原理
跳表(skiplist)是一种链表,而链表查询的时间复杂度为O(n),为了优化查询效率,我们可以让每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点:

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半。在查询时,我们不再需要与链表中每个节点逐个进行比较了,只需要先比较上面的一层链表,当目标值小于下一个节点的值时,就跳到下一层继续比较,这样比较的节点数大概只有原来的一半。以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层,增加一个指针,从而产生第三层链表,这样搜索效率就进一步提高了。
按照上面生成链表的方式,上面每一层链表的节点个数是下面一层的节点个数的一半,这样查找过程就非常类似二分查找,使得查找的时间复杂度可以降低到O(log n)。但是插入删除数据的时候会打乱上下相邻两层链表上节点个数严格的2:1的对应关系,如果要维持这种对应关系,就必须对整个结构重新进行调整,不仅实现繁琐,还影响效率。skiplist的设计为了避免这种问题,不再严格要求上下相邻两层链表上节点个数严格的2:1的对应关系,而是插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数。
一般跳表会设计一个最大层数maxLevel的限制,其次会设置一个多增加一层的概率p,这两个参数的取值为p = 1/4,maxLevel = 32,这样新增一个结点时其层数的伪代码如下:
可以得知跳表中每个结点的平均层数为:
经过推导,可以得知跳表的查询的平均时间复杂度为O(logN),具体推导过程可以参考 复杂度推导。

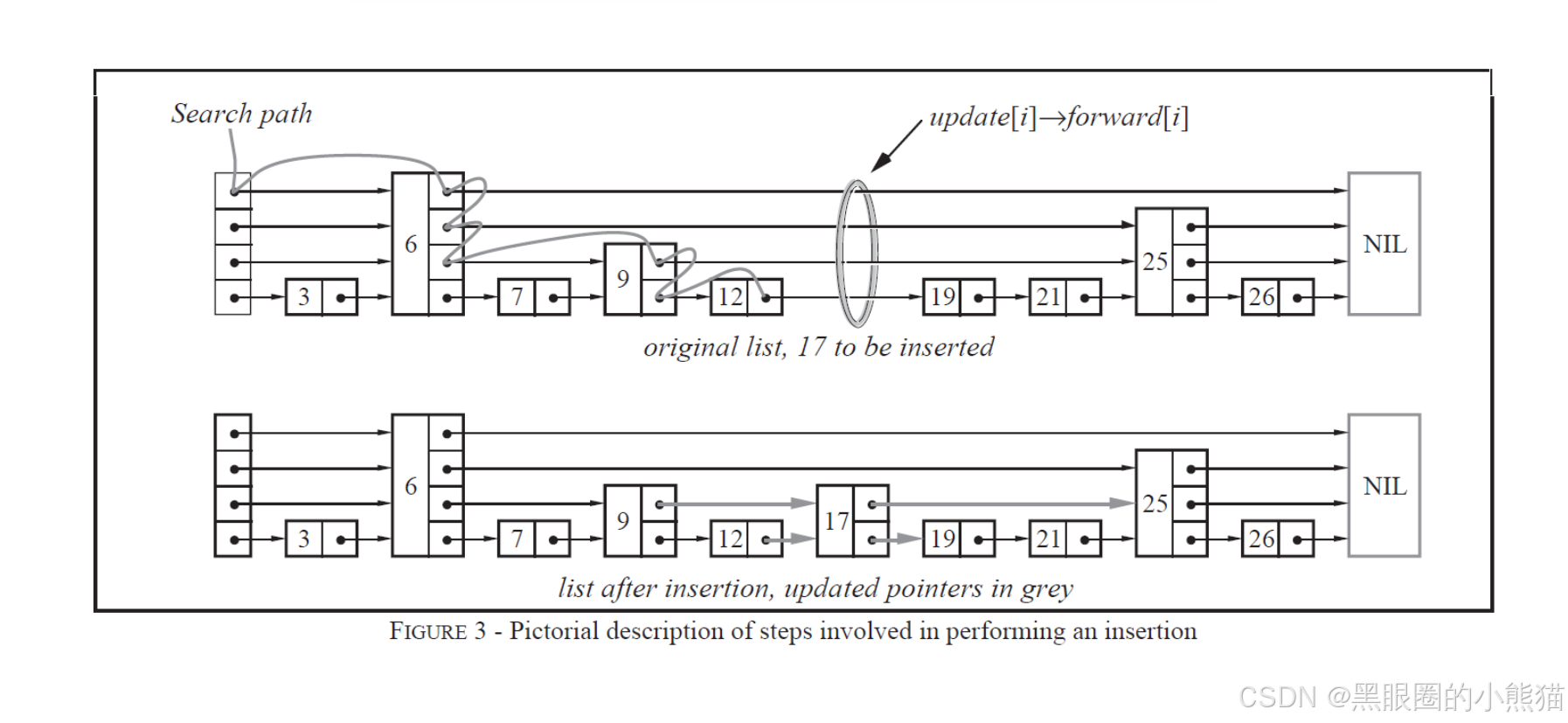
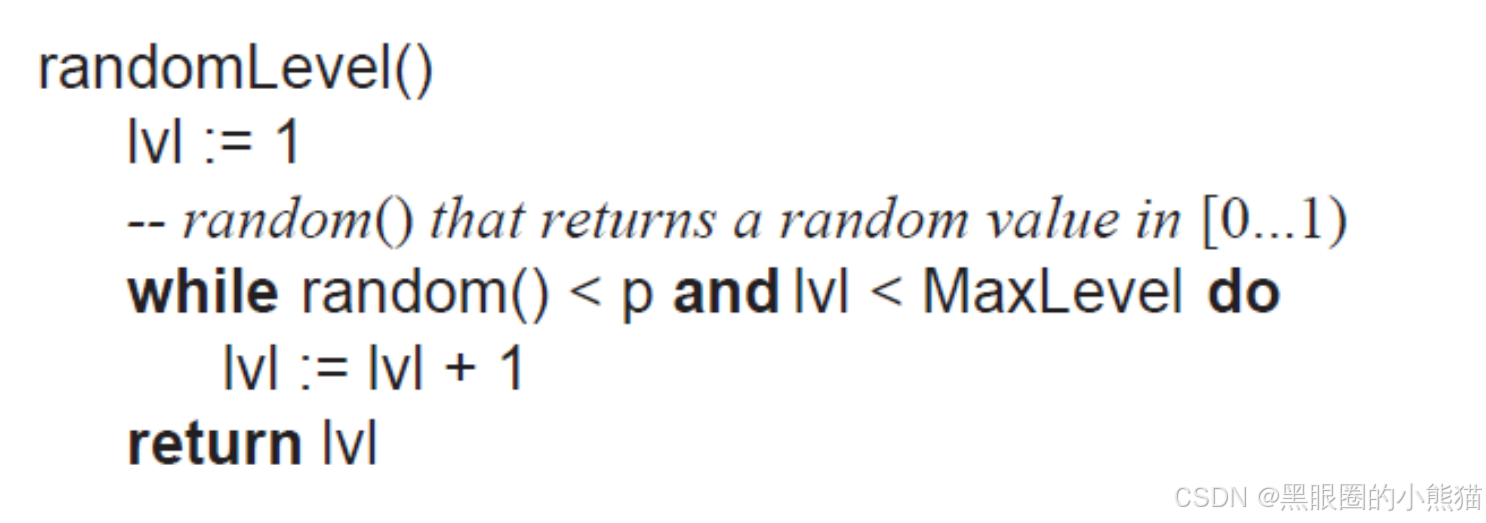
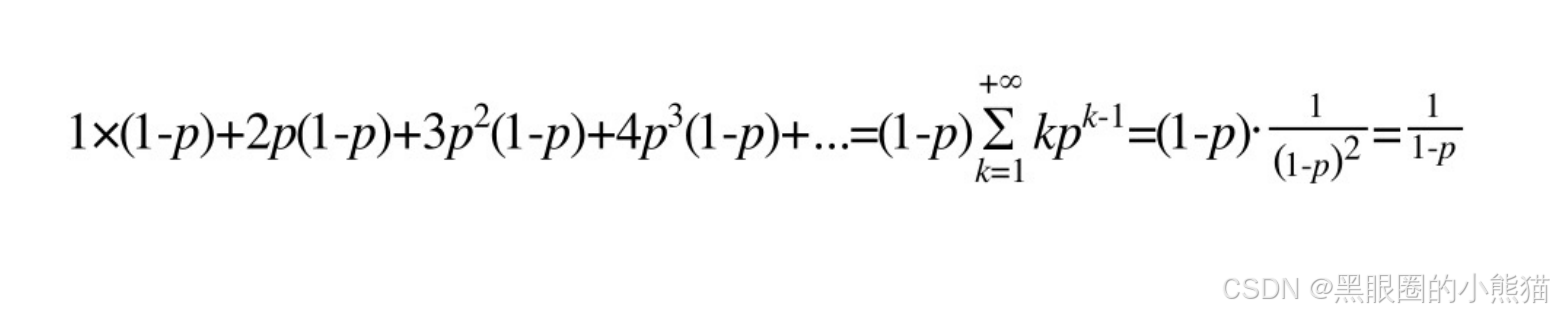
实现
#include<iostream>
#include<vector>
#include<time.h>
#include<stdlib.h>
using namespace std;
float p=0.5; //产生下一层的概率
int maxLevels=32; //最大层数
template<class T>
struct listNode {
listNode(T data, int levels)
:_data(data)
,_next(levels, nullptr)
{}
listNode()
{}
~listNode()
{}
T _data; //结点数据
vector<listNode<T>*> _next; //指向下一个结点的指针
};
template<class T>
class skipList {
public:
skipList(){
srand(time(nullptr));
_head = new listNode<T>(T(), maxLevels);
}
~skipList() {
listNode<T>* cur = _head;
listNode<T>* next =nullptr;
while (cur) {
next = cur->_next[0];
delete cur;
cur = next;
}
}
bool search(T data) {
listNode<T>* cur = _head;
int level = maxLevels-1;
while (level>=0) {
if (nullptr == cur->_next[level]|| data < cur->_next[level]->_data) {
--level;
}
else if(data == cur->_next[level]->_data) {
return true;
}
else {
cur = cur->_next[level];
}
}
return false;
}
void add(T data) {
vector<listNode<T>*> preLinks(maxLevels,nullptr);
getPreLink(data, preLinks);
listNode<T>* np = new listNode<T>(data, getLevels());
int level = np->_next.size() - 1;
while (level >= 0) {
np->_next[level] = preLinks[level]->_next[level];
preLinks[level]->_next[level] = np;
--level;
}
}
bool erase(T data) {
if (!search(data)) {
return false;
}
vector<listNode<T>*> preLinks(maxLevels, nullptr);
getPreLink(data, preLinks);
int level = preLinks[0]->_next[0]->_next.size() - 1;
listNode<T>* tmp = preLinks[0]->_next[0];
while (level >= 0) {
preLinks[level]->_next[level] = preLinks[level]->_next[level]->_next[level];
--level;
}
delete tmp;
tmp = nullptr;
return true;
}
private:
//获取某个结点所有与之相连的前一个结点
void getPreLink(T& data,vector<listNode<T>*>& links) {
int level = maxLevels - 1;
listNode<T>* cur = _head;
while (level >= 0) {
if (nullptr == cur->_next[level] || cur->_next[level]->_data >= data) {
links[level] = cur;
--level;
}
else {
cur = cur->_next[level];
}
}
}
int getLevels() {
int levels = 1;
while (rand() <= RAND_MAX * p && levels < maxLevels) {
++levels;
}
printf("level:%d\n", levels);
return levels;
}
private:
listNode<T>* _head; //头节点
};
int main() {
skipList<int> sl;
printf(" is find %d: %d\n", 1, sl.search(1));
sl.add(1);
sl.add(2);
sl.add(1);
sl.add(5);
sl.add(9);
printf(" is find %d: %d\n", 5, sl.search(5));
printf(" is find %d: %d\n", 1, sl.search(1));
printf(" is erase %d: %d\n", 1, sl.erase(1));
printf(" is erase %d: %d\n", 5, sl.erase(5));
printf(" is erase %d: %d\n", 10, sl.erase(10));
printf(" is find %d: %d\n", 5, sl.search(5));
printf(" is find %d: %d\n", 1, sl.search(1));
return 0;
}