目录
Redis

第一章
1、理解redis的基本概念 2、安装、配置redis 3、redis的使用
1、什么是redis
redis是一种非关系型数据库,它用于存储数据提供给程序使用(c语言编写) 非关系型数据(NoSql) 它的特点:它没有数据表的概念了,它存放的数据是存放在内存中的 典型的非关系型数据库,主要有:redis,mongodb redis它是采用键、值对的方式,将数据存放在内存中 关系型数据库: sqlserver,mysql,oracle这些都是关系型数据库 它们的特点:数据是以数据表的形式进行存储,数据是存放在数据库系统中
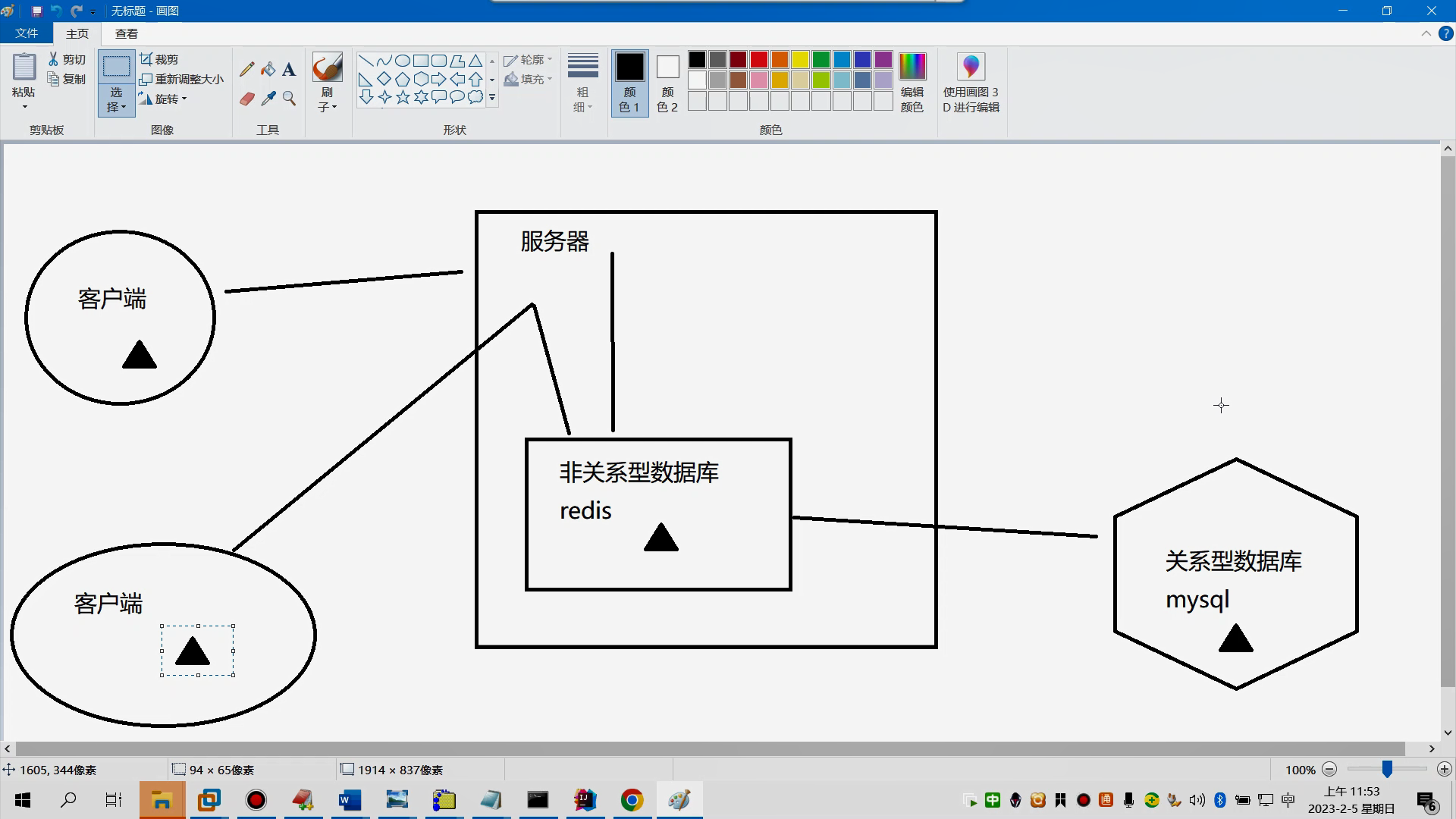
非关系型数据库从内存中加载数据,速度会更快
关系型数据库的数据是存放在数据库系统中的,它们会更安全
@@@@@@在实际应用中,项目一般会将关系型数据库与非关系型数据库结合使用
redis这种非关系型数据库,主要是作为缓存使用,这样可以避免频繁查询数据库,导致数据库压力过大
2、安装redis
步骤
1-7
@@@@@redis可以在windows中使用,也可以在linux下使用。但一般都会配置到linux下
1、下载redis
2、将它发布到linux下的 d113
3、安装C语言运行环境(REDIS是采用c语言编写的)
yum install gcc-c++
4、将/d113目录下的redis解压缩
tar -xvPf /d113/redis-3.0.0.tar.gz -C /usr/local/d113/
5、进入/usr/local/d113/redis-3.0.0目录
cd /usr/local/d113/redis-3.0.0
6、构建redis
make
7、安装redis
make install PREFIX=/usr/local/d113/redis
8
8、启动redis的服务端
1、进入 /usr/local/d113/redis/bin目录
cd /usr/local/d113/redis/bin
2、准备启动redis服务器(启动有两种方式)
@@@@@@@@@@前台启动
(这种方式启动后,控制台界面就不能再编写其他代码了,需要再打开一个新的控制台窗口写代码)
./redis-server
@@@@@@@@@后台启动(启动后,界面不会被占用,还可以继续写代码 )-------推荐使用
1、进入/usr/local/d113/redis-3.0.0将redis.conf文件复制到/usr/local/d113/redis/bin目录中
cp /usr/local/d113/redis-3.0.0/redis.conf /usr/local/d113/redis/bin
2、进入usr/local/d113/redis/bin目录,修改redis.conf配置,指定后台启动redis
找到配置文件 daemonize no
修改为 daemonize yes
3、进入usr/local/d113/redis/bin执行
./redis-server redis.conf
3、启动客户端连接redis服务器
1、进入目录 /usr/local/d113/redis/bin
2、执行 ./redis-cli
4、退出redis的客户端: exit
停止redis的服务器:
1、查看redis进程
ps -ef | grep redis
2、杀死进程
kill -9 进程号
3、redis使用
@@@@@@redis在编辑文件时,查找指定内容的快捷键:
1、vi 文件
2、按下/输入要查找的内容,回车
3、按字母i,开始编辑
4、如果还要查找其他内容,可以先按esc 退出编辑模式,再按下/输入要查找的内容,回车
5、保存退出
第二章
1、redis中的五种数据类型 2、redis的使用 3、redis的持久化策略 4、redis中的主从复制
前情摘要
@@@@@@@@@@@@@@@@@@@启动redis分为前台启动与后台启动
后台启动redis的步骤:
1、进入/usr/local/d113/redis/bin
2、后台启动redis
./redis-server redis.conf
3、查看redis是否启动成功
ps -ef | grep redis
4、如果要停止redis
kill -9 进程号
@@@@@@@@在编辑文件时,要快速查找指定内容
1、vi 文件名
2、输入/要查询的内容,然后回车
3、找到内容后按字母i进行编辑
4、如果编辑完了,要再查找其他内容,只需要按esc退出编辑模式,再继续输入/内容
1、redis的使用
1、使用方式
@@@@@@@@@@@操作redis的方式主要有三种:
方式1、通过redis的客户端访问redis服务器
1、在/usr/local/d113/redis/bin目录下输入下列命令即可连接redis客户端
./redis-cli
2、退出redis客户端
exit
方式2:用一个桌面管理工具,在windows中可以直接访问linux下的redis
@@@@如果要用桌面管理工具体或者java连接redis都必须将redis的6379端口号在linux的防火墙中注册
firewall-cmd --zone=public --add-port=6379/tcp --permanent
firewall-cmd --reload
方式3:在java代码中通过jedis与redis建立连接
@@@@@@@@@jedis:用java代码连接redis的技术
2、使用Java代码使用redis
步骤
1、创建工程
2、导入下列依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.7.0</version>
</dependency>
3、编写代码
//创建jedis
Jedis jedis = new Jedis("192.168.47.128",6379);
//存数据
//jedis.set("msg2","abc");
//关闭jedis
jedis.close();
@@@@@@这种方式连接redis性能不好,它在连接redis的时候需要自己创建连接,用完后,连接又会被销毁,这样会导致频繁创建、销毁连接,会消耗更多资源降低程序的性能
为了解决该问题,在连接redis时,我们都需要配置连接池,配置jedis连接池以后,当需要使用连接时,不需要自己创建,只需要从连接池中获得连接,用完以后,关闭资源,连接并不会真的释放。它会回到连接池,其他用户可以继续使用,这样可以避免频繁创建、销毁连接
3、优化连接redis
@@@@@@@@@@@@@采用连接池的方式操作redis
//创建连接池的配置对象,用于设置连接池配置信息
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//指定连接池的最小闲置连接数--------连接池最少要保证有多个闲置连接,如果没有就会马上自动创建
jedisPoolConfig.setMinIdle(50);
//指大最大闲置连接数
jedisPoolConfig.setMaxIdle(100);
//设置最大连接数
jedisPoolConfig.setMaxTotal(200);
//由于用完的连接并不会释放,会回到连接池,设置多余闲置连接的销毁时间
jedisPoolConfig.setEvictorShutdownTimeoutMillis(3000);
//设置等待连接的超时时间
jedisPoolConfig.setMaxWaitMillis(3000);
//创建jedis连接池
JedisPool jedisPool = new JedisPool(jedisPoolConfig,"192.168.47.128",6379);
//通过连接池获得jedis
Jedis jedis = jedisPool.getResource();
//操作redis
jedis.set("msg3","china");
//关闭jedis(不是真的关闭,只是让用完的连接回到连接池中)
jedis.close();
2、五种数据类型
redis中的数据类型有五种: 1、string-----------------字符串类型 2、hash-------------------散列类型 3、list-------------------列表类型 4、set--------------------无序集合类型 5、zset-------------------有序集合类型
常用命令
查看当有redis中有哪些键 keys * 清空redis中的所有数据 flushall 删除键 del 键 判断当前键对应的数据类型 type 键 给键设置过期时间(秒) 如果不设置,键将永远存在 expire 键 10 注意:键必须要先存在,才能设置。键默认是永不过期 查看键的过期时间 ttl 键 -1:永不过期 -2:键已经过期 18:当前键还可以存活18秒
string
@@@@@@@@@@string-----------------字符串类型 1、存数据 set 键 值 set msg hello 2、通过键取值 get 键 get msg 3、一次存放多键值对 mset 键1 值1 键2 值2 mset k1 aa k2 bb 4、一次通过多个键取值 mget 键1 键2 mget k1 k2 5、判断是否存在某一个键(存在返回1,不存在返回0) exists 键 6、删除某一个键(成功返回1,失败返回0) del 键 @@@@@@@@@@@如果当前键对应的值是一个数值,则可以使用下列这一组命令 incr 键---------------------让当前的数值加1 decr 键---------------------让当前的数值减1 incrby 键 5--------------- 当前值上加5 decrby 键 5--------------- 当前值上减5 字符串类型的数据在存放数据时,如果键已经存在,值将会被覆盖
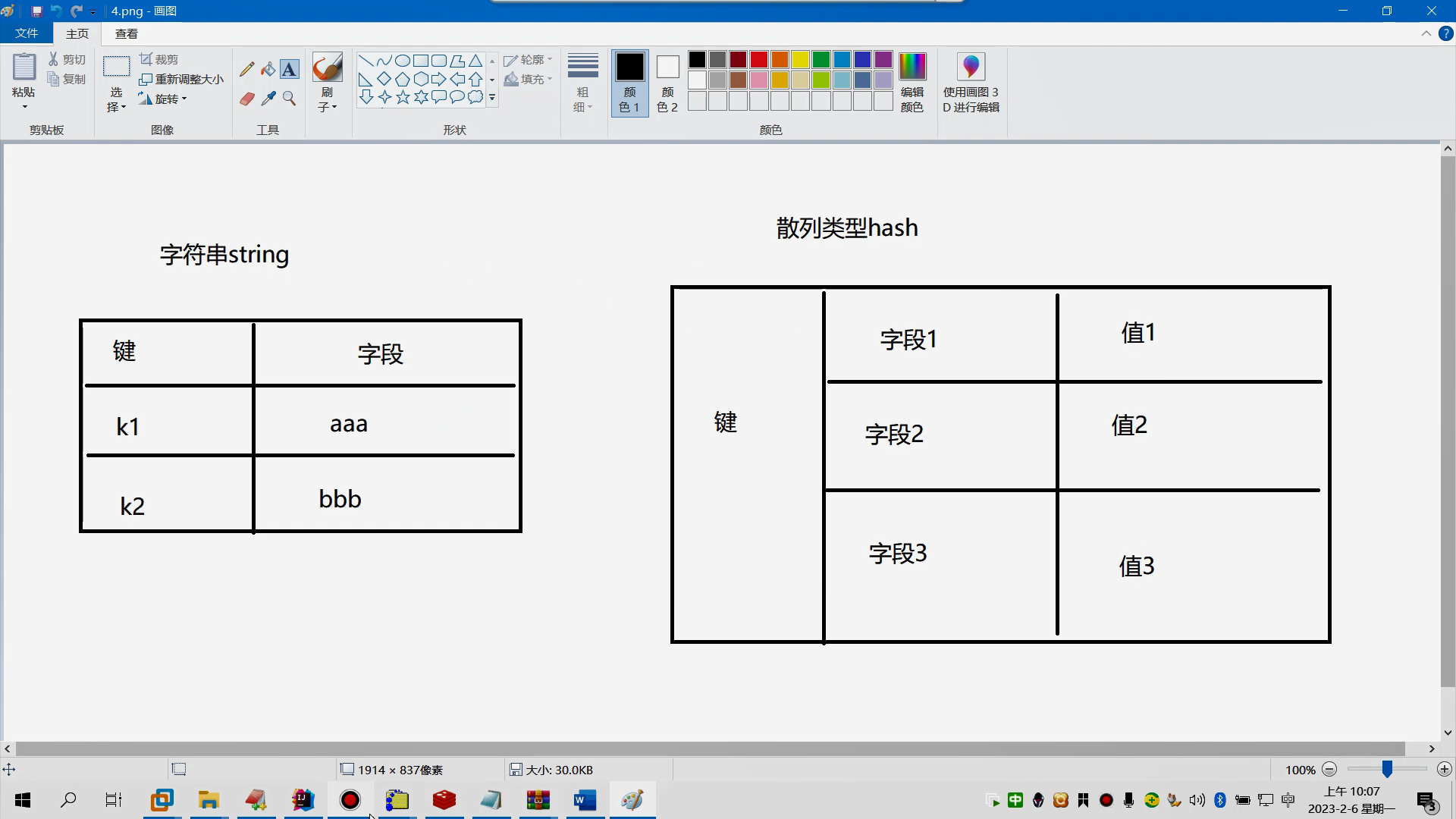
hash
@@@@@@@@@@@@@hash散列类型 它存放的值是一个map类型 1、存数据: hset 键 字段 值 hset stu id 1 hset stu name jack hset stu score 100 @@@@@散列结构在存放数据时,只有键与字段名都相同的时候,值才会被覆盖。如果仅仅是键相同字段名不同,它执行追加 2、取数据 hget 键 字段 hget stu id hget stu name hget stu score 3、一次性存放多个字段 hmset 键 字段1 值1 字段2 值2 hmset s2 id 1 name jack score 99 4、一次性取多个字段 hmget 键 字段1 字段2 hmget s2 id name score 5、获得键里面包含的所有字段名 hkeys 键 6、获得键中包含所有的字段值 kvals 键 7、判断键中是否包含某一个字段 hexists 键 字段名 8、删除某一个字段 hdel 键 字段名
list
@@@@@@@@@@list列表类型 它是一种双向链表结构,它存放数据时,可以从两头进存放 特点: 1、有顺序 2、可以有重复元素 1、存放数据(从左向右存放)left lpush 键 值1 值2 值3 lpush list1 a b c 输出:c b a 2、从右向左存放 right rpush 键 值1 值2 值3 rpush list1 111 222 333 @@@@键存在,也不会覆盖,只是追加数据 输出:c b a 111 222 333 3、取列表中最左侧的数据(取一次,列表中就会少一个数据) lpop 键 4、取列表中最右侧的数据(取一次,列表中就会少一个数据) rpop 键 5、遍历列表的所有数据 lrange 键 0 -1 lrange list1 0 -1
set
@@@@@@@@set无序集合类型 特点:1、没有顺序 2、不能有重复元素 1、存数据 sadd 键 值1 值2 值3 sadd set1 aaa bbb ccc 2、获得所有数据 smembers 键 smembers set1 3、判断是否包含某一个值 sismember 键 值 sismember set1 aaa 4、从无序集合中随机获得一个值(获得该值后,这个值就会从集合中移除) spop set1(适合用于抽奖)
zset
@@@@@@@@zset有序集合类型 特点: 1、有顺序 2、不能有重复元素 1、存数据 zadd 键 分数1 值1 分数2 值2 -------------它在添加数据时必须给每一个值设置一个分数,排序时按分数升序排序 zadd zset1 100 andy 80 bruce 90 tom 2、查看所有数据(不包含分数),默认是按分数升序排序 zrange 键 0 -1 zrange zset1 0 -1 3、查看所有数据(包含分数),默认是按分数升序排序 zrange 键 0 -1 withscores zrange zset1 0 -1 withscores 4、查看所有数据(包含分数),按分数降序排序 zrevrange 键 0 -1 withscores zrevrange zset1 0 -1 withscores
不同数据类型存、取、遍历的方法
string set key value get key hash hset key 字段 值 hget key 字段 list lpush 键 aa bb cc rpush 键 aa bb cc lrange 键 0 -1 set sadd 键 aaa bbb ccc smembers 键 spop 键 zset zadd 键 分数 值1 分数 值2 zrange 键 0 -1 zrange 键 0 -1 withscores zrevrange 键 0 -1 withscores
3、redis在项目中使用
@@@@@@@@redis在项目中的使用 redis在项目中主要是作为缓存使用,这样可以在高并发环境下,环境数据库的压力 项目中配置了redis后的执行过程: 1、当请求到达服务器,查询某一条数据时,系统会首先查询redis缓存中有没有需要数据 2、如果缓存中没有需要的数据,系统就会查询数据库,并且把查询到结果放入缓存,然后将查询结果返回给客户端 3、下一次当客户端再一次查询该数据时,由于缓存中已存在该数据,系统就会直接返回缓存中的数据,不再查询数据库
示例
<!--具体详情请看:redis_j54_singleton项目 -->
1、导入素材与redis无关 2、@@@加入redis实现功能
1
1、在pom.xml导入下列依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.0</version>
</dependency>
2
2、添加配置文件 applicationContext-redis.xml
<!--1、指定redis配置对象-->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!--指定连接池的最小闲置连接数连接池最少要保证有多个闲置连接,如果没有就会马上自动创建-->
<property name="minIdle" value="50"/>
<!--最大闲置连接数-->
<property name="maxIdle" value="100"/>
<!-- 设置最大连接数-->
<property name="maxTotal" value="200"/>
<!--由于用完的连接并不会释放,会回到连接池,设置多余闲置连接的销毁时间-->
<property name="evictorShutdownTimeoutMillis" value="3000"/>
<!--设置等待连接的超时时间-->
<property name="maxWaitMillis" value="3000"/>
</bean>
<!-- 2、配置连接池-->
<bean id="jedisPool" class="redis.clients.jedis.JedisPool">
<constructor-arg name="poolConfig" ref="jedisPoolConfig"/>
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="6379"/>
</bean>
3
3、修改web.xml加载redis的配置文件 <servlet> <servlet-name>mvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:applicationContext*.xml</param-value> </init-param> </servlet> <servlet-mapping> <servlet-name>mvc</servlet-name> <url-pattern>*.do</url-pattern> </servlet-mapping>
4
4、编写redis的接口
public interface JedisClient {
public void set(String key,String value);
public String get(String key);
public void hset(String key,String field,String value);
public String hget(String key,String field );
public void hdel(String key, String filed);
}
5
5、编写Jedis的实现类(单机版)
@Component
public class JedisClientSingleImpl implements JedisClient {
//注入连接池
@Autowired
private JedisPool jedisPool;
@Override
public void set(String key, String value) {
Jedis jedis = jedisPool.getResource();
jedis.set(key,value);
jedis.close();
}
@Override
public String get(String key) {
Jedis jedis = jedisPool.getResource();
String value = jedis.get(key);
jedis.close();
return value;
}
@Override
public void hset(String key, String field, String value) {
Jedis jedis = jedisPool.getResource();
jedis.hset(key,field,value);
jedis.close();
}
@Override
public String hget(String key, String field) {
Jedis jedis = jedisPool.getResource();
String value = jedis.hget(key, field);
jedis.close();
return value;
}
@Override
public void hdel(String key, String filed) {
Jedis jedis = jedisPool.getResource();
jedis.hdel(key,filed);
jedis.close();
}
}
6-7
6、导入jsonUtil工具类,用于转换Json数据
7、修改Service的代码
在查询数据之前,先查询redis,如果有需要的数据,就不再查询数据库
@Service
public class PrdServiceImpl implements PrdService {
@Autowired
private PrdMapper mapper;
//注入jedis接口
@Autowired
private JedisClient jedisClient;
@Override
public List<Prd> getList() {
return mapper.getList();
}
@Override
public Prd findById(String pid) {
//首先查询redis中有没有需要的数据
String json = jedisClient.hget("redis_j54_singleton", pid);
//判断数据是否为null,如果为空,表示缓存中还没有需要的数据,需要到数据库加载
if(StringUtils.isEmpty(json)){
//为空,表示缓存中还没有需要的数据,需要到数据库加载
System.out.println("到数据库加载编号为:"+pid+"的数据");
//准备查询数据库
Prd prd = mapper.findById(pid);
//在返回之前要把它转换成json存放到redis
json = JsonUtils.objectToJson(prd);
jedisClient.hset("redis_j54_singleton",pid,json);
return prd;
}else{
//缓存中有需要的数据.需要将Json还原成对象返回
System.out.println("到缓存中加载编号为:"+pid+"的数据");
Prd prd = JsonUtils.jsonToPojo(json, Prd.class);
return prd;
}
}
}
第三章
1、缓存击穿(缓存穿透、缓存雪崩) 2、redis数据持久化策略 3、redis中的主从复制 4、redis集群的使用
Linux常用命令
编辑文件:vi redis.conf 搜索内容:/内容 进入编辑模式: i 退出编辑: esc 保存: :wq 不保存: q! 查看正在运行的某一个程序(进程) ps -ef | grep 程序名 杀死进程 kill -9 进程号 解压缩: tar -xvPf 压缩包名称 -C /usr/local/d113 复制文件 cp 文件名 指定路径 复制文件夹 cp 文件名 -r 指定路径 删除文件 rm -rf 文件名 重命名 mv 原文件名 新文件名 查看ip ifconfig 新建文件夹 mkdir 文件夹名称 查看文件内容 cat less 查看当前文件夹中的所有文件 ls 查看当前文件夹中的所有文件(包含隐藏文件) ls -a 联网安装软件 yum install 软件名 返回上一级 cd .. 返回根目录 cd /
1、redis的作用
redis在项目中的主要作用是:作为缓存使用 在客户端请求到达服务器后,系统会首先判断缓存中有没有需要的数据,如果没有,系统就会查询数据库,并且把查询到的数据放入到缓存中,然后再返回。 当下一次请求,再次到达到服务器,如果检测到缓存中有需要的数据,就会直接返回缓存中的数据,不再走数据库加载,这样可以缓解数据压力。 在项目中配置redis缓存后,假设某一个条数据被请求了10000次 第1次应该从数据库加载数据 剩余的9999次都应该从缓存中加载
存在问题
问题:当缓存中有数据,请求就会直接返回缓存中的数据,不再走数据库,假设,此时后台的数据被修改了,但由于缓存中有数据,
将会导致最新修改的数据无法加载
答:当后台某一台数据被修改后,我们可以找到它对应的缓存数据,将该数据从缓存中移除掉
1、高并发
高并发:大量请求同时访问
条件:在高并发环境下,有1000个请求访问同一条数据,线程池每次可以并发执行100个线程
1、第1批的100个线程,它们一开始并发执行到redis中访问数据,由于redis中没有数据,所有它们得到的结果就是redis中没有需要的数据,这100个线程都要到数据库查询
2、这100个线程查询数据库后,每一个线程都会将查询到的对象,存放到redis中
3、后面900个请求对应的线程,由于redis中已经有数据了,就直接返回缓存中的数据,不再查询数据库
2、缓存击穿
缓存击穿:
大量请求访问同一条数据(热点数据),如果该数据在redis中不存在,但是在数据库中存在,导致大量请求同时访问数据库,这种情况我们称为:“缓存击穿”
解决方案:
1、设置热点数据永不过期
2、设置互斥锁(双重检测锁)
双层检测锁
双重检测锁 假设有100个线程并发执行 1、在方法中首先查询缓存中有没需要的数据(100个线程会同时查询) 2、如果这100个线程没有找到需要数据,它们都要准备查询数据库 3、在这100个线程准备查询数据库之前,编写一个同步锁synchronized,在同步锁中每一次只能执行1个线程 4、在synchronized中,再查询一次缓存,这100个准备查询数据库的线程,只能一个一个查询 5、如果在synchronized中如果能够从缓存中查询到需要的数据,就表示已经有线程查询过数据库,当前线不需要再次查询,直接返回缓存中的数据即可 6、如果synchronized中的线程,从缓存中依然查询不到数据,表示这100个线程都还没有查询过数据库,当前线程就要到数据库查询,并且将查询结果放入到缓存,其他线程就返回缓存中的数据即可
3、缓存雪崩
缓存雪崩:
缓存中的大量热数据同时到期,导致缓存中的大量数据同时失效,这样大量请求会同时访问数据库,导致数据库压力过大
解决方案:
1、均匀的给热点数据设置过期时间,不要让它们同时失效
4、缓存穿透
缓存穿透 当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。 解决方案: 缓存穿透的方案,常见的方案有三种。 第一种方案,非法请求的限制; 第二种方案,缓存空值或者默认值; 第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
总结
缓存击穿:一个热点数据过期,它在缓存不存在,在数据库存在,会导致并发环境下,大量请求同时访问数据库 缓存雪崩:大量热点数据同一时间过期,会导致大量请求同时访问数据库 缓存穿透:请求的数据在缓存中不存在,在数据库也不存在,导致无法构建缓存结构,所有请求会频繁访问数据库
2、redis数据持久化策略
redis的持久化策略
问题:redis的数据是存放在缓存中的,但当程序关闭时,缓存会被释放掉,为什么redis的数据不会丢失?
答:因为redis有自己的持久化策略。
当用户向redis存放数据时,数据是存在内存中的,当程序关闭时,redis默认会将内存中的数据保存到一个名为dump.rdb文件中,此时即使内存被释放,但数据已经存放在dump.rdb文件,当起动redis时,系统又会将dump.rdb中的数据加载到内存中
数据持久化策略有两种
方式1
方式1:采用一种快照的方式,定时将内存中的数据存放到rdb文件 如果修改了redis中的1条数据,系统会在900秒以后,自动存放到dump.rdb文件 如果修改了redis中的10条数据,系统会在300秒以后,自动存放到dump.rdb文件 如果修改了redis中的10000条数据,系统会在60秒以后,自动存放到dump.rdb文件 save 900 1 save 300 10 save 60 10000 问题:如果修改了1条数据,如果关闭redis它会不会马上保存 不会保存,会丢失掉 希望数据后马上保存,可以执行 save命令即可 @@@@@默认情况下redis是采用rdb快照的方式定时存储数据 这种方式的缺点时,由于它是定时存储,如果存储时间没有到程序意外终止,将会导致未保存的数据丢失。为了解决这个问题,redis提供了另一种持久化策略
方式2
方式2:采用一种日志的方式即时存储(一般用的也是aof) 这种方式会生成一个aof文件,对redis做的任何修改都会马上保存到这个文件中,即使程序意外终止,数据也不会丢失 配置方式: 1、修改/usr/local/d113/redis/bin/redis.conf vi /usr/local/d113/redis/bin/redis.conf 2、修改文件中的一行代码 将 appendonly no 修改为 appendonly yes 3、重启redis服务
区别
@@@@@@@Redis持久化策略中的rdb方式与aof方式的区别?
答:rdb是采用快照的方式定时存储,它比较节省资源,但可能会导致未保存的数据意外丢失
aof是采用日志的方式即时存储,它消耗的资源会比rdb方式更多,但它可以防止数据意外丢失
3、redis中的主从复制
@@@@@@@@@@@如何解决redis的单点故障?
单点故障:某一台redis服务无法使用,导致数据无法读取
解决方案:
配置redis服务器的主从复制(给主机配置从机),主机上的数据,会自动备份到从机。主机如果发生故障,从机可以提供数据
配置步骤
1、将/usr/local/d113/redis/bin目录复制一份名为bin2 bin-----主机 bin2----从机 cp /usr/local/d113/redis/bin -r /usr/local/d113/redis/bin2 2、删除bin2目录下的 rdb与aof文件 rm -rf *.rdb *.aof 3、主机不需要进行任何配置 4、修改从机的 redis.conf 1、进入bin2 slaveof 主机的Ip地址 主机的端口号 slaveof 192.168.47.128 6379 由于在同一台电脑中,多个端口不能冲突,所以要将从机的端口改为6380 port 6380
5、启动从机服务器 1、进入bin2 2、执行命令 ./redis-server redis.conf 6、在主机上进行的任何操作,数据都会反映到从机 bin是主机 bin2是从机 7、登录从机的客户端查看数据 1、进入bin2 2、执行命令 ./redis-cli -p 6380 @@@@@@@@@@@@@@注意:从机只能读数据,不能写数据
第四章
redis集群的配置及使用
1、redis的集群配置
@@@@我们之前配置的redis是单机版,所有请求需要由一台redis服务器进行处理,当请求的数据量比较大时,该服务器的压力也会比较大 为了解决这个问题,我们可以配置redis集群 配置redis服务器集群的好处: 1、将原本应该由一台redis主机承受的压力,分散到多台redis主机共同分担,这样可以减少单台redis主机的压力 2、配置redis集群,可以让多台redis主机共同处理请求,性能会更快 3、配置redis集群后,redis的主机会自动配置从机。当redis主机挂了,它的从机会自动升级成主机可读可写
1、配置要求
@@@@配置redis集群的要求:
1、redis的主机数量必须是单数,至少需要配置3台redis主机
2、redis的主机需要配置从机
@@@@@@配置redis集群至少需要6台redis服务器,其中3台主机,3台从机
2、判断失败标准
@@@@@@判断redis集群是否失败的标准是什么 1、如果集群中主机挂了,它如果没有配置从机。该节点无法访问,集群失败无法使用 2、如果集群中有一半以上的主机挂了,即使它们配置了从机,集群也是失败的
3、配置原理
@@@@配置redis集群的原理: 通过网络将多台redis服务器连接在一起,共同处理请求,这样可以提升处理请求的效率,减少单台服务的压力
4、配置完成数据如何存储
@@@@配置redis服务器集群后,数据是如何存储的? 当配置redis集群中,集群中会产生16384个哈希槽(哈希槽用于具体存储数据),这些哈希槽会均分到每一台主机上,当向redis集群存储数据时,redis存放数据是采用:键值对方式存储的。系统会对键采用一种CRC16算法,将键转换成一个数值,然后系统用这个数值取模16384,会得到一个介于0~16383之间的值,系统会判断这个值对应的哈希槽在哪一台主机上,就会自动切换到主机 这些哈希槽范围是: 0~16383 假设有三台主机: 第一台主机: 0 ~ 5000 第二台主机: 5001 ~ 10000 第三台主机: 10001~16383
2、准备工作
@@@@@@@配置redis集群前的准备工作: 由于redis集群的管理工具是用ruby语言写出来的,所以我们要先配置ruby的环境 1、联网安装ruby的环境 yum install ruby yum install rubygems 2、下载redis集群管理工具 redis-3.0.0.gem 3、将工具发布到Linux下的/d113目录中 4、进入/d113目录执行下列命令安装工具 gem install redis-3.0.0.gem 5、在/usr/local/d113目录下,创建一个名为:redis-cluster的目录,用于存放redis集群中的所有redis服务器 mkdir /usr/local/d113/redis-cluster 6、将/usr/local/d113/redis/bin目录复制一份到/usr/local/d113/redis-cluster,同时命名为7001(它就是一台redis服务器) cp /usr/local/d113/redis/bin -r /usr/local/d113/redis-cluster/7001 7、将/usr/local/d113/redis0-3.0.0/src目录下的redis-trib.rb文件拷贝到/usr/local/d113/redis-cluster目录,用于构建集群 cp /usr/local/d113/redis-3.0.0/src/redis-trib.rb /usr/local/d113/redis-cluster
3、构建redis集群
步骤
1-5
@@@@@@@@@@@@@构建redis集群 1、将7001目录中的*.rdb,*.aof文件删除 1、进入目录 cd /usr/local/d113/redis-cluster/7001 2、删除 rm -rf *.rdb *.aof 2、进入7001目录,修改redis.conf 1、将端口改为: 7001 2、启用集群 # cluster-enabled yes 将前面的#去掉即可 cluster-enabled yes 3、保存退出 3、将7001复制5份,分别命名为:7002~7006 (它们就是6台redis服务器) 1、进入 /usr/local/d113/cluster 2、复制 cp 7001 -r 7002 cp 7001 -r 7003 ..... 4、分别进入 7002~7006修改redis.conf,将端口号分别改为7002~7006 5、分别启动 7001~7006这些服务器 1、分别进入7001~7006 2、分别执行 ./redis-server redis.conf
6-11
6、查看进程,看这些服务器是否启动好了 7001~7006
ps -ef | grep redis
7、进入/usr/local/d113/redis-cluster用 redis-trib.rb文件构建redis集群
./redis-trib.rb create --replicas 1 192.168.47.128:7001 192.168.47.128:7002 192.168.47.128:7003 192.168.47.128:7004 192.168.47.128:7005 192.168.47.128:7006
在执行过程中,有一个地方要求要输入,我们输入yes确定即可
8、登录redis集群
配置集群后,集群中的所有服务器是可以共享访问,登录其中的任意一台服务器都可以
1、进入 7001目录
2、通过客户端访问redis集群
./redis-cli -h 192.168.47.128 -p 7001 -c
9、查看集群的状态
cluster info
10、查看集群中的主从机信息以及哈希槽的分配信息
cluster nodes
11、将7001~7006在防火墙中注册
firewall-cmd --zone=public --add-port=7001/tcp --permanent
firewall-cmd --reload
4、测试集群
@@@@@@@@@@测试集群: 问题1:集群中的服务器是共享的,当存储数据时,系统对键采用CRC16算法得到数值取模16384得到一个哈希值,然后就会切换该值对应哈希槽的主机 7001主机:0~5460 (7004) 7002主机:5461~10922 (7005) 7003主机:10923~16384 (7006) 问题2:如果集群中的某一台主机如果挂了,它的从机会自动升级成主机可读可写 键为stu的数据,是存放在7003这个主机中的 将7003的进程关掉,7006就会升级成主机 如果此时将7003启动,它将会成为7006的从机
5、Java代码访问集群
示例1:与spring无关,单独访问集群
示例1:与spring无关,单独访问集群
package org.java.demo;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.util.HashSet;
import java.util.Set;
/**
* @author arjun
* @title: clusterRedis
* @description: 描述信息
* @date 2023.08.20 10:15
*/
//redis集群测试
public class clusterRedis {
public static void main(String[] args) {
/*******************连接池****************************/
//创建连接池的配置对象,用于设置连接池配置信息
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//指定连接池的最小闲置连接数--------连接池最少要保证有多个闲置连接,如果没有就会马上自动创建
jedisPoolConfig.setMinIdle(50);
//指大最大闲置连接数
jedisPoolConfig.setMaxIdle(100);
//设置最大连接数
jedisPoolConfig.setMaxTotal(200);
//由于用完的连接并不会释放,会回到连接池,设置多余闲置连接的销毁时间
jedisPoolConfig.setEvictorShutdownTimeoutMillis(3000);
//设置等待连接的超时时间
jedisPoolConfig.setMaxWaitMillis(3000);
/******************redis集群****************************/
//真实项目中,不是改端口号,而是修改ip,端口号都为6379
Set<HostAndPort> set=new HashSet<>();
set.add(new HostAndPort("192.168.18.128",7001));
set.add(new HostAndPort("192.168.18.128",7002));
set.add(new HostAndPort("192.168.18.128",7003));
set.add(new HostAndPort("192.168.18.128",7004));
set.add(new HostAndPort("192.168.18.128",7005));
set.add(new HostAndPort("192.168.18.128",7006));
/*****************测试集群****************************/
JedisCluster jedisCluster=new JedisCluster(set,jedisPoolConfig);
String score = jedisCluster.get("id");
System.out.println(score);
}
}
示例2:在spring中使用集群
1、修改applicationContext-redis.xml配置集群
<!--1、指定redis配置对象-->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!--指定连接池的最小闲置连接数连接池最少要保证有多个闲置连接,如果没有就会马上自动创建-->
<property name="minIdle" value="50"/>
<!--最大闲置连接数-->
<property name="maxIdle" value="100"/>
<!-- 设置最大连接数-->
<property name="maxTotal" value="200"/>
<!--由于用完的连接并不会释放,会回到连接池,设置多余闲置连接的销毁时间-->
<property name="evictorShutdownTimeoutMillis" value="3000"/>
<!--设置等待连接的超时时间-->
<property name="maxWaitMillis" value="3000"/>
</bean>
<!-- 配置redis集群-->
<bean id="cluster" class="redis.clients.jedis.JedisCluster">
<!--指定构造参数1:redis服务器的集合-->
<constructor-arg index="0">
<set>
<!--所有的redis服务器都要放在set集合-->
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7001"/>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7002"/>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7003"/>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7004"/>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7005"/>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg name="host" value="192.168.47.128"/>
<constructor-arg name="port" value="7006"/>
</bean>
</set>
</constructor-arg>
<!--指定构造参数2:连接池的配置对象-->
<constructor-arg index="1" ref="jedisPoolConfig"/>
</bean>
2、编写JedisClient接口的实现类(采用集群的方式实现)
@Component("myCluster")
public class JedisClientClusterImpl implements JedisClient {
@Autowired
private JedisCluster jedisCluster;
@Override
public void set(String key, String value) {
jedisCluster.set(key,value);
}
@Override
public String get(String key) {
return jedisCluster.get(key);
}
@Override
public void hset(String key, String field, String value) {
jedisCluster.hset(key,field,value);
}
@Override
public String hget(String key, String field) {
return jedisCluster.hget(key,field);
}
@Override
public void hdel(String key, String filed) {
jedisCluster.hdel(key,filed);
}
}
3、在PrdService注入JedisClient的实例
//注入jedis接口
@Autowired//这种方式是按类型自动注入,它注入的接口的实现类,这种方式注入要求:只允许出现一个匹配类型(接口只有一个实现类才可以这样使用) //如果有多个匹配类型,就不能按类型注入,只能按名称注入
@Qualifier("myCluster")
private JedisClient jedisClient;
@@@@@@@@@@Redis集群中的数据是共享访问的,但如果使用REDIS的管理工具查看集群的数据,当前主机只能看到当前主机的数据