可以使用该种形式的Series对DataFrame进行筛选
print(df)
print(“=======================”)
print(df.loc[df[‘AAA’] > 110])
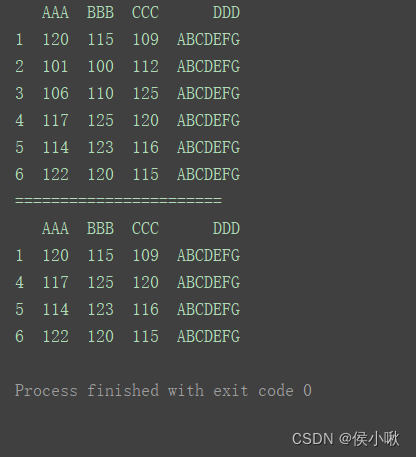
也可以传入多个条件进行筛选。每个条件需要使用括号()括起来。
以获取’AAA’大于110且’CCC’大于115的为例:
print(df)
print(“=======================”)
print(df.loc[(df[‘AAA’] > 110) & (df[‘CCC’] > 115)])
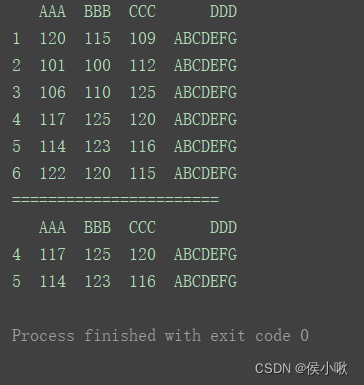
2.4.1 按列增加数据
2.4.1.1 直接添加
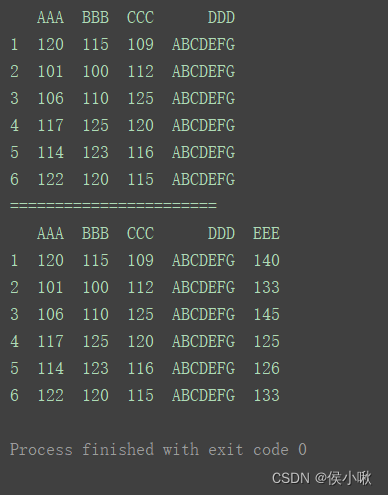
print(df)
print(“=======================”)
df[‘EEE’] = [140, 133, 145, 125, 126, 133]
print(df)
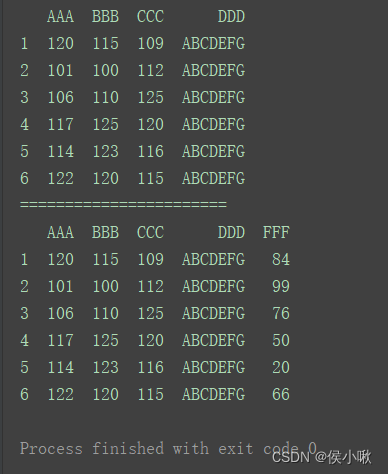
也可以使用loc添加
添加一整列时行索引必须是所有行,列索引是一个新的列名。添加的数据个数必须等于总行数。插入的数据在最后一列。
print(df)
print(“=======================”)
df.loc[:, ‘FFF’] = [84, 99, 76, 50, 20, 66]
print(df)
如果行索引是部分行,且列索引已存在于原数据中,则效果为修改局部数据。
print(df)
print(“=======================”)
df.loc[1:4, ‘CCC’] = [99, 76, 50, 20]
print(df)
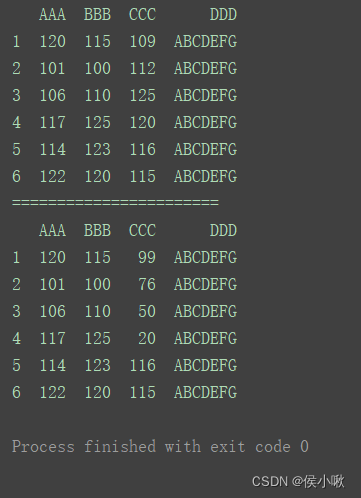
使用insert()方法添加
在第1列后添加一个名为’SSS’的列,数据为s1中的数据。
print(df)
print(“=======================”)
s1 = [99, 89, 95, 84, 110, 104]
df.insert(1, ‘SSS’, s1)
print(df)
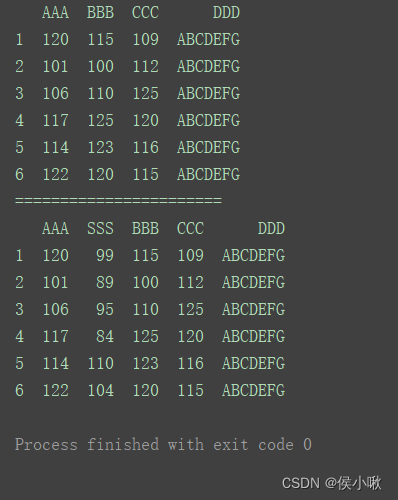
2.4.2 按行增加数据
2.4.2.1 增加一行
print(df)
print(“=======================”)
df.loc[‘100’] = [111, 132, 99, 123]
print(df)
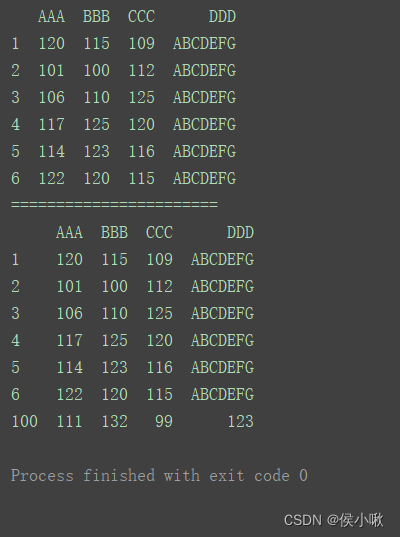
2.4.2.2 增加多行数据
将新数据创建一个格式一致的、新的DataFrame,然后使用append方法追加在原数据后边。
print(df)
print(“=======================”)
df_insert = pd.DataFrame({‘AAA’: [102, 124, 133, 120, 115, 121],
‘BBB’: [110, 125, 140, 111, 117, 126],
‘CCC’: [112, 118, 122, 114, 136, 125],
‘DDD’: ‘XYZ’}
, index=[10, 20, 30, 40, 50, 60])
df1 = df.append(df_insert)
print(df)
print(“============================”)
print(df1)
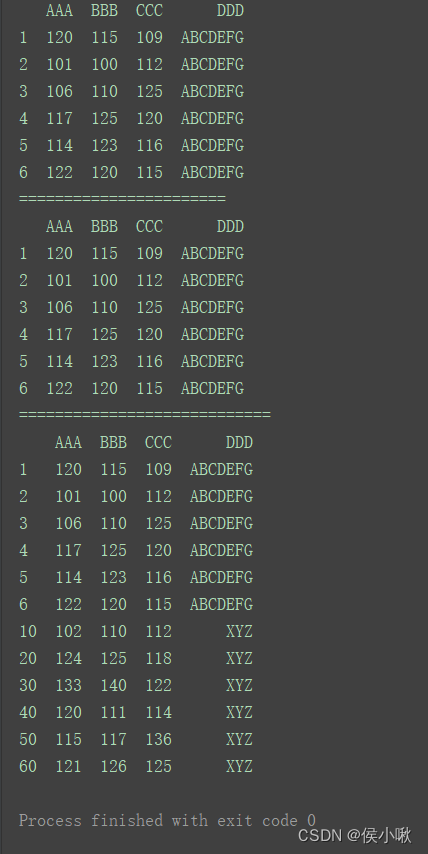
如图,使用append方法对一个DataFrame在后边追加一个DataFrame,不会改变原DataFrame,这一点不同于列表追加元素。
2.5.1修改列名
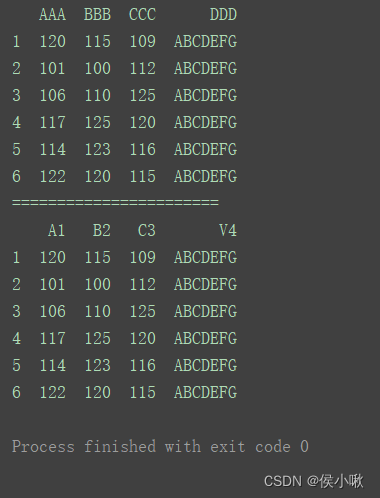
2.5.1.1 通过DataFrame的columns属性
print(df)
print(“=======================”)
df.columns = [‘A1’, ‘B2’, ‘C3’, ‘V4’]
print(df)
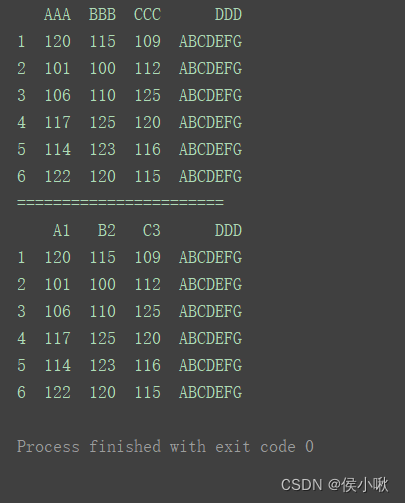
2.5.1.2 通过DataFrame的rename()方法
print(df)
print(“=======================”)
df.rename(columns={‘AAA’: ‘A1’, ‘BBB’: ‘B2’, ‘CCC’: ‘C3’}, inplace=True)
print(df)
inplace参数表示是否修改原DataFrame,默认False不修改。
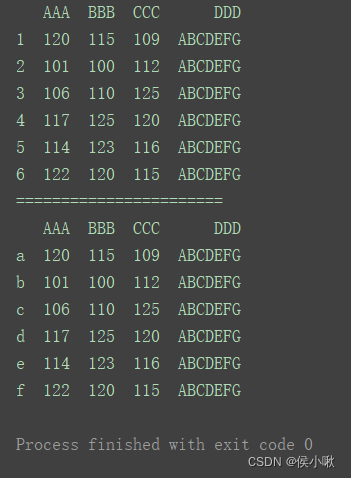
2.5.2 修改索引(index)
2.5.2.1 通过index属性
print(df)
print(“=======================”)
df.index = list(‘abcdef’)
print(df)
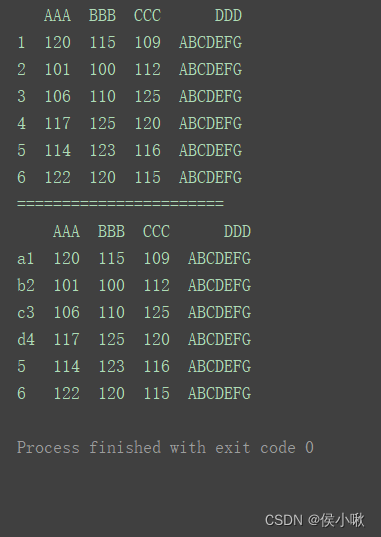
2.5.2.2通过rename方法
通过rename方法也可以实现对索引的修改。
参数axis默认为0,表示对index操作,(所以这里不设置axis也可)除非像上边的例子中传入有columns参数则表示对列操作。
print(df)
print(“=======================”)
df.rename({1: ‘a1’, 2: ‘b2’, 3: ‘c3’, 4: ‘d4’}, axis=0, inplace=True)
print(df)
2.6.1 使用loc
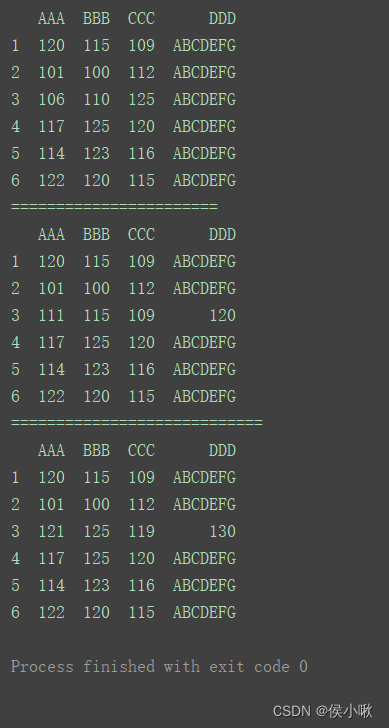
修改整行数据
print(df)
print(“=======================”)
df.loc[3] = [111, 115, 109, 120]
print(df)
print(“============================”)
df.loc[3] = df.loc[3]+10
print(df)
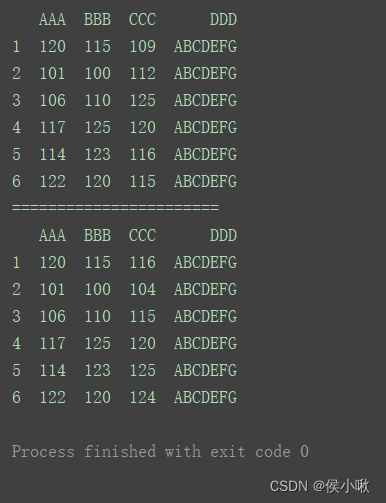
修改整列数据
print(df)
print(“=======================”)
df.loc[:, ‘CCC’] = [116, 104, 115, 120, 125, 124]
print(df)
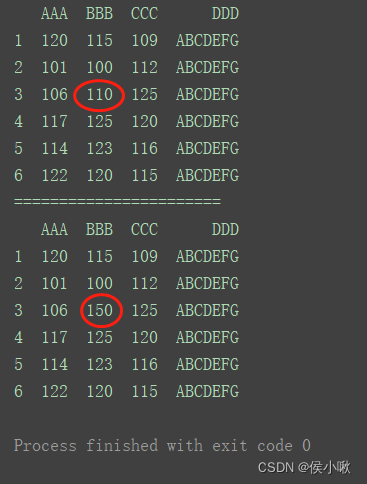
修改指定某一数据
print(df)
print(“=======================”)
df.loc[3, ‘BBB’] = 150
print(df)
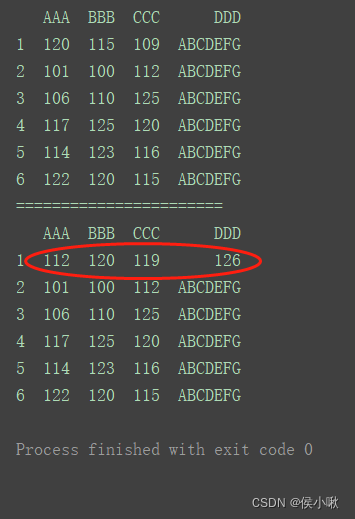
2.6.2 使用iloc
修改整行数据
print(df)
print(“=======================”)
df.iloc[0, :] = [112, 120, 119, 126]
print(df)
修改整列数据
print(df)
print(“=======================”)
df.iloc[:, 0] = [111, 118, 114, 102, 125, 130]
print(df)
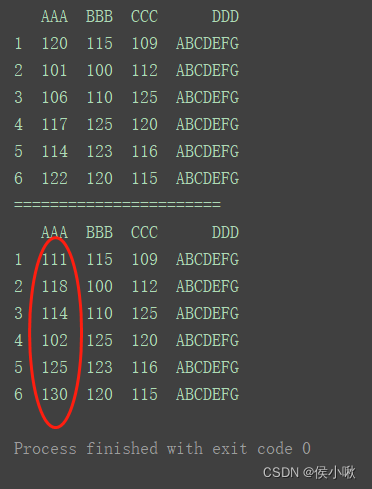
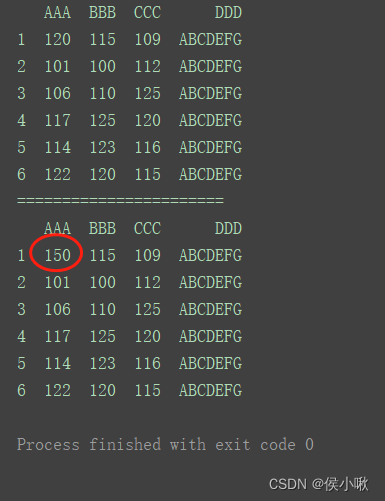
修改指定某一数据
print(df)
print(“=======================”)
df.iloc[0, 0] = 150
print(df)
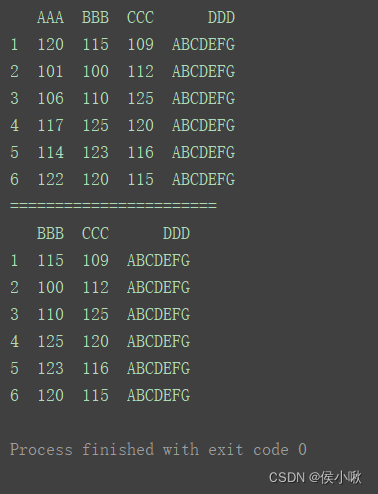
2.7.1 删除某列
print(df)
print(“=======================”)
df.drop([‘AAA’], axis=1, inplace=True)
print(df)
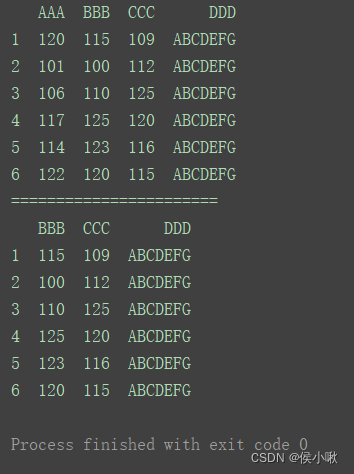
print(df)
print(“=======================”)
df.drop(columns=‘AAA’, inplace=True)
print(df)
删除标签为’BBB’的,axis=1表示对列操作
print(df)
print(“=======================”)
df.drop(labels=‘BBB’, axis=1, inplace=True)
print(df)
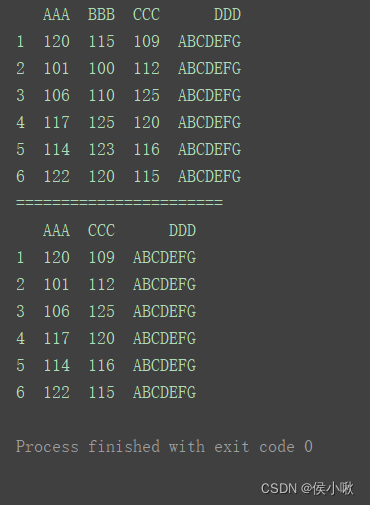
2.7.2 删除某行
删除标签为2,4的行,axis默认为0,默认对行操作。
print(df)
print(“=======================”)
df.drop([2, 4], inplace=True)
print(df)
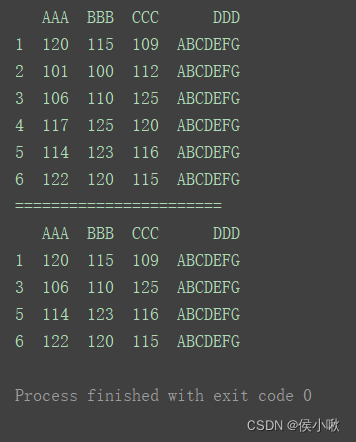
print(df)
print(“=======================”)
df.drop(index=3, inplace=True)
print(df)
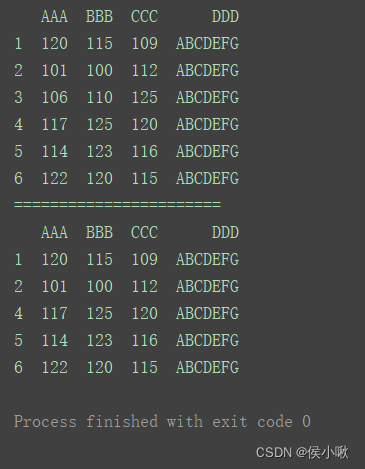
删除标签为4的,axis=0表示对行操作。
print(df)
print(“=======================”)
df.drop(labels=4, axis=0, inplace=True)
print(df)
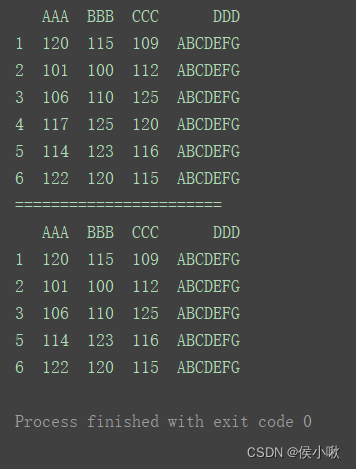
2.7.3删除特定条件的行
删除字段’AAA’为120,101或114的行。
print(df)
print(“=======================”)
df.drop(index=df[df[‘AAA’].isin([120, 101, 114])].index, inplace=True)
print(df)
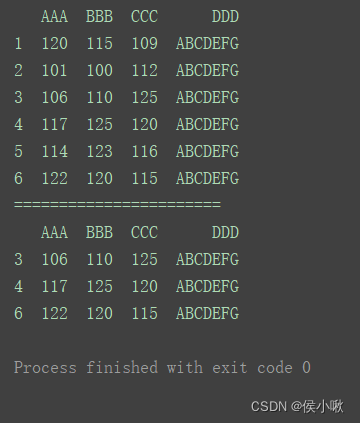
删除"BBB"字段小于120的行
print(df)
print(“=======================”)
df.drop(index=df[df[‘BBB’] < 120].index, inplace=True)
print(df)
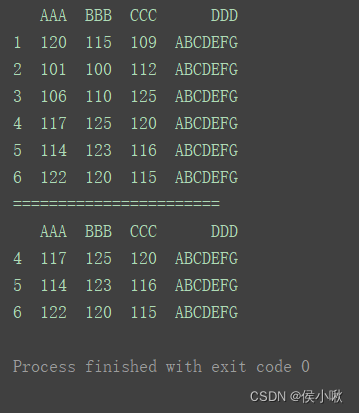
print(df)
print(“=======================”)
print(df.info())
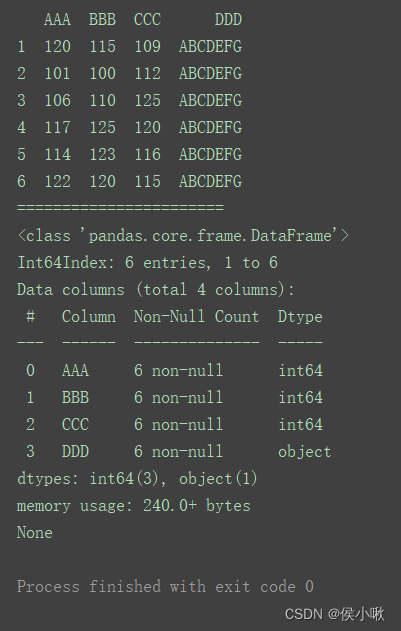
2.9.1处理缺失值
2.9.1.1 准备缺失值
准备两个缺失值
import numpy as np
df.iloc[0, 0] = np.NaN
df.iloc[2, 2] = np.NaN
print(df)
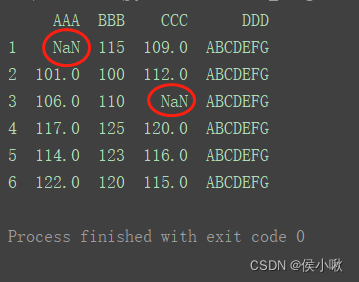
2.9.1.2 删除该缺失值所在行
print(df)
print(“====================”)
不修改原df的写法
df1 = df.dropna()
print(df1)
修改原df的写法
df.dropna(inplace=True)
print(df)
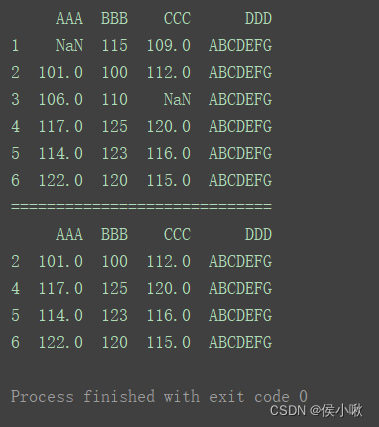
2.9.1.3获取某字段没有缺失值 的行
print(df)
print(“=============================”)
df2 = df[df[‘AAA’].notnull()]
print(df2)
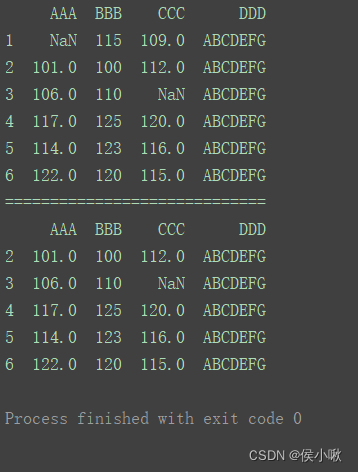
2.9.1.4 填充缺失值
以将缺失值填充为0为例
2.9.1.4.1 填充所有缺失值
print(df)
print(“=============================”)
df3 = df.fillna(0)
print(df3)
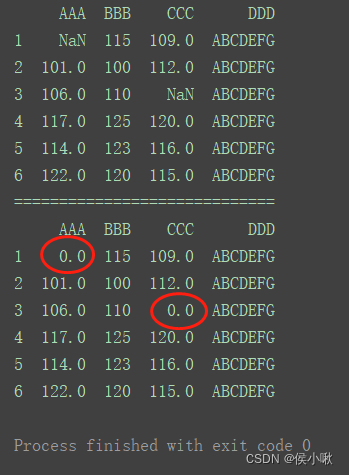
2.9.1.4.2 填充局部缺失值
print(df)
print(“=============================”)
df[‘AAA’] = df[‘AAA’].fillna(0)
print(df)
2.9.2 处理重复值
2.9.2.1准备数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 122],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
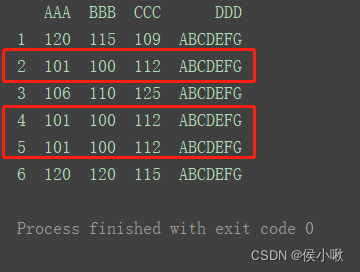
2.9.2.2 判断重复值
2.9.2.2.1 判断整行数据是否重复
将一行完全相同的判断为重复值,第一次出现的行不会被判定为重复值,第二次及以上次数重复出现的才会。
print(df)
print(“=============================”)
print(df.duplicated())
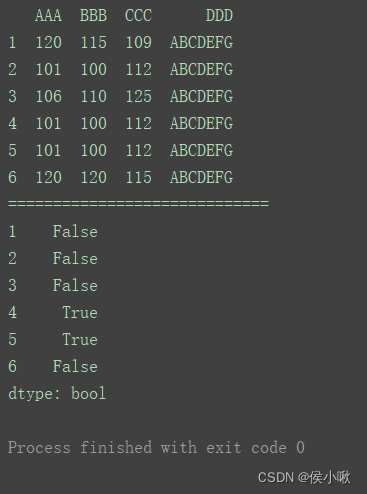
2.9.2.2.2 判断某字段数据是否重复
以字段"AAA"为例。
print(df)
print(“=============================”)
print(df[‘AAA’].duplicated())
或者
print(df.duplicated([‘AAA’]))
print(“=============================”)
print(df.loc[df[‘AAA’].duplicated()])
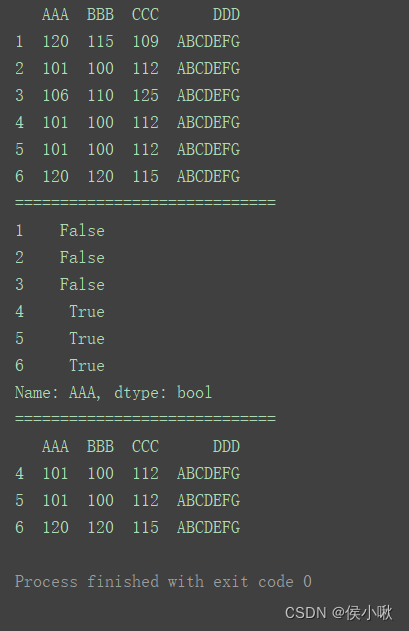
2.9.2.3 去重
2.9.2.3.1 删除整行重复值
不更改原df
print(df)
print(“=============================”)
df1 = df.drop_duplicates()
print(df1)
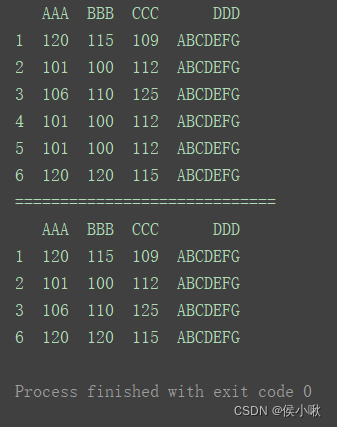
print(df)
print(“=============================”)
df.drop_duplicates(inplace=True)
print(df)
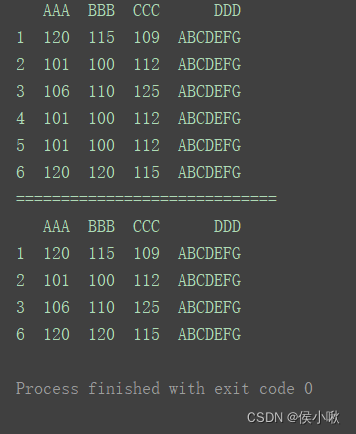
2.9.2.3.2 删除某字段重复 的行
print(df)
print(“=============================”)
print(df.drop_duplicates([‘AAA’]))
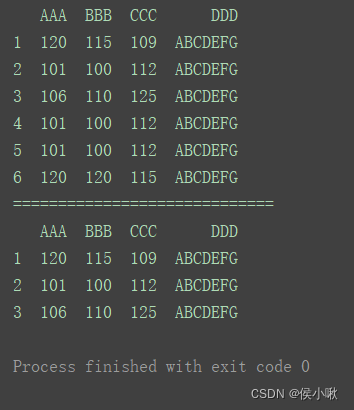
如果要保留重复行中的最后一行(默认是第一行),须将参数keep设置为’last’:
print(df)
print(“=============================”)
print(df.drop_duplicates([‘AAA’], keep=‘last’))
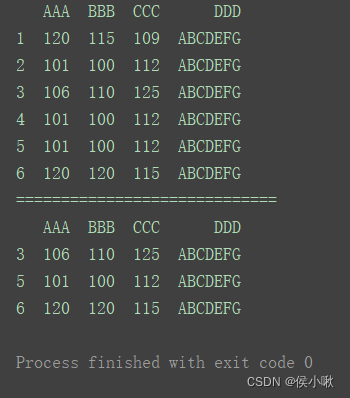
2.10.1 reindex
缺失值以0填充
from pandas import Series
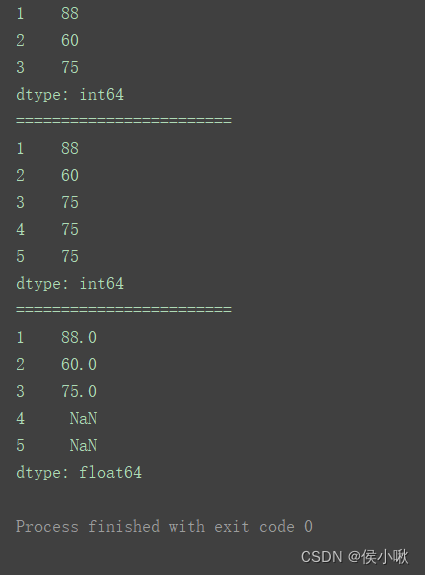
s1 = Series([88, 60, 75], index=[1, 2, 3])
print(s1)
print(“========================”)
print(s1.reindex([1, 2, 3, 4, 5]))
print(“========================”)
重新设置索引,NaN以0填充
print(s1.reindex([1, 2, 3, 4, 5],fill_value=0))
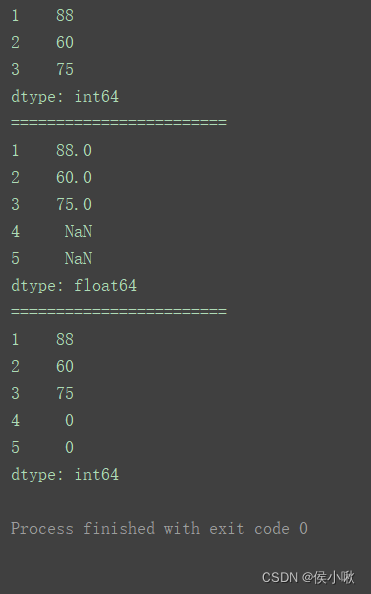
缺失值向前/向后填充
from pandas import Series
从pandas引入Series对象,就可以直接使用Series对象了,如Series([88,60,75],index=[1,2,3])
s1 = Series([88, 60, 75], index=[1, 2, 3])
print(s1)
print(“========================”)
print(s1.reindex([1, 2, 3, 4, 5], method=‘ffill’)) # 向前填充
print(“========================”)
print(s1.reindex([1, 2, 3, 4, 5], method=‘bfill’)) # 向后填充
重新设置行索引、列索引和行列索引
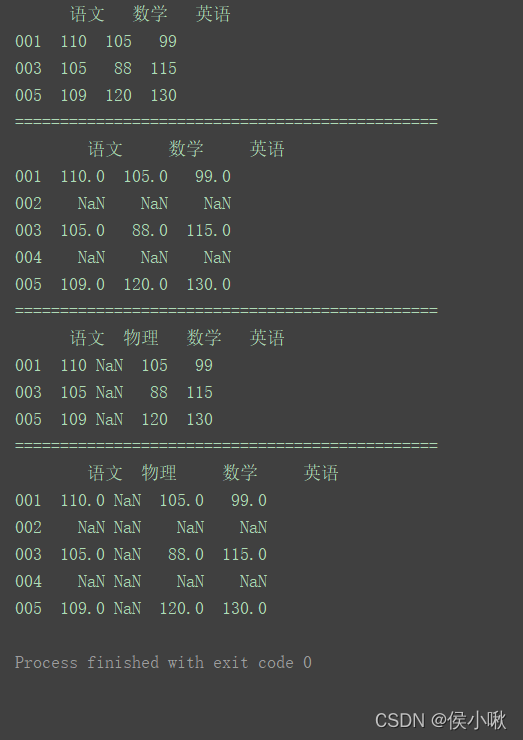
import pandas as pd
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130]]
index = [‘001’, ‘003’, ‘005’]
columns = [‘语文’, ‘数学’, ‘英语’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print(“===============================================”)
通过reindex()方法重新设置行索引、列索引和行列索引
print(df.reindex([‘001’, ‘002’, ‘003’, ‘004’, ‘005’]))
print(“===============================================”)
print(df.reindex(columns=[‘语文’, ‘物理’, ‘数学’, ‘英语’]))
print(“===============================================”)
print(df.reindex(index=[‘001’, ‘002’, ‘003’, ‘004’, ‘005’], columns=[‘语文’, ‘物理’, ‘数学’, ‘英语’]))
2.10.2 set_index
2.10.2.1 设置某列为index
设置"AAA"为index
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-8vQw7nBg-1712561676805)]
[外链图片转存中…(img-ezOSQjdb-1712561676806)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-duKIx9V8-1712561676806)]
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-r1MdQcj6-1712561676807)]