集群
集群的基本介绍
关于集群这个名词:
广义的集群:只要是多台机器构成了分布式系统,就可以称为是一个“集群”。之前介绍的主从结构,哨兵模式就可以称为是“广义的集群”。
狭义的集群:Redis提供的集群模式。在这个集群模式下,主要是为了解决存储空间不足的问题。
哨兵模式提高了系统的可用性,但是本质上还是redis主从节点上存储数据,这就要求了每个节点(主节点/从节点)都要存储这个数据的“全集”。因为Redis是内存存储数据的,一个服务器的内存大小很容易到达上限(即便现在的硬件在不断发展)。
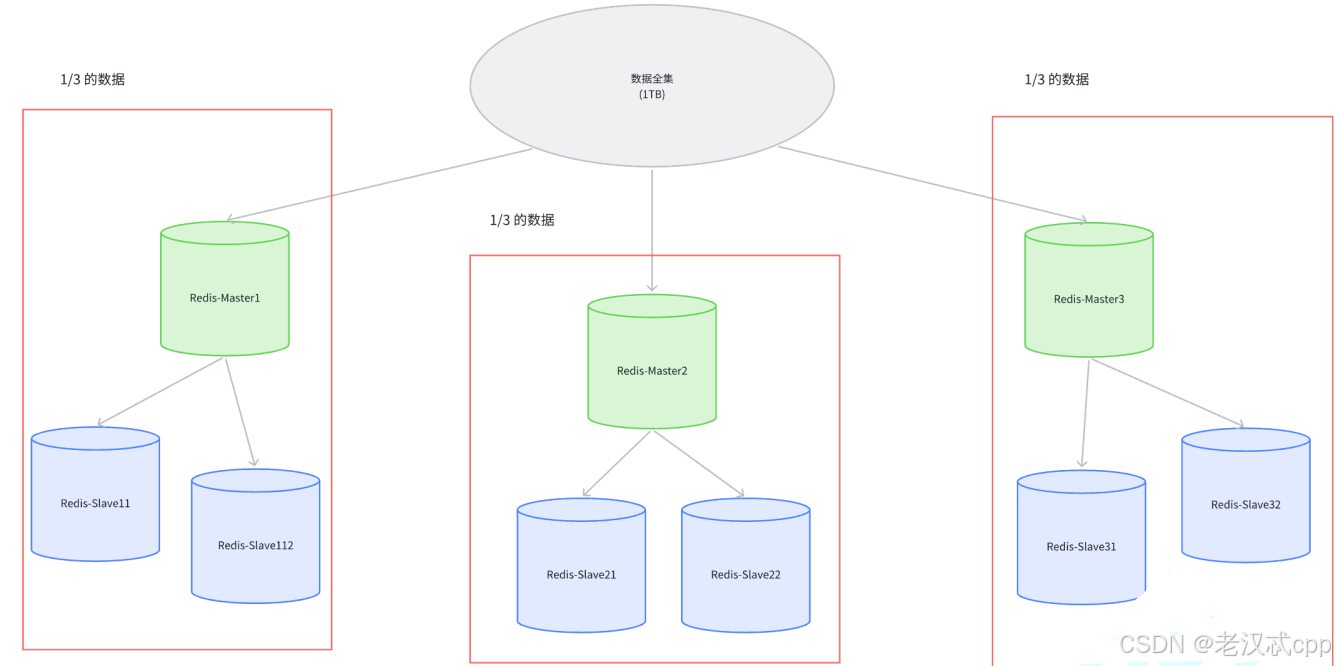
这样把数据分成了多份,把每份数据称为 一个 “分片”。
如果全量数据进一步增加,那么就只要跟着增加分片的数量即可。
接下来就介绍三种主流的分片方式。
哈希求余算法
哈希求余的分片方式主要就是借鉴了哈希表的思想:
借助hash函数,把一个key映射到一个整数,再针对数组的长度求余,就可以得到一个数组下标。
比如有三个分片的编号:0,1,2 。此时对于要插入数据的key进行一个hash算法(比如md5算法),计算出了hash值,然后再用这个hash值 模上分片的数量,就可以求出应该要把它放在哪一个分片上。将来如果要查找这个key,也是经过同样的步骤,先计算hash值,然后找到它在哪一个分片上,最后再在这个分片上查找即可。
关于md5算法:
md5本身就是一个计算hash值的算法,针对一个字符串里面的内容进行一系列的数学变换,将其转化成为一个十六进制的数字。
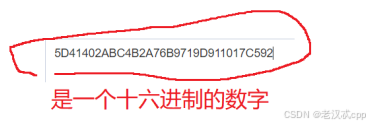
md5是一个应用很广泛的hash算法。它的优点有如下:
1.md5计算的结果是定长的:无论输入的原字符串有多长,最终计算的结果都是固定长度。
2.md5计算的结果是分散的:两个原字符串,即便只是有一点地方不相同,那么最终计算出来的结果也是会相差很大的。
3.md5计算结果是不可逆的(加密):理论上是不能通过md5的值计算出原字符串是啥的。
虽然有一些md5破解,但其实无非就是将一些常用的字符串生成md5值,然后将这些值储存起来,然后按照打表的方式映射到原来的字符串。这其实就是一种暴力破解方式,是一种用空间换时间的方式,还是不大靠谱的。
哈希求余算法存在一个很大的问题,那就是一旦服务器集群需要扩容,那么就需要更高的成本。

如上图可以看到, 整个扩容⼀共 21 个 key, 只有 3 个 key 没有经过搬运, 其他的 key 都是搬运过的
虽然hash算法和key都没有改变,仅仅只是N变了,但是key最终映射的结果还是有较大概率不同


一致性哈希算法
第⼀步, 把 0 -> 2^32-1 这个数据空间, 映射到⼀个圆环上. 数据按照顺时针⽅向增⻓ 假设此时还是三个分片。
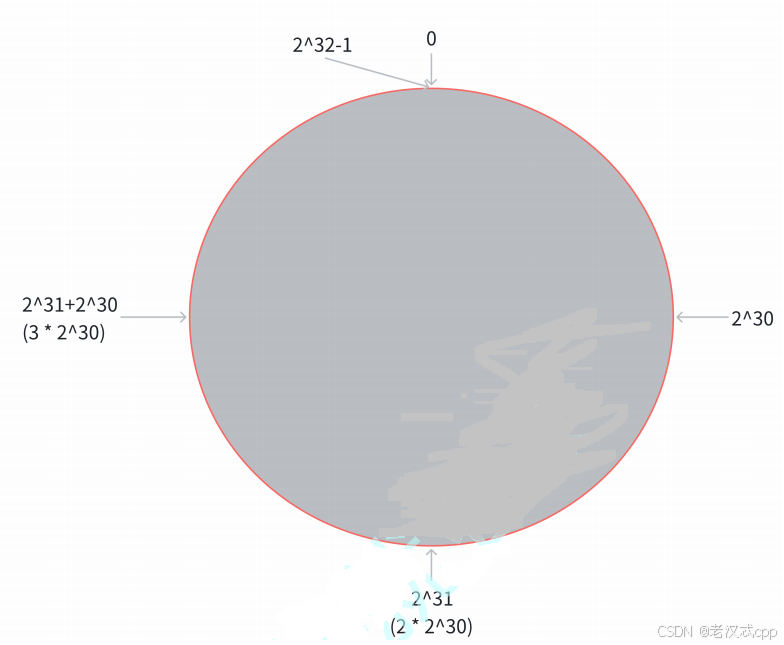
第⼆步, 假设当前存在三个分⽚, 就把分⽚放到圆环的某个位置上
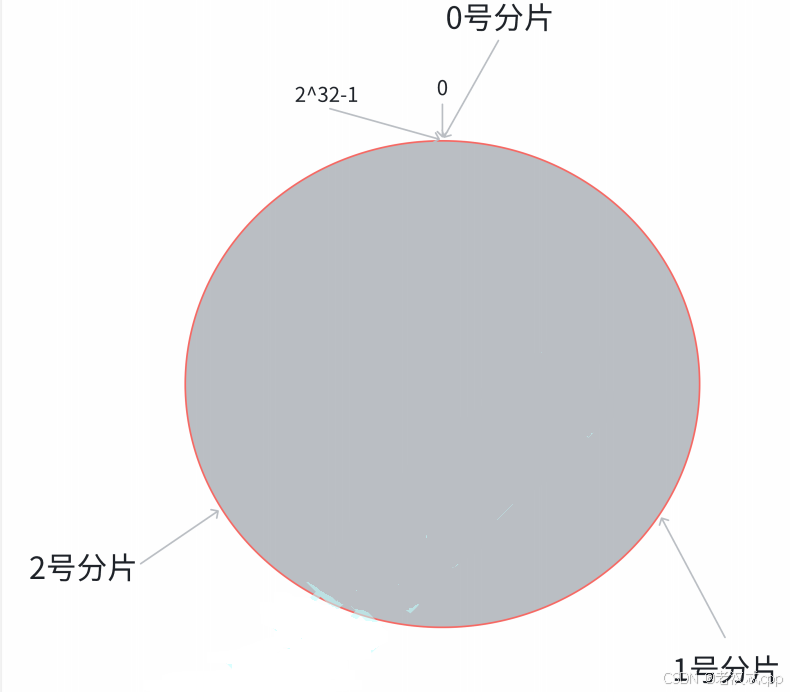

在哈希求余算法中,搬运数据的成本之所以会很大,是因为计算当前key属于哪个分片,是交替的
比如:

此时当我们由三个分片扩容到四个分片时:
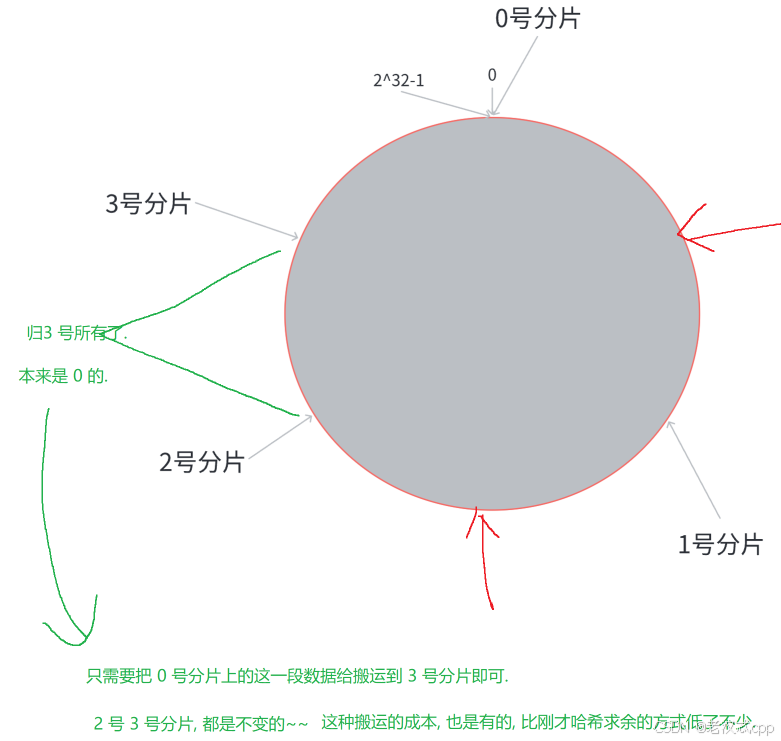
比如3号分片,我们只需要在原本属于0号分片的区间切分出一半给3号分片就可以了,那么此时的1号分片和2号分片的数据是不需要改动的,只需要将0号分片的数据搬运就可以了。
这样就大大减少了数据搬运的成本。
不过数据搬运的成本是变低了,但是又出现了一个新的问题,那就是这几个分片上的数据变得不均匀了,也就是数据倾斜问题。
虽然针对数据倾斜的问题,以上图为例,我们可以通过再加两批机器多分两片的方式,让数据变得均匀,这种方案是可行的,但是这样就会导致实际存储数据用不了这么多内存,导致内存浪费掉了
哈希槽分区算法
哈希槽分区算法也是Redis真正采用的分片算法。
hash_slot = crc16(key) % 16384其中这个crc16也是一种hash算法。
16384是指有16384个槽位,也就是16k的大小。
注意:分配槽位的方式是很灵活的,并且每个分片的槽位也不一定连续。
在上述过程中,只有被移动的槽位,才需要进行数据搬运。
这种算法本质其实就是把哈希求余算法和一致性哈希算法这两种方式结合了一下。
此外,每个分片都会用 “位图” 这样的数据结构来表示当前有多少槽位。
也就是使用16384个bit位,每一个bit位用 0/1来表示是否拥有这个槽位。
16384 / 8 / 1024 = 2,也就是2KB的数据大小。
对于此处有两个常见的面试题:
问题⼀: Redis 集群是最多有 16384 个分⽚吗?
如果有16384个分片,也就意味着每一个分片只有一个槽位,此时是很难保证在各个分片上的均衡性的。因为key是要先映射到槽位,再由槽位映射到分片上的。
比如有的槽位可能是多个key,有的槽位可能没有key。
问题⼆: 为什么是 16384 个槽位?
在github上有Redis作者的回答:
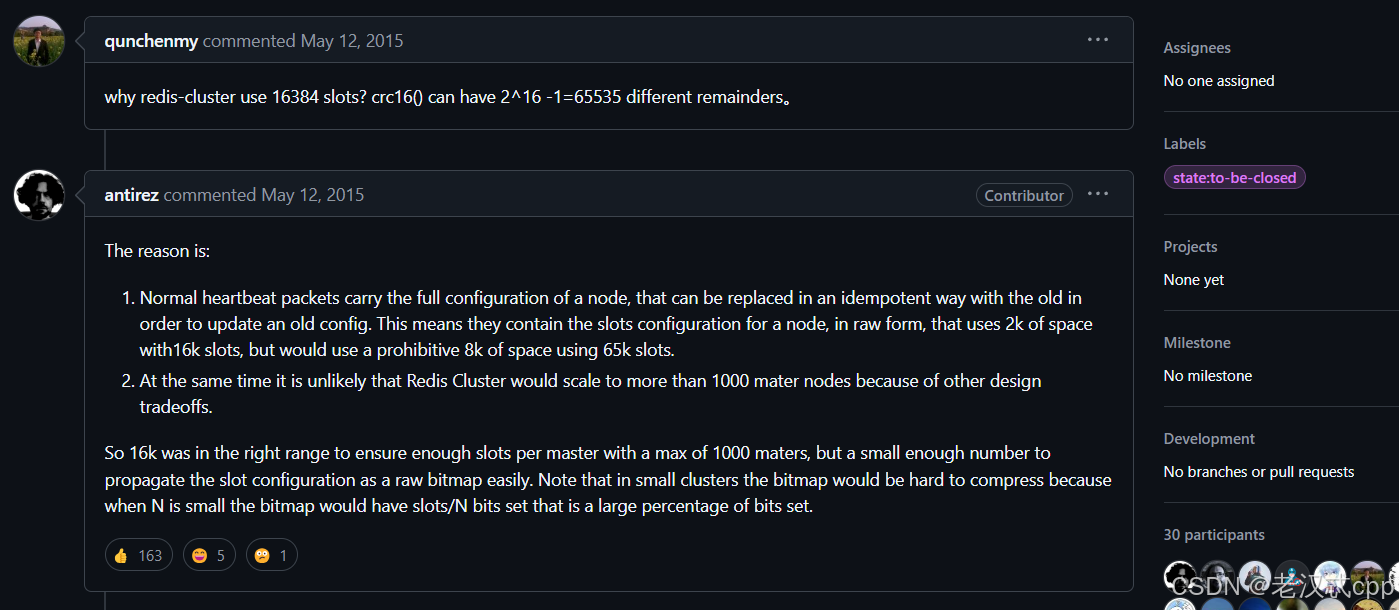
简短总结就是:16384个槽位基本是够用的,同时占用的硬件资源(比如在网络带宽中)又不是很大。如果用65535差不多就是8kb的大小,虽然在内存上8kb比2kb大不了多少,但是心跳包是周期性通信的,就比较频繁的吃网络带宽资源。
docker搭建集群环境
因为这里我们只有一个云服务器,所以我们还是利用docker来搭建一个集群,在实际工作中一般是通过多台主机的方式来搭建集群的。
并且在搭建集群环境之前,需要先把之前的redis容器给停止掉。
第一步:创建目录和配置
redis-cluster/
├── docker-compose.yml
└── generate.sh其中,在linux上,.sh后缀结尾的文件称为 “shell脚本”。
使用命令操作,就比较适合把命令写到一个文件中,批量化执行,同时还能加入条件,循环,函数等机制,基于这些可以完成一些更复杂的工作。
这里我们先创建9个redis节点,然后再创建2个redis节点作为扩容节点,一共就是11个redis节点。
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
# 注意 cluster-announce-ip 的值有变化.
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done 关于这里的一些解释:
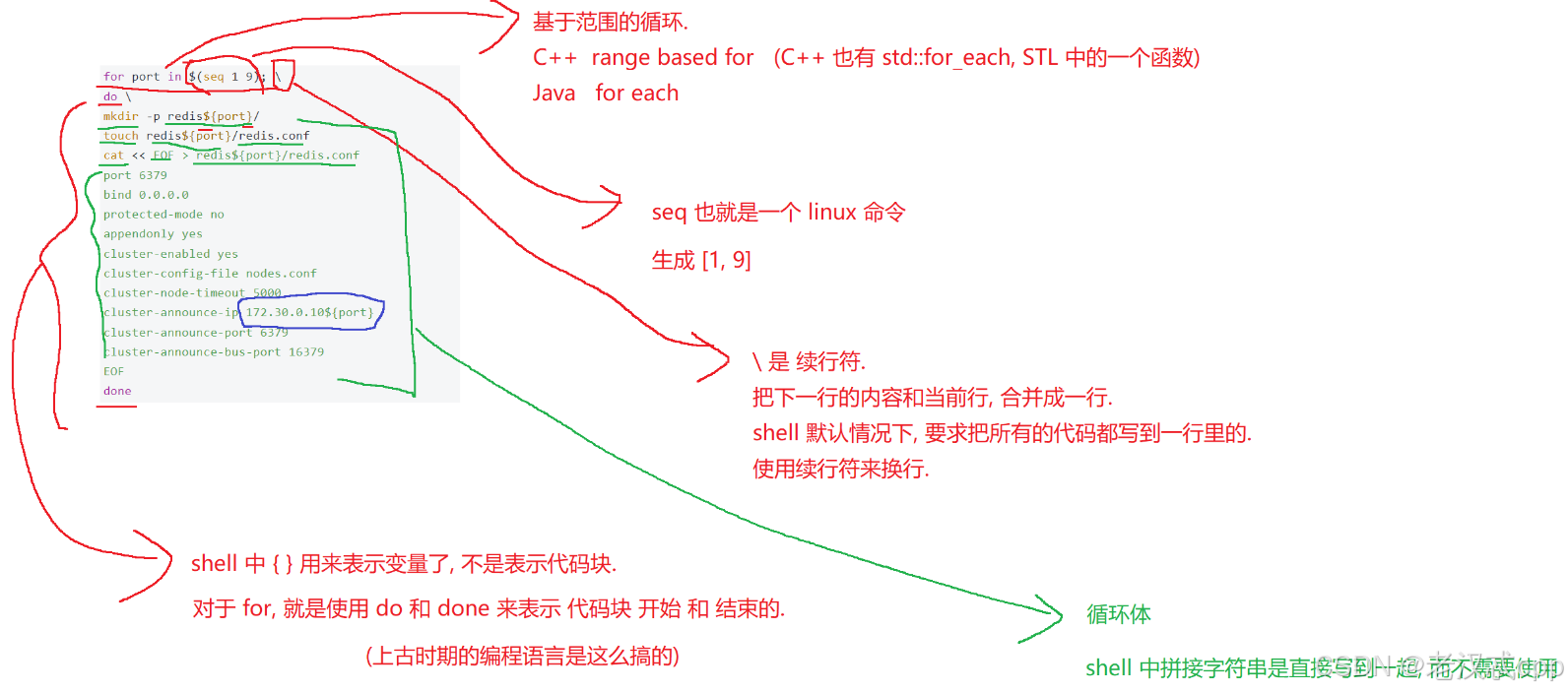
这里基于循环一共创建了11个redis的配置文件。
写好后,执行这个脚本:
bash generate.sh
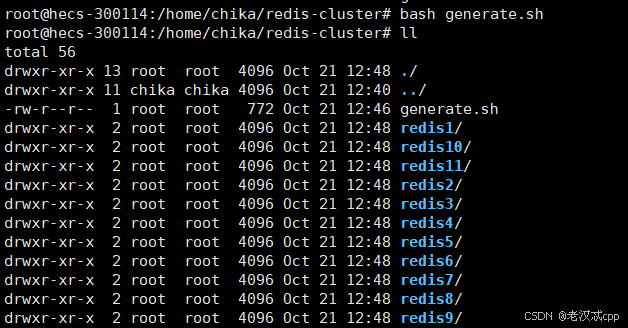
如期生成了11个目录,每个目录下就是一个redis的配置文件
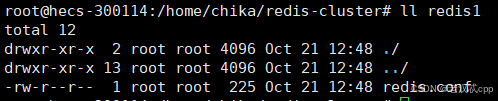
每个配置文件里:
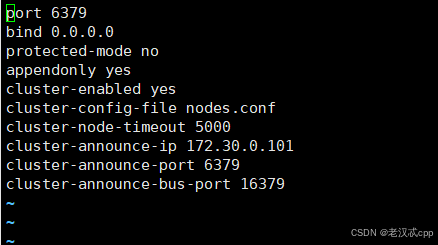
但是主要注意,这里我们配置的是静态id地址,比如上述的ip地址主机号101,网络号都是127.30.0 一共24位。
在shell脚本那里,我们就用了shell中字符拼接的方式,配置了主机号是递增的一系列ip地址。
这些配置文件其实就是 cluster-announce-ip不同,其它都是一样的。
cluster-announce-ip就是该redis节点所在的主机ip,因为当前使用的是docker模拟的容器,所以此处写的应该是docker容器的ip。
另外我们还发现这里有俩端口号, 其中port就是redis节点自身绑定的端口(容器内的端口),不同的容器内部可以有相同的端口,后续进行端口映射时再把容器内的端口映射到容器外不同的端口号即可。
这里的第一个port也就是业务端口,bus-port则是管理端口。
一个服务器是可以绑定多个端口号的。
业务端口就是用来进行业务数据通信的,也就是响应客户端请求的。
管理端口则是为了完成一些管理上的任务来进行通信的,比如某个分片的redis主节点挂了,那么此时要让从节点成为主节点,就需要通过管理端口来完成对应的操作。
关于配置的其它说明:
第二步:编写docker-compose.yml
version: '3.7'
networks:
mynet:
ipam:
config:
- subnet: 172.30.0.0/24
services:
redis1:
image: 'redis:5.0.9'
container_name: redis1
restart: always
volumes:
- ./redis1/:/etc/redis/
ports:
- "6371:6379"
- "16371:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.101
redis2:
image: 'redis:5.0.9'
container_name: redis2
restart: always
volumes:
- ./redis2/:/etc/redis/
ports:
- "6372:6379"
- "16372:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.102
redis3:
image: 'redis:5.0.9'
container_name: redis3
restart: always
volumes:
- ./redis3/:/etc/redis/
ports:
- "6373:6379"
- "16373:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.103
redis4:
image: 'redis:5.0.9'
container_name: redis4
restart: always
volumes:
- ./redis4/:/etc/redis/
ports:
- "6374:6379"
- "16374:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.104
redis5:
image: 'redis:5.0.9'
container_name: redis5
restart: always
volumes:
- ./redis5/:/etc/redis/
ports:
- "6375:6379"
- "16375:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.105
redis6:
image: 'redis:5.0.9'
container_name: redis6
restart: always
volumes:
- ./redis6/:/etc/redis/
ports:
- "6376:6379"
- "16376:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.106
redis7:
image: 'redis:5.0.9'
container_name: redis7
restart: always
volumes:
- ./redis7/:/etc/redis/
ports:
- "6377:6379"
- "16377:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.107
redis8:
image: 'redis:5.0.9'
container_name: redis8
restart: always
volumes:
- ./redis8/:/etc/redis/
ports:
- "6378:6379"
- "16378:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.108
redis9:
image: 'redis:5.0.9'
container_name: redis9
restart: always
volumes:
- ./redis9/:/etc/redis/
ports:
- "6379:6379"
- "16379:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.109
redis10:
image: 'redis:5.0.9'
container_name: redis10
restart: always
volumes:
- ./redis10/:/etc/redis/
ports:
- "6380:6379"
- "16380:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.110
redis11:
image: 'redis:5.0.9'
container_name: redis11
restart: always
volumes:
- ./redis11/:/etc/redis/
ports:
- "6381:6379"
- "16381:16379"
command: redis-server /etc/redis/redis.conf
networks:
mynet:
ipv4_address: 172.30.0.111关于redis的节点的配置很多都是重复的,不过要特别注意ip地址要与刚刚redis配置文件中的保持一致。
还有在开头的时候,先创建了一个network,并分配网段:172.30.0.0/24。
关于每个节点的端口映射不配置也可以,配置的目的是为了可以通过宿主机用ip + 映射端口进行访问,也可以通过容器自身ip:6379的方式访问。
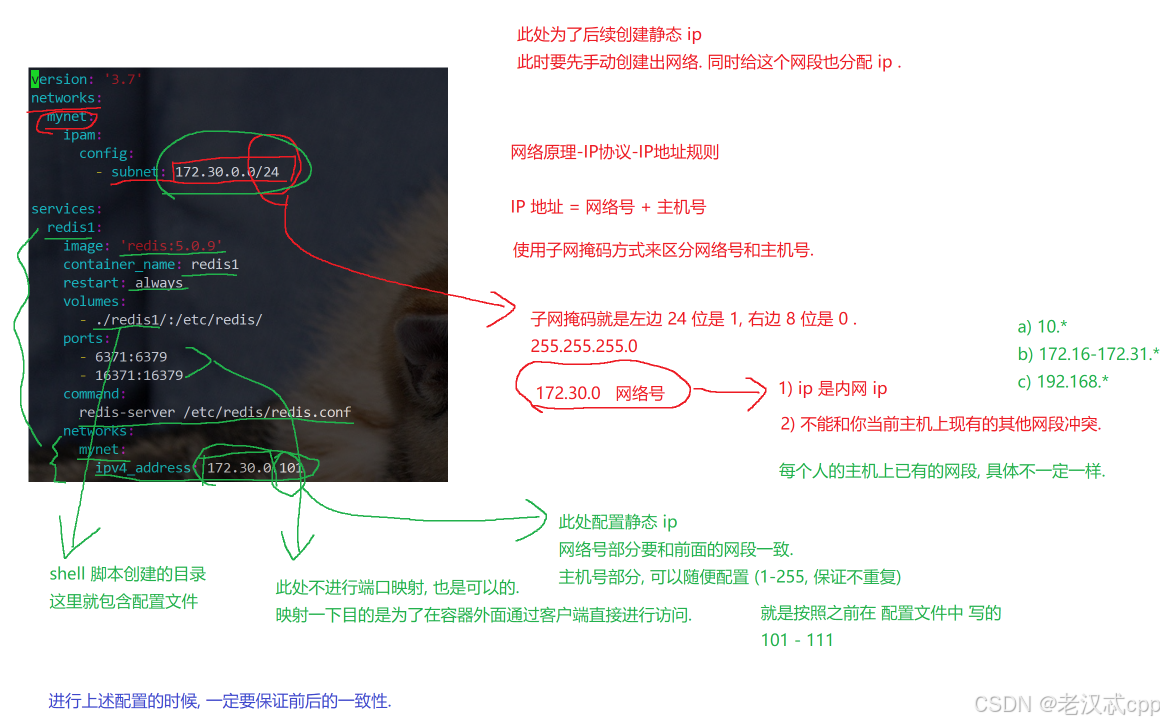
第三步:启动容器
执行命令:
docker-compose up -d-d表示程序在后台运行。
补充一些操作:
停止现在运行的所有容器:
docker stop $(docker ps -q)查看当前的容器
docker ps如果之前的redis服务没有关闭,导致端口冲突了,那么启动就可能会是这个样子:
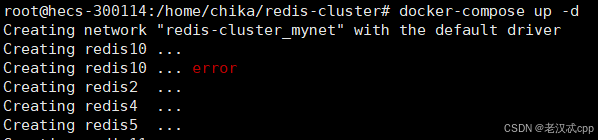
启动成功应该是这样的:
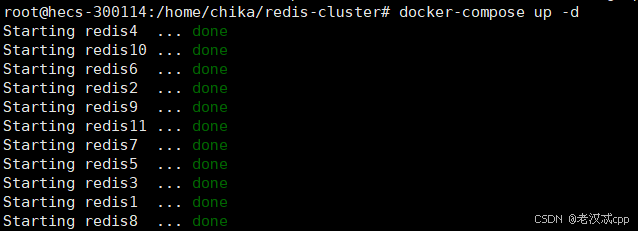
此时虽然启动成功,但是此时它们还并没有成为一个集群,而是各自管自己的。
第四步:构建集群
执行命令(在命令行中):
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379
172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379
172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2其中:cluster create表示要建立一个集群,后面就要填写每个节点的ip和端口。
--cluster-replicas 2:表示每个主节点有两个从节点。这个配置设置了之后,redis也就是知道了一个分片有三个节点。
另外,redis在构建集群的时候,谁是主节点,谁是从节点,谁和谁是一个分片,这些都是不固定的。本身从集群的角度来看,提供的这些节点本身应该是等价的。
输入命令后:

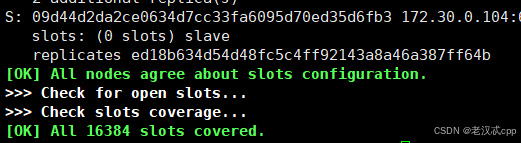
可以看到redis已经将哈希槽位给主节点们分配好了,这里需要再输入yes才开始真正构建集群。
成功了:

另外,关于客户端这里:
cluster nodes 

可以看到,我们set的操作会先对key进行一个hash运算,得出它在哪个哈希槽位,如果当前客户端不在这个槽位,那么就会将请求重定向到对应的主节点上,并且将我们的客户端的连接也切换到对应的节点上。如果启动客户端时不加 -c选项,那么就会报错,插入也就失败了。
我们通过cluster nodes 查看,比如看到主机号是101这个节点是一个从节点,我们登录上去

然后set了一个key2,发现这个命令也会被重定向到一个主节点上,跟之前的操作一样。
在使用集群之后,我们之前学过的大部分命令都是可以正常使用的,但是有些操作多个key的指令就不一定了,如果这多个key最终映射到了不同的主节点上,那么就会报错。
演示主节点宕机
如果是从节点挂了,那么问题不是很大。如果是主节点挂了,那么写操作就不能执行了。
此时集群所作的工作跟哨兵机制那里类似,都会挑选一个挂掉的主节点所属的从节点,让其成为主节点。

之前我们看到了redis1 (主机号101)就是一个主节点,我们可以把它停止掉。
docker stop redis1停掉之后,随便连上一个节点,然后查看一下:
CLUSTER NODES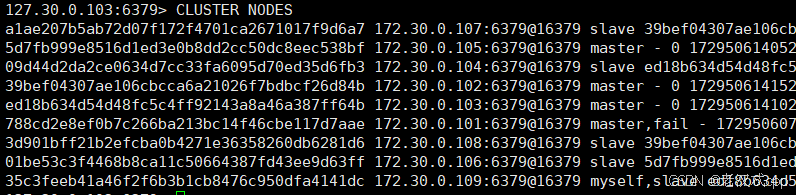
仔细观察,发现有一个节点就处于了一个fail状态。
然后又发现,主机号105的节点原本是从节点,现在就变成了主节点了。
此时如果我们再重新启动redis1节点
docker start redis1


此时主机号101就变成了一个从节点重新加入到了这个分片中。
cluster failover集群的故障处理
由此可见,集群也具有处理故障转移的功能。
1.先进行故障判定:
某个节点宕机,有的时候会引起整个集群都宕机。(fail状态)
以下三种情况会导致集群宕机:
a.某个分片中,所有的主节点和从节点都挂了。
b.某个分片,主节点挂了,但是没有从节点,其实就跟a一样。
c.超过半数的主节点挂了。
2.故障转移:
集群的扩容
扩容是⼀个在开发中⽐较常遇到的场景
所谓分布式的本质, 就是使⽤更多的机器, 引⼊更多的硬件资源。
第⼀步: 把新的主节点加⼊到集群:
这里把redis10作为主节点,redis11作为从节点。
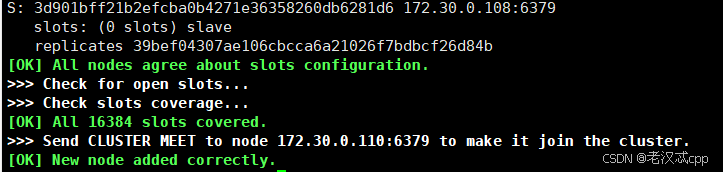
redis-cli --cluster add-node 172.30.0.110:6379 172.30.0.101:6379这里后面还写了一个主机号为101的节点,后面这个节点只要是集群里的节点都可以,目的就是为了表示我们要在这个集群中加入新的节点(分片)。
执行成功:
第⼆步: 重新分配 slots:
redis-cli --cluster reshard 172.30.0.101:6379
执行后:
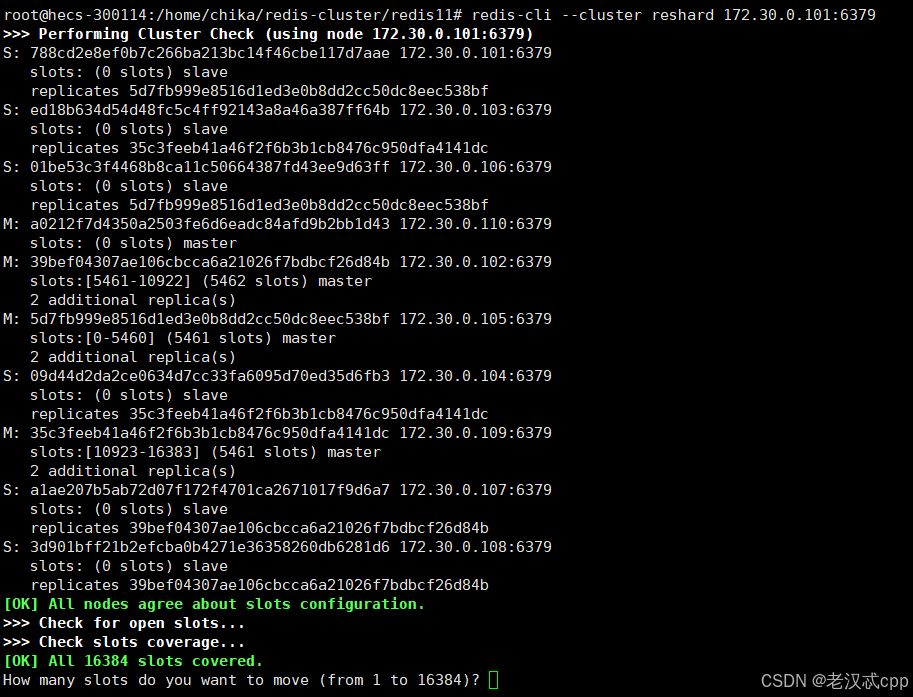

这里的node ID是

第三步: 给新的主节点添加从节点
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id [172.30.1.110 节点的 nodeId]
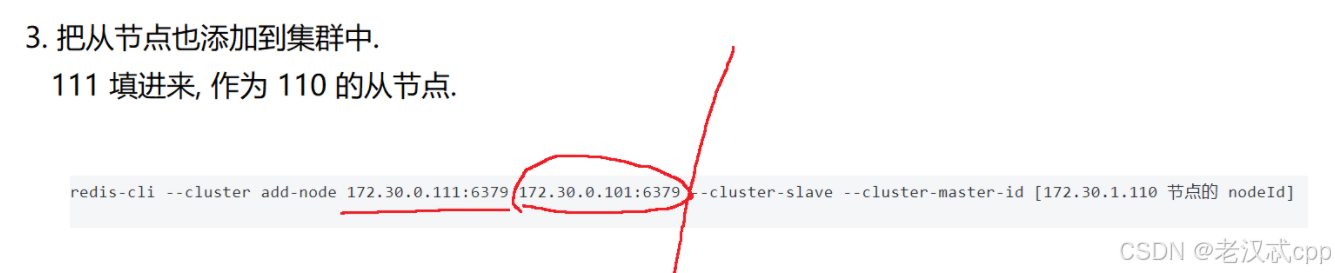
其中这个主机号101的只是为了表示这个集群,写集群中的哪个节点都无所谓。
关于集群的缩容(了解)
删除从节点:
此处删除的节点 nodeId 是 111 节点的 id
redis-cli --cluster del-node [集群中任⼀节点ip:port] [要删除的从机节点 nodeId]