实时迁移发送

然后,我们将进入脏 VRAM 传输的活动阶段。 此阶段包括调用脏位平面 DDI 来获取 VF 帧缓冲区的快照,然后将这些页面从 GPU 分页到之前准备好的 CPU 缓冲区。
在传输中的某个阶段,VM 及其所有虚拟设备都会暂停。 可以停止为来宾安排 VF,此时,可以为 PF 提供额外的时间分区来完成内容分页。 由于 VM 中的 VF 和 vCPU 都已暂停,因此在此之后,被迁移的内容(CPU 或设备本地内存)不应再有任何变化。
暂停的迁移发送
脏页的最后一次迭代是在暂停时传输的。 此时,系统会调用最后的设备和驱动程序状态碎片,这些碎片在激活时是可变的,但在之前的准备过程中无法传输。 此状态可以是另一端需要重建的任何状态、任何跟踪结构,或者一般来说是最终还原目标方 VF 状态所需的所有信息。
实时迁移拆解
最后,一旦 VM 及其所有虚拟设备将其状态转移到新的物理实现中,源端就可以清理 VM 残余。 缓冲区和其他迁移状态被清除,并且 vGPU 会被销毁。
目标主机的时期
下图演示了目标端迁移状态。
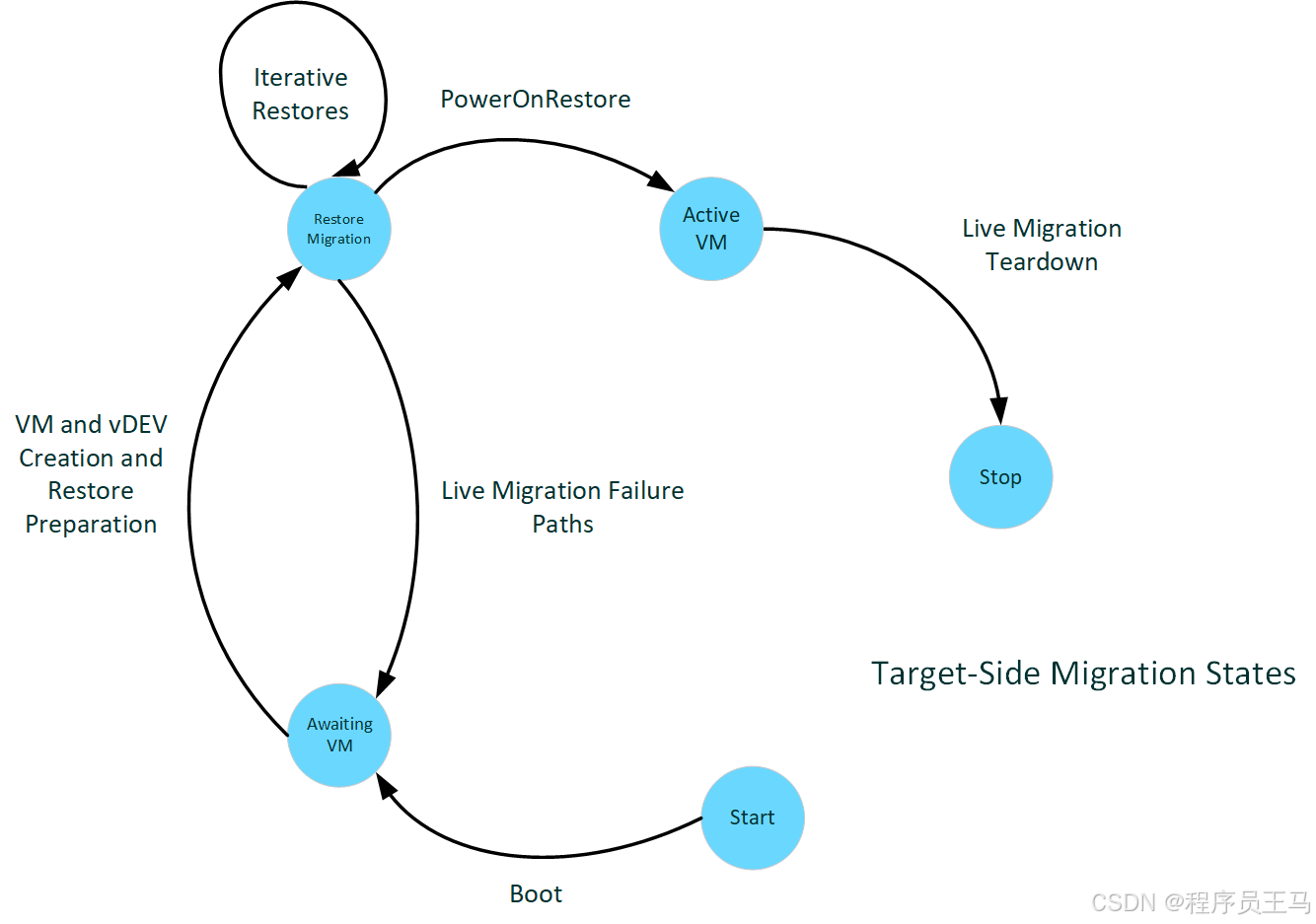
目标端启动
目标机上的启动与源机上的启动相同。 启动是针对整个系统的,在整个生命周期中,系统可以是不同 VM 的源和目标。 驱动程序只需指定支持实时迁移即可参与。
实时迁移接收准备
在目标端,VM 将像新 VM 一样开始构建。 创建 VM 和虚拟设备。 此创建过程包括虚拟 GPU,创建时所用的参数与在源端创建时相同。 创建完成后,会收到验证数据并将其传递给驱动程序,以验证目标端是否与源端兼容,从而还原 VM。 此时,应确保任何可能影响兼容性的因素,包括驱动程序版本、固件版本以及目标系统和驱动程序的其他环境状态。 驱动程序将配置为允许 PF 访问通常分配给 VF 的分页的所有时间,而 VF 尚未处于活动状态。
实时迁移接收

接收脏页数据的过程与源阶段类似,只是分页方向是从 CPU 缓冲区到 VRAM。 所有传输都是在 VF 暂停时进行的,因此整个传输都可以在 VF 预算内完成。
VM 启动和拆解
完成所有 VRAM 迁移后,vGPU 将有机会设置需要传输的其他状态(最终可变保存数据)。 然后,我们在目标机上启动 VM 并拆解迁移状态,包括用于传输的缓冲区。
性能目标
实时迁移的一个重要部分是其响应能力。 具体而言,它会最大程度地减少虚拟化的停机时间,因为虚拟化不会在外部做出响应(无论是对虚拟化的用户,还是可能进一步连接到的任何终结点)。 许多网络堆栈协议在重试/重建失败前,远程机器上的超时时间都很短,因此一旦超时,就会对用户造成干扰。 作为一个常见的固定目标,传输和启动的总停顿时间应低于四分之三秒(750 毫秒),这样就能将脱离接触的时间降低到许多最常见的堆栈超时时间之下。
此外,如果可能,活动系统的性能变化不应引发其他终端用户的中断。 在使用这些 DDI 的设备中,系统不应通过减慢时间片计划来显著提高 TDR 的速率。 现在,我们预计大多数 TDR 都不是长数据包,而是挂起的设备,执行数据包的时间增加一倍或两倍应该不会使大多数数据包达到超过数秒的明显超时。 但需要注意的是,在总体性能情况下,不要触发超时。
设备驱动程序接口
一般来说,实时迁移 DDI 指的是 WDDM 和 MCDM DDI 的一般概念,尤其是 GPU-P 虚拟化 DDI。
-
hAdapter 通常是指表示此驱动程序管理的特定设备的句柄令牌。 系统枚举了多个物理设备的系统可能会让一个驱动程序管理多个 hAdapter,因此 hAdapter 会本地化到特定设备。
-
vfIndex 标识引用的是哪个虚拟函数/vDEV。 它本地化到特定的虚拟设备。 它有时也被称为分区 ID。
-
DeviceLuid 还会本地化特定的虚拟设备,但仅限于使用虚拟设备管理 UMED 界面的语言。
-
在引用存储在设备上的内容(如 VRAM 储备)时,SegmentId 可识别特定的 VidMm 段曝光。
关于接口定义的说明
本文指的是动态调整大小的结构。 这些结构是通过动态大小的数组实现的,参考页描述如下:
size_t ArraySize;
ElementType Array[ArraySize];其中,接口在结构的前面传递了一个数组的大小,然后当提供数组时,接口对象的解析就会遍历这个数组中的元素。 这些声明在 C/C++ 语言中无效,因为这些语言表达的是静态大小的片段。 首先读入静态大小的结构,然后在代码中进行动态解析。