已知有如下格式的日志文件,请统计每天的error次数。
2022-03-01 error:no boot disk has been detected
2022-03-01 warning:hardware failure detected
2022-03-01 error:flash download failed
2022-03-02 error:1d returned 1exit status
2022-03-05 error:expected expression
2022-03-05 warning:the high memory area
1.本地模式
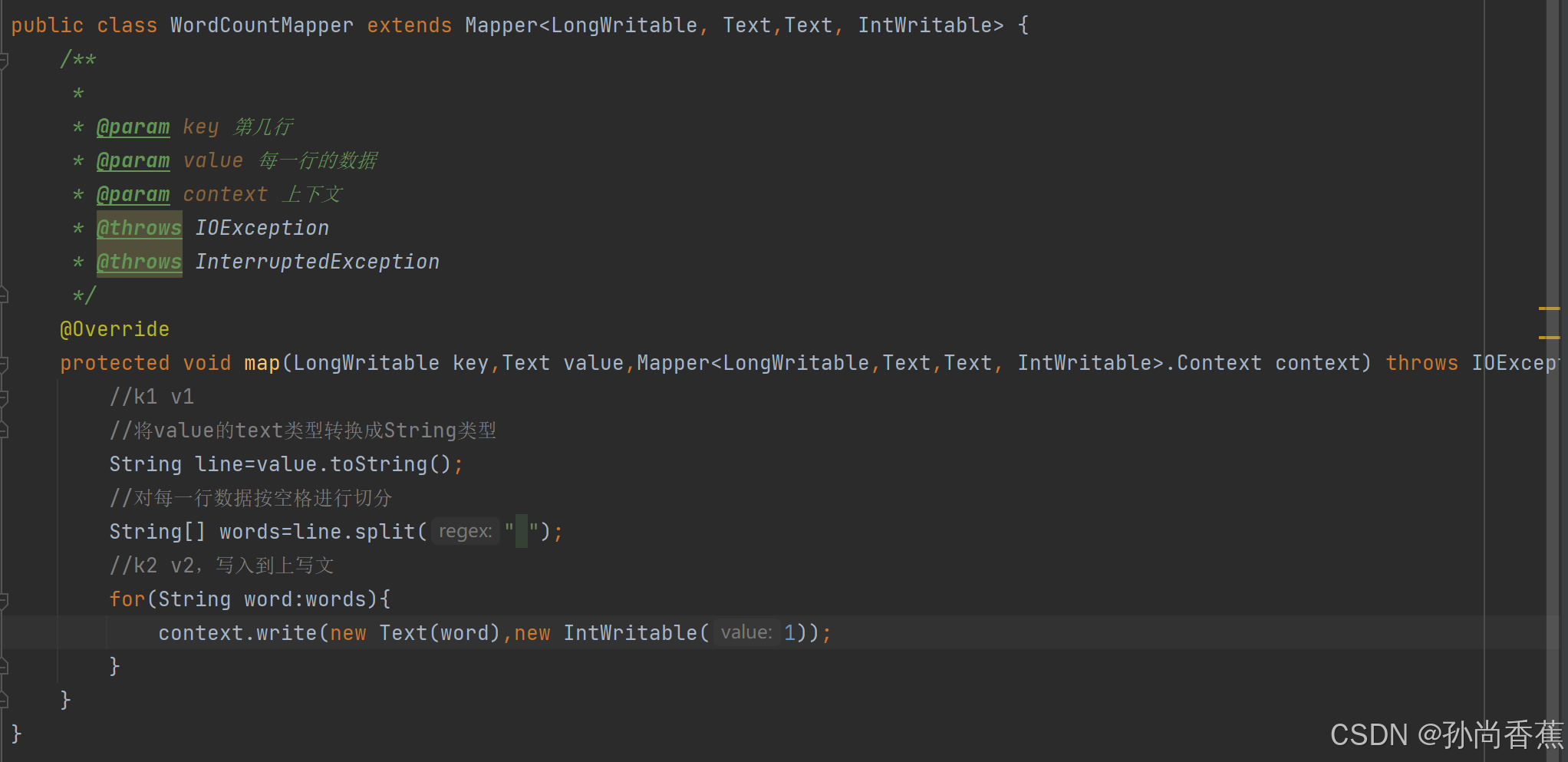
(1)自定义mapper组件,map()方法指定的处理逻辑为:首先将每个键值对中的值转换为String类型,即获取数据块的每行数据;然后根据分隔符空格将每行数据拆分为多个单词,并将这些单词存放到数组;最后遍历数组以获取每个单词,将每个单词与值1组合成新的键值对<单词,1>,并输出到Reduce Task. 代码如下:
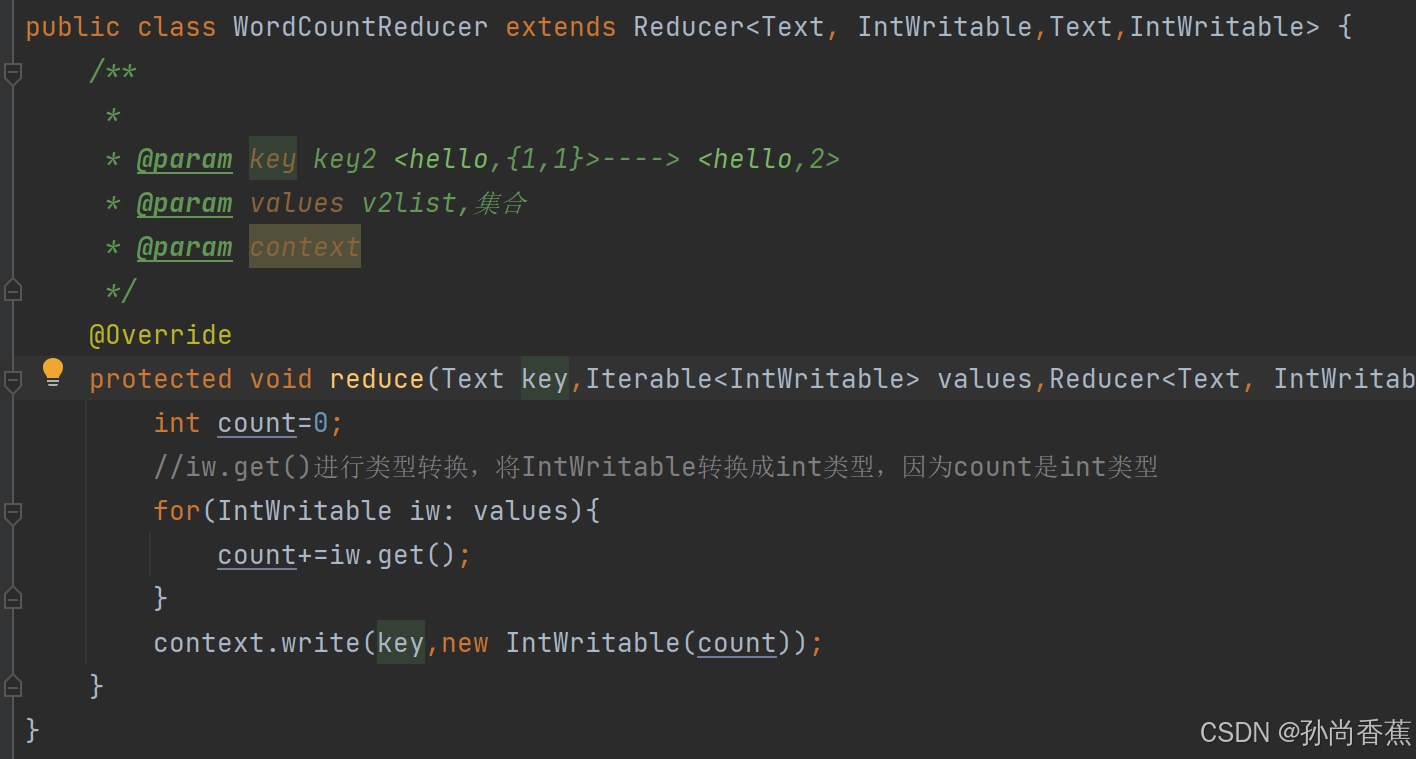
(2)自定义reducer组件,使用reducer组件处理数据,对mapper自建输出到reducer组件的数据进行处理,将相同对应的值累加,从而统计每个单词的出现次数,具体代码如下:
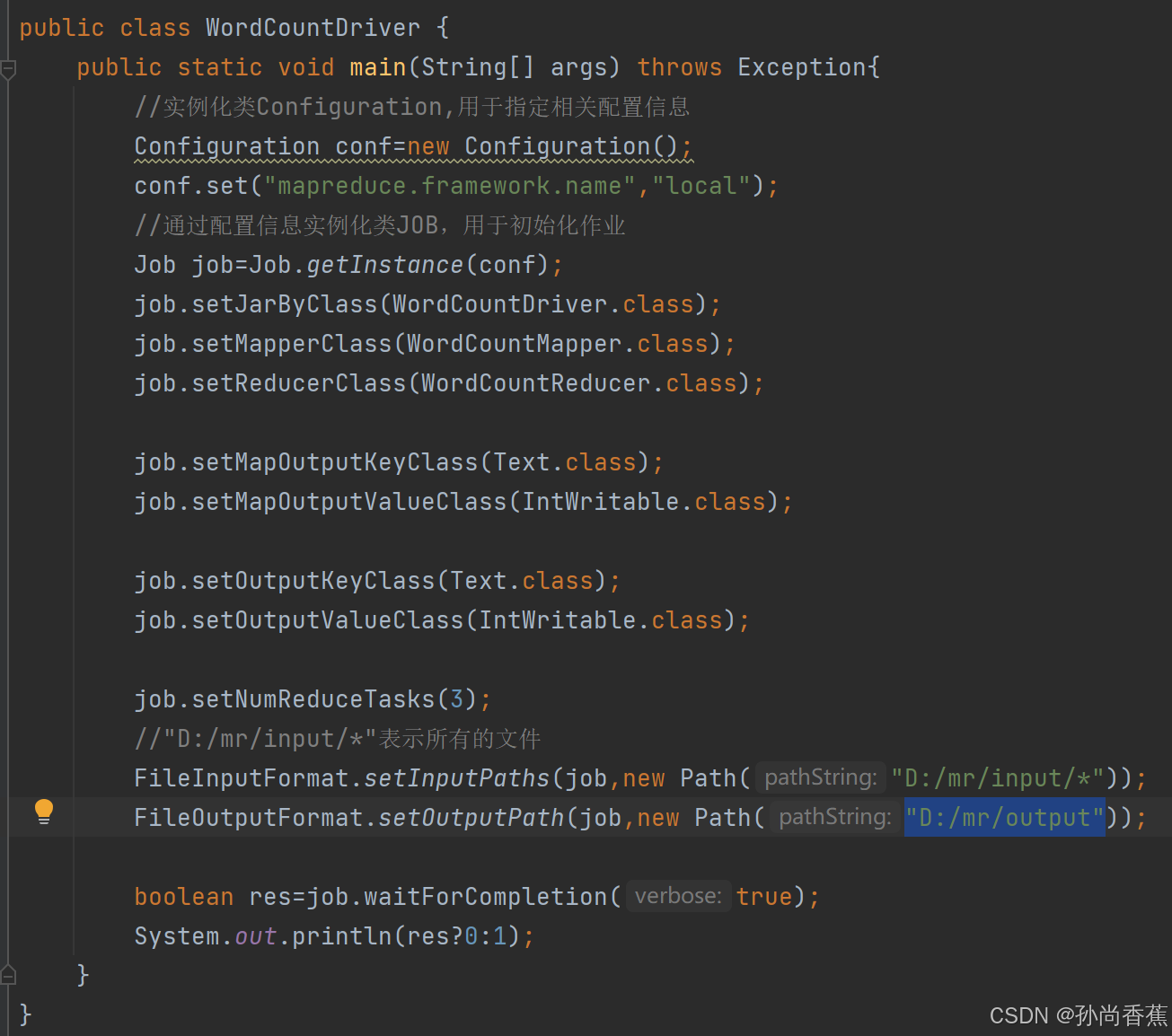
(3)编写驱动类,具体代码如下:
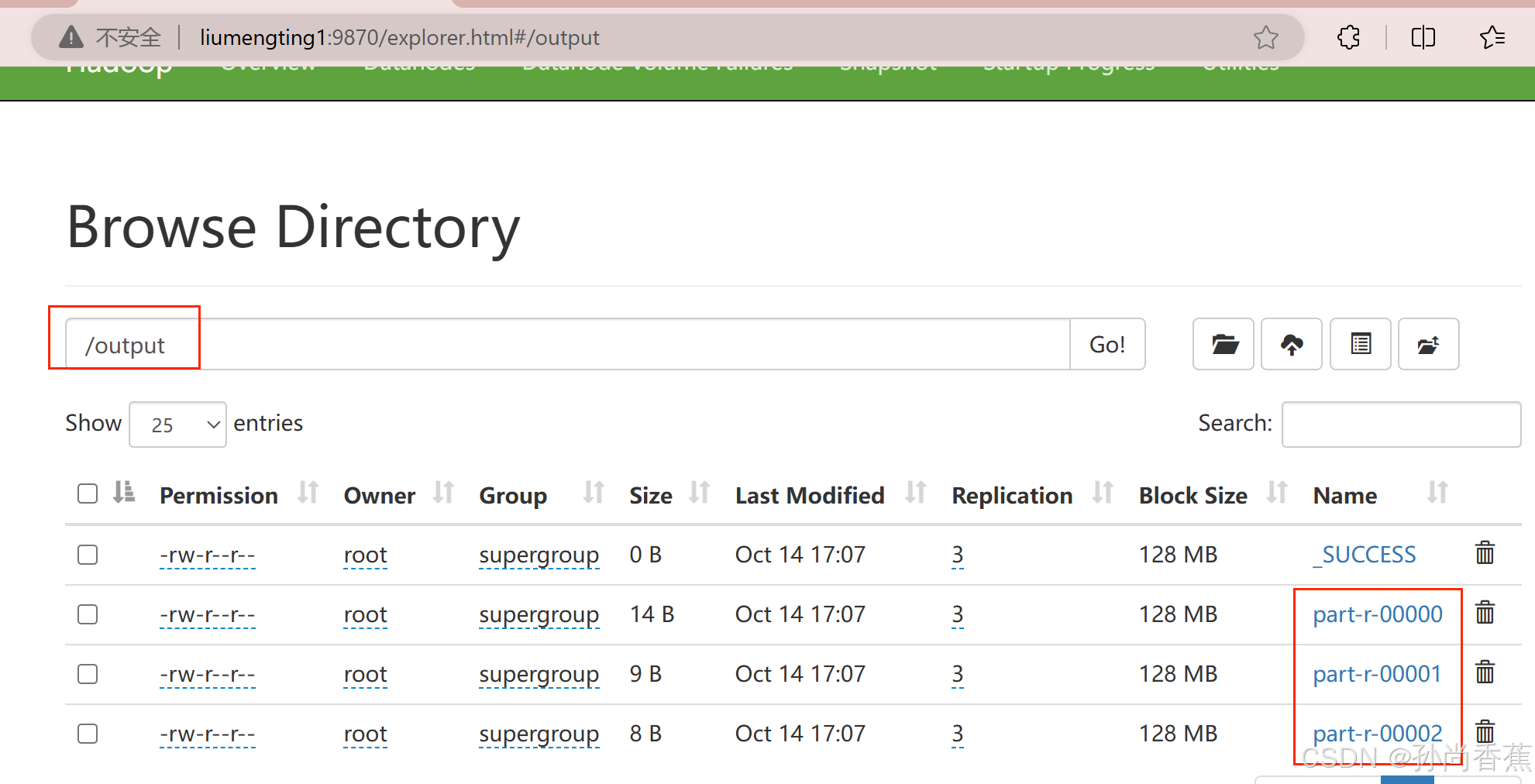
(4)运行结果:

2.集群模式
(1)mapper组件和reducer组件的定义和本地模式一样。
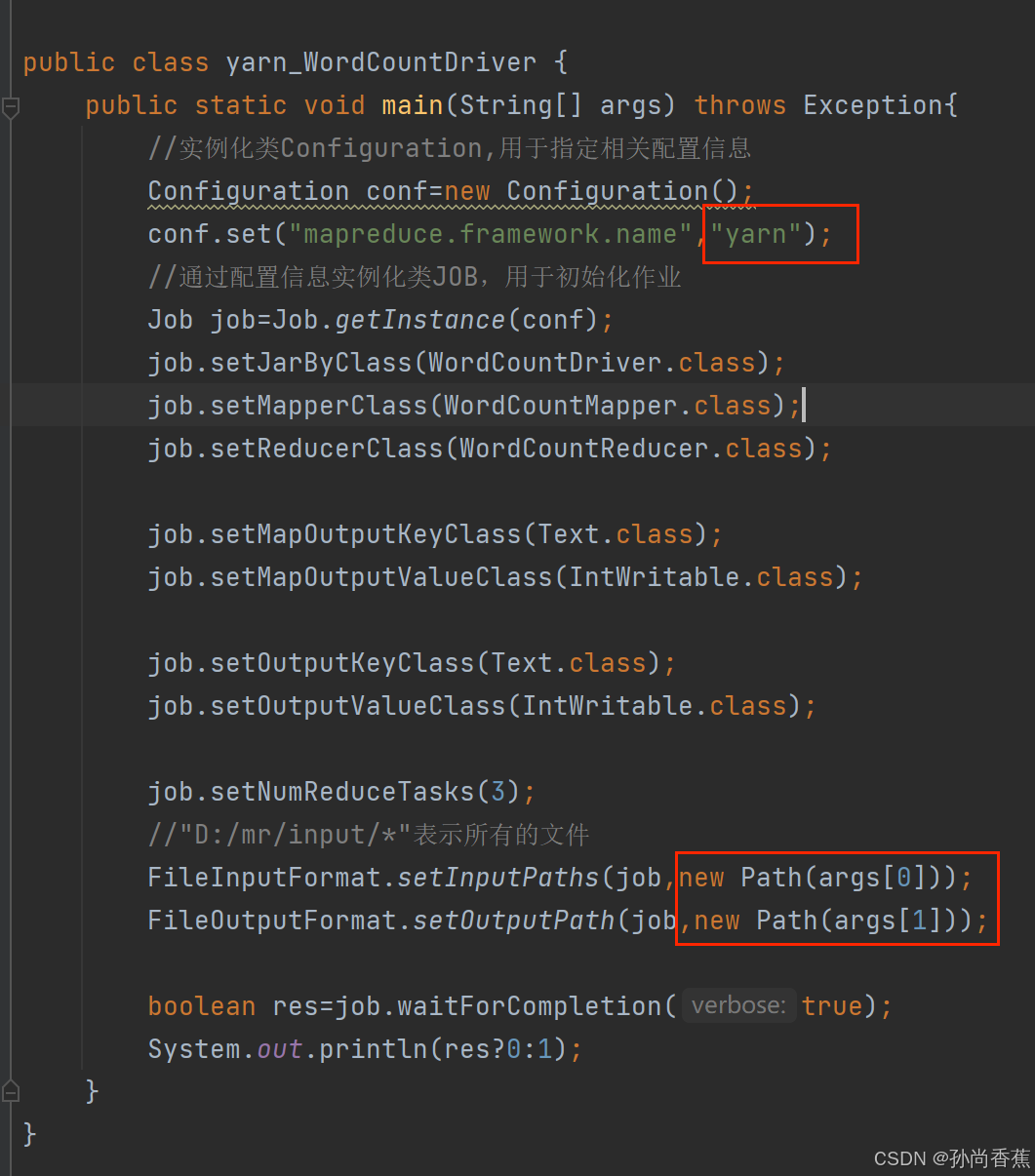
(2)驱动类需要将local改为yarn,文件的路径改为args[0]和args[1],代码如下:
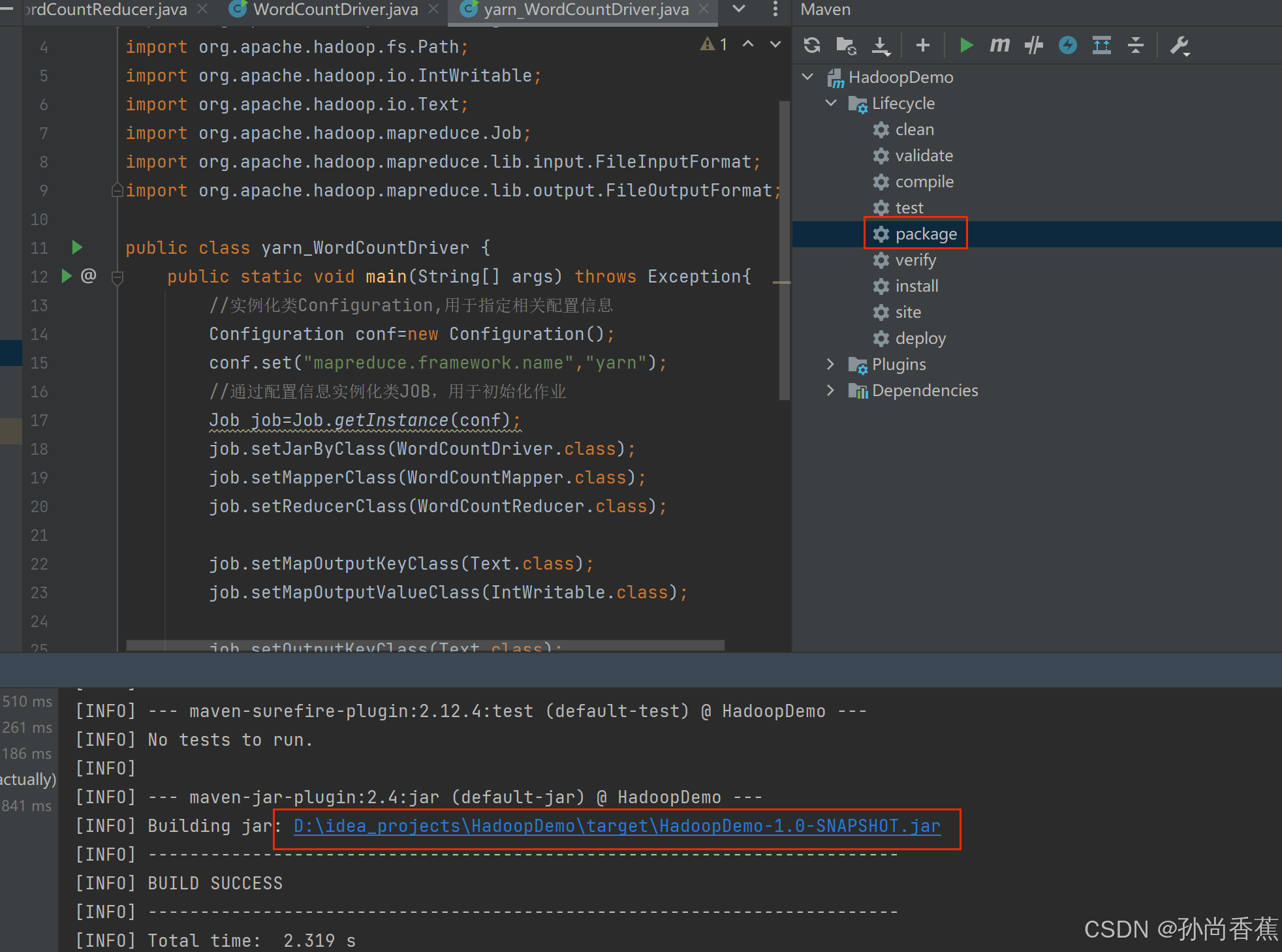
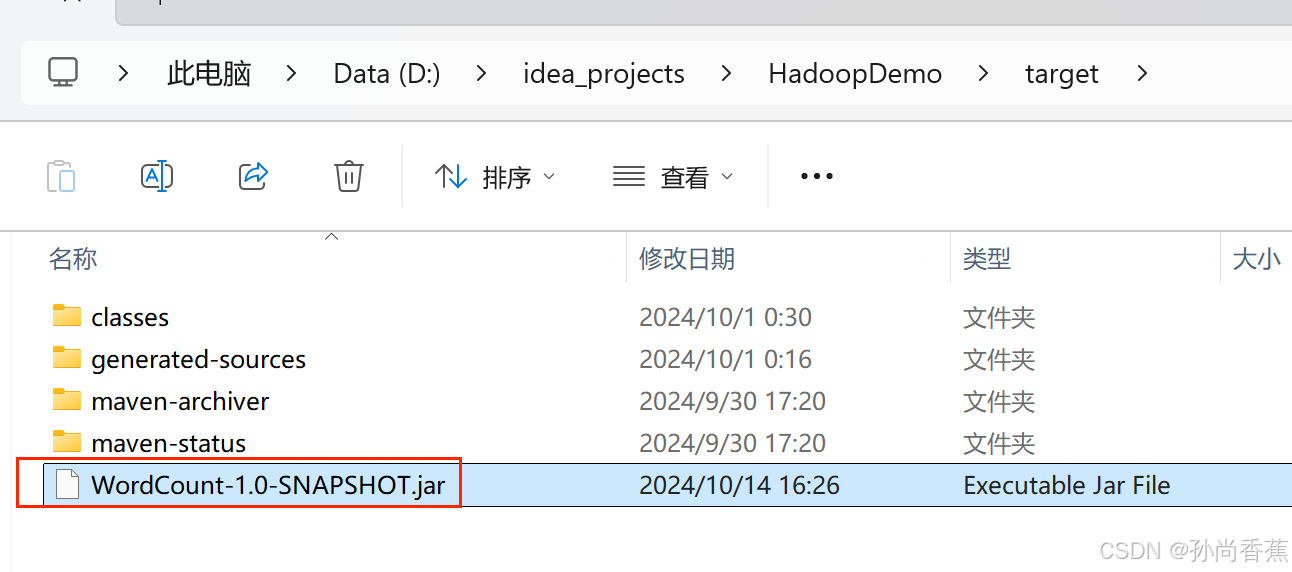
(4)将jar文件重命名:
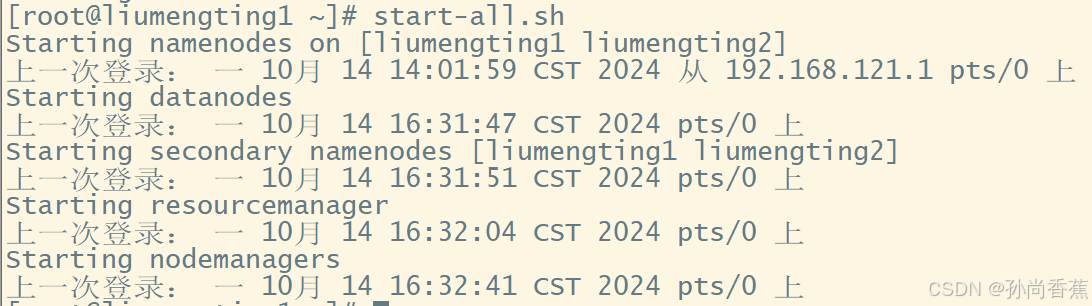
(5)使用start-all.sh命令开启集群:
(6)使用rz命令上传jar文件:
(7)在HDFS上创建input文件夹:
(8)编写txt文件,并将该文件上传到HDFS上的/input目录下:

(9)在jar文件所在目录执行如下命令,将MapReduce程序提交到YARN集群运行:

(10)运行结果: