
|
|
文章目录

1. 集合
在之前的章节中, 我们学习了列表, 元组, 字符串. 已经可以覆盖七成的使用场景了.
那么为什么还要学习集合类型呢.
-
列表: 有序可变, 元素可重复.
-
元组: 有序不可变, 元素可重复.
-
字符串: 有序不可变, 字符可重复.
以上数据类型有一个共同点, 就是都支持元素可重复.
当我们需要一个数据集, 且不允许重复的时候, 就可以使用到集合.
集合的特点:
- 可以容纳多个元素.
- 可以容纳不同类型的元素.
无序的.不允许重复元素.- 是可变的.
1.1 集合的定义
变量名称 = {元素1, 元素2, 元素3, ....}
# 定义空集合
变量名称 = set()
注意:
Python的集合(set)可以容纳任何可哈希(hashable)的数据类型的元素(key),例如数字、字符串、元组等. 不可哈希(unhashable)的数据类型,例如列表、字典、集合等,则不能作为集合的元素(key). 这是因为集合的元素(key)需要能够进行哈希运算,以便于进行快速的查找和去重.
1.2 集合的常用操作
- 添加新元素: set.add(元素), 将指定的元素添加到集合内.
# 添加新元素: set.add(元素), 将指定的元素添加到集合内. set1 = set() set1.add('张三') print(set1) - 删除元素: set.remove(元素), 将指定的元素从集合内删除.
# 删除元素: set.remove(元素), 将指定的元素从集合内删除. # remove(key), 如果不存在这个key就会报错 set1.remove('张三') print("remove删除新元素", set1) - 从集合中随机取出元素: set.pop(). 有返回值.
从集合中随机取出元素: set.pop(). 有返回值. ele = set1.pop() print("ele", ele) print("set1", set1) - set.update() 类似于列表中的 .extend()
hello_string = "hello world" new_set = set() new_set.update(hello_string) print(new_set) - 从集合中删除一个元素, 如果该元素不存在, 则什么也不做: set.discard(元素)
set1 = {'zhangsan', 4, 2, 3, "apple", "banana", "cherry", '张三'} set1.discard('张三') print("删除'张三后的'set1", set1) set1.discard('李四') print("删除'李四后的'set1", set1) - 清空集合: set.clear()
set1.clear() print("clear()后的set1", set1) - 获取2个集合的差集: set1.difference(set2), 取出集合1和集合2的差集(集合1有但是集合2没有的元素.) 返回一个新集合, 集合1和集合2保持不变.
set1 = {'zhangsan', 4, 2, 3, "apple", "banana", "cherry", '张三'} set2 = {'lisi', 4, 2, 1, "orange"} new_set = set1.difference(set2) # new_set = set2.difference(set1) print(new_set) - 消除2个集合的差集: set1.difference_update(set2): 对比2个集合, 在集合1内删除和集合2相同的元素.
set1 = {'zhangsan', 4, 2, 3, "apple", "banana", "cherry", '张三'} set2 = {'lisi', 4, 2, 1, "orange"} set1.difference_update(set2) # set2.difference_update(set1) print(set2) - 合并2个集合: set1.union(set2). 将集合1和集合2合并组成新的集合. 返回一个新的集合, 集合1和集合2保持不变.
set1 = {'zhangsan', 4, 2, 3, "apple", "banana", "cherry", '张三'} set2 = {'lisi', 4, 2, 1, "orange"} new_set = set1.union(set2) print(new_set) - 两个集合中的交集: set.intersection(set1)
set1 = {'zhangsan', 4, 2, 3, "apple", "banana", "cherry", '张三'} set2 = {'lisi', 4, 2, 1, "orange"} new_set = set1.intersection(set2) print(new_set) - 集合1.issubset(集合2): 判断集合1是否为集合2的子集. 如果是子集, 则返回true
# 集合1.issubset(集合2): 判断集合1是否为集合2的子集, 如果是子集, 则返回true print(set1.issubset(set2)) - 集合1.isdisjoint(集合2): 判断集合1和集合2是否包含相同的元素.如果交集为空,则返回true
# 集合1.isdisjoint(集合2): 判断集合1和集合2是否包含相同的元素. 如果交集为空, 则返回True print(set1.isdisjoint(set2)) - len: 返回集合中元素的个数.
# len: 返回集合中元素的个数. length = len(set2) print(length) # 集合也是可以遍历的 for i in set2: print(i)
1.3 集合练习
给定一个列表, 使用集合将其去重, 并保持原列表的顺序.
a_list = [1, 2, 2, 3, 4, 6, 5, 8, 7, 7]
b_list = list(set(a_list)) # 留意这两步, 很妙
b_list.sort(key=a_list.index)
print(b_list)
- 给定两个列表a和b,输出这两个列表中都出现的元素组成的集合
a_list = [1, 2, 3, 4]
b_list = [3, 4, 5, 6]
new_set = set(a_list).intersection(set(b_list))
print(new_set)
- 给定一个字符串,输出该字符串中不重复的字符组成的集合
hello_string = 'hello world'
new_set = set()
new_set.update(hello_string) # 类似于列表中的extend
print(new_set)
print(dir(set())) # 使用set()可以获取该对象中的所有的方法
set1 = set()
for s in hello_string:
set1.add(s)
print(set1)
2. 字典
回顾:
- 列表: 解决了多个变量定义的问题.
- 元组: 保证了容器内数据的安全性.
- 集合: 存储多个数据的同时还保证了唯一性.
但是以上数据容器查看元素, 只能通过遍历或者通过下标索引来获取, 十分的不方便.
字典:
字典的作用是通过部首或者拼音可以快速定位到对应的字词.
目前为止,Python中最常用的数据类型,我们只剩下一个 字典 还没有给大家介绍了。
字典,是Python开发中非常重要的一种数据类型。
为什么呢? 因为字典 提供了一种特别的结构, 就是 存放 键值对 数据。这种结构使得字典,特别像 一张 表
什么是键值对数据?
举个例子, 一个游戏系统 里面会存储 用户信息。
系统 经常需要 查询某个用户的信息,比如 某个用户的等级、装备等。
那么根据什么去查找该用户的信息呢? 根据 唯一标志 该用户的属性,比如 用户登录名 或者 用户分配的ID号 等。
根据 登录名1 就查到 用户1 的信息
根据 登录名2 就查到 用户2 的信息
这样就形成了如下 的一种 从 登录名 到 用户信息数据 的映射关系
上图中
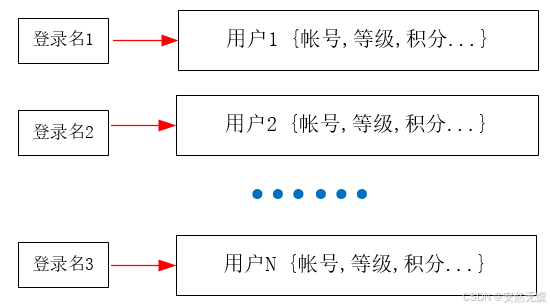
登录名1就是键(英文叫Key), 用户1 就是值(英文叫Value);
登录名2就是键, 用户2就是值。
每个对应的帐号 和 会员数据 就形成了一个键值对。
要存储像这样 一对一 的映射关系的数据结构,就像一张表一样,在Python中就可以使用字典这种数据类型
在python中, 字典作为存储数据的一种容器, 是python中的一种映射类型, 它的每个元素都由
键-值(key-value)对组成, 键-值对包括key和value两部分, 其中key必须唯一且可哈希(不可变), 对元素的查找和修改是根据元素的key进行的.
2.1 字典的定义
# 最常见的创建字典的方式
dic = {
'name': '张三',
'age': 18
}
- 每个元素的键值对之间用:分隔.
- 每个元素之间用,分隔.
- 整个字典的元素包含在大括号{}中.
- key必须是唯一的且不可变的.
空字典的创建:
# 创建一个不含任何元素的空字典.
dic = {}
# 或者
dic = dict()
使用字典关键字创建字典
dic = dict(name='zhangsan', age=18)
# 或者
key_value = [('name', '张三'), ('age', 18)]
dic = dict(key_value)
使用fromkeys创建字典
# fromkeys() 函数用于创建一个新字典,以序列seq中元素做字典的键,
# value为字典所有键对应的初始值 - 用的少, 了解即可
dict.fromkeys(seq[, value])
# 如下:
dic = {}.fromkeys(['name', 'age']) -> 值都是None
dic = {}.fromkeys(['name', 'age'], 'abc') -> 值都是'abc'
总结
字典因其具有查找和操作快速的优势, 在Python中使用范围很广泛, 字典是无序的. 元素的存储顺序没有意义, 使用 需注意:
- 字典的key具有唯一性.
- 字典的key只能是不可变类型.
- 字典的value可以是任意类型.
- 字典是可变的.
注意
-
同一个字典中出现相同的key, 即同一个key被多次赋值时, 程序此时不会抛出异常, 编辑器会给出警告, 只是相同的key的value值, 会被覆盖掉.
如:dic = { 'name': '张三', 'age': 18, 'age': 19 } print(dic) -
当key使用了可变类型时, 如列表,程序会抛出
TypeError: unhashable type: 'list'错误, 这是因为字典的key必须是可哈希的, 不可变的(类似集合)
2.2 嵌套字典和字典的取值
用嵌套字典记录多个学生和他们所对应的各个科目的成绩.
如: 张三, 和张三的语文,数学,英语的成绩. 李四, 王五等等.
stu_dict = {
'张三': {
'语文': 90,
'数学': 95,
'英语': 93,
},
'李四': {
'语文': 91,
'数学': 92,
'英语': 97,
},
'王五': {
'语文': 80,
'数学': 75,
'英语': 83,
},
}
zhangsan_score = stu_dict['张三']['数学']
# print(zhangsan_score)
lisi_score = stu_dict.get('张三', {}).get('数学', 0) -> .get()方法的第2个参数是在字典中没有找到该key的情况下给的默认值
# lisi_score = stu_dict['李四'].get('英语') -> get()没有就返回None
print(lisi_score)
2.3 字典的常用操作
对于字典的常用操作, 大家可以根据我之前的文章学习:
为什么在Python中总是使用【字典】这种类型呢?
- 新增元素: dict[key] = value. 往字典中新增元素
- 修改元素: dict[key] = value. 当key在字典中已经存在时,会修改对应key的value值。
- 删除元素: dict.pop(key). 删除指定key的元素,有返回值,返回对应key的value值。
- 删除元素: del dict[key], 删除指定key的元素
- 删除字典内所有元素: dict.clear()
- 获取字典所有的键key值: dict.keys()
- 获取字典所有的value值:dict.values()
- 把字典dict2的键/值对更新到dict里: dict.update(dict2)
- 获取(键, 值) 元组数组: dict.items()
- 字典的遍历:
- 遍历字典所有的key
- 遍历字典所有的value
- 遍历字典的key和value
# 1. 新增元素: dict[key] = value. 往字典中新增元素
# dic['gender'] = '男'
# 2. dict[key] = value. 当key在字典中已经存在时,会修改对应key的value值。
# dic['age'] = 20
# print(dic)
# 3. 使用get方法可以获取指定键key的值value, 如果该key不存在.get()就返回None
print(dic.get('gender'))
# 4. 删除元素. dict.pop(key)
# age = dic.pop('age')
# print(dic)
# print(age)
# 5. 删除元素: del dict[key], 删除指定key的元素
# del dic['age']
# print(dic)
# 6. 删除字典内所有元素: dict.clear()
# dic.clear()
# print(dic)
# 7. 获取字典所有的键: dict.keys()
# keys = dic.keys()
# print(list(keys))
# 8. 获取字典所有的value值:dict.values()
# values = dic.values()
# print(list(values))
# 9. 把字典dict2的键/值对更新到dict里: dict.update(dict2)
# dic2 = {'gender': "男", 'age': 20, 'name': 'zhangsan'}
# dic.update(dic2)
# print(dic)
dic = {
'name': '张三',
'age': 18,
'gender': '男',
}
# 10. 获取(键, 值) 元组数组: dict.items()
# tup = dic.items()
# print(tup)
- 字典的遍历.
# keys = dic.keys()
# for key in keys:
# print(key)
# print('-' * 30)
# vals = dic.values()
# for val in vals:
# print(val)
# 下面其实也是遍历key
# for d in dic:
# print(d)
# 重点: 遍历字典的key和value
for key, value in dic.items():
print(key, value)
- 在python的字典中, 要判断字典中是否含有某一个key可以使用in:
dic = {
'name': '张三',
'age': 18
}
'name' in dic
# 返回True, 因为dic中含有'name'的key
'gender' in dic
#返回False, 因为dic中没有'gender'的key.
补充知识: 字典的优势是查找值效率高
字典具有查找和操作快速的优势, 要想高效查找字典中的值, 首先不应该使用遍历的方式, 这样发挥不出字典的优势, 应该首先想到的是根据key来查找值, 这样查找效率才会很高.
原因如下:
-
字典的 .items() 方法,会产生一个列表,把字典所有元素依次放入,然后,for 循环 遍历这个列表,如果 字典有上万个元素,这样查询效率很低
-
字典元素值的获取一定要直接根据key查找值,因为这样才会用到字典的哈希查询算法,而不是遍历查询,速度会快很多
2.4 字典推导式
字典推导式是一种快速创建字典的方式,它的语法类似于列表推导式,使用一对大括号{}表示字典,其中每个键值对用冒号:分隔
字典推导式的一般语法形式为:
{key: value for key, value in iterable}
其中iterable是一个可迭代对象,如列表、元组、集合等。可以通过对iterable中的元素进行操作,生成键值对加入到新字典中。
案例:
从列表中创建字典,键为元素的索引,值为元素的值
将字典中的值转换为大写
# 从列表中创建字典,键为元素的索引,值为元素的值
my_list = ['apple', 'banana', 'cherry'] # {0: 'apple', 1: 'banana', 2: 'cherry'}
dic = {index: val for index, val in enumerate(my_list) if index > 0}
print(dic)
# 将字典中的值转换为大写
my_dict = {'a': 'apple', 'b': 'banana', 'c': 'cherry'} # {'a': 'APPLE', 'b': 'BANANA', 'c': 'CHERRY'}
# dic2 = {key: value.upper() for key, value in my_dict.items()}
# print(dic2)
2.5 字典练习
- 给定一个字典,把它的键和值互换,返回一个新字典
dict1 = {'a': 100, 'b': 200, 'c': 300}
dic = {}
for key, value in dict1.items():
dic[value] = key
print(dic)
# 使用字典推导式一行代码搞定:
dict2 = {value: key for key, value in dict1.items()}
print(dict2)
- 给定两个字典,合并成一个字典,相同的键的值相加
dict1 = {'a': 100, 'b': 200, 'c': 300}
dict2 = {'b': 150, 'c': 250, 'd': 400}
for key, value in dict2.items():
if key in dict1:
dict1[key] += value
else:
dict1[key] = value
print(dict1)
- 给定一个字符串,统计其中每个字符出现的次数,返回一个字典
a_string = "112333abc"
dic = {}
for a in a_string:
if a in dic:
dic[a] += 1
else:
dic[a] = 1
print(dic)
- 给定一个列表,统计其中每个元素出现的次数
a_list = [1, 1, 2, 3, 3, 3, 'a', 'b', 'b', 'b']
dic = {a: a_list.count(a) for a in a_list}
print(dic)
很重要的补充练习:希望你能掌握
练习一
有一个日志文件, 比如文件名叫 2019-10-22_11.05.40.log, 其中发现该文件格式如下:
1571713540.9697|API list_order >0.03s|sales_22
1571713569.1041|API list_order >0.05s|sales_3
1571713599.2024|API list_order >0.08s|sales_3
1571713569.1578|API list_order >0.05s|sales_302
1571713571.7784|API list_order >0.1s|sales_29
1571713657.2568|API list_order >0.5s|sales_576
1571713657.4442|API list_order >1s|sales_845
该日志文件记录了 服务端对 各个请求处理 耗费的时间信息。
每行以 | 为分隔符, 记录了3个信息:
时间戳
什么请求处理时间大于多少秒
请求对应的用户
要求你写一个程序,统计:
请求处理时间 在 各个时间段的数量,结果格式如下:
API list_order >0.03s : 548个
API list_order >0.05s : 274个
API list_order >0.1s : 306个
API list_order >0.08s : 105个
API list_order >0.5s : 157个
API list_order >1s : 2062个
响应超时 : 403个
并且把结果写入文件
注意:你不能假设日志里面的响应时间就是这些内容 ,也可能有 其它的延迟时间,比如
API list_order >1.5s : 2068个
API list_order >1.8s : 2068个
等等
所以,代码不能写死 ,要动态的碰到一种,添加一种统计
with open('2019-10-22_11.05.40.log', 'r', encoding='utf8') as f:
loglist = f.read().splitlines()
handle_count = {}
request_overtime = 0
for info in loglist:
# 清除每行的前后空格
info = info.strip()
# 清除空行
if not info:
continue
if '响应超时' in info:
request_overtime += 1
continue
time_arr = info.split('|')[1] # API list_order >0.03s
time_info = time_arr.split('>')[1] # 0.03s
time_res = time_info.split('s')[0]
if time_res not in handle_count:
handle_count[time_res] = 1
else:
handle_count[time_res] += 1
# 将统计结果追加到文件末尾
with open('2019-10-22_11.05.40.log', 'a', encoding='utf8') as f:
for request_time, time_count in handle_count.items():
f.write('\n')
res = f'API list_order >{request_time}s : {time_count}个'
f.write(res)
f.write(f'\n响应超时 : {request_overtime}个')
练习二
有一个股票代码文件stock.txt,记录了中国所有的股票名称和代码
格式如下:
R007 | 201001
R014 | 201002
R028 | 201003
R091 | 201004
R182 | 201005
R001 | 201008
R002 | 201009
R004 | 201010
RC001 | 202001
RC003 | 202003
RC007 | 202007
0501R007 | 203007
0501R028 | 203008
0501R091 | 203009
0504R007 | 203016
0504R028 | 203017
请写一个股票信息查询程序,从文件加载数据, 可以让使用者 循环多次 查询股票信息
每次查询时,提示 请输入要查询的股票名称或代码:
当用户输入股票代码(6位全是数字)时,打印出对应的 股票名称和代码
当用户输入股票名称(不全是数字)时,打印出对应的 股票名称和代码
# 一开始我写的效率比较低的代码
with open('stock.txt', 'r', encoding='utf-8') as f:
infolist = f.read().splitlines()
# 以 股票名:股票代码 的形式存放于字典中
stock_code = {}
for info in infolist:
# 清除每行前后空格
info = info.strip()
# 去除空行
if not info:
continue
stock_list = info.split(' | ')
name = stock_list[0]
code = stock_list[-1]
stock_code[name] = code
while 1:
content = input("请输入要查询的股票名称或代码: ")
if content.isdigit():
# 股票代码
for name, code in stock_code.items():
if content == code:
print(f'股票名称是: {name}, 股票代码是: {code}')
else:
# 股票名称
print(f'股票名称是: {content}, 股票代码是: {stock_code[content]}')
# 改进后的代码:
# 建立两张表
# 股票名 到 股票信息的表
name2info = {}
code2info = {}
with open('stock.txt', 'r', encoding='utf-8') as f:
stocks = f.read().splitlines()
for stock in stocks:
stock = stock.split(' | ')
name = stock[0].strip()
code = stock[-1].strip()
name2info[name] = f'{name}:{code}'
code2info[code] = f'{name}:{code}'
while 1:
keywords = input("请输入要查询的股票名称或代码: ")
keywords = keywords.strip()
if not keywords:
# 如果输入为空
continue
if keywords.isdigit():
# 一定要写全6位股票代码
if len(keywords) < 6:
print("请写全6位股票代码")
continue
elif keywords in code2info:
print(code2info[keywords])
else:
print("找不到该股票代码")
else:
# 如果不全是数字, 作为股票名称处理
if keywords in name2info:
print(name2info[keywords])
else:
print("找不到该股票名称")
前面的代码效率之所以低的原因:
字典的 .items() 方法,会产生一个列表,把字典所有元素依次放入,
然后,for 循环 遍历这个列表,如果 字典有上万个元素,这样查询效率很低
字典元素值的获取一定要直接根据key查找值,因为这样才会用到字典的哈希查询算法,而不是遍历查询,速度会很快很多
可以定义2个字典,方便从名字 和从 股票代码的 两种查询.
所以对于查找字典中的值来说:
字典具有查找和操作快速的优势, 要想高效查找字典中的值, 首先不应该使用遍历的方式, 这样发挥不出字典的优势, 应该首先想到的是根据key来查找值, 这样查找效率才会很高.
|
|
|
|