目录
⑵. String s2 = new String("hello");
①String s1 = "abc" 和 String s2 = new String("hello") 的内存位置
⑵.String(char[] value, int offset, int count)
(2) String(byte[] bytes, int offset, int length)
(3) String(byte[] bytes, Charset charset)
(4) String(byte[] bytes, String charsetName)
3. String(String original) 构造方法
一、String初识

Java 中所有使用双引号("")直接定义的字符串字面量,在 编译阶段 会被识别并记录到 class 文件的常量池中。当程序运行时,JVM 会将这些字符串字面量加载到 字符串常量池(String Pool)中,并确保每个唯一的字符串字面量在池中仅保留 一份实例。以下是详细说明:
1. 字符串字面量的处理流程
(1) 编译阶段
当 Java 源代码被编译为字节码(
.class文件)时,所有双引号包围的字符串字面量(如"hello")会被记录在 class 文件的 常量池表(Constant Pool) 中。目的:为后续的类加载和运行阶段提供字符串的元数据。
(2) 类加载阶段
当类被 JVM 加载时,字符串字面量会被加载到 运行时常量池(Runtime Constant Pool)。
关键点:此时尚未创建实际的
String对象,仅记录字面量的引用。
(3) 运行时阶段
首次使用字符串字面量时:JVM 会检查字符串常量池中是否存在相同内容的字符串:
存在:直接返回池中对象的引用。
不存在:在堆内存的字符串常量池中创建新对象,并返回其引用。
驻留(Interning):此过程称为字符串的驻留,确保相同内容的字符串字面量共享同一实例。
2. 示例验证
示例 1:字面量直接赋值
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // true(指向同一对象)-
结果分析:
s1和s2指向字符串常量池中的同一实例。
示例 2:使用 new 创建字符串
显式使用 new 创建字符串对象时,会在堆中生成新对象,绕过常量池。
String s3 = new String("hello");
String s4 = new String("hello");
System.out.println(s3 == s4); // false(堆中不同对象)
System.out.println(s3.equals(s4)); // true(内容相同)-
结果分析:
new会强制在堆中创建新对象,即使内容相同。
示例 3:显式调用 intern()
String s5 = new String("hello").intern();
String s6 = "hello";
System.out.println(s5 == s6); // true(s5 被驻留到池中)-
结果分析:
intern()方法将字符串手动添加到常量池(若池中不存在)。
注意点1:
public class StringTest1 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2); // true(指向同一对象)
/*String s1 = "abc";
String s2 = new String("hello");*/
}
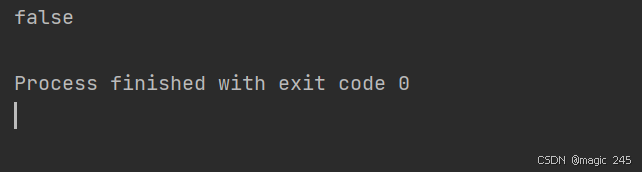
}String s1 = "abc"; String s2 = new String("hello");这两个是不是都在字符串常量池?
运行结果:

⑴. String s1 = "abc";
当使用双引号直接创建字符串时,Java 会首先检查字符串常量池(String Constant Pool)中是否已经存在相同内容的字符串对象。如果存在,就直接返回常量池中该对象的引用;如果不存在,则在常量池中创建一个新的字符串对象,并返回其引用。
对于代码 String s1 = "abc";,由于使用了双引号直接创建字符串,所以 "abc" 会被存储在字符串常量池中,变量 s1 引用的就是常量池中的这个 "abc" 对象。
以下是示例代码验证:
public class StringConstantPoolExample {
public static void main(String[] args) {
String s1 = "abc";
String s3 = "abc";
System.out.println(s1 == s3); // 输出 true,说明 s1 和 s3 引用的是同一个对象
}
}⑵. String s2 = new String("hello");
当使用 new 关键字创建字符串对象时,会在堆内存中创建一个新的字符串对象。同时,双引号中的 "hello" 部分会像上面一样先检查字符串常量池,如果常量池中不存在 "hello",则会在常量池中创建一个 "hello" 对象;如果已经存在,则不会再创建。
也就是说,new String("hello"); 会创建至少一个对象,如果常量池中原本没有 "hello",则会创建两个对象,一个在常量池中,一个在堆内存中。变量 s2 引用的是堆内存中的那个新创建的字符串对象,而不是常量池中的对象。
以下是示例代码验证:
public class StringConstantPoolExample {
public static void main(String[] args) {
String s2 = new String("hello");
String s4 = "hello";
System.out.println(s2 == s4); // 输出 false,说明 s2 和 s4 引用的不是同一个对象
}
}运行结果:
总结
String s1 = "abc";中的"abc"在字符串常量池中。String s2 = new String("hello");中,"hello"会在字符串常量池中存在一份,而s2引用的是堆内存中通过new关键字创建的新对象,不在常量池中。
注意点2:
如果常量池中原本没有 "hello",则会创建两个对象,一个在常量池中,一个在堆内存中。那为什么还会有intern() 方法将字符串手动添加到常量池(若池中不存在)?
解释:
使用 new String("hello") 这种方式在常量池中原本没有 "hello" 时会在常量池和堆内存各创建一个对象,但这和 intern() 方法的作用并不冲突,下面详细解释:
new String("hello") 创建对象的情况
当执行 String s = new String("hello"); 时:
- 常量池部分:双引号中的
"hello"会先检查字符串常量池,若池中没有"hello",则在常量池中创建"hello"对象。- 堆内存部分:使用
new关键字会在堆内存中创建一个新的String对象,该对象的字符序列内容和常量池中的"hello"相同,但它是一个独立的对象实例。s引用的就是堆内存中的这个对象。
intern() 方法的作用
intern() 方法是 String 类的一个实例方法,其作用是手动将字符串添加到常量池中(若池中不存在该字符串),并返回常量池中的字符串引用。虽然 new String("hello") 已经会在常量池创建对象,但有些情况下还是需要使用 intern() 方法,主要原因如下:
① 动态创建的字符串
new String("hello") 这种方式是在编译期就确定了字符串内容,而有些字符串是在运行时动态生成的,这些动态生成的字符串默认不会放入常量池。例如:
public class StringInternExample {
public static void main(String[] args) {
String str1 = "hello";
String str2 = "world";
String dynamicStr = str1 + str2; // 动态生成 "helloworld"
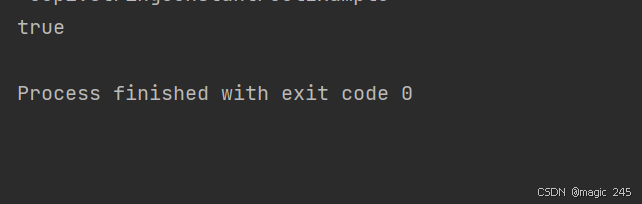
String internedStr = dynamicStr.intern();
String literalStr = "helloworld";
System.out.println(internedStr == literalStr); // 输出 true
}
}运行结果:
在上述代码中,dynamicStr 是通过字符串拼接动态生成的,它只存在于堆内存中,不会自动放入常量池。调用 intern() 方法后,会检查常量池中是否有 "helloworld",若没有则将其添加到常量池,并返回常量池中的引用。
②节省内存和提高比较效率
由于常量池中的字符串对象是唯一的,使用 intern() 方法可以让多个内容相同的字符串引用指向常量池中的同一个对象,从而节省内存。同时,使用 == 比较常量池中的字符串引用比使用 equals() 方法比较字符串内容要快。例如:
public class StringInternMemoryExample {
public static void main(String[] args) {
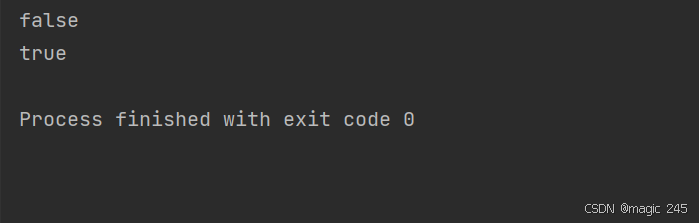
String s1 = new String("test");
String s2 = new String("test");
System.out.println(s1 == s2); // 输出 false,因为 s1 和 s2 是堆内存中的不同对象
String internedS1 = s1.intern();
String internedS2 = s2.intern();
System.out.println(internedS1 == internedS2); // 输出 true,因为它们都指向常量池中的同一个对象
}
}运行结果:
注意点3:字符串的拼接
使用 + 进行拼接的生成的新的字符串不会被放到字符串常量池中。(+两边至少有一个是变量。) * * 当 + 两边都是字符串字面量的时候,编译器会进行自动优化。在编译阶段进行拼接。
/**
* 使用 + 进行拼接的生成的新的字符串不会被放到字符串常量池中。(+两边至少有一个是变量。)
*
* 当 + 两边都是字符串字面量的时候,编译器会进行自动优化。在编译阶段进行拼接。
*/
public class StringConstantPoolExample {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "def";
String s3 = s1 + s2;//s1和s2是变量
String s4 = "abcdef";
// s3 指向的对象,没有在字符串常量池中。在堆中。
// 底层实际上在进行 + 的时候(这个 + 两边至少有一个是变量),会创建一个StringBuilder对象,进行字符串的拼接。
// 最后的时候会自动调用StringBuilder对象的toString()方法,再将StringBuilder
// 转换成String对象。
//System.out.println(s3 == s4); // false
// 以下程序中 + 两边都是字符串字面量,这种情况java对其进行优化:
// 在编译的时候就完成了字符串的拼接。
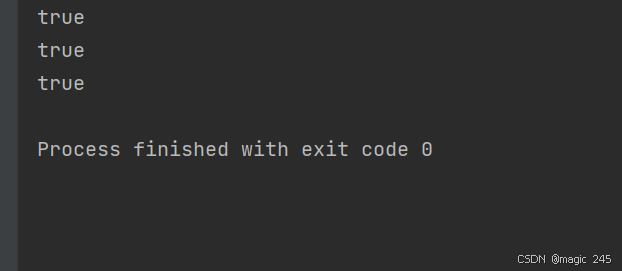
String x = "java" + "test"; // 等同于:String x = "javatest";
String y = "javatest";
System.out.println(x == y); // true
// 以上程序中s3指向了堆中的一个字符串对象,并没有在常量池中。
// 如果这个字符串使用比较频繁,希望将其加入到字符串常量池中,怎么办?
String s5 = s3.intern();
System.out.println(s4 == s5); // true
String m = "m";
String f = m + "e";
String str = f.intern(); // 将"me"放入字符串常量池中,并且将"me"对象的地址返回。
System.out.println(str == "me"); // true
}
}运行结果:
注意点1和注意点2总结
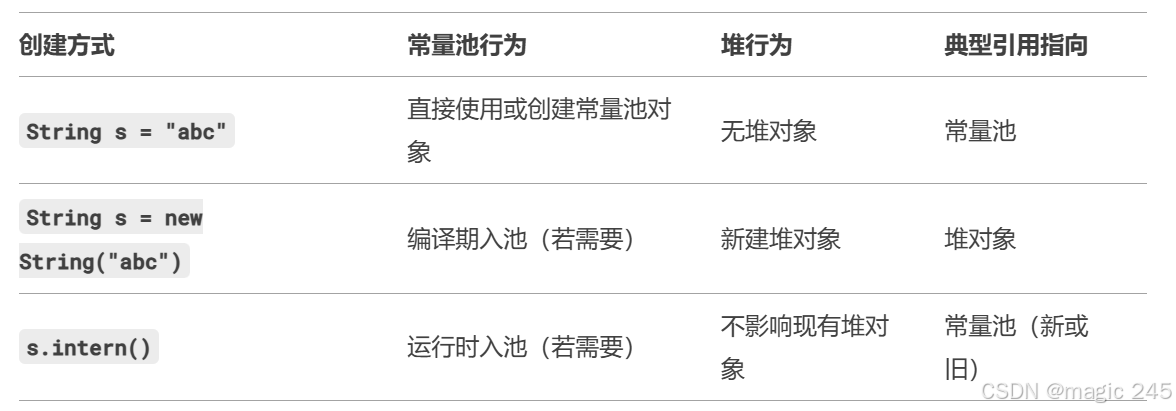
①String s1 = "abc" 和 String s2 = new String("hello") 的内存位置
-
直接赋值
"abc":-
编译期行为:
"abc"是字面量,编译时会被放入字符串常量池(如果池中不存在)。 -
变量
s1的引用:直接指向常量池中的"abc"对象。 -
验证:通过
s1 == "abc"为true可确认。
-
-
new String("hello"):-
编译期行为:
"hello"作为字面量,编译时会检查并放入常量池(若不存在)。 -
运行时行为:
new会在堆中创建一个新对象,其内容与常量池中的"hello"相同。 -
变量
s2的引用:指向堆中的新对象,而非常量池中的"hello"。 -
验证:通过
s2 == "hello"为false可确认。
-
② 为什么需要 intern() 方法?
new String("hello") 已经在常量池中存入了 "hello",但 intern() 的用途远不止于此:
(1) 动态生成的字符串不会自动入池
-
问题:运行时通过拼接、计算生成的字符串(如
new String("he") + "llo")默认仅存在于堆中,不会自动进入常量池。 -
示例:
String s3 = new String("he") + "llo"; // 堆中的新对象,内容为 "hello"
String s4 = "hello";
System.out.println(s3 == s4); // false,s3在堆,s4在常量池解决:调用 s3.intern() 会将 "hello" 手动添加到常量池(若池中没有),并返回池中引用:
String s5 = s3.intern();
System.out.println(s5 == s4); // true,s5指向常量池中的"hello"运行结果:
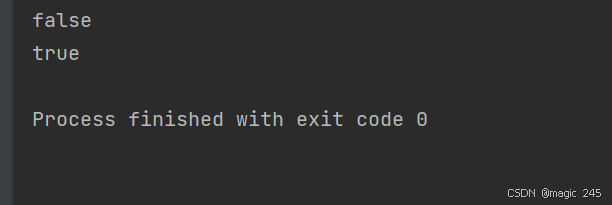
执行完上述代码后,各个变量的指向情况如下:
s3:指向堆内存中通过字符串拼接创建的内容为"hello"的对象。s4:指向字符串常量池中的"hello"对象。s5:指向字符串常量池中的"hello"对象。
(2) 节省内存和加速比较
-
内存优化:若程序中有大量重复字符串(如从文件、网络读取的动态数据),使用
intern()可让相同内容的字符串共享常量池的唯一实例,减少内存占用。 -
性能提升:用
==代替equals()比较字符串引用,效率更高。
(3) 避免重复创建常量池对象
-
误区澄清:
new String("hello")仅在编译时检查常量池,而运行时生成的字符串不会触发此机制。intern()是运行时主动入池的唯一方式。 -
示例:
// 常量池中已有"hello",new String("hello") 不会重复创建常量池对象
String s6 = new String("hello").intern(); // 直接返回常量池中的引用
System.out.println(s6 == "hello"); // true③intern() 的核心作用
行为:检查常量池中是否存在与当前字符串内容相同的对象:
存在:直接返回池中对象的引用。
不存在:将当前字符串的引用添加到池中(注意:JDK7+ 后,常量池位于堆中,直接保存引用,而非拷贝对象)。
关键场景:
动态字符串入池(如
StringBuilder拼接的结果)。复用高频字符串(如数据库查询结果的重复字段)。
④ 最终结论
-
"abc"在常量池,new String("hello")的堆对象和常量池对象共存。 -
intern()的核心价值:处理动态生成的字符串,确保其引用能被常量池管理,从而优化内存和比较效率。即使new String("hello")在编译期将字面量存入常量池,intern()仍是运行时控制字符串入池的唯一手段。
3. 字符串常量池的位置
-
Java 8 之前:位于永久代(PermGen),可能导致
OutOfMemoryError: PermGen space。 -
Java 8 及之后:移至堆内存,便于垃圾回收,避免内存溢出。
4. 关键特性
(1) 不可变性(String为什么不可变?(很重要))
-
底层实现:
String使用private final byte[] value(Java 9+)或char[](Java 8 及之前)存储数据,内容不可修改。
byte[ ]数组创建长度一旦确定不可变
-
操作影响:任何修改字符串的操作(如拼接、替换)都会生成新对象,原对象不变。
(2) 唯一性保证
-
编译时确定性:所有双引号定义的字符串字面量在编译时确定其唯一性,运行时保证池中仅一份实例。
-
动态字符串处理:运行时通过拼接生成的字符串(如
s1 + s2)默认不在池中,需调用intern()手动驻留。
5. 注意事项
-
避免滥用
new String("..."):-
直接使用字面量赋值更高效,避免不必要的堆内存分配。
-
// 推荐
String s = "hello";
// 不推荐(除非明确需要新对象)
String s = new String("hello");-
性能优化与内存管理:
-
频繁拼接字符串时使用
StringBuilder或StringBuffer。 -
谨慎使用
intern(),可能导致常量池膨胀。
-
-
字符串比较原则:
-
使用
equals()比较内容,而非==(除非明确需要地址比较)。
-
二、String类常用的构造方法
1. 基于字符数组的构造方法
⑴. String(char[] value)
此构造方法根据字符数组创建一个新的字符串对象。
public class StringConstructorExample {
public static void main(String[] args) {
// 定义一个字符数组
char[] charArray = {'H', 'e', 'l', 'l', 'o'};
// 使用字符数组创建字符串对象
String str = new String(charArray);
System.out.println(str); // 输出: Hello
}
}运行结果:
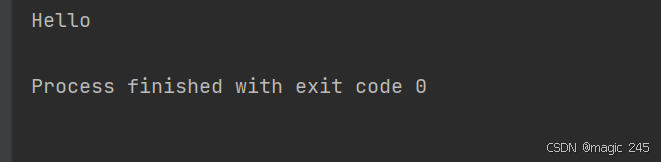
⑵.String(char[] value, int offset, int count)
功能:截取字符数组的指定部分生成字符串。
参数:
offset:起始索引。
count:截取长度。
示例:
public class StringConstructorExample {
public static void main(String[] args) {
// 定义一个字符数组
char[] charArray = {'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd'};
// 从索引2开始,取5个字符创建字符串对象
String str = new String(charArray, 2, 5);
System.out.println(str); // 输出: llo W
}
}运行结果:
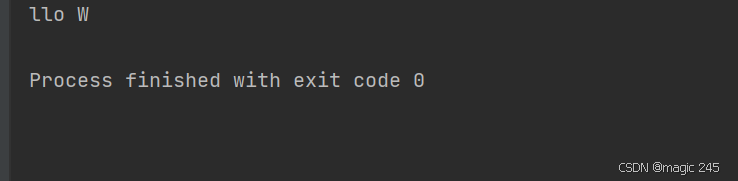
2. 基于字节数组的构造方法
⑴.String(byte[] bytes)
此构造方法根据字节数组创建一个新的字符串对象,默认使用平台默认的字符集进行解码。
public class Main {
public static void main(String[] args) {
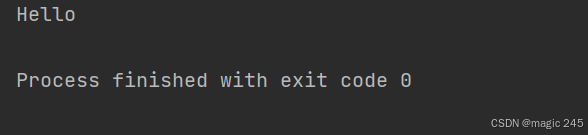
byte[] bytes = {72, 101, 108, 108, 111}; // "Hello" 的 ASCII 编码
String str = new String(bytes); // 结果:"Hello"
System.out.println(str);
}
}运行结果:
(2) String(byte[] bytes, int offset, int length)
该构造方法根据字节数组的指定部分创建一个新的字符串对象,默认使用平台默认的字符集进行解码。
-
功能:截取字节数组的指定部分,按默认字符集解码。
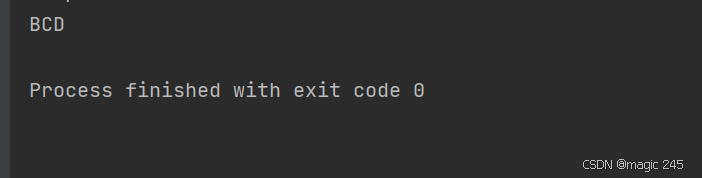
public class Main {
public static void main(String[] args) {
byte[] bytes = {65, 66, 67, 68, 69};
String str = new String(bytes, 1, 3); // 解码字节 66,67,68 → "BCD"
System.out.println(str);
}
}运行结果:
(3) String(byte[] bytes, Charset charset)
此构造方法根据字节数组和指定的字符集创建一个新的字符串对象
在 Java 里,字符串在内存中是以 Unicode 编码形式存储的。而字节数组则可能是按照不同的字符编码规则存储的数据,比如 UTF - 8、GBK 等。此构造方法的目的就是依据给定的字符集(Charset 对象),把字节数组中的字节数据解码成对应的 Unicode 字符,进而构建一个新的 String 对象。
-
功能:使用指定字符集解码字节数组。
方法签名
public String(byte[] bytes, Charset charset)
- 参数:
bytes:要进行解码的字节数组。charset:用于解码字节数组的字符集,类型为java.nio.charset.Charset。
示例:
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
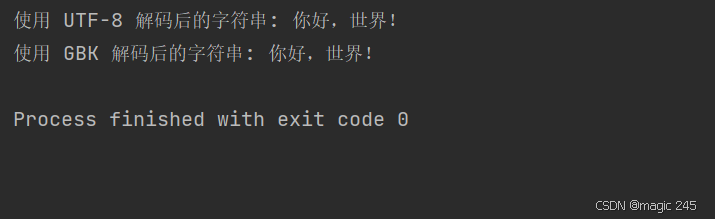
public class StringConstructorExample {
public static void main(String[] args) {
// 定义一个字符串
String originalString = "你好,世界!";
// 使用 UTF-8 字符集将字符串编码为字节数组
byte[] utf8Bytes = originalString.getBytes(StandardCharsets.UTF_8);
// 使用 UTF-8 字符集将字节数组解码为字符串
String decodedUtf8String = new String(utf8Bytes, StandardCharsets.UTF_8);
System.out.println("使用 UTF-8 解码后的字符串: " + decodedUtf8String);
// 使用 GBK 字符集将字符串编码为字节数组
byte[] gbkBytes = originalString.getBytes(Charset.forName("GBK"));
// 使用 GBK 字符集将字节数组解码为字符串
String decodedGbkString = new String(gbkBytes, Charset.forName("GBK"));
System.out.println("使用 GBK 解码后的字符串: " + decodedGbkString);
}
}运行结果:
(4) String(byte[] bytes, String charsetName)
功能概述
当你有一个字节数组,并且知道这些字节是按照某种特定字符编码规则存储的,就可以使用这个构造方法,传入字节数组和对应的字符集名称,将字节数组转换为 String 对象。该构造方法会在内部查找指定名称的字符集,并使用它来完成解码操作。
方法签名
public String(byte[] bytes, String charsetName) throws UnsupportedEncodingException
- 参数:
bytes:需要进行解码的字节数组。charsetName:用于解码字节数组的字符集名称,例如"UTF-8"、"GBK"等。- 异常:如果指定的字符集名称无效,也就是 JVM 不支持该字符集,会抛出
UnsupportedEncodingException异常。
示例代码
import java.io.UnsupportedEncodingException;
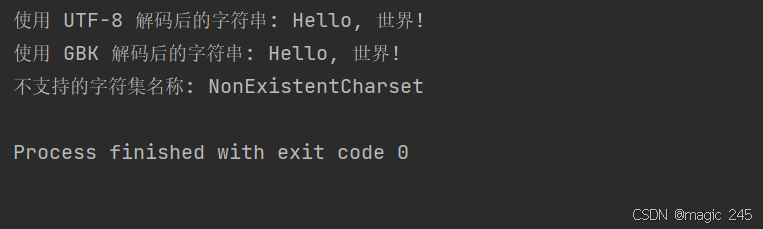
public class StringConstructorWithCharsetName {
public static void main(String[] args) {
// 定义原始字符串
String originalString = "Hello, 世界!";
try {
// 使用 UTF-8 编码成字节数组
byte[] utf8Bytes = originalString.getBytes("UTF-8");
// 使用 UTF-8 字符集名称解码字节数组
String decodedUtf8String = new String(utf8Bytes, "UTF-8");
System.out.println("使用 UTF-8 解码后的字符串: " + decodedUtf8String);
// 使用 GBK 编码成字节数组
byte[] gbkBytes = originalString.getBytes("GBK");
// 使用 GBK 字符集名称解码字节数组
String decodedGbkString = new String(gbkBytes, "GBK");
System.out.println("使用 GBK 解码后的字符串: " + decodedGbkString);
// 尝试使用一个不存在的字符集名称
try {
String nonExistentCharset = new String(utf8Bytes, "NonExistentCharset");
} catch (UnsupportedEncodingException e) {
System.out.println("不支持的字符集名称: " + e.getMessage());
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}运行结果:
代码解释
- 定义原始字符串:创建一个包含英文和中文字符的字符串
originalString。- 使用 UTF - 8 编码和解码:
- 调用
getBytes("UTF-8")方法,将originalString按照 UTF - 8 字符集编码为字节数组utf8Bytes。- 使用
String(byte[] bytes, String charsetName)构造方法,传入utf8Bytes和"UTF-8",将字节数组解码为新的字符串decodedUtf8String,并打印结果。- 使用 GBK 编码和解码:
- 调用
getBytes("GBK")方法,将originalString按照 GBK 字符集编码为字节数组gbkBytes。- 使用
String(byte[] bytes, String charsetName)构造方法,传入gbkBytes和"GBK",将字节数组解码为新的字符串decodedGbkString,并打印结果。- 异常处理:尝试使用一个不存在的字符集名称
"NonExistentCharset"进行解码,捕获UnsupportedEncodingException异常并打印错误信息。
注意事项
- 字符集名称的正确性:要确保传入的字符集名称是 JVM 支持的,否则会抛出
UnsupportedEncodingException异常。常见的字符集名称如"UTF-8"、"GBK"、"ISO-8859-1"等通常是被支持的。- 异常处理:由于该构造方法可能会抛出
UnsupportedEncodingException异常,在使用时必须进行异常处理,可使用try-catch块来捕获并处理该异常,避免程序因异常而崩溃。- 优先使用
Charset对象:在 Java 中,更推荐使用String(byte[] bytes, Charset charset)构造方法,因为使用Charset对象可以避免因字符集名称拼写错误而导致的异常,并且代码可读性和安全性更高。
3. String(String original) 构造方法
功能概述
String(String original) 构造方法用于创建一个新的 String 对象,该对象是传入的 original 字符串的副本。简单来说,就是复制一个已有的字符串,新创建的字符串和原始字符串在内容上是相同的,但它们是不同的对象实例。
方法签名
public String(String original)参数:original 是一个已有的 String 对象,作为新字符串的内容来源
示例代码
public class StringConstructorExample {
public static void main(String[] args) {
// 原始字符串
String original = "Hello, World!";
// 使用 String(String original) 构造方法创建新的字符串对象
String copy = new String(original);
// 输出原始字符串和新字符串
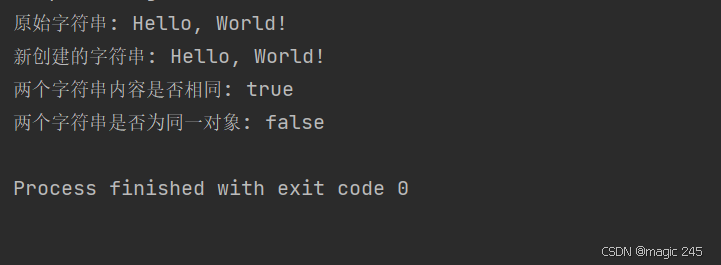
System.out.println("原始字符串: " + original);
System.out.println("新创建的字符串: " + copy);
// 比较两个字符串的内容
System.out.println("两个字符串内容是否相同: " + original.equals(copy));
// 比较两个字符串的引用
System.out.println("两个字符串是否为同一对象: " + (original == copy));
}
}运行结果:
代码解释
- 创建原始字符串:定义一个字符串
original,其内容为"Hello, World!"。- 使用构造方法创建新字符串:通过
new String(original)调用String(String original)构造方法,创建一个新的字符串对象copy,该对象是original的副本。- 输出字符串内容:分别打印原始字符串和新创建的字符串。
- 比较字符串内容:使用
equals()方法比较original和copy的内容是否相同,结果为true,因为它们的字符序列是一样的。- 比较字符串引用:使用
==运算符比较original和copy是否为同一对象,结果为false,因为它们是不同的对象实例,只是内容相同。
(1) 功能与行为
作用:基于现有字符串创建一个新对象(内容与原字符串相同)。
内存影响:
String s1 = "hello"; // s1 指向常量池中的 "hello"
String s2 = new String(s1); // s2 指向堆中的新对象,但内容为 "hello"验证:
System.out.println(s1 == s2); // false(地址不同)
System.out.println(s1.equals(s2)); // true(内容相同)(2) @IntrinsicCandidate 注解说明
该标注是让方法成为候选,不建议用
实际代码:在 OpenJDK 源码中,String(String original) 构造方法确实标记了 @IntrinsicCandidate。
注解作用:提示 JVM 可以对该方法进行底层优化(如内联、替换为本地代码),不影响开发者使用。
是否建议使用: 无性能问题,但大多数场景直接使用字面量赋值即可,无需显式调用此构造方法。