前言
在现代城市基础设施中,路灯控制箱起着至关重要的作用,它不仅负责路灯的开关控制,还与城市的照明安全息息相关。由于控制箱可能分布广泛且数量众多,当这些设备出现故障时,及时的维修至关重要。然而,如何快速识别使用电子摄像头拍摄的各角度的照片,以及记录控制箱编号及相关的维修电话成为了一个重要问题。解决这一问题有助于提升城市管理部门的响应效率,减少故障修复时间,从而保证城市照明的正常运行,提高居民的生活质量。
相关研究
现有的研究主要集中在图像识别与字符识别技术上。OCR(光学字符识别)技术被广泛用于从图像中提取字符信息,并且在路灯编号等标识信息的自动化识别方面具有显著的应用潜力。例如,基于深度学习的OCR技术已经能够较为准确地识别多角度、不同光线条件下的文字信息。具体来说,Convolutional Neural Networks (CNN) 和 Recurrent Neural Networks (RNN) 等深度学习模型【1】已被应用于图像中的文字提取,尤其在处理复杂的背景时表现较好。
另外,物联网(IoT)与智慧城市的结合也推动了该领域的进展。一些研究人员提出了将摄像头与物联网传感器结合的方案,用于监测和维护城市基础设施。例如,现有研究提出了一种基于图像处理和物联网的城市照明管理系统,可以通过摄像头自动识别路灯设备的编号,并通过无线传感器网络将故障信息实时发送给管理中心【2】。
然而,目前的研究大多局限于实验室环境或小规模试验。实现大规模、自动化的控制箱识别和故障信息处理仍然面临着挑战,例如环境光线变化、摄像头角度、图像噪声等问题。
方法
由于OCR技术对于图像中字符的识别顺序受到字符文本框在图像中的(x,y)坐标位置的影响。故对于同一格式的路灯控制箱箱牌,由于拍摄角度、年久标识牌老化弯曲等,便无法具体得知识别到的键名(标签名,如“灯箱号:”)和键值(标签值,如灯箱具体的号码)的前后一一对应关系,就无法第一时间或者使用程序大批量高效率的识别和分类众多信息。
因此,本文的从该角度入手,由于具体的字符识别需要大量的数据集和训练成本,故本文在实现过程中使用了现有的OCR技术(EasyOCR),在识别图像中的标签字符的基础上,同时保证了识别的先后顺序,为下游任务如分析信息等提供了一定基础。
具体来说,若图像向右上倾斜,有一行的内容是“灯箱号:12345”,那由于“12345”文本框的纵坐标值高于“灯箱号:” 文本框的纵坐标值,故识别结果会是“12345;灯箱号:”就有可能会引起歧义。因此,本文先对原始图像旋转,使得大部分内容都呈水平状态,再使用OCR技术进行分割和识别,以下是算法的具体介绍:
将图像转换为灰度图
将彩色图像转换为灰度图像是图像处理中的一个常见步骤【3】。这是因为灰度图像包含了足够的亮度信息,能够简化后续处理。对于OCR任务,色彩信息往往不是必需的,而亮度变化能更好地反映出字符的边缘。使用的公式是:
其中,IR、IG、IB是红、绿、蓝通道的像素值。
边缘检测(Canny)、边缘检测优化(使用自适应阈值处理)
Canny边缘检测是一种流行的边缘检测算法,用于识别图像中的重要特征(如物体的边缘),从而为后续的图像处理(如分割、识别等)提供基础。边缘检测有助于简化图像数据,保留重要的结构信息,同时消除噪声。Canny边缘检测算法基于多个步骤:使用高斯滤波器平滑图像,以减少噪声对边缘检测的影响;使用Sobel算子计算图像的梯度,识别出可能的边缘;在梯度图上保留局部最大值,精确定位边缘;应用两个阈值,分类强边缘和弱边缘(代码中以参数的形式体现);通过连接强边缘和相邻的弱边缘,形成完整的边缘。高斯滤波器公式如下:
其中,是标准差,用于控制平滑程度。
由于后续操作需要检测图像中的直线,由于图像的拍摄光影不同且是不可预知的,为了得出相对最好的结果,在此时引入边缘检测优化技术。自适应阈值处理是为了将图像转换为二值图像,突出文本的区域。通过对图像的局部区域计算阈值,可以更好地应对光照不均匀的情况。使用的python函数 cv2.adaptiveThreshold() 中的参数如 11(块大小)和 2(常数C)影响了阈值的计算,前者决定了每个局部区域的大小,后者则用于调整每个区域的阈值:
其中,是以点(x,y)为中心的区域。
使用霍夫变换检测直线
霍夫变换是用于从图像中检测几何形状的技术【4】。通过将每个边缘点映射到参数空间(通常是极坐标的形式),可以有效识别出图像中的直线。对于每个点 (x, y),其对应的极坐标参数为:
其中,r是到原点的距离,θ 是与水平线的夹角。
旋转图像进行水平矫正
对于图像的旋转,本文首先计算应为水平线的直线在原图中的倾斜角度,然后取所有检测到直线的平均倾斜角度,旋转图像进行矫正,旋转中心为图像中心。
首先计算直线的斜率,如果斜率小于1,即纵坐标值的变化小于横坐标值的变化,则认为是水平线,因为若取图中所有识别到的直线的倾斜角度均值,垂线在原图中的角度会对结果产生较大的误差。使用如下公式:

通过计算所有识别到的直线的平均倾斜角度来确定图像的整体倾斜程度。平均倾斜角度 θ可以用公式:
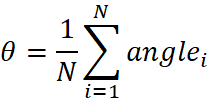
其中N是检测到的直线数量。接着,使用旋转矩阵来旋转图像:

其中 和
是为了保持图像中心不变的偏移量。
使用cv2.getRotationMatrix2D ( ) 函数确保旋转后图像的大小与原图保持不变。
光学字符识别
到此,已经完成了所有图像处理(旋转)部分的内容,之所以没有做直方图均值化、对比度增强等操作是因为EasyOCR已经包含了这部分的内容,以下是对EasyOCR的介绍:
阅读器(EasyOCR)
OCR(Optical Character Recognition),光学字符识别,是最常用的图像文字提取技术。
EasyOCR 是一个基于深度学习的开源 OCR 工具库,由 Jaided AI 提供【5】。它能够识别多种语言的文字,特别是非拉丁字符(如中文、日文、韩文等)。它的背后模型主要依赖于深度学习中的卷积神经网络(CNN)和循环神经网络(RNN)相结合的方式,并且还使用了注意力机制来增强对序列化文本的识别能力。EasyOCR 可以识别超过80种语言的文字,支持从简单的拉丁字母到复杂的汉字、阿拉伯字母等。它的 API 非常简洁,可以轻松集成到 Python 项目中,只需要几行代码即可完成从图像中提取文本的任务。且它是完全开源的,用户可以根据自己的需要对其进行修改和扩展。
其工作原理是首先对输入图像进行灰度化、二值化等预处理操作,以增强文本区域的对比度。其次使用预训练的文字检测模型,如 CRAFT (Character Region Awareness for Text Detection),来识别图片中的文本区域。再对检测到的文本区域使用深度学习模型(CRNN + Attention)进行文字识别,将图像中的字符转换为文本。最终对于识别出的文字,基于CTC(Connectionist Temporal Classification)损失函数【6】进行一些简单的后处理操作,允许模型在没有对齐标签的情况下进行训练,从而提高了识别精度,可以纠正错误的识别结果等。
EasyOCR阅读器会输出每个识别到的文本框的坐标位置和文本的置信度。文本框的坐标位置是通过对输入图像进行文本区域检测和分析得出的。EasyOCR通过CNN提取图像的特征;并通常通过回归方法来获得每个字符或单词的边界,从而预测文本区域的边界框(bounding box);返回的坐标通常是一个四个角点的数组,表示文本框在图像中的位置。模型在进行文本识别时,计算每个字符或文本框的概率分布;使用Softmax ( ) 函数将模型输出转换为概率值,这些值表示模型对各个字符类别的信心;最终返回的置信度是模型对识别结果的最高概率值,反映了文本识别的可靠性。每个文本框的坐标位置正是我们在3.1中想要极力去纠正调整的,而获取文本的置信度让我们在后台对检测到的内容错误风险也有了一定的了解和预判能力。
分割图像
在识别到文本后,通过获取每个识别结果的边界框坐标,可以将图像切割成小块,以便进一步处理或分析。
数据实验
本文基于学校课程资料中所给出的三幅“随机角度拍摄的路灯控制箱”图(jpg格式图1.2.3)完成了对拍摄图中标签的分割,并准确和有序地识别了箱号和报修电话。

首先,先进行旋转操作,图中红线为识别到的直线,即根据这些线段的平均倾斜角度旋转。经实验发现,若不引入边缘检测优化技术,图5和6无法识别到最上部的那根红线。

其次便是EasyOCR对文本的提取,可以看到在未进行旋转操作时,对于第二幅图像(即向右上角倾斜)的识别的结果“12319”在“报修电话”之前(图7),旋转后便没有该问题了(图8)。

讨论
在本研究中,探索了使用EasyOCR进行图像文本识别的有效性和应用潜力。通过对不同图像处理步骤的实施,包括灰度转换、边缘检测及图像旋转,我们观察到这些预处理操作显著提高了文本识别的准确性。特别是,Canny边缘检测和霍夫变换在确定文本区域的边缘和结构方面发挥了关键作用。此外,EasyOCR的强大之处在于其对多语言文本的支持,尤其是在中文字符的识别上。尽管如此,模型在处理复杂背景和噪声时仍然存在一定的挑战,如图2中的光影如果覆盖的范围更大或更刺眼,又如灯箱上被贴了小广告等其他文字。受限于数据集过少,网络上也无法找到贴近本研究目的的合适的灯箱牌图,进一步研究可以集中于优化图像质量和提高置信度的稳定性。
结论
综上所述,本研究验证了EasyOCR在图像文本识别中的有效性,并展示了图像预处理技术在提高识别性能方面的重要作用。具体而言,将图像转换为灰度图显著减少了处理复杂性,使得后续步骤如边缘检测和文本区域识别更加高效。使用Canny边缘检测和自适应阈值处理优化了图形和文本边缘的提取,增强了图像中的关键信息。此外,通过霍夫变换检测直线并将图片纠正回水平,进一步提高了文本的结构化,使得后续的文本识别更为准确和有序。
尽管EasyOCR提供了令人满意的识别结果,但在处理复杂背景、低对比度或高噪声环境时仍面临挑战。因此,未来的研究可以集中在优化图像质量的算法上,例如改进图像增强技术和自适应阈值方法。同时,结合深度学习模型和增强学习方法将有助于进一步提升识别精度和处理速度,从而扩展EasyOCR在实际应用中的可行性和适用性。通过这些努力,我们有望实现更广泛的文本识别应用,为智能图像分析领域做出贡献。
参考文献
- [1] Smith, J. "Automated recognition of street light control boxes using deep learning." IEEE Transactions on Smart Cities, vol. 5, no. 2, 2021, pp. 145-156.
- [2] Huang, X., et al. "A smart city lighting system using image recognition and IoT." Journal of Urban Technology, vol. 26, no. 3, 2020, pp. 120-132.
- [3] Gonzalez, R. C., & Woods, R. E. (2008). Digital Image Processing.
- [4] Duda, R. O., & Hart, P. E. (1972). Use of the Hough Transformation to Detect Lines and Curves in Pictures. Communications of the ACM, 15(1), 11-15.
- [5] Wang, T. Y., & Wang, Y. (2019). EasyOCR: A Deep Learning-based Optical Character Recognition Tool.
- [6] Graves, A., & Jaitly, N. (2014). Towards End-to-End Speech Recognition with Recurrent Neural Networks. arXiv preprint arXiv:1401.2200.
附录代码
import cv2
import numpy as np
import os
import easyocr
import re
# 获取当前工作目录
current_dir = os.getcwd()
# 获取所有 .jpg 文件
image_files = [f for f in os.listdir(current_dir) if f.endswith('.jpg')]
# 创建 easyocr 阅读器
reader = easyocr.Reader(['ch_sim']) # 简体中文
# 检查是否包含中文字符
def contains_chinese(text):
return re.search("[\u4e00-\u9fff]", text) is not None
# 中文的虚线框颜色
chinese_color = [0, 255, 0] # 绿色
# 非中文的虚线框颜色
non_chinese_color = [255, 0, 0] # 蓝色
# 绘制虚线框
def draw_dashed_rectangle(img, top_left, bottom_right, color, thickness=2, dash_length=10):
x1, y1 = top_left
x2, y2 = bottom_right
# 绘制上边框和下边框
for i in range(x1, x2, dash_length * 2):
cv2.line(img, (i, y1), (min(i + dash_length, x2), y1), color, thickness)
cv2.line(img, (i, y2), (min(i + dash_length, x2), y2), color, thickness)
# 绘制左边框和右边框
for i in range(y1, y2, dash_length * 2):
cv2.line(img, (x1, i), (x1, min(i + dash_length, y2)), color, thickness)
cv2.line(img, (x2, i), (x2, min(i + dash_length, y2)), color, thickness)
# 遍历每张图片
for image_file in image_files:
# 读取图像
image_path = os.path.join(current_dir, image_file)
image = cv2.imread(image_path)
# 将图像转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# # 创建CLAHE对象 对比度增强
# clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(15, 15))
# # 应用CLAHE到灰度图
# clahe_image = clahe.apply(gray)
# # 高斯模糊
# blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# # 直方图均衡化
# equalized = cv2.equalizeHist(gray)
# 使用自适应阈值处理 边缘检测优化
adaptive_thresh = cv2.adaptiveThreshold(gray, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
# 使用Canny边缘检测
edges = cv2.Canny(adaptive_thresh, 100, 200)
# 使用霍夫变换检测直线
lines = cv2.HoughLinesP(edges, 1, np.pi/180, threshold=250, minLineLength=250, maxLineGap=10)
new_lines = []
# 绘制只包含水平方向的直线
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
# 计算直线的斜率,如果斜率接近 0,认为是水平线
if x2 - x1 != 0 and abs(y2 - y1) / (x2 - x1) < 1: # 斜率接近0的情况
# 绘制水平直线,颜色为红色,线条宽度为2
new_lines.append(line)
cv2.line(image, (x1, y1), (x2, y2), (0, 0, 255), 2)
# 计算图像中的倾斜角度
angles = []
for line in new_lines:
x1, y1, x2, y2 = line[0]
angle = np.arctan2(y2 - y1, x2 - x1) * 180 / np.pi
angles.append(angle)
# 取所有检测到直线的平均倾斜角度
if angles:
average_angle = np.mean(angles)
else:
average_angle = 0 # 没有检测到水平直线时,不做旋转
# 旋转图像进行矫正
(h, w) = image.shape[:2]
center = (w // 2, h // 2)
M = cv2.getRotationMatrix2D(center, average_angle, 1.0)
rotated = cv2.warpAffine(image, M, (w, h))
# 保存旋转后的图像到本地,文件名为 rotated_原图片名.jpg
rotated_image_path = os.path.join(current_dir, f'rotated_{image_file}')
cv2.imwrite(rotated_image_path, rotated)
# 读取旋转后的图像中的文字
result = reader.readtext(rotated_image_path, detail=1)
# 输出识别的文字并分割标签
print(f"识别结果({image_file}):")
for i, detection in enumerate(result):
print(detection[1]) # detection[1] 是识别出的文本
# 获取文字框的坐标,用于分割图像
bbox = detection[0]
top_left = (int(bbox[0][0]), int(bbox[0][1]))
bottom_right = (int(bbox[2][0]), int(bbox[2][1]))
# # 使用坐标切割图像
# cropped_label = rotated[top_left[1]:bottom_right[1], top_left[0]:bottom_right[0]]
# # 保存每个分割的标签图像,命名为 "label_原图片名_i.jpg"
# label_image_path = os.path.join(current_dir, f'label_{image_file.split(".")[0]}_{i}.jpg')
# cv2.imwrite(label_image_path, cropped_label)
# print(f"已保存分割标签:{label_image_path}")
# 根据文本内容选择颜色
text = detection[1]
if contains_chinese(text):
color = chinese_color # 中文标签使用绿色
else:
color = non_chinese_color # 非中文标签使用红色
# 绘制虚线框
draw_dashed_rectangle(rotated, top_left, bottom_right, color)
# 保存带有所有标签框的图像
labeled_image_path = os.path.join(current_dir, f'labeled_{image_file}')
cv2.imwrite(labeled_image_path, rotated)
print(f"已保存带有标签框的图像:{labeled_image_path}")