列夫托尔斯泰写:“如果你能感受到痛苦,那么你还活着;如果你能感受到他人的痛苦,那么你才是人”
—— 24.11.27
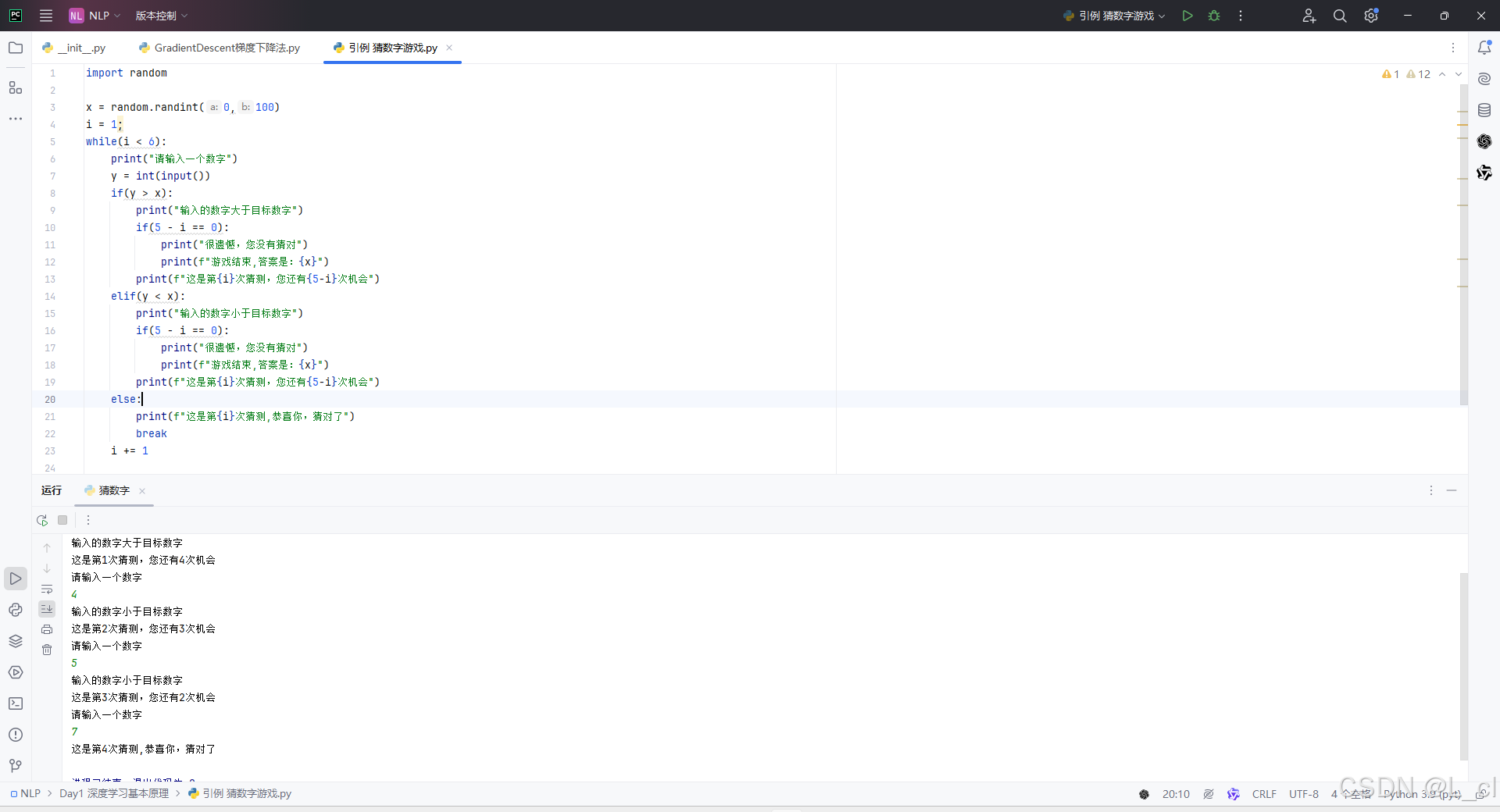
一、引例 —— 猜数字游戏
给出一个范围,从其中进行猜测数字,对每次猜测结果给出一定反馈,首先随机给出一个初始值,根据反馈计算损失函数loss,根据损失函数得到loss值调整下一次猜测的大小,一次次猜测使得猜测与结果的差距不断减小,直到猜对为止
import random
x = random.randint(0,100)
i = 1;
while(i < 6):
print("请输入一个数字")
y = int(input())
if(y > x):
print("输入的数字大于目标数字")
if(5 - i == 0):
print("很遗憾,您没有猜对")
print(f"游戏结束,答案是:{x}")
print(f"这是第{i}次猜测,您还有{5-i}次机会")
elif(y < x):
print("输入的数字小于目标数字")
if(5 - i == 0):
print("很遗憾,您没有猜对")
print(f"游戏结束,答案是:{x}")
print(f"这是第{i}次猜测,您还有{5-i}次机会")
else:
print(f"这是第{i}次猜测,恭喜你,猜对了")
break
i += 1

优化
1.随机初始化
假如一开始猜的数字就是最终答案,则损失函数直接为0
NLP的预训练模型实际上是对随机初始化的技术进行优化
2.优化损失函数
假如损失函数定义的是返回精确的差距 loss = (y_true - y_pred),则只需进行一次猜数字流程就可以得出精确的值
损失函数选的越好,优化越简单
3.调整参数的策略
将参数的调整依照一定的策略,选择合适的策略
本例中可以采用二分法调整参数
4.调整模型的结构
选取初识的函数或公式,本质是因为不同模型能够拟合不同的数据集,不同模型结构适用于不同的任务
二、深度学习相关概念
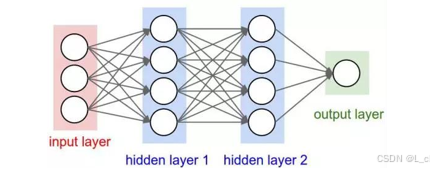
1.隐含层/中间层
神经网络模型输入层和输出层之间的部分
隐含层可以有不同的结构:
RNN CNN DNN LSTM Transformer ……
它们本质上的区别只是不同的运算公式
2.随机初始化
隐含层中会含有很多的权重矩阵,这些矩阵需要有初始值,才能进行运算
初始值的选取会影响最终的结果
一般情况下,模型会采取随机初始化,但参数会在一定范围内
在使用预训练模型一类的策略时,随机初始值被训练好的参数代替
好的开始是成功的一半!所以初始值的选取也很重要
3.损失函数
损失函数用来计算模型的预测值与真实值之间的误差
模型训练的目标一般是依靠训练数据来调整模型参数,使得损失函数到达最小值。
损失函数有很多,选择合理的损失函数是模型训练的必要条件
4.导数与梯度
导数表示导数曲线上的切线斜率
除了切线的斜率,导数还表示函数在该点的变化率
5.梯度下降
梯度告诉我们函数向哪个方向增长最快,那么他的反方向,就是下降最快的方向
梯度下降的目的是找到函数的极小值
为什么要找到函数的极小值?
因为我们最终的目标是损失函数值最小
6.优化器(公式)
知道走的方向,还需要知道走多远
假如一步走太大,就可能错过最小值,如果一步走太小,又可能困在某个局部低点无法离开
学习率(learningrate),动量(Momentum) 都是优化器相关的概念
7.Mini Batch / epoch
一次训练数据集的一小部分,而不是整个训练集,或单条数据
它可以使内存较小、不能同时训练整个数据集的电脑也可以训练模型。
它是一个可调节的参数,会对最终结果造成影响
不能太大,因为太大了会速度很慢。也不能太小,太小了以后可能算法永远不会收敛
我们将遍历一次所有样本的行为叫做一个 epoch,epoch 是一个重要的概念,它指的是训练过程中整个训练数据集被完整地通过模型一次。
8.人工神经网络
人工神经网络(Artificial Neural Networks,简称ANNs),也简称为神经网络(NN)。
它是一种模拟动物神经网络行为特征,进行分布式并行信息处理的算法数学模型
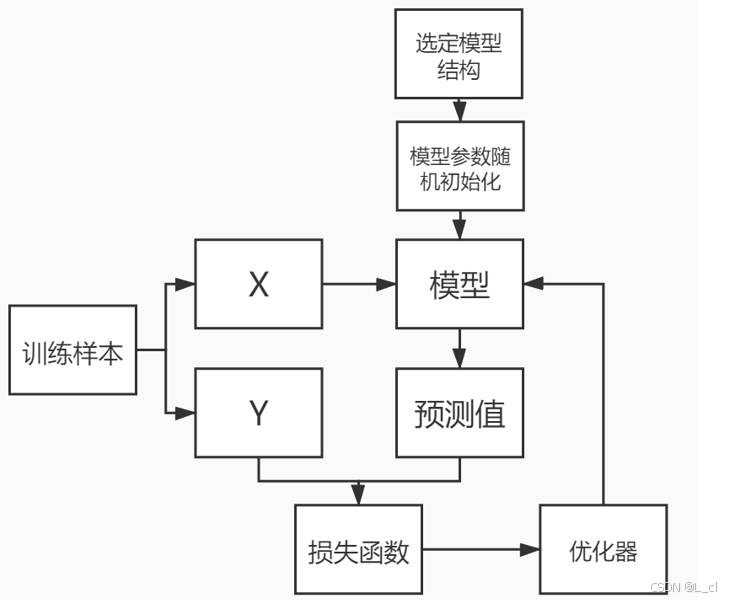
三、深度学习是怎样进行
训练迭代进行
模型训练好后把参数保存,即可用于对新样本的预测
首先选取一个模型结构(公式),对模型的参数进行随机初始化,选用训练样本中的X代入模型中预测出对应的预测值Y,然后用这个预测值和对应的真实值用提前选好的损失函数算出对应的损失,再用优化器(另一个公式)对模型的参数进行优化,然后迭代重复以上步骤,我们重复迭代,优化损失函数,使损失函数变小,小到一定程度损失函数不再下降,我们就认为该模型收敛了,此时模型中的参数值是多少,就是我们最终需要的模型
要点:
① 模型结构选择 ② 初始化方式选择 ③ 损失函数选择 ④ 优化器选择 ⑤ 样本质量数量
四、总结
机器学习的本质,是从已知的数据中寻找规律,用这个规律预测未知的数据
深度学习是机器学习的一种方法
深度学习的基本思想:
选取公式 ——> 参数随机初始化 ——> 标注数据算误差 ——> 根据误差调整参数
简而言之,“先猜后调”