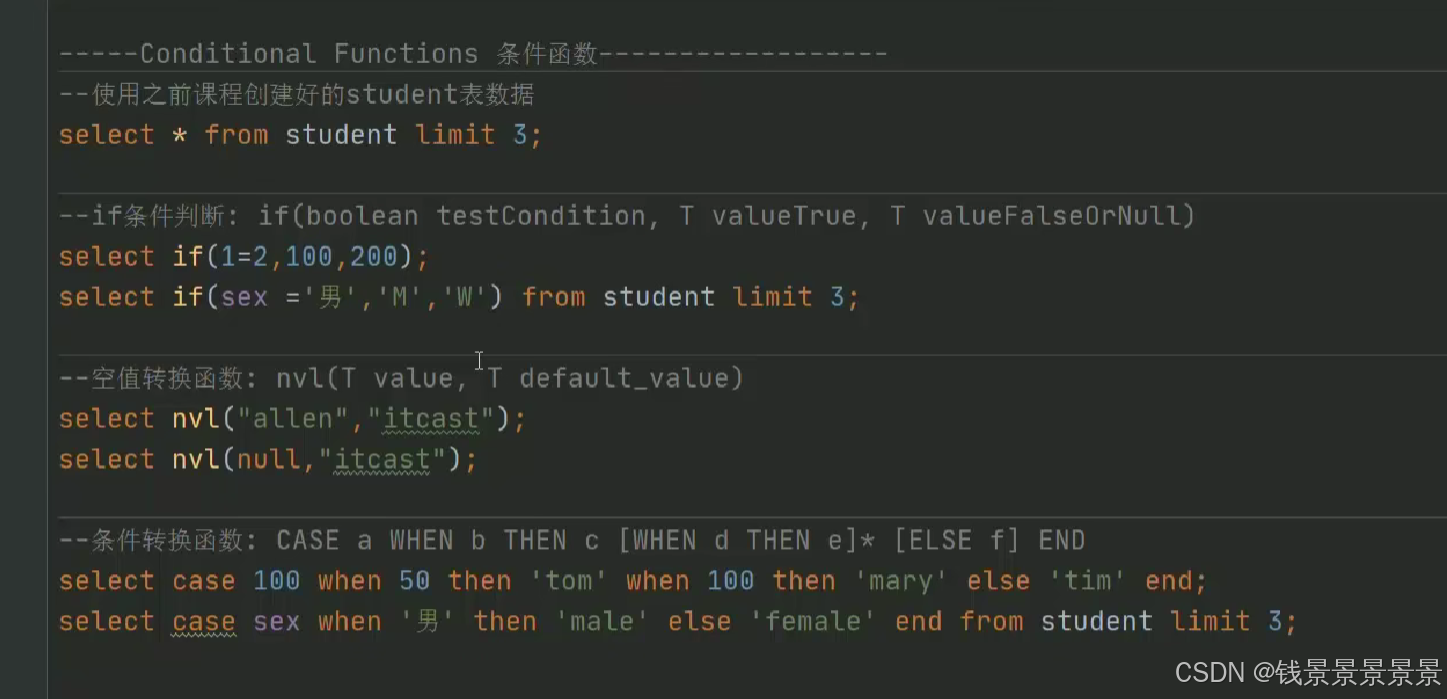
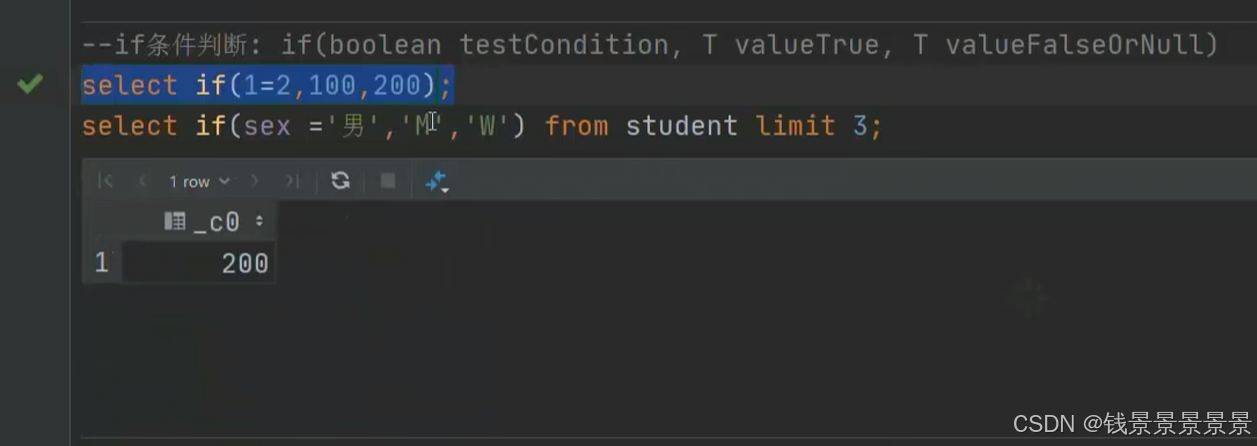
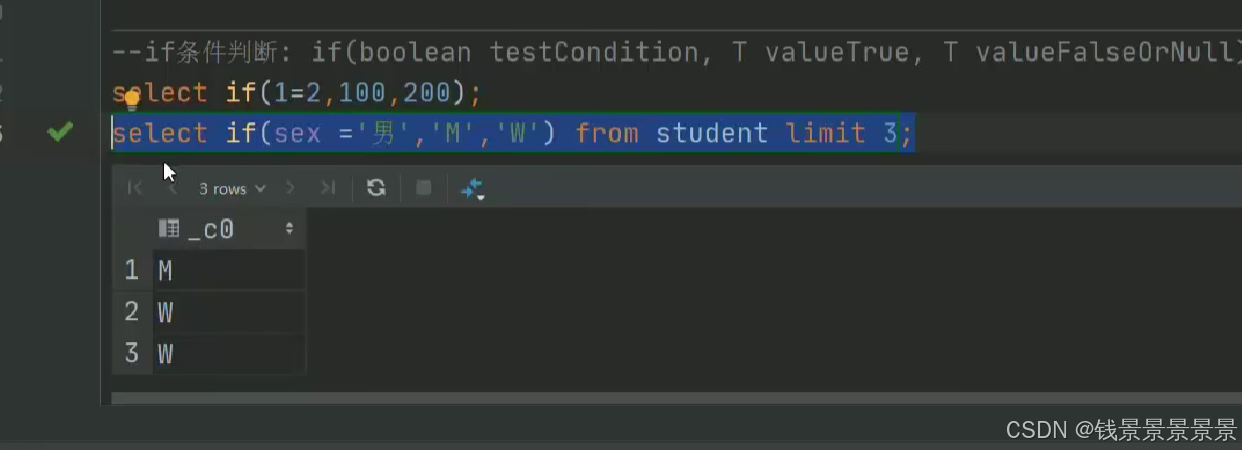
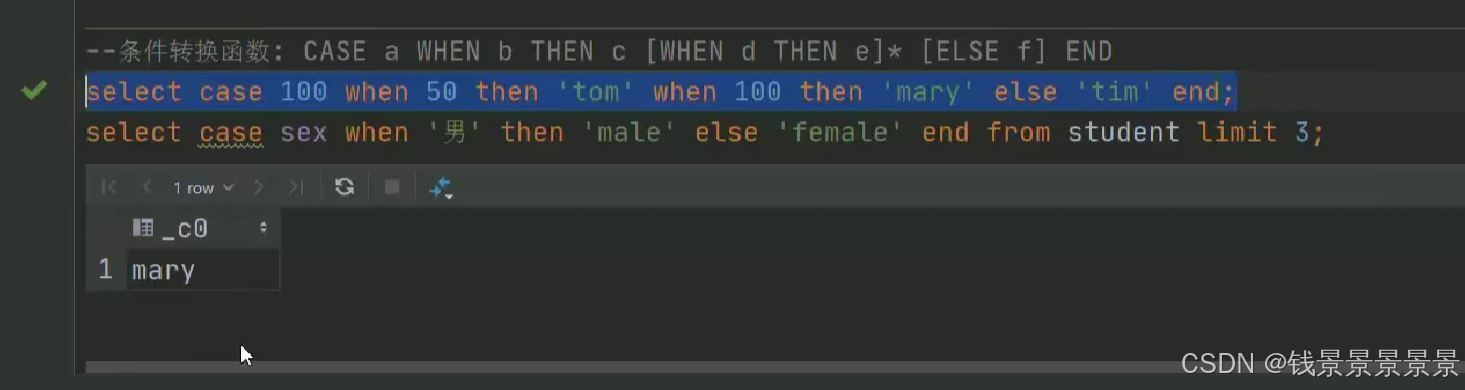
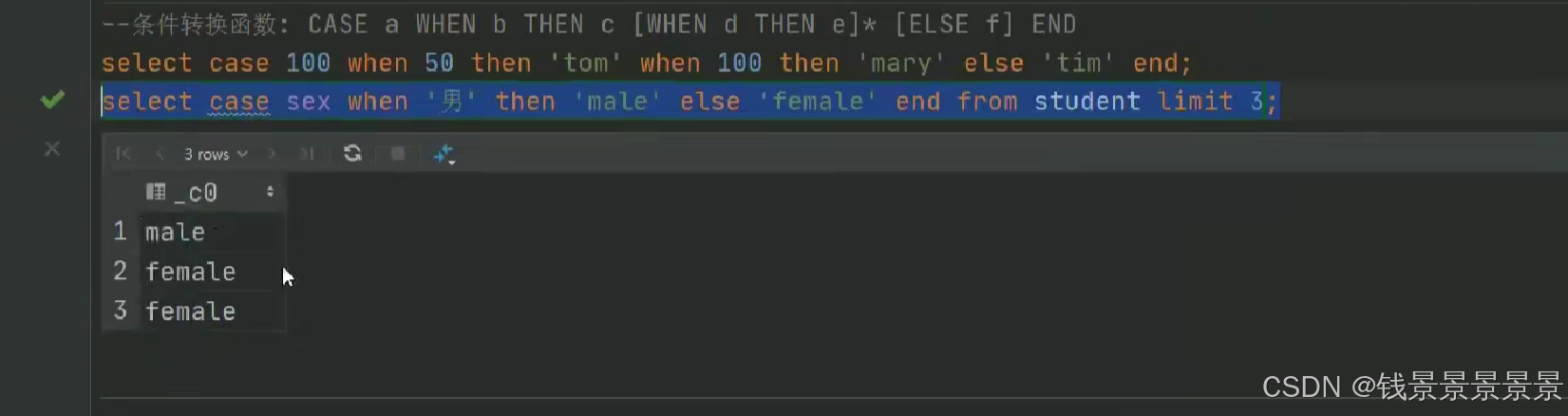
如果有多个条件判断
第六部分(Hadoop生态综合案例--陌陌聊天数据分析)
1.课程内容大纲与学习目标


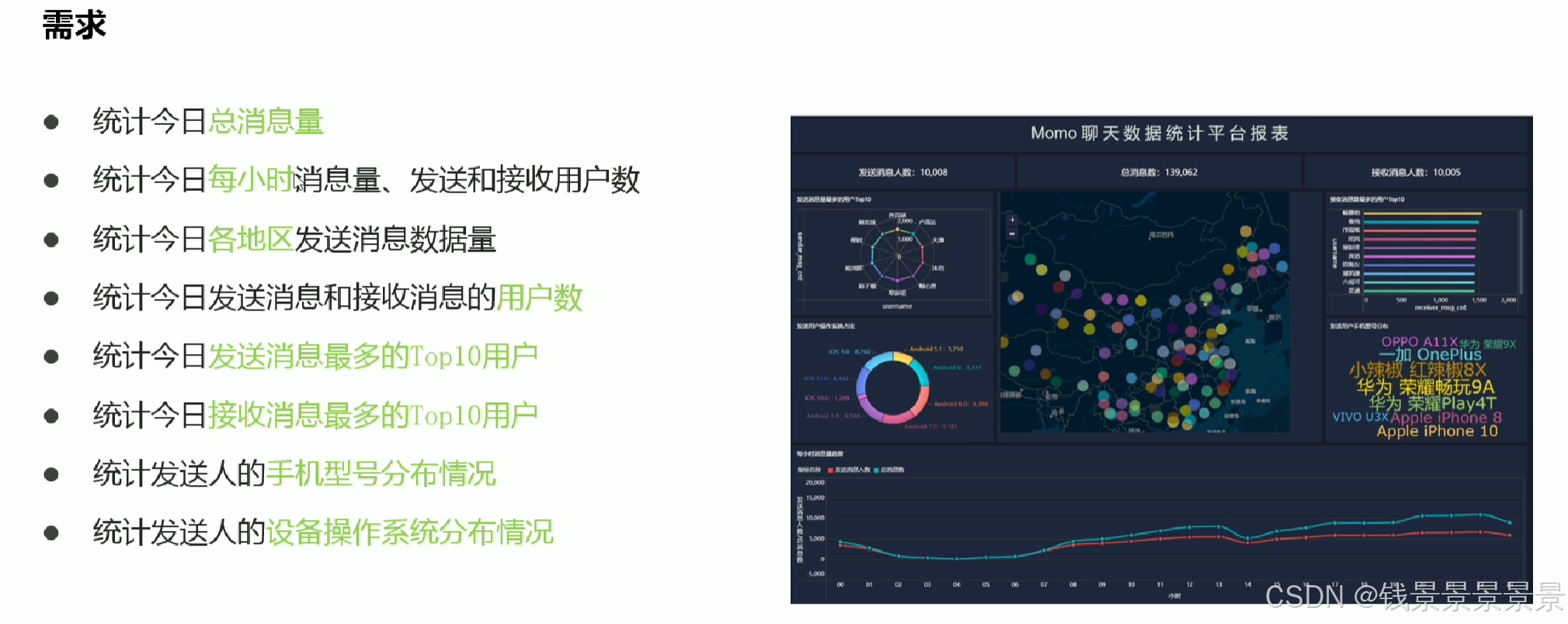
2.陌陌聊天数据分析案例需求

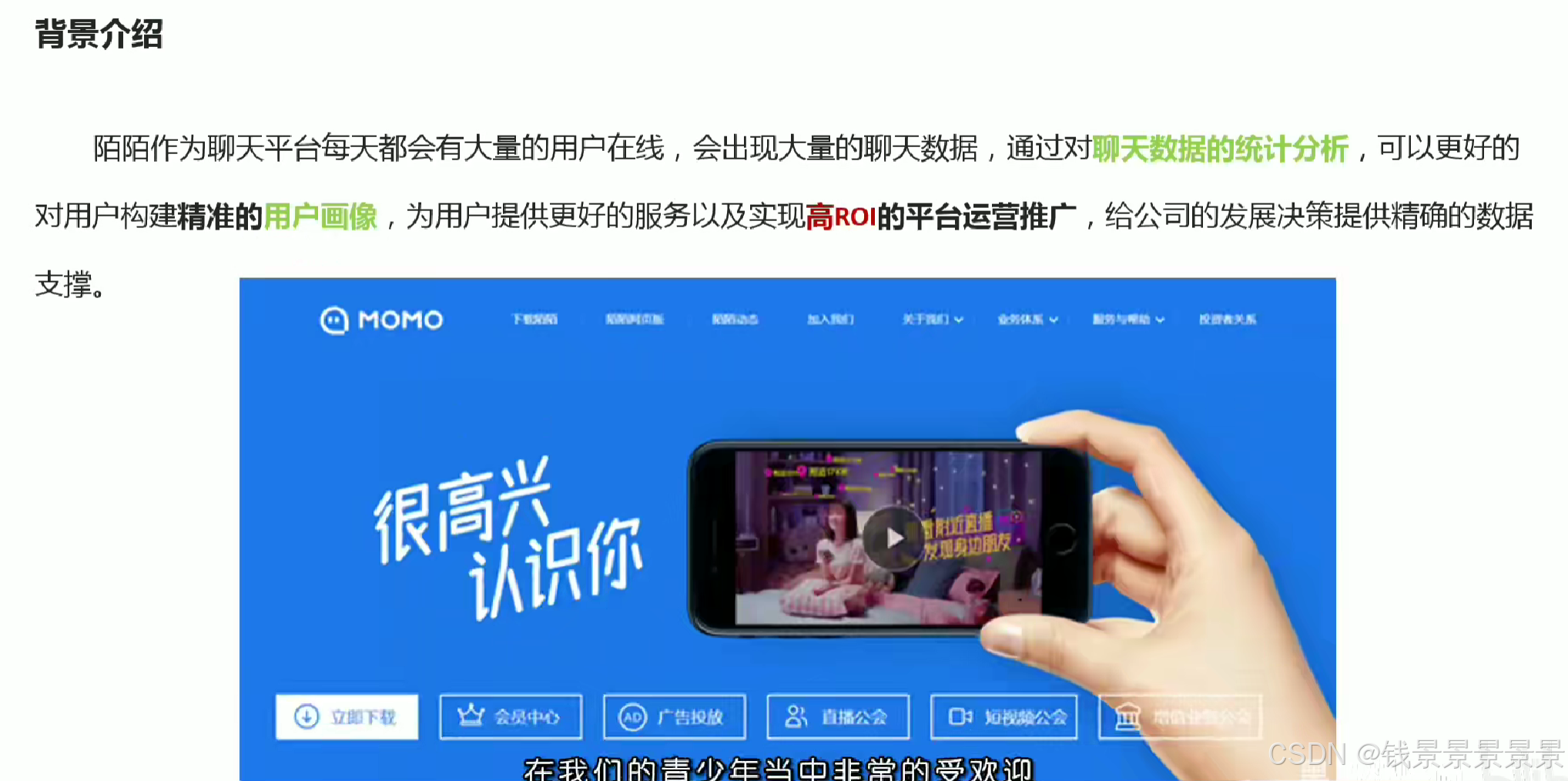
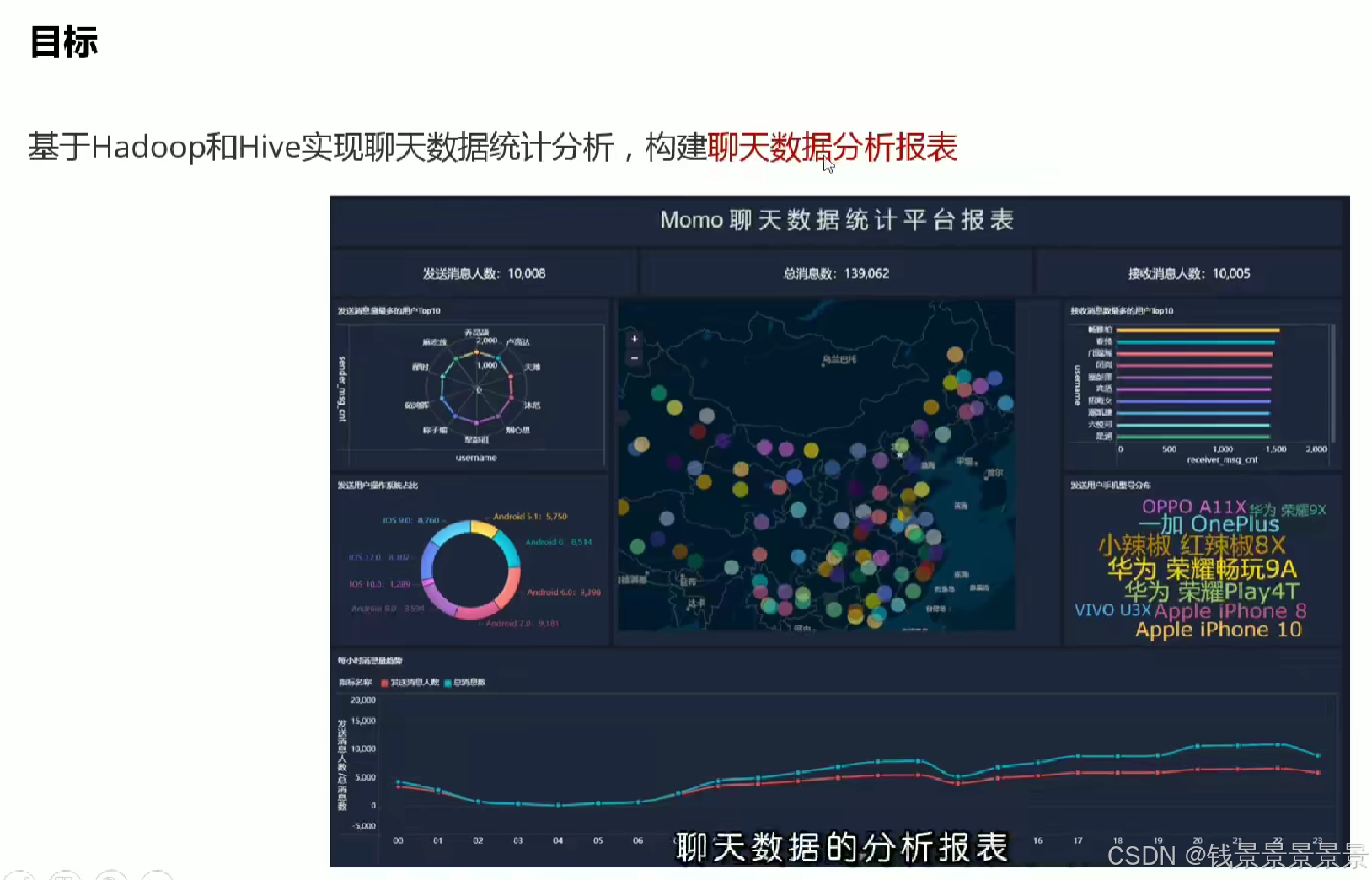
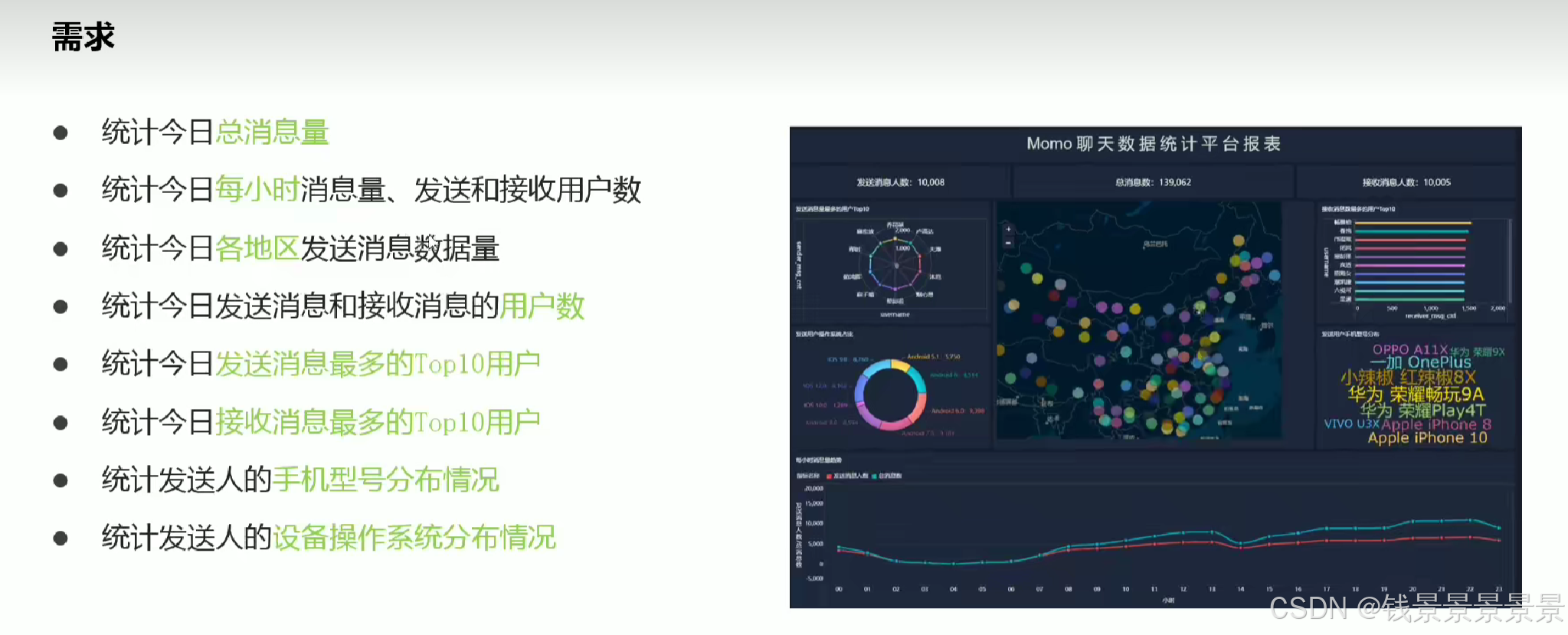
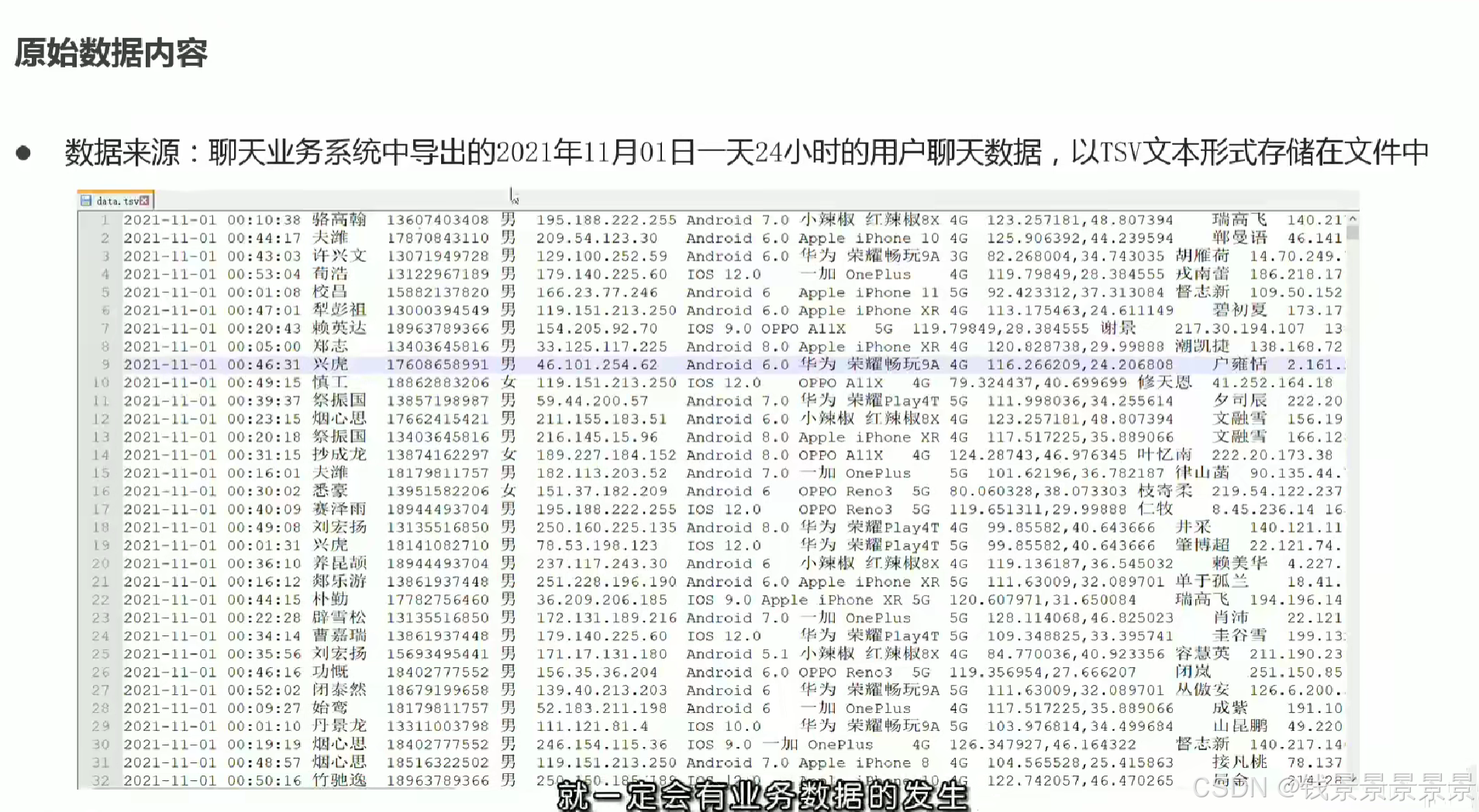
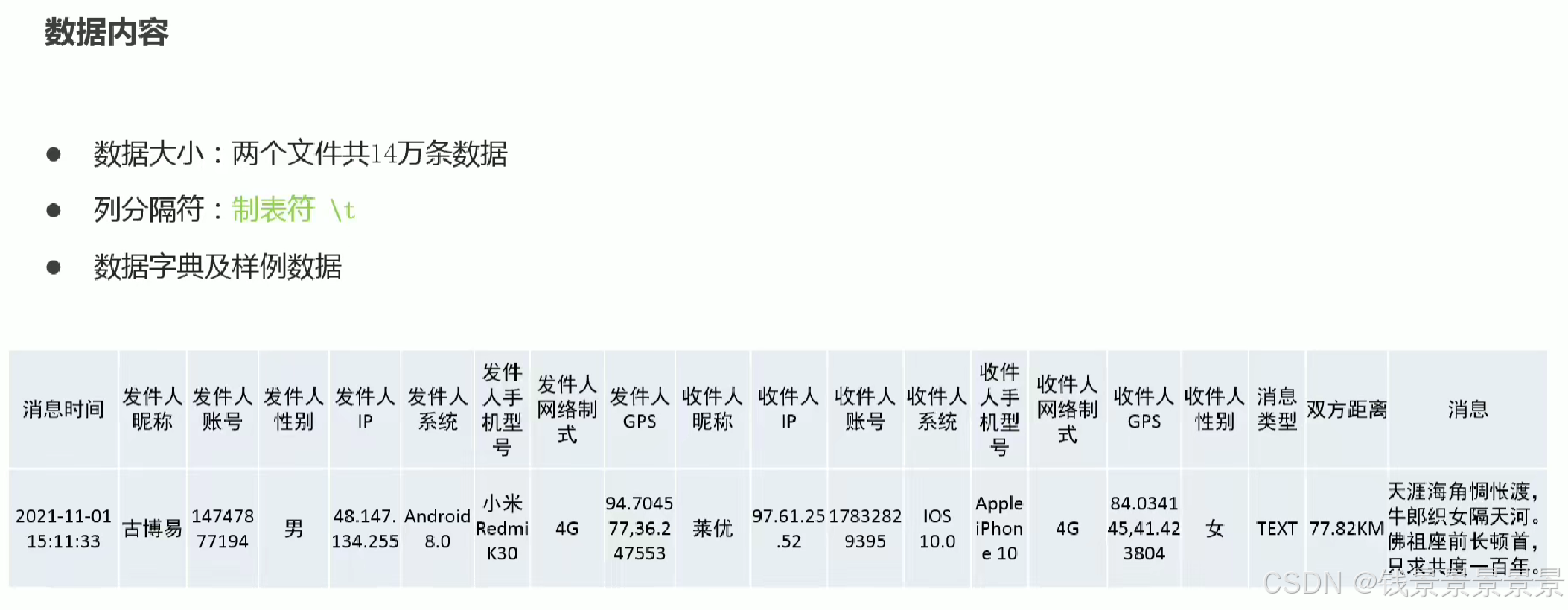
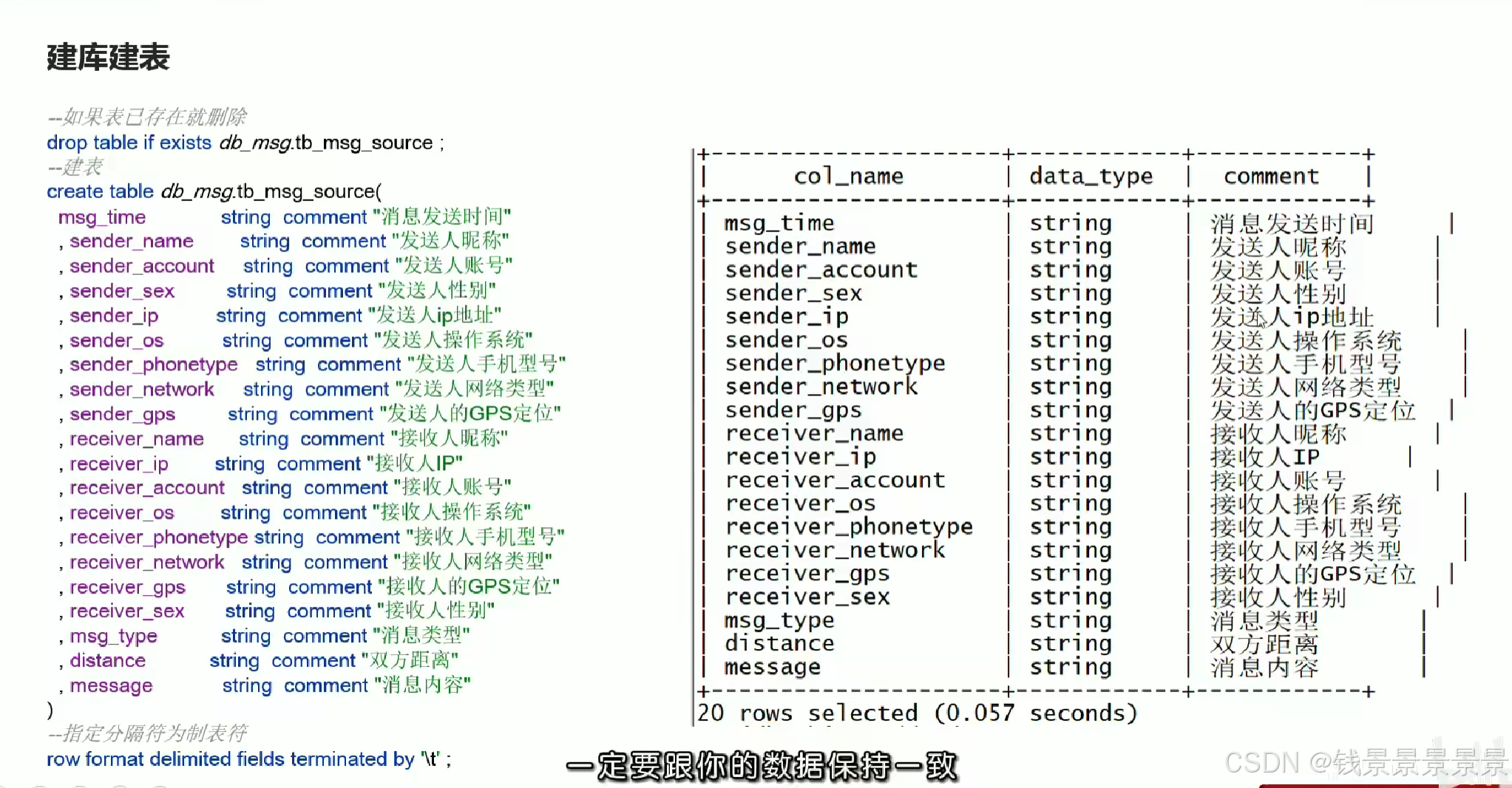
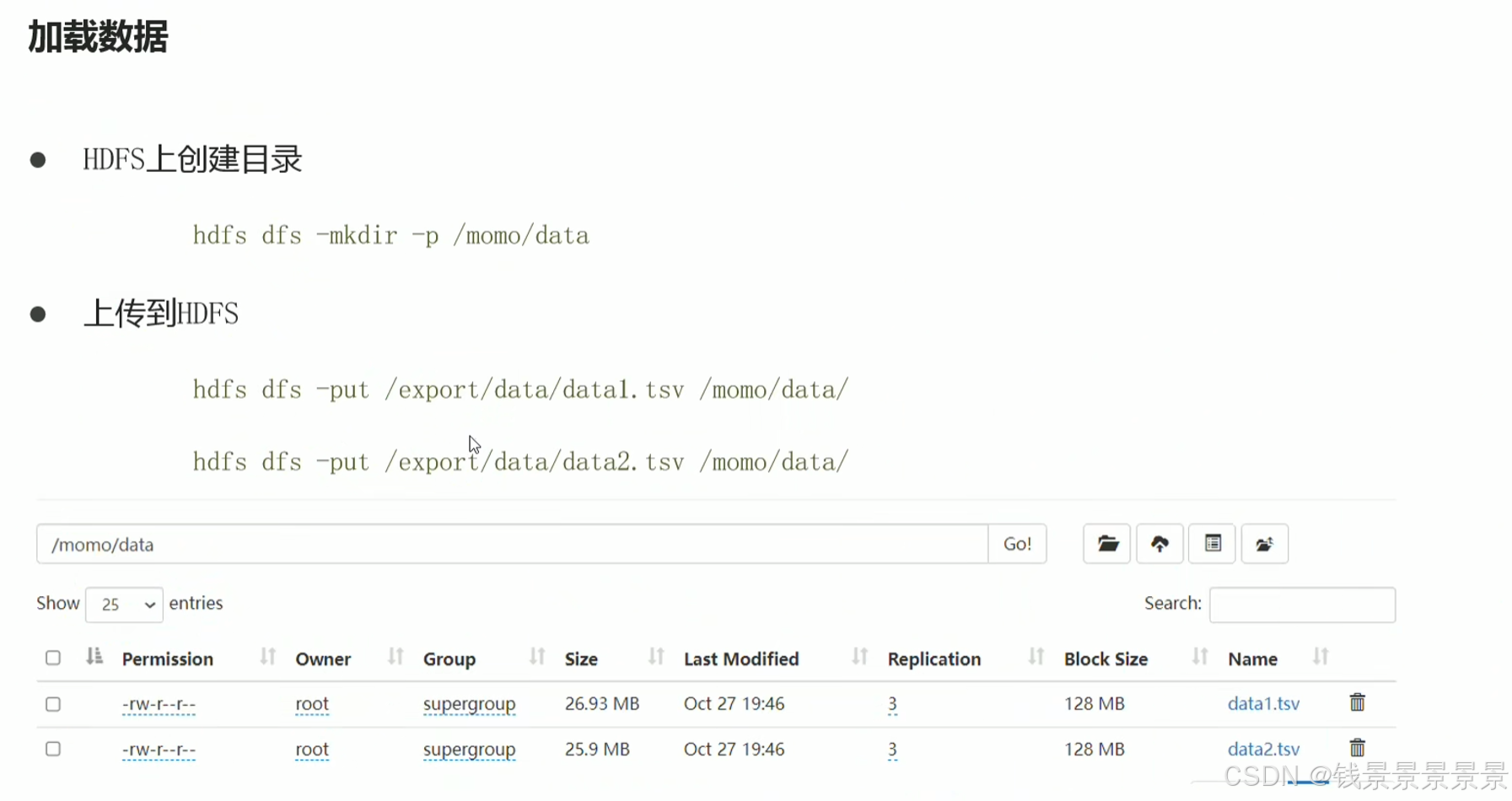
3.基于hive数仓实现需求开发-建库建表与加载数据

我们点击显示所有符号,可以查看我们的分割符
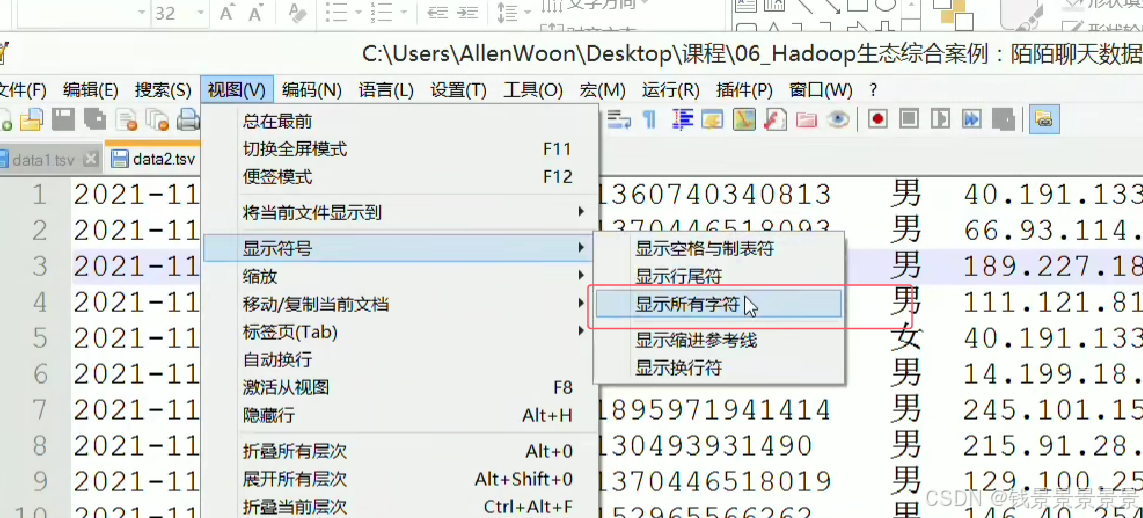
我们的tab键制表符就是->
空格键就是 .....

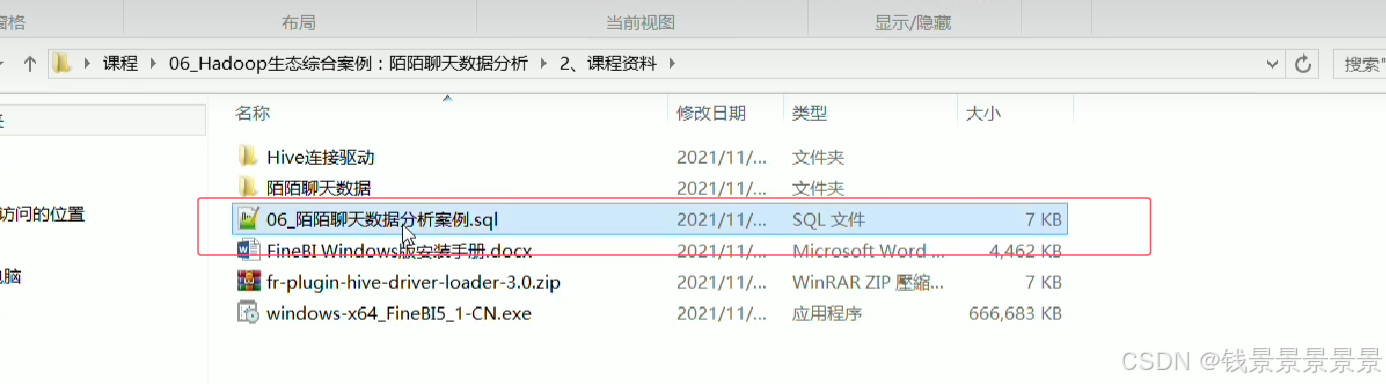
下面是课程使用的SQL文件
复制到datagrip
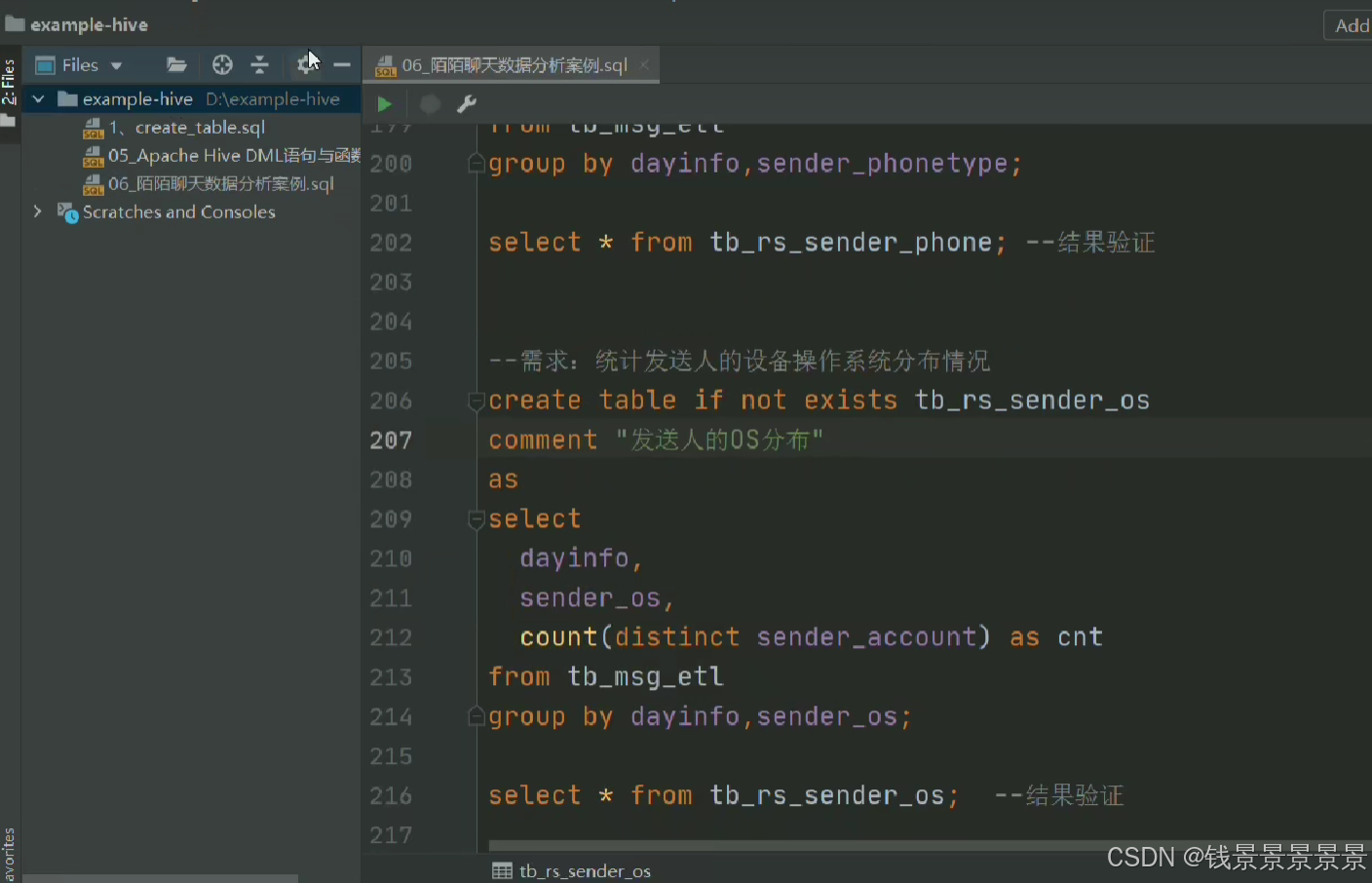
修改SQL为hive支持
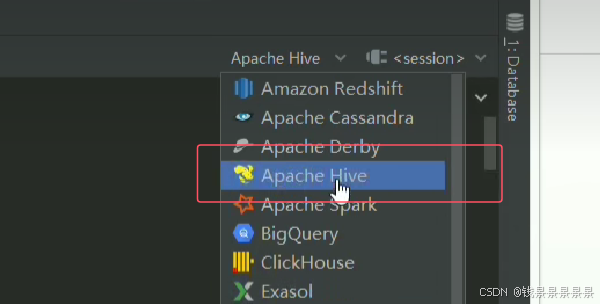
与hive服务器做一个连接
首先创建数据库
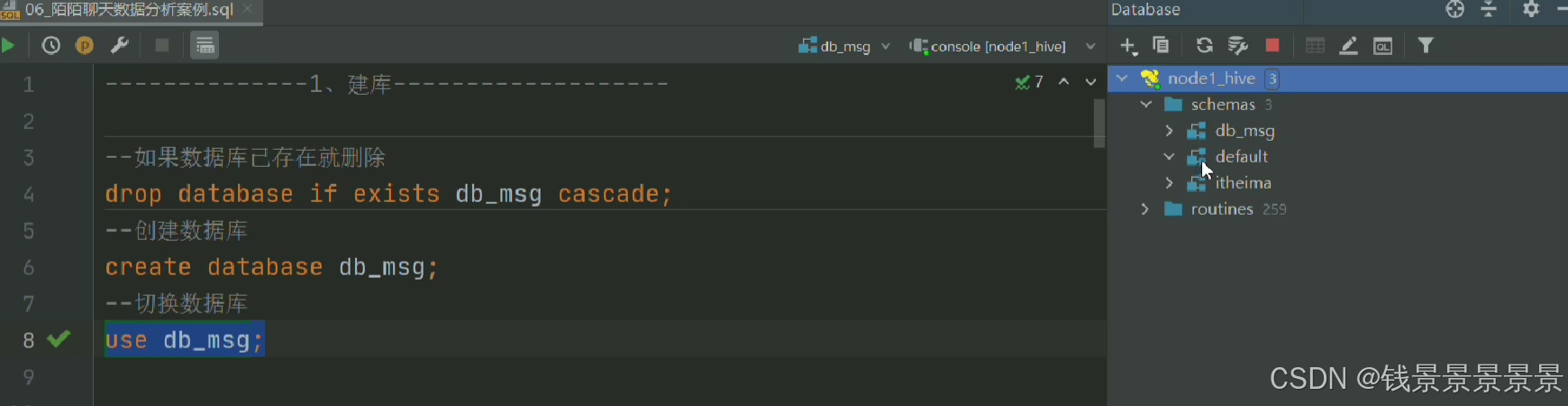
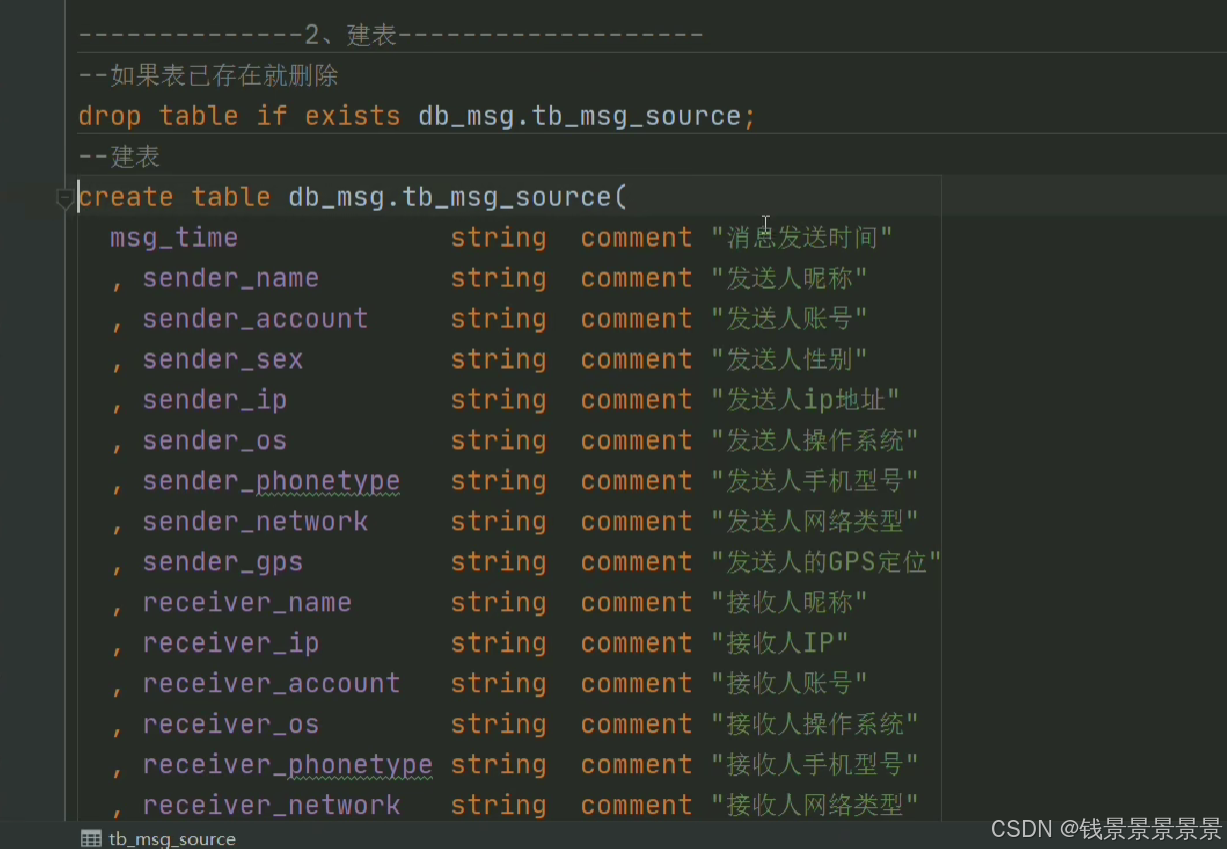
然后创建表
然后加载数据
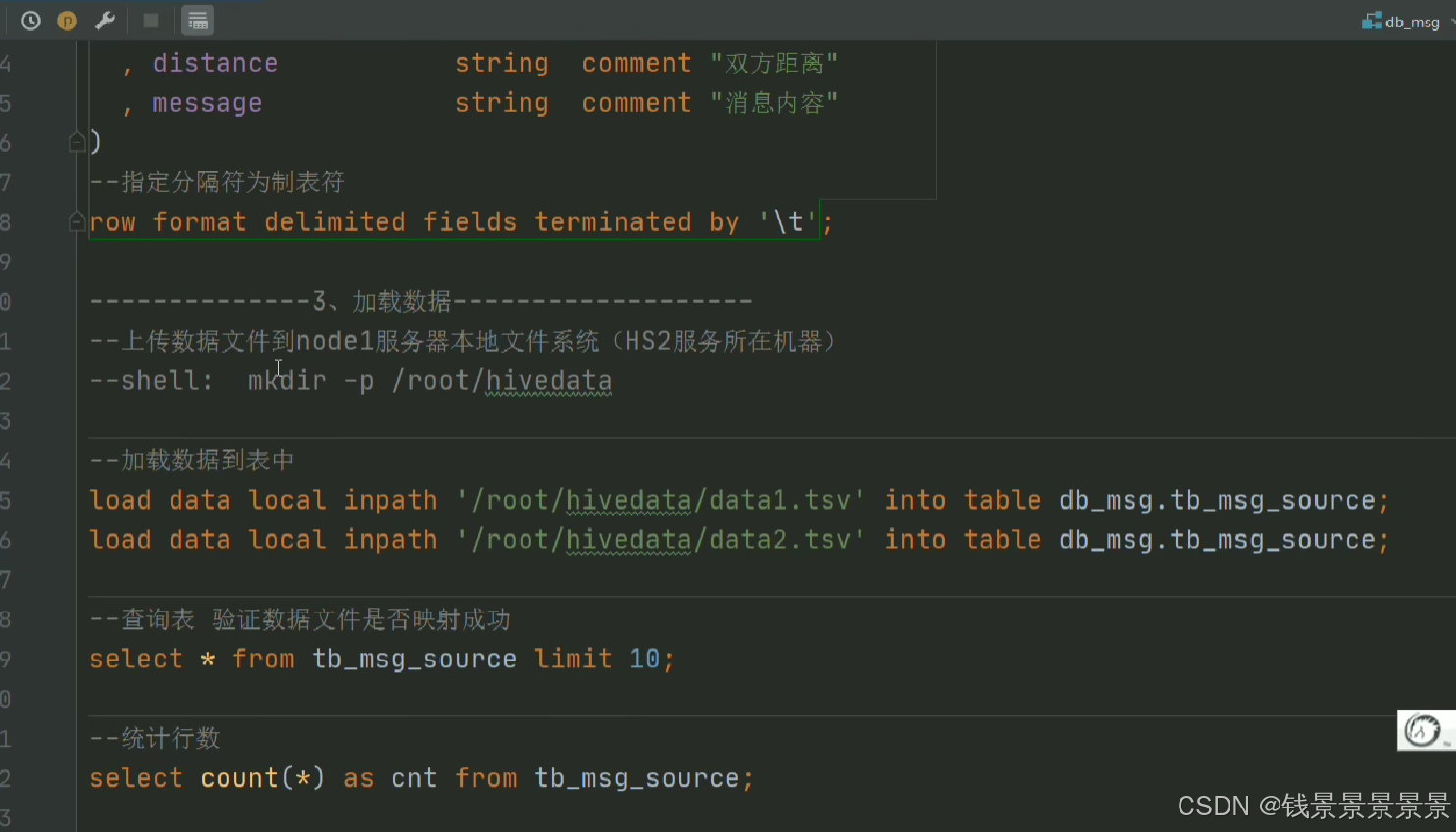
要先将文件上传到Linux系统中
4.基于hive数仓实现需求开发-ETL需求分析与技术支持



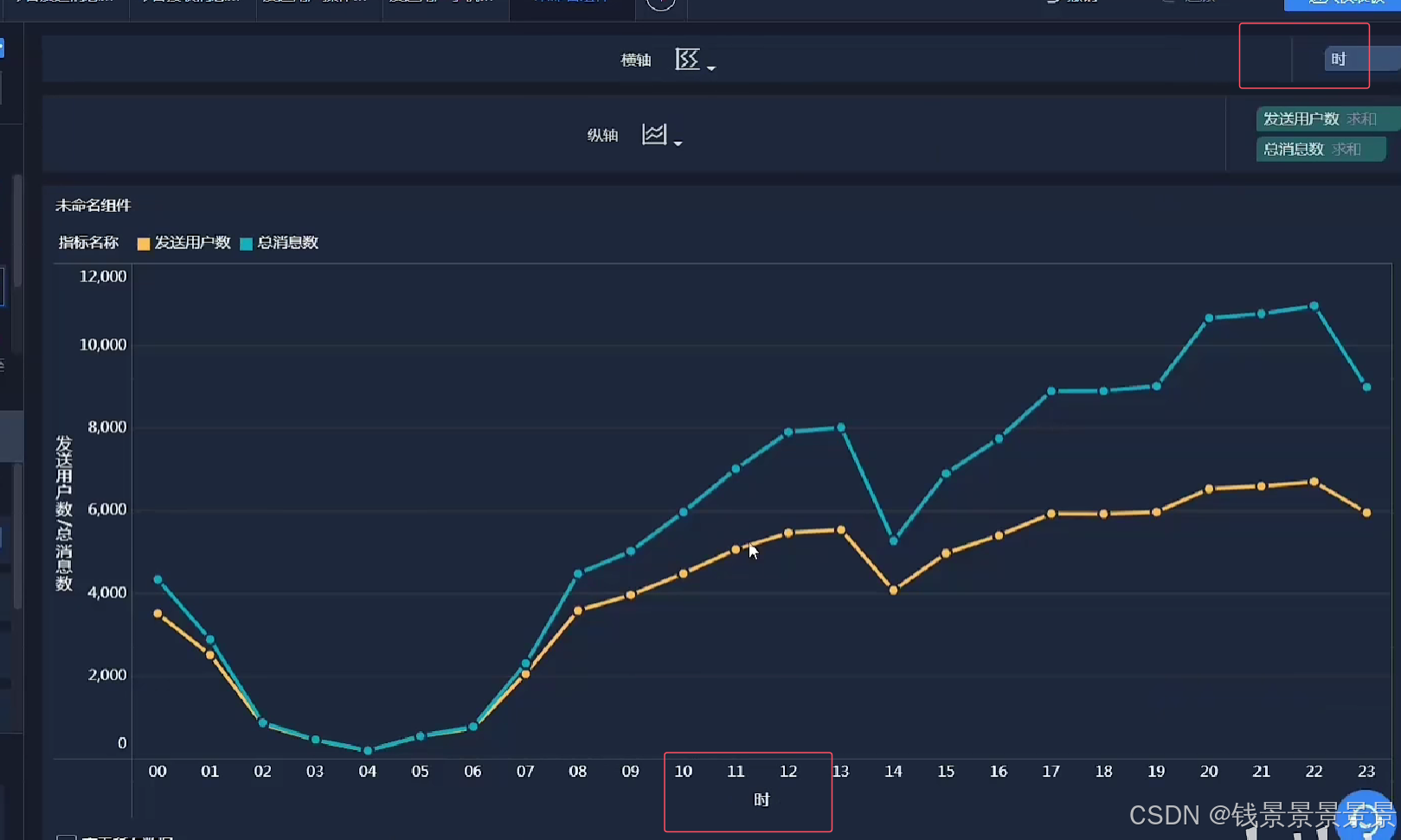
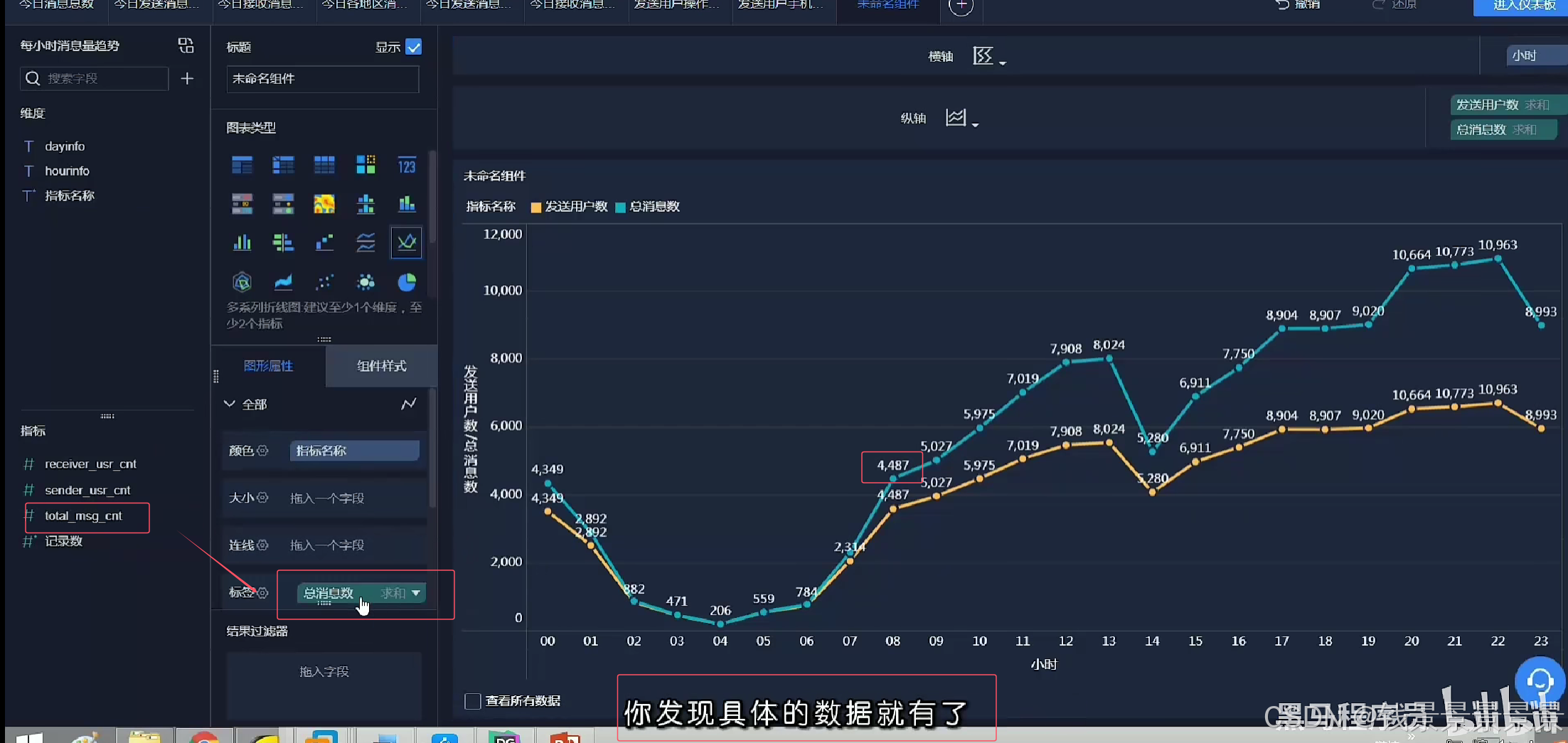
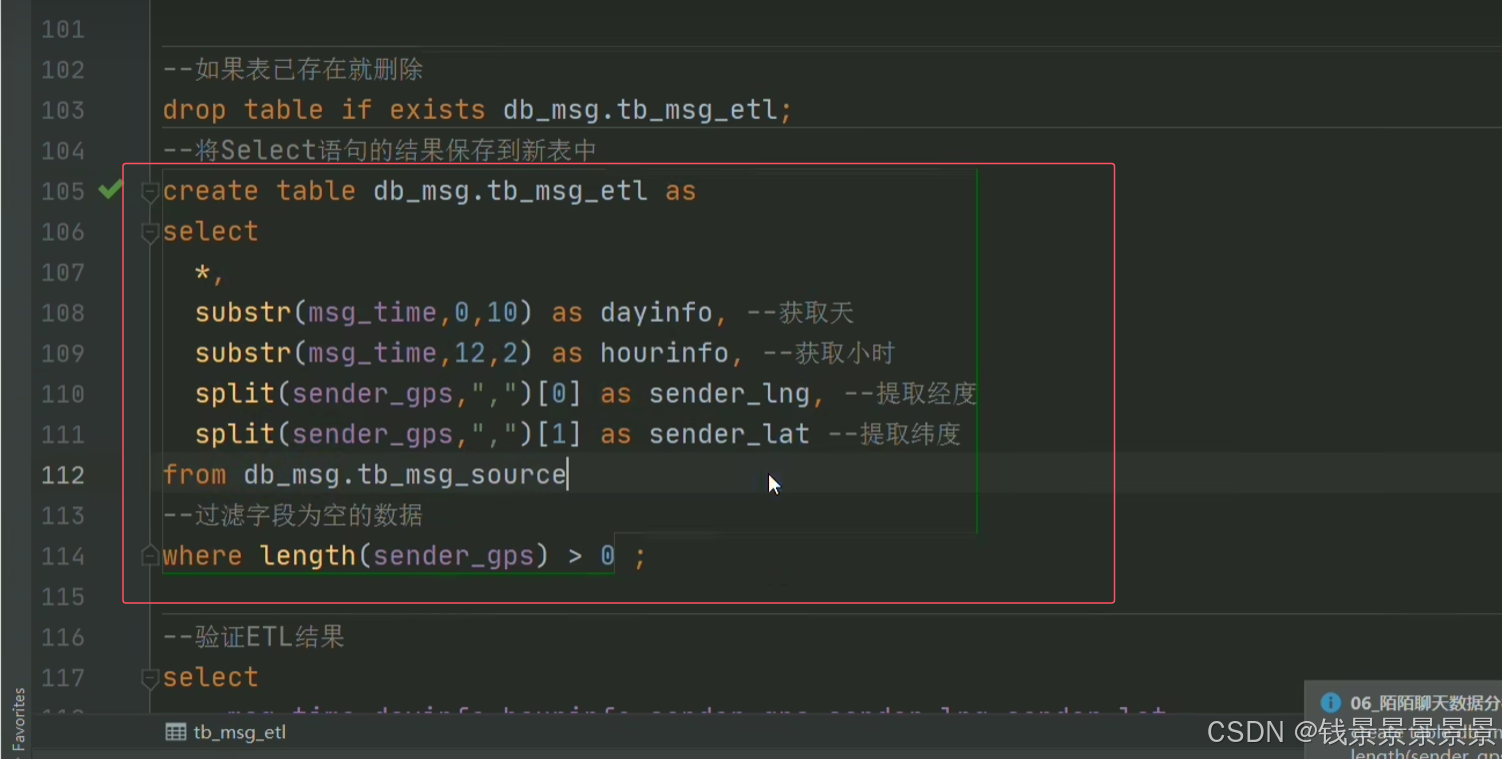
比如要统计每个小时的数量
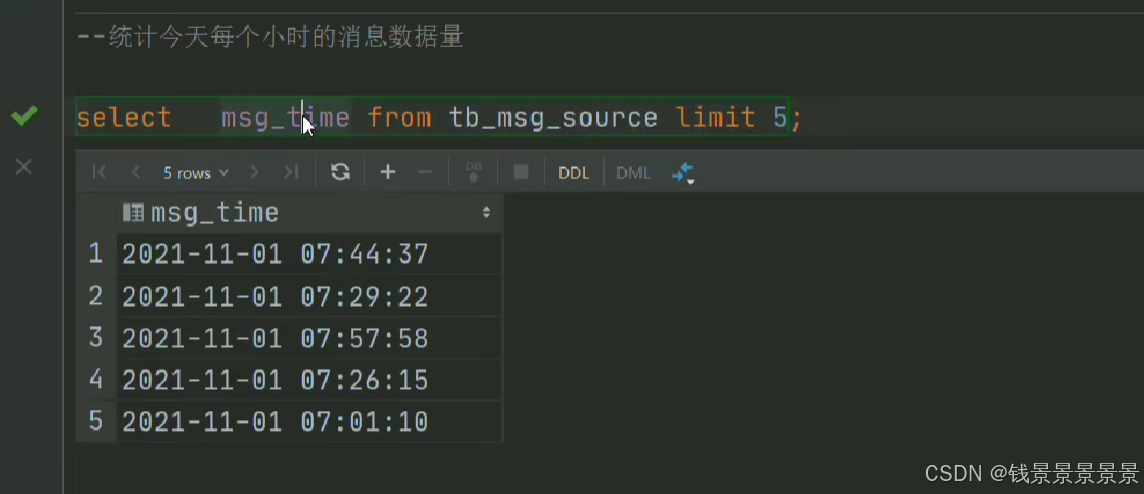
我们做一个截取
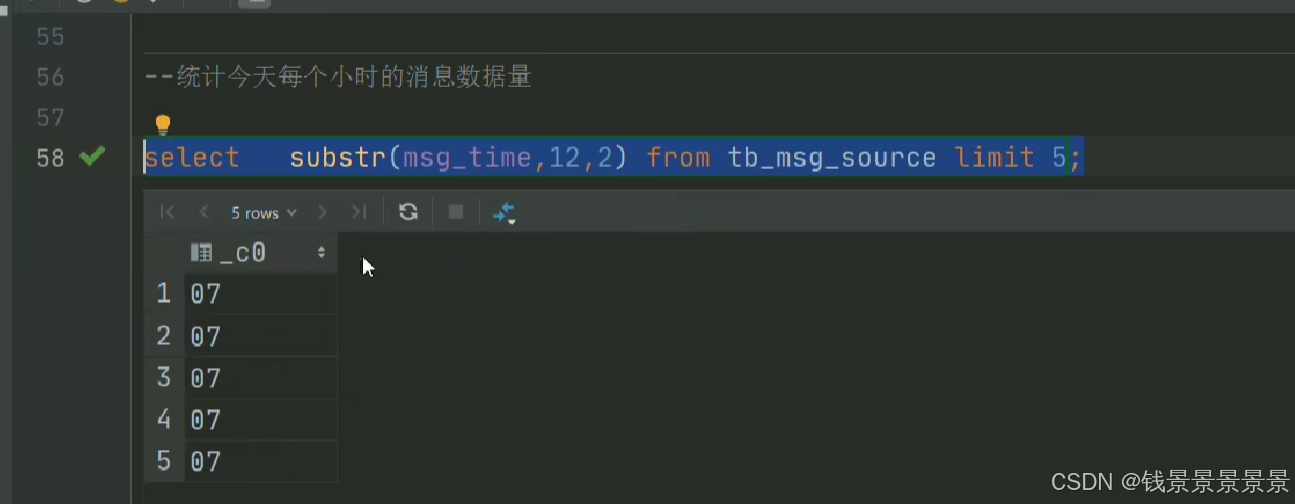
那我们要以小时分组,可以用下面的方式
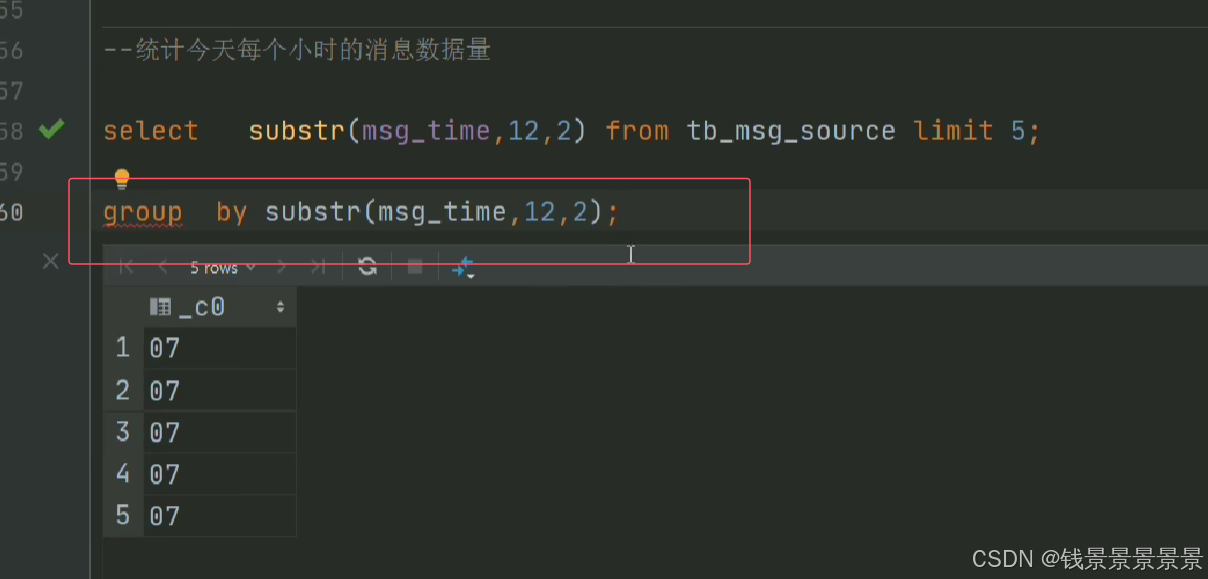
但有一个弊端
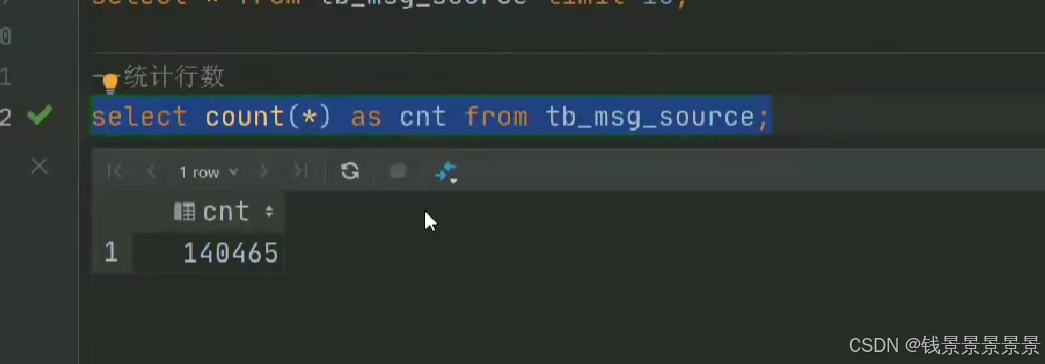
14w条数据,每次都要截取,性能受到很大的影响
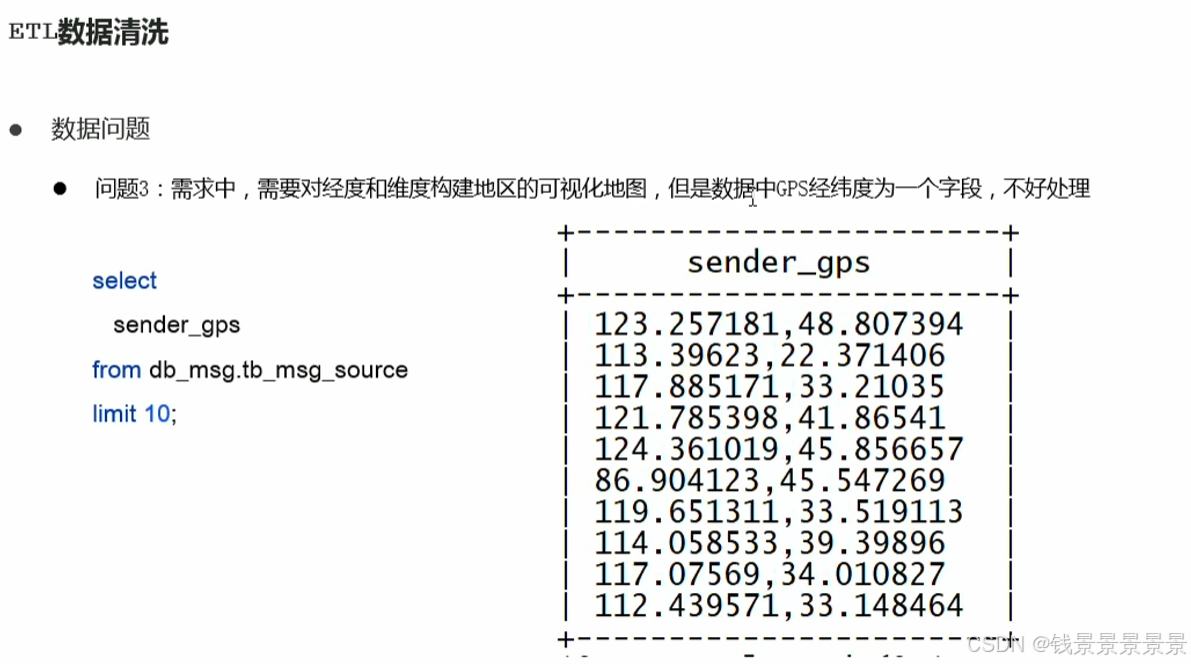

需求4,就是解决我们清洗好的数据放在什么地方的问题
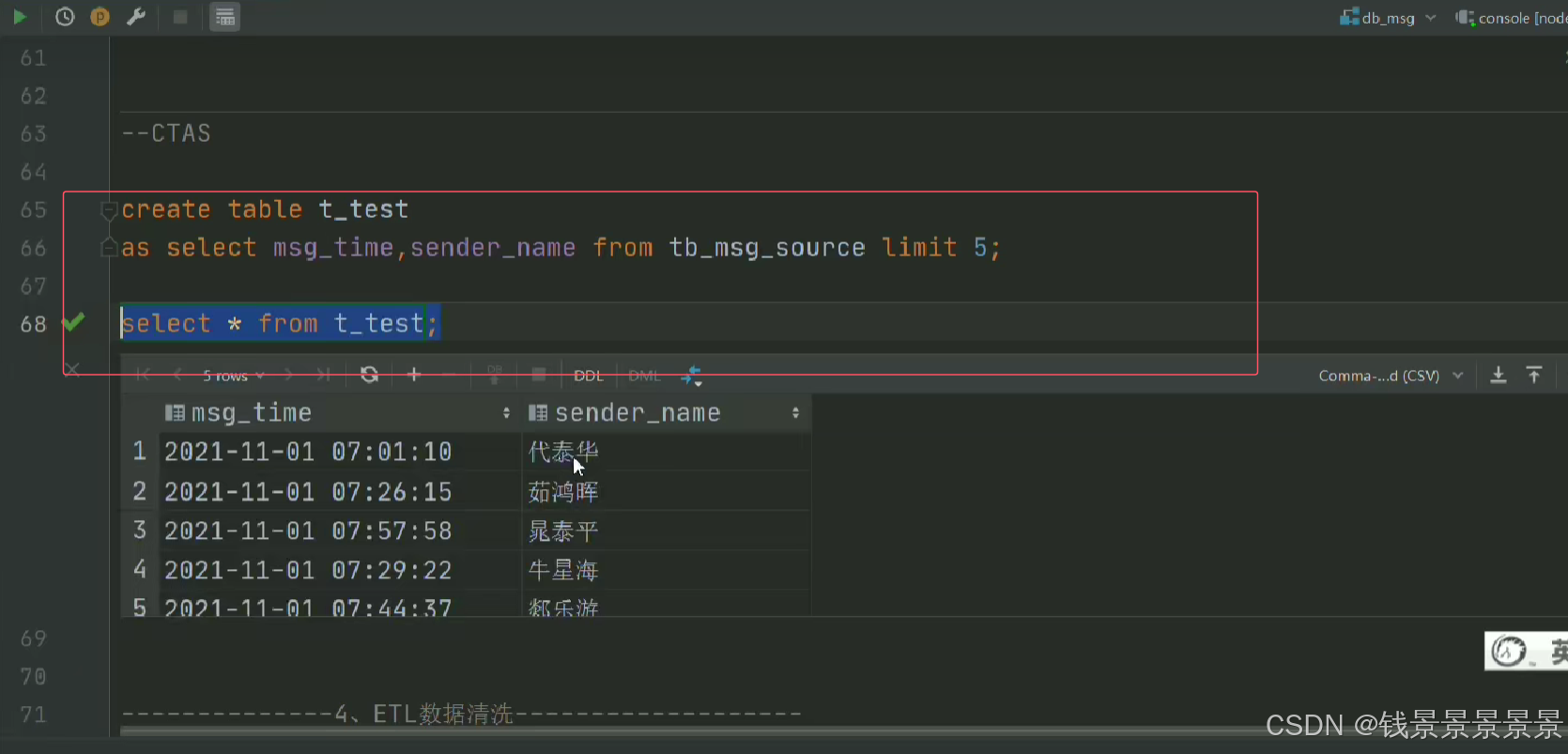
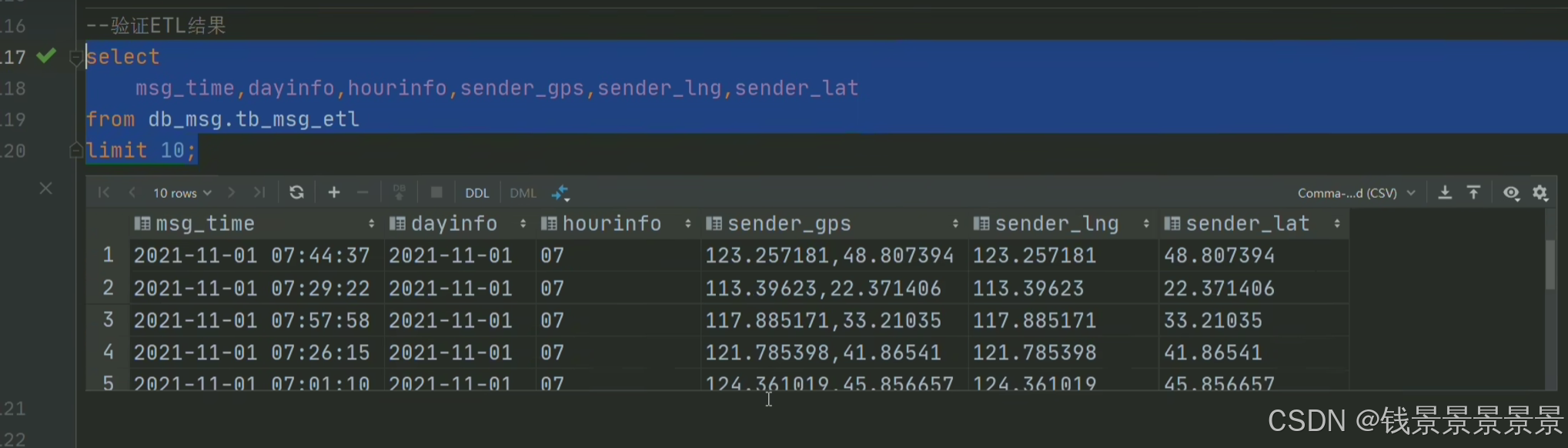
5.基于hive数仓实现需求开发-ETL SQL实现
6.基于hive数仓实现需求开发--SQL编写思路与指标计算part1


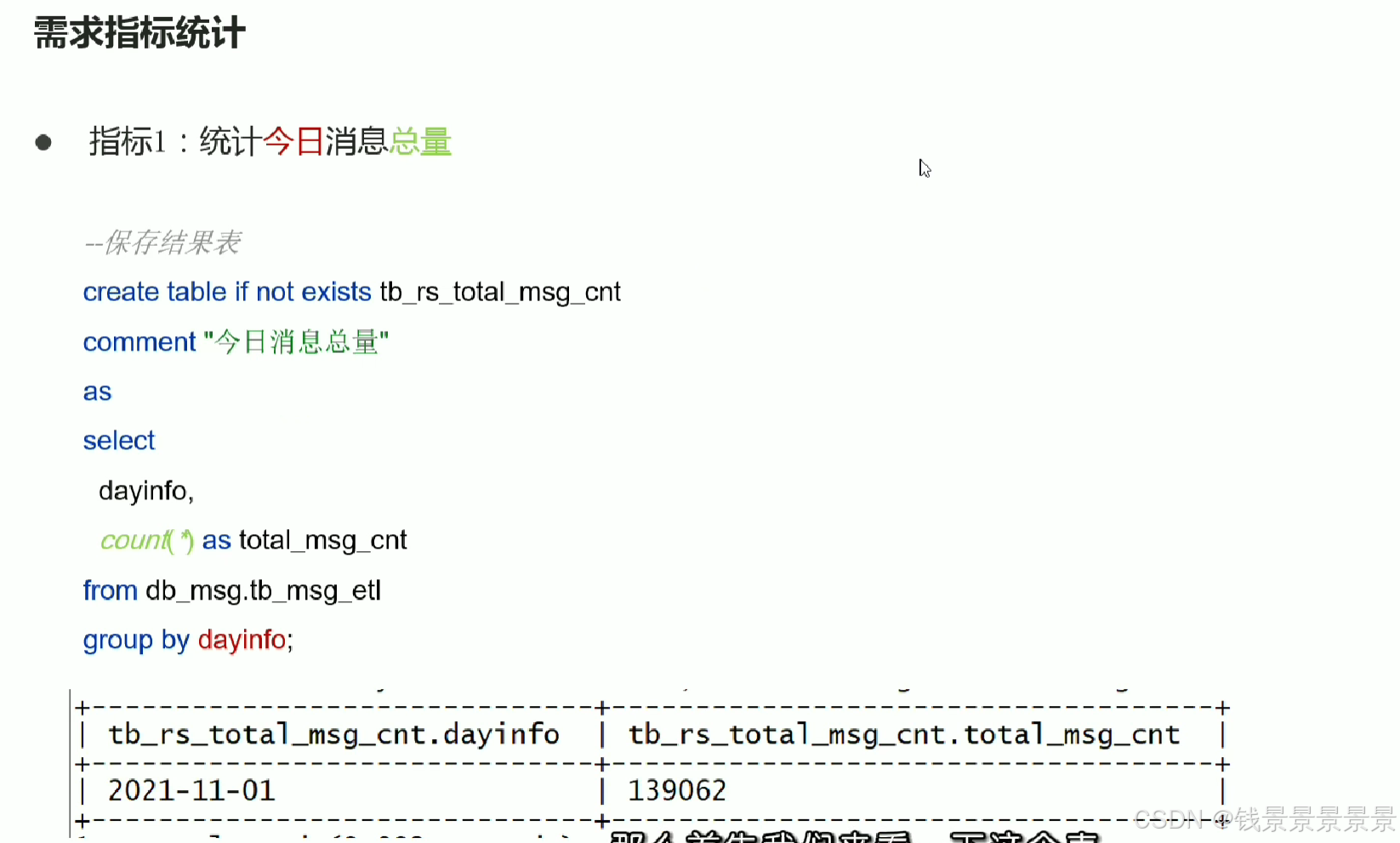
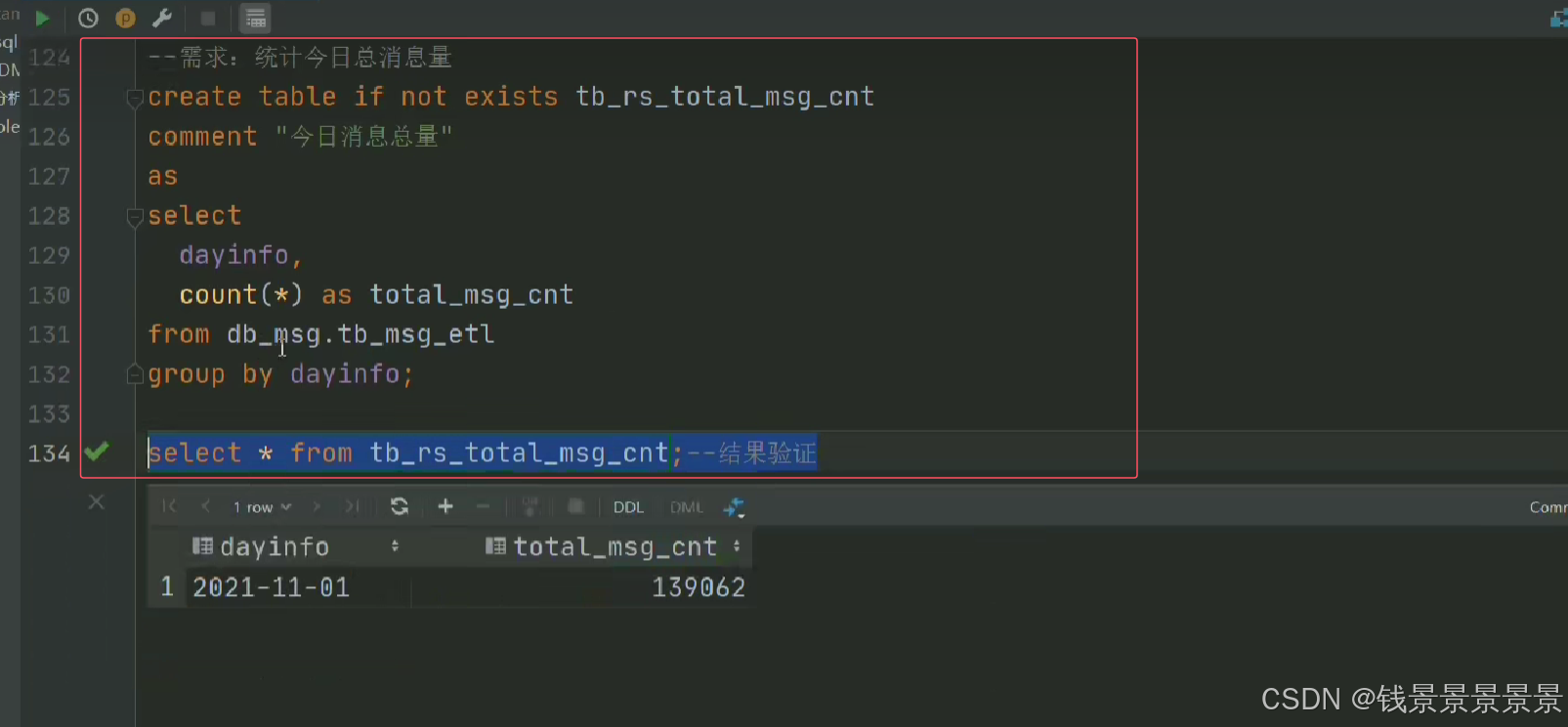

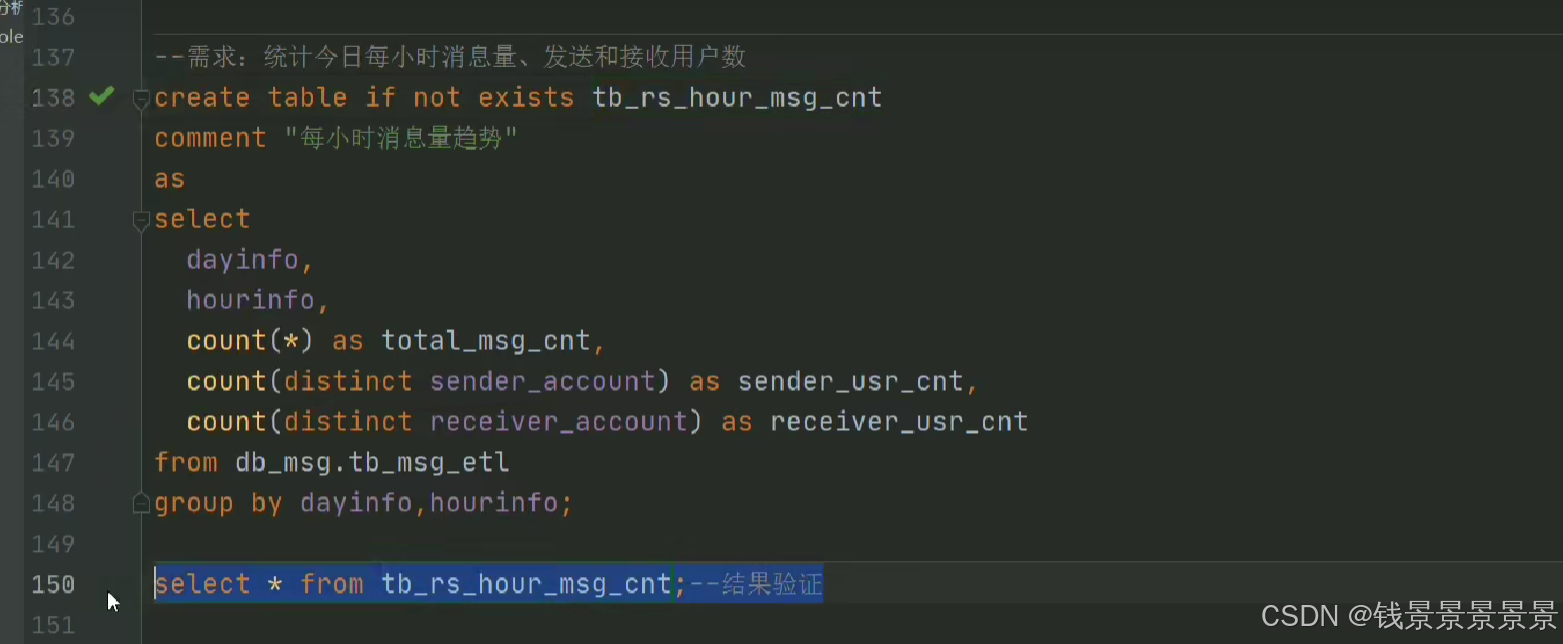
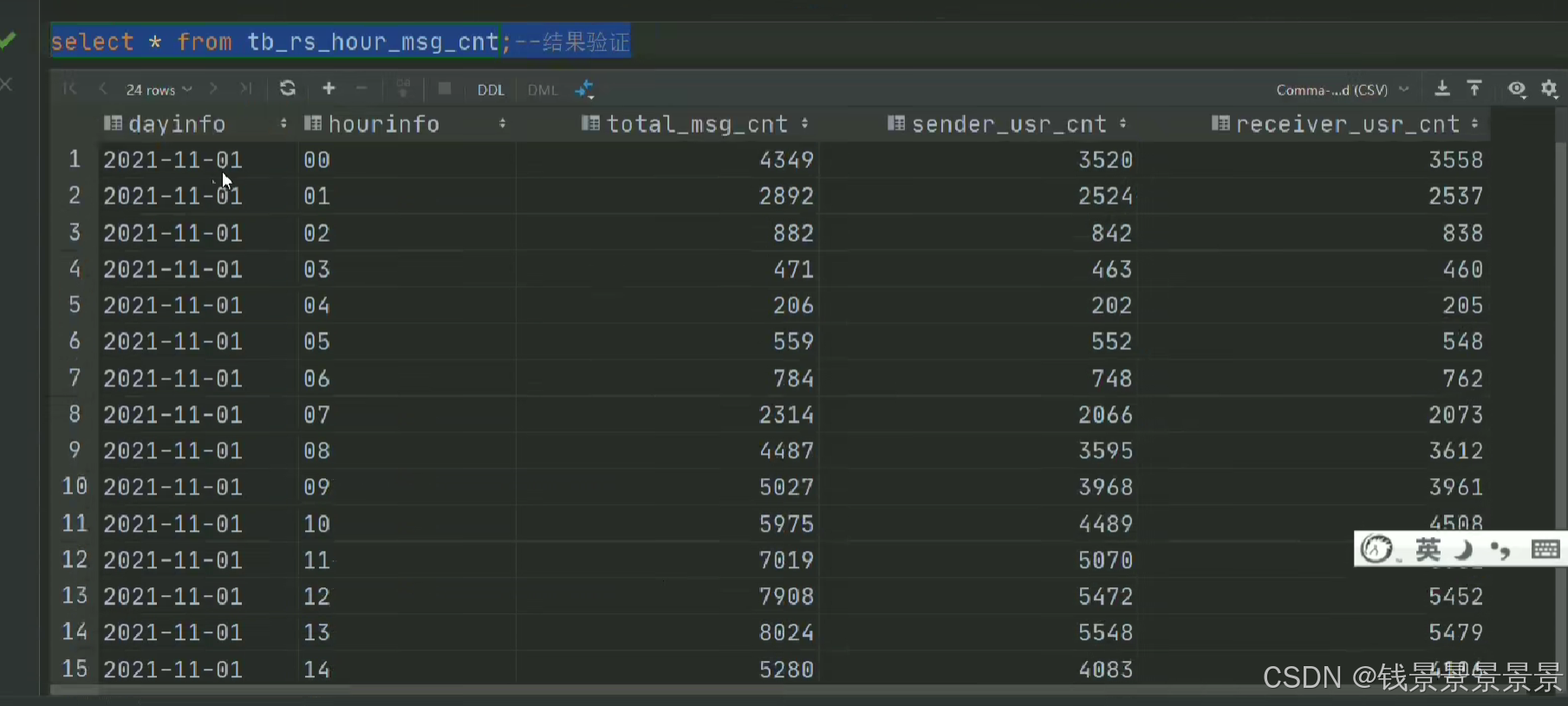
7.基于hive数仓实现需求开发--SQL编写思路与指标计算part2
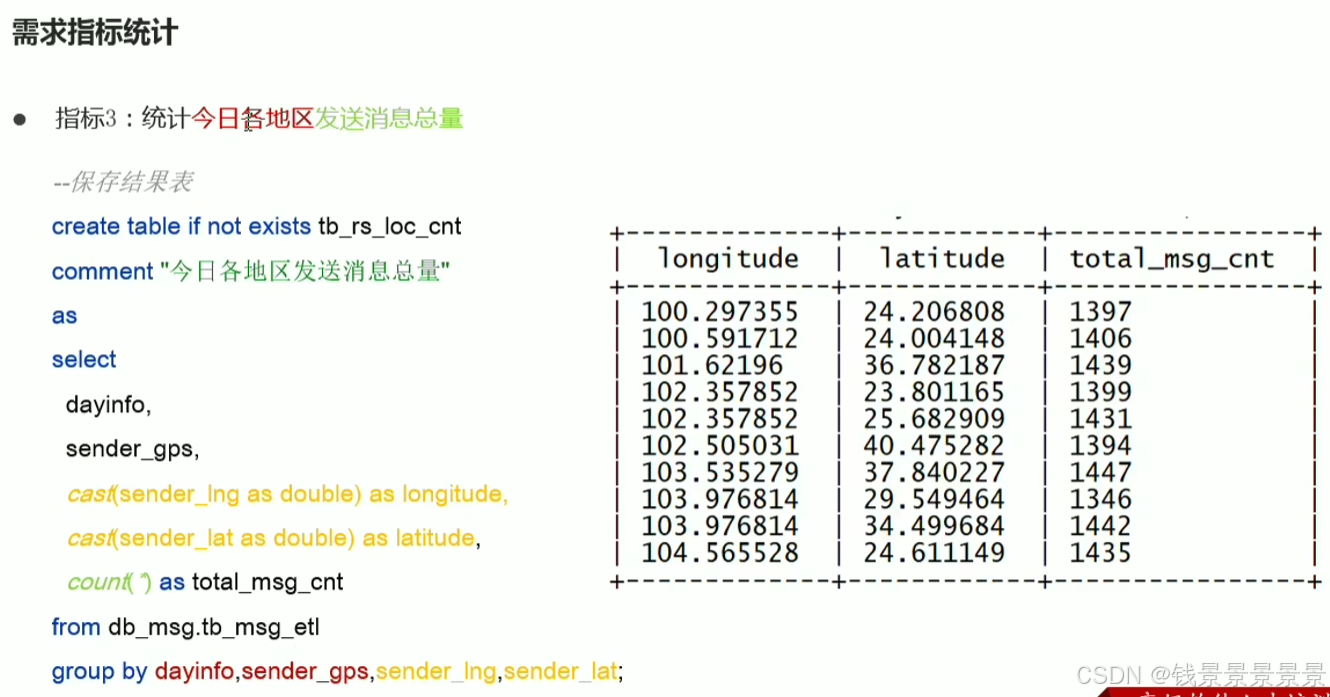
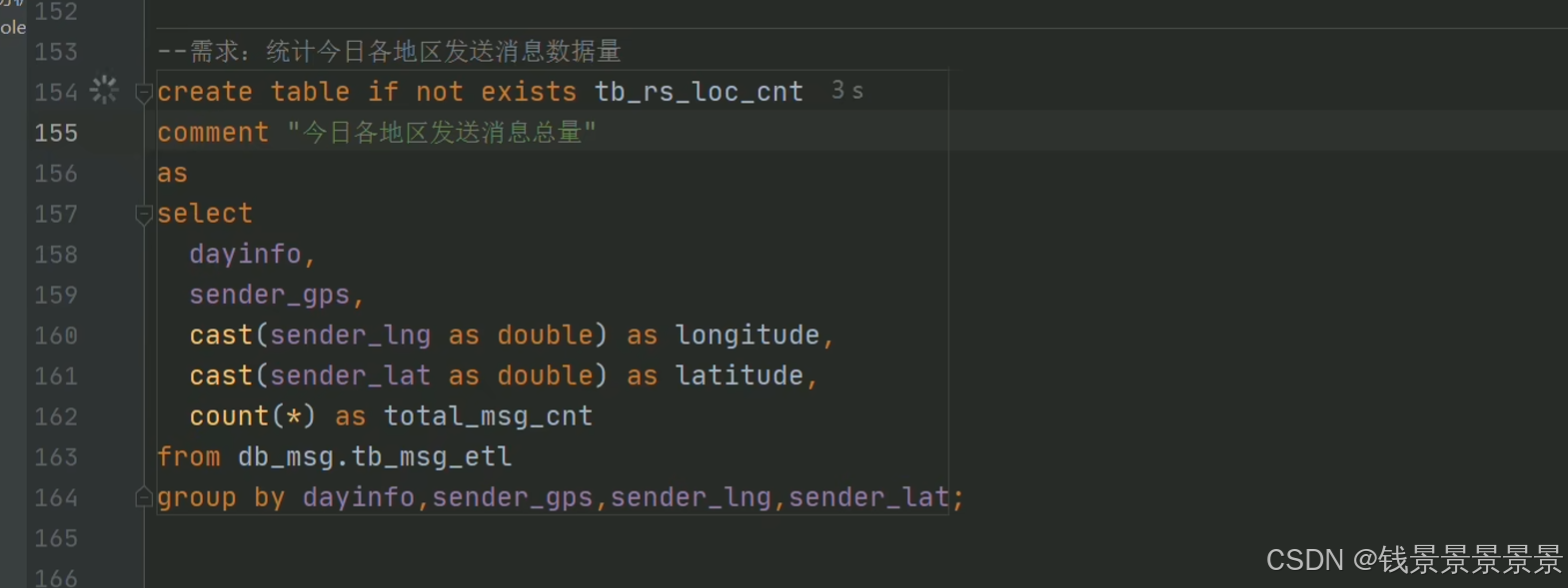
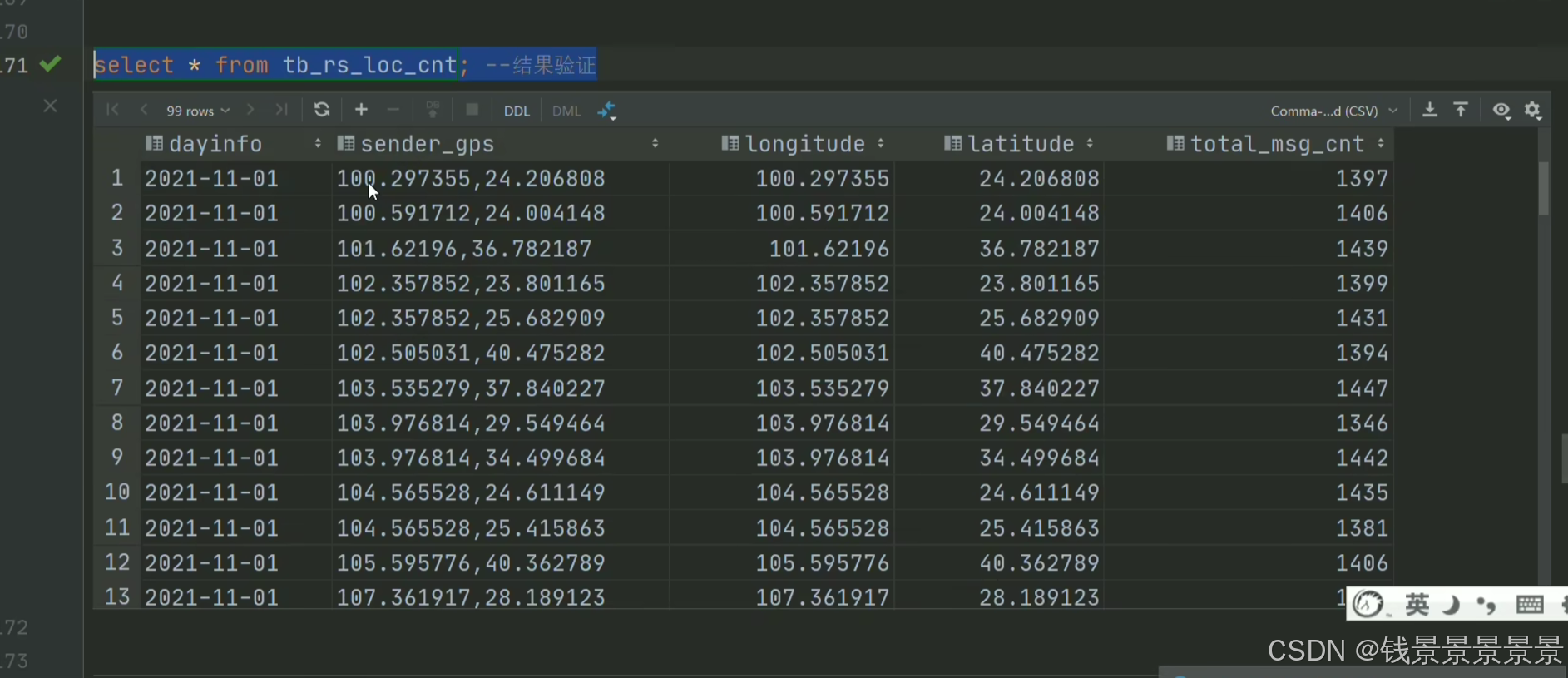

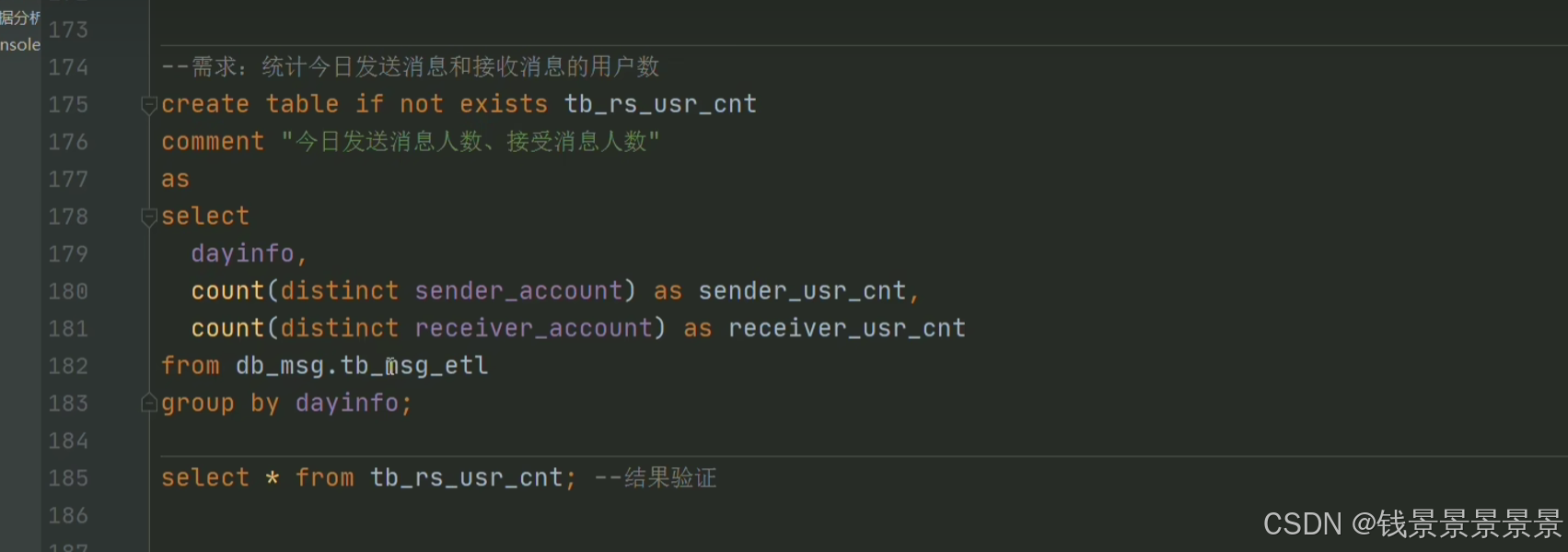
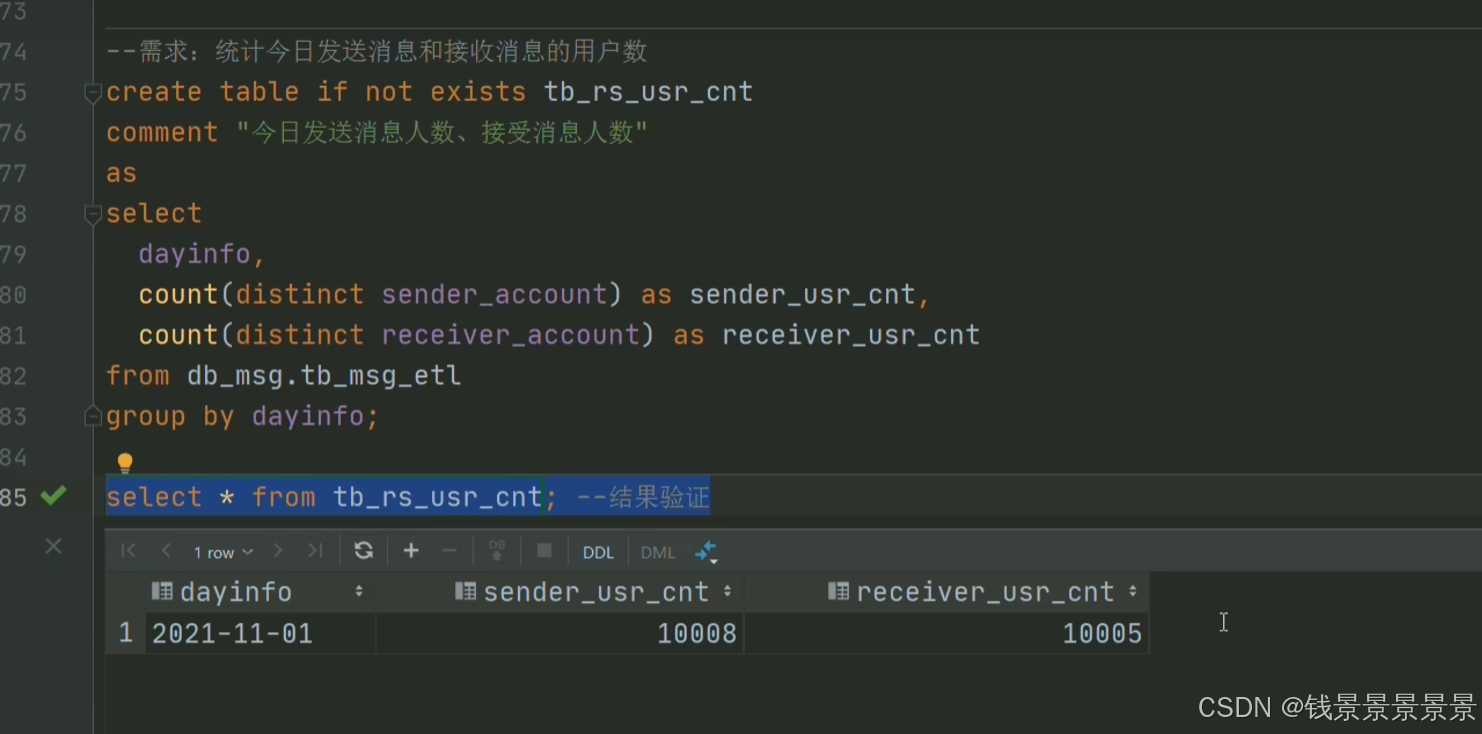
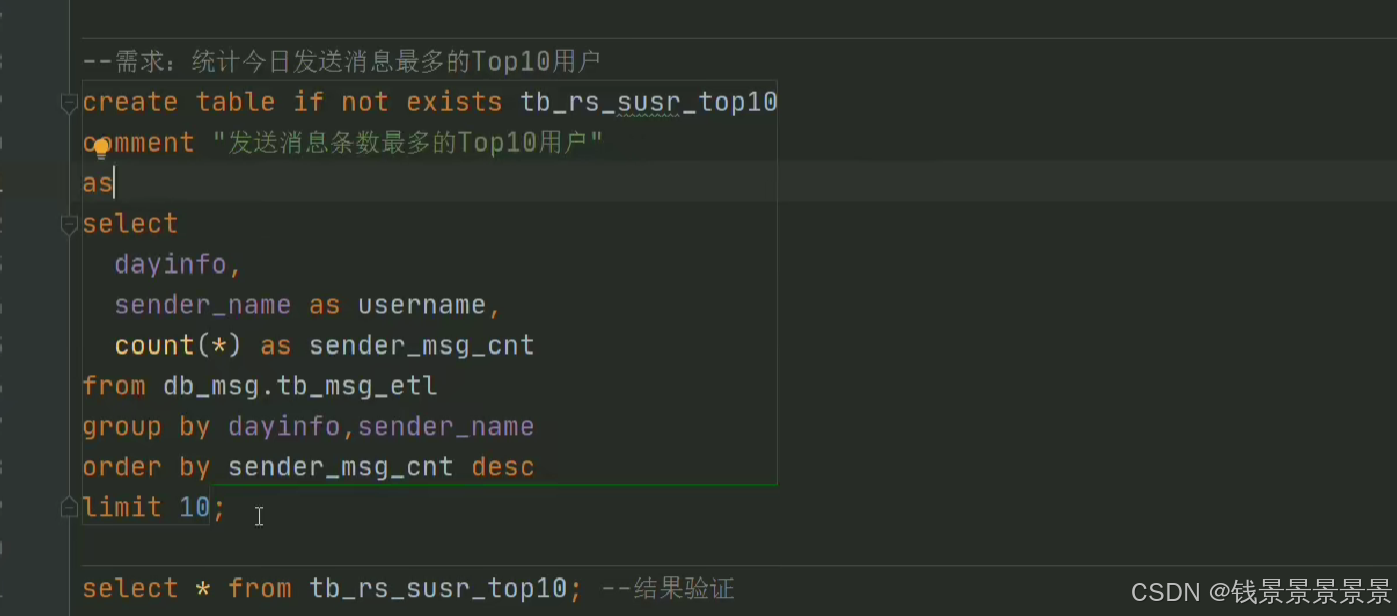
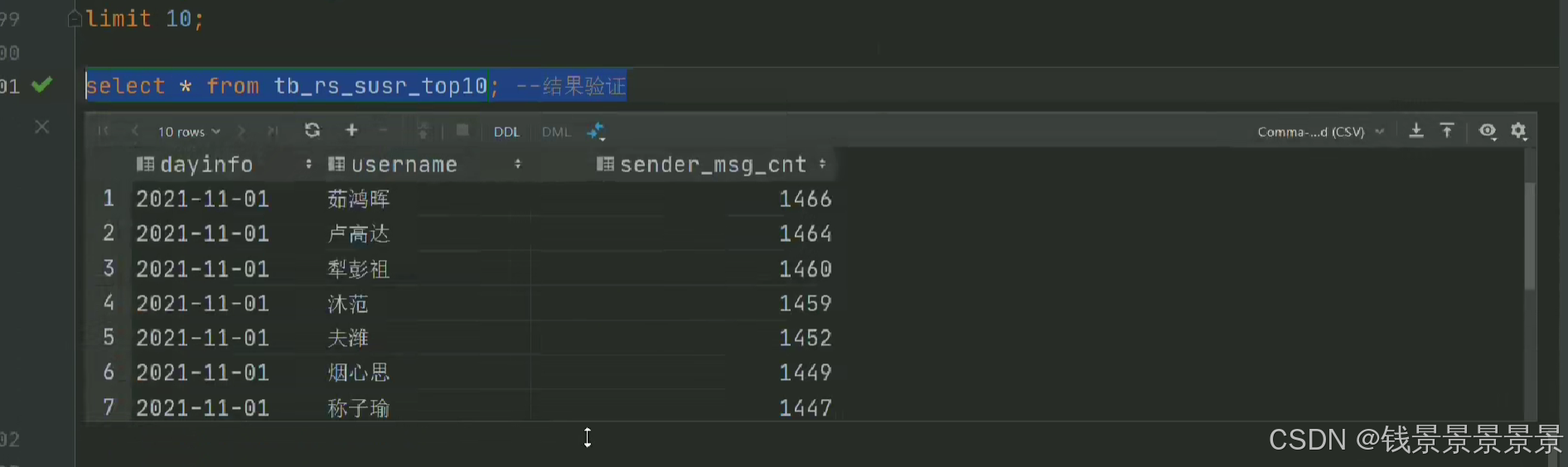
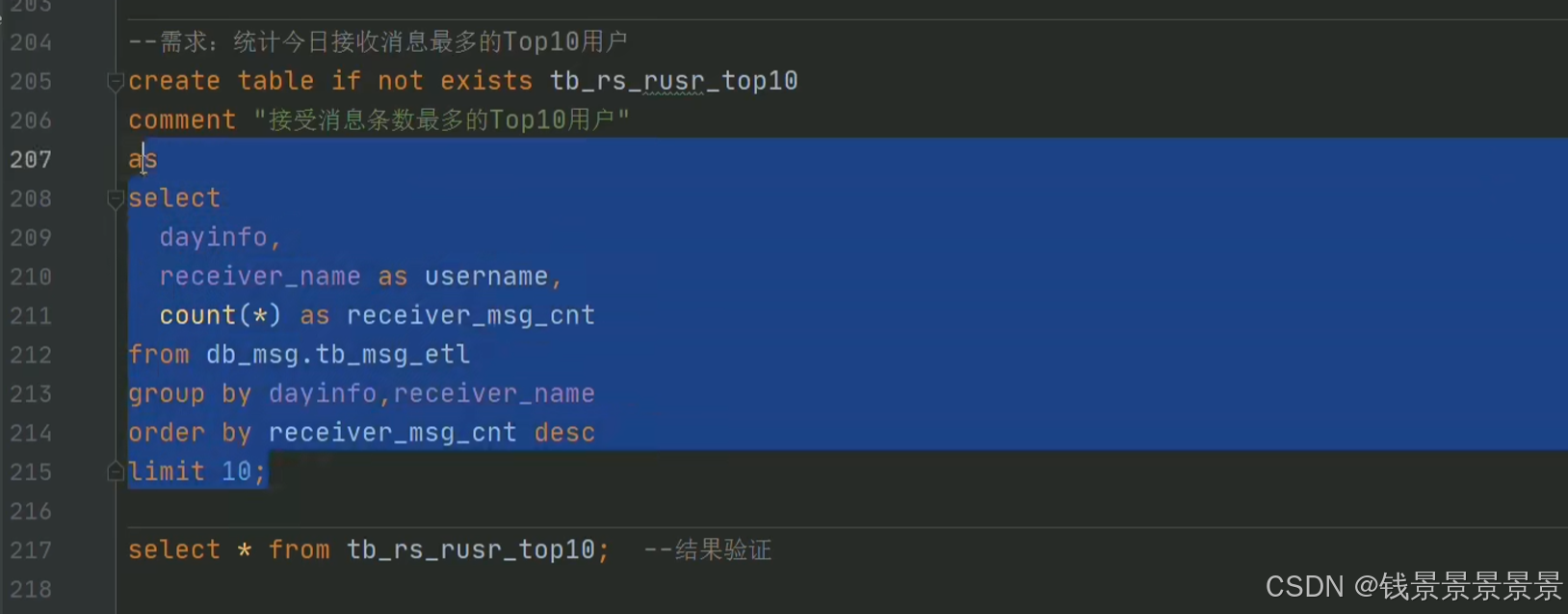
8.基于hive数仓实现需求开发--SQL编写思路与指标计算part3




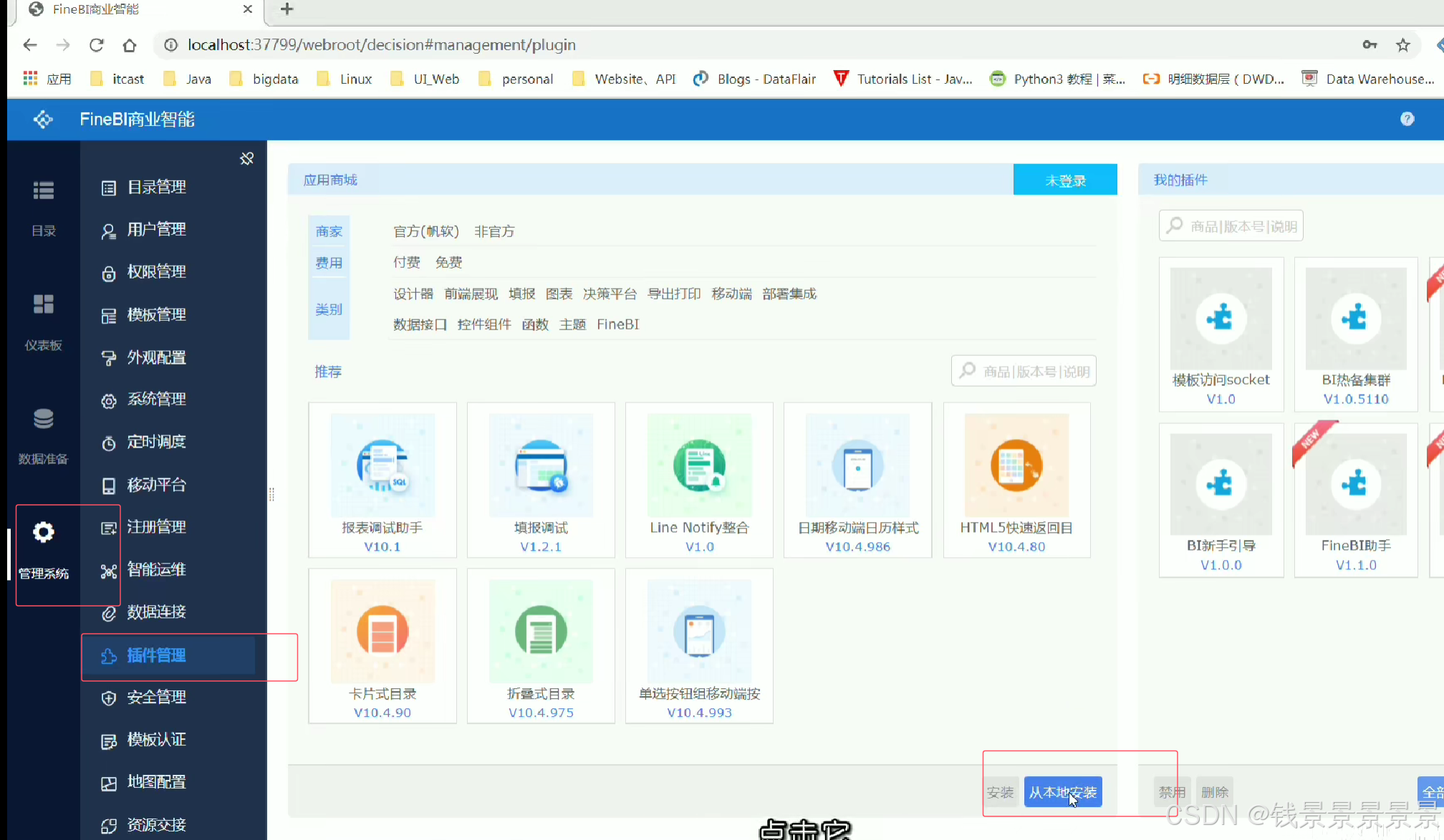
9、基于fineBI实现可视化报表-fineBi介绍与安装

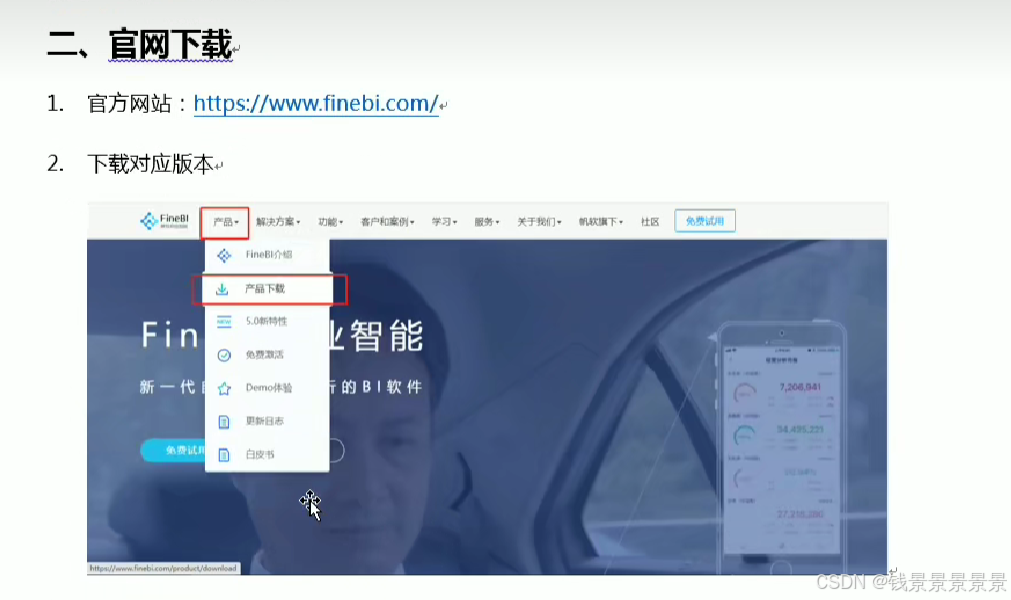
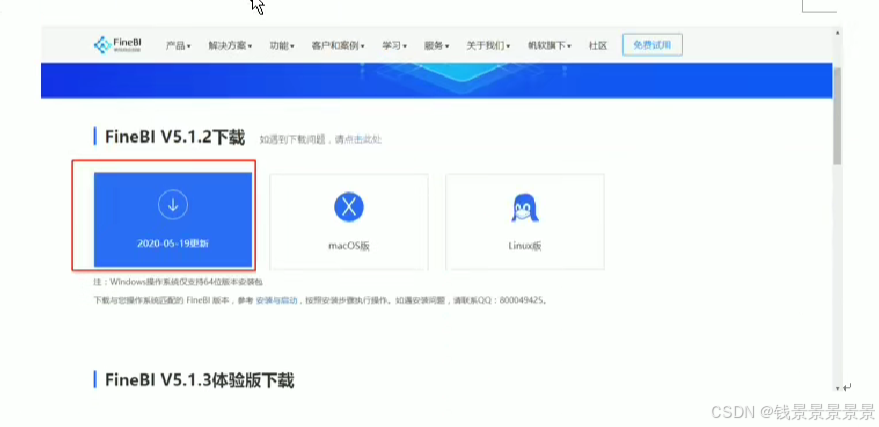
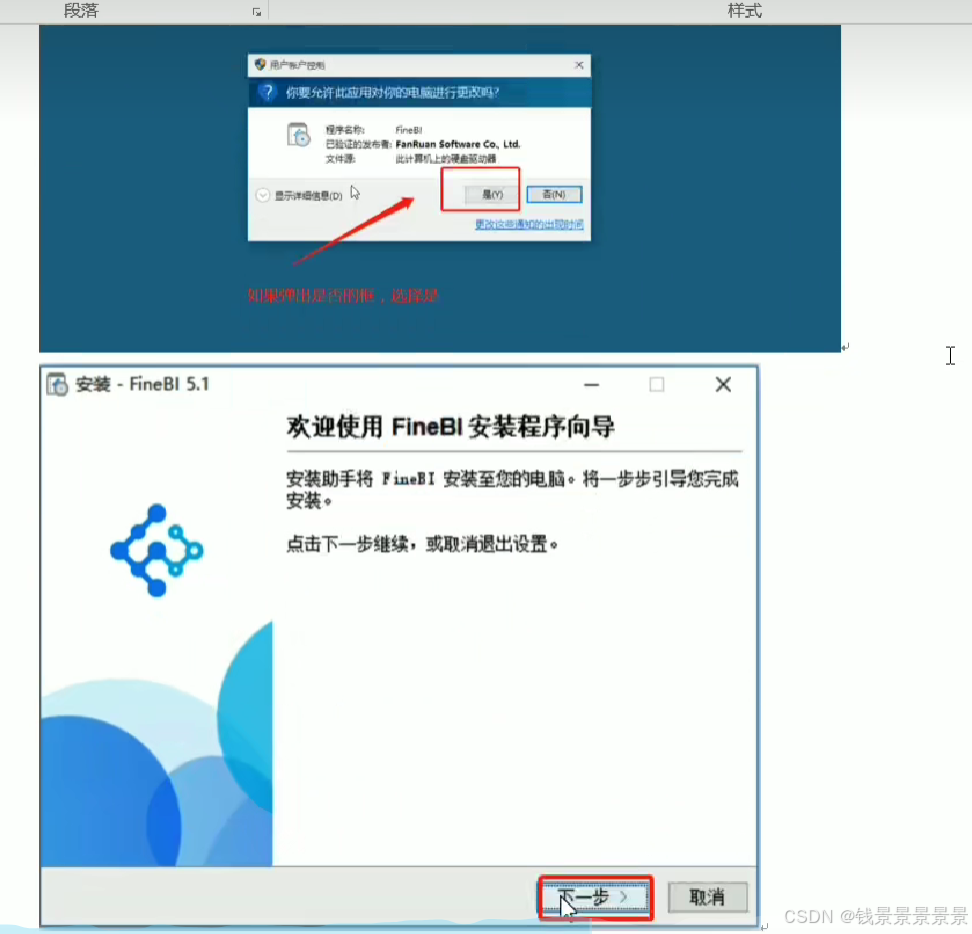
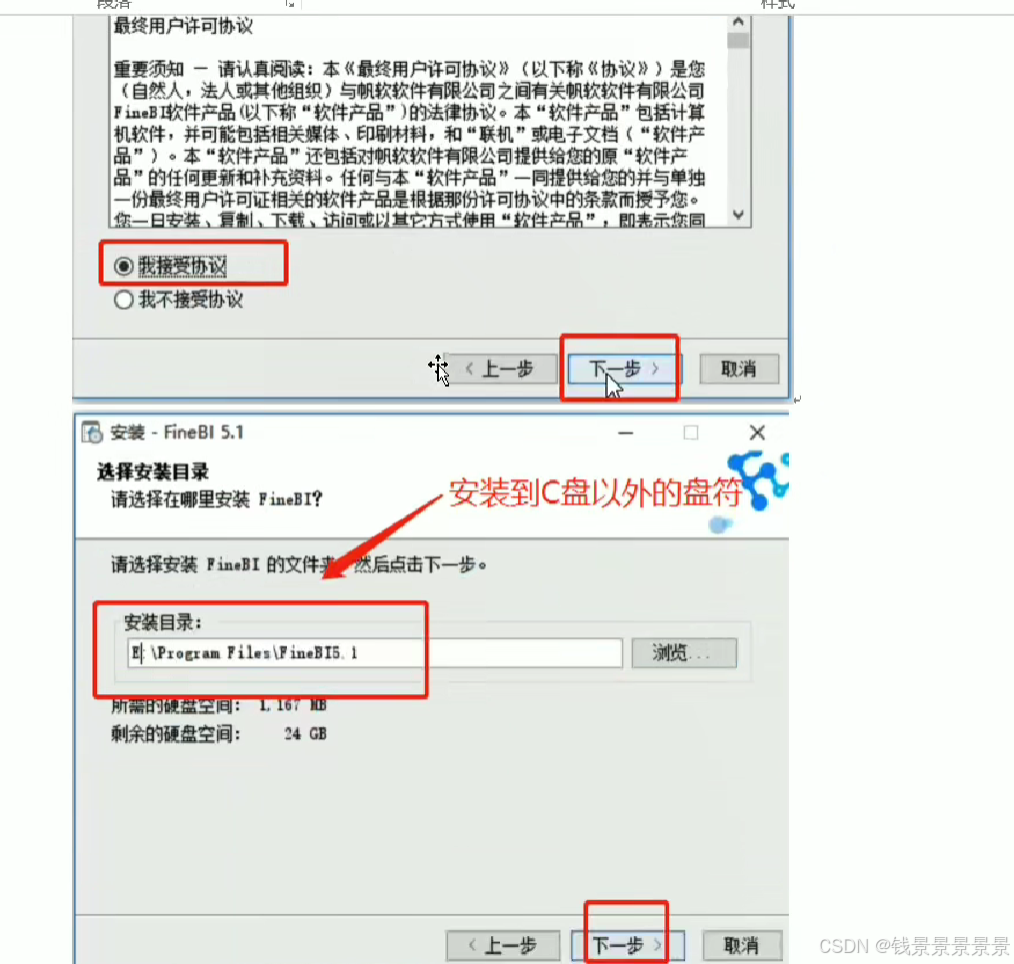
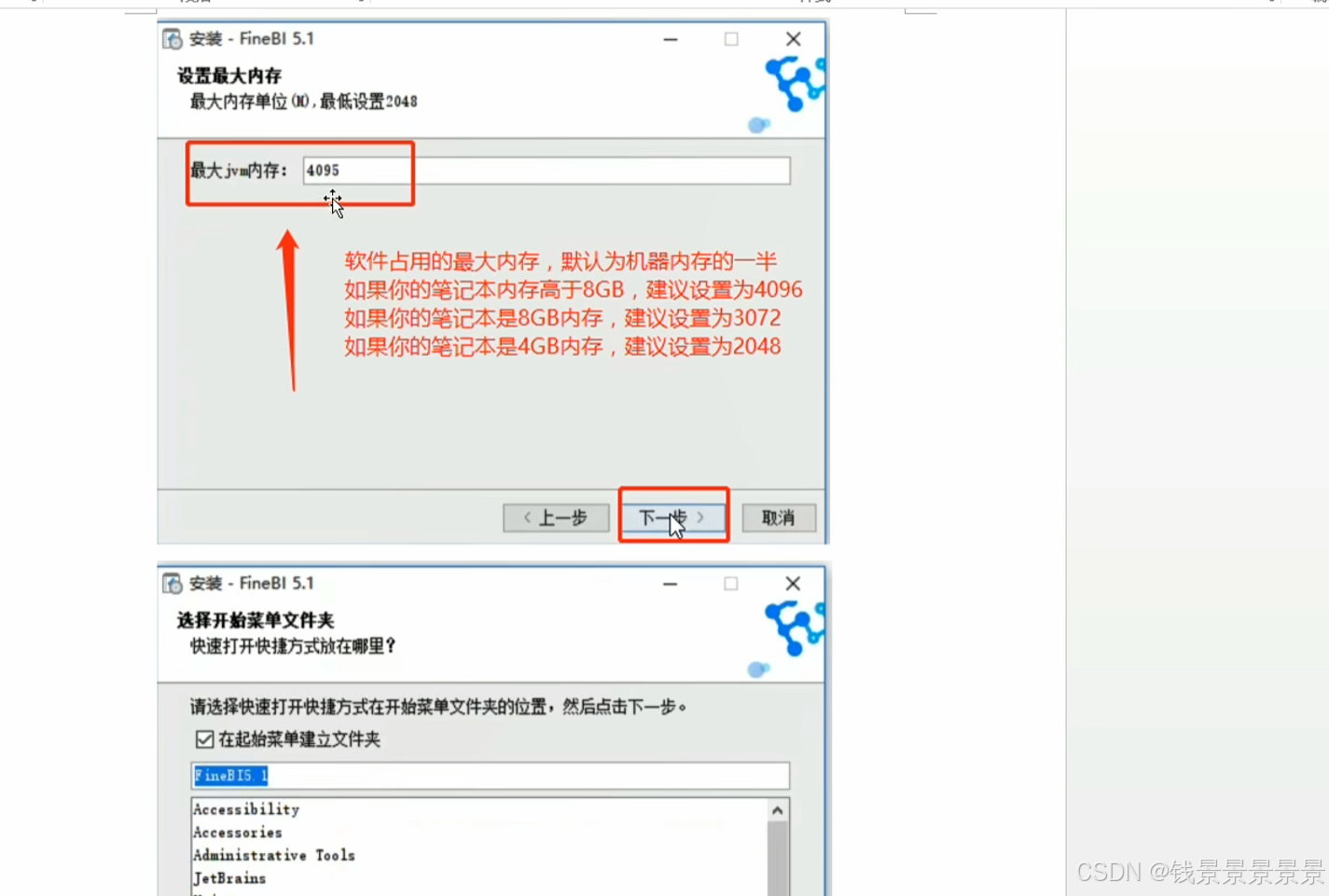
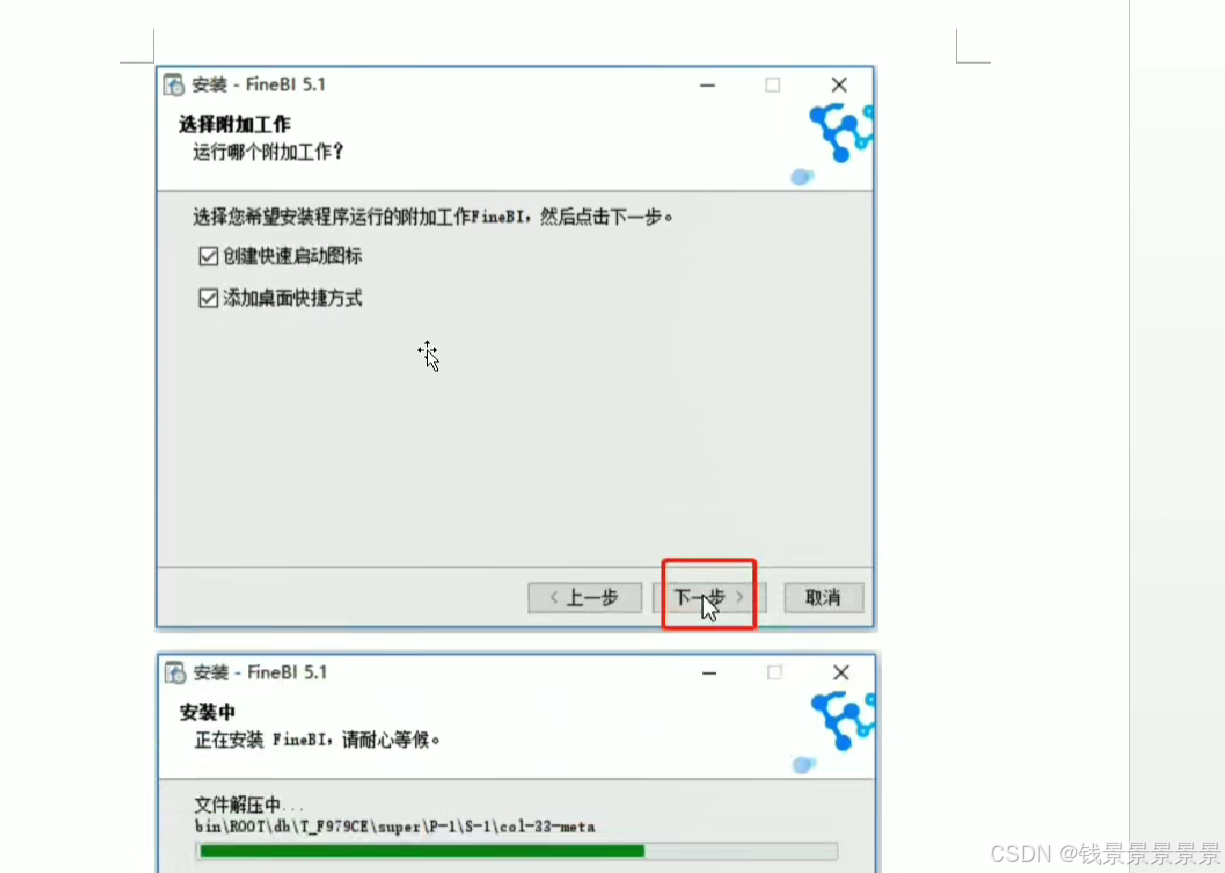
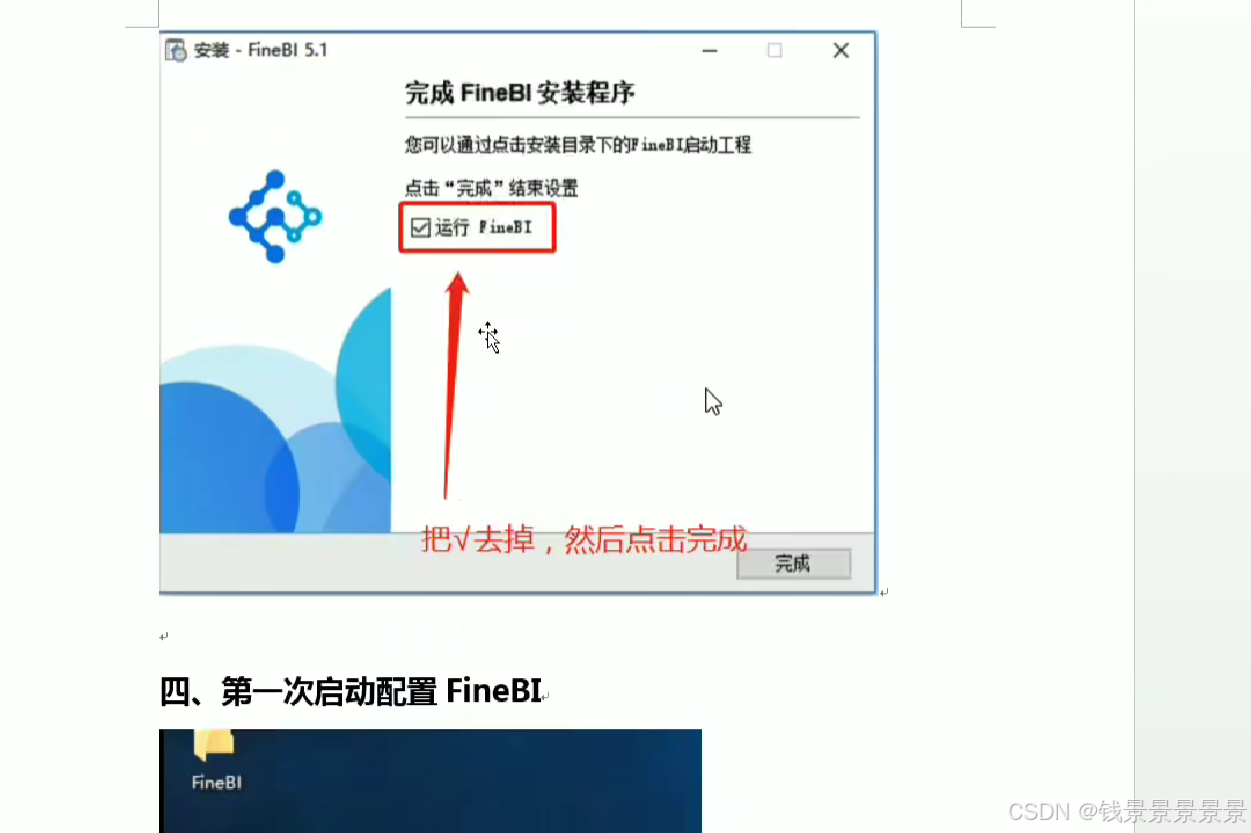

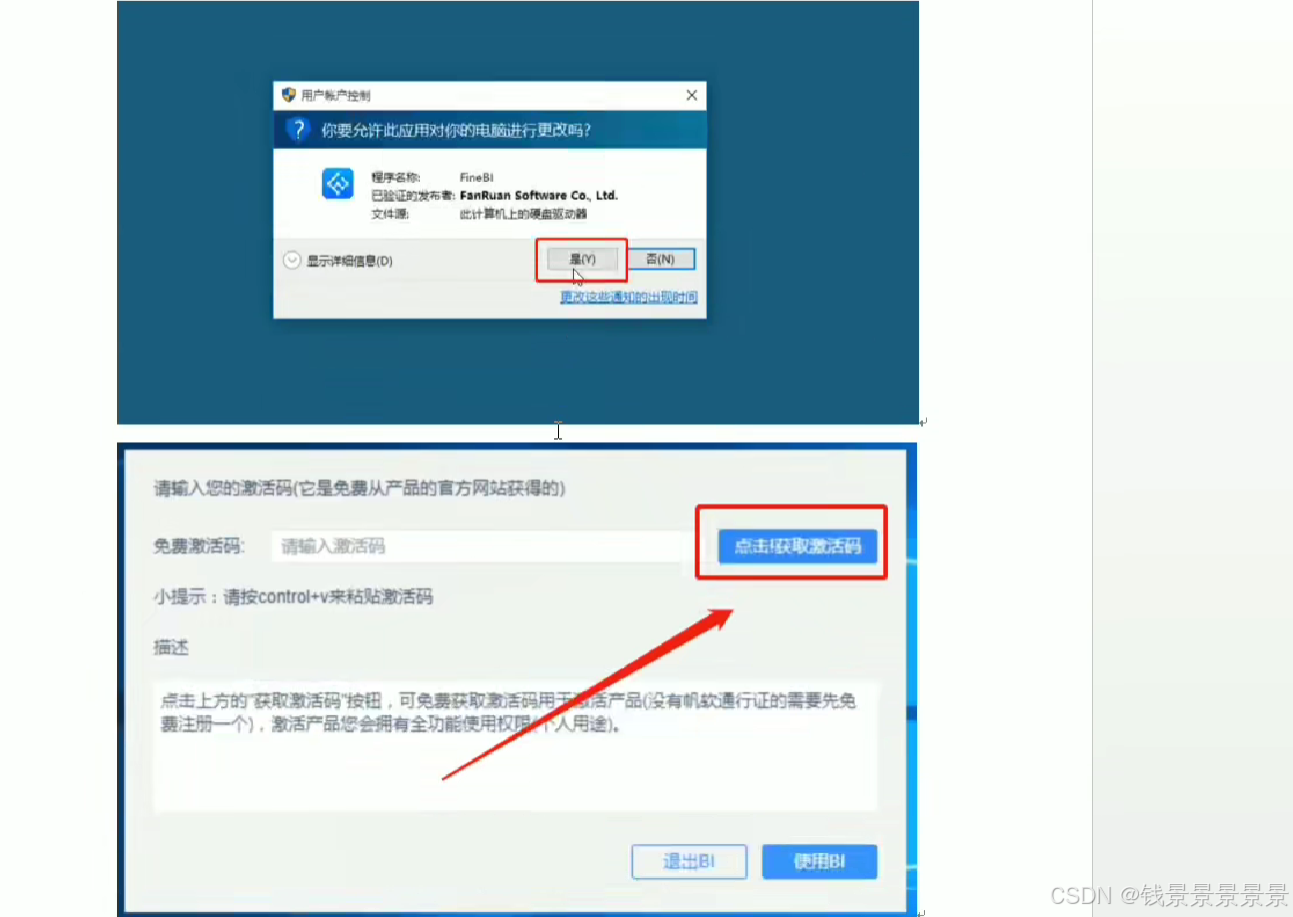
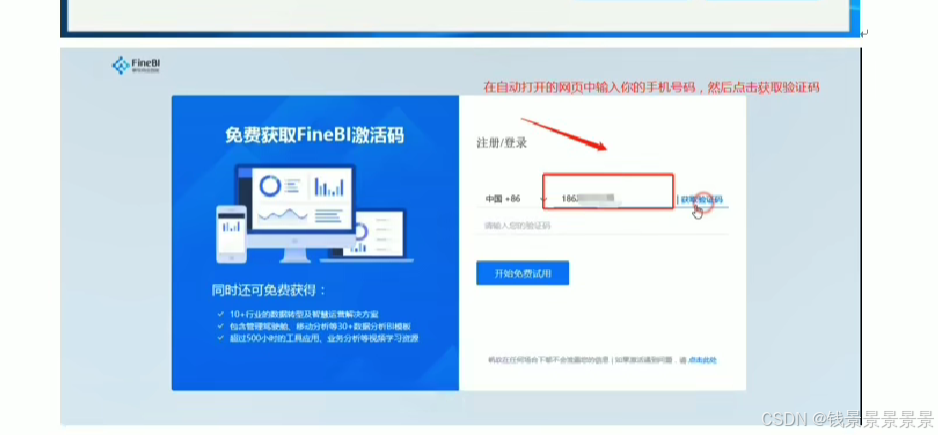

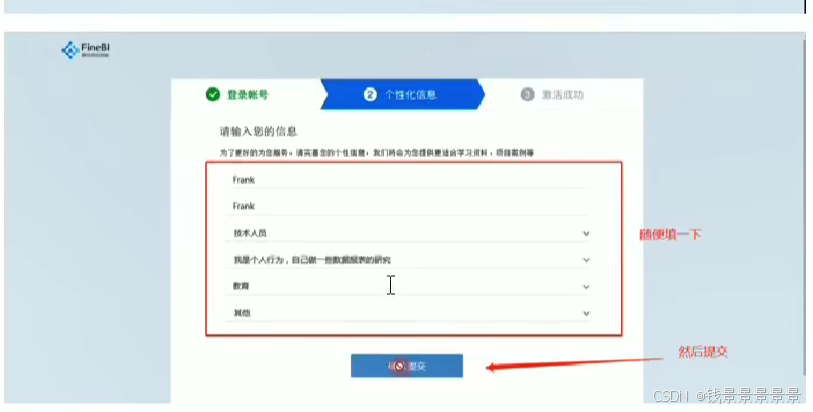
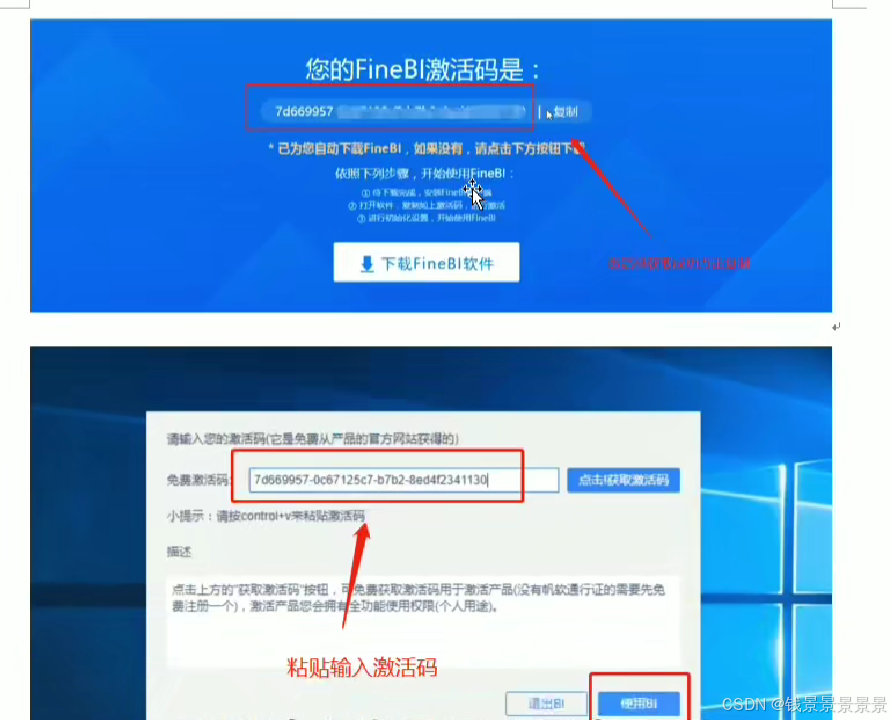
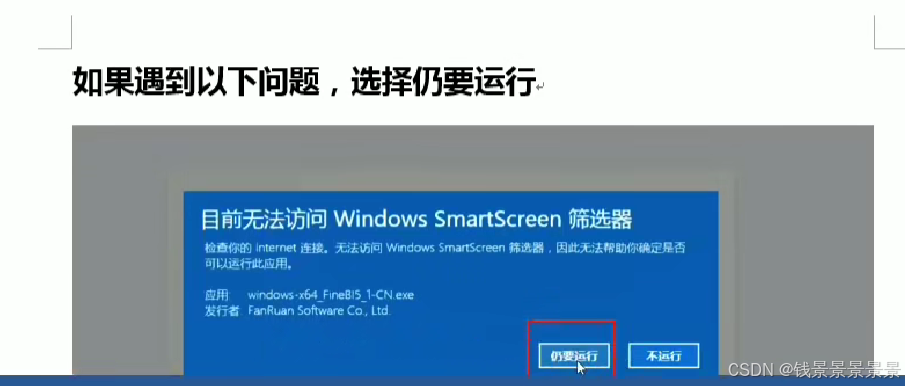
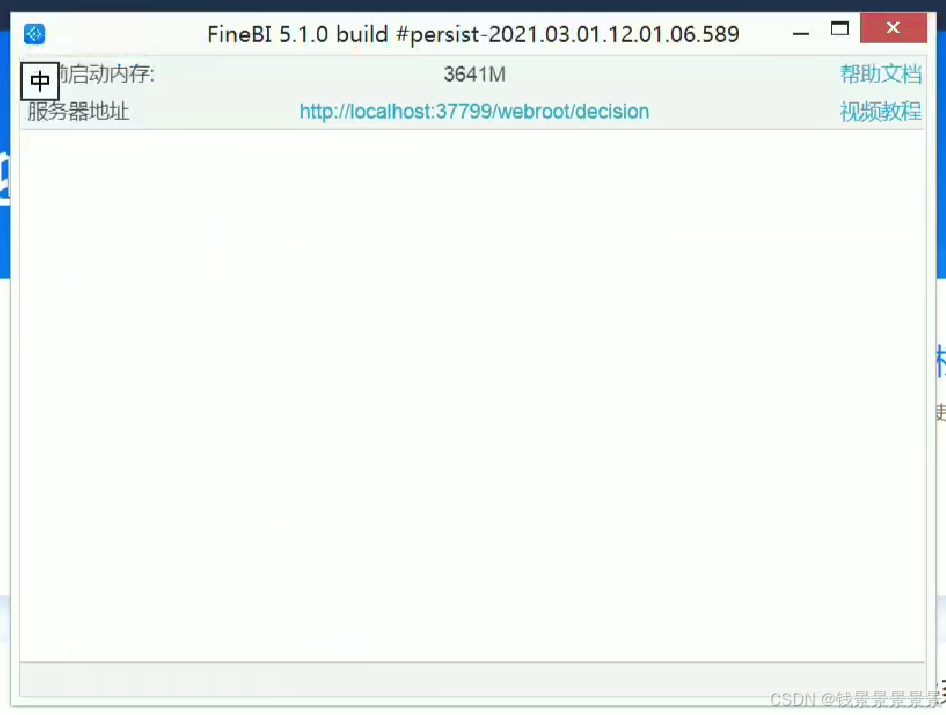
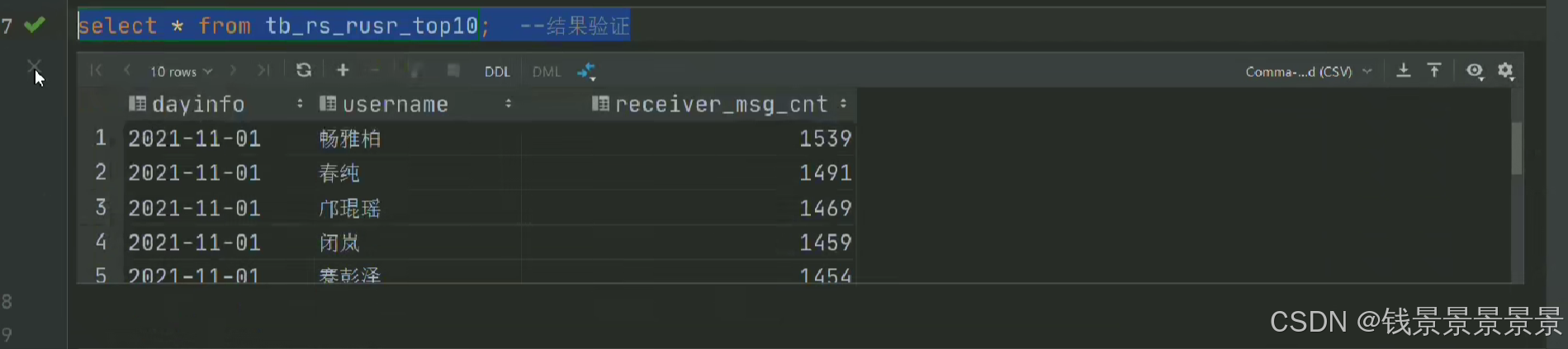
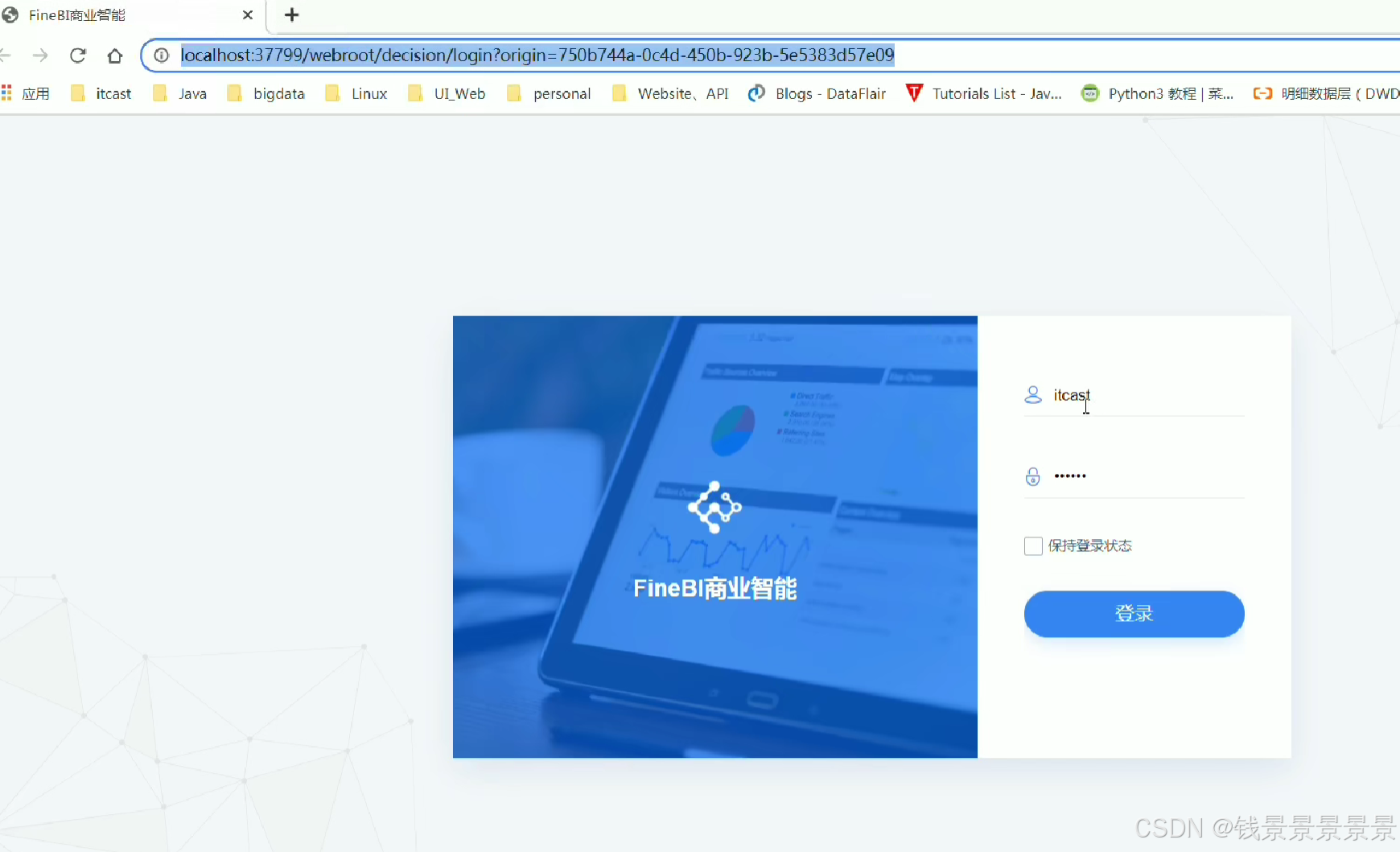
这里的登入提供了上面的服务器
登入在网页中进行
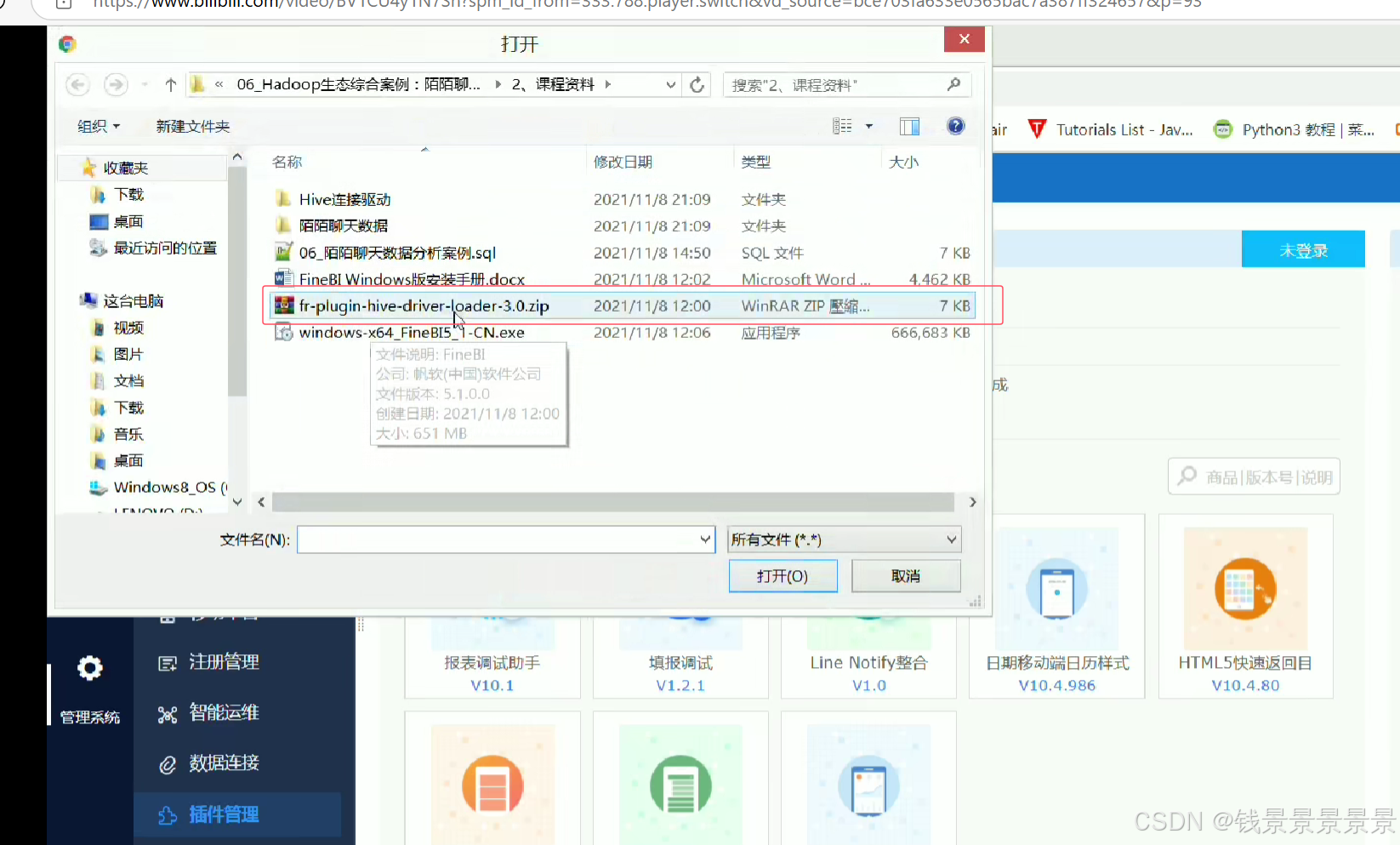
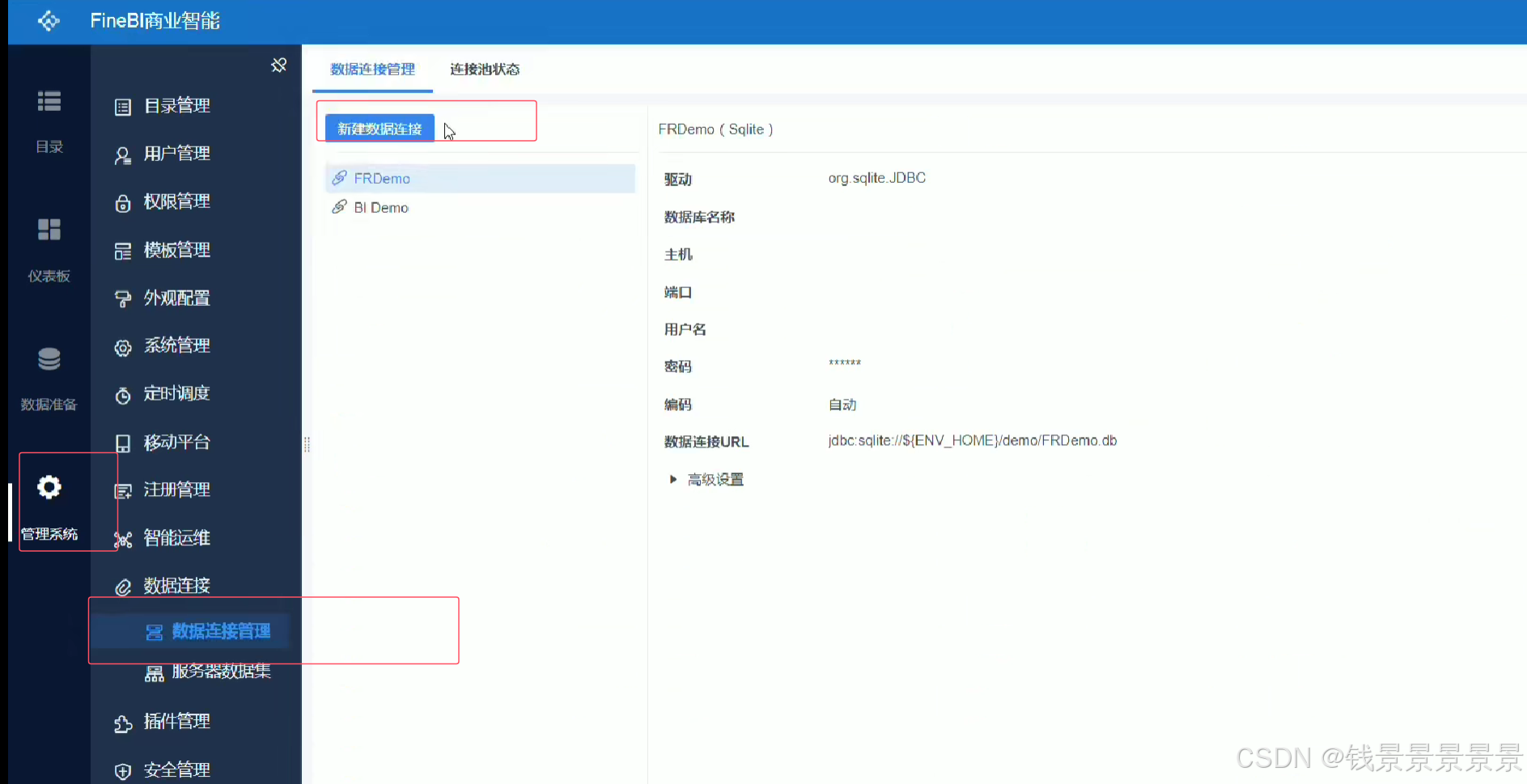
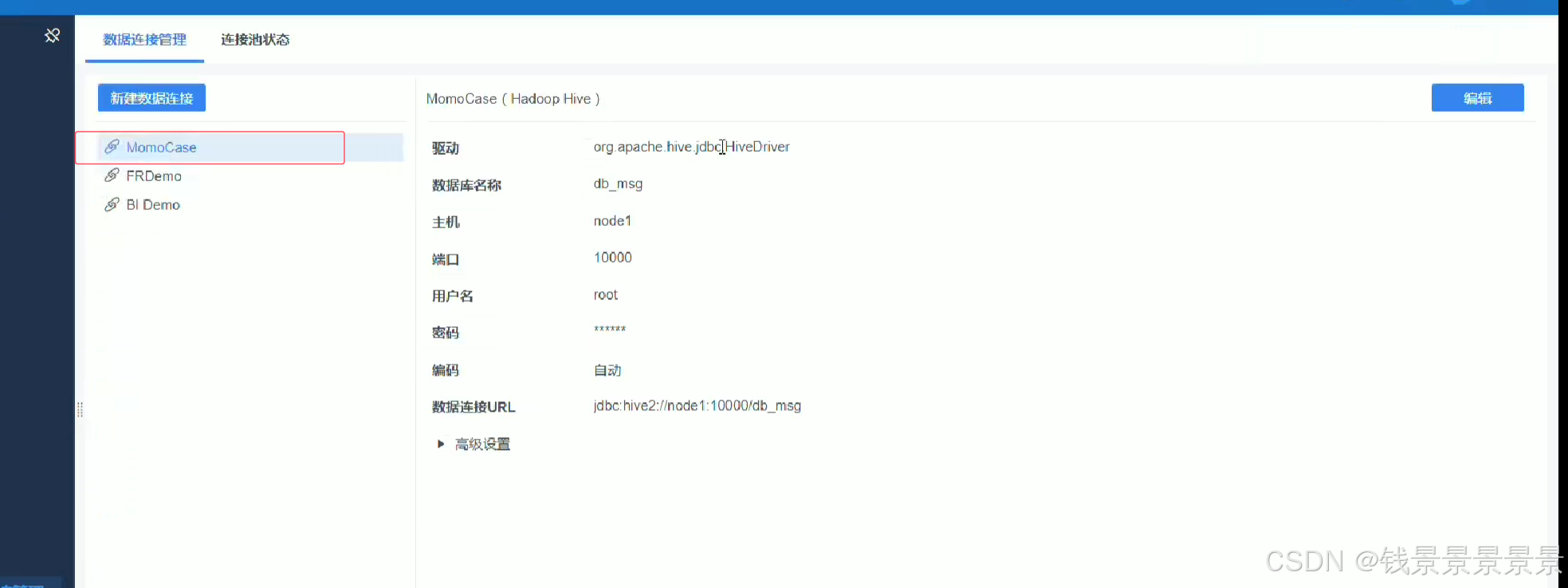
10.基于fineBI实现可视化报表-配置数据源和数据准备


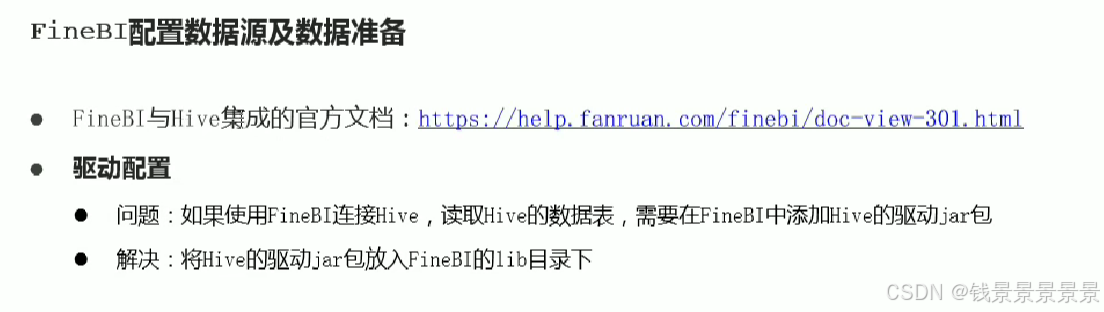
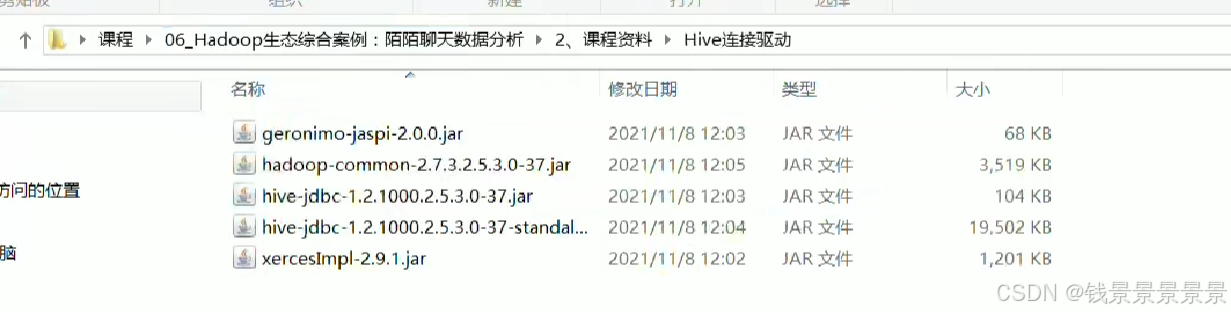
首先是hive驱动
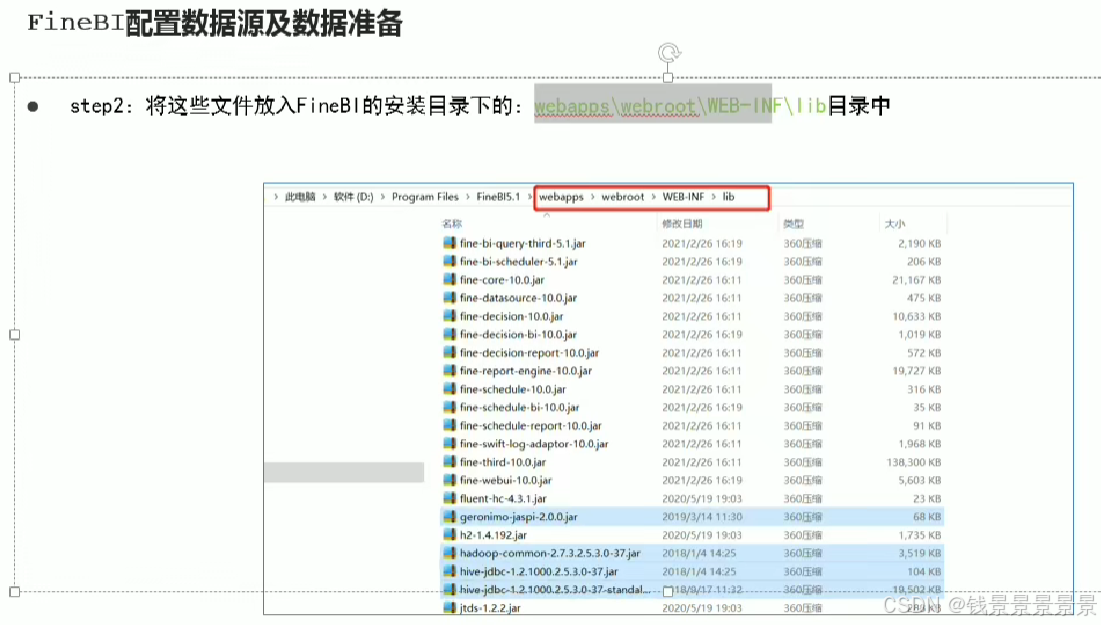

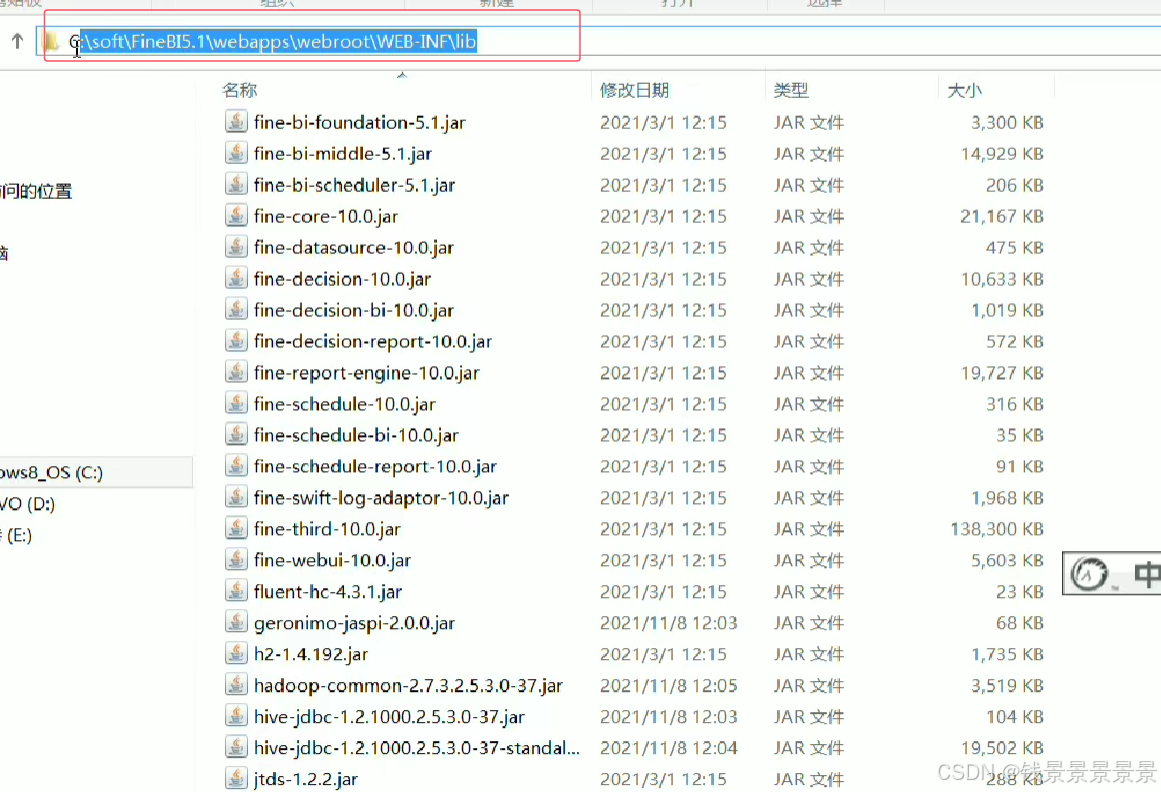

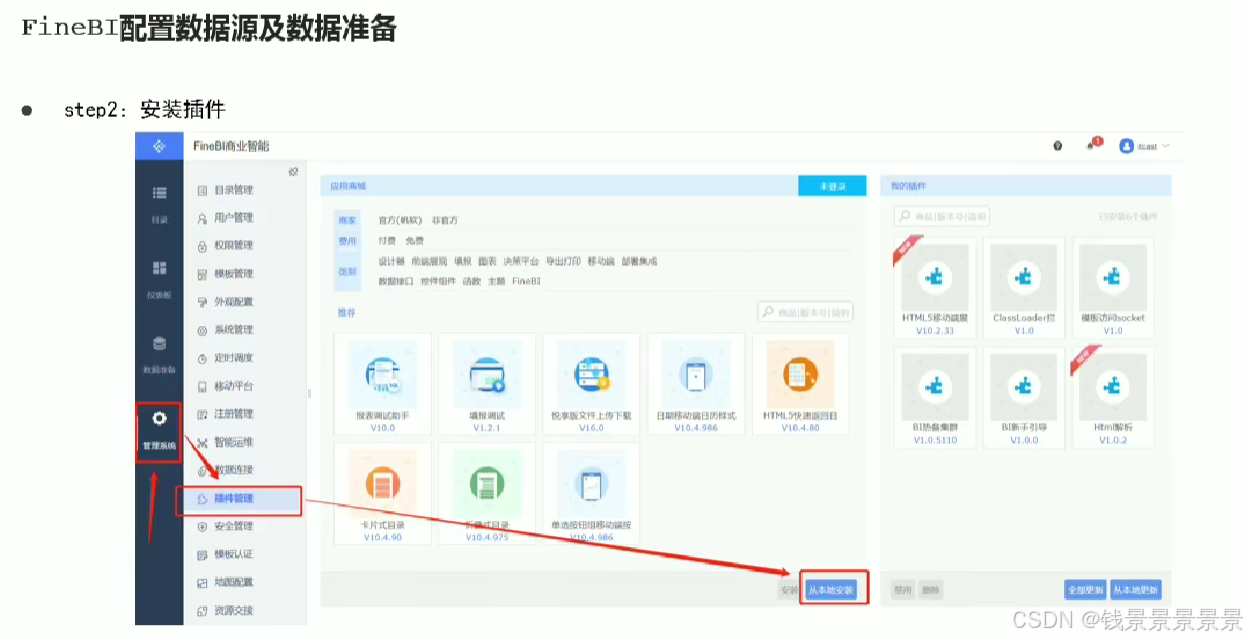
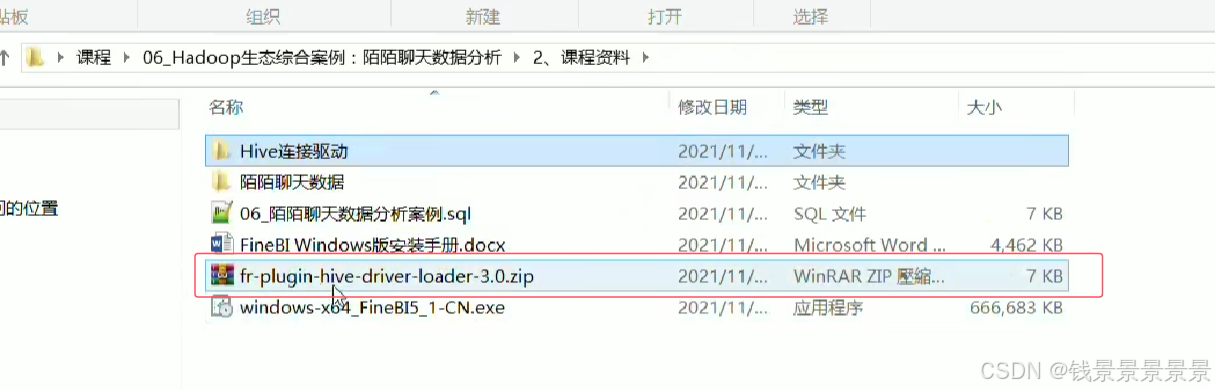
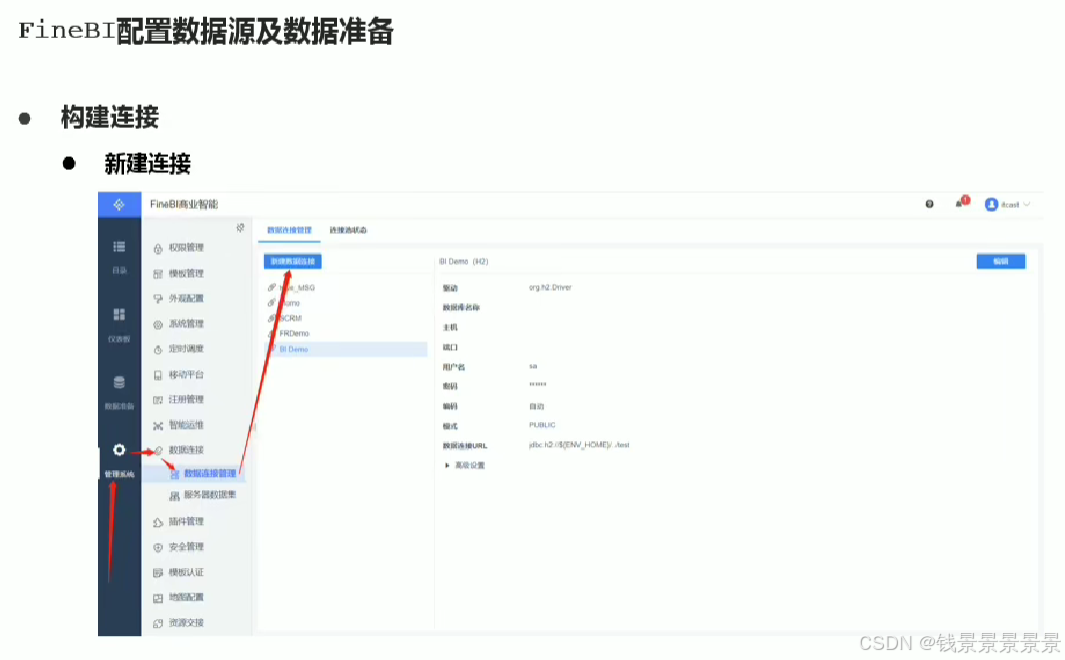
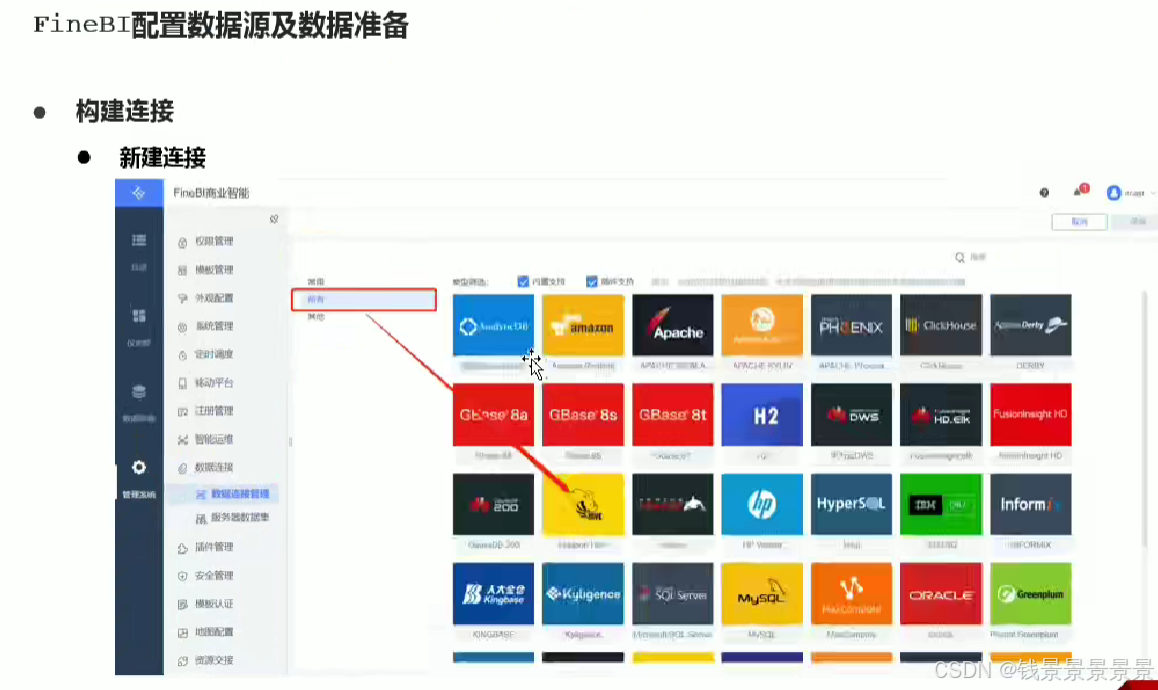
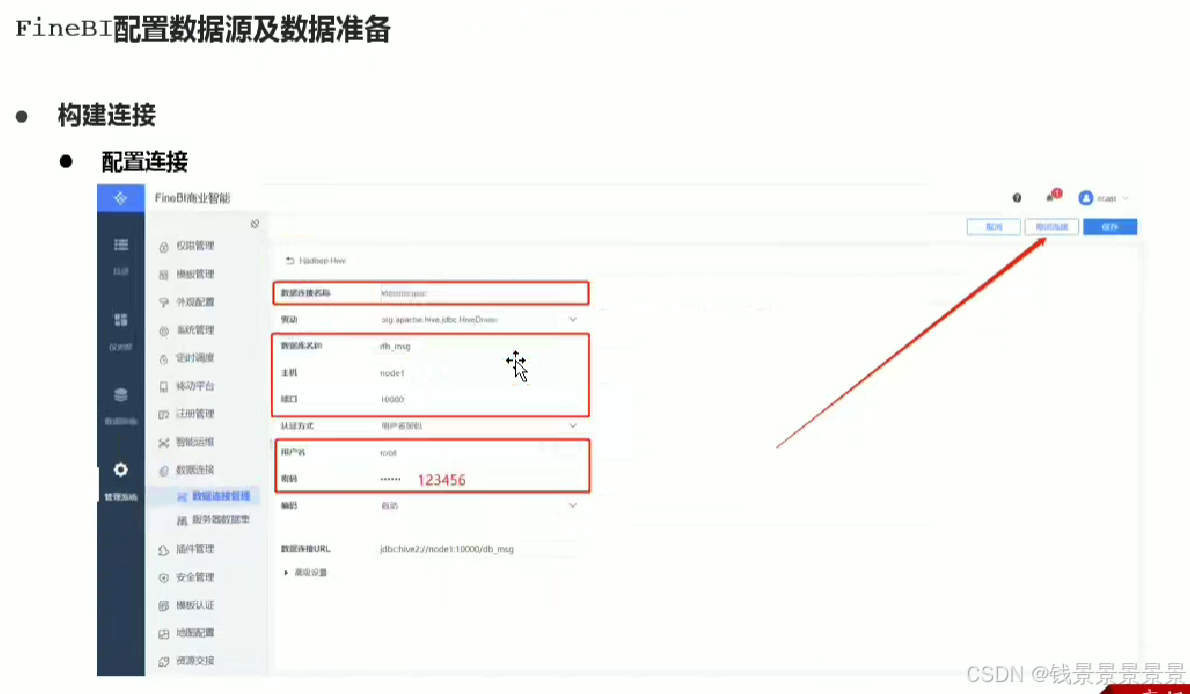
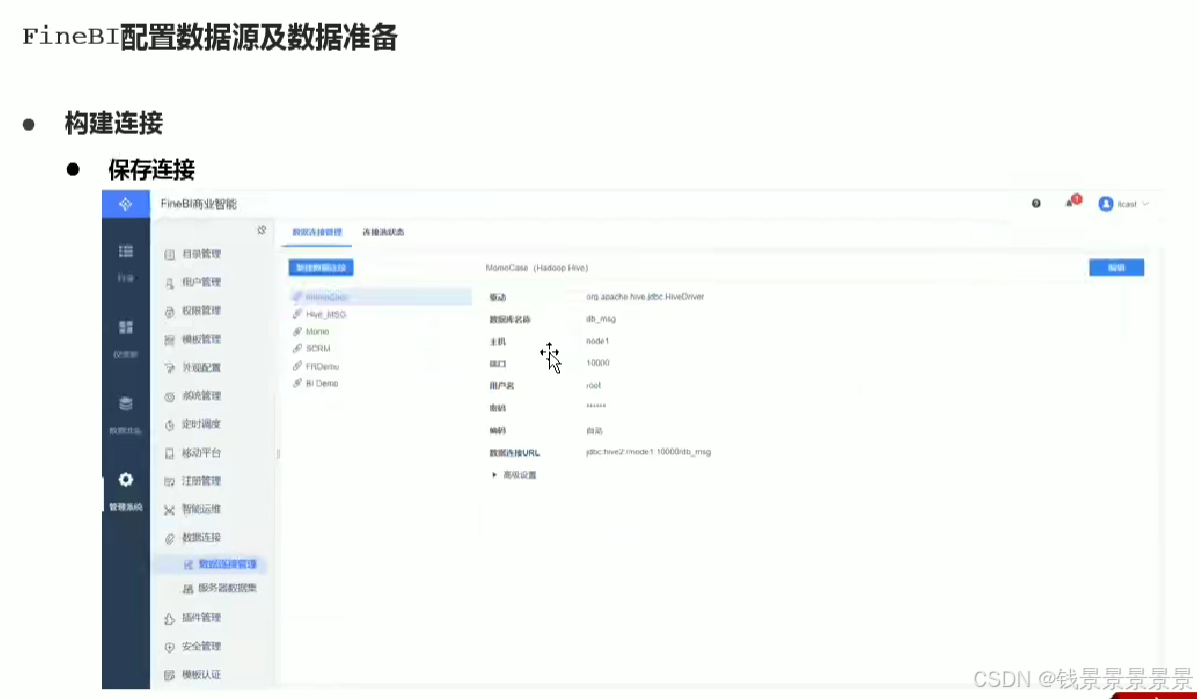

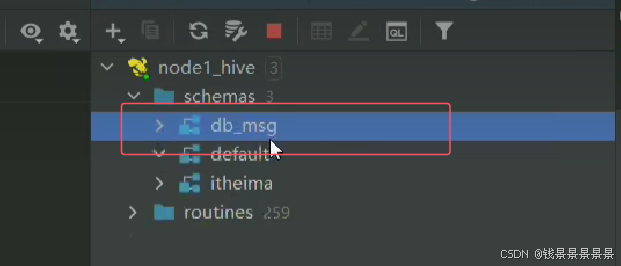
这是数据库名字
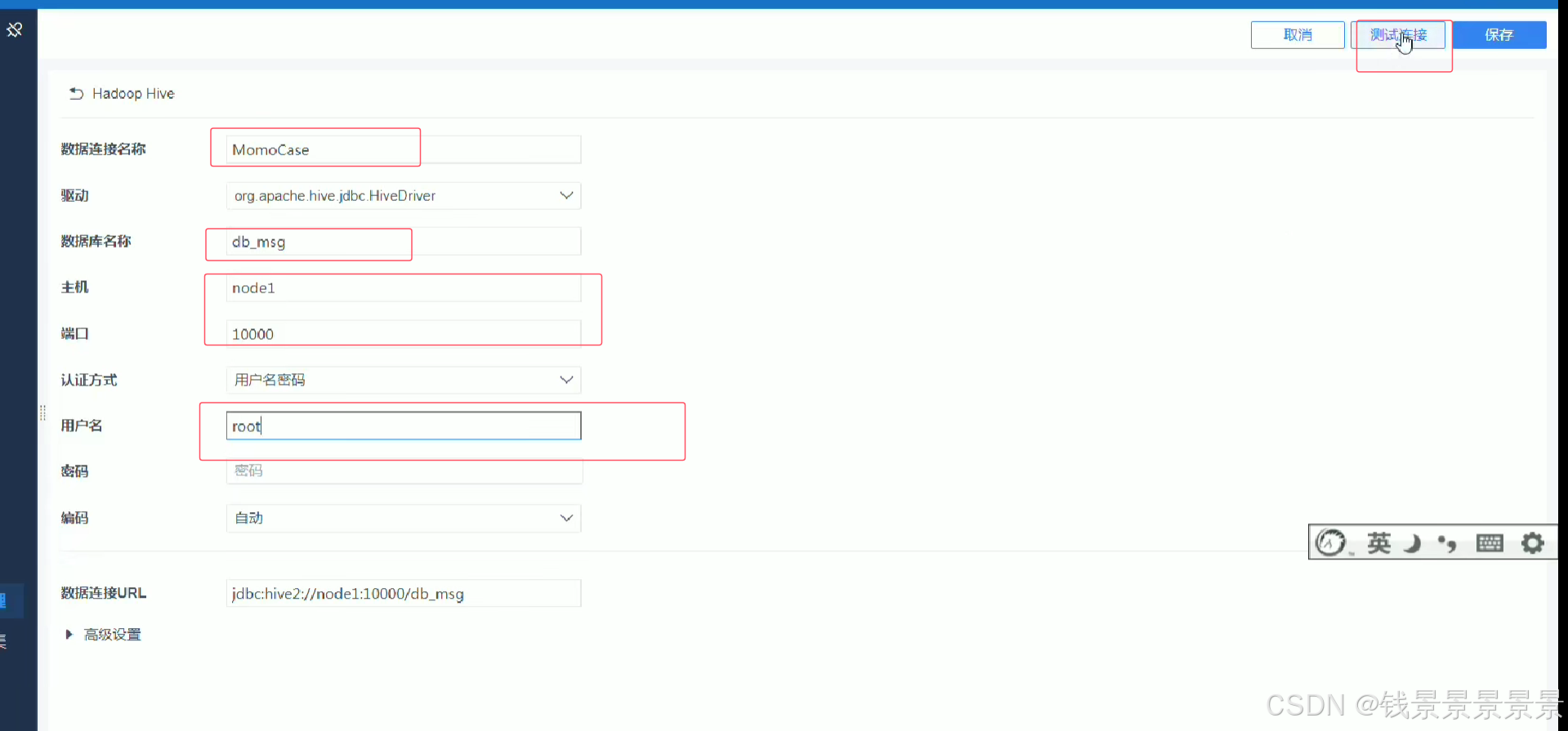
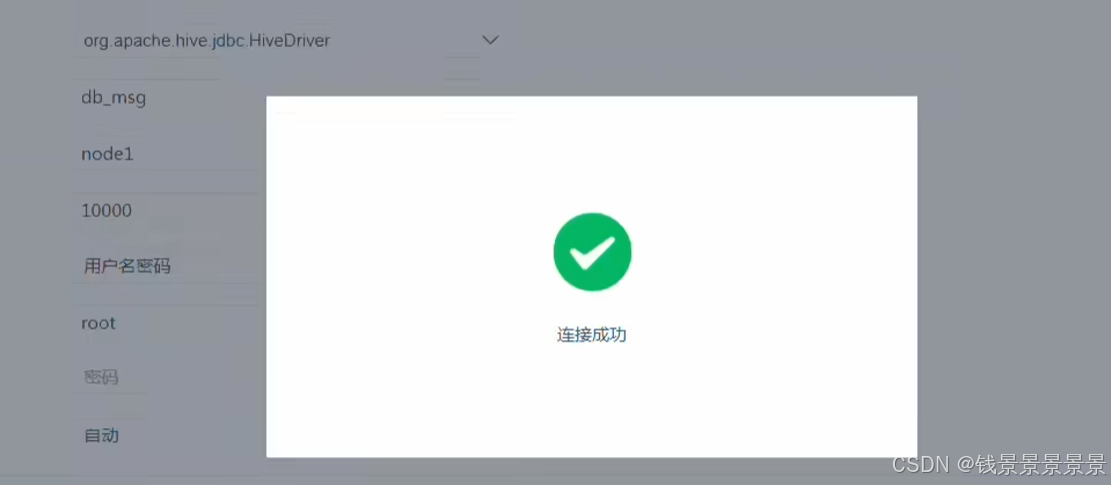
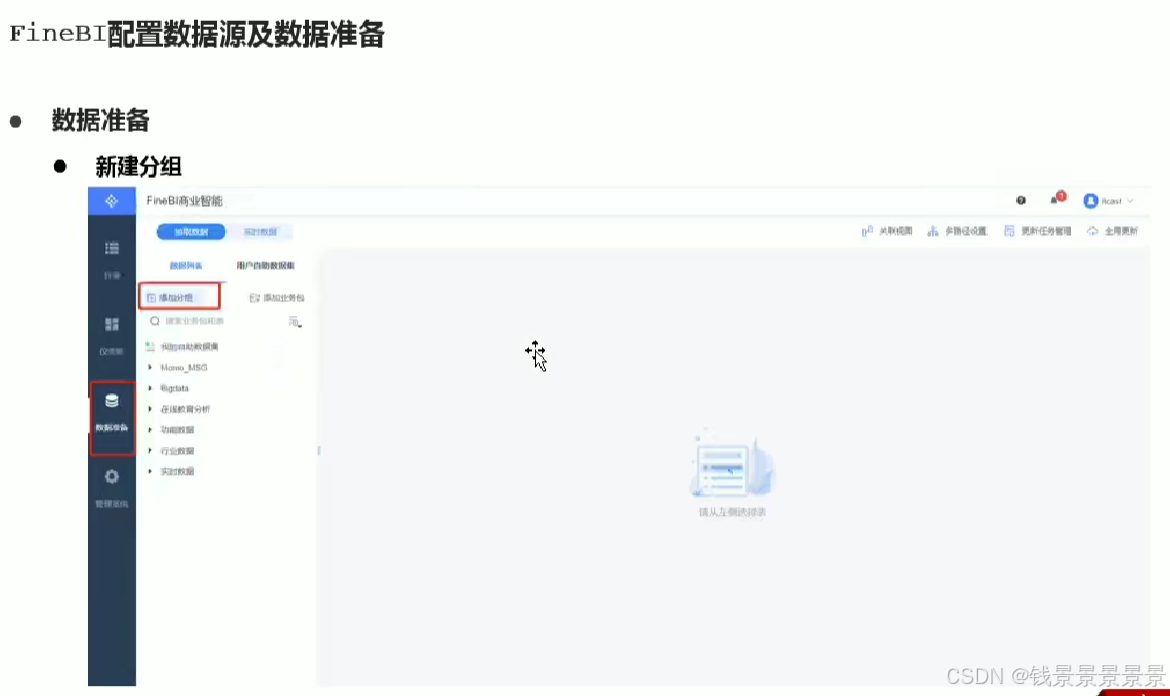
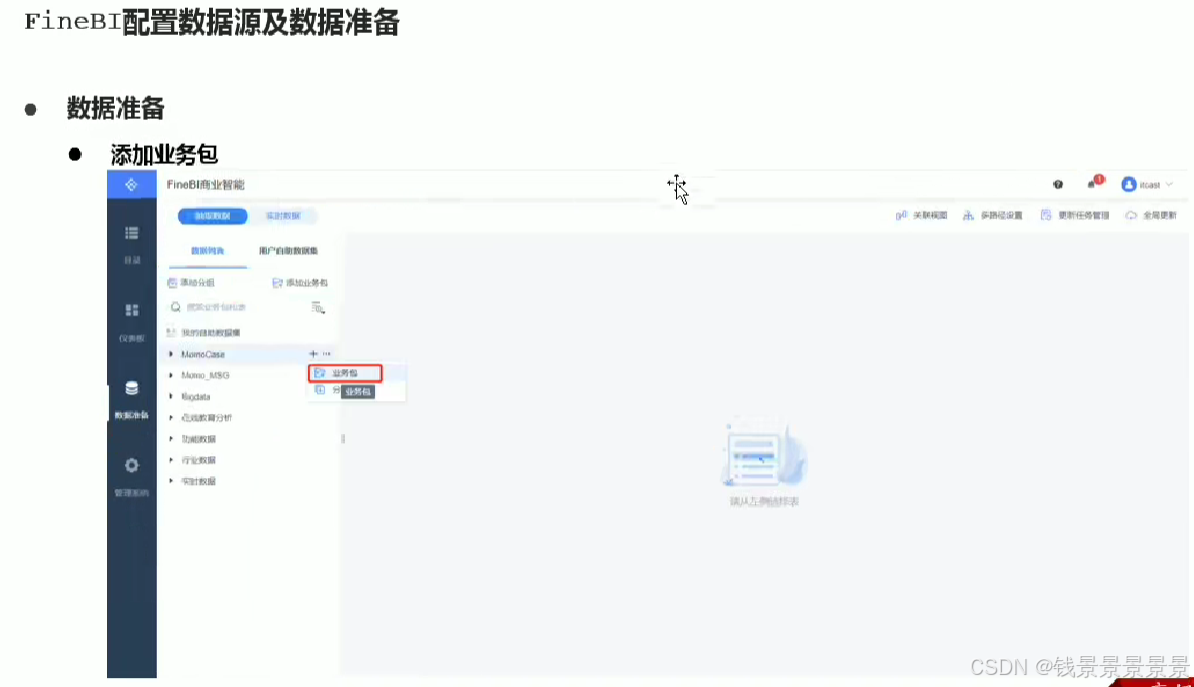
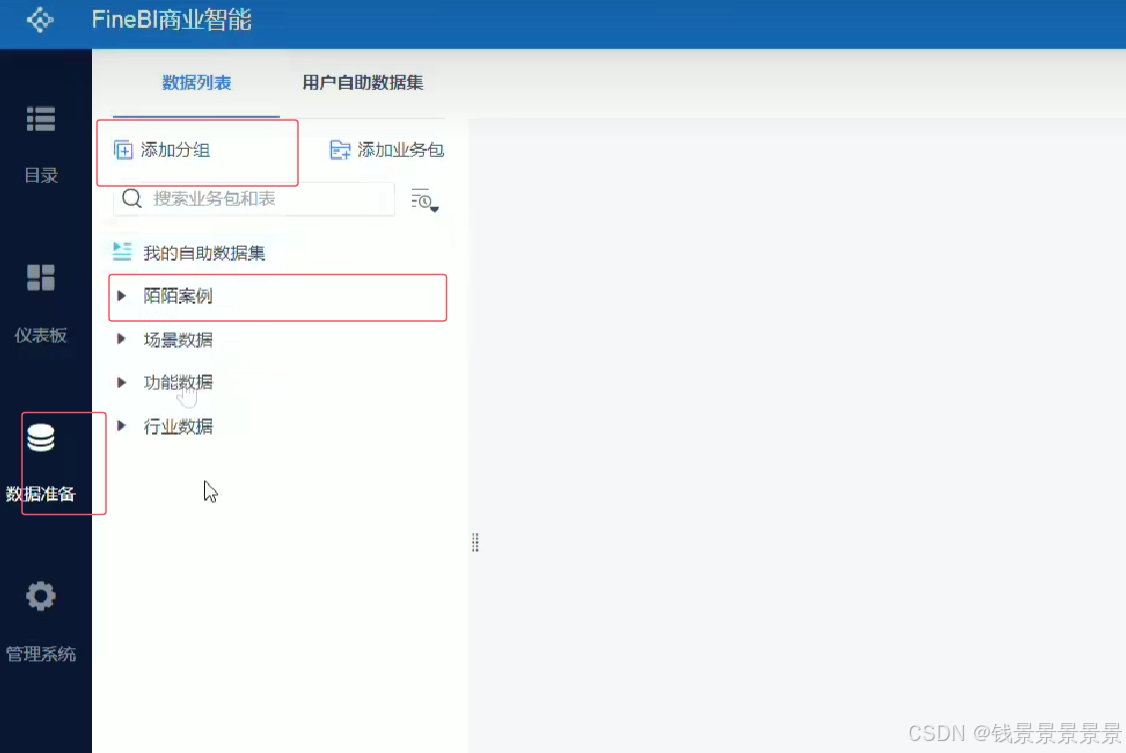
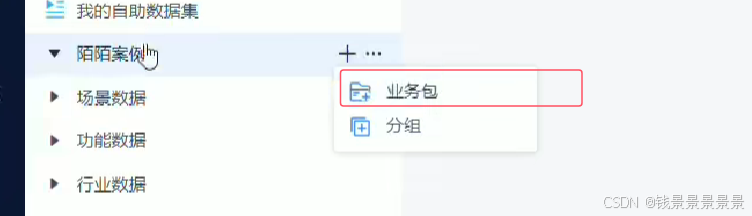
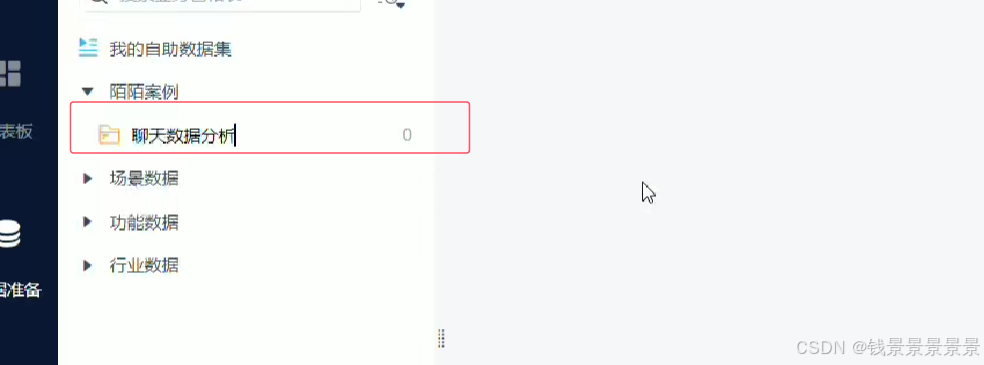
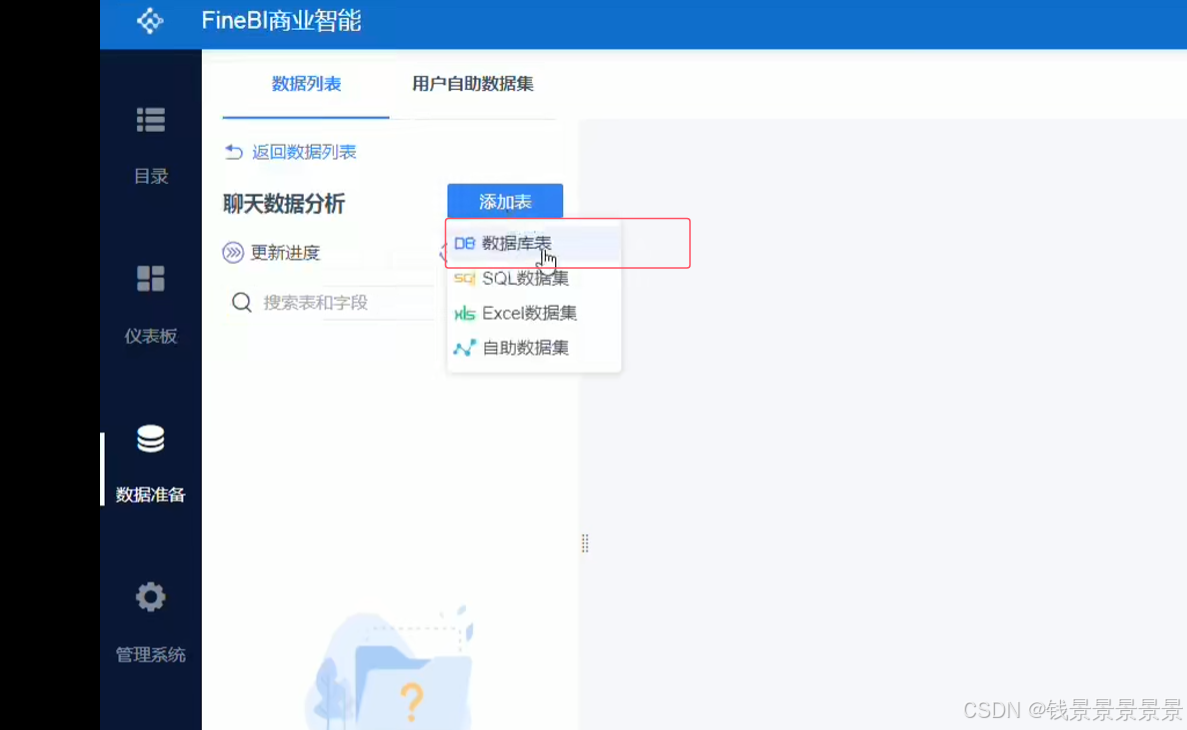
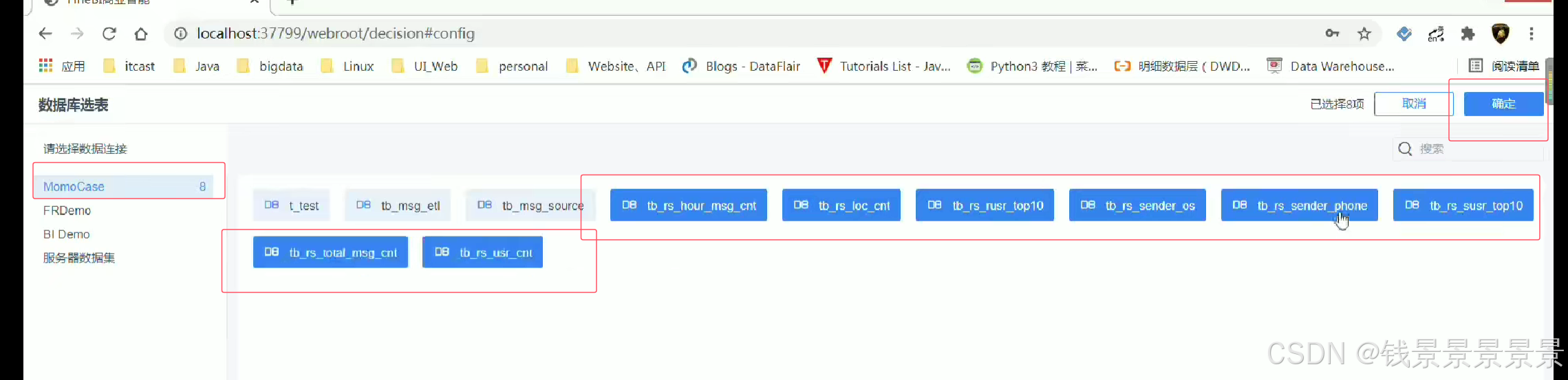
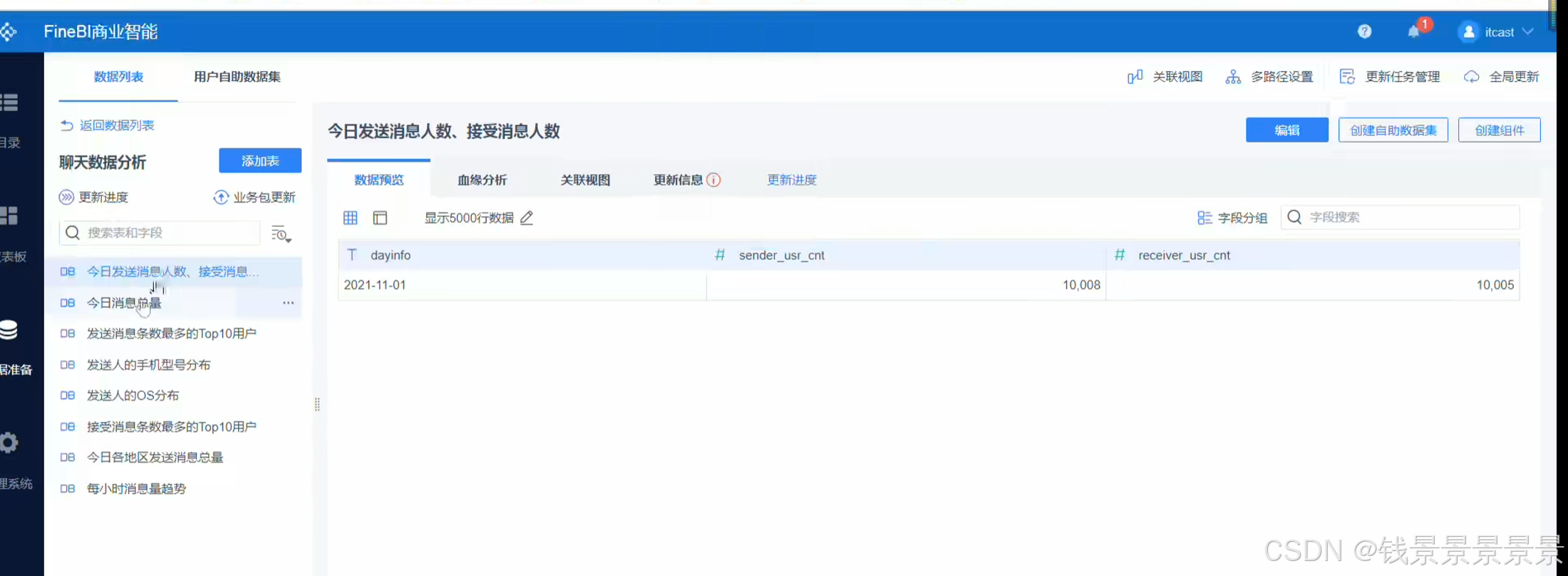
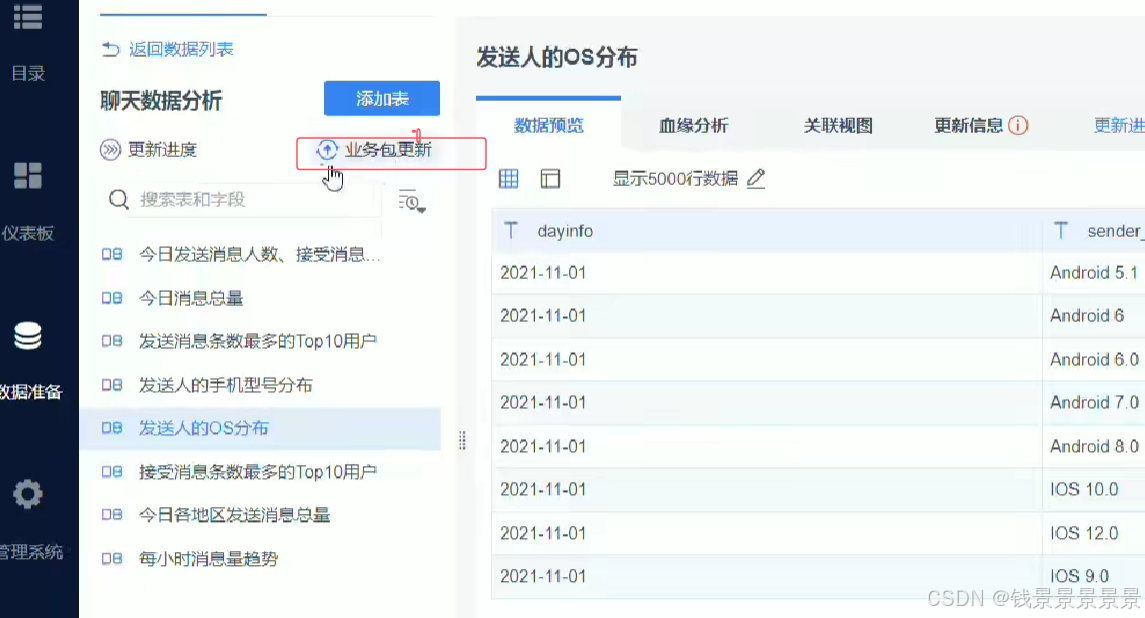
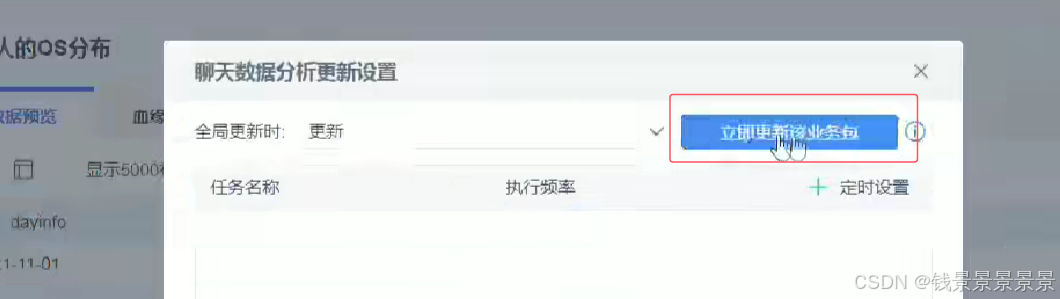
如果要更新的话
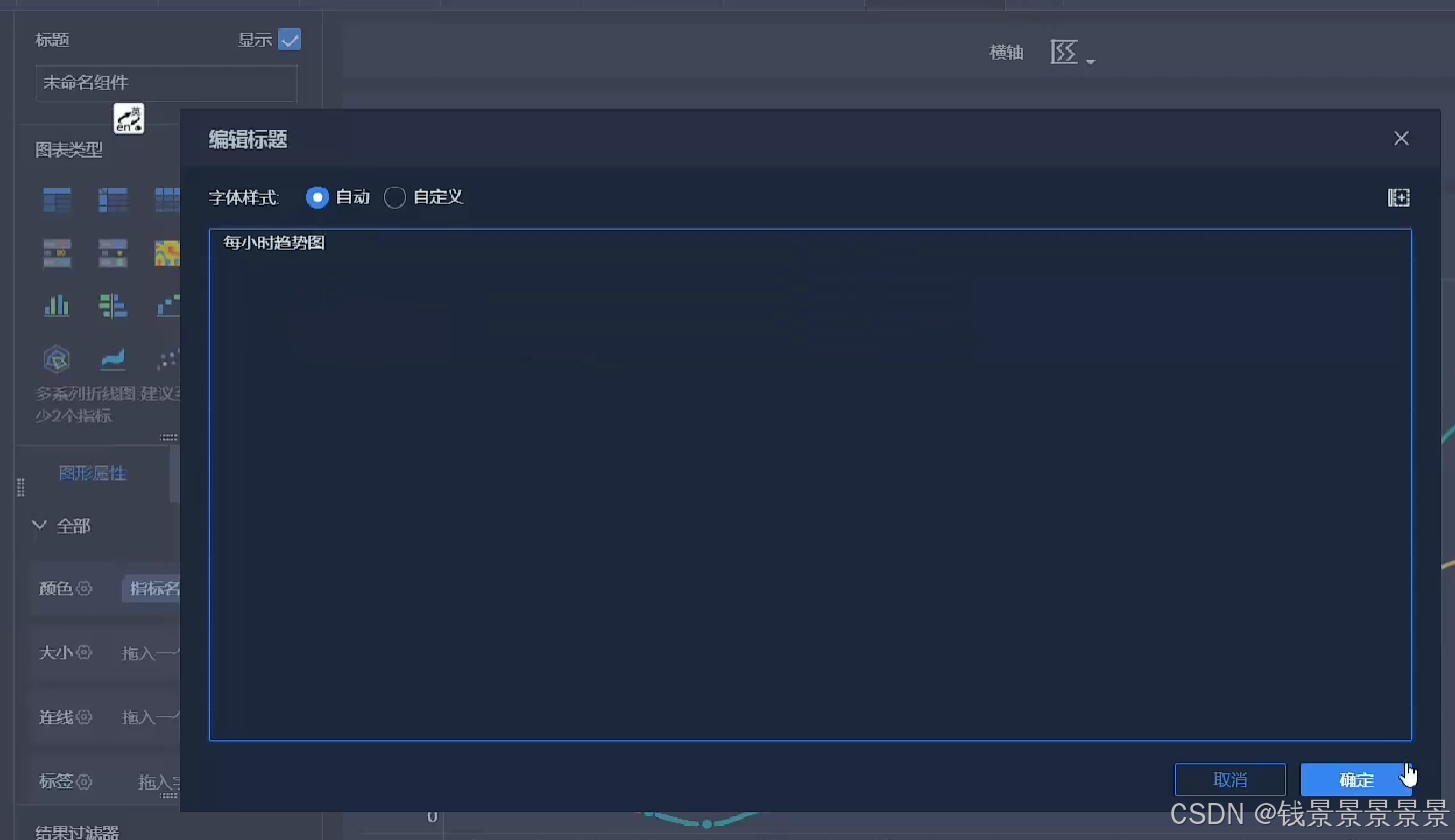
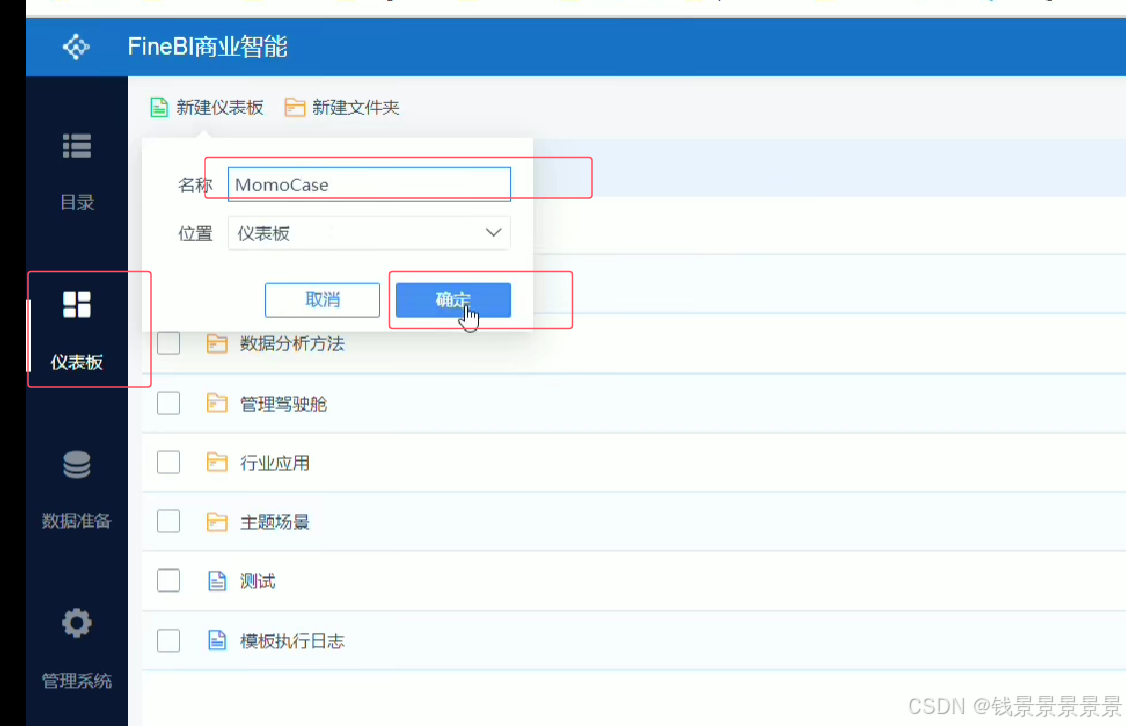
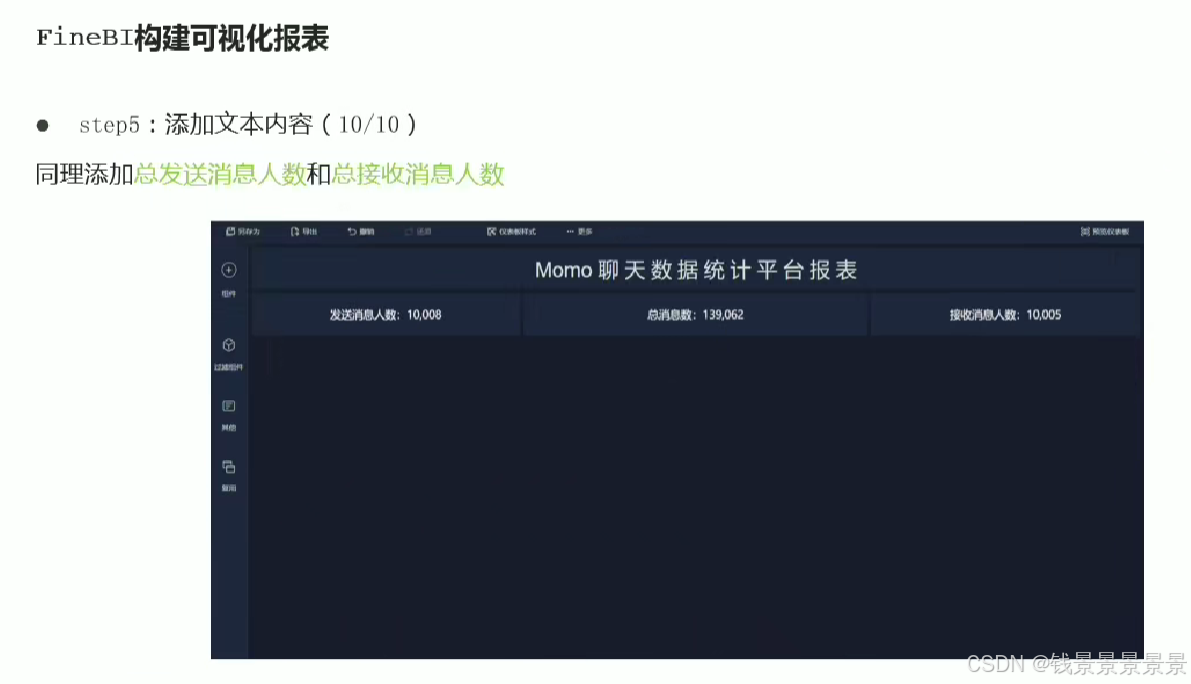
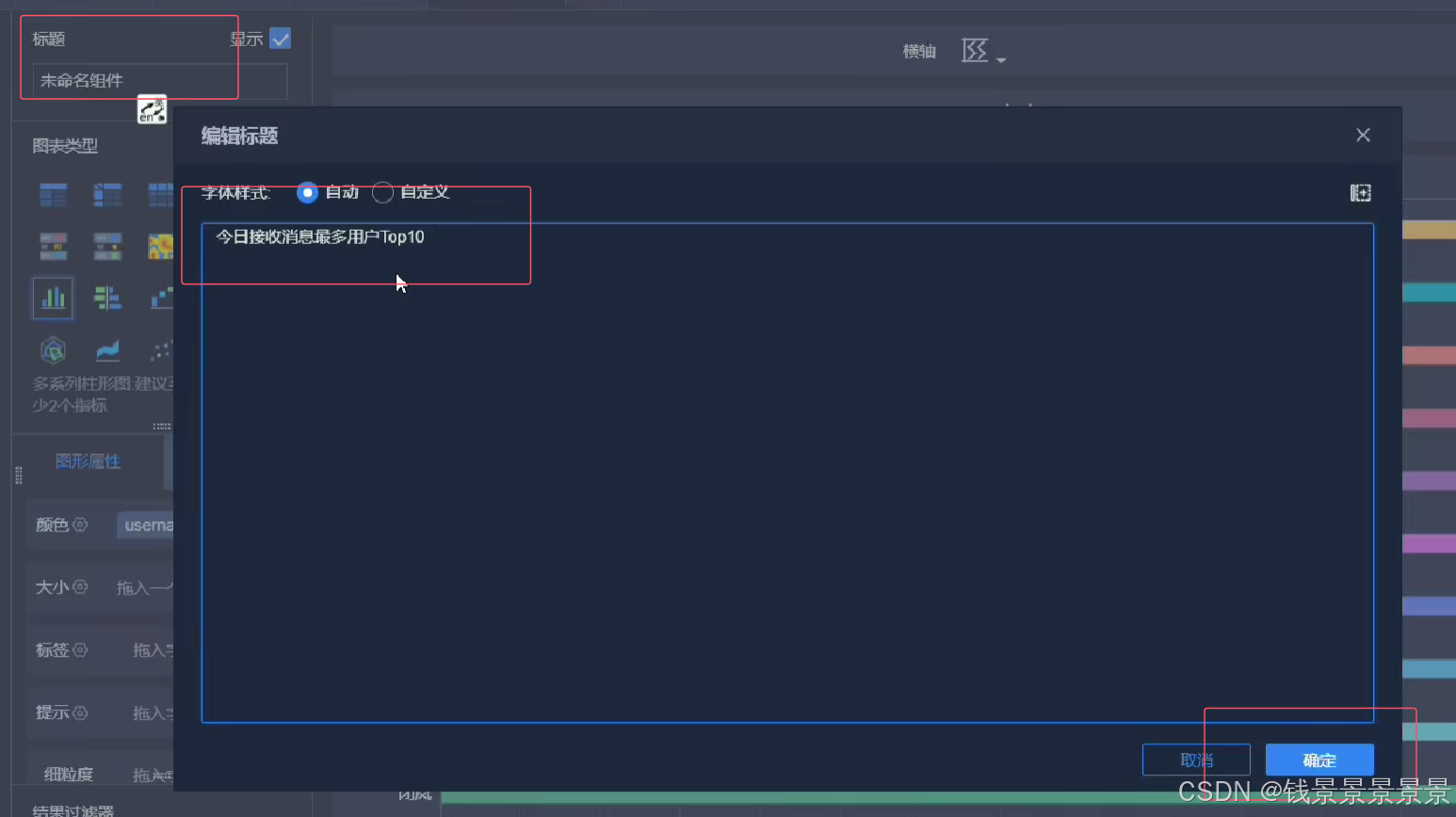
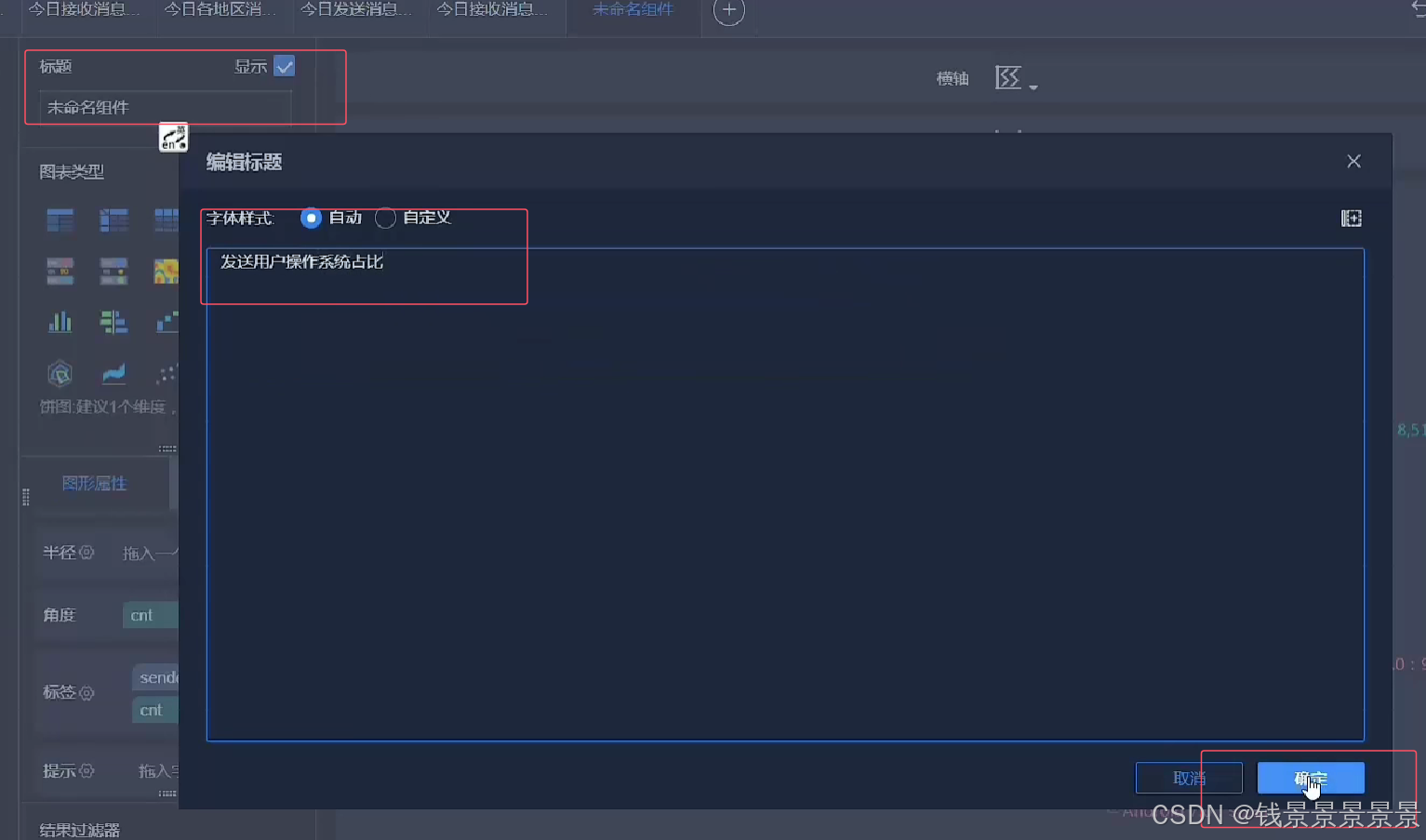
11.基于fineBI实现可视化报表-标题配置与文本框使用

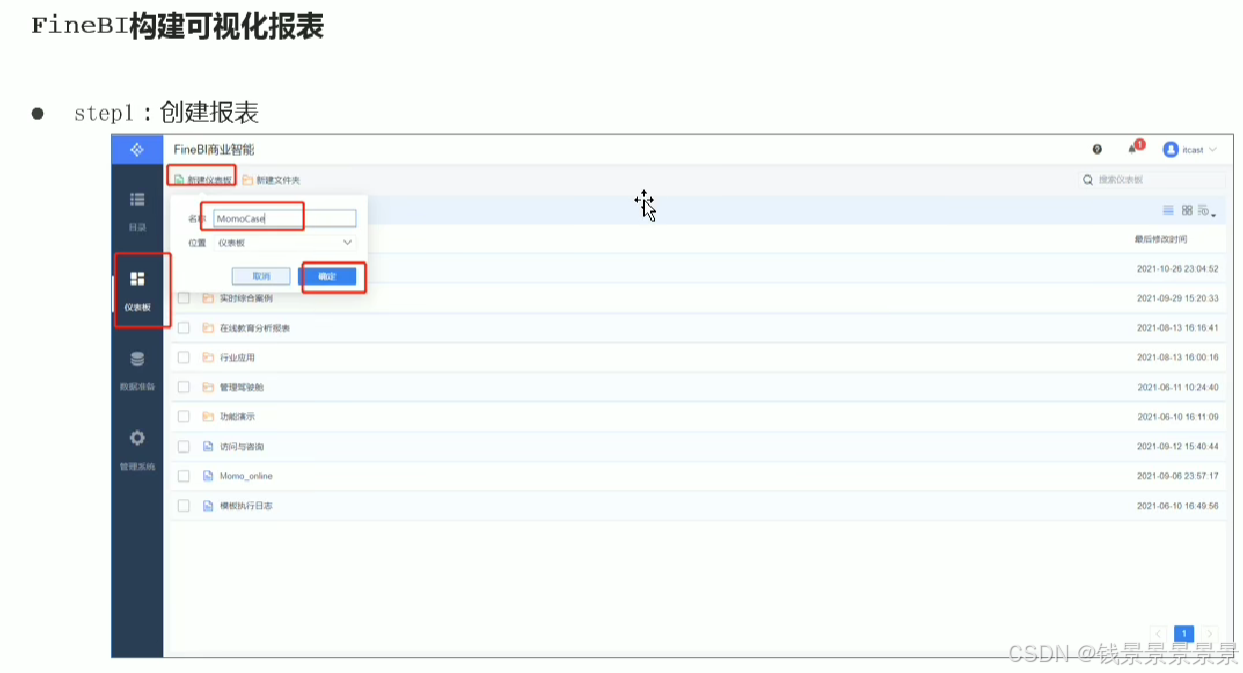
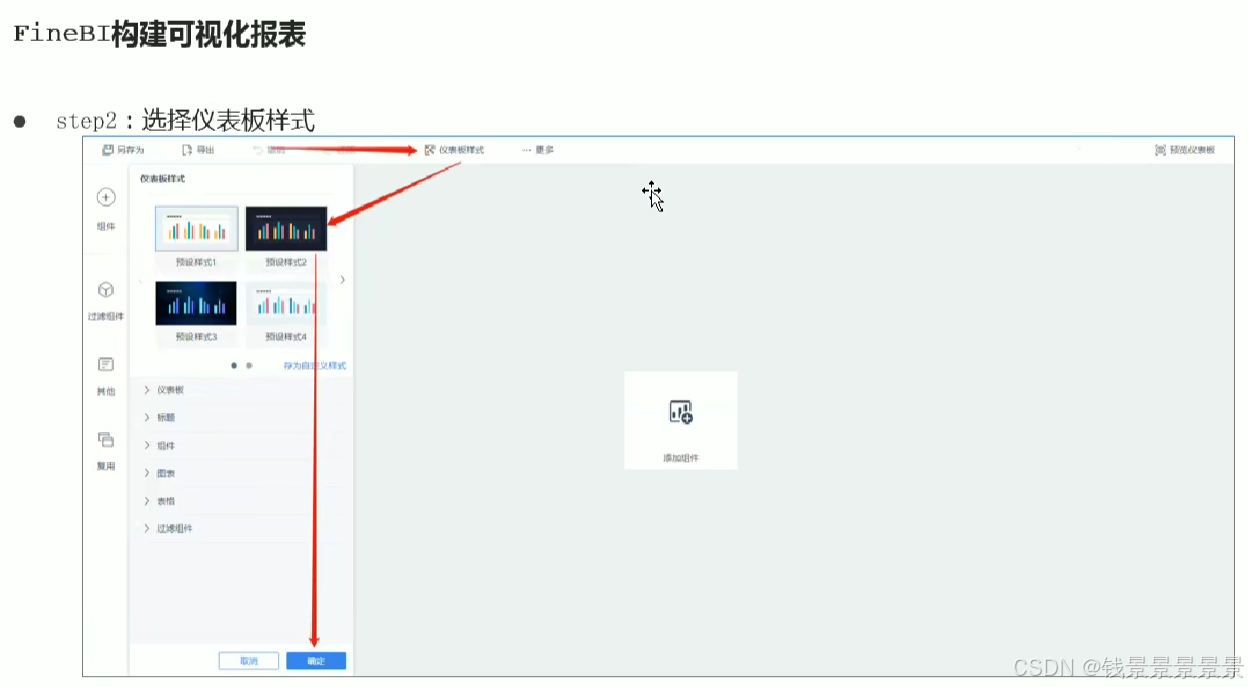
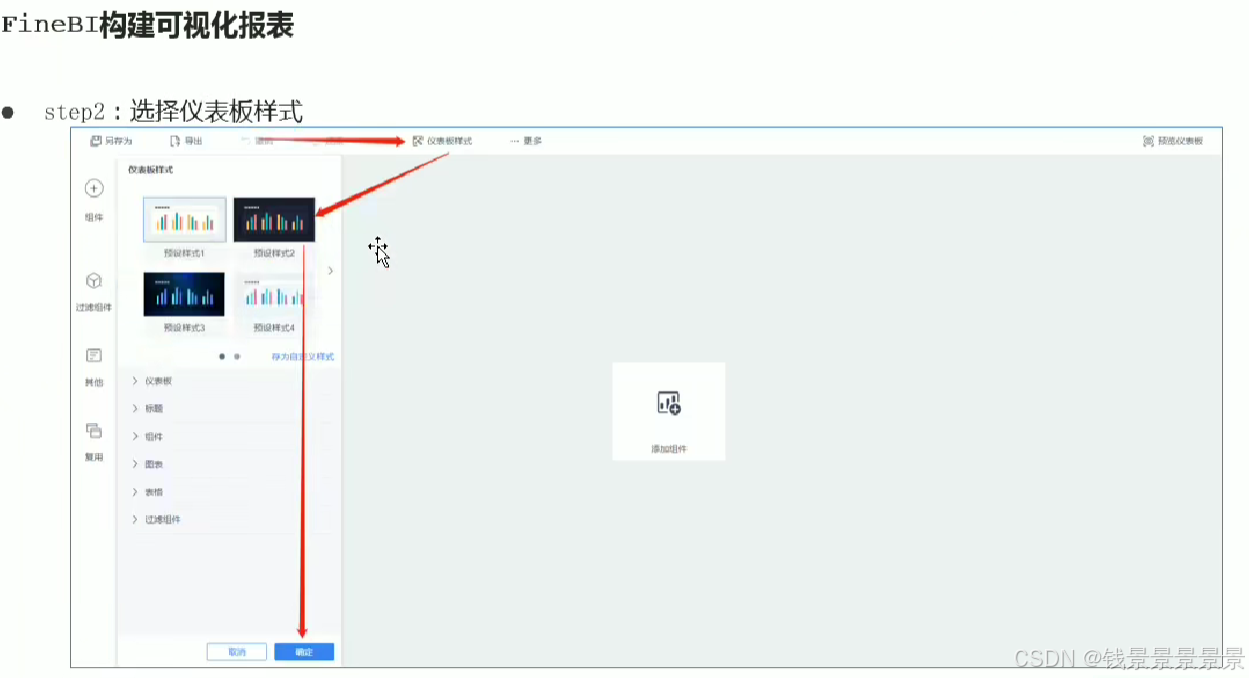
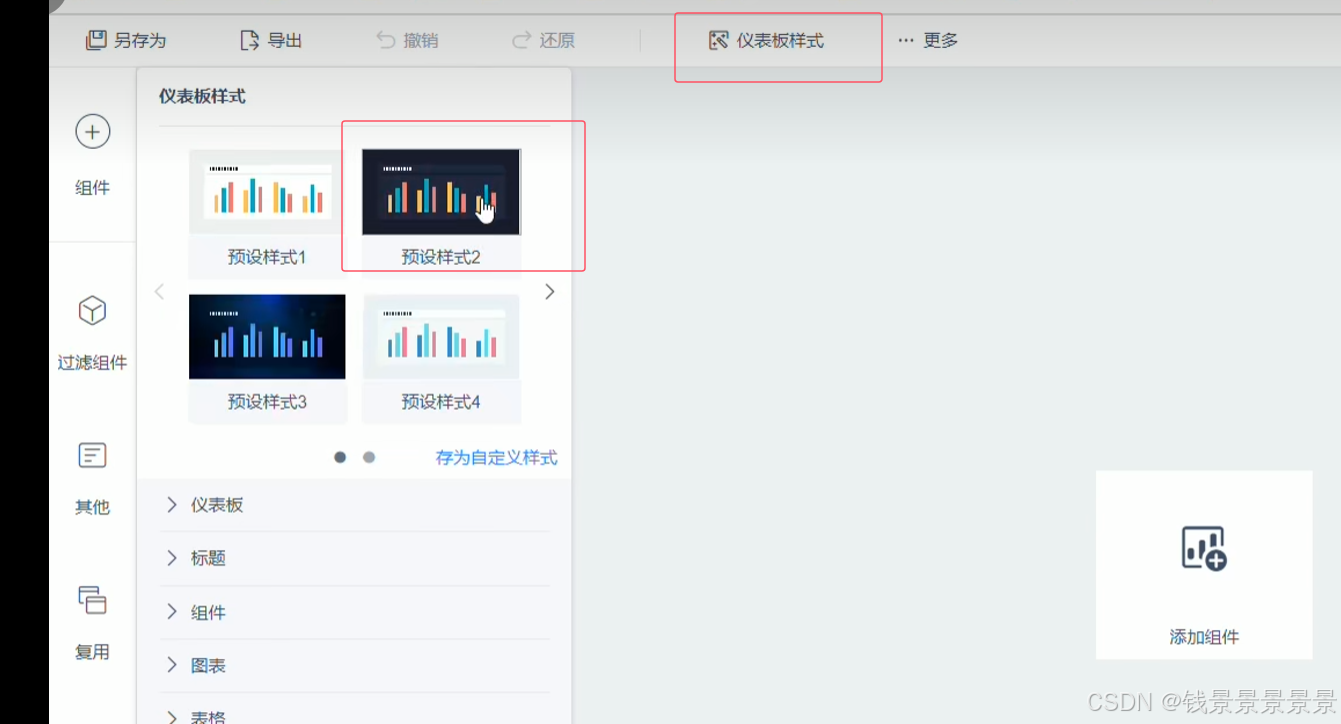
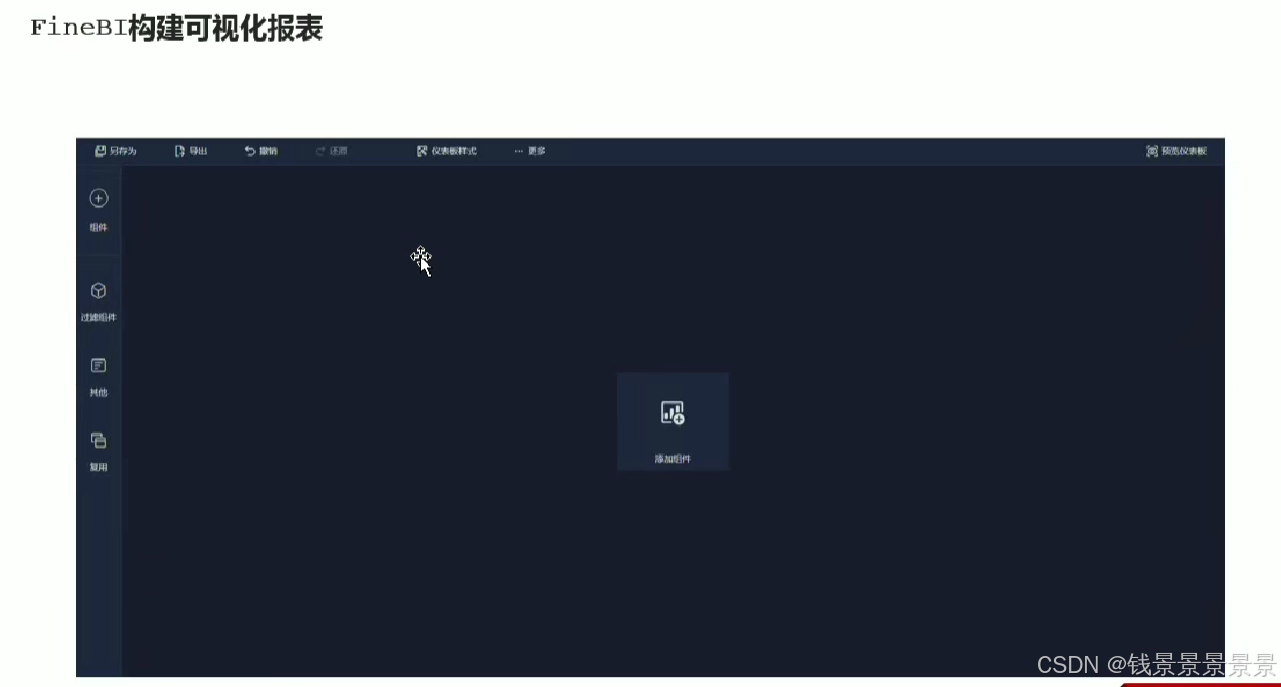
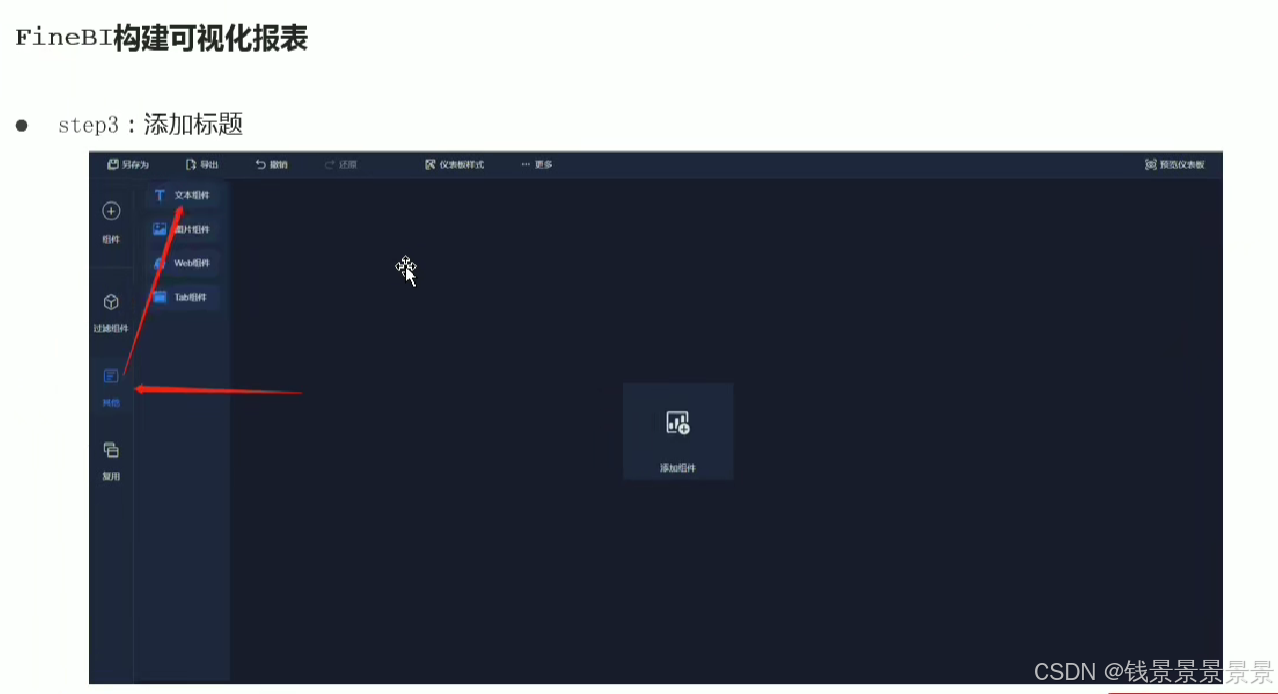
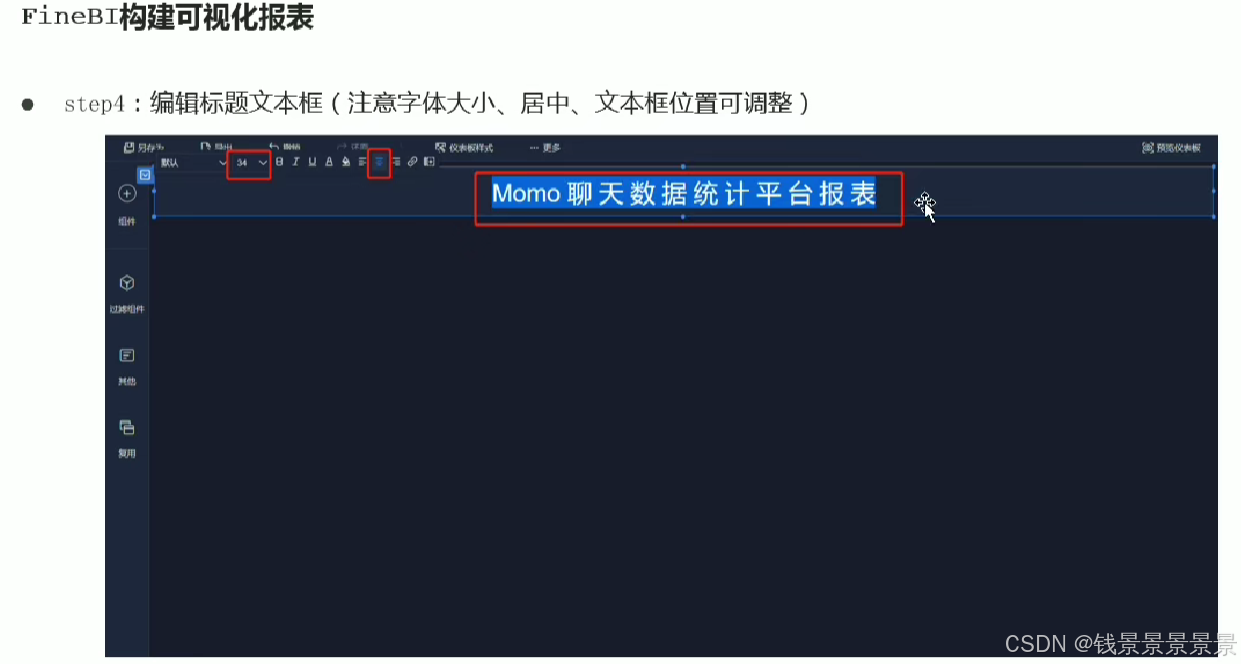

右上角可以预览一下效果

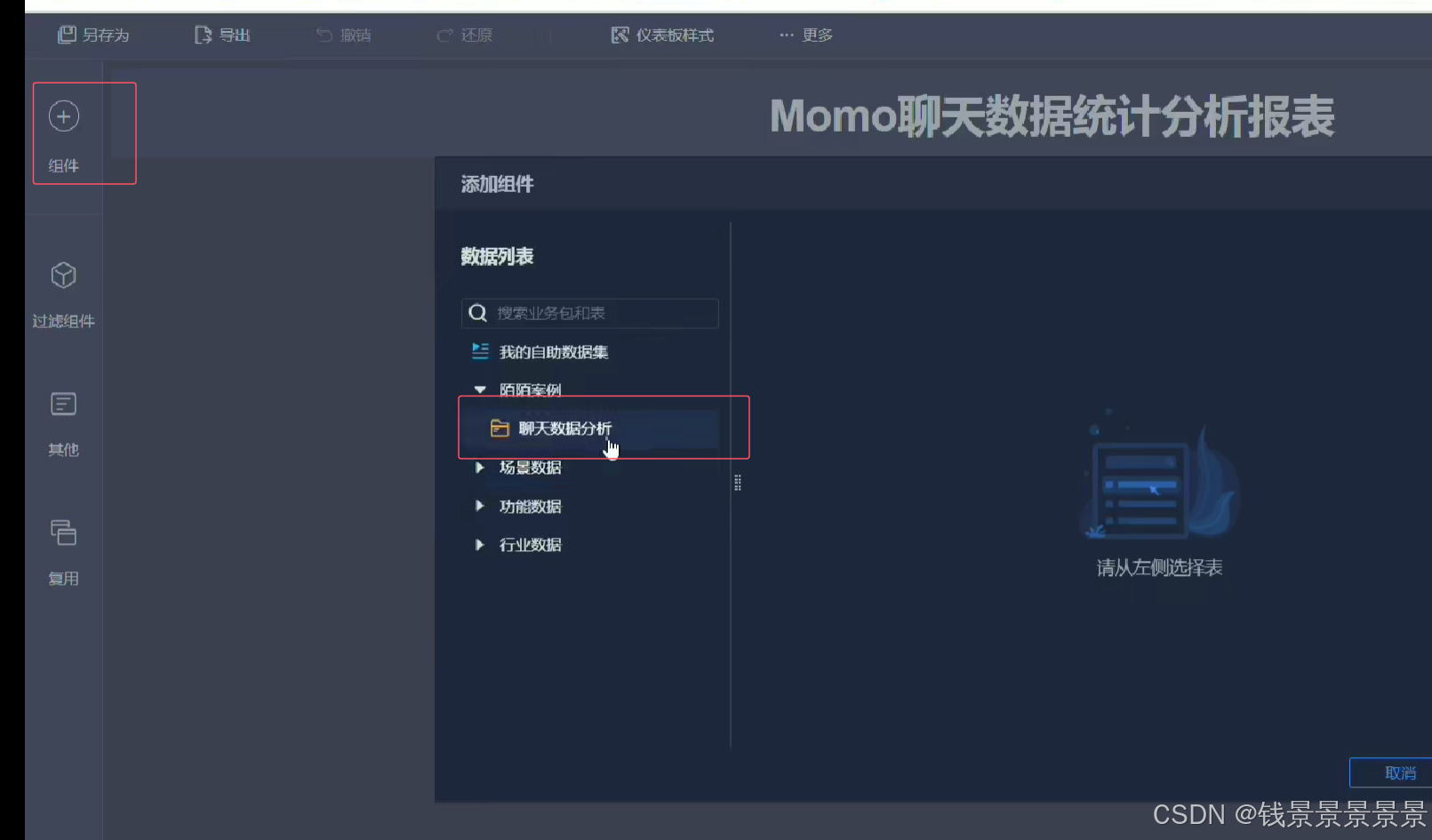
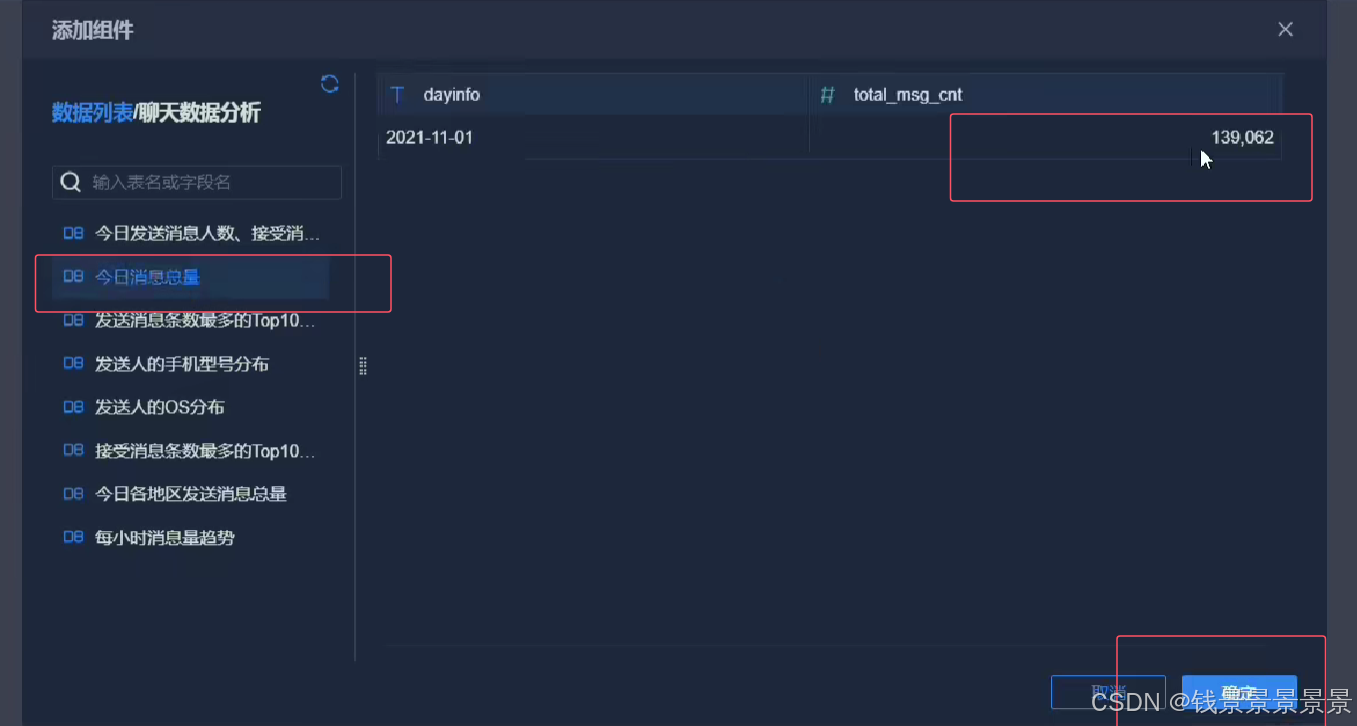
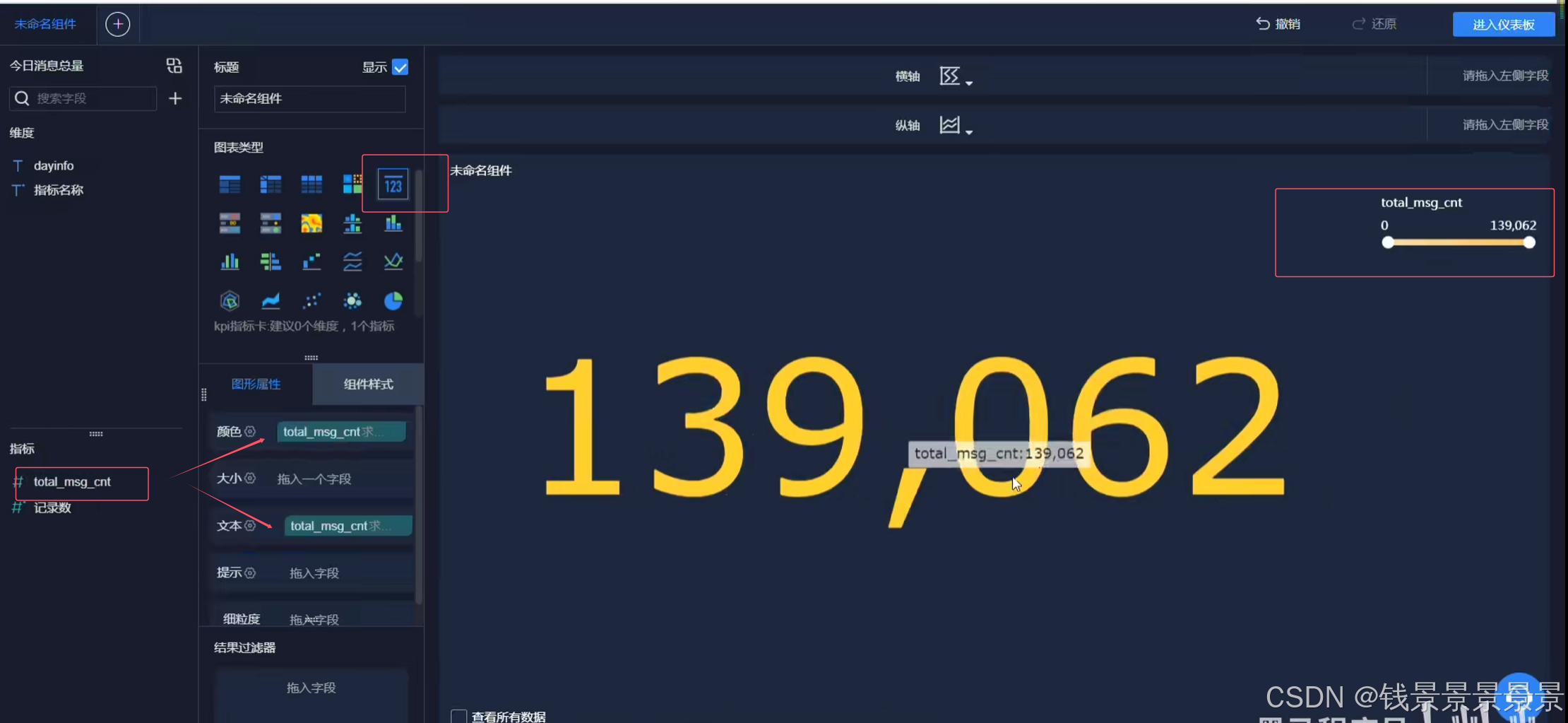
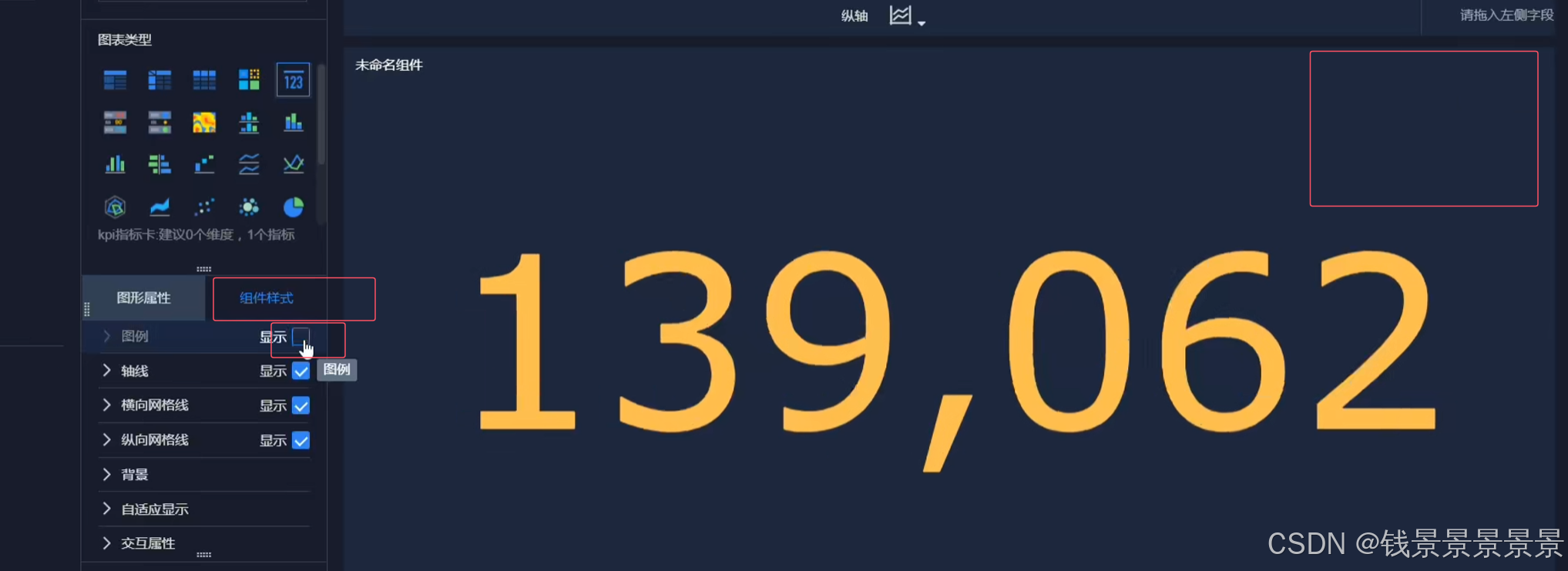
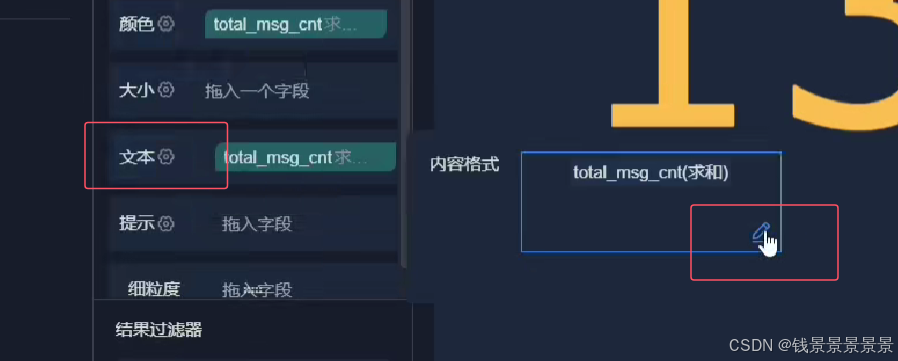
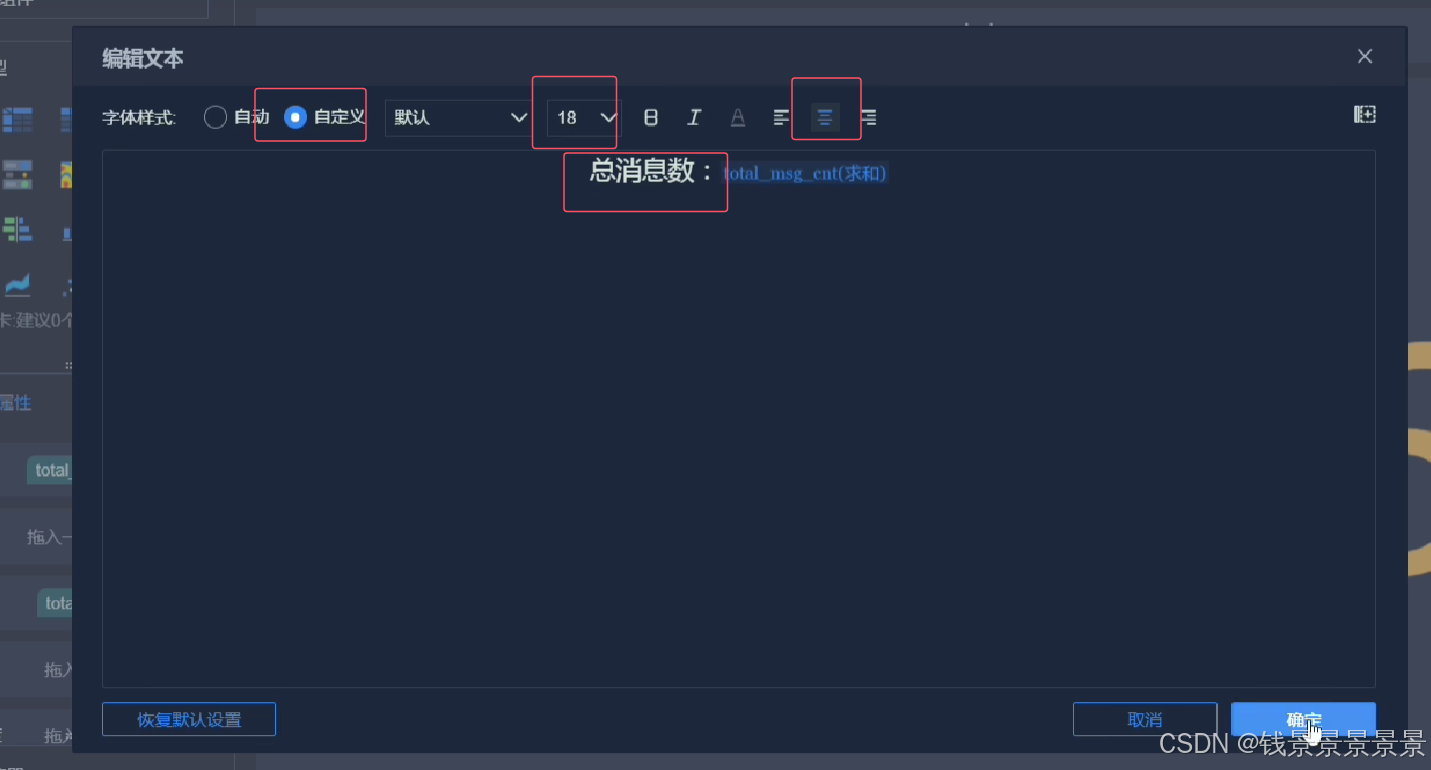
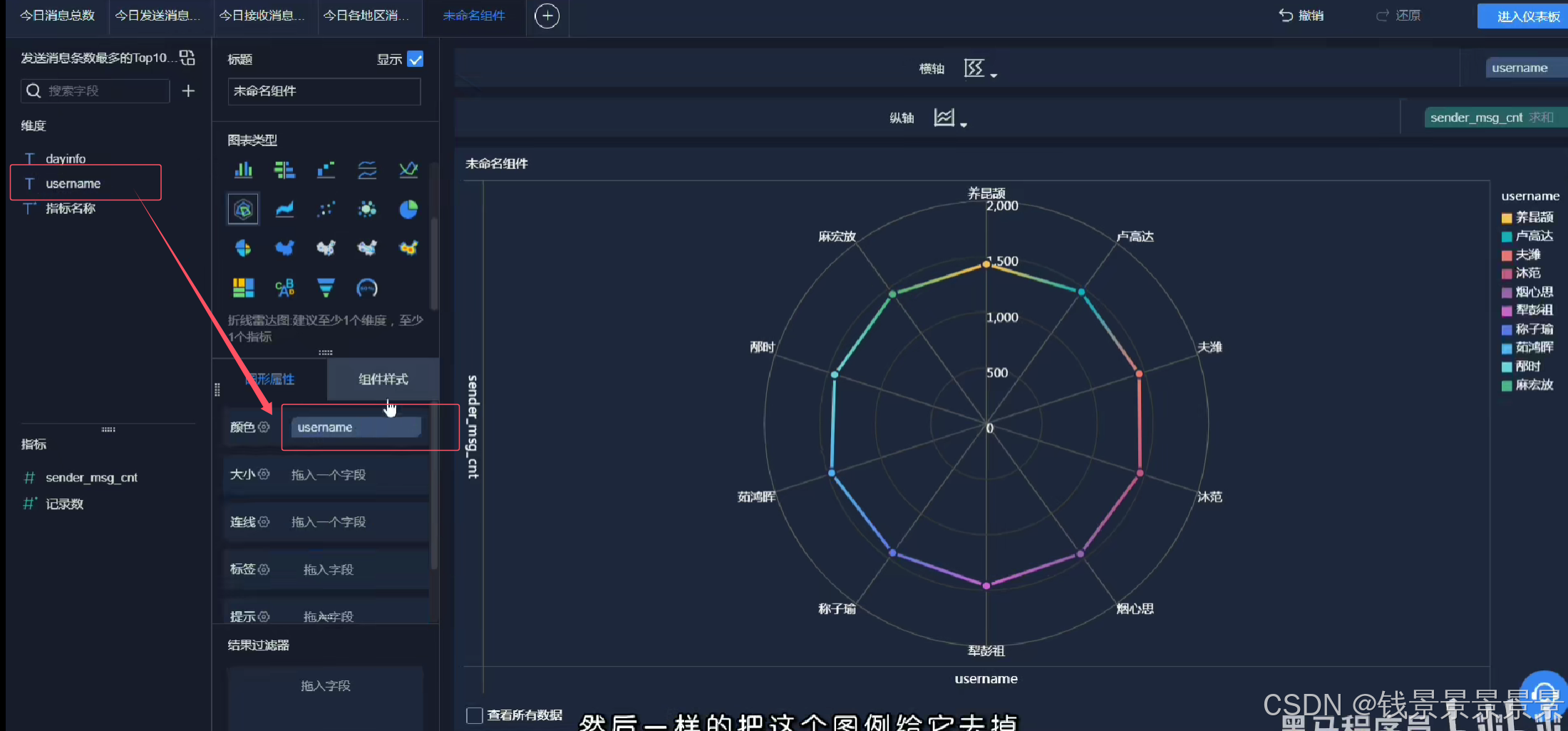
再给这个组件起一个名字(可以选择不显示)
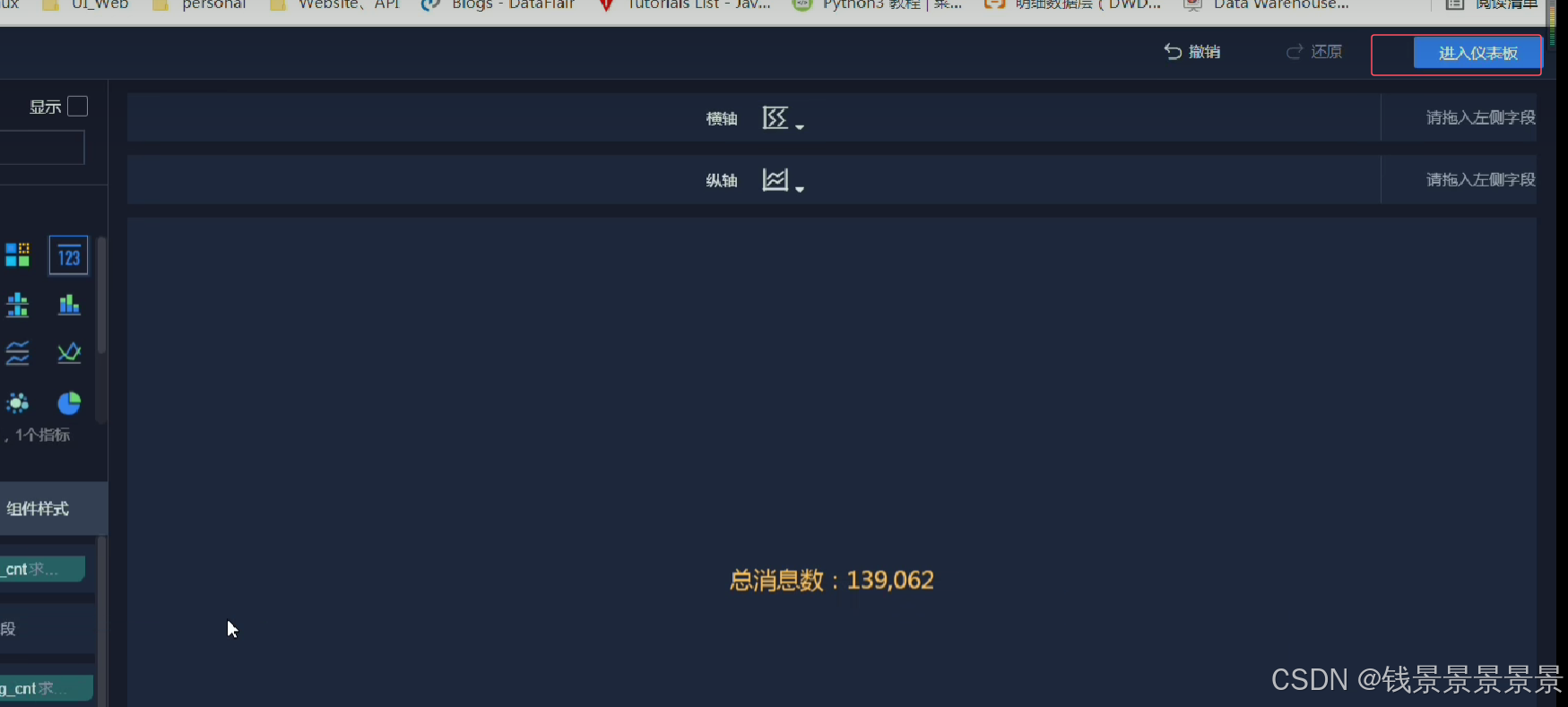
结束后
进入仪表盘
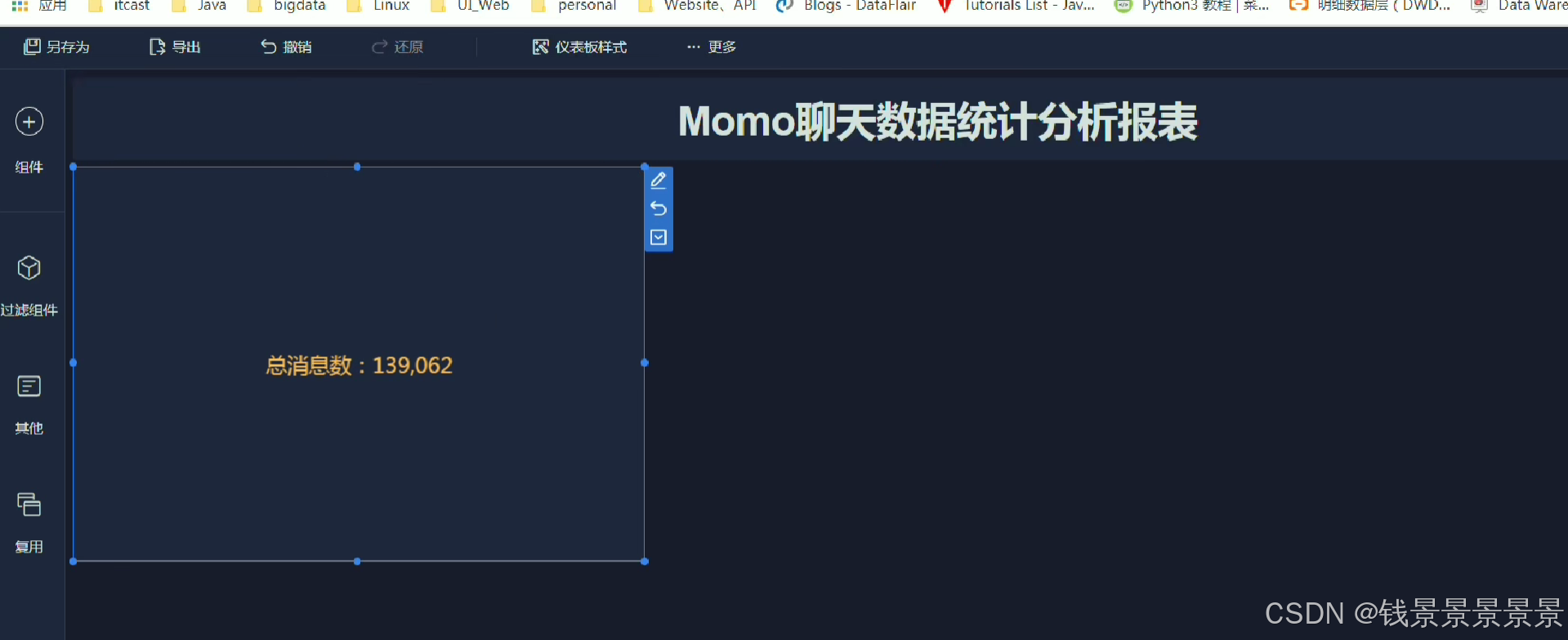
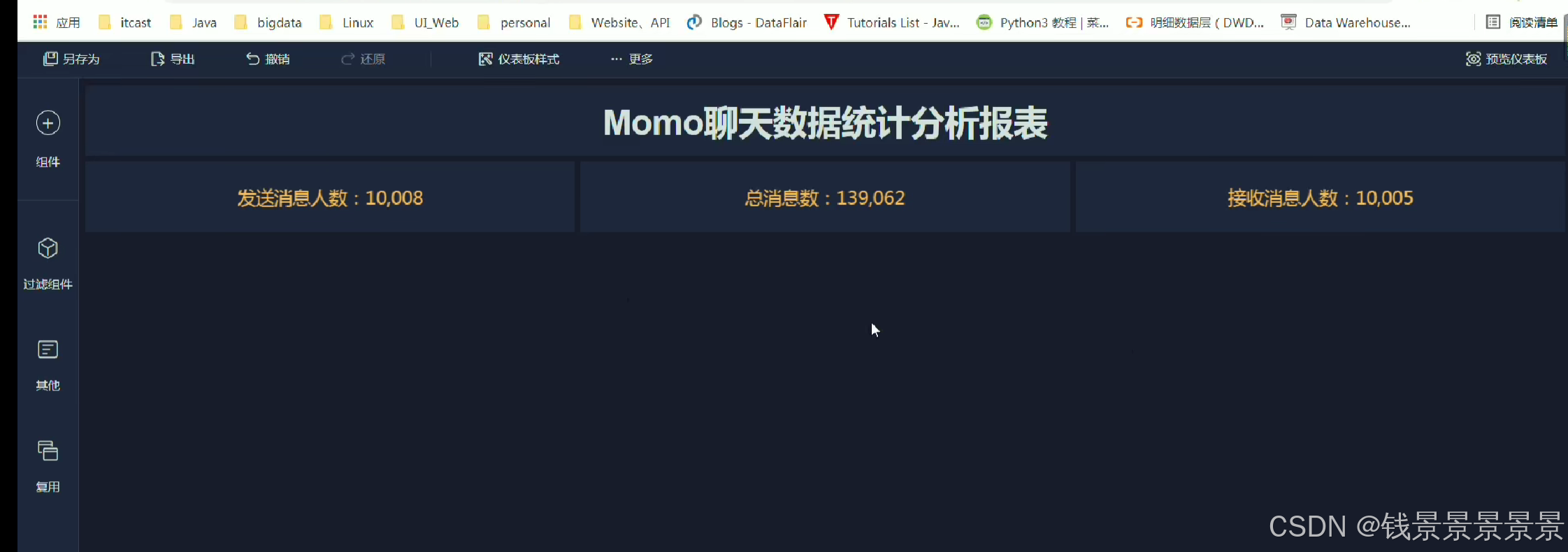
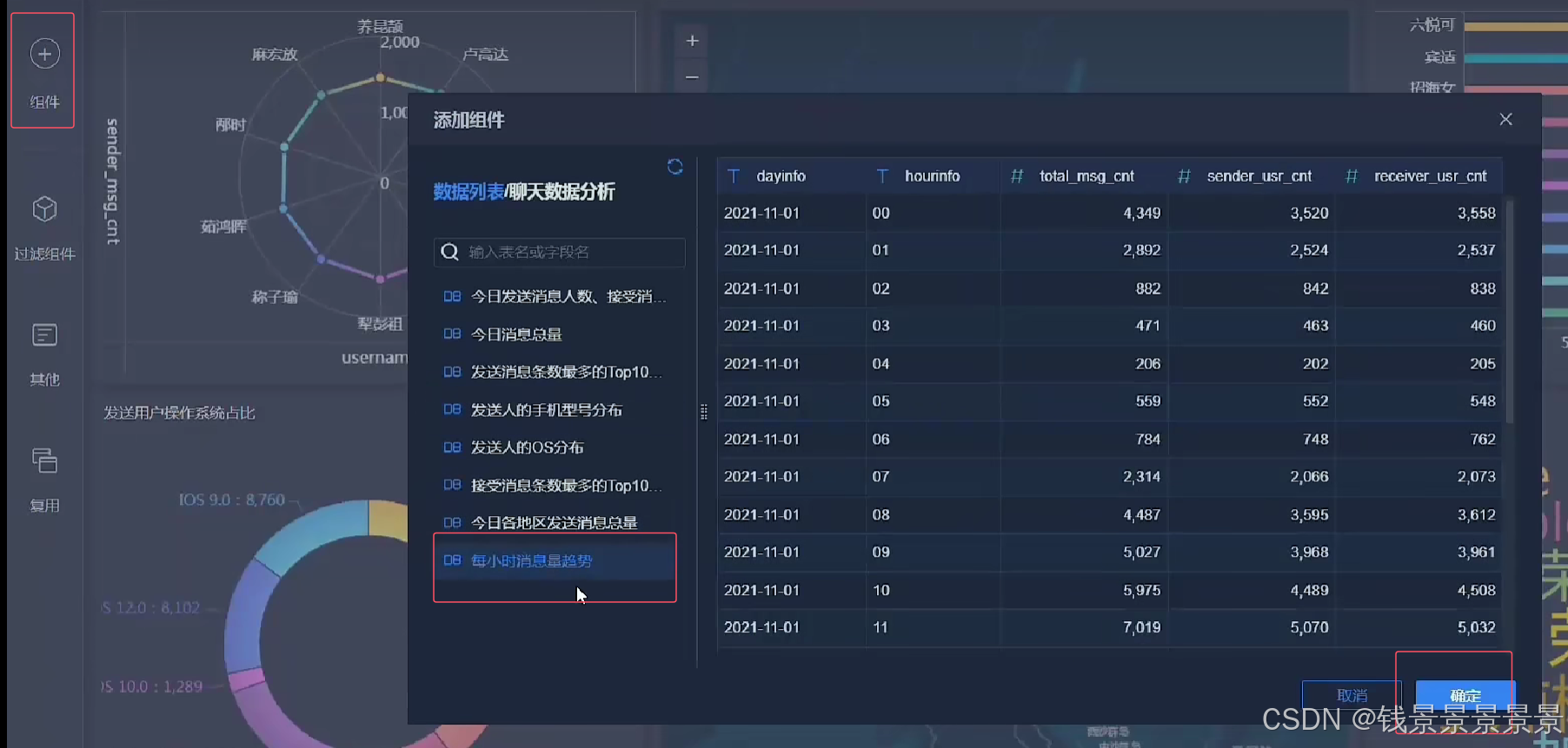
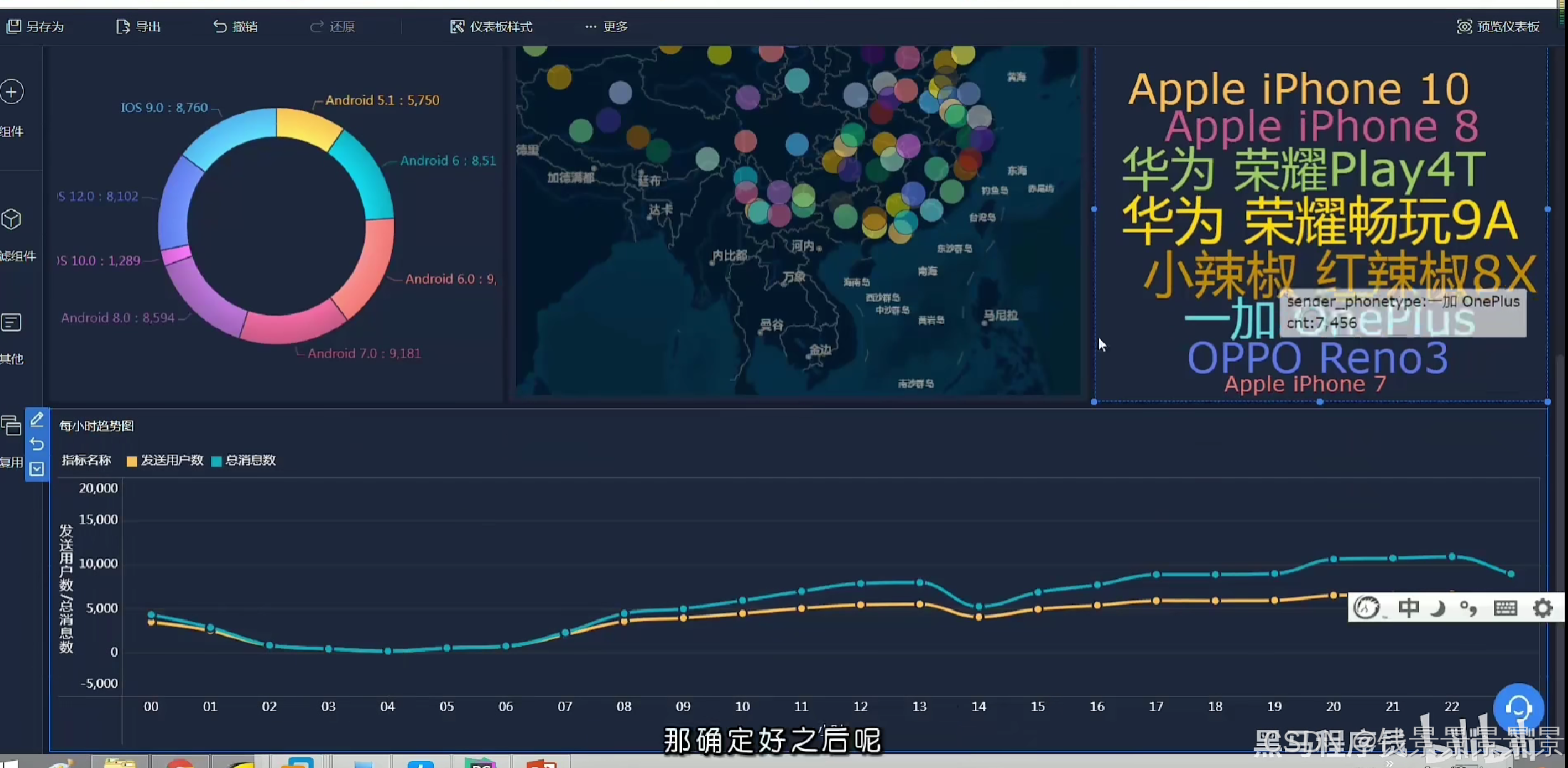
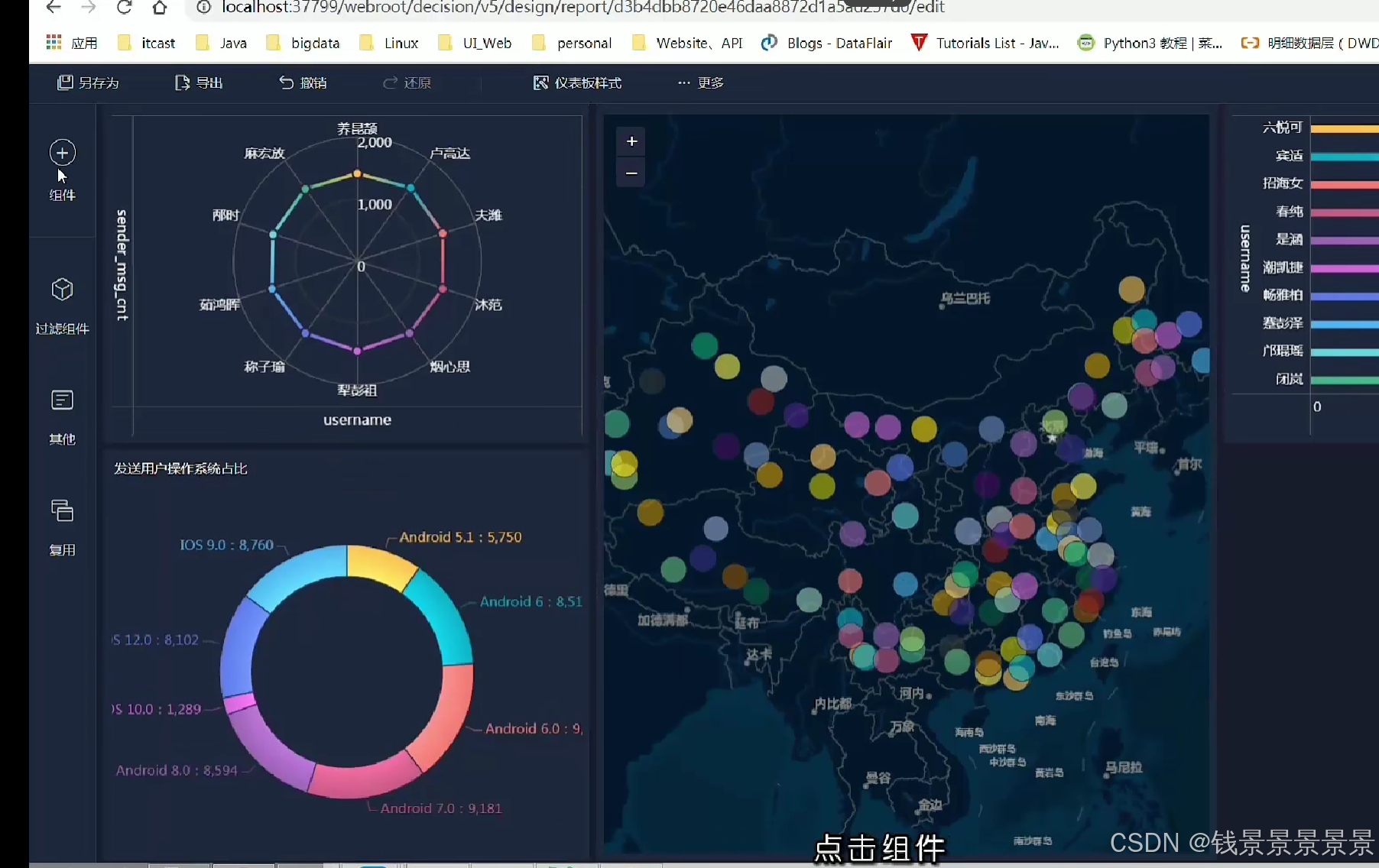
12.基于fineBI实现可视化报表-地图、雷达、柱状图构建
地图
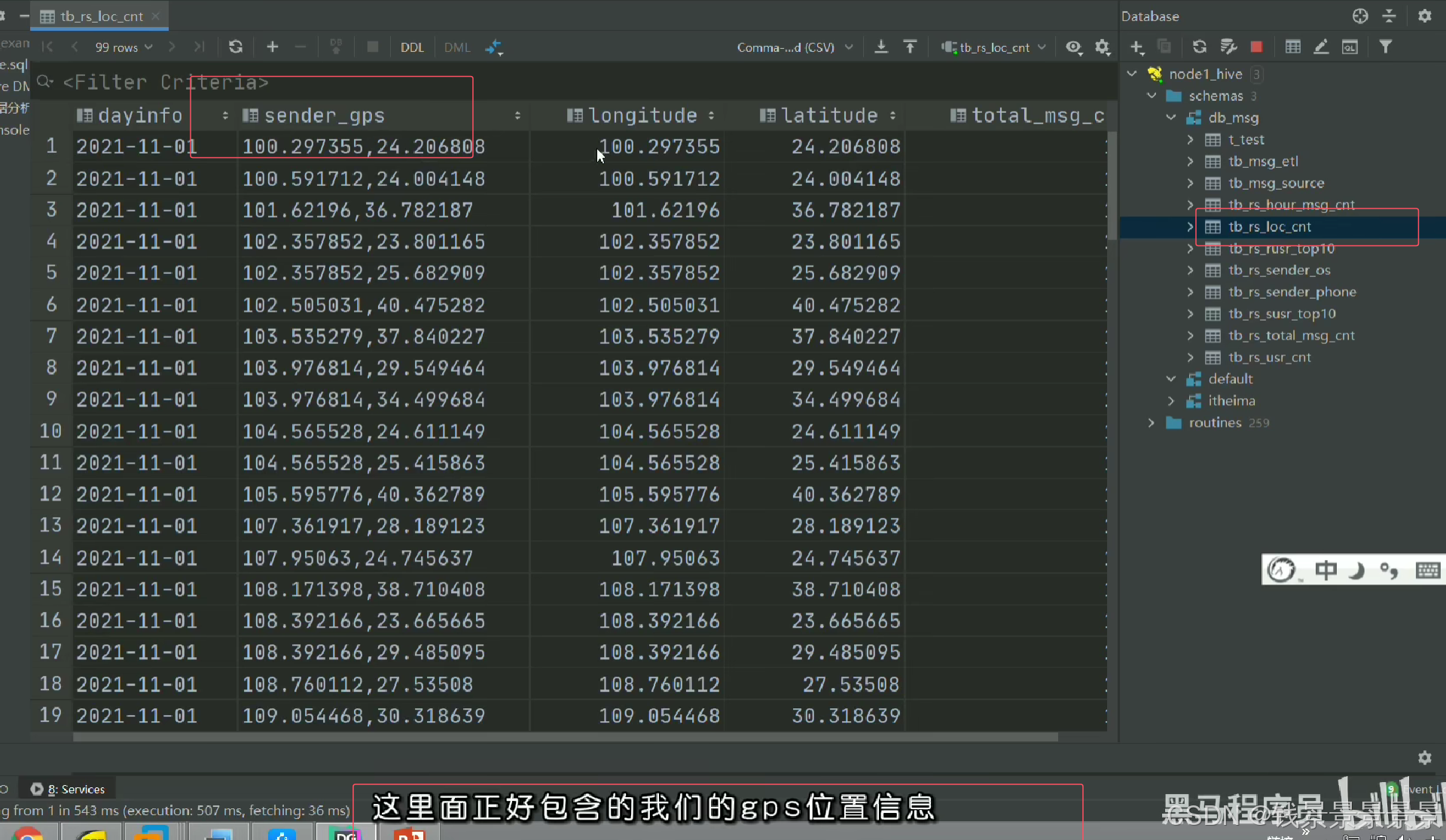
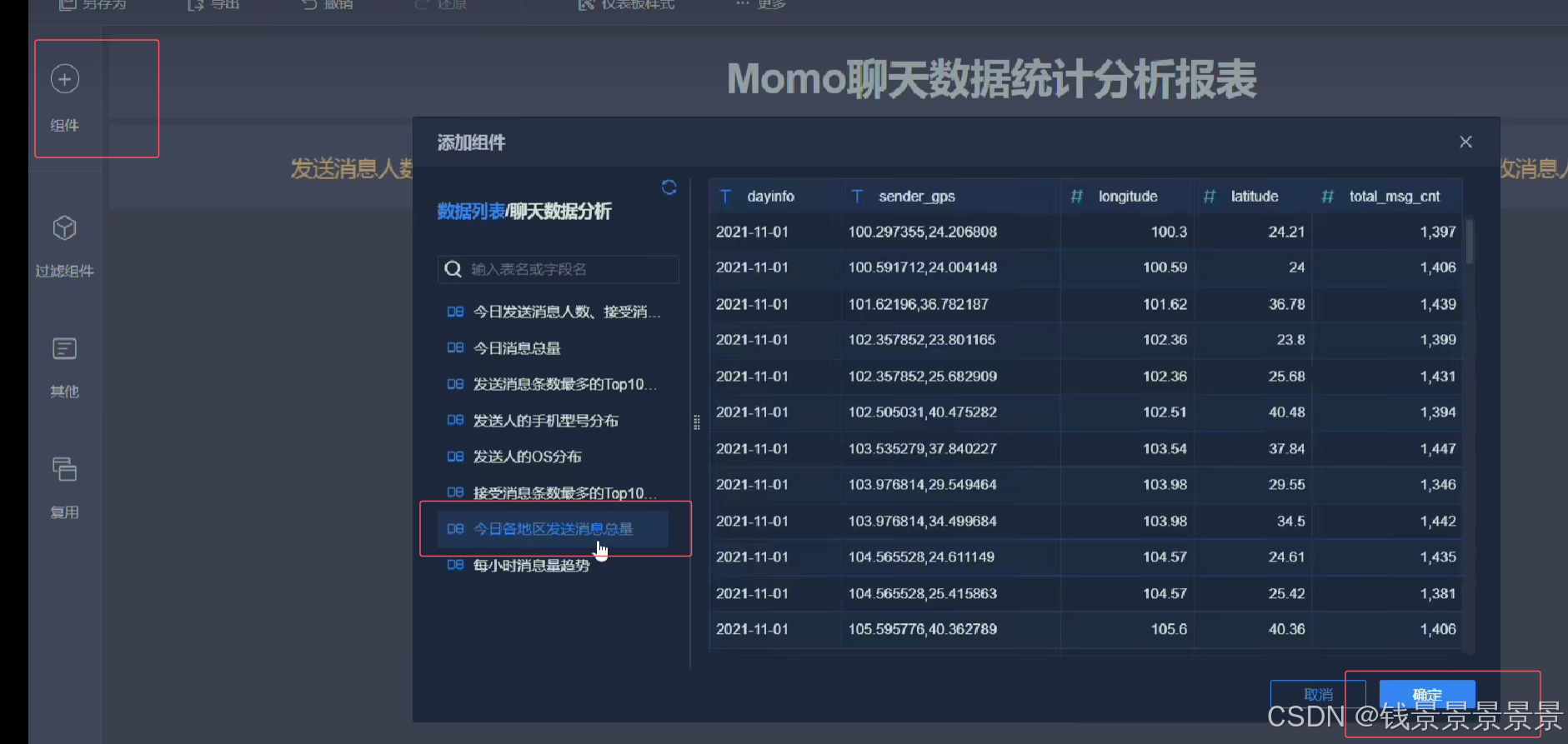
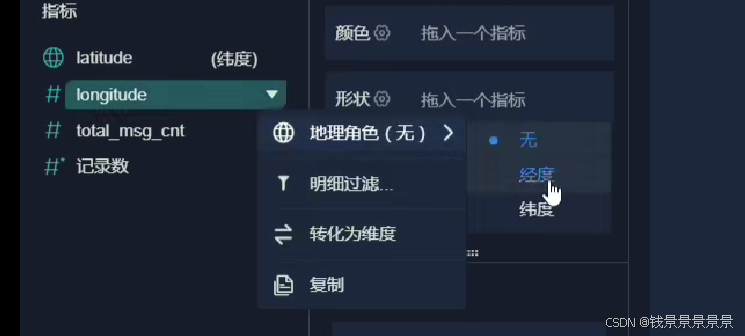
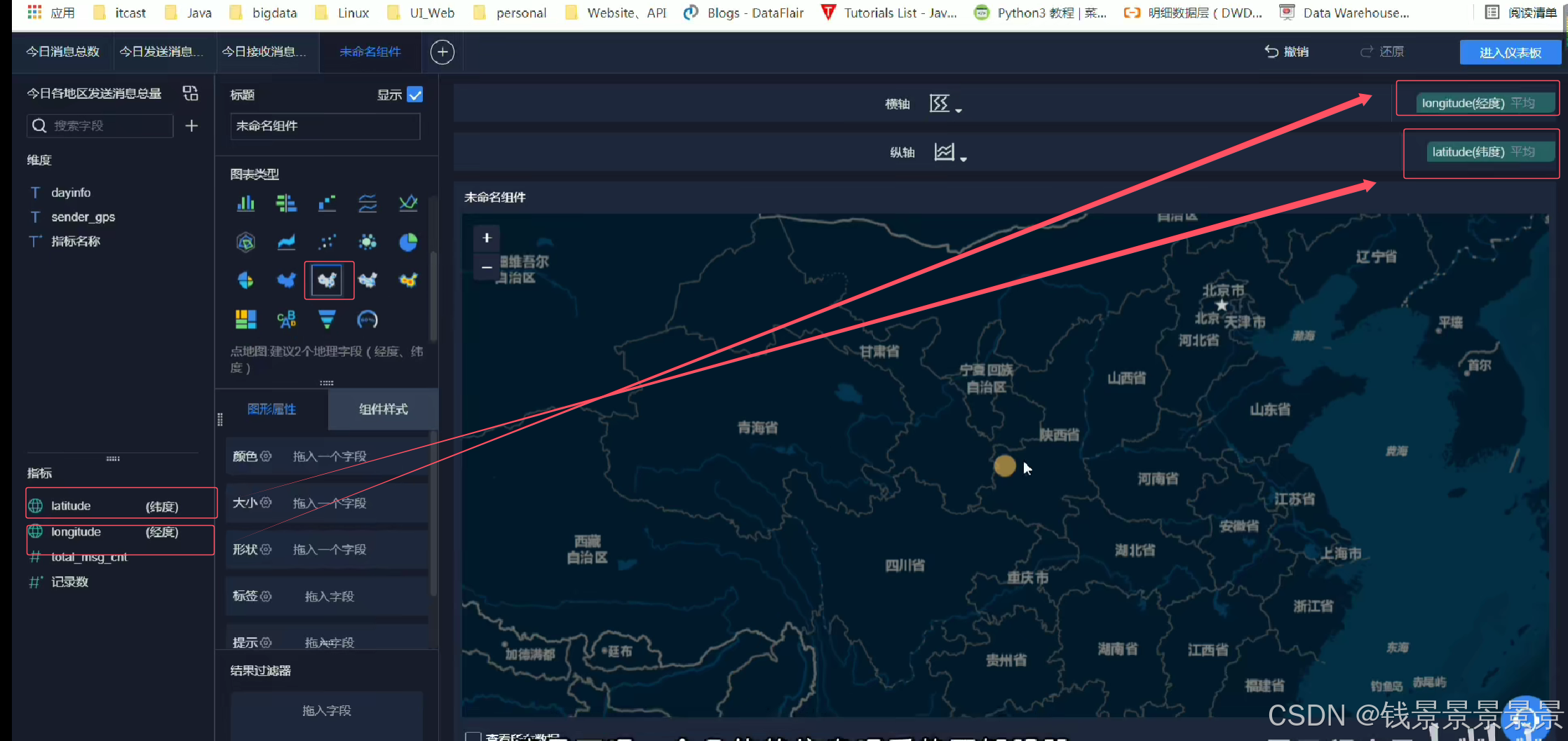
里面的信息不是很详细
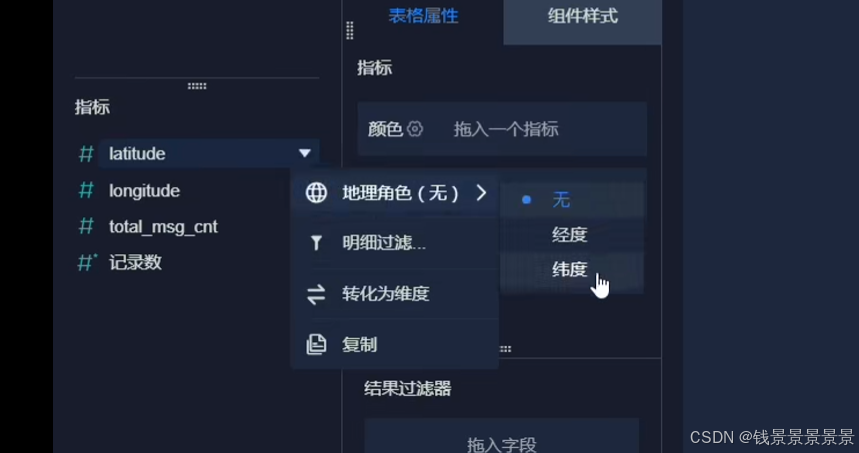
我们可以根据GPS调整它的粒度
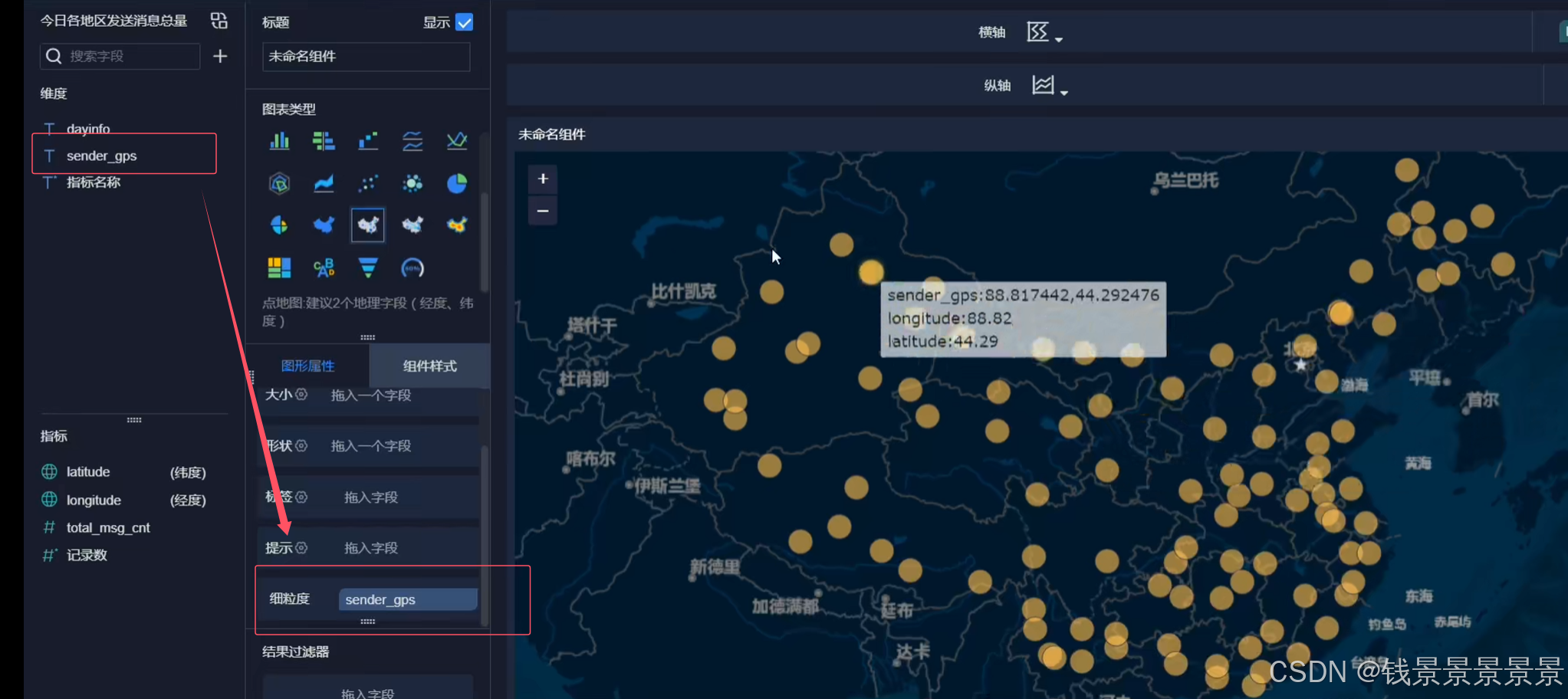

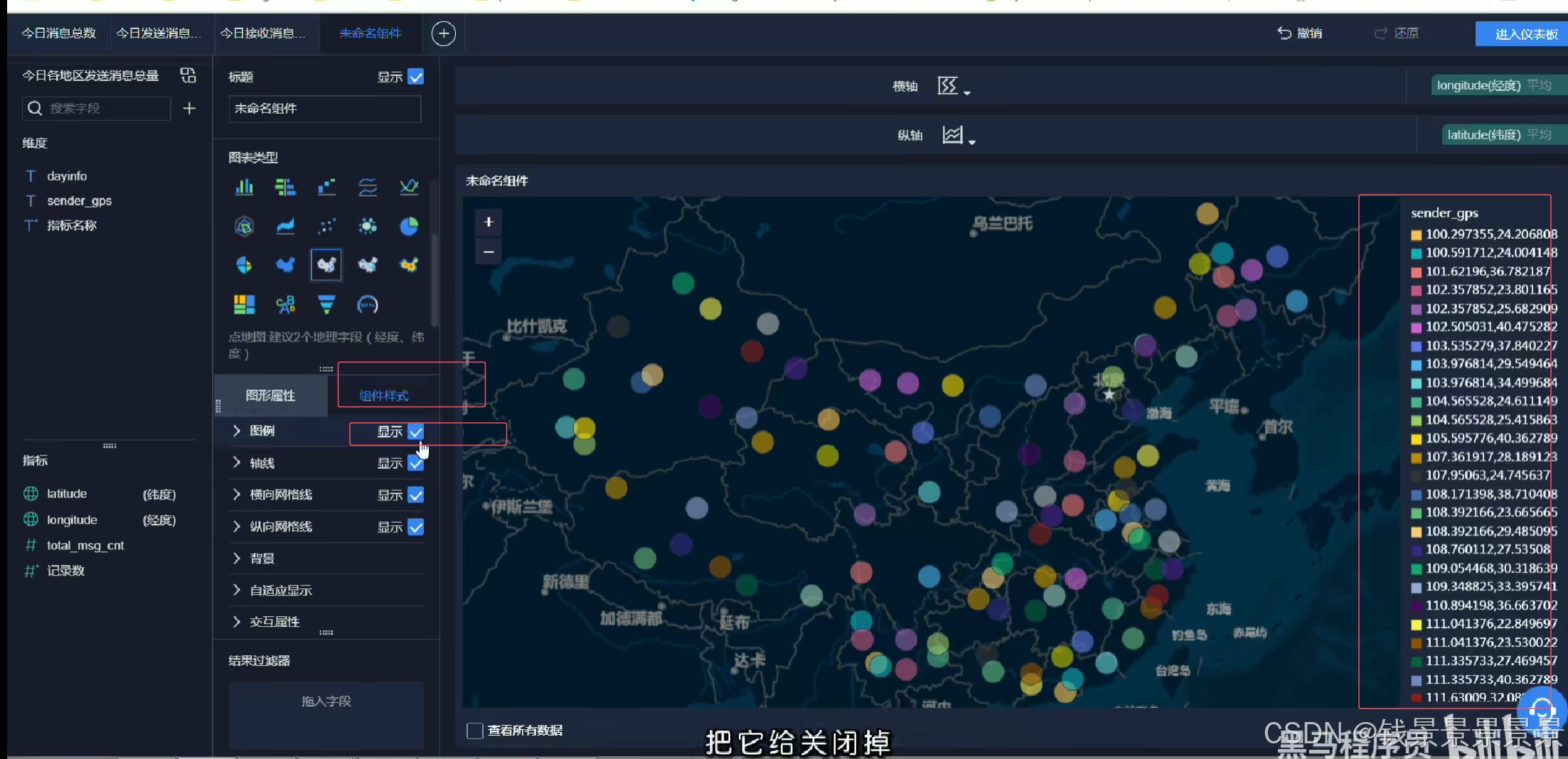
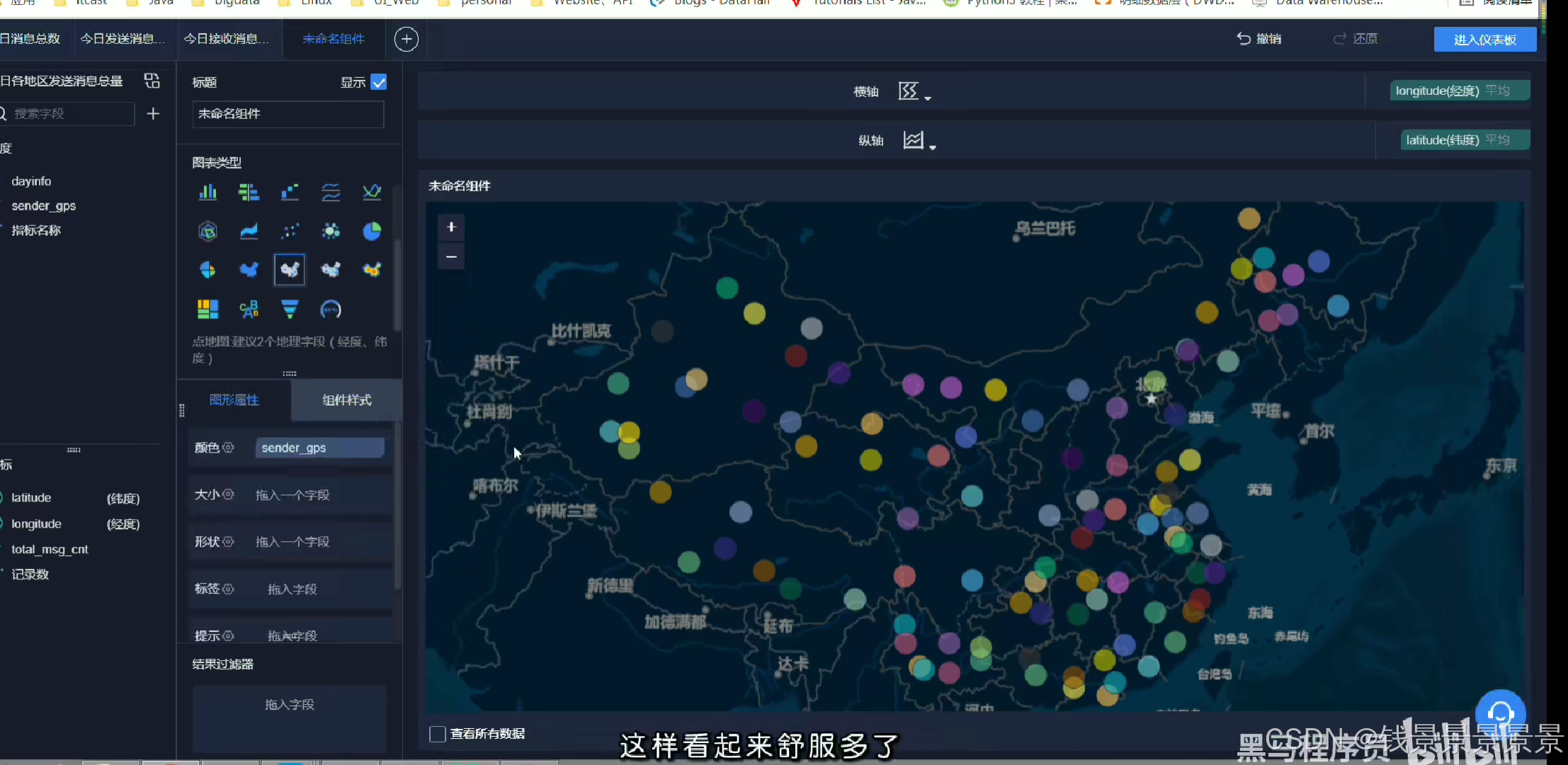
我们还可以根据人的多少
调整圈的大小


==================================================================================================================================================
雷达图
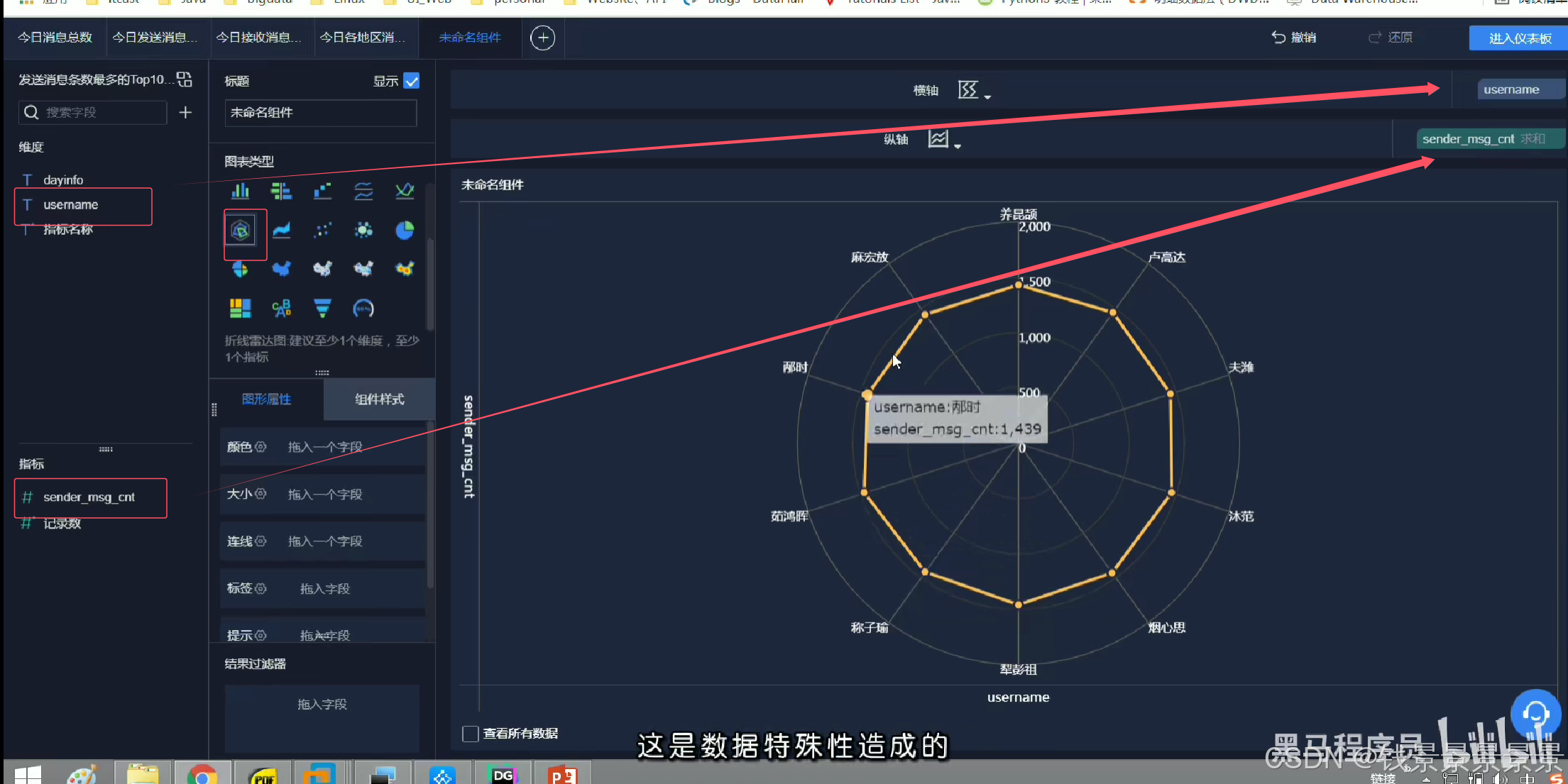

==================================================================================================================================================
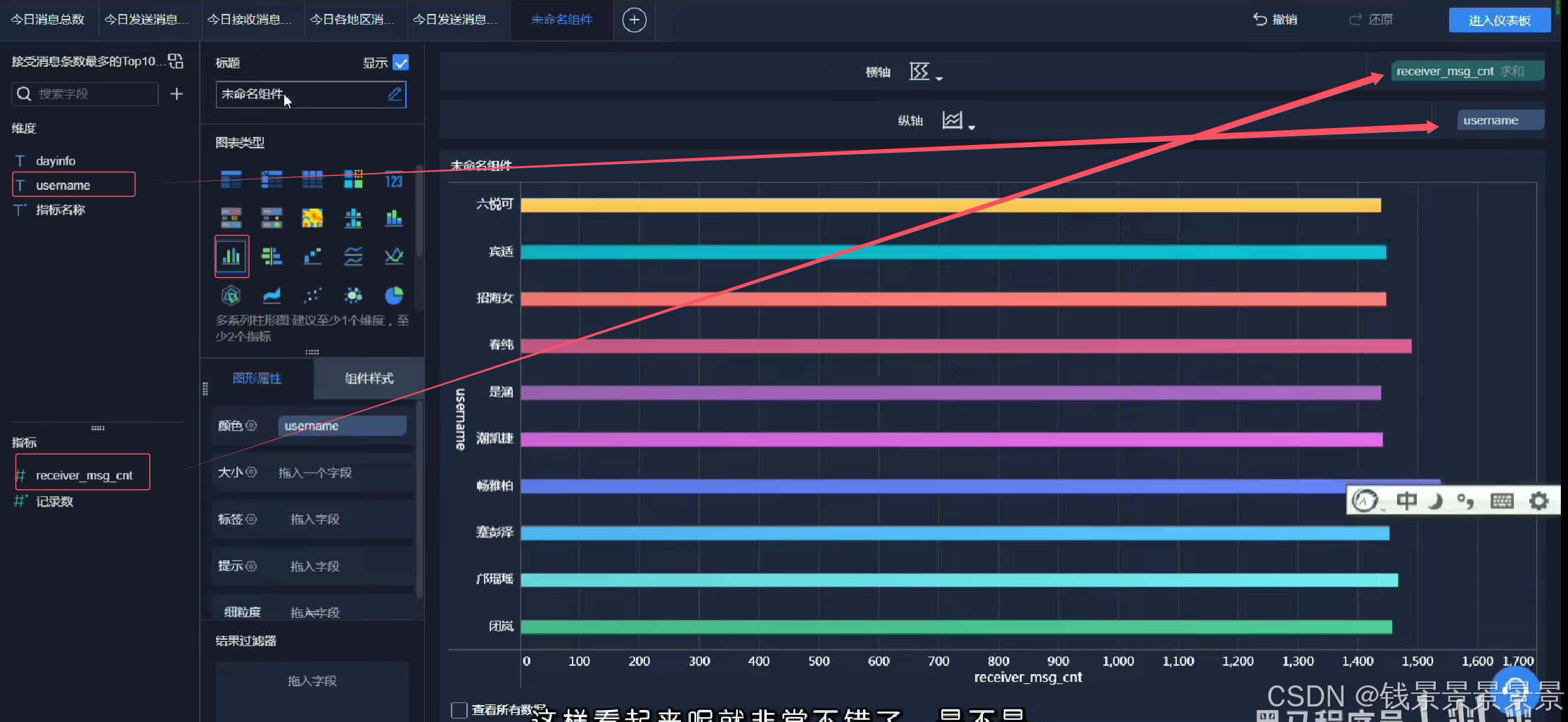
柱状图

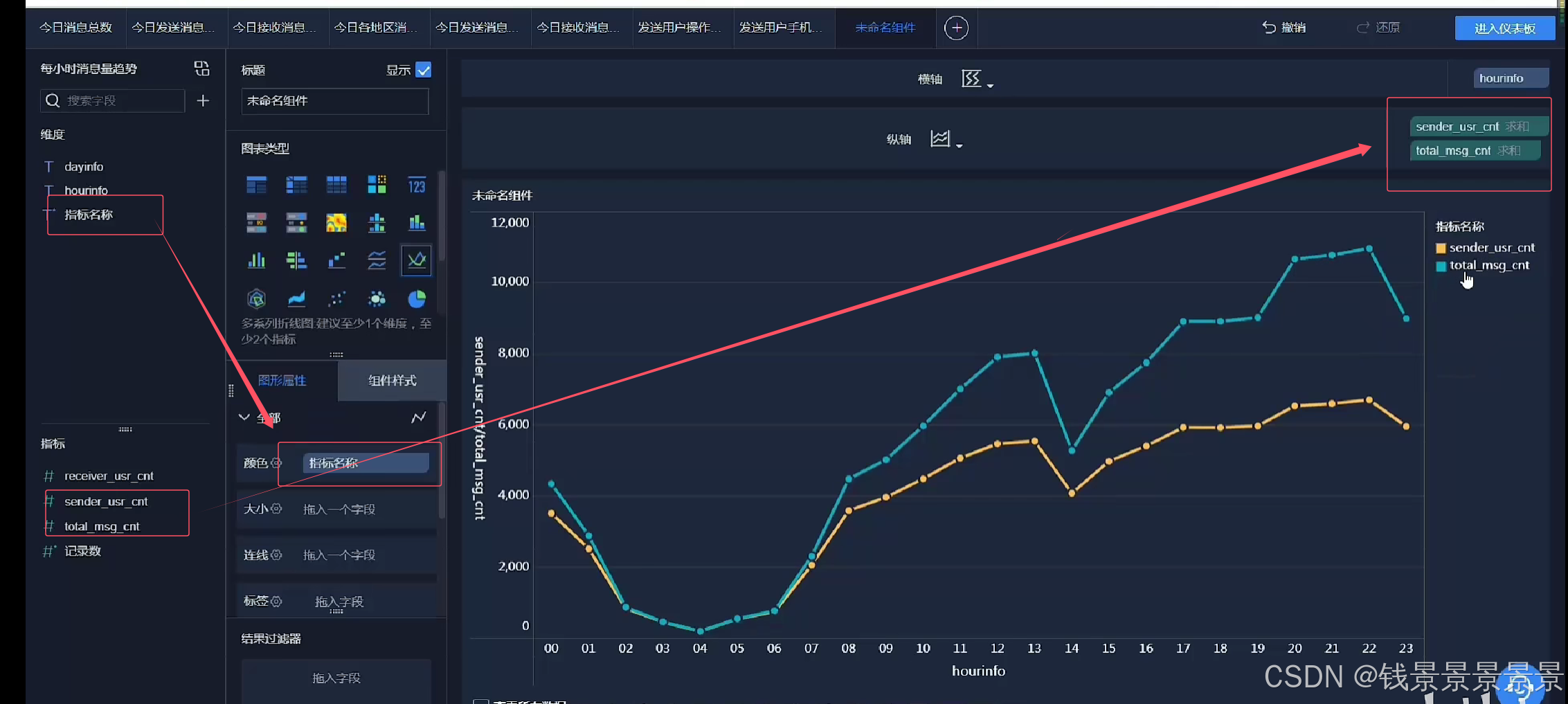
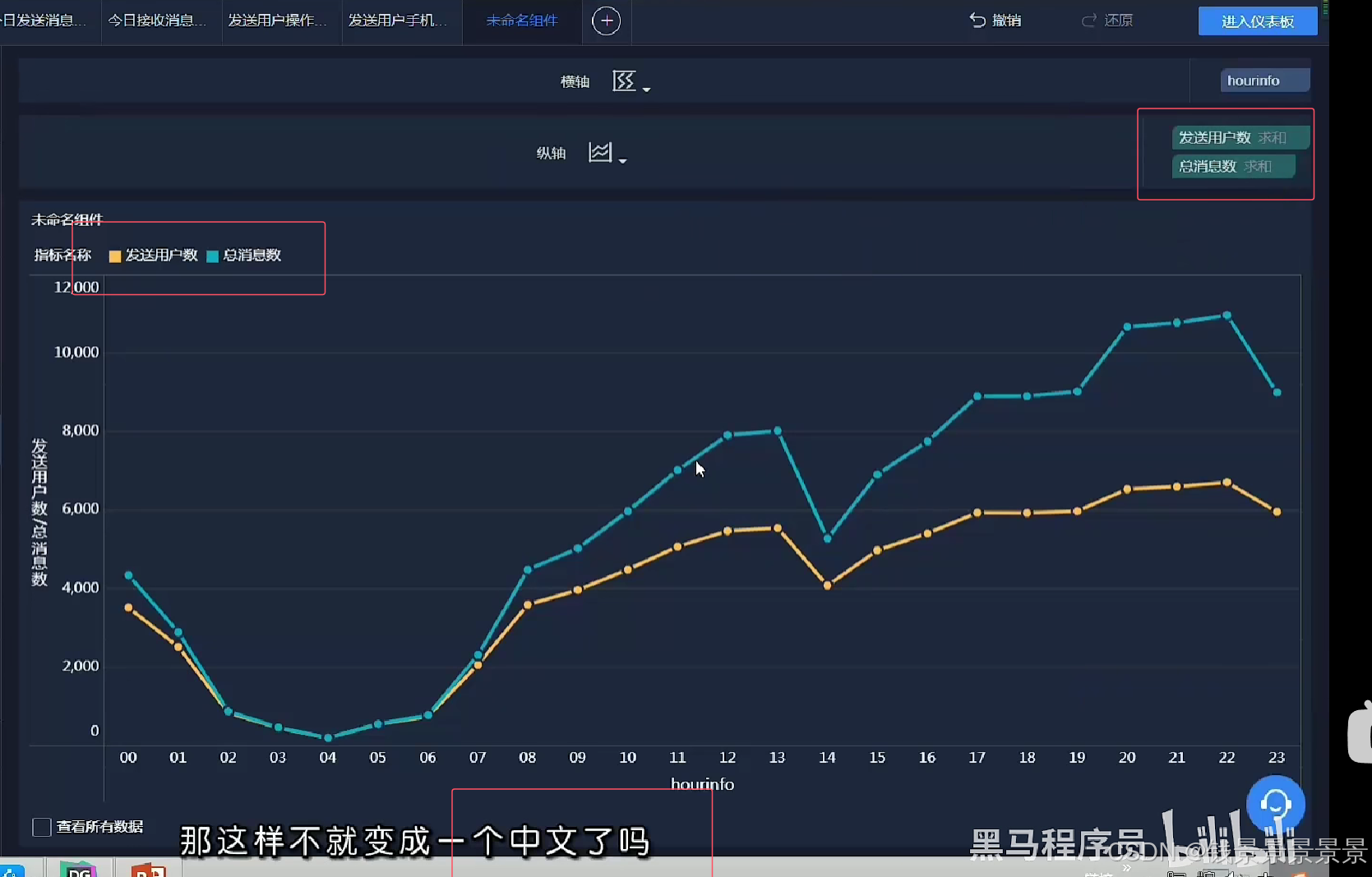
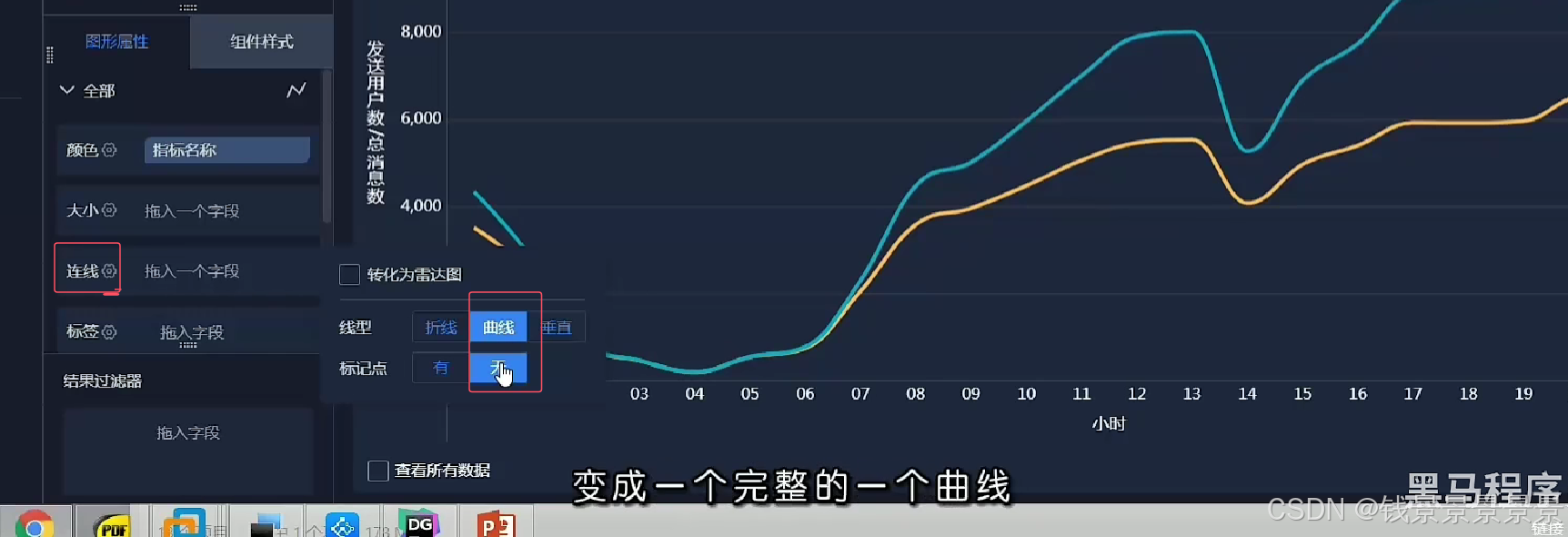
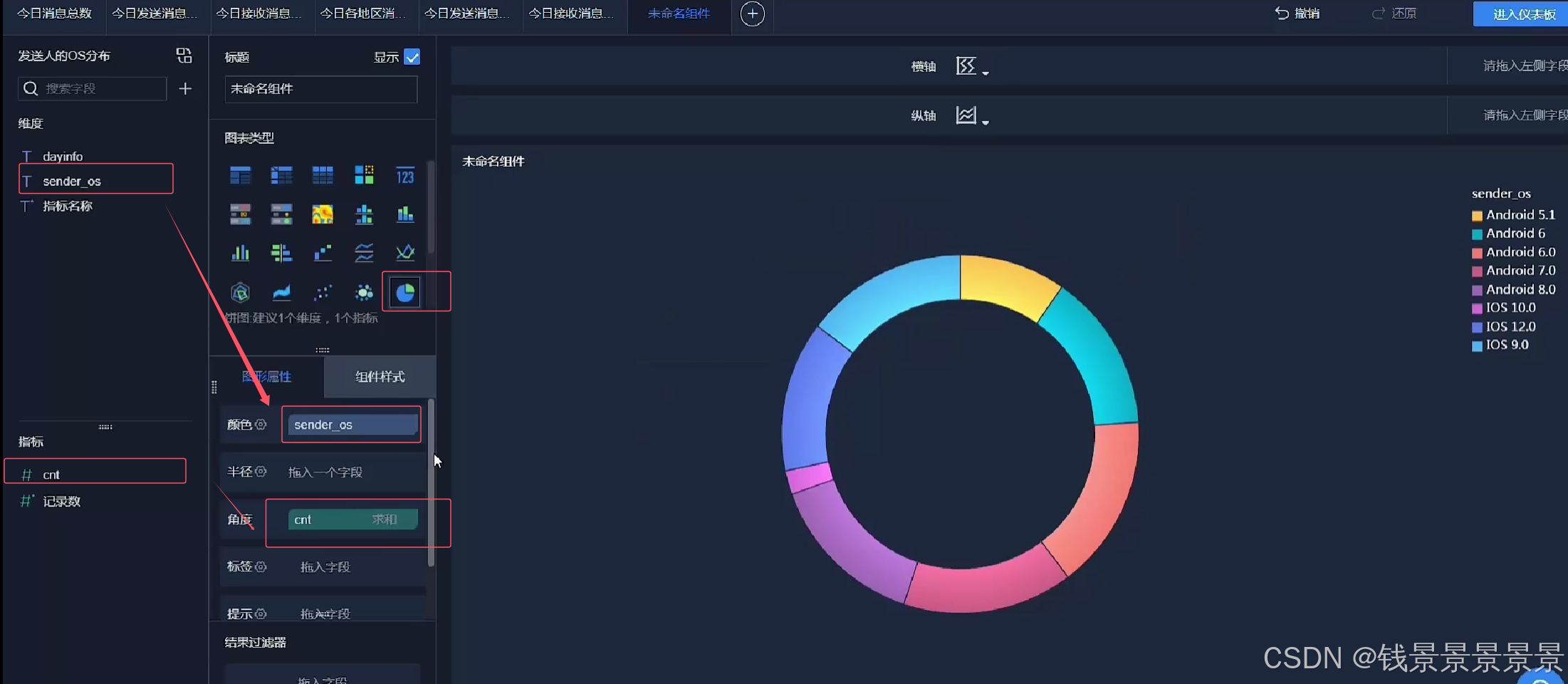
13.基于fineBI实现可视化报表-饼图、词云、趋势图构建
饼图

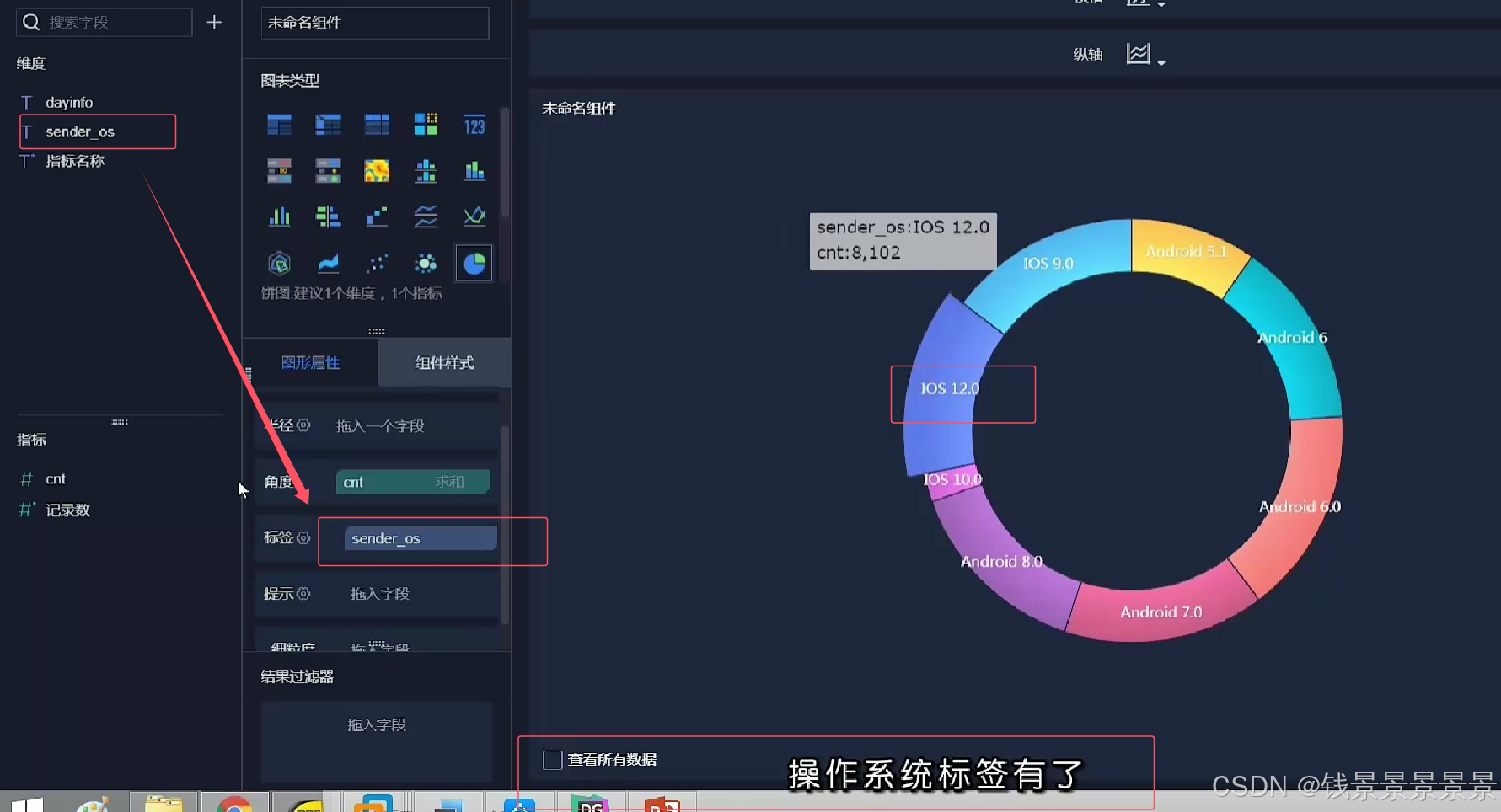
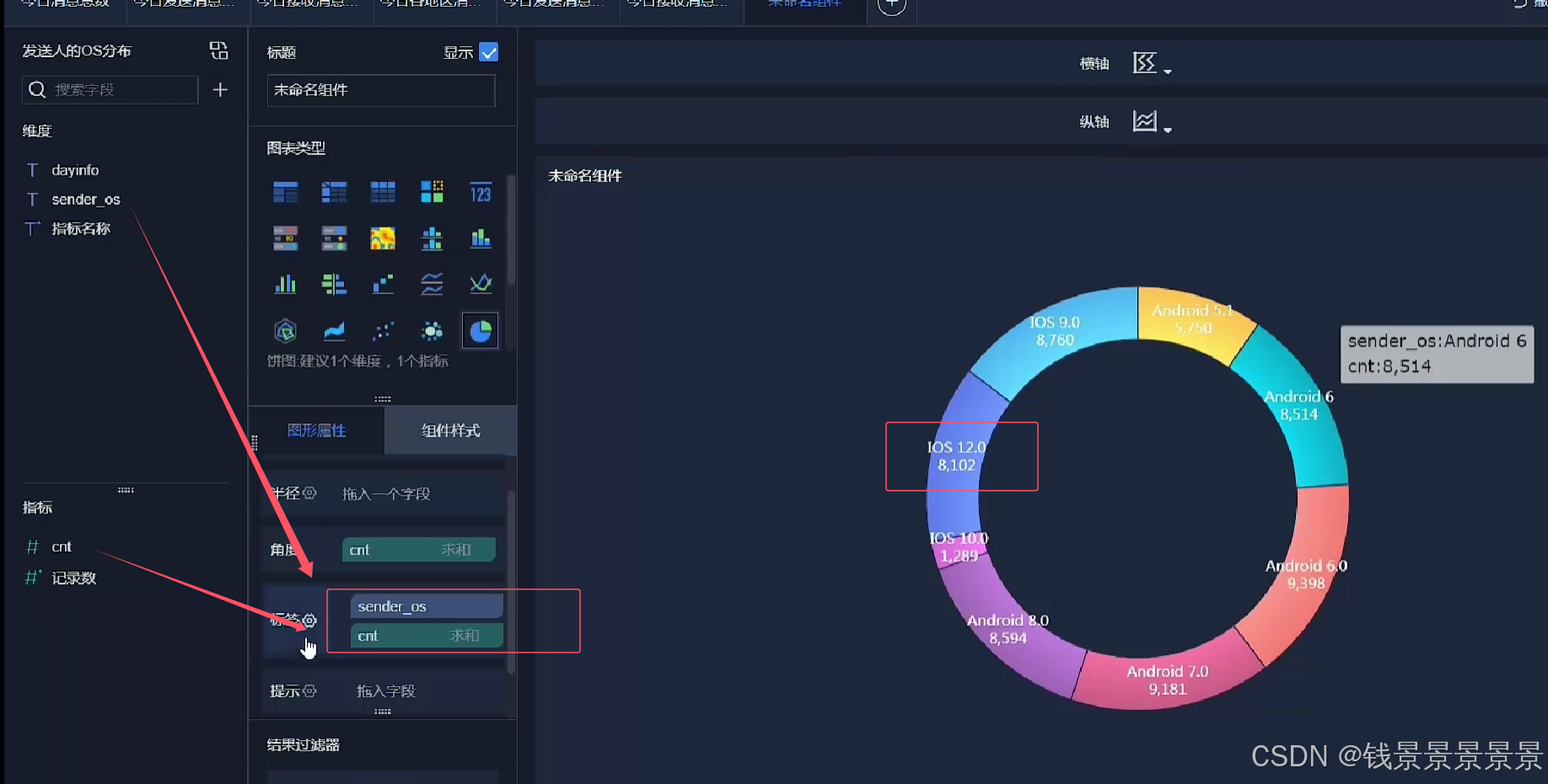
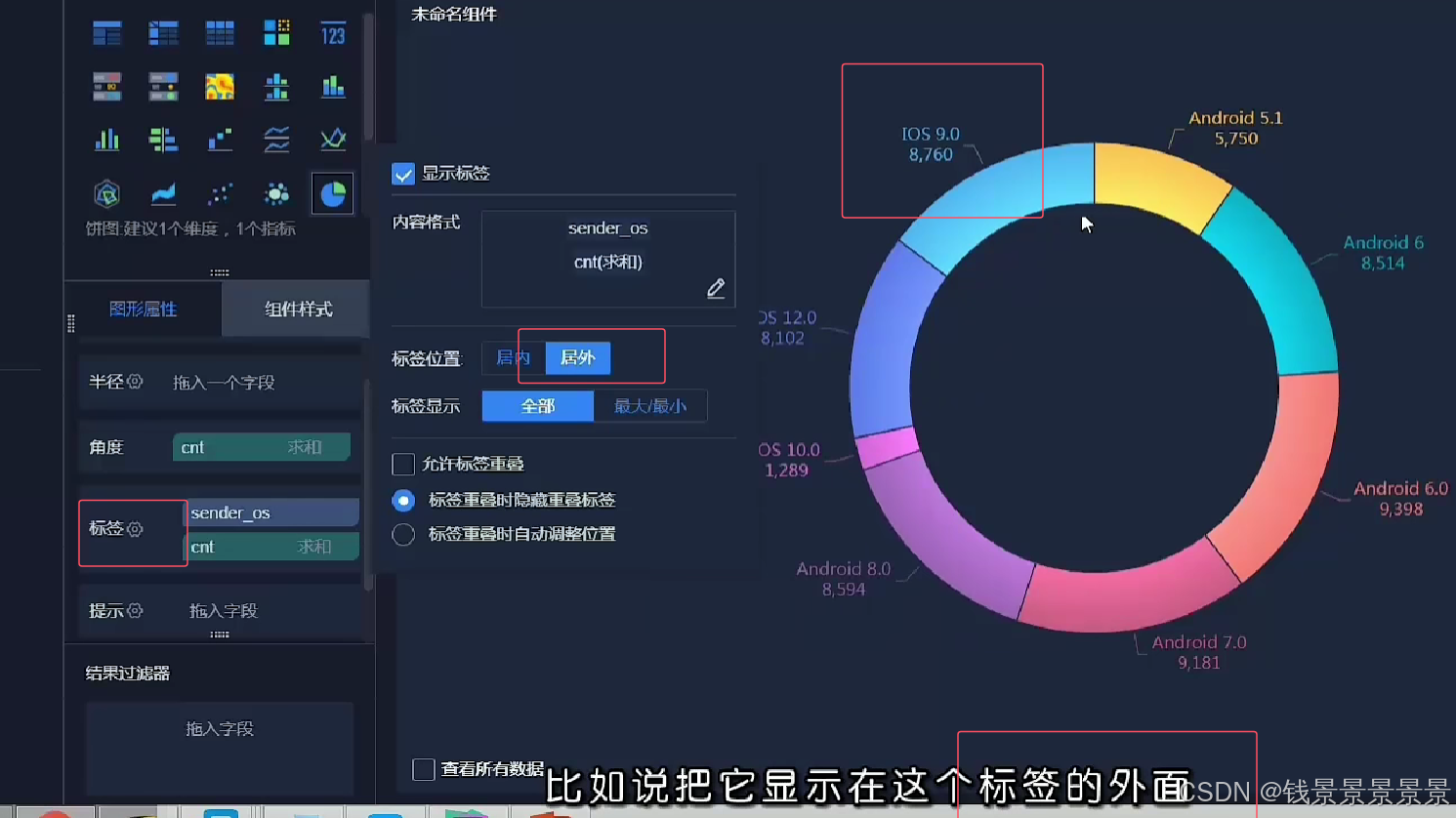
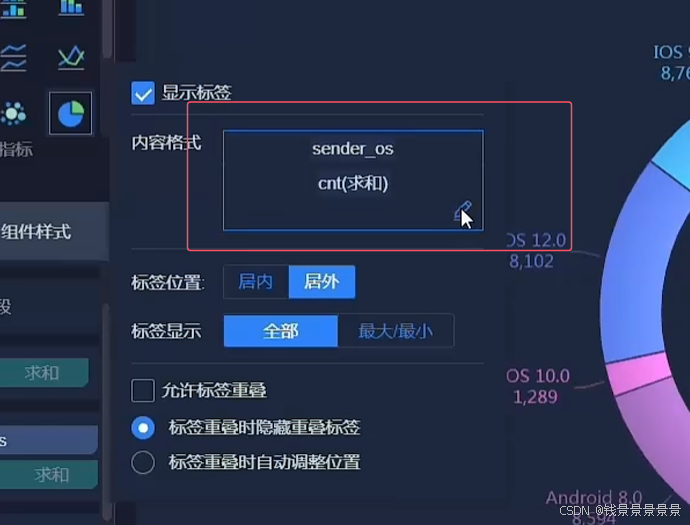
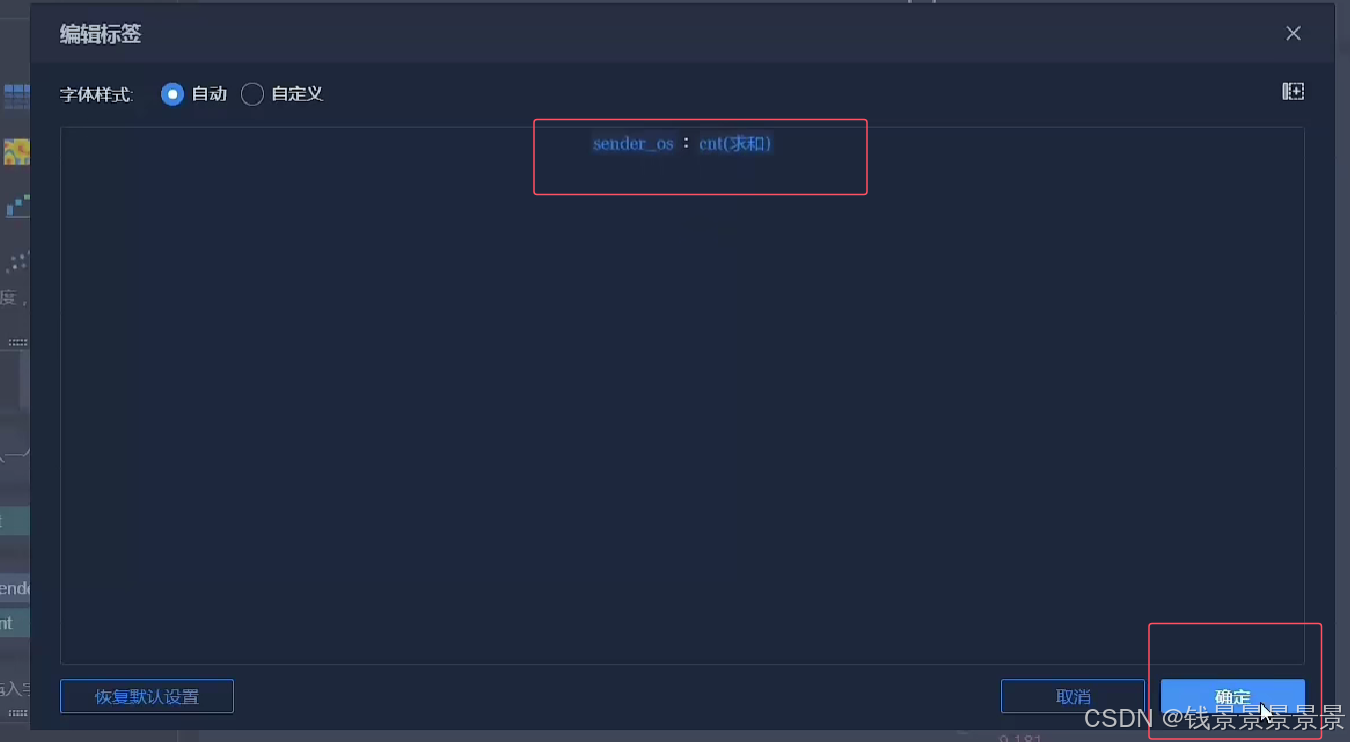
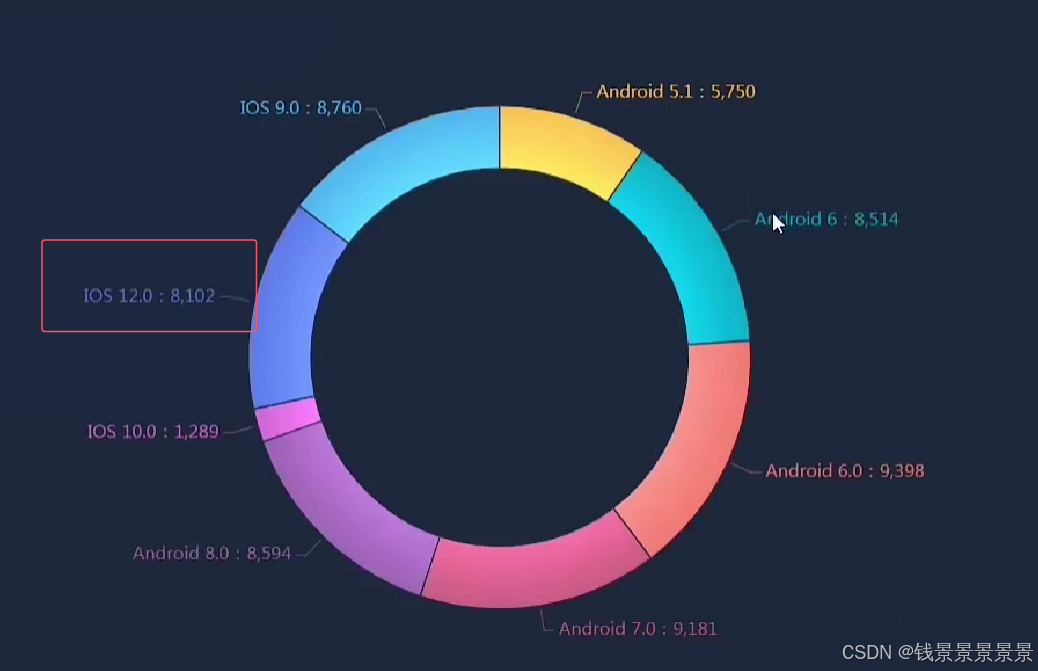
==================================================================================================================================================
词云
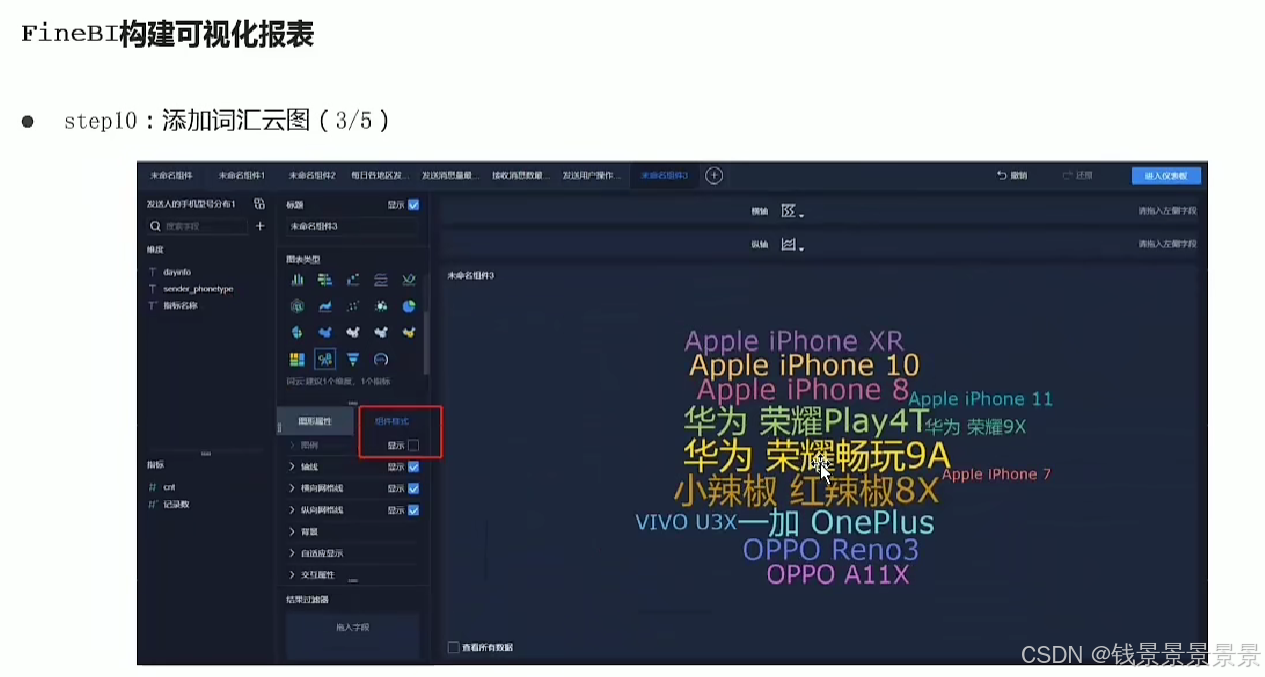
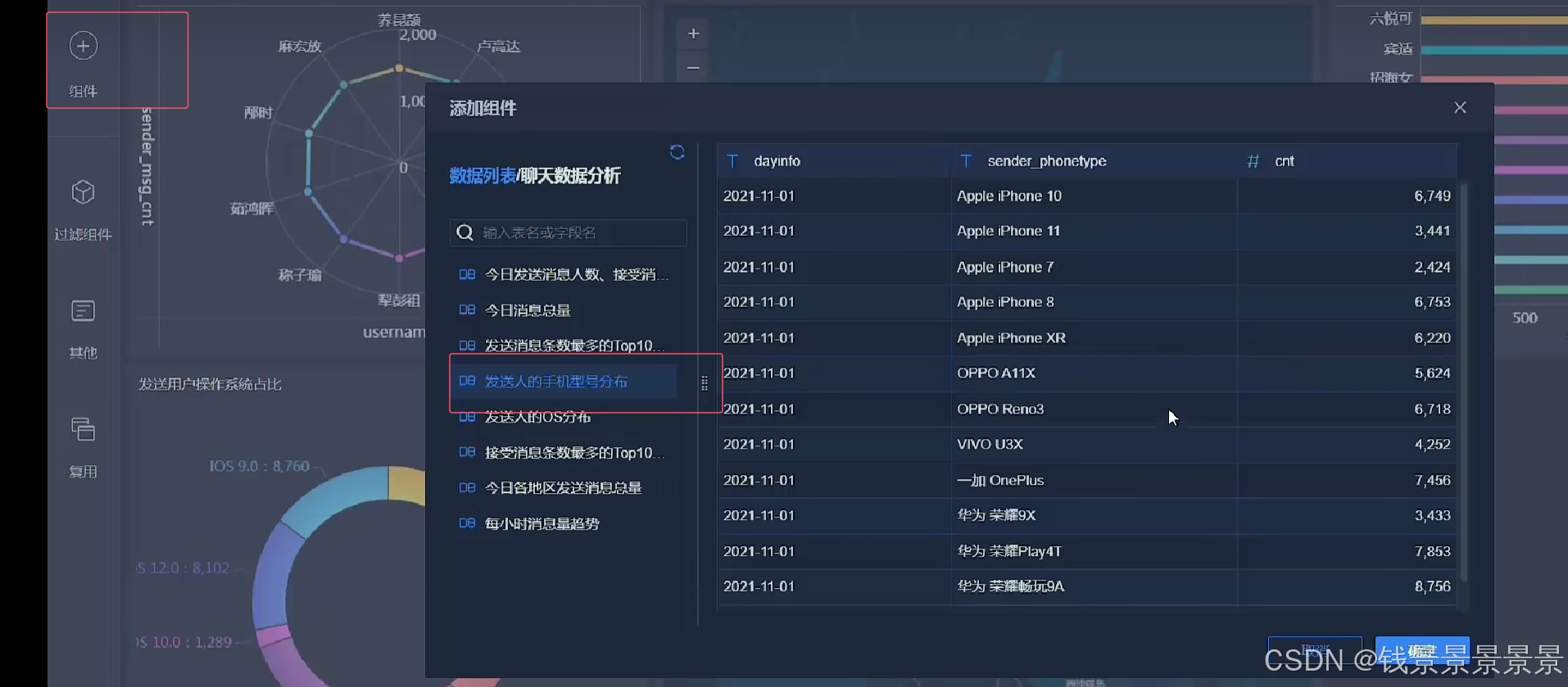
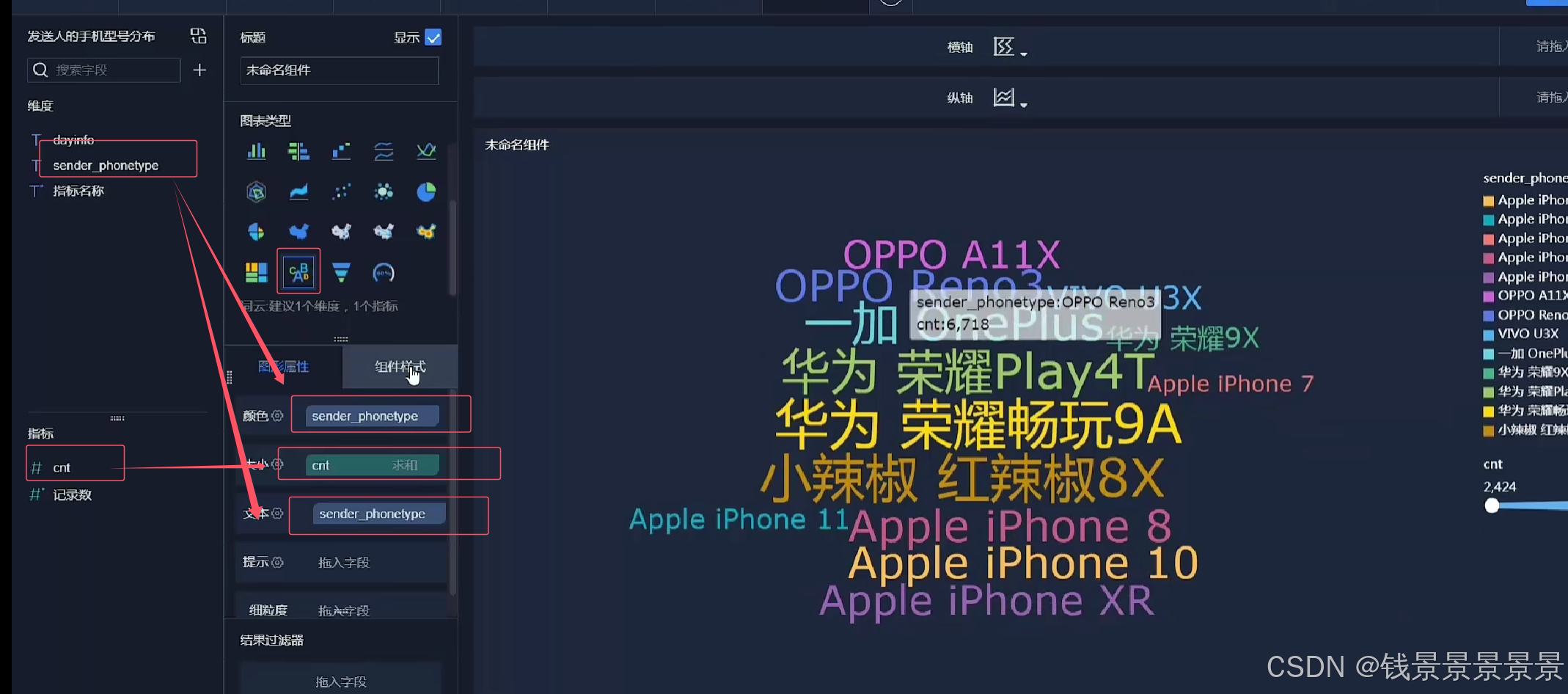

==================================================================================================================================================
词云