目录
方法三:MySQL递归(既可以向下递归也可以向上递归)(MySQL8 支持)
1.批量插入,查询,删除数据
千万不要循环调用数据库!!!
比如:
public void deleteBatch(List<Integer> ids) {
for (Integer id : ids) {
blogMapper.deleteById(id);
}
}缺点
- 性能问题:
-
- 高延迟:每次数据库操作都需要建立连接、执行操作、然后关闭连接,这个过程涉及到网络延迟和数据库处理时间。
- 资源消耗:频繁的数据库连接和断开操作会消耗大量的系统资源,如内存和CPU。
- 并发限制:数据库连接通常是有限的资源,大量并发连接可能会导致数据库连接池耗尽。
- 可扩展性问题:
-
- 瓶颈:当需要处理大量数据时,循环调用数据库会成为一个明显的性能瓶颈。
- 扩展难度:随着数据量的增加,系统的性能会显著下降,而优化这种循环操作通常比较困难。
- 事务管理:
-
- 事务开销:每次数据库操作可能都会启动一个新的事务,这会增加事务管理的开销。
- 原子性保证困难:如果需要保证一系列操作的原子性,循环调用可能会导致部分操作成功而部分失败,难以实现原子性。
- 维护和调试困难:
-
- 代码复杂性:循环调用数据库的代码通常比较冗长且难以维护。
- 错误追踪:如果其中一个操作失败,可能需要检查每个单独的操作来确定问题所在,增加了调试的难度。
- 锁竞争和死锁:
-
- 锁竞争:循环操作可能会导致数据库上的锁竞争,影响数据库的整体性能。
- 死锁风险:如果多个线程或进程同时进行循环操作,可能会增加死锁的风险。
- 用户体验:
-
- 响应时间:用户可能会遇到较长的等待时间,特别是在前端需要等待所有数据库操作完成后才能继续执行的情况下。
实现方法
1.批量插入数据
public interface BlogMapper {
// 假设Blog是一个实体类,代表要插入的数据
int insertBatch(List<Blog> blogs);
}
public class BlogService {
@Autowired
private BlogMapper blogMapper;
public void insertBatch(List<Blog> blogs) {
blogMapper.insertBatch(blogs);
}
}<!-- BlogMapper.xml -->
<insert id="insertBatch" parameterType="java.util.List">
INSERT INTO blogs (column1, column2, ...)
VALUES
<foreach collection="list" item="blog" separator=",">
(#{blog.column1}, #{blog.column2}, ...)
</foreach>
</insert>2.批量查询数据
public interface BlogMapper {
// 假设Blog是一个实体类,代表查询结果
List<Blog> selectBatch(List<Integer> ids);
}
public class BlogService {
@Autowired
private BlogMapper blogMapper;
public List<Blog> selectBatch(List<Integer> ids) {
return blogMapper.selectBatch(ids);
}
}<!-- BlogMapper.xml -->
<select id="selectBatch" parameterType="java.util.List" resultType="Blog">
SELECT * FROM blogs WHERE id IN
<foreach item="id" collection="list" open="(" separator="," close=")">
#{id}
</foreach>
</select>3.批量删除数据
public interface BlogMapper {
int deleteBatch(List<Integer> ids);
}
public class BlogService {
@Autowired
private BlogMapper blogMapper;
public void deleteBatch(List<Integer> ids) {
blogMapper.deleteBatch(ids);
}
}<!-- BlogMapper.xml -->
<delete id="deleteBatch" parameterType="java.util.List">
DELETE FROM blogs WHERE id IN
<foreach item="id" collection="list" open="(" separator="," close=")">
#{id}
</foreach>
</delete><delete id="deleteEnergyWorkshopByIds" parameterType="String">
delete from energy_workshop where id in
<foreach item="id" collection="array" open="(" separator="," close=")">
#{id}
</foreach>
</delete>4.批量修改数据
举例 1:
<update id="changeSort">
<foreach collection="videoSeriesList" separator=";"
item="item">
update user_video_series
set sort = #{item.sort}
where user_id = #{item.userId}
and series_id = #{item.seriesId}
</foreach>
</update>举例 2:
void update(@Param("blogs") List<Blog> blogs);<update id="update" parameterType="java.util.List">
UPDATE blog
SET read_count =
<foreach collection="blogs" item="blog" separator=" "
open="CASE id" close="END">
WHEN #{blog.id} THEN #{blog.readCount}
</foreach>
WHERE id IN
<foreach collection="blogs" item="blog" separator=","
open="(" close=")">
#{blog.id}
</foreach>
</update>以上sql拼接的结果类似于:
UPDATE blog
SET read_count =
CASE id
WHEN 1 THEN 10
WHEN 2 THEN 20
WHEN 3 THEN 30
END
WHERE id IN (1, 2, 3)解释
foreach标签的作用:foreach标签用于遍历集合,并将集合中的每个元素插入到 SQL 语句中。它最终生成的是一条 SQL 语句,而不是多条 SQL 语句。IN子句的实现:MyBatis 会将foreach标签生成的 SQL 语句发送到数据库,数据库会一次性处理这些查询操作,而不是逐条查询。这种方式比逐条查询更高效。
2.树型表查询
树型表举例:

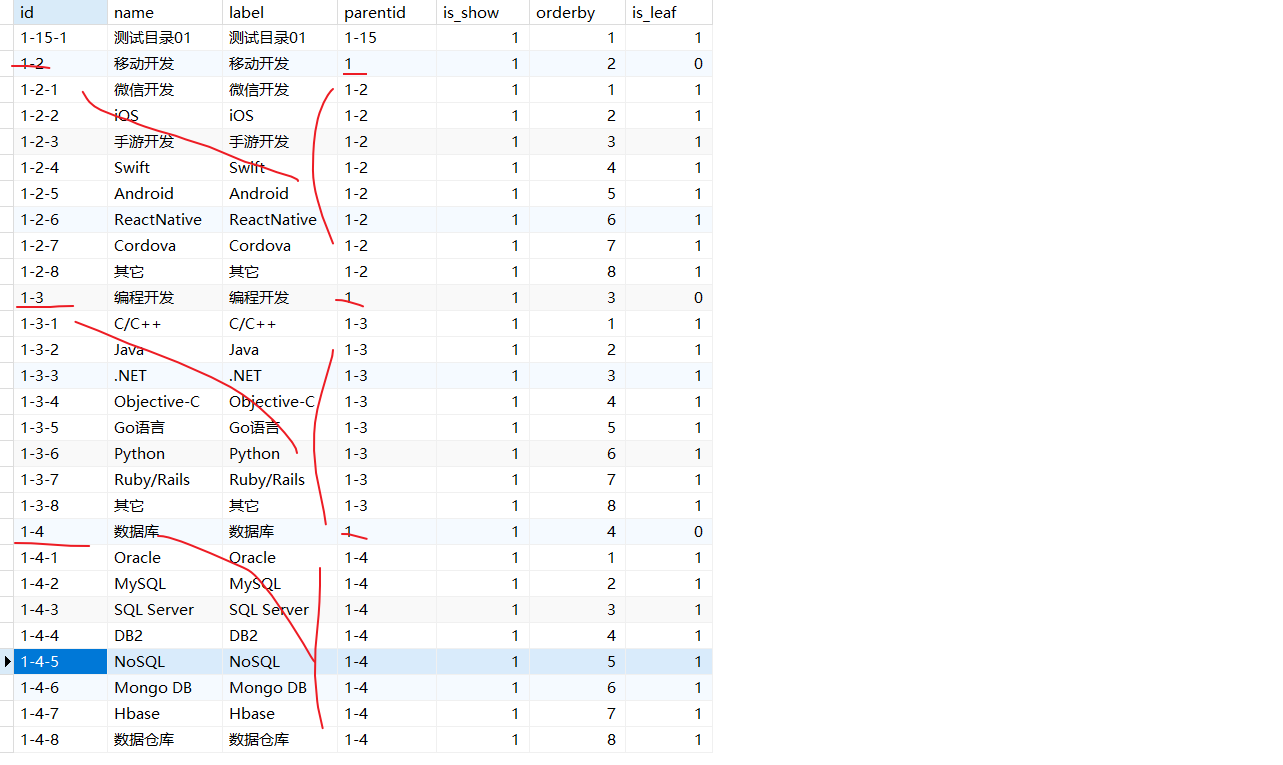
方法一:递归(适用于多级的情况)
private List<CategoryInfo> convertLine2Tree(
List<CategoryInfo> dataList, Integer pid) {//pid:0
List<CategoryInfo> children = new ArrayList();
for (CategoryInfo m : dataList) {
if (m.getCategoryId() != null &&
m.getpCategoryId() != null &&
m.getpCategoryId().equals(pid)) {
m.setChildren(convertLine2Tree(dataList, m.getCategoryId()));
children.add(m);
}
}
return children;
}方法二:表的自连接
层级固定的话用表的自连接
select
one.id one_id,
one.name one_name,
one.parentid one_parentid,
one.orderby one_orderby,
one.label one_label,
two.id two_id,
two.name two_name,
two.parentid two_parentid,
two.orderby two_orderby,
two.label two_label
from course_category one
inner join course_category two on one.id = two.parentid
where one.parentid = 1
and one.is_show = 1
and two.is_show = 1
order by one.orderby,
two.orderby举例:
查询课程计划(树型结构)(这个树型结构固定为两层)
<!-- 课程分类树型结构查询映射结果 -->
<resultMap id="treeNodeResultMap"
type="com.xuecheng.content.model.dto.TeachplanDto">
<!-- 一级数据映射 -->
<id column="one_id" property="id"/>
<result column="one_pname" property="pname"/>
<result column="one_parentid" property="parentid"/>
<result column="one_grade" property="grade"/>
<result column="one_mediaType" property="mediaType"/>
<result column="one_startTime" property="startTime"/>
<result column="one_endTime" property="endTime"/>
<result column="one_orderby" property="orderby"/>
<result column="one_courseId" property="courseId"/>
<result column="one_coursePubId" property="coursePubId"/>
<!-- 一级中包含多个二级数据 -->
<!-- 映射子节点teachPlanTreeNodes,一对多映射,用collection-->
<collection property="teachPlanTreeNodes" ofType="com.xuecheng.content.model.dto.TeachplanDto">
<!-- 二级数据映射 -->
<id column="two_id" property="id"/>
<result column="two_pname" property="pname"/>
<result column="two_parentid" property="parentid"/>
<result column="two_grade" property="grade"/>
<result column="two_mediaType" property="mediaType"/>
<result column="two_startTime" property="startTime"/>
<result column="two_endTime" property="endTime"/>
<result column="two_orderby" property="orderby"/>
<result column="two_courseId" property="courseId"/>
<result column="two_coursePubId" property="coursePubId"/>
<!-- 每个小章节子节点还对应着一个媒资视频文件 -->
<!-- 一对一映射用association -->
<association property="teachplanMedia" javaType="com.xuecheng.content.model.po.TeachplanMedia">
<result column="teachplanMeidaId" property="id"/>
<result column="mediaFilename" property="mediaFilename"/>
<result column="mediaId" property="mediaId"/>
<result column="two_id" property="teachplanId"/>
<result column="two_courseId" property="courseId"/>
<result column="two_coursePubId" property="coursePubId"/>
</association>
</collection>
</resultMap>
<!-- 表的自连接 查询课程计划(树型结构)(这个树型结构固定为两层) -->
<select id="selectTreeNodes" parameterType="long"
resultMap="treeNodeResultMap">
select one.id one_id,
one.pname one_pname,
one.parentid one_parentid,
one.grade one_grade,
one.media_type one_mediaType,
one.start_time one_startTime,
one.end_time one_endTime,
one.orderby one_orderby,
one.course_id one_courseId,
one.course_pub_id one_coursePubId,
two.id two_id,
two.pname two_pname,
two.parentid two_parentid,
two.grade two_grade,
two.media_type two_mediaType,
two.start_time two_startTime,
two.end_time two_endTime,
two.orderby two_orderby,
two.course_id two_courseId,
two.course_pub_id two_coursePubId,
m1.media_fileName mediaFilename,
m1.id teachplanMeidaId,
m1.media_id mediaId
from teachplan one
LEFT JOIN teachplan two on one.id = two.parentid
LEFT JOIN teachplan_media m1 on m1.teachplan_id = two.id
where one.parentid = 0
and one.course_id = #{cousrseId}
order by one.orderby,
two.orderby
</select>方法三:MySQL递归(既可以向下递归也可以向上递归)(MySQL8 支持)
with recursive t1 as (
select * from course_category p where id= '1'
union all
select t.* from course_category t inner join t1 on t1.id = t.parentid
)
select * from t1 order by t1.id, t1.orderby3.表的连接该怎么选择
1.等值连接&内连接
等值连接一定程度上就是内连接。
等值连接是内连接的一种,通常是内连接最常见和最基础的形式。
等值连接可以视为内连接的一种特例,因为等值连接只是内连接的一种情况,其中连接条件使用了相等运算符 (=)。换句话说,所有的等值连接都是内连接,但并非所有的内连接都是等值连接。
内连接允许使用各种比较运算符(包括等于、不等于、大于、小于等),而等值连接专门使用等于运算符(=)作为连接条件。
SELECT a.id, b.name
FROM table_a a,table_b b
WHERE a.id = b.id;
这是最开始学的等值连接写法。实际上和下面的内连接意义相同。SELECT a.id, b.name
FROM table_a a
INNER JOIN table_b b ON a.id = b.id;
SELECT orders.id, customers.name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id;
这是内连接的写法。2.左连接&右连接&外连接
左连接
- 定义:左连接返回左表中的所有记录,即使右表中没有匹配的记录。如果右表中没有匹配的记录,结果会显示为
NULL。 - 使用场景:当你希望获取左表中所有数据,包括没有匹配数据的记录时使用。
- 示例:查询所有客户及他们的订单(即使客户没有订单也要显示)。
SELECT customers.name, orders.id
FROM customers
LEFT JOIN orders ON customers.id = orders.customer_id;这个查询会返回所有客户及他们的订单,如果客户没有订单,则订单字段为 NULL。
右连接(用的比较少)
- 定义:右连接与左连接类似,但它返回的是右表中的所有记录。如果左表中没有匹配的记录,结果会显示为
NULL。 - 使用场景:这种连接方式使用得较少,通常在需要保留右表的所有数据时才使用。
- 示例:查询所有订单和对应的客户信息(即使某个订单没有关联客户)。
SELECT orders.id, customers.name
FROM orders
RIGHT JOIN customers ON orders.customer_id = customers.id;外连接(用的很少)
- 定义:外连接返回左表和右表中的所有记录,当某一表没有匹配的记录时,另一个表中的字段会填充
NULL。不过需要注意,MySQL 不直接支持 FULL OUTER JOIN,可以通过使用LEFT JOIN和RIGHT JOIN结合来模拟。 - 使用场景:当你希望返回两个表中所有的记录(无论是否匹配)时使用。
- 示例:没有直接的支持,你可以通过组合
LEFT JOIN和RIGHT JOIN来模拟:
SELECT * FROM A
LEFT JOIN B ON A.id = B.id
UNION
SELECT * FROM A
RIGHT JOIN B ON A.id = B.id;3.自连接
一个表与它自己连接,通常用来查找同一表中的关联数据。
使用自连接一定要给表取别名。
至于自连接的实现方式的选择就要看具体情况了:
自连接通常使用 内连接 或 左连接,具体选择取决于你是否需要保留左表的所有记录。
- 如果你只关心表中有匹配关系的记录,使用 内连接。
- 如果你希望保留表中的所有记录(即使没有匹配的记录),使用 左连接。