以下参考Real Python:
https://realpython.com/pandas-read-write-files/
https://realpython.com/pandas-dataframe/
一、简介
pandas 是一个功能强大且灵活的 Python 包,可让您处理标记和时间序列数据。它还提供统计方法、绘图等。pandas 的一个重要特性是它能够写入和读取 Excel、CSV 和许多其他类型的文件。read_csv() 方法等函数使您能够有效地处理文件。您可以使用它们将 pandas 对象中的数据和标签保存到文件中,然后将它们加载为 Series 或 DataFrame 实例。
(1) Series:一维数组,类似于Numpy中的一维array,但具有索引标签,可以保存不同类型的数据,如字符串、布尔值、数字等。
(2) DataFrame:二维表格型数据结构,与SQL表或Excel工作表类似,每列可以是不同的数据类型(如数值、字符串或日期),并且具有列名和行索引。DataFrame是Pandas的核心数据结构,提供了丰富的数据操作方法。
原文链接:https://blog.csdn.net/CNY8888/article/details/144189212
二、安装
$ pip install pandas三、导入
import pandas as pd四、DataFrame函数
DataFrames 类似于 SQL 表或您在 Excel 或 Calc 中使用的电子表格。在许多情况下,DataFrames 比表或电子表格更快、更易于使用且功能更强大,因为它们是 Python 和 NumPy 生态系统不可或缺的一部分。
(一)数据结构
DataFrames 是包含以下内容的数据结构:
- 数据以二维形式组织,即行和列
- 与行和列对应的标签
(二)使用字典创建 DataFrame
1.传递数据
假设你正在使用 pandas 分析有关使用Python开发 Web 应用程序的职位的求职者的数据。假设你对求职者的姓名、城市、年龄和 Python 编程测试的分数感兴趣:
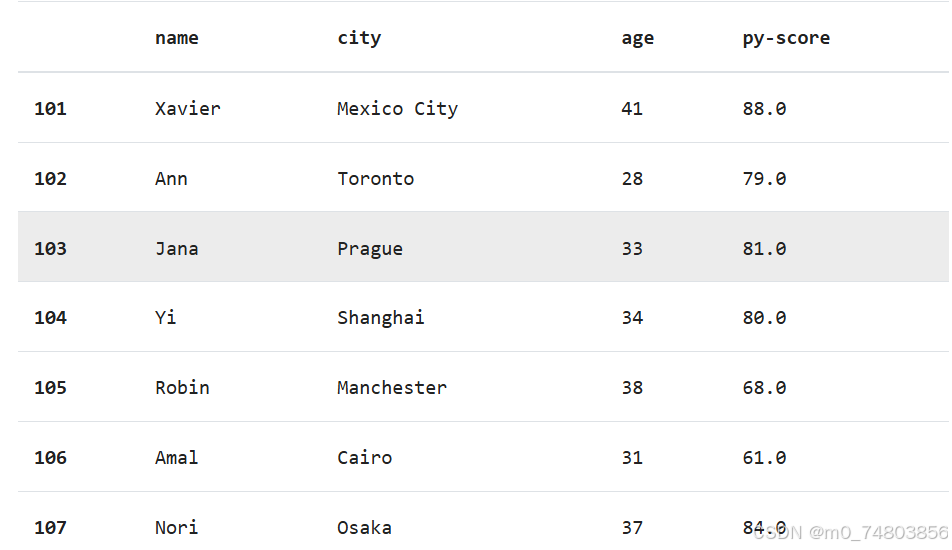
在此表中,第一行包含列标签(name、city、age和py-score)。第一列包含行标签(101、102,等等)。所有其他单元格都填充了数据值。
现在您已拥有创建 pandas DataFrame 所需的一切。有几种方法可以创建 DataFrame。在大多数情况下,您将使用DataFrame构造函数并提供数据、标签和其他信息:
您可以将数据作为二维列表、元组或NumPy 数组传递。
您还可以将其作为字典或Series实例传递,对于此示例,假设我们使用字典来传递数据:(其他方法请参考https://realpython.com/pandas-dataframe/)
>>> data = {
... 'name': ['Xavier', 'Ann', 'Jana', 'Yi', 'Robin', 'Amal', 'Nori'],
... 'city': ['Mexico City', 'Toronto', 'Prague', 'Shanghai',
... 'Manchester', 'Cairo', 'Osaka'],
... 'age': [41, 28, 33, 34, 38, 31, 37],
... 'py-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
... }
>>> row_labels = [101, 102, 103, 104, 105, 106, 107]data是一个Python 变量,它引用保存候选数据的字典。它还包含列的标签:
'name''city''age''py-score'
最后,row_labels指的是包含行标签的列表,这些标签是从101到的数字107。
现在您可以创建 pandas DataFrame 了:
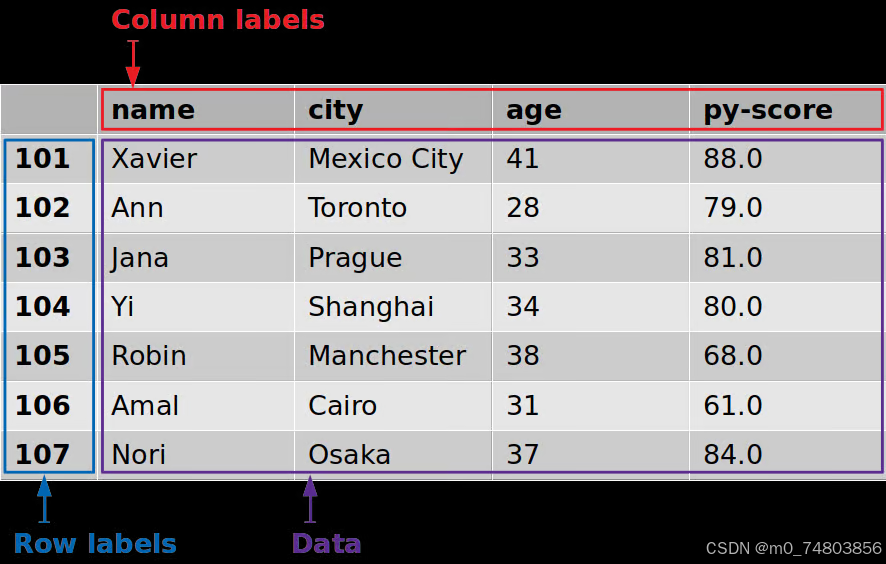
>>> df = pd.DataFrame(data=data, index=row_labels)
>>> df
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0该图显示了以下标签和数据df:
补充1:如果没有指定行标签Row labels ,只传递了一个字典,如下:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100那么,字典的键是 DataFrame 的列标签,字典的值是相应 DataFrame 列中的数据值。而行标签默认为0,1,2...
补充2:可以使用columns参数控制列的顺序,并使用行标签控制index:
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 32.查看某行
pandas DataFrames 有时会非常大,因此无法一次查看所有行。您可以使用.head()显示前几个项目,并.tail()使用 显示后几个项目:
>>> df.head(n=2)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
>>> df.tail(n=2)
name city age py-score
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0 这就是如何仅显示 pandas DataFrame 的开头或结尾。参数n指定要显示的行数。
3.查看某列
可以像从字典中获取值一样访问 pandas DataFrame 中的列:
>>> cities = df['city']
>>> cities
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: object五、to_csv函数
您可以将 pandas DataFrame 中的数据和标签保存到多种文件类型,包括 CSV、Excel、SQL、JSON 等,也可以从多种文件类型加载数据和标签。这是一个非常强大的功能。
(一)参数 path_or_buf(必填)
作用:指定文件路径或文件对象。
您可以使用以下方法将求职者 DataFrame 保存为CSV文件:
>>> df.to_csv('data.csv')上述语句将在您的工作目录中生成一个名为的CSV 文件‘data.csv’。
(二)参数 columns (默认: None)
作用: 指定要保存的列。
df.to_csv('output.csv', columns=['col1', 'col2']) # 只保存 'col1' 和 'col2' 列(三)编码相关参数 encoding (默认: 'utf-8')
作用: 指定文件的编码格式。
df.to_csv('output.csv', encoding='gbk') # 使用 GBK 编码保存文件 (四)参数index (默认: True)
作用: 控制是否保存行索引。
示例Data Frame:
import pandas as pd
data = {'Title': ['Title 1', 'Title 2', 'Title 3']}
df = pd.DataFrame(data)
print(df)
输出Data Frame:
Title
0 Title 1
1 Title 2
2 Title 3
这里的 0, 1, 2 是 Pandas 自动生成的索引(行号)。
情况 1:保存索引(默认,index=True)
df.to_csv('output_with_index.csv', index=True)
生成的 .csv 文件内容:
,Title
0,Title 1
1,Title 2
2,Title 3
情况 2:不保存索引(index=False)
df.to_csv('output_without_index.csv', index=False)
生成的 .csv 文件内容:
Title
Title 1
Title 2
Title 3
索引(0,1,2)没有被保存,只有 Title 这一列数据。
六、read_csv函数
read_csv() 是 pandas 中用来读取 CSV 文件并将其转换为 DataFrame 的常用函数。它的基本作用是将 CSV 格式的文件加载到内存中,便于后续的分析和处理。
(一)基础用法
示例:读取 CSV 文件并显示前几行
import pandas as pd
df = pd.read_csv('your_file.csv', encoding='utf-8-sig')
print(df.head()) # 显示前五行数据
(二)参数sep
示例:指定分隔符(例如 tab 键),默认为逗号。
df = pd.read_csv('your_file.tsv', sep='\t', encoding='utf-8-sig')
(三)参数names
如果 CSV 文件没有列名,可以通过 names 参数传入列名列表。
示例:设置列名
df = pd.read_csv('your_file.csv', names=['Name', 'Age', 'City'], encoding='utf-8-sig')
(四)参数usecols
只读取指定的列,适用于文件非常大时,减少内存消耗。可以传入列名列表或列的索引。
示例:只读取指定的列
df = pd.read_csv('your_file.csv', usecols=['Name', 'Age'], encoding='utf-8-sig')