Collectors.groupingBy是Java steam常用分组方法,但默认情况下分组的数据是无序的(因为默认使用的是HashMap),groupingBy有三个参数:
- 第一个参数就是key的Function了,指定分组按照什么分类
- 第二个参数是一个map工厂,也就是最终结果的容器,一般默认的是采用的HashMap::new,指定分组最后用什么容器保存返回
- 第三个参数是一个downstream,类型是Collector,也是一个收集器,指定按照第一个参数分类后,对应的分类的结果如何收集
代码复现:
SearchResponse<Map> search = null;
try {
search = client.search(s -> s.index("tbanalyzelist")
.query(
q -> q.matchAll(m -> m)
)
.sort(o -> o.field(f -> f.field("openTime").order(SortOrder.Asc)))
.from(0)
.size(2000)
, Map.class);
} catch (IOException e) {
e.printStackTrace();
}
List<Map> AnalyzeList = search.hits().hits().stream().map(f -> f.source()).collect(Collectors.toList());
for(Map item : AnalyzeList){
//System.out.println("在线机器分析:"+item);
System.out.print("机器编号:"+item.get("machineId") + "\t");
System.out.print("机器持续开机时间:"+item.get("duration") + "\t");
System.out.print("日期:"+item.get("openTime") + "\n");
}
Map<Object, Object> durationMap = new HashMap<>();
List<Object> durationList = new ArrayList<>();//机器持续开机时间集合
List<Object> monthList = new ArrayList<>();//机器开机时间月份集合
Map<Object, List<Map>> listMap = AnalyzeList.stream().collect(Collectors.groupingBy(e -> e.get("openTime")));
// listMap.entrySet().stream().sorted(Comparator.comparing(Map.Entry.comparingByKey()));
for ( Map.Entry<Object, List<Map>> entry : listMap.entrySet() ){
System.out.println("Key(日期):{" + entry.getKey() +"}" + "\t 该日期数据数量:{" + entry.getValue().size() +"}");
List<Map> entryValue = new ArrayList<>();
entryValue = entry.getValue();
double duration = entryValue.stream().mapToDouble(k -> Double.parseDouble(k.get("duration").toString())).sum();
System.out.print("日期:" + entry.getKey() + "\t");
System.out.println("开机持续时间:" + duration);
monthList.add(entry.getKey());//收集月份数据
durationList.add(duration);
}
durationMap.put("month",monthList);
durationMap.put("duration",durationList);
System.out.println("===============页面需要数据=================");
for (Map.Entry<Object,Object> entry : durationMap.entrySet()){
System.out.println("月份:" + entry.getKey());
System.out.println("机器持续开机时间:" + entry.getValue());
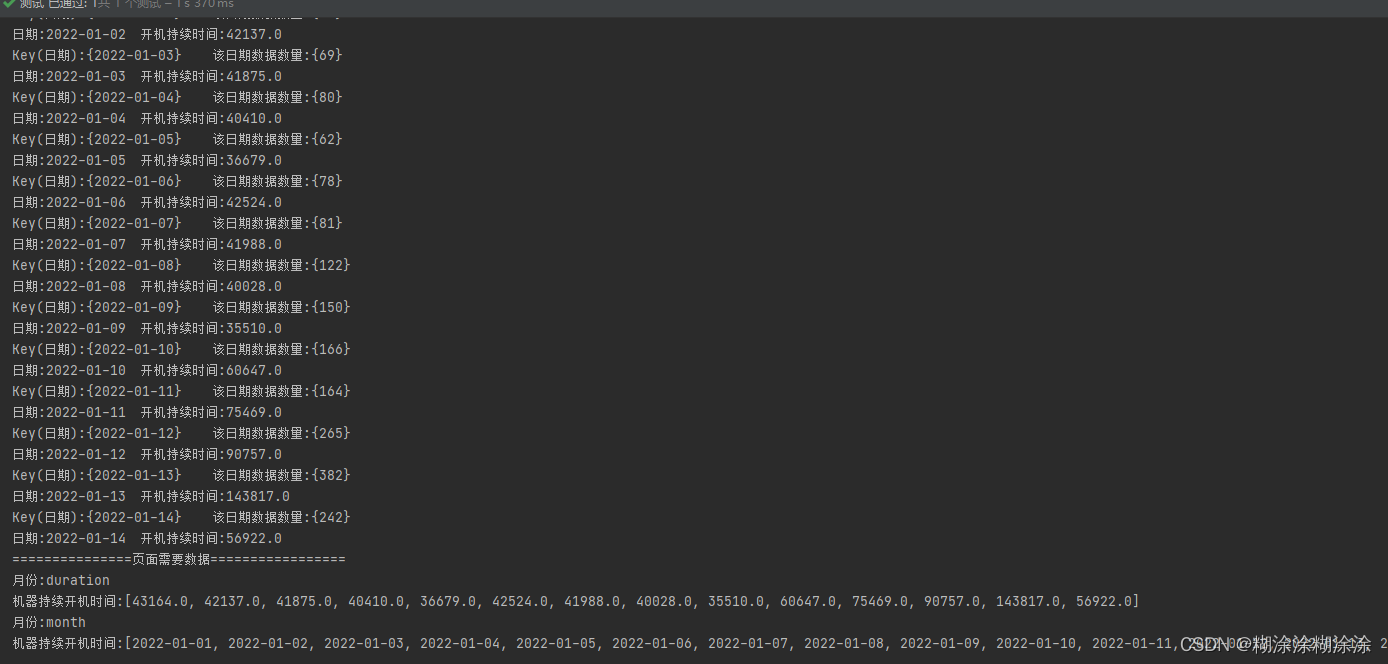
}es查询到的信息,通过月份分组后

导致后续数据顺序出现无序问题,可以看到结果中的机器开机时间中的日期顺序没有按照从小到大排序
解决方案:为了保持原有顺序可以指定LinkedHashMap来存放数据
即原来的28行分组代码
Map<Object, List<Map>> listMap = AnalyzeList.stream()
.collect(Collectors.groupingBy(e -> e.get("openTime")));修改为以下代码
Map<Object, List<Map>> listMap = AnalyzeList.stream()
.collect(Collectors.groupingBy(e -> e.get("openTime"),
LinkedHashMap::new, Collectors.toList()));LinkedHashMap通过维护一个运行于所有条目的双向链表,保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序 。
结果保持顺序一致(机器持续开机时间按照日期从小到大输出)