1.引言
- Yolo1,2,3的作者是Joseph Redmon.
- Yolo是one-stage算法,即无需提取候选框、没有复杂的上下游处理工作,而是图片输入后经过网络,一次性往前推段得到bounding box的定位以及分类结果。是端到端训练优化。
优点:
- 将目标检测问题当作回归问题,无需提取候选框,是单阶段的。
- 速度快。
- 可以捕捉上下文信息,recall高、迁移泛化好
缺点:
- 小物体检测效果差
- 定位误差高
训练阶段:
- 图片输入到网络中,输出7 * 7 * 30的向量
- 计算损失反向传播调整网络权重
预测阶段:
- 图片输入到网络中,得到98个框的20维向量
- 对于类别1,找到高于阈值的框,最高的框A拿出来,计算剩余框与框A的IOU,高于某阈值的就去掉
- 对于类别2,重复以上步骤
- 最后剩下的框就是最终的预测框了
2.Yolo v1论文

这是一个统一的、实时的目标检测框架,正如其名字一样,你只需要看一次,就可以得到目标检测的结果。一次性向前推段bbox的位置和分类置信度,优化也是端到端的。
摘要

- Yolo框架很快,每秒能处理155帧(每秒30帧就算是实时检测了)。并且mAP(平均准确率)还可以保持很高。迁移泛化能力也很强,用训练好的模型去识别油画也能进行检测。
1.介绍


- 一些方法比如RCNN是分阶段去进行目标检测的。第一阶段是提取潜在的候选框,第二阶段是用分类器去筛选每个框、修正位置。这个方法很慢也很难去优化,因为每个步骤都是分开的。


- 于是作者将目标检测视为单一回归问题,直接从图像中识别出候选框和分类。如图一所示,仅仅用一个卷积神经网络就预测出了多个候选框和分类置信度。训练与优化一气呵成。



优点很多:
- 超级快!因为作者将目标检测问题重新定义为了回归问题,所以流程一点也不复杂。
- Yolo是分析全图信息,误把背景识别为物体的错误更小。而不像比如Fast RCNN 误把背景识别为物体,因为它看不了全局更大的信息(Fast RCNN是用anchor去某一像素点生成一系列的候选框)
- 泛化能力强。在普通图片数据集上训练,在艺术图片等新领域上识别时,也表现不错。


也有一定的缺点:
- 准确率不是最高的,稍有下降,但这也是速度和准确率权衡的结果。
- 识别小物体的性能差。


2.一个统一的目标检测框架
Yolo将多个阶段的(先识别候选框,再对候选框进行分类)识别框架流程合并为一个单独的网络。这个网络输入图片,直接同时输出每个预测框的位置和分类置信度。
这个网络是端到端的、实时检测的。
- 首先将图片划分为S×S个grid(网格)
- 如果目标物体的GT框中心落在了网格A中,那么网格A就负责检测这个物体,检测这个目标物体的bbox就有网格A生成。
- 每个网格需要预测B个候选框以及候选框置信度。置信度是指:有多确定这个候选框包含了物体,以及这个框的位置预测得有多准确。
- 置信度计算公式为 P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU^{truth}_{pred} Pr(Object)∗IOUpredtruth。 P r ( O b j e c t ) = 0 或 者 1 Pr(Object)=0或者1 Pr(Object)=0或者1。
- 如果没有物体在这个网格内,那么置信度分数为0;如果有,那么置信度分数就是predict bbox和GT bbox的IOU。


- 每个bbox会产生5个预测值: x , y , w , h , c o n f i d e n c e x,y,w,h,confidence x,y,w,h,confidence。即预测框的四个坐标和一个置信度分数。
- 这五个值都在0~1之间。 ( x , y ) (x,y) (x,y)是相对这个网格的坐标, w 和 h w和h w和h是相对整个图片的宽和高。
- 每个网格预测的类别有 C C C个,是条件概率,是假设负责预测某物体的条件下是某类别的概率。
- 每个网格只预测一组条件类别概率,这个网格产生的所有bbox都共享这个条件类别概率。

- 在测试阶段,将候选框的置信度和条件类别概率相乘,成为最终的具体的分类置信度分数,这个分数既表明了分类的精度,又表明了定位的精度。
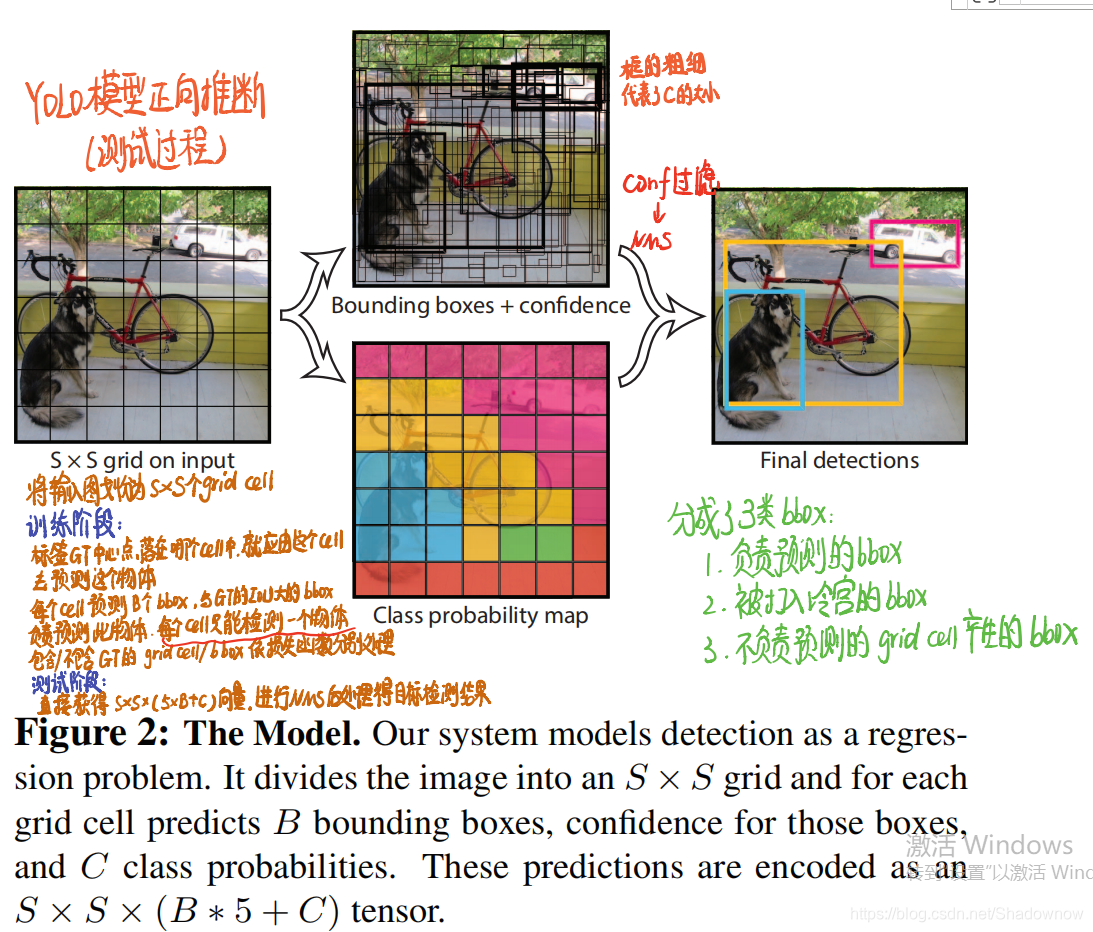

在论文中,S=7,B=2,C=20,因此每个网格会产生30个分数,共有49个网格。网络的输出向量就是7 * 7 * 30。
2.1 网络设计

- 使用卷积网络去实现的Yolo. 卷积层去提取特征,全连接层去进行预测和输出分类概率和坐标。
- 使用GoogleNet模型进行图片分类训练。有24层卷积层,后接2个全连接层。不用GoogleNet中所使用的inception module,我们直接在1×1的reduction layer后接3×3卷积层。如下图所示。
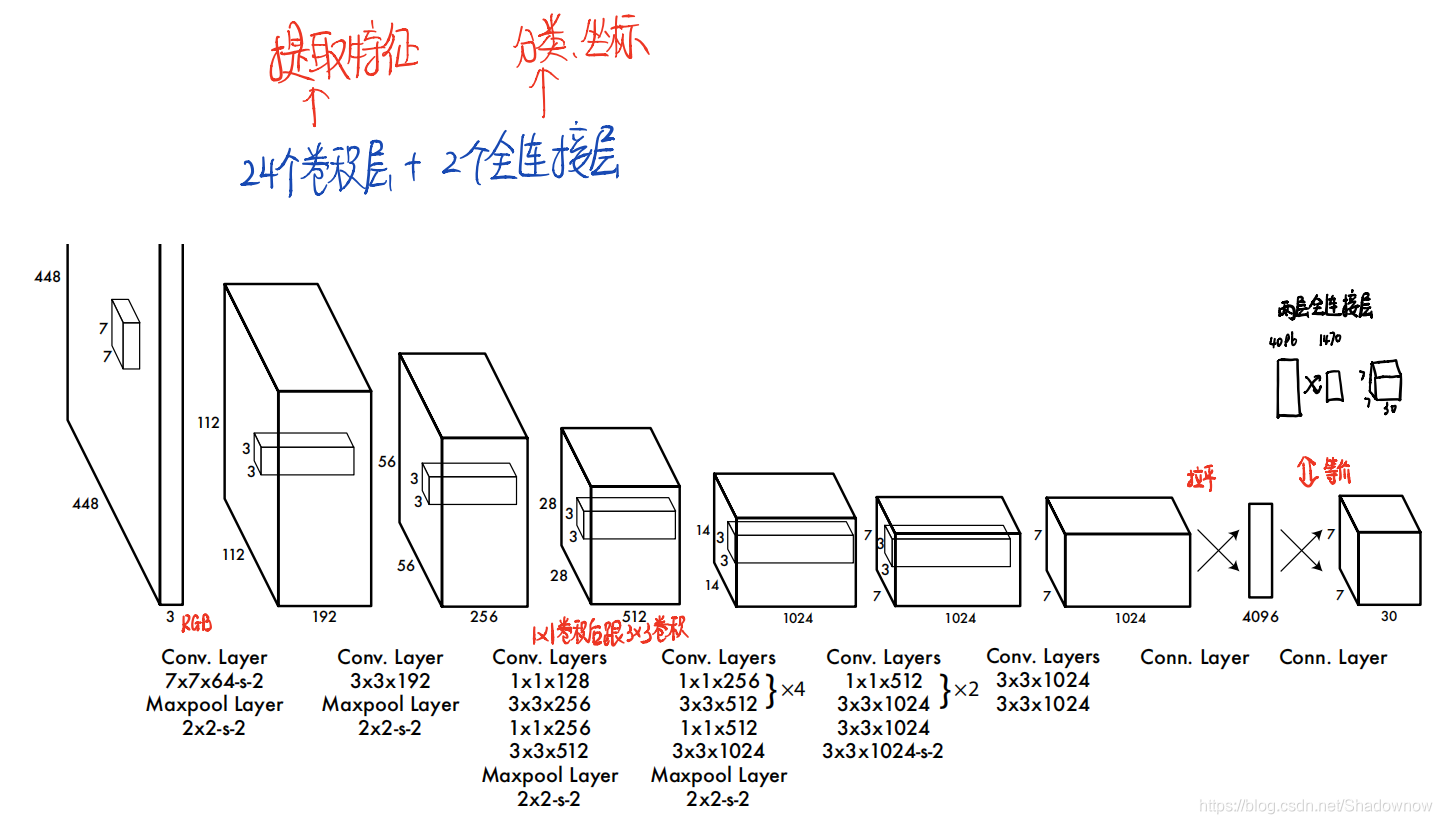

如果使用更小型的网络,不用24层,用9层,且卷积核数量减少,速度会更快。
2.2 训练阶段





- 在ImageNet 1000类数据集上预训练一个分类模型,使用图3的前20层卷积层,接1个average-pooling 层和1个全连接层。
- 保留这个权重再去训练目标检测模型。
- 在训练好的模型上加4个卷积层和两个全连接层(这些层的参数随机初始化)
- 检测一般需要细粒度的视觉信息,因此我们将输入的分辨率从224×224 提升到448×448.
- 网络输出预测框坐标和概率。最后一层用线性激活函数,其他层都用leaky rectified linear activation。
- 使用平方和误差作为损失函数。但是这个误差对大小框、定位和分类、包含物体和不包含物体的框都是一视同仁的,这样实际上不好,因此为了加强定位误差损失,削弱不包含GT的预测框的confidence损失,加入了两个参数。对于大小框,计算h和w的平方根,削弱大框的误差。

在训练阶段,我们只希望每个物体只有一个预测框。因此负责检测物体的网格产生的候选框,我们保留与GT框最大IOU的候选框作为预测框。
Yolo和Faster RCNN这样的模型不一样,没有anchor的概念,在Faster RCNN中,anchor的数量、长宽比以及大小都是固定了的,但是yolo没有。yolo是在训练过程中逐渐特化的。
损失函数

共有5个损失组成:
- 负责检测物体的候选框的中心点位置误差;
- 负责检测物体的候选框的宽高定位误差;
- 负责检测物体的候选框的置信度误差;(置信度的标签值是该候选框与GT的IOU)
- 不负责检测物体的候选框的置信度误差;(标签值为0,因为本来就不应该有它)
- 负责检测物体的网格的分类误差。

训练参数的设定:
- 训练135epochs
- 在开始的epochs,学习率从 1 0 − 3 10^{-3} 10−3缓慢提升到 1 0 − 2 10^{-2} 10−2;因为一开始学习率高的话会因为不稳定的梯度导致发散。
- 然后75个epochs用 1 0 − 2 10^{-2} 10−2;
- 然后30个epochs用 1 0 − 3 10^{-3} 10−3
- 最后30个epochs用 1 0 − 4 10^{-4} 10−4

为了避免过拟合,使用了dropout和很广泛的数据增强。在全连接层随机drop百分之50的神经元,然后数据会有一些缩放、调整曝光饱和度的数据增强行为。
2.3 推断预测阶段


2.3 Yolo的缺陷

- 缺陷1:每个grid cell只能预测2个bbox,且只能有一个分类,当好多个小物体都挤在一个grid cell里时,就很难都识别出来。
- 缺陷2:在新的或不寻常高宽比的图像域里,泛化能力是受限的。
- 缺陷3:这个模型是使用较粗粒度的特征,因为有较多的池化层或下采样层,所以会导致空间信息的缺失。
- 小框产生的错误会对IOU有更大的影响。主要错误来源是定位误差。


3.一些数据对比
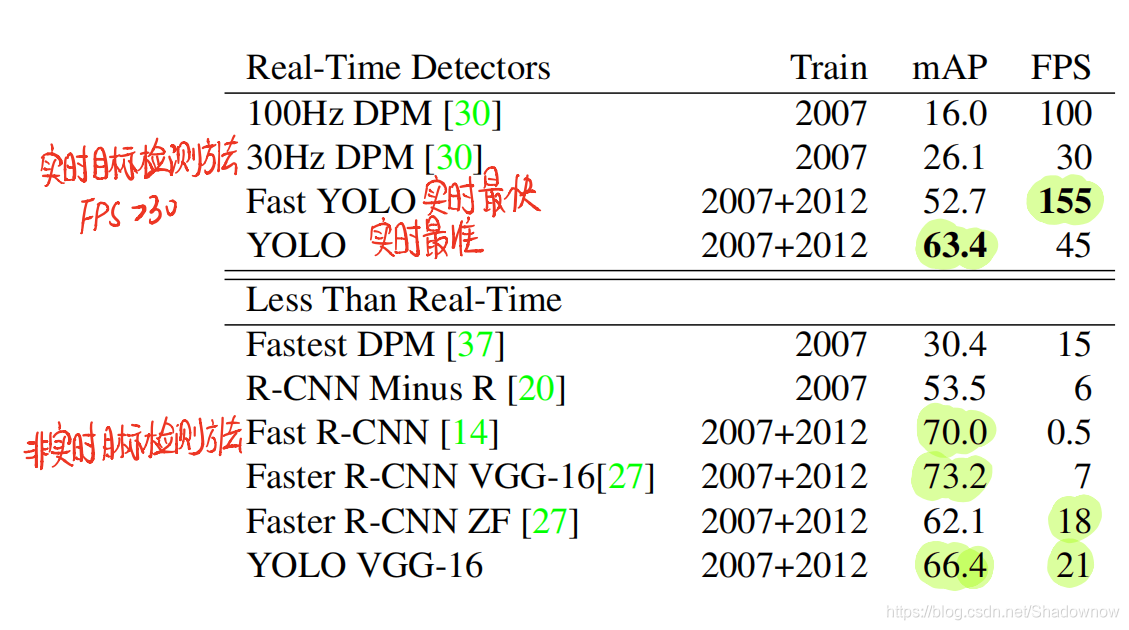
- Fast YOLO是实时最快的
- YOLO是实时最准的
- Fast(er) R-CNN准确率最高,但是没有速度较慢
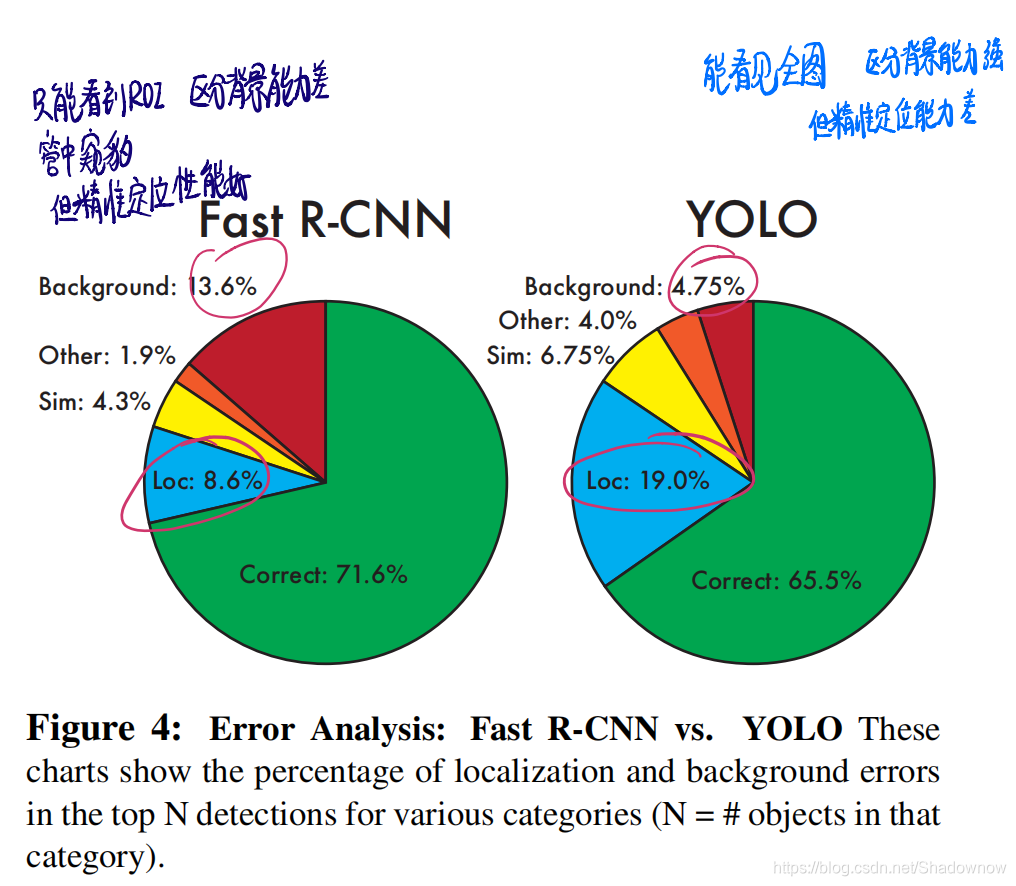
- Fast R-CNN的错误中,误把背景识别为目标物体的误差最高
- YOLO的错误中,定位误差最高
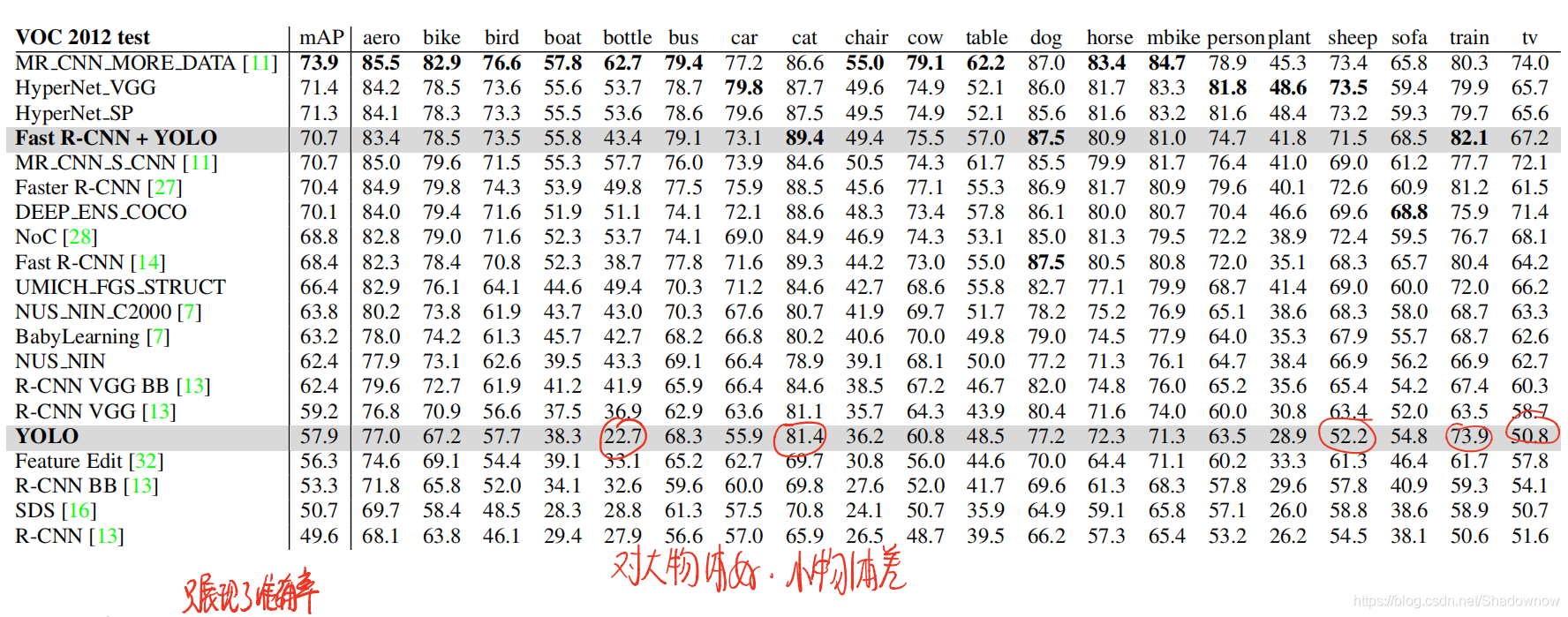
- YOLO对大物体的检测准确率更高,检测小物体的能力更差。