1.前期准备
(1)看看上一期的博客,最好跟着上一期的博客把sparkRDD的基本命令给熟练掌握后,再来做这篇文章的任务。
上一期的博客:sparkRDD教程之基本命令-CSDN博客
(2)新建文件task6.scala
package com.itheima
import org.apache.spark.sql.SparkSession
object task6 {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("task6")
.master("local")
.getOrCreate()
val sc = spark.sparkContext
//代码在这里写
spark.stop()
}
}

(3)在开始写代码之前先熟悉一下这2个文件
result_bigdata.txt(学号,科目为大数据,成绩),注意了这里的分隔符为"\t"
1001 大数据基础 90
1002 大数据基础 94
1003 大数据基础 100
1004 大数据基础 99
1005 大数据基础 90
1006 大数据基础 94
1007 大数据基础 100
1008 大数据基础 93
1009 大数据基础 89
1010 大数据基础 78
1011 大数据基础 91
1012 大数据基础 84
result_math.txt(学号,科目为数学,成绩),注意了这里的分隔符为"\t"
1001 应用数学 96
1002 应用数学 94
1003 应用数学 100
1004 应用数学 100
1005 应用数学 94
1006 应用数学 80
1007 应用数学 90
1008 应用数学 94
1009 应用数学 84
1010 应用数学 86
1011 应用数学 79
1012 应用数学 91
2.任务1:(十分简单)
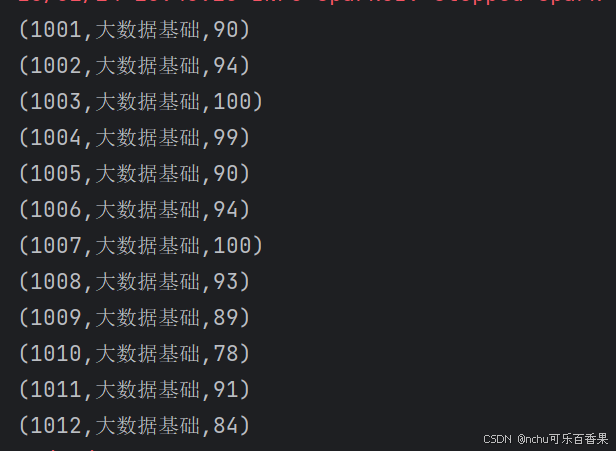
(1)取出大数据成绩排名前5的学生成绩信息并且在控制台打印出来,
代码1
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
println(math1.collect().mkString("\n"))截图1

代码2(最终代码)
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
var rdd1 = math1.sortBy(x => x._3, false)
println(rdd1.take(5).mkString("\n"))截图2
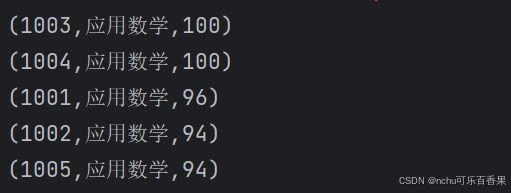
(2)取出数学成绩排名前5的学生成绩信息并且在控制台打印出来
代码1
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
println(bigdata1.collect().mkString("\n"))截图1
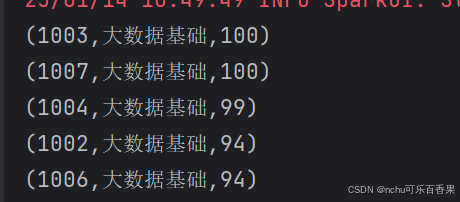
代码2(最终代码)
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
var rdd2=bigdata1.sortBy(x=>x._3,false)
println(rdd2.take(5).mkString("\n"))截图2
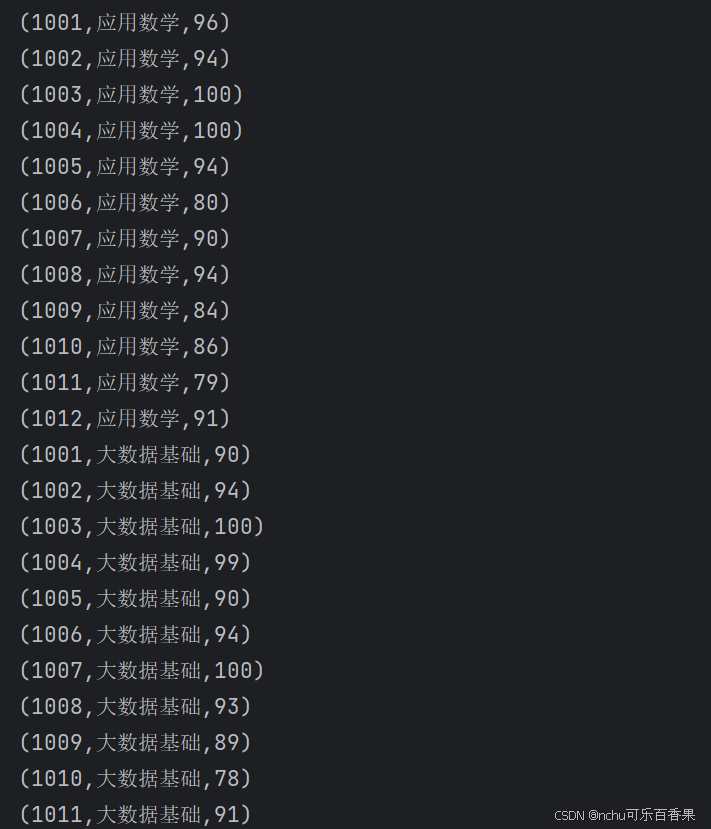
3.任务2:获取单科成绩为100的学生id
代码1
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var total1 = math1.union(bigdata1)
println(total1.collect().mkString("\n"))截图1
代码2(最终代码)
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var total1 = math1.union(bigdata1)
val scoreIs100_id=total1.filter(x=>x._3==100).map(x=>x._1).distinct()
// println(total1.collect().mkString("\n"))
println(scoreIs100_id.collect().mkString("\n"))截图2

4.任务3:
(1)求每个学生的总成绩(即大数据成绩+数学成绩)
代码1
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var math2=math1.map(x=>(x._1,x._3))
var bigdata2=bigdata1.map(x=>(x._1,x._3))
var total2=math2.union(bigdata2)
println(total2.collect().mkString("\n"))截图1
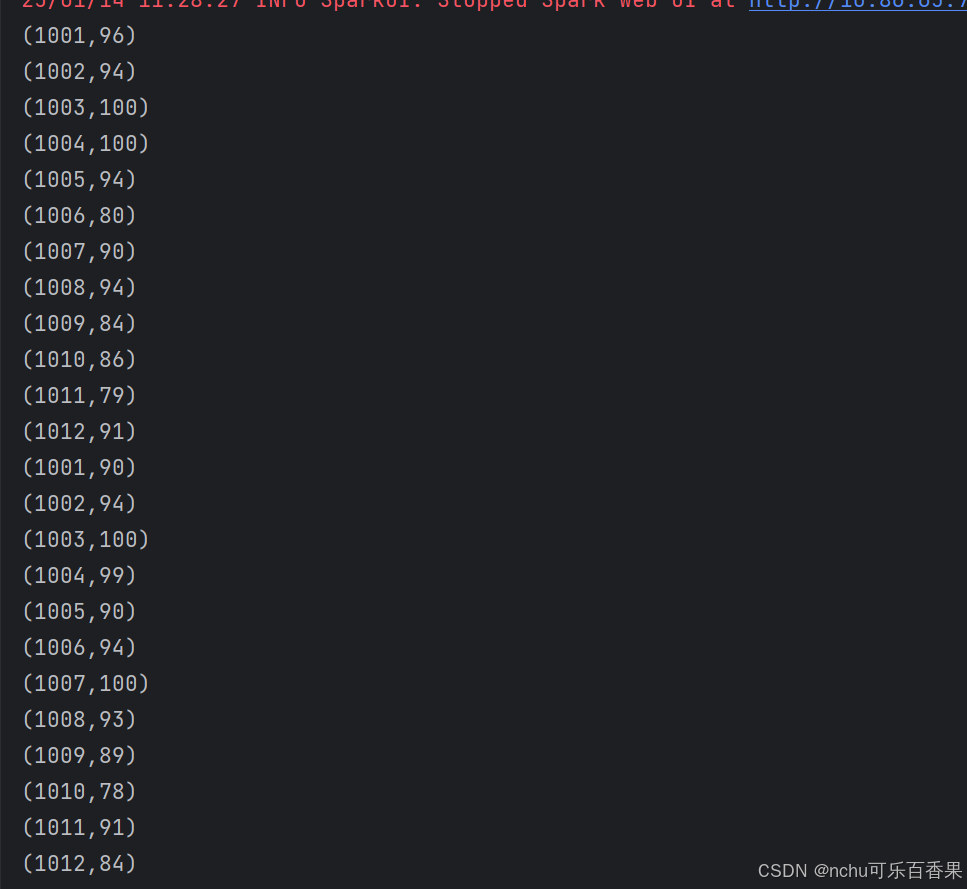
代码2
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var math2 = math1.map(x => (x._1, x._3))
var bigdata2 = bigdata1.map(x => (x._1, x._3))
var total2=math2.union(bigdata2)
var total_score=total2
.reduceByKey((y1,y2)=>(y1+y2))
println(total_score.collect().mkString("\n"))截图2
代码3(最终代码)
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var math2 = math1.map(x => (x._1, x._3))
var bigdata2 = bigdata1.map(x => (x._1, x._3))
var total2=math2.union(bigdata2)
var total_score=total2
.reduceByKey((y1,y2)=>(y1+y2))
.map(x=>(x._1,"总成绩",x._2))
.sortBy(x=>x._1)
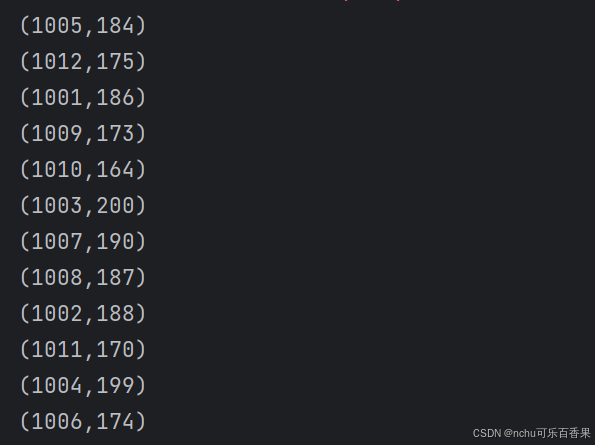
println(total_score.collect().mkString("\n"))截图3

(2)求每个学生的平均成绩(即总成绩/科目总数)
代码1
var math_path = "src\\main\\resources\\result_math.txt"
var math_data = sc.textFile(math_path)
var math1 = math_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd1 = math1.sortBy(x => x._3, false)
// println(rdd1.take(5).mkString("\n"))
var bigdata_path = "src\\main\\resources\\result_bigdata.txt"
var bigdata_data = sc.textFile(bigdata_path)
var bigdata1 = bigdata_data.map(x => x.split("\t")).map(x => (x(0), x(1), x(2).toInt))
// var rdd2=bigdata1.sortBy(x=>x._3,false)
// println(rdd2.take(5).mkString("\n"))
var total0 = math1.union(bigdata1)
//求科目总数
var subjectNum=total0.map(x=>x._2).distinct().count().toInt
var aver1_score=total0.map(x=>(x._1,x._3))
.reduceByKey((y1,y2)=>(y1+y2))
.map(x=>(x._1,"平均成绩",x._2/subjectNum))
.sortBy(x=>x._1)
println(aver1_score.collect().mkString("\n"))截图1
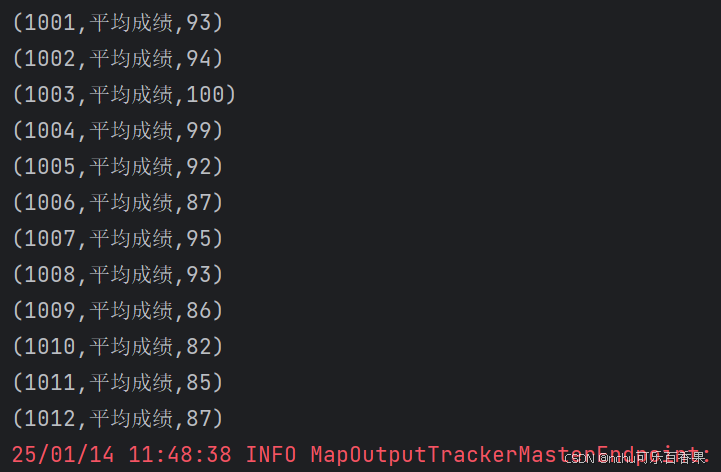
5.任务4:
(1)求全班大数据单科平均分
代码1
//求数学单科平均分
var math_stuCount = math1.count().toInt
var math_oneSubjectAver = math1.map(x => (x._2, x._3))
.reduceByKey((y1, y2) => (y1 + y2))
.map(x => ("数学单科平均分", x._2 / math_stuCount))
println(math_oneSubjectAver.collect().mkString(", "))截图1

(2)求全班数学单科平均分
代码1
//求大数据单科平均分
var bigdata_stuCount = bigdata1.count().toInt
var bigdata_oneSubjectAver = bigdata1.map(x => (x._2, x._3))
.reduceByKey((y1, y2) => (y1 + y2))
.map(x => ("大数据单科平均分", x._2 / bigdata_stuCount))
println(bigdata_oneSubjectAver.collect().mkString(","))截图1

6.其他
(1)sparkRDD是什么和sparkSQL是什么关系
在Apache Spark中,`RDD`(Resilient Distributed Dataset)和`SparkSQL`是两个不同的概念,它们分别代表了Spark中的核心数据结构和处理框架,但它们之间是有关系的。
### 1. **RDD(Resilient Distributed Dataset)**
- **定义**:RDD是Spark的核心抽象,是一个不可变的分布式数据集,支持并行处理。它是Spark计算模型的基础,所有的数据都可以通过RDD进行处理。
- **特性**:
- **弹性(Resilient)**:即使某些数据分区丢失,RDD也能够自动从其他地方恢复数据。
- **分布式(Distributed)**:RDD的元素存储在集群中的多个节点上,因此可以进行并行处理。
- **不可变(Immutable)**:RDD一旦创建,就无法更改。如果需要修改RDD的内容,必须创建一个新的RDD。
- **使用场景**:RDD通常用于处理低级的并行计算任务,它提供了丰富的操作,如`map`、`filter`、`reduce`等。
### 2. **SparkSQL**
- **定义**:SparkSQL是一个用于结构化数据查询的组件,它允许使用SQL查询、DataFrame和Dataset API对数据进行处理。SparkSQL支持从多种数据源加载数据,如Hive、Parquet、JSON等。
- **特性**:
- 支持通过SQL语法直接查询数据,使用SQL与RDD不同的高层次抽象(如DataFrame和Dataset)。
- 提供了对结构化数据的优化查询执行引擎,可以有效地优化查询计划。
- 可以通过SQL执行复杂的操作,如联接、分组、排序等。
- **使用场景**:SparkSQL适用于需要使用SQL查询的结构化数据处理场景,并且能比直接使用RDD更方便和高效地执行复杂查询。
### **RDD与SparkSQL的关系**
- **底层实现**:SparkSQL的核心实现是建立在RDD之上的。虽然用户可以使用SQL或者DataFrame API进行高层次操作,但底层的计算仍然通过RDD来实现。
- **转换关系**:
- `DataFrame`和`Dataset`(SparkSQL的两种高层次API)都是基于RDD构建的。你可以通过将RDD转换为DataFrame或Dataset来利用SparkSQL提供的优化和功能。
- 例如,`DataFrame`是一个分布式的数据集,类似于数据库中的表格,它是在RDD的基础上进一步封装的,提供了更高效的查询和处理功能。
- **性能优化**:SparkSQL通过Catalyst查询优化器对SQL查询进行优化,生成更高效的执行计划。这个优化过程是通过RDD操作的进一步封装和调整来实现的,确保SparkSQL在处理数据时尽可能高效。
### 总结
- **RDD** 是Spark的基础抽象,代表分布式、不可变的数据集。
- **SparkSQL** 是一个高层次的接口,用于进行结构化数据的查询和分析,支持SQL语法和更高级的DataFrame、Dataset API。它建立在RDD的基础上,但提供了更优化和简便的查询方式。
(2)spark-shell是什么
`spark-shell` 是 Apache Spark 提供的一个交互式命令行工具,用于与 Spark 集群进行交互并执行 Spark 作业。它提供了一个基于 Scala 的 REPL(Read-Eval-Print Loop)环境,允许用户以编程方式直接在 Spark 集群上运行代码、执行数据分析操作和调试任务。
具体来说,`spark-shell` 的功能包括:
1. **交互式编程**:通过 Scala 命令行,用户可以直接在 Spark 集群上运行代码,而无需编写完整的 Spark 应用程序。
2. **集群管理**:它自动设置 Spark 集群的连接和资源管理,帮助用户方便地运行分布式计算任务。
3. **调试和测试**:适用于开发和调试阶段,可以快速验证代码段或算法的执行结果。
4. **支持 RDD 和 DataFrame 操作**:用户可以利用 `spark-shell` 进行 Spark 核心功能的操作,如 RDD 和 DataFrame 的创建与转换。
### 使用方式
在安装了 Spark 的机器上,可以通过命令行启动 `spark-shell`:
```bash
./bin/spark-shell
```
这将启动一个 Scala REPL 环境,允许用户通过 Scala 编写并执行 Spark 代码。
### 示例
启动 `spark-shell` 后,可以执行如下操作:
```scala
val data = sc.parallelize(1 to 100)
val result = data.filter(_ % 2 == 0).collect()
println(result.mkString(", "))
```
以上代码会在 Spark 集群上并行地处理数据,筛选出偶数并返回结果。
总的来说,`spark-shell` 是一个非常有用的工具,适合用于快速原型开发、调试以及测试 Spark 程序。