一、Abstract
(一) 问题
model merging(模型融合)是无需额外训练,直接将多个不同的任务网络融合成一个多任务网络。但面临两个问题:(a)interference between different models(不同模型之间的干扰)和(b) heterogeneous data during testing(测试中的异构数据);这两个问题使传统模型融合的效果并不比按任务微调模型效果好;同时,这种模型融合缺乏泛化性,即“对多样化测试数据的灵活性”
(二) 思路
1. 知识模块化为共享和专有组件
modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency;
2. 根据输入动态融合共享和特定任务知识
dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data.
二、总结
(一) 提出问题:
在大规模语言模型时代,模型合并是一种有前景的方法,可以将多个特定任务的模型合并为一个多功能模型,而无需额外训练。然而,现有方法在合并不同领域的模型时,往往会牺牲特定任务的性能,导致与单独微调模型相比存在较大的性能差距。
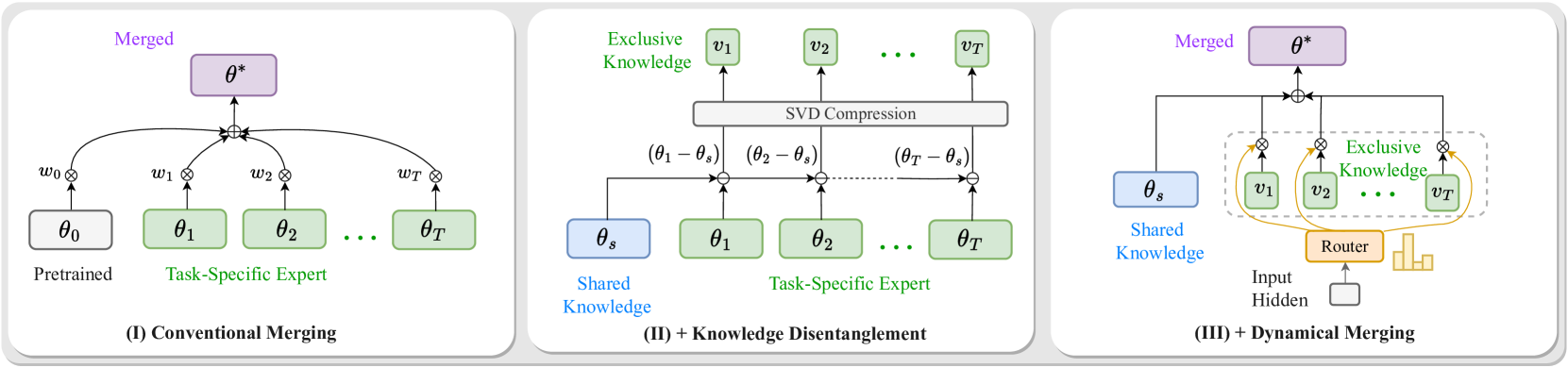

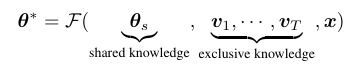
图(I)显示在传统合并方法中,来自不同任务特定模型和预训练模型的参数被加权求和成一个单一的多任务模型进行推理(parameter averaging [6, 74], weight interpolation [46, 33], and advanced strategies like task arithmetic [29, 51, 78, 67])。图(II)展示了Twin-Merging首先隔离共享知识,然后通过识别任务专家与共享模型之间的差异来提取独有知识。这种独有知识随后被压缩成稀疏向量。图(III)显示在测试期间,Twin-Merging根据测试输入动态合并共享和压缩的专业知识,以形成最终的推理模型。
传统方法面临两大挑战:
(1)模型之间的干扰,包括参数冗余和符号差异以及任务之间的分布差距(parameter redundancy and sign discrepancies [76], as well as the distribution gap between tasks [31]);【参数干扰:在不同任务模型中 位于相同位置(例如,自注意力权重)的参数中发现的冗余或符号差异,这反过来又导致信息冲突和性能损失。】
(2)测试时数据的异质性,即单一模型难以适应多样化的测试数据。先前的方法追求的是"single, static optimal solution for various tasks"(针对各种任务的单一、静态最优解),而这种“one-size-fits-all model”成功避免了引入新参数,但产生了由于测试输入的不确定性从而导致输出不足或结果次优的可能性 [78]。这限制了互补知识的利用,导致相对单个expert模型性能下降。
(二) 方法:
1. 知识模块化(Knowledge Modularization)
Twin-Merging将专家模型的知识分解为共享知识和特定任务的独有知识。通过压缩技术减少冗余并提高效率。(模型内存在由shared knowledge构成的共享专家(shared expert)和由task-specific knowledge构成的任务专家(task experts))
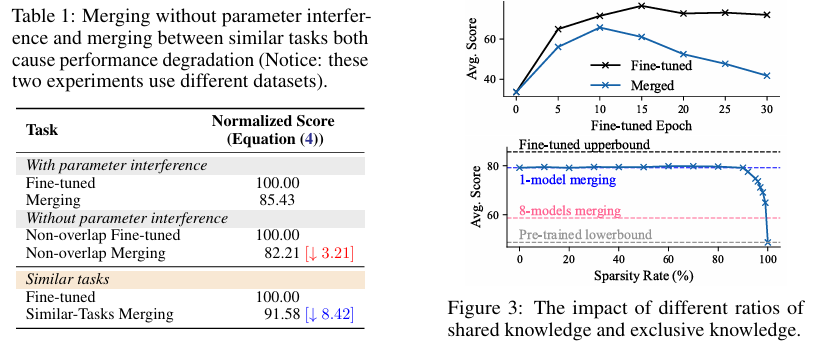
表格内容展示了无参数干扰的合并以及相似任务间的合并都会导致性能下降,而图展示了共享知识与专有知识不同比例的影响
过多的微调迭代可能导致灾难性遗忘,这是一种模型保留特定任务知识但失去一般知识的现象。随着微调迭代的增加,共享知识逐渐减少。图的上半部分说明了随着迭代次数的增加,合并性能显著下降,尽管微调模型在其任务上表现良好。这强调了共享知识在合并性能中的关键作用。
文章团队应用稀疏化方法(例如 SVD)来降低合并模型中特定任务权重的比例,从 100% (标准合并)降低到 0% (基础模型)。如图的下部分所示,性能在 90% 稀疏化之前保持稳定。值得注意的是,即使在 99% 稀疏化率下,单个合并模型也优于多模型合并,证实了专有知识的存在,并且随着模型数量的增加而更加明显。这也强调了未合并特定任务知识的价值,因为通过保留未合并的特定任务信息,微调性能可以有效地恢复。
总结来说,共享知识和未合并的任务特定知识在合并性能中发挥着至关重要的作用。任务特定知识的排他性阻碍了合并方法的有效性。不同类型的知识需要分离和模块化以实现最佳性能。
2. 共享知识
通过任务算术等技术提取共享专家模型,捕捉跨任务的通用知识。
3. 独有知识
基于任务专家与共享专家之间的差异,提取独有知识,并通过奇异值分解(SVD)进行压缩。
4. 动态合并(Dynamic Merging)
【将参数合并问题简化为条件组合问题】在推理阶段,根据输入动态合并共享知识和独有知识。引入router,根据输入数据的特征动态调整合并的参数(conditionally injected,有条件地注入),从而更好地适应不同的测试数据。
5. 知识解耦与动态融合(knowledge disentanglement and dynamic merging)
(三) 实现
1. 预处理
(1) 共享专家:为了分离不同模型之间的共享知识,我们将预合并模型视为一个自然占位符来封装对所有任务都重要的公共知识(表示为 𝜽∗ )。通过利用已建立的合并技术,如任务算术,我们可以轻松地从初始合并模型中提取共享专家。
(2) 独有知识:为了传达特定任务的信息同时分离公共知识,我们计算差分向量: 𝒗t=𝜽t−𝜽∗ 。这个减法向量保留了未合并的任务特定信息,同时丢弃了共享知识。
(3) 压缩的独有向量:为了实际应用和分发,我们应用奇异值分解(SVD)将上述独有知识进一步压缩成每个任务的向量。假设𝒗t存在秩为m的分解,对于𝒗t=𝐔t𝚺t𝐕tT ,通过选择前 r 个奇异值,我们实现了一个低秩的任务空间,结果为 𝐔t(r)𝚺t(r)𝐕t(r)T 。我们只存储𝐔t(r),𝚺t(r),𝐕t(r)T。
2. 推理inference
适应不可预见的挑战是困难的,尤其是在多样化的测试数据中。例如,如果大部分数据由某种类型组成,我们应该为该特定任务定制合并模型以获得最佳结果,而不是预先定义最佳参数。
文章提出了一种新的方法,该方法结合了共享的专业知识和专有知识。文章的方法涉及使用输入 𝒙 动态调整当前数据,使我们能够利用共享知识并根据输入应用专业专业知识。
(四) 实验结果:
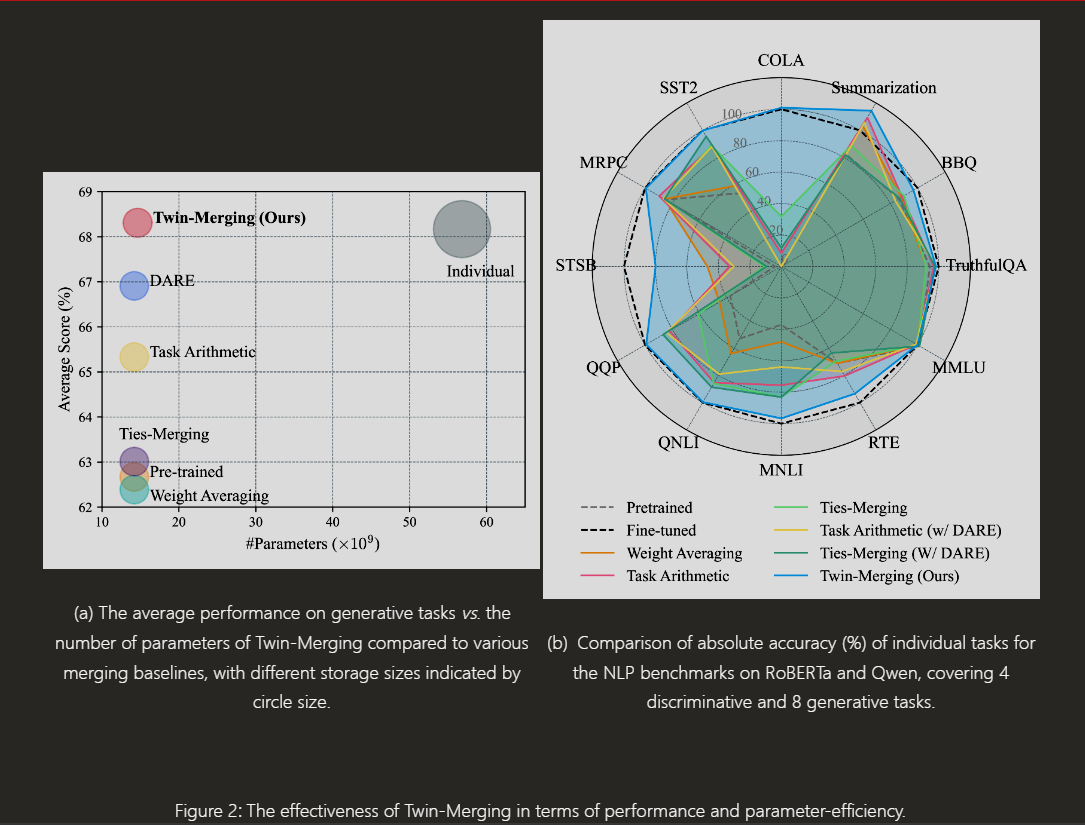
在12个数据集上进行了广泛的实验,涵盖判别性和生成性任务,以及不同的模型架构和领域内/领域外设置。
Twin-Merging在所有数据集上均优于其他合并方法,判别性任务的平均绝对归一化分数提高了28.34%,生成性任务甚至超过了微调模型的上限。
在参数效率方面,即使在参数减少99.9%的情况下,性能仅下降了14%,显示出良好的可扩展性和存储效率。
(五) 贡献:
1. 对模型效果下降的深层原因进行探究
文章团队使用 LoRA 微调了 Qwen-14B,将非重叠模块分配以避免参数干扰。尽管如此,性能下降了 3.21 %,表明干扰持续存在。其次,文章团队使用两个类似的摘要任务(XSUM 和 DailyMail),观察到与单独微调的模型相比,性能下降了 8.42 %,这证实了干扰即使在相似任务之间也持续存在。这些结果表明,模型合并中的干扰不仅限于参数和任务层面的问题。
2. 研究了共享知识和独有知识对合并性能的影响,并提出了创新的知识解耦和动态合并技术。
3. 提出Twin-Merging易于实现,超参数少,无需重新训练专家模型,且可以与其他合并方法结合以获得进一步的改进。
(六) 其他相关方案:
1. Multi-Task Learning. 多任务学习
多任务训练通常通过同时优化特定任务的目标来学习多任务特征,从而促进不同知识在模型中的整合。现有工作主要关注通过参数共享、调整合适的目标、寻找合适的任务权重以及最小化负迁移来缓解任务冲突和灾难性遗忘。在模型不断增大、任务场景数量增加的时代,我们需要探索一种更经济高效的多任务学习方法。因此,我们的重点是那些不需要获取或整合多任务数据且不涉及现有专家额外更新的多任务场景。
2. Mixture of Experts. 混合专家
为了在不增加计算成本的情况下提高模型的可扩展性,混合专家(MoE)范式引入了对一组可学习参数的 conditional routing of inputs。一些研究扩展了 Transformer 中的前馈网络(FFN),以纳入 MoE 层,例如 GShard和 Switch Transformer。这些模型通常采用可学习的 top-2 或 top-1 路由策略,将 MoE 语言模型扩展到极其庞大的规模。最近的研究主要集中在专家负载均衡、训练不稳定性、专家专业化和同步降低等挑战上。
然而,这些方法通常需要大量的多任务数据和昂贵的联合训练。相比之下,文章的方法直接重用特定任务的专家,导致专家在不同领域的自然专业化。我们只需要对一个小型路由器进行最小程度的微调,以计算融合权重,这使得Twin-Merging方法非常高效。
(七) 思考点与思路
- 知识解耦的重要性:
-
- Twin-Merging通过将知识分解为共享和独有两部分,有效地解决了模型合并中的干扰问题。这种方法强调了在合并过程中对知识进行精细化管理的重要性。
- 动态合并的灵活性:
-
- 动态合并机制使模型能够根据输入数据的特征灵活调整合并参数,从而更好地适应多样化的测试数据。这为处理异质性数据提供了一种有效的策略。
- 压缩技术的应用:
-
- 通过SVD等压缩技术减少独有知识的存储需求,不仅提高了效率,还降低了模型的存储成本。
(八) 优化思路
- 多任务学习中的应用:
-
- Twin-Merging可以应用于多任务学习场景,通过动态调整任务特定的知识模块,进一步提高模型在多任务上的性能。
- 跨模态模型合并:
-
- 当前Twin-Merging主要针对语言模型,可以探索将其应用于跨模态任务(如图像和文本)的模型合并,以验证其在更广泛场景下的有效性。
- 结合其他优化技术:
-
- 将Twin-Merging与其他模型优化技术(如剪枝、量化)结合,进一步提高模型的效率和性能。
- 自适应学习率调整:
-
- 在动态合并阶段,引入自适应学习率调整机制,根据输入数据的复杂性动态调整路由器的学习率,以提高合并的精度。
- 多阶段动态合并:
-
- 目前的动态合并是基于单个路由器的。可以探索多阶段动态合并,即在不同层次上逐步合并共享和独有知识,以进一步提高模型的适应性。
- 结合强化学习:
-
- 引入强化学习机制来优化路由器的决策过程,使其能够更智能地选择合适的任务特定知识进行合并。