Linux内核线程(kernel threads)是运行在内核空间的线程,它们不拥有独立的地址空间,因此不能访问用户空间,但可以访问内核空间的数据结构。内核线程通常用于执行一些需要并行处理的任务,例如文件系统的任务、I/O操作、定时器等。
要创建一个内核线程,你可以使用以下步骤:
-
包含必要的头文件:
linux/kthread.h:提供内核线程相关的函数。linux/sched.h:定义了task_struct结构体。
-
定义线程函数: 线程函数需要符合
int (*threadfn)(void *data)的签名。 -
创建内核线程: 使用
kthread_create函数创建一个新的内核线程。这个函数接收线程函数和传递给线程函数的数据作为参数。 -
启动线程: 使用
wake_up_process函数将新创建的线程添加到可运行队列中。 -
停止线程: 在模块退出时,使用
kthread_stop函数来停止内核线程。
下面是一个简单的内核模块示例,它创建了两个内核线程:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/kthread.h>
#include <linux/sched.h>
static int kthread_func(void *arg) {
printk(KERN_INFO "I am thread: %s[PID = %d]\n", current->comm, current->pid);
return 0;
}
static int __init init_func(void) {
struct task_struct *ts1, *ts2;
int err;
printk(KERN_INFO "Starting 2 threads\n");
ts1 = kthread_run(kthread_func, NULL, "thread-1");
if (IS_ERR(ts1)) {
printk(KERN_INFO "ERROR: Cannot create thread ts1\n");
err = PTR_ERR(ts1);
return err;
}
ts2 = kthread_run(kthread_func, NULL, "thread-2");
if (IS_ERR(ts2)) {
printk(KERN_INFO "ERROR: Cannot create thread ts2\n");
err = PTR_ERR(ts2);
return err;
}
return 0;
}
static void __exit exit_func(void) {
printk(KERN_INFO "Exiting the module\n");
}
module_init(init_func);
module_exit(exit_func);
MODULE_LICENSE("GPL");在这个例子中,kthread_func是线程函数,它打印出当前线程的信息。init_func是模块初始化函数,它创建了两个内核线程。exit_func是模块退出函数,它在模块卸载时被调用。
内核线程通常由kthreadd进程(PID为2)管理,它在系统启动时由内核创建。kthreadd负责创建和调度其他内核线程。
Process creation (kernel_clone)
-
调用
get_task_pid()分配可用的 PID- 作用: 进程 ID (PID) 是系统中唯一标识进程的编号。
get_task_pid()负责从系统中为新创建的任务(子进程)分配一个未被使用的 PID。 - 比喻: 就像在学校里,给新学生分配一个独特的学号,用来唯一标识每个学生。
- 作用: 进程 ID (PID) 是系统中唯一标识进程的编号。
-
调用
copy_process()- 作用: 这是创建新进程的核心函数。
copy_process()复制或者共享父进程的资源,比如打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间(namespace)。 - 比喻: 想象一下,一个团队的主管创建了一个副手,这个副手会共享一些资源,比如文件夹(文件系统)和工具(信号处理),但可能会有自己独立的工作区(进程地址空间)。
- 作用: 这是创建新进程的核心函数。
-
在
copy_process()中调用dup_task_struct()- 作用: 该函数会为新进程创建一个新的内核栈、
thread_info结构和task_struct结构。task_struct是一个重要的数据结构,用于表示 Linux 中的进程,包含了进程的各种状态信息。 - 比喻: 这是为新员工创建一张新的工位,包括桌子(内核栈)、档案(
thread_info)、以及工号(task_struct)。
- 作用: 该函数会为新进程创建一个新的内核栈、
-
调用
wake_up_new_task()唤醒子进程- 作用: 在创建子进程后,通过调用
wake_up_new_task()函数将子进程唤醒,并将其插入到就绪队列(running queue)中。这样,操作系统可以在合适的时机调度这个新进程执行。 - 比喻: 就像是主管将新员工带到工作现场,并告诉调度员(操作系统)可以让他开始工作。
- 作用: 在创建子进程后,通过调用
kernel_clone_args
struct kernel_clone_args {
u64 flags; // 标志位,用于指定创建线程或进程时的各种选项,如是否与父进程共享虚拟内存空间等。
int __user *pidfd; // 用户空间指针,用于接收新创建的进程或线程的文件描述符。
int __user *child_tid; // 用户空间指针,用于接收子线程的线程ID。
int __user *parent_tid; // 用户空间指针,用于接收父线程的线程ID。
int exit_signal; // 指定子进程退出时向父进程发送的信号。
unsigned long stack; // 指定新线程或进程的用户态栈的起始地址。
unsigned long stack_size; // 指定用户态栈的大小。
unsigned long tls; // 指向线程局部存储(Thread Local Storage)的指针。
pid_t *set_tid; // 指向存储线程ID的变量的指针。
size_t set_tid_size; // set_tid指向的变量的大小,通常用于数组。
int cgroup; // 控制组(cgroup)相关的字段,用于指定新进程所属的cgroup。
struct cgroup *cgrp; // 指向cgroup结构的指针。
struct css_set *cset; // 用于控制组的计数集合(css_set)的指针。
};成员解释:
-
u64 flags: 这是一个64位的标志字段,用于设置创建进程或线程时的各种属性。例如,是否与父进程共享文件描述符、信号处理等。 -
int __user *pidfd: 这是一个指向用户空间的指针,用于接收新创建的进程的文件描述符。这允许父进程通过文件描述符与子进程进行通信。 -
int __user *child_tid: 这是一个指向用户空间的指针,用于存储新创建的子线程的线程ID。 -
int __user *parent_tid: 这是一个指向用户空间的指针,用于存储父线程的线程ID。 -
int exit_signal: 指定当子进程退出时,父进程应该接收到的信号。 -
unsigned long stack: 指定新线程或进程的用户态栈的起始地址。 -
unsigned long stack_size: 指定用户态栈的大小。 -
unsigned long tls: 指向线程局部存储(Thread Local Storage, TLS)的指针,TLS是线程特有的数据区域。 -
pid_t *set_tid: 这是一个指向pid_t类型的指针,用于存储线程或进程的ID。 -
size_t set_tid_size: 指定set_tid指针指向的存储区域的大小,通常用于数组。 -
int cgroup: 控制组(cgroup)相关的字段,用于指定新进程所属的cgroup。 -
struct cgroup *cgrp: 这是一个指向cgroup结构的指针,cgroup是一种Linux内核特性,用于对进程组进行细粒度的资源管理和分配。 -
struct css_set *cset: 控制组的计数集合(css_set)的指针,用于管理进程和cgroup之间的关系。
-
u64 flags;- 作用: 用于指定创建新进程或线程时的各种选项。这个字段是一个标志位的集合,可以通过位操作设置多个不同的选项。例如,是否共享父进程的虚拟内存、文件描述符等。
- 比喻: 类似于定制一个机器的配置,你可以选择是否共享零件(虚拟内存)或是否使用相同的操作系统(文件描述符)。
-
int __user *pidfd;- 作用: 指向一个用户空间的指针,接收新创建进程的文件描述符。通过这个字段,父进程可以获取新创建进程的文件描述符,以便进一步管理。
- 比喻: 假设你是在给一个新员工分配一张工卡,这个工卡就是进程的文件描述符,方便未来查找或管理这个员工(进程)。
-
int __user *child_tid;- 作用: 用于接收子线程的线程ID。这个字段指向用户空间的一个地址,存储新创建子线程的线程ID。
- 比喻: 就像是为新员工分配了一个工号(线程ID),以后可以通过这个工号找到他们。
-
int __user *parent_tid;- 作用: 用于接收父线程的线程ID。这个字段可以让子线程知道其父线程的ID,以便在需要时进行通信或同步操作。
- 比喻: 类似于新员工记录其上级领导的工号,方便在日后需要时进行汇报或交流。
-
int exit_signal;- 作用: 指定子进程退出时需要发送给父进程的信号。通常会设置为
SIGCHLD,表示当子进程结束时通知父进程。 - 比喻: 就像是员工离职时会给上级发送一个通知,告知他们已经完成工作并且离开。
- 作用: 指定子进程退出时需要发送给父进程的信号。通常会设置为
-
unsigned long stack;- 作用: 指定新创建的线程或进程的栈地址。栈是存储临时数据(如局部变量、函数调用)的地方。
- 比喻: 这就像是给新员工分配了一个办公桌,方便他们在工作过程中临时存放文件和物品。
-
unsigned long stack_size;- 作用: 定义栈的大小,决定了新线程或进程在用户空间中能使用的栈空间的大小。
- 比喻: 类似于你给新员工安排了一个大还是小的办公桌,影响他们可以处理多少工作。
-
unsigned long tls;- 作用: 线程局部存储(TLS)的指针。TLS 是为每个线程提供的独立存储空间,线程之间互不干扰。
- 比喻: 就像每个员工有自己的专用柜子,放入个人的资料(线程局部变量),别人无法访问。
-
pid_t *set_tid;- 作用: 指向存储线程ID的变量的指针。通过这个字段,可以存储新创建线程或进程的ID。
- 比喻: 这就像是安排某人去记录每个新员工的工号,以便日后查找。
-
size_t set_tid_size;
- 作用: 这个字段表示
set_tid数组的大小,通常用于存储多个线程的ID。 - 比喻: 就像是给了多个新员工一个工号列表,每个员工都有自己的工号。
int cgroup;
- 作用: 控制组(cgroup)相关的字段,用于限制新创建的进程使用系统资源(如CPU、内存)。
- 比喻: 就像是为新员工设置了公司规则,规定他们每天可以用多少资源(CPU时间、内存等)。
struct cgroup *cgrp;
- 作用: 指向控制组结构的指针,用于指定新进程所属的具体控制组。
- 比喻: 类似于把新员工分配到具体的部门,每个部门有不同的资源和规则。
struct css_set *cset;
- 作用: 指向控制组的计数集合。每个进程都隶属于一个或多个控制组,
css_set用于管理这些关系。 - 比喻: 就像公司规定了哪些员工属于哪个部门,并且管理部门之间的关系和资源分配。
流程说明:
-
传递参数: 当创建新线程或进程时,系统会通过这个结构体接收相关参数,包括栈地址、线程ID、控制组等。
-
线程/进程创建: 操作系统内核根据这些参数创建新的进程或线程,分配资源并建立父子进程的关系。
-
资源限制与信号处理: 创建的新线程或进程可能会受到
cgroup的资源限制,并在退出时根据exit_signal向父进程发送信号。
Its implementation is defined in ‘/kernel/fork.c’: Call get_task_pid() to assign an available PID to the new task. Call copy_process() then either duplicates or shares open files, file system information, signal handlers, process address space, and namespace. In copy_process, it calls dup_task_struct(), which creates a new kernel stack, thread_info structure, and task_struct for the new process. wake_up_new_task() to wake up the child process and insert the child process to the running queue. For more details https://elixir.bootlin.com/linux/v5.10/source/kernel/fork.c#L2415 You should check basing on your own version
-
kernel_clone是 Linux 内核中用于创建新进程或线程的系统调用的底层函数,而kernel_clone_args是其参数结构体,用于传递所有与进程/线程创建相关的选项和配置。二者的关系:
kernel_clone():- 这是 Linux 内核中实际创建新进程或线程的函数。它负责基于传入的参数配置新进程的各种属性。
- 在这个函数中,操作系统会调用一系列函数(例如
get_task_pid()、copy_process()等),以完成进程/线程的创建、资源分配和启动。
kernel_clone_args:- 这是一个结构体,包含了传递给
kernel_clone()的各种参数。它定义了与新进程/线程的创建相关的配置选项,如标志位、线程ID、退出信号、栈地址、控制组等。 kernel_clone_args将这些配置选项打包成一个结构体,便于传递和管理。
- 这是一个结构体,包含了传递给
比喻:
可以将 kernel_clone() 想象成一个“工厂机器”,专门负责根据给定的配置生产新进程,而 kernel_clone_args 是这台机器所接收的“生产订单”,详细列出了新进程的规格、资源需求和行为设置。
内核线程的创建与返回值
在内核中,创建内核线程通常使用的是 kernel_thread() 或者 kthread_create()。这些函数的行为类似于 fork(),但主要用于创建仅在内核中运行的线程,而不是用户态进程。它们的返回值含义如下:
-
成功创建内核线程:
- 返回值:新内核线程的 PID(进程 ID)
- 与用户态进程类似,成功创建一个内核线程时,
kernel_thread()或kthread_create()函数会返回新线程的 PID。这个 PID 可以用于管理新线程,例如通过wake_up_process()来唤醒它。
- 与用户态进程类似,成功创建一个内核线程时,
- 比喻: 在内核中创建线程类似于内核本身为自己增添助手,这些助手在同一个共享空间工作,不需要单独的工作场所(独立的虚拟内存空间)。
- 返回值:新内核线程的 PID(进程 ID)
-
创建失败:
- 返回值:负值(通常是
-ENOMEM或-EAGAIN)- 如果创建线程失败,函数会返回一个负数,表示错误码。例如:
-ENOMEM:表示内存不足,无法分配新的线程。-EAGAIN:表示系统已经达到最大线程数,无法再创建新的线程。
- 如果创建线程失败,函数会返回一个负数,表示错误码。例如:
- 比喻: 内核试图为自己创建新助手时,如果系统资源不足或者已经有足够多的助手,创建操作将失败,并返回相应的错误码。
- 返回值:负值(通常是
内核线程的创建流程:
-
调用
kthread_create()或kernel_thread()- 这两个函数是用于创建内核线程的主要接口。
- 它们接收一个函数指针作为参数,新线程创建后会执行这个函数。
-
分配 PID 和初始化
task_struct- 内核会为新线程分配一个唯一的 PID,并为其创建相应的
task_struct,这个结构体保存了线程的状态、资源等信息。 - 注意: 与用户态进程不同,内核线程不会创建新的虚拟内存空间,而是共享内核的地址空间。
- 内核会为新线程分配一个唯一的 PID,并为其创建相应的
-
将内核线程添加到就绪队列
- 创建完毕后,内核线程会被添加到调度器的就绪队列中,等待被调度执行。
-
唤醒线程
- 通常需要通过
wake_up_process()来唤醒新创建的内核线程,使其开始执行预定义的函数。#include <linux/kthread.h> // 包含内核线程相关的函数 #include <linux/sched.h> // 包含调度器相关的定义 #include <linux/delay.h> // 包含延迟函数 // 线程函数,内核线程执行的内容 int thread_function(void *data) { while (!kthread_should_stop()) { pr_info("Kernel thread running\n"); ssleep(5); // 线程休眠 5 秒 } return 0; } static int __init my_module_init(void) { struct task_struct *task; // 用于存储内核线程的信息 // 创建内核线程 task = kthread_create(thread_function, NULL, "my_kthread"); if (IS_ERR(task)) { // 检查是否创建成功 pr_err("Failed to create kernel thread\n"); return PTR_ERR(task); } // 唤醒内核线程 wake_up_process(task); pr_info("Kernel thread created successfully\n"); return 0; } static void __exit my_module_exit(void) { pr_info("Module exiting\n"); } module_init(my_module_init); module_exit(my_module_exit); MODULE_LICENSE("GPL");kthread_should_stop()是用于检查内核线程是否被请求停止的函数。这个函数返回一个布尔值,用于告诉内核线程是否应该退出执行。通常,它与kthread_stop()函数配合使用,当调用kthread_stop()时,kthread_should_stop()会返回true,从而让内核线程自行结束执行。kthread_should_stop()的工作原理: -
创建线程时的状态设置:
- 当你使用
kthread_create()或kthread_run()创建一个内核线程时,内核会为这个线程创建一个task_struct结构体,其中包含该线程的状态信息。 - 其中有一个标志位
task->kthread_flags,这个标志位用于管理内核线程的状态,比如是否应该停止等。
- 当你使用
-
kthread_should_stop()函数的实现:kthread_should_stop()函数实际上是检查线程的状态标志位task_struct->kthread_flags,判断其中是否设置了KTHREAD_SHOULD_STOP标志。- 该标志位是在调用
kthread_stop()函数时被设置的,表明线程应该停止运行。
-
kthread_stop()触发的机制:- 当需要停止内核线程时,通常会调用
kthread_stop()函数。这个函数会设置当前线程的kthread_flags中的KTHREAD_SHOULD_STOP标志,并唤醒线程(如果线程处于睡眠状态),从而使kthread_should_stop()在下一次被调用时返回true,通知线程该退出了。 - 线程一旦检测到
kthread_should_stop()返回true,就可以自行退出执行。
- 当需要停止内核线程时,通常会调用
- 通常需要通过
Program execution (do_execve)
在 Linux 内核中,执行一个程序的具体过程是通过 do_execve() 完成的,它实现了程序从用户空间的执行请求到最终加载和运行二进制文件的完整过程。该过程涉及多个步骤和数据结构,如 struct linux_binprm,prepare_bprm_creds() 等函数。
程序执行流程 (do_execve)
1. struct linux_binprm:
- 定义:
struct linux_binprm是一个结构体,用于存储在加载二进制文件时的参数信息,定义在include/linux/binfmts.h。 - 作用: 它存储了执行程序所需的所有关键信息,比如命令行参数、文件描述符、程序路径、权限信息等。
struct linux_binprm { char buf[BINPRM_BUF_SIZE]; // 缓冲区,用于存储二进制文件的前128字节。 struct mm_struct *mm; // 内存管理结构,用于描述虚拟内存布局。 struct file *file; // 要执行的程序的文件指针。 int argc, envc; // 参数和环境变量的数量。 char * filename; // 可执行文件的名称。 unsigned long p; // 参数指针。 // 其他相关的字段... };
2. 初始化 struct linux_binprm:
- 使用
prepare_bprm_creds()函数来初始化该结构体的权限字段,如 UID、GID 和其他与安全相关的字段。 prepare_bprm_creds()主要用来设置当前任务的安全凭证。
3. 打开程序文件并分配 struct linux_binprm 的字段:
- 使用
do_filp_open()打开程序文件,并将相应的文件描述符分配给struct linux_binprm的file字段。 - 在此阶段,还要为该结构体分配命令行参数和环境变量的相关值。
bprm->file = do_filp_open(file_path, O_RDONLY, 0); // 打开要执行的二进制文件 bprm->filename = filename; // 将程序的文件名赋值给 struct linux_binprm
4. 准备执行二进制文件:
- 调用
bprm_mm_init()函数来初始化与该进程相关的内存管理结构mm_struct,这将为新进程的地址空间做准备。 prepare_binprm()函数则用来准备与二进制文件执行相关的其他资源,包括读取文件内容,将数据复制到buf字段等。
5. 读取文件内容并将相关信息复制到 linux_binprm 结构体:
- 程序文件的内容会被读取到
struct linux_binprm中的缓冲区buf中,存储执行程序所需的前128个字节。 - 这一步通过
kernel_read()函数完成,它将二进制文件的内容复制到buf中。
6. 执行二进制文件:
search_binary_handler()函数会根据linux_binprm的内容搜索合适的二进制处理程序,并实际执行该二进制文件。- 内核有一组二进制格式处理程序(如 ELF、脚本等),会根据文件内容(例如 ELF 文件头的魔数)选择合适的处理器来加载和运行程序。
7. 完成 execve 调用后的处理:
- 在成功执行二进制文件后,内核会调用
acct_update_integrals()来更新进程的统计信息,如 CPU 使用时间、内存使用情况等。 - 调用
free_bprm()释放与二进制文件执行相关的资源,避免内存泄漏。
do_execve() 是 Linux 内核中的一个函数,用于执行可执行文件。它实现了 execve() 系统调用的核心逻辑,负责加载和执行用户空间的二进制程序,并替换当前进程的内存映像。以下是该函数的详细解释,包括参数说明、返回值和执行流程。
do_execve() 函数签名与参数:
int do_execve(struct filename *filename, const char __user *const __user *argv, const char __user *const __user *envp);
参数说明:
-
filename:- 类型:
struct filename * - 说明: 这是要执行的二进制文件的文件名,表示可执行文件的路径。
- 比喻: 就像你指明了一个程序的路径(如
/bin/bash),该路径指向需要执行的二进制文件。
- 类型:
-
argv:- 类型:
const char __user *const __user * - 说明: 这是一个字符串数组,包含传递给可执行文件的命令行参数。它的格式与用户态中的
argv[]类似,通常第一个参数是可执行文件的名字。 - 比喻: 类似于启动程序时输入的命令行参数(如
bash -c "echo Hello",这里的-c "echo Hello"就是命令行参数)。
- 类型:
-
envp:- 类型:
const char __user *const __user * - 说明: 这是一个字符串数组,包含环境变量(如
PATH、HOME等)信息,它们将在程序执行时提供系统环境。 - 比喻: 类似于启动程序时附带的系统环境信息(如
PATH=/usr/bin:/bin)。
- 类型:
返回值说明:
-
执行成功时:
- 返回值:
0 - 说明: 当
do_execve()成功执行并替换当前进程的内存空间为指定的二进制文件时,它会返回0。这意味着程序已经成功加载并准备执行。
- 返回值:
-
执行失败时:
- 返回值: 负值(错误代码)
- 说明: 如果加载可执行文件或执行过程中遇到错误,
do_execve()会返回一个负数,表示出错,并会设置对应的errno变量来描述具体的错误原因。可能的错误包括文件未找到、权限不足、内存不足等。
do_execve() 执行流程:
-
打开可执行文件:
- 首先,
do_execve()会根据传入的filename打开指定的二进制文件。内核会确保该文件存在且当前进程有权限执行它。 - 如果文件无法打开,则返回错误(如
ENOENT,文件未找到)。
- 首先,
-
解析命令行参数和环境变量:
argv和envp被解析并传递给执行的二进制文件,内核会检查它们的合法性,并在合适的位置将它们存储。
-
检查权限和安全性:
- 内核会检查执行文件的权限(如文件是否可执行、是否符合当前进程的用户权限),并执行与安全相关的检查。
-
加载二进制文件:
- 内核会根据二进制文件的格式(如 ELF 文件格式)调用相应的二进制加载器(如
search_binary_handler())来加载可执行文件的代码和数据段到内存中。 - 同时,旧的进程地址空间将被替换。
- 内核会根据二进制文件的格式(如 ELF 文件格式)调用相应的二进制加载器(如
-
设置程序的初始状态:
- 内核为新进程初始化堆栈和寄存器,并设置命令行参数和环境变量在新进程的内存中。
- 在此步骤,新的程序就像刚刚开始运行的进程那样,准备执行。
-
启动新程序:
- 在所有准备工作完成后,
do_execve()将控制权交给新加载的程序,它会开始从程序入口点执行。 - 注意: 旧进程的内存空间被新程序覆盖,旧进程不会继续执行。
- 在所有准备工作完成后,
-
返回成功或错误:
- 如果所有步骤都成功完成,
do_execve()返回0。 - 如果在任何步骤中出现错误,例如权限问题、内存不足、文件格式不支持等,
do_execve()返回负值,并设置错误码。
- 如果所有步骤都成功完成,
示例:
假设用户通过系统调用执行以下命令:
execve("/bin/ls", ["/bin/ls", "-l"], ["PATH=/usr/bin:/bin", "HOME=/home/user"])
内核将执行以下操作:
filename:/bin/ls指定要执行的二进制文件。argv:["/bin/ls", "-l"]是传递给程序的参数。envp:["PATH=/usr/bin:/bin", "HOME=/home/user"]是执行程序时的环境变量。- 内核: 打开
/bin/ls文件,检查权限,加载二进制文件并传递参数和环境变量。 - 新程序: 成功执行后,开始运行
ls -l命令。
do_wait() 是一个内核模式下的系统调用,它负责实现进程的等待机制,尤其是父进程等待子进程终止的情况。这个机制是通过 wait() 系列系统调用(例如 waitpid() 或 wait())实现的。在 do_wait() 函数的执行过程中,涉及到进程状态的管理、等待队列的操作以及子进程终止后通知父进程等一系列操作。
以下是详细的执行流程和关键点的解释。
执行流程 (do_wait)
1. 创建 wait_opts 结构体
wait_opts是一个用于保存等待选项的结构体,它包含了父进程希望从子进程获取的信息(例如子进程的 PID、退出状态等)。wait_opts结构体被传递给等待队列,并用于管理等待的状态和结果。struct wait_opts { int wo_flags; // 等待标志,例如 WNOHANG,表示是否阻塞等待。 struct pid *wo_pid; // 等待的子进程的 PID。 int wo_stat; // 存储子进程的退出状态。 struct rusage *wo_rusage; // 子进程的资源使用信息。 struct task_struct **wo_task; // 指向等待的任务(父进程)。 };
- 通过创建
wait_opts,系统准备好收集子进程终止时所需要的信息。
2. 将 wait_opts 添加到等待队列中
- 调用
add_wait_queue()函数将wait_opts结构体添加到等待队列(wait queue)中。等待队列是用于管理进程睡眠和唤醒机制的数据结构。 - 父进程会在这里进入等待状态,直到子进程终止或者满足其他条件时被唤醒。
add_wait_queue(¤t->signal->wait_chldexit, &wait);
- 比喻: 类似于父进程将自己放入一个等待名单中,等待子进程完成它的任务。
3. 更新父进程的状态
- 使用
set_current_state()更新父进程的状态为TASK_INTERRUPTIBLE或TASK_RUNNING。TASK_INTERRUPTIBLE:表示进程处于可以被信号打断的睡眠状态。TASK_RUNNING:表示进程处于就绪状态,可以被调度执行。
- 当父进程进入
TASK_INTERRUPTIBLE状态时,它会等待子进程的终止信号。当子进程终止时,父进程会被唤醒。set_current_state(TASK_INTERRUPTIBLE);比喻: 父进程类似于一个父母,告诉操作系统自己正在等待,并且随时可以被唤醒来处理子进程的退出状态。
4. 子进程终止时唤醒父进程
- 当子进程终止时,系统会调用
wake_up_parent()来唤醒父进程。 - 该函数会遍历等待队列并唤醒在该队列中等待的父进程。
- 唤醒后,父进程会开始重复扫描等待队列,以检查子进程的退出状态。
wake_up_parent(p);比喻: 就像子进程完成了任务(或者退出),会通知父进程“我已经结束了”,父进程可以继续扫描来获取子进程的退出状态。
5. 重复扫描等待队列
-
在子进程终止时,父进程被唤醒并开始重复扫描等待队列,以检查子进程的退出状态。
-
如果满足条件,父进程会读取子进程的退出状态并处理它,例如将退出码返回给调用的用户进程。
-
比喻: 父进程在被唤醒后,反复查看等待队列,确保所有子进程的状态都得到处理。
6. 清理等待队列
- 当子进程的退出状态被父进程成功获取后,等待队列中的条目会被移除,父进程恢复正常的执行。
remove_wait_queue(¤t->signal->wait_chldexit, &wait);
do_wait() 是 Linux 内核中实现进程等待的函数,特别是父进程等待子进程结束的核心功能。它通过 struct wait_opts 结构体传递各种参数,以控制等待选项、指定等待的进程以及获取子进程的退出状态、资源使用信息等。
函数签名和结构体定义:
do_wait()的作用是等待一个或多个子进程结束,然后将子进程的状态信息返回给父进程。
struct wait_opts 结构体解释:
struct wait_opts 是用来存储父进程等待子进程终止时的选项和返回结果的。下面详细解释每个字段:
struct wait_opts {
enum pid_type wo_type; // 表示进程标识符的类型 (如 PIDTYPE_PID, PIDTYPE_PGID)
int wo_flags; // 等待选项 (如 WNOHANG, WEXITED 等)
struct pid *wo_pid; // 内核中的进程标识符结构
struct siginfo __user *wo_info; // 信号信息 (包括终止信号的信息)
int __user *wo_stat; // 子进程的终止状态 (退出码)
struct rusage __user *wo_rusage; // 子进程资源使用信息 (如 CPU、内存使用情况)
wait_queue_entry_t child_wait; // 任务等待队列
int notask_error; // 错误码,当没有等待任务时的错误状态
};
字段详细解释:
-
enum pid_type wo_type:- 定义位置:
/include/linux/pid.h - 作用: 指定要等待的进程类型。
pid_type是一个枚举值,用于表示内核中的进程标识符的类型。常见的类型包括:PIDTYPE_PID:指定等待的是一个具体的进程 ID。PIDTYPE_PGID:等待某个进程组。PIDTYPE_SID:等待某个会话。
- 比喻: 这是告诉系统你想要等待哪一类的进程(一个进程,还是一组进程)。
- 定义位置:
-
int wo_flags:- 作用: 用于控制
do_wait()的行为。常见的标志包括:WNOHANG:非阻塞等待,如果没有子进程终止,立即返回。WEXITED:等待子进程正常退出。WUNTRACED:等待已停止的子进程。
- 比喻: 就像你告诉系统是否要“挂起”父进程等待子进程,还是允许继续执行。
- 作用: 用于控制
-
struct pid *wo_pid:- 作用: 内核对进程标识符的内部表示。通过这个字段,父进程可以指定要等待的子进程或进程组。
- 如何获取: 使用
find_get_pid()函数从 PID 获取对应的struct pid结构体。 - 比喻: 就像是你手中的“任务单”,用于明确表示你要等待的子进程。
-
struct siginfo __user *wo_info:- 作用: 保存子进程终止时的信号信息,例如子进程是因为信号被终止还是因为正常退出。
- 比喻: 这是为父进程提供子进程的“死亡原因报告”,说明子进程是正常退出还是被信号杀死。
-
int __user *wo_stat:- 作用: 保存子进程的退出状态,通常用来返回给父进程
waitpid()的返回值。 - 比喻: 这是子进程的“退出码”,用来告诉父进程子进程是如何终止的。
- 作用: 保存子进程的退出状态,通常用来返回给父进程
-
struct rusage __user *wo_rusage:- 作用: 记录子进程的资源使用情况,例如 CPU 时间、内存使用等。
- 比喻: 这是子进程的“使用资源统计表”,详细描述了子进程在运行期间消耗的系统资源。
-
wait_queue_entry_t child_wait:- 作用: 用于实现父进程的等待机制。
child_wait是一个等待队列的条目,父进程可以在该队列中等待,直到子进程终止。 - 比喻: 就像一个“等待通知系统”,父进程在此处排队,直到子进程完成时收到通知。
- 作用: 用于实现父进程的等待机制。
-
int notask_error:- 作用: 当没有等待的任务时,保存错误状态。常见的错误情况包括没有匹配的子进程。
- 比喻: 这是父进程收到的错误信息,告知它没有子进程可以等待或者子进程已经结束。
do_wait() 的执行流程:
-
初始化
wait_opts结构体:- 系统调用进入内核态后,首先初始化
wait_opts结构体,设置wo_pid来指定等待的子进程或进程组。
- 系统调用进入内核态后,首先初始化
-
添加到等待队列:
- 将
wait_opts添加到等待队列中,父进程进入睡眠状态,等待子进程终止。如果设置了WNOHANG标志,则不会进入睡眠,而是立即返回。
- 将
-
等待子进程终止:
- 当子进程终止时,系统会通过
wake_up_parent()将父进程从等待队列中唤醒,并更新wait_opts中的状态信息,包括子进程的退出码、资源使用情况和终止原因。
- 当子进程终止时,系统会通过
-
返回状态信息:
- 如果子进程终止,
do_wait()会通过wo_stat将子进程的退出状态返回给父进程,并将信号信息和资源使用情况写入wo_info和wo_rusage中。
- 如果子进程终止,
-
错误处理:
- 如果父进程没有找到可以等待的子进程,或者子进程已经结束,
do_wait()会设置notask_error并返回错误码,表示没有可等待的子进程。
- 如果父进程没有找到可以等待的子进程,或者子进程已经结束,
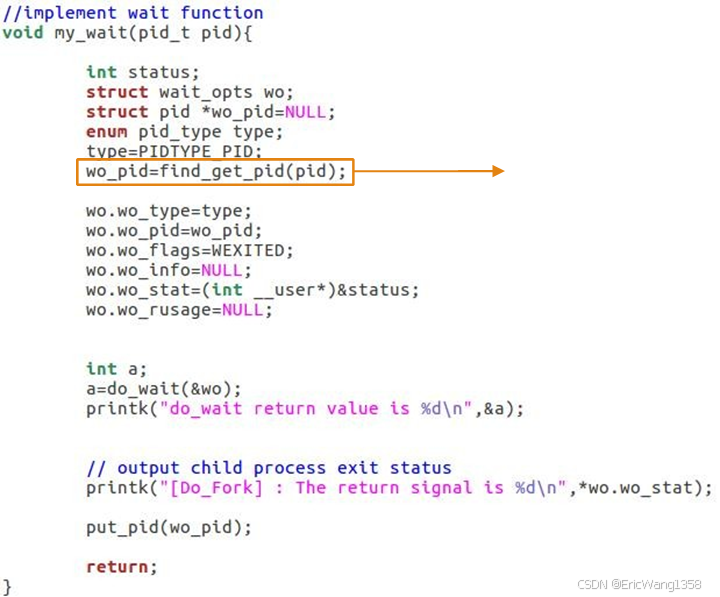
这个代码示例实现了一个自定义的 my_wait() 函数,用于等待指定子进程的结束,并获取该子进程的退出状态。
My_wait()函数代码逐步解析:
1. 函数定义和输入参数:
void my_wait(pid_t pid) {
- 这个函数的输入参数是一个进程 ID (
pid_t pid),表示要等待的子进程的进程号。
2. 局部变量声明:
int status;
struct wait_opts wo;
struct pid *wo_pid=NULL;
enum pid_type type;
status:用于存储子进程的退出状态。
struct wait_opts wo:定义一个wait_opts结构体变量,用于传递给do_wait()函数来设置等待选项。struct pid *wo_pid:指向内核中的pid结构的指针,用于指定等待的子进程。enum pid_type type:枚举类型pid_type,用于表示进程标识符的类型。
3. 查找子进程的 PID 并赋值:
type = PIDTYPE_PID;
wo_pid = find_get_pid(pid);
type = PIDTYPE_PID;:设置type为PIDTYPE_PID,表示我们是基于进程 ID 来等待特定的子进程。wo_pid = find_get_pid(pid);:通过调用find_get_pid()函数,将用户传入的进程号pid转换为内核使用的struct pid,并将结果赋给wo_pid。
4. 配置 wait_opts 结构体:
wo.wo_type = type;
wo.wo_pid = wo_pid;
wo.wo_flags = WEXITED;
wo.wo_info = NULL;
wo.wo_stat = (int __user *)&status;
wo.wo_rusage = NULL;
wo.wo_type = type;:设置wo_type为PIDTYPE_PID,表示等待指定的进程。wo.wo_pid = wo_pid;:将查找到的wo_pid(内核中的进程结构体指针)赋值给wait_opts的wo_pid字段。wo.wo_flags = WEXITED;:设置等待标志为WEXITED,表示等待子进程正常退出。wo.wo_info = NULL;:不需要子进程的信号信息。wo.wo_stat = (int __user *)&status;:将status的地址赋值给wo_stat,用于存储子进程的退出状态。wo.wo_rusage = NULL;:不需要子进程的资源使用信息。
5. 调用 do_wait() 函数并处理返回值:
int a;
a = do_wait(&wo);
printk("do_wait return value is %d\n", &a);
a = do_wait(&wo);:调用内核函数do_wait(),传入wait_opts结构体wo,等待指定的子进程结束。返回值a表示do_wait()的执行结果,成功时返回 0,失败时返回负值。printk("do_wait return value is %d\n", &a);:输出do_wait()的返回值,用于调试或日志记录。
6. 输出子进程的退出状态:
printk("[Do_Fork]: The return signal is %d\n", *wo.wo_stat);
- 通过
printk()输出子进程的退出状态,使用*wo.wo_stat获取子进程的退出码。
7. 释放 PID 资源:
put_pid(wo_pid);
put_pid(wo_pid);:释放通过find_get_pid()获取的 PID 引用,避免内存泄漏。
8. 函数结束:
return;
总结:
- 这个自定义的
my_wait()函数实现了父进程等待指定子进程终止的逻辑。 - 通过调用
do_wait()函数,父进程可以获取子进程的退出状态并进行处理。 - 该函数还通过
find_get_pid()函数查找子进程的 PID,并在等待结束后使用put_pid()释放该引用。
在 Linux 内核中,信号是用于进程间通信和控制的机制,允许内核向进程传递异步事件。每个进程都需要管理其接收的信号,包括哪些信号正在等待处理(pending)、哪些信号被屏蔽(masked),以及每个信号的处理方式。为了实现这些功能,内核为每个进程维护多个与信号相关的数据结构。
Handle signal (k_sigaction):
-
struct signal_struct(信号结构体):- 这个结构体包含了一个进程(或线程组)的信号处理的全局信息。在 Linux 内核中,进程的多个线程共享同一个
signal_struct结构。 - 字段描述:
shared_pending:所有线程组共享的待处理信号的列表。group_exit_code:线程组中任意线程退出时的退出码(如果是因为信号引起的)。signal_queue:信号队列,用于跟踪多个未处理的信号。flags:各种标志位,例如指示进程是否已终止。
- 这个结构体包含了一个进程(或线程组)的信号处理的全局信息。在 Linux 内核中,进程的多个线程共享同一个
-
struct sighand_struct(信号处理程序结构体):- 这个结构体包含了进程的信号处理行为。它描述了每个信号如何被处理:是被忽略、默认处理,还是使用自定义的信号处理函数(如
SIG_IGN,SIG_DFL)。 - 字段描述:
action:一个数组,存储每个信号对应的k_sigaction结构。siglock:用于保护信号处理程序的锁。
- 信号的处理方式:
- 默认处理:例如终止进程、生成核心转储等。
- 忽略信号:如
SIG_IGN,意味着忽略这个信号。 - 自定义处理:通过
signal()或sigaction()系统调用注册自定义的信号处理函数。
- 这个结构体包含了进程的信号处理行为。它描述了每个信号如何被处理:是被忽略、默认处理,还是使用自定义的信号处理函数(如
-
struct k_sigaction(信号处理动作):- 这个结构体存储了信号的具体处理动作,表示进程收到某个信号时该如何处理。
- 字段描述:
sa:保存与信号处理相关的配置(例如信号处理程序的地址)。sa.sa_handler:指向信号处理函数的指针。sa.sa_flags:信号处理的标志位,如SA_RESTART、SA_SIGINFO。sa.sa_mask:指定信号处理函数执行期间要屏蔽的信号。
-
struct sigpending(待处理信号结构体):- 这个结构体用于表示哪些信号已经发送给进程但尚未处理,分为进程级和线程级的信号。
- 字段描述:
signal:信号的集合,表示进程的哪些信号处于待处理状态。list:链接在信号队列中的信号。
-
sigset_t(信号集):- 信号集是用来表示一组信号的集合,通常用于屏蔽(mask)或取消屏蔽某些信号。它在许多系统调用(如
sigprocmask())中用来定义要操作的信号集。 - 字段描述:
sig:每个位对应一个信号,用位操作来表示是否屏蔽某个信号。
- 信号集是用来表示一组信号的集合,通常用于屏蔽(mask)或取消屏蔽某些信号。它在许多系统调用(如
-
task_struct(进程描述符):- 每个进程的核心结构体,其中包含与该进程相关的所有信息,包括与信号相关的字段。
- 字段描述:
pending:进程的待处理信号。blocked:进程当前被屏蔽的信号集。sighand:指向sighand_struct的指针,存储信号处理程序。signal:指向signal_struct的指针,存储与信号相关的其他全局信息。
具体操作流程:
-
信号发送:
- 内核通过
send_sig()或send_sig_info()等函数向进程发送信号。这些函数会将信号添加到pending列表中,并根据task_struct中的blocked集合决定信号是否应该立即处理或保持等待。
- 内核通过
-
信号的处理:
- 当进程被调度时,内核检查
task_struct中的pending列表。如果有待处理的信号,并且信号不在blocked集合中,内核将调用信号处理函数。 - 信号处理函数根据
k_sigaction中的定义决定如何处理信号。如果是自定义信号处理程序,则将控制权交给用户态的信号处理函数。
- 当进程被调度时,内核检查
-
信号屏蔽:
- 进程可以使用
sigprocmask()或pthread_sigmask()来屏蔽或解除屏蔽特定信号。屏蔽的信号将不会被立即处理,直到它们被解除屏蔽。
- 进程可以使用
-
信号等待:
- 使用
sigwaitinfo()或sigsuspend(),进程可以主动等待一个信号的到来,而不是被动处理信号。
- 使用
1. 信号描述符 (signal_struct) 和 k_sigaction 结构体
-
signal_struct:- 进程的
task_struct中有一个指向signal_struct结构体的字段,该结构体跟踪与信号相关的状态,包括共享的待处理信号列表。这是所有线程共享的信号状态。 signal_struct结构体包括shared_pending字段,该字段表示线程组所有线程共享的待处理信号列表。信号在被发送时会被放置在这个列表中。
- 进程的
-
k_sigaction:k_sigaction结构体定义了如何处理每个信号。它包含了信号的处理程序(handler)、信号处理的选项(如SA_RESTART、SA_SIGINFO)以及信号屏蔽(mask)信息。- 当一个进程接收到信号时,内核会查看信号的处理方式:是默认处理、忽略还是自定义的处理程序。
k_sigaction结构体存储了这些信息。
2. 信号的到达和准备 (do_signal)
- 当信号到达时,内核会检测到信号的到来,并准备修改目标进程的进程描述符(
task_struct)来接收信号。这是在do_signal()函数中完成的。 do_signal():do_signal()是 Linux 内核中负责处理信号到达的核心函数。它会被调用来处理所有进程接收到的信号。- 该函数的主要作用包括检查哪些信号已经到达、查看是否存在待处理的信号,并决定如何处理这些信号。
3. 信号处理程序的执行 (handle_signal)
- 如果为某个信号设置了信号处理程序(handler),
do_signal()会调用handle_signal()函数来执行该信号的处理程序。 handle_signal():- 这个函数负责具体执行信号处理程序。它首先确保信号是可处理的,然后将信号的上下文保存,并执行信号处理函数。
- 在信号处理程序执行完毕后,它还需要恢复进程的上下文,以便继续执行处理信号之前的程序指令。
流程概述:
-
信号到达 (Signal Arrival)
- 当内核检测到某个进程接收到一个信号时,该信号会被添加到
signal_struct的shared_pending列表中。 - 内核随后会调用
do_signal()来处理该信号。
- 当内核检测到某个进程接收到一个信号时,该信号会被添加到
-
信号检查 (do_signal):
do_signal()会从待处理信号中检查信号,并查看是否为该信号设置了处理程序。如果该信号被屏蔽或没有设置处理程序,信号将保持待处理状态。- 如果该信号有对应的处理程序,
do_signal()将调用handle_signal()来执行信号处理程序。
-
信号处理程序执行 (handle_signal):
handle_signal()函数会实际执行信号处理程序。它首先会将当前的进程状态保存,然后根据k_sigaction结构中的处理程序指针,调用用户定义的信号处理函数。- 信号处理程序可以执行自定义的动作,例如在收到
SIGINT时,进程可能会执行一些清理工作。
-
恢复上下文 (Context Restore):
- 在信号处理程序执行完毕后,内核会恢复进程的上下文,确保进程可以继续在接收到信号前的状态下执行。
具体实现流程的细节:
-
信号的到来:
- 内核通过
send_sig()或send_sig_info()函数向进程发送信号,并将信号放入进程的pending列表中。进程的task_struct中包含了一个signal字段,该字段指向一个signal_struct,其中包含了进程和线程组的信号状态。
- 内核通过
-
检查待处理信号 (
do_signal):- 当内核发现有待处理信号时,会调用
do_signal()函数。该函数的主要任务是遍历pending信号列表,检查是否有需要处理的信号。 - 对于每个信号,内核会检查信号处理方式。如果信号有处理程序,内核会进一步调用
handle_signal()。
- 当内核发现有待处理信号时,会调用
-
处理信号 (
handle_signal):handle_signal()函数会根据k_sigaction结构体中定义的信号处理程序(例如用户定义的信号处理函数)来执行。- 信号处理期间,内核会保护和保存当前进程的状态,避免在信号处理过程中丢失数据。
-
恢复进程状态:
- 在信号处理完毕后,内核会通过上下文切换,恢复进程执行信号之前的状态。