本文引用原帖:
提示词工程师入门教程(非常详细),提示词工程入门到精通,收藏这一篇就够了!
ChatGPT提示工程|AI大神吴恩达教你写提示词(上篇)(建议收藏)
一文读懂「Chain of Thought,CoT」思维链
人人都能懂的 Prompt 技巧: Few-Shots 、 COT 、 SC、 TOT 、 Step-Back
Prompt定义

Prompt的不同分类
- Zero-shot prompt: 零样本的prompt。此为最常见的使用形式。之所以叫zero-shot,是因为我们直接用大模型做任务而不给其参考示例。这也被视为评测大模型能力的重要场景之一。
- Few-shot prompt: 与zero-shot相对,在与大模型交互时,在prompt中给出少量示例。
- Role prompt: 与大模型玩“角色扮演”游戏。让大模想象自己是某方面专家、因而获得更好的任务效果。
- Instruction prompt: 指令形式的prompt。
- Chain-of-thought prompt: 常见于推理任务中,通过让大模型“Let’s think step by step”来逐步解决较难的推理问题。
- Multimodal prompt: 多模态prompt。顾名思义,输入不再是单一模态的prompt,而是包含了众多模态的信息。如同时输入文本和图像与多模态大模型进行交互。
Prompt编写策略
策略1:Few-shot prompting
few-shot examples会为大模型提供一些额外的知识,叫做in-context learning(一种学习范式,允许模型在给定的上下文中进行学习和推理,而无需真正更新模型参数;参考链接:大模型学习范式之语境学习(In-context learning))。因此,通常情况下,few-shot prompt效果较好。
example的选取上,可遵循以下三点建议:
- 使用KNN等近邻算法去选择与test样本距离更近的few-shot example
- 随机使用few-shot example
- 使用强化学习或主动学习去进一步选择few-shot example
prompt = f"""
Your task is to answer in a consistent style.
<child>: Teach me about patience.
<grandparent>: The river that carves the deepest valley flows from a modest
spring; the grandest symphony originates from a single note; the most intricate
tapestry begins with a solitary thread.
<child>: Teach me about resilience.
"""
response = get_completion(prompt)
print(response)
策略2:给你的模型一个角色/背景
通过与模型进行角色扮演游戏来提高其在特定任务上的性能。如,我们告诉模型,你是一个聪明的数学家,那么模型便也许会在解数学问题上更上一层楼。
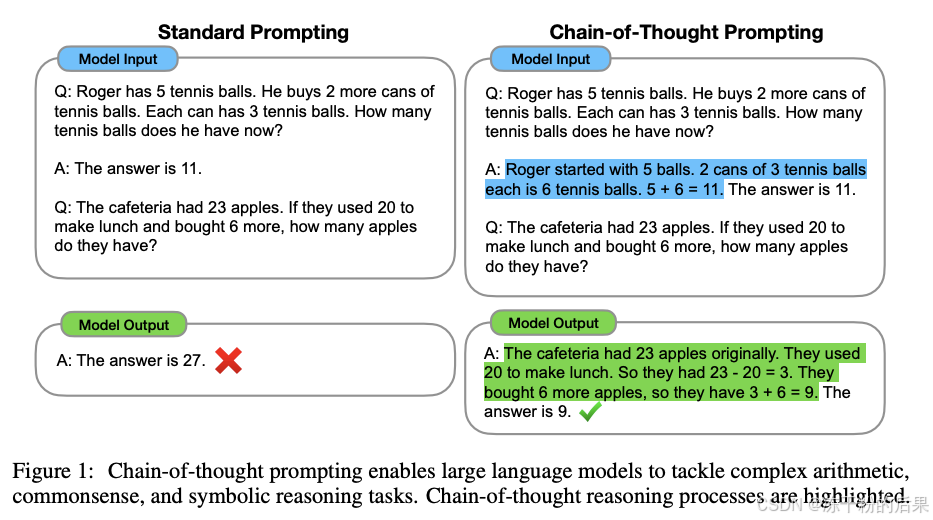
策略3:在推理任务中使用CoT
- CoT: 要求模型在输出最终答案之前,显式输出中间逐步的推理步骤
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT:
Zero-Shot-CoT
不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。
Few-Shot-Cot
则在示例中详细描述了“解题步骤”,让模型照猫画虎得到推理能力。
什么时候使用CoT
CoT 应当被用于 20B 以上参数规模的模型之中,并且模型的训练数据应当与任务问题相关且彼此相互有较强的联结。
从工程的角度而言,CoT 的适用场景抽象一下可以被归纳为三点,分别是:
- 使用大模型
- 任务需要复杂推理
- 参数量的增加无法使得模型性能显著提升
- 此外,现有的论文实验也表明,CoT 更加适合复杂的推理任务,比如计算或编程,不太适用于简单的单项选择、序列标记等任务之中,并且 CoT 并不适用于那些参数量较小的模型(20B以下),在小模型中使用 CoT 非常有可能会造成机器幻觉等等问题。
CoT缺点
- 思维链提示需要用户提供一些自然语言形式的推理过程,这可能对用户有一定的负担和要求。
- 思维链提示可能不适用于所有类型的问题,特别是一些需要专业知识或常识的问题。
- 思维链提示可能导致ChatGPT过度依赖于给定的推理过程,而忽略了其他可能的解决方案或角度。
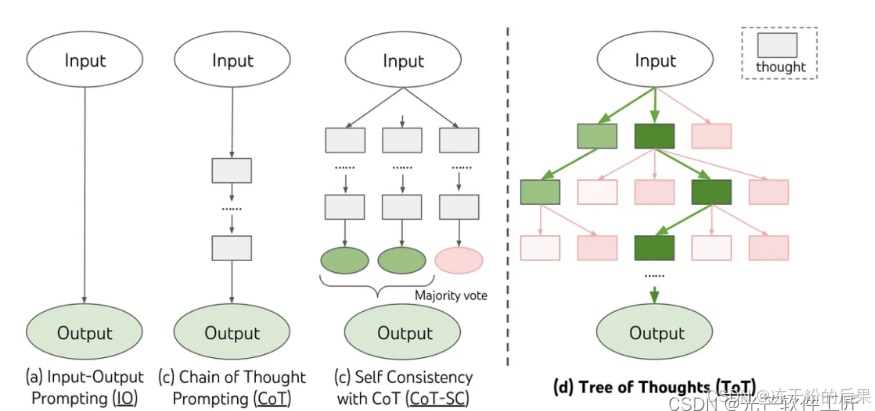
CoT+SC
COT 通过分步骤加大了 LLM 的深度。SC 则是在增加深度的基础上再增加宽度。
- CoT:
你需要2个步骤来执行这个任务:
1. 将英文直接翻译为中文,主要考虑意思表达的准确性
2. 将步骤 1 直译的中文翻译成更简洁优雅通顺的中文标题,主要考虑中文的语言表达习惯
- CoT+SC:
你需要3个步骤来执行这个任务:
1. 将英文直接翻译为中文,主要考虑意思表达的准确性,请给出 3个结果
2. 将步骤 1 直译的3个中文翻译成更简洁优雅通顺的中文,主要考虑中文的语言表达习惯
3. 审视步骤 2 提供的 3 个结果,整合出一个最好的结果,作为最终结果输出
TOT
与 COT+SC 类似,也是先分步骤,然后每个步骤多个结果,不同的是,COT+SC 是并列输出多个结果。而 TOT 是在每一步的多个结果中进行选择,然后再进行下一步,输出多个结果。
你需要3个步骤来执行这个任务:
1. 将英文直接翻译为中文,主要考虑意思表达的准确性,请给出 3个结果
2. 从步骤 1 的结果中选择一个意思表达更恰当的给出 1 个结果
3. 将步骤 2 的结果润色为更简洁优雅通顺的中文,主要考虑中文的语言表达习惯,输出 3 个结果
4. 审视步骤 3 提供的 3 个结果,整合出一个最好的结果,作为最终结果输出
Step-Back
即往后退一步,想想在回答这个问题之前需要先回答什么问题
请按照一下步骤输出结果:
1. 要想得到通顺优雅简洁的翻译文章,你需要知道哪些前提问题
2. 这些前提问题的答案分别是什么
3. 基于这个前提问题,对于给出英文的翻译结果
策略4:编写明确而具体的指令
使用分隔符
- 三重引号:”””
- 三重反引号:`````,
- 三重划线:—-,
- 尖括号:< >,
- XML tags:
text = f"""
You should express what you want a model to do by providing instructions
that are as clear and specific as you can possibly make them.
This will guide the model towards the desired output, and reduce the
chances of receiving irrelevant or incorrect responses. Don't confuse
writing a clear prompt with writing a short prompt.
In many cases, longer prompts provide more clarity and context for the
model, which can lead to more detailed and relevant outputs.
"""
prompt = f"""
Summarize the text delimited by triple backticks into a single sentence.
```{text}```
"""
请求结构化输出(HTML 或 JSON 等)
方便对结果进行管理
prompt = f"""
Generate a list of three made-up book titles along with their authors
and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""
response = get_completion(prompt)
print(response)
要求模型检查任务所需要的假设是否成立
加入一些条件判断以使得我们的模型可以在不满足条件时,返回相应的输出。这样模型就避免了在不满足条件时胡说八道。
text_1 = f"""
Making a cup of tea is easy! First, you need to get some water boiling.
While that's happening, grab a cup and put a tea bag in it. Once the water
is hot enough, just pour it over the tea bag. Let it sit for a bit so the
tea can steep. After a few minutes, take out the tea bag. If you like, you
can add some sugar or milk to taste.
And that's it! You've got yourself a delicious cup of tea to enjoy.
"""
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, re-write those instructions
in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions,
then simply write \\"No steps provided.\\"
\\"\\"\\"{text_1}\\"\\"\\"
"""
response = get_completion(prompt)
print("Completion for Text 1:")
print(response)
策略五:善用温度变量
大模型通常会涉及到一个温度变量,如ChatGPT API中的temperature变量。此变量的值与模型输出结果的随机性有关:
- 当其值为0时,表明模型输出结果是确定的,通常用于决定性任务,如分类、预测等;
- 当其值>0时,越大,则表明模型随机性越强,适合生成任务。
摘要类LLM——Prompt编写策略
策略一:用字/句/字数限制进行总结
Summarize the review below, delimited by triple
backticks, in at most 30 words.
策略二:以" "为重点进行总结
Summarize the review below, delimited by triple
backticks, in at most 30 words, and focusing on any aspects that are
relevant to the price and perceived value.
“relevant to the price and perceived value”
策略三:尝试用 “extract”(提取)代替 “summarize”(总结)
From the review below, delimited by triple quotes extract the information
relevant to shipping and delivery. Limit to 30 words.
推理类LLM——Prompt编写案例
案例一:情感分析(判断)
prompt = f"""
What is the sentiment of the following product review,
which is delimited with triple backticks?
Give your answer as a single word, either "positive" or "negative".
Review text: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
案例二:识别情感的类型(枚举)
prompt = f"""
Identify a list of emotions that the writer of the following review is
expressing. Include no more than five items in the list.
Format your answer as a list of lower-case words separated by commas.
Review text: '''{lamp_review}'''
"""
案例三:从客户评论中提取产品和公司名称(识别&提取)
prompt = f"""
Identify the following items from the review text:
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks.
Format your response as a JSON object with "Item" and "Brand" as the keys.
If the information isn't present, use "unknown" as the value.
Make your response as short as possible.
Review text: '''{lamp_review}'''
"""
案例四:推理故事主题
prompt = f"""
Determine five topics that are being discussed in the following text,
which is delimited by triple backticks.
Make each item one or two words long.
Format your response as a list of items separated by commas.
Text sample: '''{story}'''
"""
转换类LLM——Prompt编写案例
案例一:通用翻译器
各国语言->英语
user_messages = [
"La performance du système est plus lente que d'habitude.", # System performance is slower than normal
"Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting
"Il mio mouse non funziona", # My mouse is not working
"Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key
"我的屏幕在闪烁" # My screen is flashing
]
for issue in user_messages:
prompt = f"Tell me what language this is: ```{issue}```"
lang = get_completion(prompt)
print(f"Original message ({lang}): {issue}")
prompt = f"""
Translate the following text to English and Korean: ```{issue}```
"""
response = get_completion(prompt)
print(response, "\\n")
案例二:语气转换
prompt = f"""
Translate the following from slang to a business letter:
'Dude, This is Joe, check out this spec on this standing lamp.'
"""
response = get_completion(prompt)
print(response)
案例三:格式转换
data_json = { "resturant employees" :[
{"name":"Shyam", "email":"[email protected]"},
{"name":"Bob", "email":"[email protected]"},
{"name":"Jai", "email":"[email protected]"}
]}
prompt = f"""
Translate the following python dictionary from JSON to an HTML table with
column headers and title: {data_json}
"""
response = get_completion(prompt)
print(response)
案例四:拼写检查/语法检查
为了向LLM发出信号,表明你希望它校对你的文本,你可以指示模型 "校对 "(proofread)或 “校对和纠正”(proofread and correct)。
text = [
"The girl with the black and white puppies have a ball.", # The girl has a ball.
"Yolanda has her notebook.", # ok
"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms
"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms
"Your going to need you’re notebook.", # Homonyms
"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms
"This phrase is to cherck chatGPT for speling abilitty" # spelling
]
for t in text:
prompt = f"""Proofread and correct the following text
and rewrite the corrected version. If you don't find
and errors, just say "No errors found". Don't use
any punctuation around the text:
```{t}```"""
response = get_completion(prompt)
print(response)