1.引入:为什么需要分布式存储?
一个服务器能存入海量数据吗?显然是不能,所以构建分布式解决了存入问题.多台服务器的协调工作也是性能的横向扩展.
总结:
1.数据量太大,单机存储能力有上限,需要靠数量来解决问题
2.数量的提升带来的是网络传输、磁盘读写、CPU、内存等各方面的综合提升。分布式组合在一起可以达到1+1 > 2的效果
2.分布式的调度:
一.去中心化模式: 没有明确的中心点,协调工作 eg:kafka
二.中心化模式: 以一个节点为中心,基于中心点工作 eg:hadoop
3.主从模式(master-slaves):(中心化模式):一台master管理多台slaves工作
4.hdfs:(全称:hadoop distributed file system):也就是Hadoop分布式文件系统,是一个Hadoop的中间组件.主要解决海量数据的存储工作
5.hdfs集群架构(既然是中心化模式,那就有个中心点):
主角色:namenode(管理hdfs整个文件系统,管理database),带着一个secondarynode(辅助)
从角色(slaves):datanode(负责数据存储)
6.搭建集群:
主要的就:配置软连接
workers文件
hadoop-env.sh文件
core-site.xml文件
hdfs-site.xml文件
创建数据目录,修改文件的所属用户与所属用户组
格式化hadoop
也可以看我的专栏
命令: start-dfs.sh
主namenode进程有:
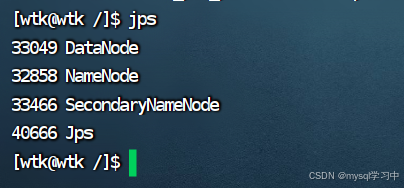
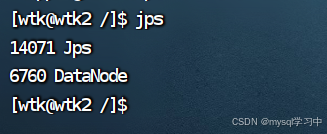
从节点进程:
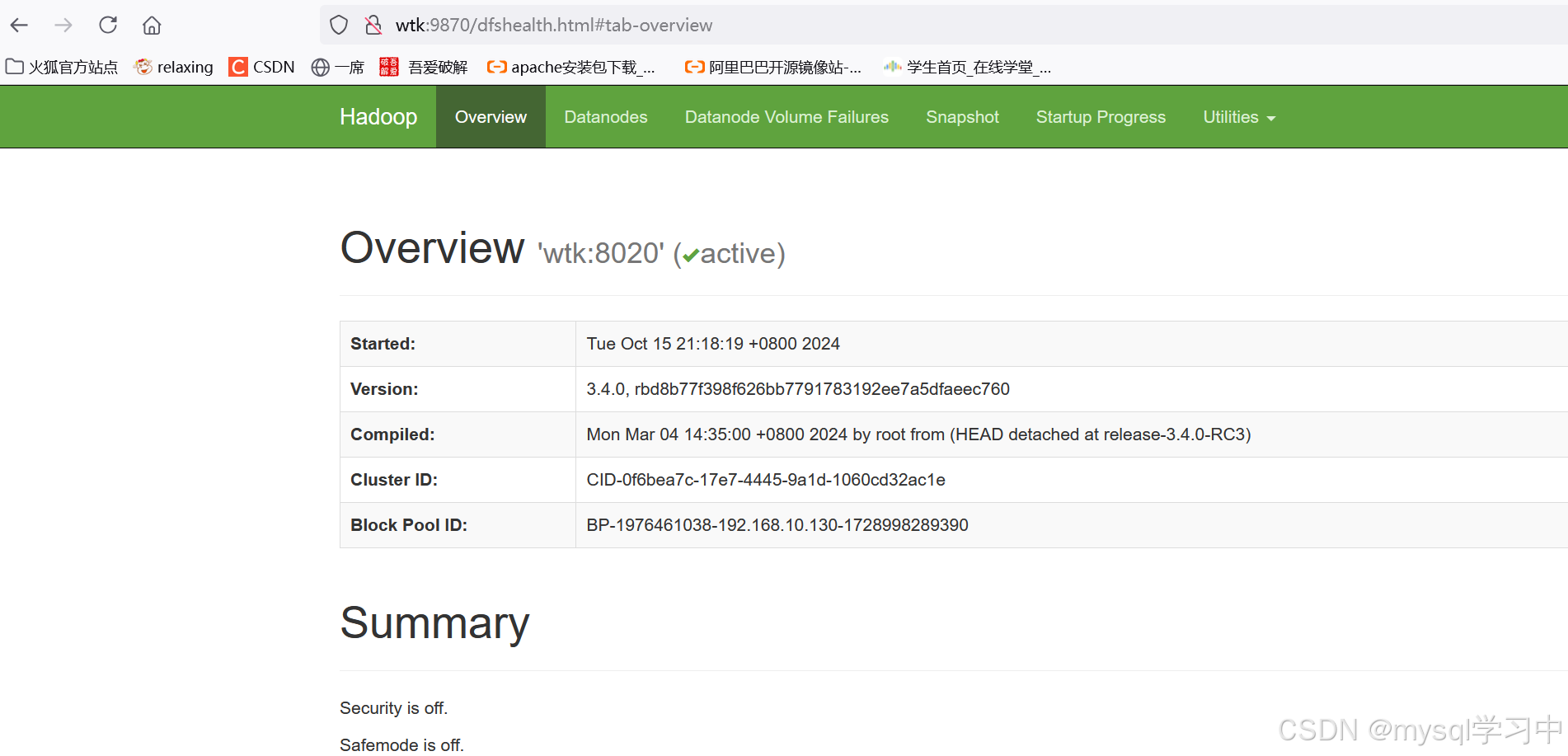
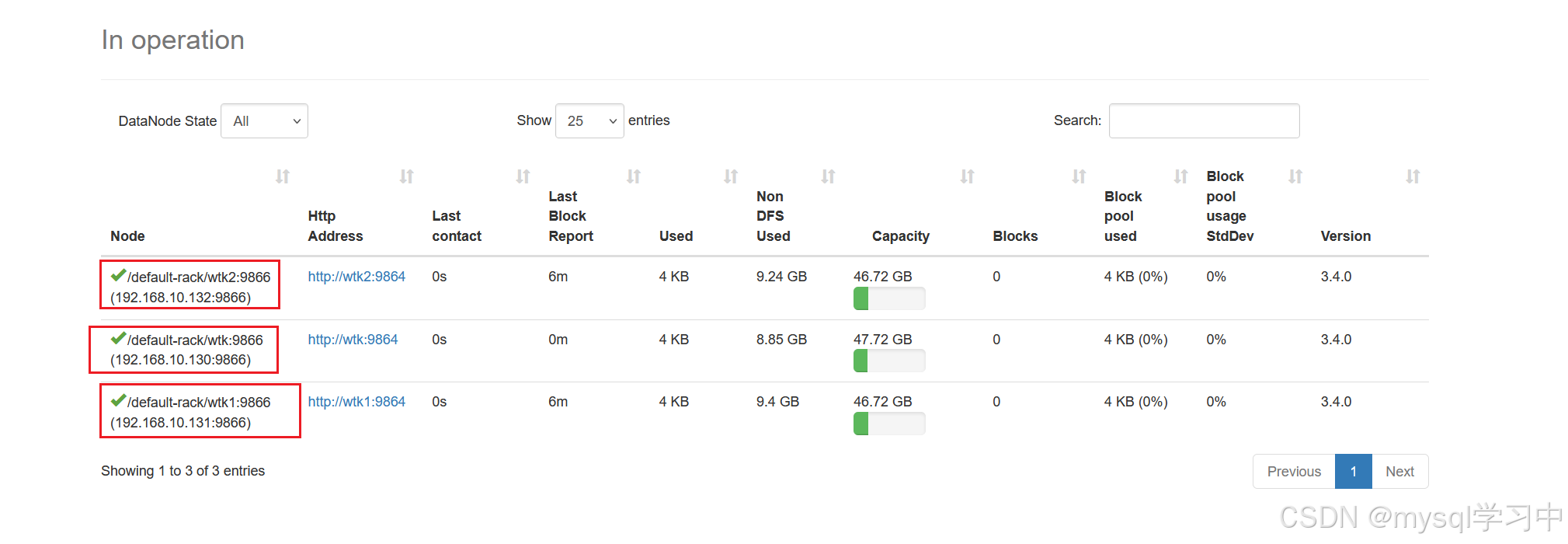
验证:主机名:9870/
8.代表集群机子数量
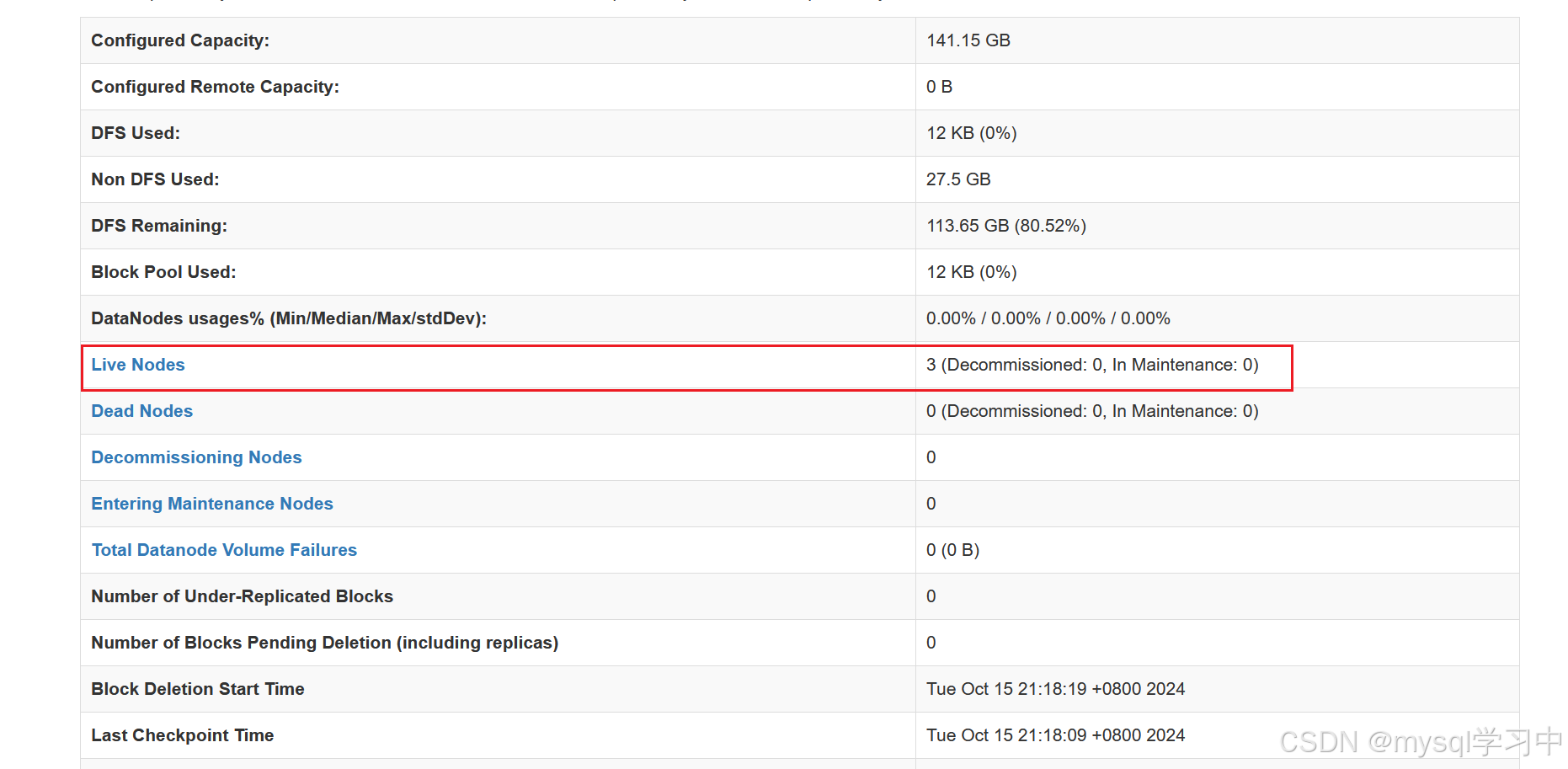
点进去就可以看到主机的信息了
配置好了记得快照
9.stop-dfs.sh关闭集群
10.然后关机即可
配置完成