7.10日学习打卡
目录:

一. redis功能
流水线pipeline
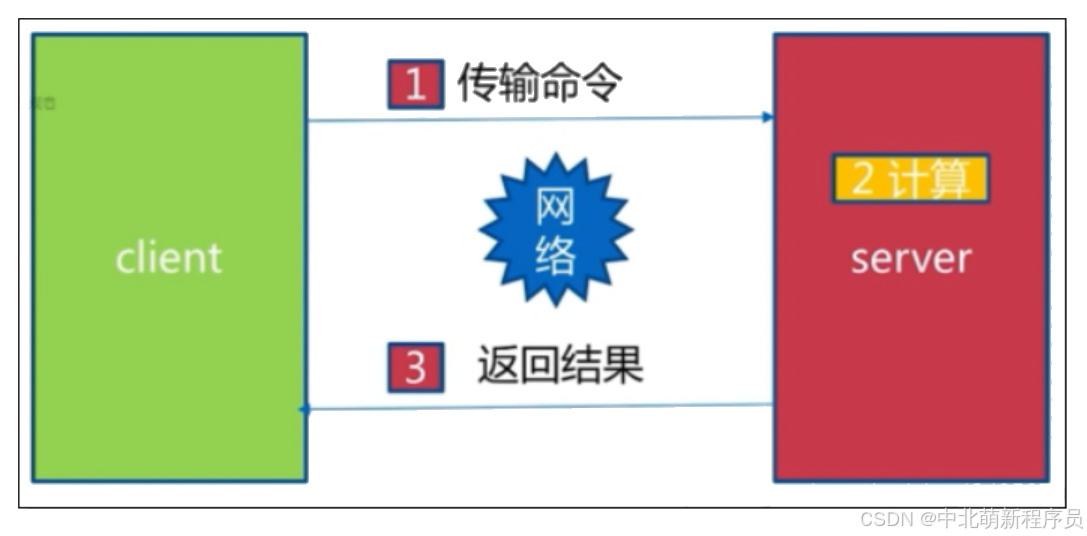
1次网络命令通信模型
经历了1次时间 = 1次网络时间 + 1次命令时间。
批量网络命令通信模型
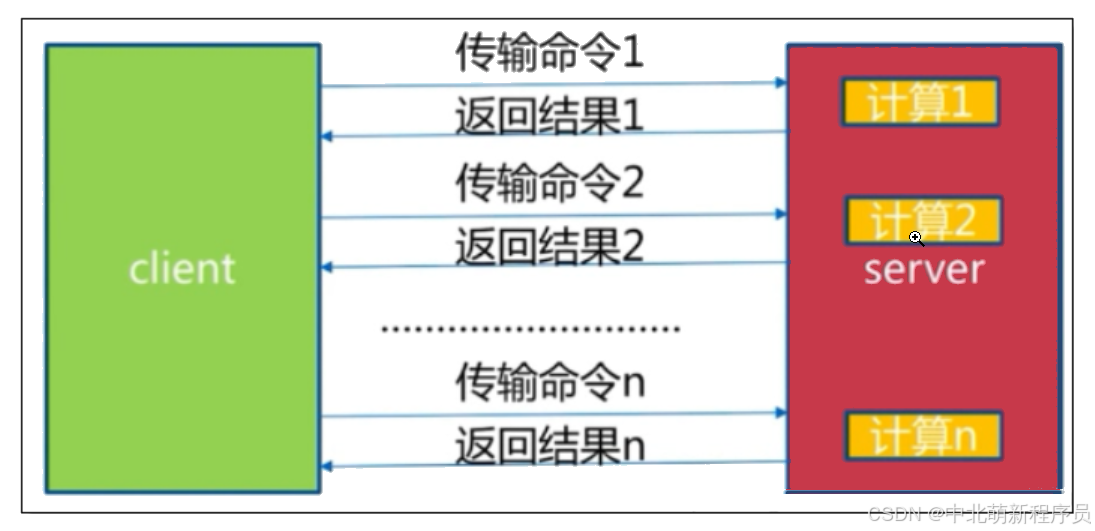
经历了 n次时间 = n次网络时间 + n次命令时间
什么是流水线?
经历了 1次pipeline(n条命令) = 1次网络时间 + n次命令时间,这大大减少了网络时间的开销,这就是流水线。
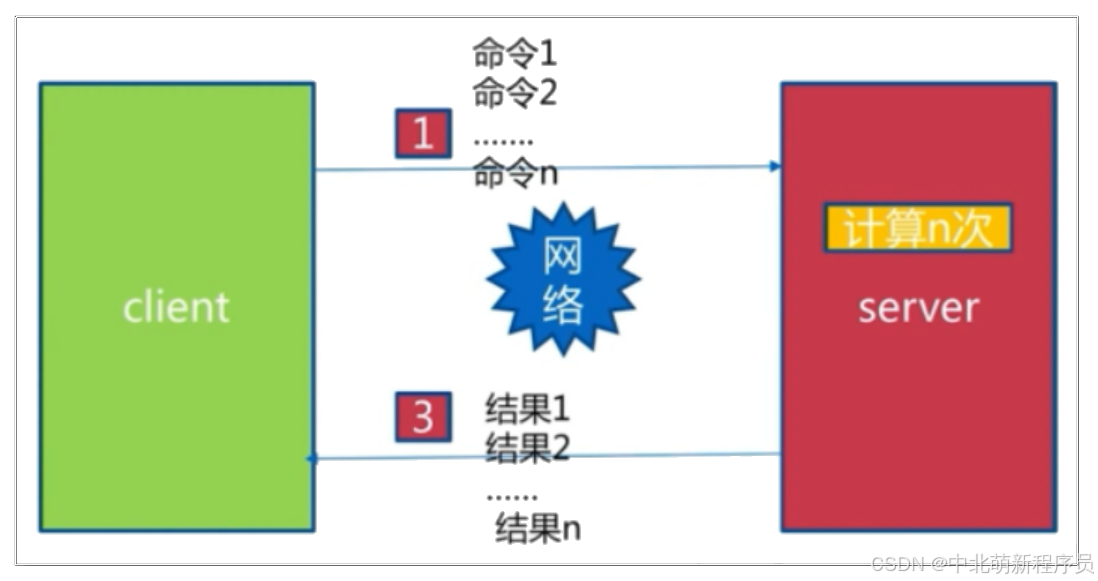
执行一条命令在redis端可能需要几百微秒,而在网络光纤中传输只花费了13毫秒。
注意:
在执行批量操作而没有使用pipeline功能,会将大量的时间耗费在每一次网络传输的过程上;而使用pipeline后,只需要经过一次网络传输,然后批量在redis端进行命令操作。这会大大提高了效率。
pipeline实现
没有pipeline的命令执行
for (int i = 0; i < 10000; i++) {
redisTemplate.opsForHash().put("hashkey:" + i, "field" + i, "value" + i);
}
注意:
在不使用pipeline的情况下,使用for循环进行每次一条命令的执行操作,耗费的时间可能达到 1w 条插入命令的耗时为50s。
使用pipeline
redisTemplate.execute(new RedisCallback<Long>() {
@Nullable
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (int i = 0; i < 10000; i++) {
connection.hSet(("hashkey:" + i).getBytes(), ("field" + i).getBytes(), ("value" + i).getBytes());
}
List<Object> result = connection.closePipeline();
return null;
}
});
发布与订阅
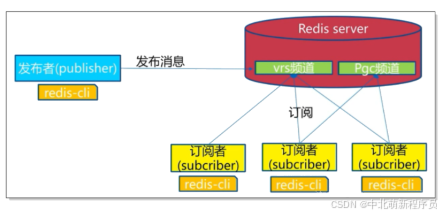
什么是发布与订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
什么时候用发布订阅
看到发布订阅的特性,用来做一个简单的实时聊天系统再适合不过了。再比如,在一个博客网站中,有100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们拉。

Redis的发布与订阅
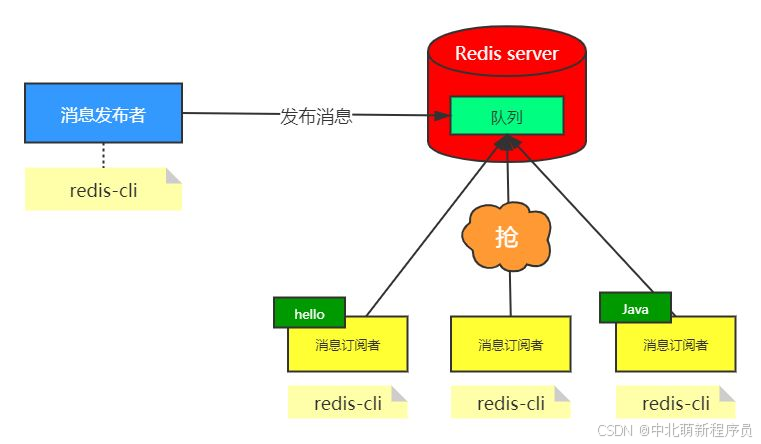
发布订阅命令行实现
订阅
语法格式:
subcribe 主题名字
示例:
127.0.0.1:6379> SUBSCRIBE channel-1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel-1"
3) (integer) 1
发布命令
语法格式:
publish channel-1 hello
示例:
打开另一个客户端,给channel1发布消息hello
127.0.0.1:6379> PUBLISH channel-1 hello
(integer) 1
注意:
返回的1是订阅者数量。
打开第一个客户端可以看到发送的消息
127.0.0.1:6379> SUBSCRIBE channel-1
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "channel-1"
3) (integer) 1
1) "message"
2) "channel-1"
3) "hello"
注意:
发布的消息没有持久化,如果在订阅的客户端收不到hello,只能收到订阅后发布的消息。
慢查询
什么是慢查询
Redis慢查询是Redis提供的一项性能优化功能,它可以记录某个查询语句的执行时间、命令参数、执行次数等信息,从而帮助运维人员快速定位某个查询语句的性能问题。
Redis命令执行的整个过程
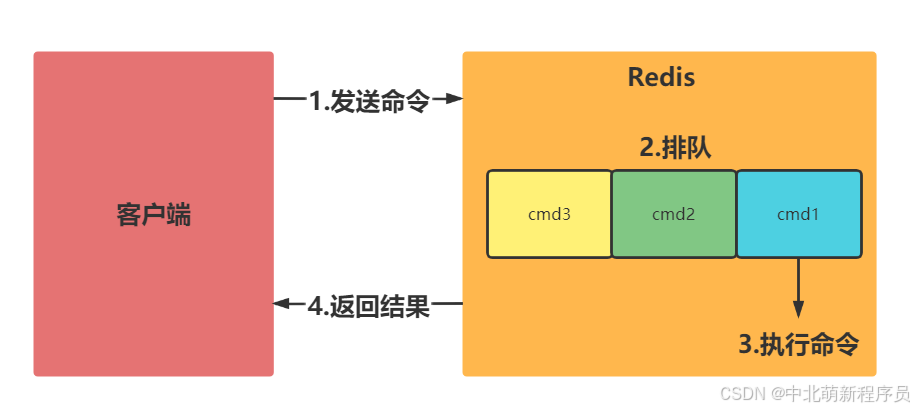
两点说明:
慢查询发生在第3阶段
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素
慢查询日志是存放在Redis内存列表中。
什么是慢查询日志
慢查询日志是Redis服务端在命令执行前后计算每条命令的执行时长,当超过某个阈值是记录下来的日志。日志中记录了慢查询发生的时间,还有执行时长、具体什么命令等信息,它可以用来帮助开发和运维人员定位系统中存在的慢查询。
如何获取慢查询日志
可以使用slowlog get命令获取慢查询日志,在slowlog get后面还可以加一个数字,用于指定获取慢查询日志的条数,比如,获取3条慢查询日志:
127.0.0.1:6379> SLOWLOG get 3
1) 1) (integer) 0
2) (integer) 1640056567
3) (integer) 11780
4) 1) "FLUSHALL"
5) "127.0.0.1:43406"
6) ""
参数:
唯一标识ID
命令执行的时间戳
命令执行时长
执行的命名和参数
如何获取慢查询日志的长度
可以使用slowlog len命令获取慢查询日志的长度。
slowlog len
(integer) 121
注意:
当前Redis中有121条慢查询日志。
怎么配置慢查询的参数
-
命令执行时长的指定阈值 slowlog-log-slower-than。
slowlog-log-slower-than的作用是指定命令执行时长的阈值,执行命令的时长超过这个阈值时就会被记录下来。 -
存放慢查询日志的条数 slowlog-max-len。
slowlog-max-len的作用是指定慢查询日志最多存储的条数。实际上,Redis使用了一个列表存放慢查询日志,slowlog-max-len就是这个列表的最大长度。
如何进行配置
查看慢日志配置
查看 redis 慢日志配置,登陆 redis 服务器,使用 redis-cli 客户端连接redis server。
127.0.0.1:6379> config get slow*
1) "slowlog-max-len"
2) "128"
3) "slowlog-log-slower-than"
4) "10000"
慢日志说明:
10000阈值,单位微秒,此处为10毫秒,128慢日志记录保存数量的阈值,此处保存128条。
修改Redis配置文件
比如,把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200:
slowlog-log-slower-than 1000
slowlog-max-len 1200
使用config set命令动态修改。
比如,还是把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200
> config set slowlog-log-slower-than 1000
OK
> config set slowlog-max-len 1200
OK
> config rewrite
OK
实践建议
slowlog-max-len配置建议
- 线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。
- 增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
slowlog-log-slower-than配置建议
- 默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。
- 由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑QPS不到1000。因此对于高QPS场景的Redis建议设置为1毫秒。
二 . redis的持久化机制
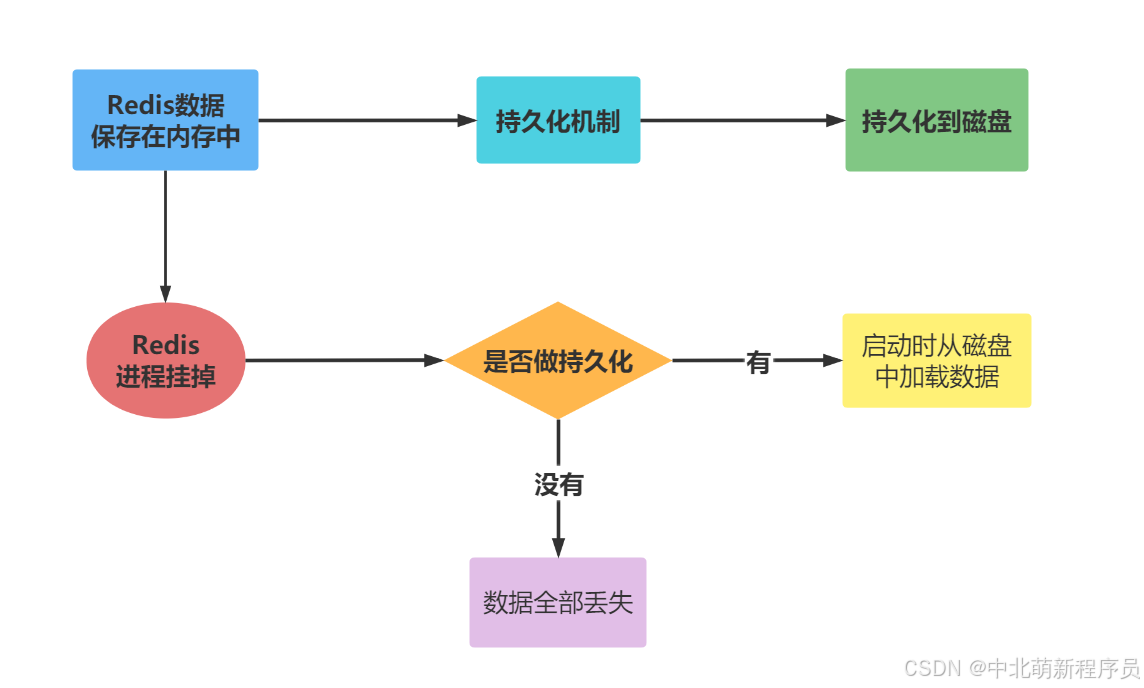
由于Redis的数据都存放在内存中,如果没有配置持久化,Redis重启后数据就全丢失了,于是需要开启Redis的持久化功能,将数据保存到磁盘上,当Redis重启后,可以从磁盘中恢复数据。
持久化机制概述
对于Redis而言,持久化机制是指把内存中的数据存为硬盘文件, 这样当Redis重启或服务器故障时能根据持久化后的硬盘文件恢复数据。
持久化机制的意义
Redis持久化的意义,在于故障恢复。比如部署了一个redis,作为cache缓存,同时也可以保存一些比较重要的数据。
Redis提供了两个不同形式的持久化方式
- RDB(Redis DataBase)
- AOF(Append Only File)
RDB持久化机制
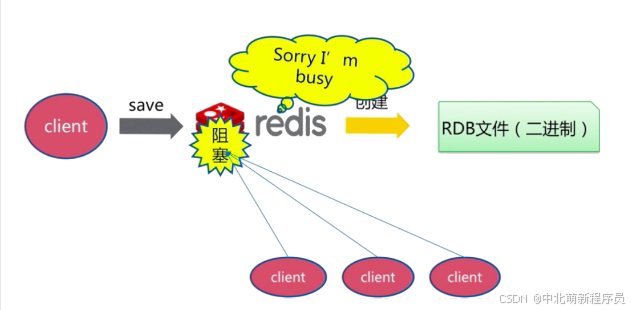
RDB是什么
在指定的时间间隔内将内存的数据集快照写入磁盘,也就是行话讲的快照,它恢复时是将快照文件直接读到内存里。
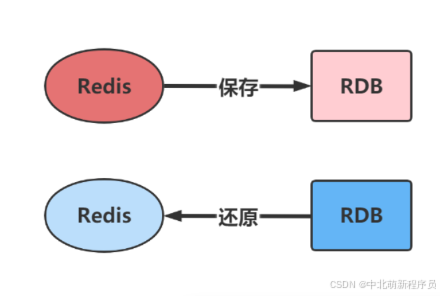
注意:
这种格式是经过压缩的二进制文件。
配置dump.rdb文件
RDB保存的文件,在redis.conf中配置文件名称,默认为dump.rdb。
439
440 # The filename where to dump the DB
441 dbfilename dump.rdb
442
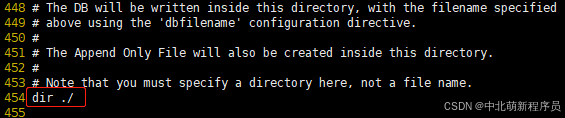
rdb文件的保存位置,也可以修改。默认在Redis启动时命令行所在的目录下。
rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下

dir ./
触发机制-主要三种方式
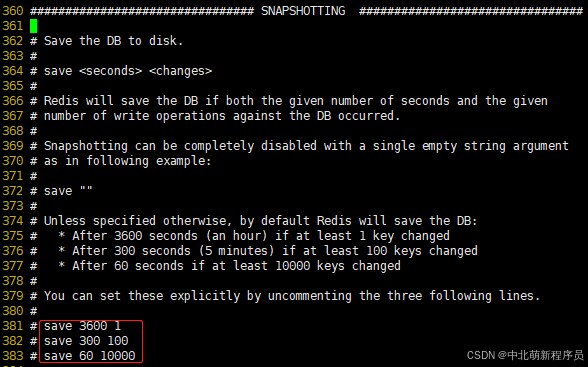
快照默认配置:
- save 3600 1:表示3600秒内(一小时)如果至少有1个key的值变化,则保存。
- save 300 100:表示300秒内(五分钟)如果至少有100个 key 的值变化,则保存。
- save 60 10000:表示60秒内如果至少有 10000个key的值变化,则保存。
配置新的保存规则
给redis.conf添加新的快照策略,30秒内如果有5次key的变化,则触发快照。配置修改后,需要重启Redis服务。
save 3600 1
save 300 100
save 60 10000
save 30 5
flushall
执行flushall命令,也会触发rdb规则。
save与bgsave
手动触发Redis进行RDB持久化的命令有两种:
-
save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止,不建议使用。 -
bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。
高级配置
stop-writes-on-bgsave-error
默认值是yes。当Redis无法写入磁盘的话,直接关闭Redis的写操作。
rdbcompression

默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。

rdbchecksum
默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
恢复数据

只需要将rdb文件放在Redis的启动目录,Redis启动时会自动加载dump.rdb并恢复数据。
优势
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 恢复速度快
劣势
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
AOF持久化机制
AOF是什么
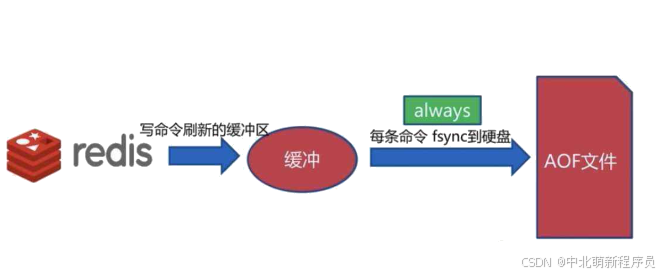
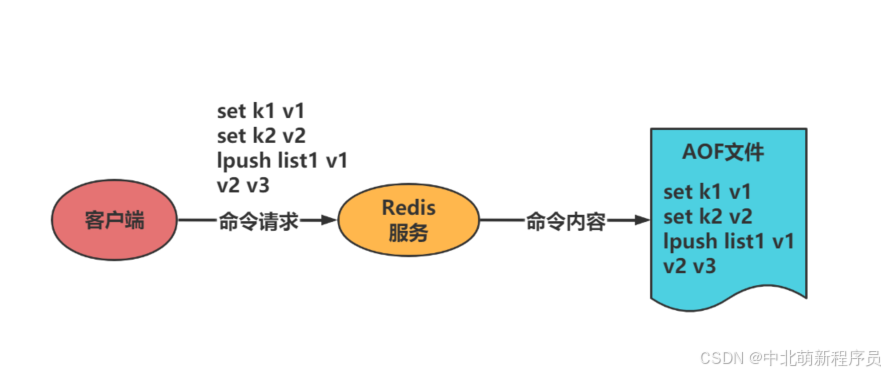
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来。
AOF默认不开启
可以在redis.conf中配置文件名称,默认为appendonly.aof。
注意:
AOF文件的保存路径,同RDB的路径一致,如果AOF和RDB同时启动,Redis默认读取AOF的数据。
AOF启动/修复/恢复
开启AOF
设置Yes:修改默认的appendonly no,改为yes
appendonly yes
注意:
修改完需要重启redis服务。
设置数据。
set k11 v11
set k12 v12
set k13 v13
set k14 v14
set k15 v15
AOF同步频率设置
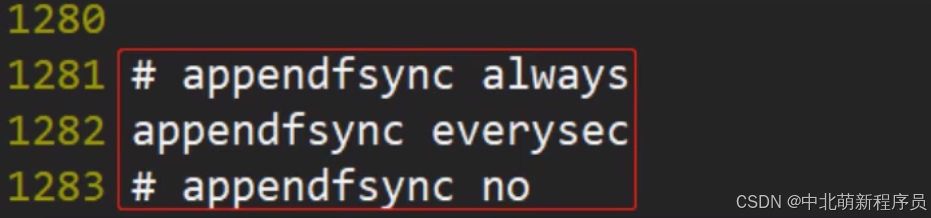
参数:
- appendfsync always
始终同步,每次Redis的写入都会立刻记入日志,性能较差但数据完整性比较好。- appendfsync everysec
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。- appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
优势
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
劣势
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
如何选用持久化方式
不要仅仅使用RDB
RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据。
也不要仅仅使用AOF
- 你通过AOF做冷备,没有RDB做冷备,来的恢复速度更快。
- RDB每次简单粗暴生成数据快照,更加健壮,可以避免AOF这种复杂的备份和恢复机制的bug。
综合使用AOF和RDB两种持久化机制
用AOF来保证数据不丢失,作为数据恢复的第一选择,用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。

如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力
