jupyter
在创建环境中安装jupyter
打开Anaconda prompt
输入conda activate your_name
输入conda install nb_conda
输入jupyter notebook
点击右侧new,进入对应的环境
输入代码,按shift+enter,运行并新建代码块
PyCharm及Jupyter使用及对比
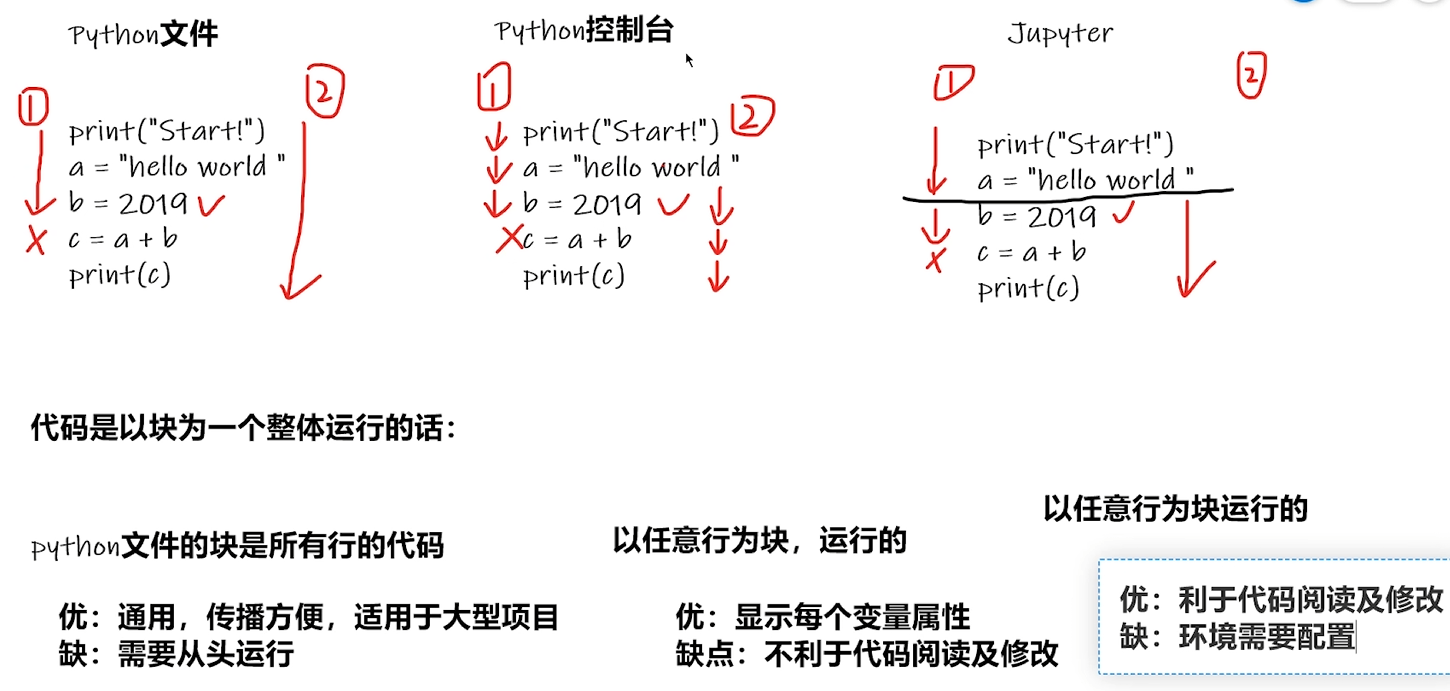
python学习中的两大法宝函数
package
包里有各种各样的工具
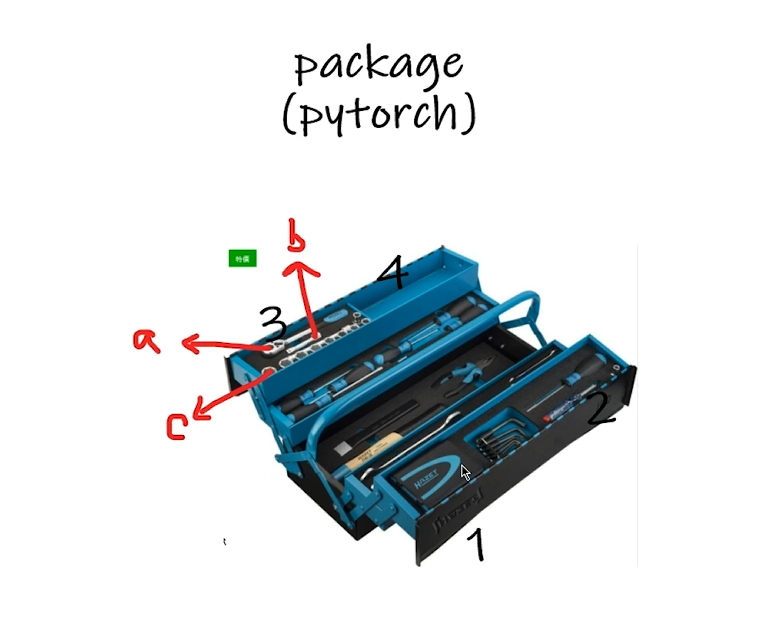
dir()函数
dir()函数,能让我们知道 工具箱以及工具箱中的分隔区有什么东西。
打开工具箱。用于列出一个对象的所有属性和方法。它返回一个包含对象所有属性和方法名称的列表。如果不传入参数,则返回当前作用域中所有可用的名称
help()函数
help()函数,能让我们知道每个工具是如何使用的,工具的使用方法。
查看说明书。用于获取对象、模块、函数、关键字等的帮助信息。当传入对象时,它会显示该对象的帮助文档。如果没有传入任何参数,则会进入交互式帮助模式。

数据集
数据集的两种形式
形式一:文件夹名称对应label

train:训练数据集
val:验证数据集
形式二:文件、label分类
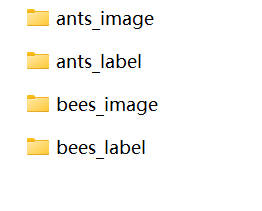
形式三:文件名称对应label

Pytorch读取数据的两个类Dataset和DataLoader
Dataset类
Dataset将数据和label进行组织编号0 1 2 3……,使得可以根据编号读取数据;需获取每一个数据及其label以及数据总数 ,要实现 len() 方法和 getitem() 方法。
len() 方法返回数据集的样本数量;
getitem() 方法根据给定的索引返回对应的数据样本
一些操作:
from PIL import Image
导入图片
img_path = "G:\\000_python\\PyTorch_deep_learning\\pythonProject2\\dataset\\train\\ants\\0013035.jpg"
打开图片地址
img = Image.open(img_path)
显示图片尺寸
img.size
from torch.utils.data import Dataset
# 从torch.utils.data导入Dataset类
from PIL import Image
# 从PIL导入Image类,用于图像处理
import os
# 导入os模块,用于处理文件和目录
class MyData(Dataset):
# 定义一个继承自Dataset的自定义数据集类
def __init__(self, root_dir, label_dir):
# 初始化方法,接受根目录和标签目录作为参数
self.root_dir = root_dir
# 设置实例的根目录
self.label_dir = label_dir
# 设置实例的标签目录
self.path = os.path.join(self.root_dir, self.label_dir)
# 构建完整的路径
self.img_path = os.listdir(self.path)
# 获取路径下的所有文件名
def __getitem__(self, idx):
# 获取指定索引处的数据
img_name = self.img_path[idx]
# 根据索引获取图像文件名
img_item_path = os.path.join(self.root_dir, self.label_dir,img_name)
# 构建图像文件的完整路径
img = Image.open(img_item_path)
# 打开图像文件
label = self.label_dir
# 获取图像的标签
return img, label
# 返回图像和标签
def __len__(self):
# 返回数据集的大小
return len(self.img_path)
# 返回图像文件的数量
root_dir = "蚂蚁蜜蜂数据集\\dataset\\train"
# 设置数据集的根目录
ants_label_dir = "ants"
# 设置蚂蚁数据的标签目录
ants_dataset = MyData(root_dir, ants_label_dir)
# 创建蚂蚁数据集实例
print(ants_dataset)
# 打印蚂蚁数据集的信息
print(ants_dataset[0])
# 打印蚂蚁数据集第一个数据项
img, label = ants_dataset[0]
# 获取蚂蚁数据集第一个数据项的图像和标签
img.show()
# 显示图像
bees_label_dir = "bees"
# 设置蜜蜂数据的标签目录
bees_dataset = MyData(root_dir, bees_label_dir)
# 创建蜜蜂数据集实例
img, label = bees_dataset[0]
# 获取蜜蜂数据集第一个数据项的图像和标签
img.show()
# 显示图像
train_dataset = ants_dataset + bees_dataset
# 拼接蚂蚁和蜜蜂两个数据集,未改变顺序,蚂蚁在前蜜蜂在后
print(len(ants_dataset))
# 打印蚂蚁数据集的大小
print(len(bees_dataset))
# 打印蜜蜂数据集的大小
print(len(train_dataset))
# 打印拼接后数据集的大小
Tensorboard
add_saclar用于在TensorBoard中添加标量数据。该方法可以用来添加训练过程中的损失值、准确率等指标,以便于在TensorBoard中进行可视化和比较

tag(字符串):用于标识添加的标量数据的名称或标签。在TensorBoard中,这个标签将用作图表的标题。
scalar_value(数值):要记录的标量数据的值。这可以是损失值、准确率等。
global_step(整数,可选):表示记录的步数或迭代次数。这个参数对于在TensorBoard中显示随时间变化的数据非常有用。例如,在训练神经网络时,您可以将当前的迭代次数传递给global_step,以便在TensorBoard中可视化损失值、准确率等随着训练步数的变化而变化的曲线。
walltime(时间戳,可选):表示记录的时间。如果不指定,则默认使用当前时间
使用tensorboard绘制 y = x 的函数
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") # 日志文件存储位置
for i in range(100):
writer.add_scalar("y = x", i, i) #前一个i是y 后一个i是横坐标
writer.close()
在终端输入
tensorboard --logdir=logs #logs是上面指定在writer = SummaryWriter("logs")中指定的文件夹名,日志文件存储在此文件中
指定窗口打开

tensorboard --logdir=logs --port=6007
模型训练
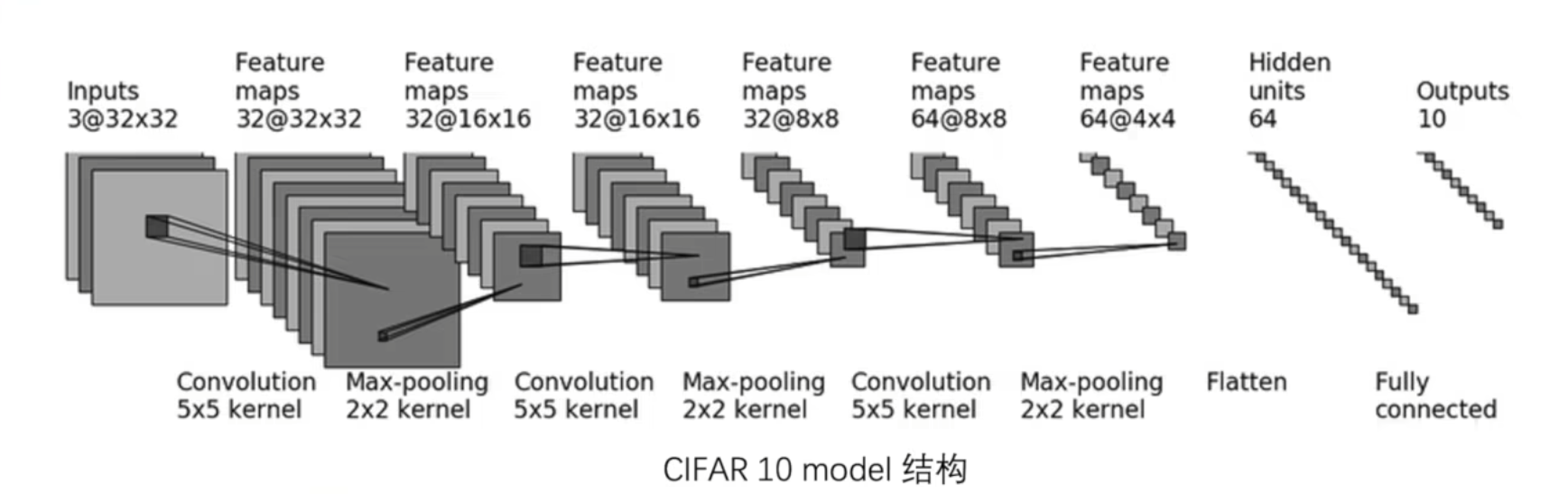
model.py
# 导入torch库和torch.nn模块
import torch
from torch import nn
# 定义一个继承自nn.Module的神经网络类Tudui
class Tudui(nn.Module):
# 定义初始化方法
def __init__(self) -> object:
# 调用父类的初始化方法
super(Tudui, self).__init__()
# 定义一个包含多个层的神经网络
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2), # 卷积层:输入通道3,输出通道32,卷积核大小5,步长1,填充2
nn.MaxPool2d(2), # 最大池化层:池化窗口大小2
nn.Conv2d(32, 32, 5, 1, 2), # 卷积层:输入通道32,输出通道32,卷积核大小5,步长1,填充2
nn.MaxPool2d(2), # 最大池化层:池化窗口大小2
nn.Conv2d(32, 64, 5, 1, 2), # 卷积层:输入通道32,输出通道64,卷积核大小5,步长1,填充2
nn.MaxPool2d(2), # 最大池化层:池化窗口大小2
nn.Flatten(), # 展平层:将多维张量展平为一维
nn.Linear(64 * 4 * 4, 64), # 全连接层:输入维度64*4*4,输出维度64
nn.Linear(64, 10) # 全连接层:输入维度64,输出维度10
)
# 定义前向传播方法
def forward(self, x):
x = self.model(x) # 将输入数据传递给定义好的神经网络
return x # 返回输出结果
# 主程序入口
if __name__ == '__main__':
tudui = Tudui() # 创建Tudui类的实例
input = torch.ones(64, 3, 32, 32) # 创建一个形状为(64, 3, 32, 32)的全1张量作为输入
output = tudui.forward(input) # 将输入数据传递给网络进行前向传播
print(output.shape) # 打印输出的形状
train.py
import torchvision
from torch.utils.data import DataLoader
from model import *
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)
# 从 torchvision.datasets 下载 CIFAR-10 训练数据集,并将其转换为张量(Tensor)。数据集将保存在 './data' 目录中。
test_data = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 从 torchvision.datasets 下载 CIFAR-10 测试数据集,并将其转换为张量(Tensor)。数据集将保存在 './data' 目录中。
# 获得数据集长度
train_data_size = len(train_data)
# 获取训练数据集的样本数量。
test_data_size = len(test_data)
# 获取测试数据集的样本数量。
print('训练数据集的长度为:{}'.format(train_data_size))
# 打印训练数据集的样本数量。
print('测试数据集的长度为:{}'.format(test_data_size))
# 打印测试数据集的样本数量。
# 利用dataloader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
# 使用 DataLoader 将训练数据集按批次加载,每个批次包含 64 张图像。
test_dataloader = DataLoader(test_data, batch_size=64)
# 使用 DataLoader 将测试数据集按批次加载,每个批次包含 64 张图像。
# 创建网络模型
tudui = Tudui()
# 实例化自定义的神经网络模型 'Tudui'。
# 如果可用,使用GPU
if torch.cuda.is_available():
tudui = tudui.cuda()
# 如果检测到 GPU 可用,将模型移至 GPU 以加速训练。
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义损失函数为交叉熵损失函数(CrossEntropyLoss),通常用于多分类任务。
# 创建优化器
learning_rate = 0.01
# 设置学习率为 0.01。
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 使用随机梯度下降(SGD)优化器,并将模型的参数传递给优化器进行更新。
# 创建SummaryWriter来记录训练日志
writer = SummaryWriter('logs')
# 创建 SummaryWriter 对象,用于记录训练过程中的日志和指标,方便使用 TensorBoard 可视化。
# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
# 初始化训练步数计数器。
total_test_step = 0 # 记录测试次数
# 初始化测试步数计数器。
epochs = 10 # 训练的轮数
# 设置训练轮数为 10 轮。
# 开始训练
for epoch in range(epochs):
print('----------第{}轮训练开始----------'.format(epoch + 1))
# 循环开始,逐轮进行训练,并打印当前的轮次。
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
# 从数据加载器中获取一批训练数据,包括图像和对应的标签。
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
# 如果 GPU 可用,将图像和标签数据移至 GPU。
outputs = tudui(imgs)
# 将图像输入模型,得到模型的输出。
loss = loss_fn(outputs, targets)
# 计算模型输出与真实标签之间的损失。
# 优化器优化模型
optimizer.zero_grad()
# 清空优化器中所有参数的梯度,避免梯度累积。
loss.backward()
# 反向传播,计算参数的梯度。
optimizer.step()
# 使用优化器更新模型参数。
total_train_step += 1
# 训练步数计数器加一。
if total_train_step % 100 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
# 每 100 次训练后,打印当前的训练步数和损失值。
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 使用 SummaryWriter 记录当前步数的训练损失值,供 TensorBoard 使用。
# 训练步骤结束
# 测试步骤开始
total_test_loss = 0
# 初始化测试集总损失为 0。
total_accuracy = 0
# 初始化测试集总准确率为 0。
with torch.no_grad():
# 禁用梯度计算,提高测试过程的效率。
for data in test_dataloader:
imgs, targets = data
# 从数据加载器中获取一批测试数据。
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
# 如果 GPU 可用,将图像和标签数据移至 GPU。
outputs = tudui(imgs)
# 将图像输入模型,得到模型的输出。
loss = loss_fn(outputs, targets)
# 计算模型输出与真实标签之间的损失。
total_test_loss += loss.item()
# 将当前批次的损失累加到测试集总损失中。
accuracy = (outputs.argmax(1) == targets).sum()
# 计算当前批次中预测正确的样本数量。
total_accuracy += accuracy
# 将当前批次的正确预测数量累加到总准确率中。
print('整体测试集上的loss:{}'.format(total_test_loss))
# 打印测试集的总损失。
print('整体测试集上的accuracy:{}'.format(total_accuracy/test_data_size))
# 打印测试集的总准确率。
writer.add_scalar('test_loss', total_test_loss, total_test_step)
# 使用 SummaryWriter 记录测试集总损失,供 TensorBoard 使用。
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
# 使用 SummaryWriter 记录测试集准确率,供 TensorBoard 使用。
total_test_step += 1
# 测试步数计数器加一。
torch.save(tudui.state_dict(), 'tudui_{}.pth'.format(epoch+1))
# 保存当前轮次训练后的模型参数,保存文件名中包含当前轮次。
print("模型保存成功!")
# 打印模型保存成功的消息。
writer.close()
# 关闭 SummaryWriter,确保所有日志数据写入文件。
代码运行结束后生成的tudui_1.pth是什么,如何使用
tudui_1.pth 是 PyTorch 保存的模型权重文件。它包含了在第一轮训练结束后,模型 Tudui 的所有参数。这些参数在后续训练中被用来继续优化模型,或者在后期加载后进行推理和预测。
加载模型权重:
可以使用 torch.load() 函数加载这个文件,并用 model.load_state_dict() 方法将权重加载到模型中。
使用已加载的模型进行推理:
一旦加载了权重,就可以使用这个模型来对新数据进行预测。
如何加载并使用 tudui_1.pth 文件:
import torch
from model import Tudui # 导入你的模型定义
import torchvision.transforms as transforms
from PIL import Image
# 创建模型实例
model = Tudui()
# 加载模型权重
model.load_state_dict(torch.load('tudui_1.pth'))
# 如果有GPU可用,可以将模型移到GPU上
if torch.cuda.is_available():
model = model.cuda()
# 切换模型到评估模式
model.eval()
# 加载并预处理测试图像
image = Image.open('path_to_your_image.jpg') # 替换为实际图片路径
transform = transforms.Compose([
transforms.Resize((32, 32)), # CIFAR-10 图片尺寸为 32x32
transforms.ToTensor(),
])
image = transform(image).unsqueeze(0) # 添加一个 batch 维度
# 如果使用GPU,将图像移到GPU上
if torch.cuda.is_available():
image = image.cuda()
# 使用模型进行推理
with torch.no_grad():
output = model(image)
predicted_class = output.argmax(1).item()
print(f'Predicted class: {predicted_class}')