目录
代码修改基于NLP09-朴素贝叶斯问句分类(3/3)
一、导入 SVM 相关库
from sklearn.svm import SVC # 导入 SVM二、修改模型初始化
# 模型训练
def train_model(self):
self.to_vect()
# 使用 SVM 替换朴素贝叶斯
svm_model = SVC(kernel='linear', C=1.0) # 线性核函数,C 是正则化参数
svm_model.fit(self.train_vec, self.train_y)
self.model = svm_model详细解释SVM
# 使用 SVM 替换朴素贝叶斯 svm_model = SVC(kernel='linear', C=1.0) # 线性核函数,C 是正则化参数


三、比较
性能评估指标主要是:准确性、精确率、召回率、F1-Score
朴素贝叶斯分类器
为了进行性能评估,我们需要使用 train_test_split 来分割数据集,并使用 sklearn.metrics 来计算准确性、精确率、召回率和 F1-Score。下面是修改后的完整代码,包含了数据集划分和各项评估指标的计算:
import os.path
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from common import constant
from ch import data_loader, nlp_util
class QuestionClassify:
def __init__(self):
self.train_x = None
self.train_y = None
self.tfidf_vec = None
self.train_vec = None
self.model = None
self.question_category_dict = None
# 文本向量化
def to_vect(self):
if self.tfidf_vec is None:
# 加载训练数据
self.train_x, self.train_y = data_loader.load_train_data()
# 初始化一个Tfidf
self.tfidf_vec = TfidfVectorizer()
# 确保 self.train_x 是字符串列表
if isinstance(self.train_x[0], list):
self.train_x = [" ".join(doc) for doc in self.train_x]
self.train_vec = self.tfidf_vec.fit_transform(self.train_x).toarray()
# 模型训练
def train_model(self):
self.to_vect()
# 使用 train_test_split 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(self.train_vec, self.train_y, test_size=0.2, random_state=42)
# 使用朴素贝叶斯模型
nb_model = MultinomialNB(alpha=0.01)
nb_model.fit(X_train, y_train) # 训练模型
self.model = nb_model
# 预测并计算评估指标
y_pred = self.model.predict(X_test)
# 计算并打印评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1-Score: {f1:.4f}")
# 模型预测
def predict(self, question):
# 词性标注做电影相关实体的抽取
question_cut = nlp_util.movie_pos(question)
# 原问句列表(刘德华演过哪些电影)
question_src_list = []
# 转换后的问句(nr演过哪些电影)
question_pos_list = []
for item in question_cut:
question_src_list.append(item.word)
if item.flag in ['nr', 'nm', 'nnt']:
question_pos_list.append(item.flag)
else:
question_pos_list.append(item.word)
question_pos_text = [" ".join(question_pos_list)]
# 文本向量化
question_vect = self.tfidf_vec.transform(question_pos_text).toarray()
# 输入模型进行预测,得到结果
predict = self.model.predict(question_vect)[0]
return predict
def init_question_category_dict(self):
# 读取问题(类别-描述)映射文件
question_category_path = os.path.join(constant.DATA_DIR, "question_classification.txt")
with open(question_category_path, "r", encoding="utf-8") as file:
question_category_list = file.readlines()
self.question_category_dict = {}
for category_item in question_category_list:
category_id, category_desc = category_item.strip().split(":")
self.question_category_dict[int(category_id)] = category_desc
def get_question_desc(self, category):
if self.question_category_dict is None:
self.init_question_category_dict()
return self.question_category_dict[category]
if __name__ == "__main__":
classify = QuestionClassify()
classify.train_model() # 训练模型并打印评估指标
result = classify.predict("刘德华和成龙合作演过哪些电影呢?&&")
print(classify.get_question_desc(result))
print(result)
修改代码解析:
# 使用 train_test_split 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(self.train_vec, self.train_y, test_size=0.2, random_state=42)详见 NLP06-Scikit-Learn 机器学习库(鸢尾花为例)的数据集拆分部分。
# 预测并计算评估指标 y_pred = self.model.predict(X_test) # 计算并打印评估指标 accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted')这几个指标是常用的分类模型评估指标。
(1) 准确率(Accuracy)
(2) 精确率(Precision)
(3) 召回率(Recall)
(4) F1-Score






输出结果:

SVM分类器
import os.path
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC # 导入 SVM
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from common import constant
from ch import data_loader, nlp_util
class QuestionClassify:
def __init__(self):
self.train_x = None
self.train_y = None
self.tfidf_vec = None
self.train_vec = None
self.model = None
self.question_category_dict = None
# 文本向量化
def to_vect(self):
if self.tfidf_vec is None:
# 加载训练数据
self.train_x, self.train_y = data_loader.load_train_data()
# 初始化一个Tfidf
self.tfidf_vec = TfidfVectorizer()
# 确保 self.train_x 是字符串列表
if isinstance(self.train_x[0], list):
self.train_x = [" ".join(doc) for doc in self.train_x]
self.train_vec = self.tfidf_vec.fit_transform(self.train_x).toarray()
# 模型训练
def train_model(self):
self.to_vect()
# 使用 train_test_split 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(self.train_vec, self.train_y, test_size=0.2, random_state=42)
# 使用 SVM(支持向量机)替换朴素贝叶斯
svm_model = SVC(kernel='linear', C=1.0) # 线性核函数,C 是正则化参数
svm_model.fit(X_train, y_train) # 训练模型
self.model = svm_model
# 预测并计算评估指标
y_pred = self.model.predict(X_test)
# 计算并打印评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted', zero_division=0)
recall = recall_score(y_test, y_pred, average='weighted', zero_division=0)
f1 = f1_score(y_test, y_pred, average='weighted')
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1-Score: {f1:.4f}")
# 模型预测
def predict(self, question):
# 词性标注做电影相关实体的抽取
question_cut = nlp_util.movie_pos(question)
# 原问句列表(刘德华演过哪些电影)
question_src_list = []
# 转换后的问句(nr演过哪些电影)
question_pos_list = []
for item in question_cut:
question_src_list.append(item.word)
if item.flag in ['nr', 'nm', 'nnt']:
question_pos_list.append(item.flag)
else:
question_pos_list.append(item.word)
question_pos_text = [" ".join(question_pos_list)]
# 文本向量化
question_vect = self.tfidf_vec.transform(question_pos_text).toarray()
# 输入模型进行预测,得到结果
predict = self.model.predict(question_vect)[0]
return predict
def init_question_category_dict(self):
# 读取问题(类别-描述)映射文件
question_category_path = os.path.join(constant.DATA_DIR, "question_classification.txt")
with open(question_category_path, "r", encoding="utf-8") as file:
question_category_list = file.readlines()
self.question_category_dict = {}
for category_item in question_category_list:
category_id, category_desc = category_item.strip().split(":")
self.question_category_dict[int(category_id)] = category_desc
def get_question_desc(self, category):
if self.question_category_dict is None:
self.init_question_category_dict()
return self.question_category_dict[category]
if __name__ == "__main__":
classify = QuestionClassify()
classify.train_model() # 训练模型并打印评估指标
result = classify.predict("刘德华和成龙合作演过哪些电影呢?&&")
print(classify.get_question_desc(result))
print(result)
输出结果:
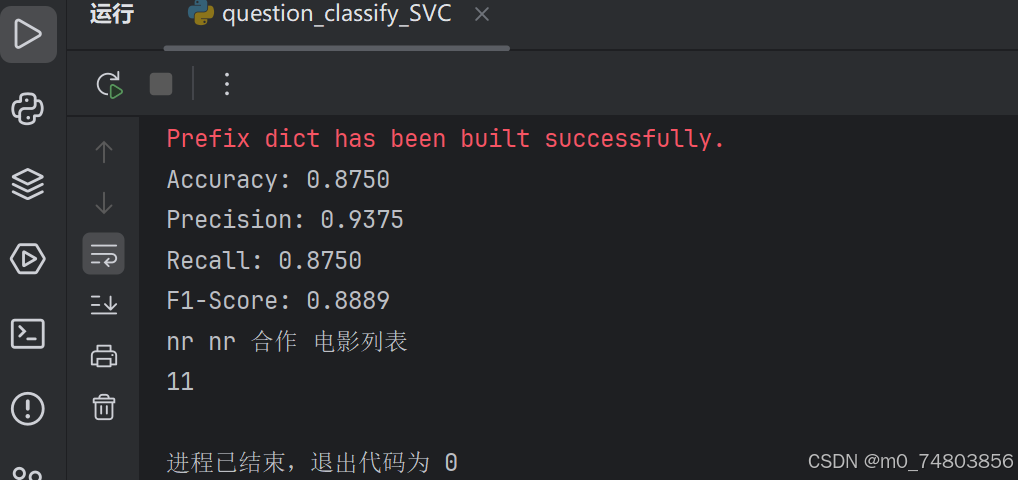
朴素贝叶斯表现更好,可能原因如下:
- 数据集较小:如果数据集较小,朴素贝叶斯可能会比 SVM 表现更好,因为 SVM 需要更多的数据来找到最优超平面。
- 特征独立性假设成立:在文本分类任务中,词语之间的独立性假设可能并不会显著影响朴素贝叶斯的性能。
- 参数调优不当:如果 SVM 的参数(如 C、kernel、gamma)没有调优好,性能可能会较差。
- 类别分布均衡:如果数据集的类别分布较为均衡,朴素贝叶斯的性能可能会更好。
四、改进SVM
主要进行核函数的选择与超参数调整。
1. 核函数的选择
在这个分类任务中,选择比较linear和rbf两个,原因如下:
- 由于 TF-IDF 处理后的文本数据本质上是高维稀疏向量,理论上可能是线性可分的,因此 linear 核可能表现不错。
- 但如果数据分布复杂,rbf 核可以更灵活地找到分类边界。
2. 超参数调整
在超参数搜索时:
- 如果 C 太小(如 0.0001),可能会导致欠拟合,模型的目标是最大化间隔,这意味着模型会倾向于选择一个非常简单的决策边界(如几乎是一条直线),模型无法正确分类。
- 如果 C 太大(如 1000),可能会导致过拟合,模型的目标是尽可能正确分类所有训练样本,而对最大化间隔的惩罚很小,这意味着模型会倾向于选择一个非常复杂的决策边界(如弯曲的曲线)即对训练集表现很好,但泛化能力下降。
过拟合和欠拟合参见 【理解机器学习中的过拟合与欠拟合】
在实际应用中,可以使用 网格搜索(Grid Search)或贝叶斯优化 来选择更精确的 C 值。
网格的比喻
-
网格:想象一个二维表格,其中每一行代表一个超参数的不同取值,每一列代表另一个超参数的不同取值。这些行和列交叉形成的点就是所有可能的参数组合。
本文采用网络搜索:
主要修改代码部分:
# SVM 参数调优
svm_param_grid = {'C': [0.1, 1, 10, 100], 'kernel': ['linear', 'rbf']}
grid_search = GridSearchCV(SVC(), svm_param_grid, cv=4, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
print(f"Best SVM parameters: {grid_search.best_params_}")
self.model = grid_search.best_estimator_逐行解释代码:
svm_param_grid = {'C': [0.1, 1, 10, 100], 'kernel': ['linear', 'rbf']}GridSearchCV 是 sklearn.model_selection 提供的 超参数搜索工具,它会遍历你提供的所有参数组合,找出最优的超参数,使得模型在交叉验证中表现最好。
grid_search = GridSearchCV(SVC(), svm_param_grid, cv=4, scoring='accuracy', n_jobs=-1)
什么是 K 折交叉验证(K-Fold Cross Validation)?
在 GridSearchCV 中,cv=4 代表 4 折交叉验证,具体过程如下:
- 将训练数据分成 4 份(即 4 份子集)。
- 进行 4 轮训练:
- 取 3 份数据训练模型,剩下 1 份数据测试模型。
- 依次轮换,保证每个数据点都被用于测试一次。
- 计算 4 轮的平均准确率,作为该超参数组合的最终分数。
这样做的好处:
- 避免模型 只对某个特定的训练集表现好,提高泛化能力。
- 使模型在所有数据上都被训练过,同时也都被测试过。

self.model = grid_search.best_estimator_将 GridSearchCV 选择出的 最优 SVM 模型 赋值给 self.model,以后 self.model 进行预测时,都是用最优参数的 SVM。
完整代码:
import os.path
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC # 导入 SVM
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from common import constant
from ch import data_loader, nlp_util
class QuestionClassify:
def __init__(self):
self.train_x = None
self.train_y = None
self.tfidf_vec = None
self.train_vec = None
self.model = None
self.question_category_dict = None
# 文本向量化
def to_vect(self):
if self.tfidf_vec is None:
self.train_x, self.train_y = data_loader.load_train_data()
self.tfidf_vec = TfidfVectorizer()
if isinstance(self.train_x[0], list):
self.train_x = [" ".join(doc) for doc in self.train_x]
self.train_vec = self.tfidf_vec.fit_transform(self.train_x).toarray()
# 模型训练
def train_model(self):
self.to_vect()
X_train, X_test, y_train, y_test = train_test_split(self.train_vec, self.train_y, test_size=0.2, random_state=42)
# SVM 参数调优
svm_param_grid = {'C': [0.1, 1, 10, 100], 'kernel': ['linear', 'rbf']}
grid_search = GridSearchCV(SVC(), svm_param_grid, cv=4, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
print(f"Best SVM parameters: {grid_search.best_params_}")
self.model = grid_search.best_estimator_
# 预测并计算评估指标
y_pred = self.model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted', zero_division=0)
recall = recall_score(y_test, y_pred, average='weighted', zero_division=0)
f1 = f1_score(y_test, y_pred, average='weighted')
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1-Score: {f1:.4f}")
# 模型预测
def predict(self, question):
question_cut = nlp_util.movie_pos(question)
question_src_list = []
question_pos_list = []
for item in question_cut:
question_src_list.append(item.word)
if item.flag in ['nr', 'nm', 'nnt']:
question_pos_list.append(item.flag)
else:
question_pos_list.append(item.word)
question_pos_text = [" ".join(question_pos_list)]
question_vect = self.tfidf_vec.transform(question_pos_text).toarray()
predict = self.model.predict(question_vect)[0]
return predict
def init_question_category_dict(self):
question_category_path = os.path.join(constant.DATA_DIR, "question_classification.txt")
with open(question_category_path, "r", encoding="utf-8") as file:
question_category_list = file.readlines()
self.question_category_dict = {}
for category_item in question_category_list:
category_id, category_desc = category_item.strip().split(":")
self.question_category_dict[int(category_id)] = category_desc
def get_question_desc(self, category):
if self.question_category_dict is None:
self.init_question_category_dict()
return self.question_category_dict[category]
if __name__ == "__main__":
classify = QuestionClassify()
classify.train_model()
result = classify.predict("刘德华和成龙合作演过哪些电影呢?")
print(classify.get_question_desc(result))
print(result)
最终结果:
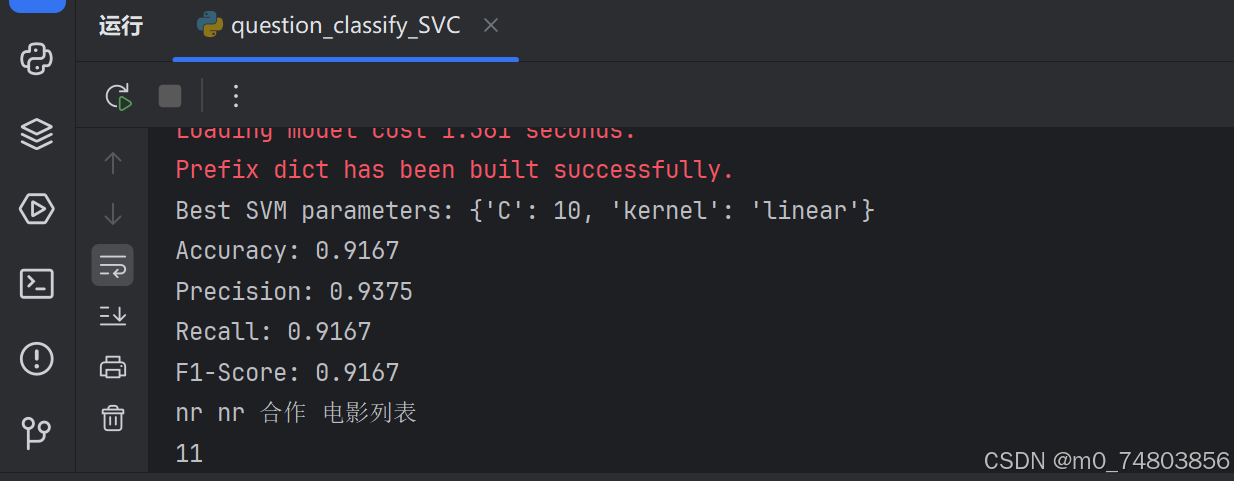
五、结果分析
可以观察到,本例中朴素贝叶斯分类器效果更好,以下为可能的原因:
1. 数据集特点
-
小数据集:朴素贝叶斯在小数据集上表现良好,因为它基于概率统计,对数据量的要求较低。
-
高维稀疏数据:虽然 SVM 通常在高维稀疏数据上表现良好,但如果数据维度非常高(如文本数据中的 TF-IDF 向量),朴素贝叶斯的独立性假设可能并不会显著影响其性能。
为什么TF-IDF向量是高维稀疏数据?
举例:高维 vs 低维
假设你的语料库只有 5 个不同的单词:
["电影", "演员", "导演", "票房", "影评"]那么,每个文本的 TF-IDF 向量就只有 5 维,比如:
"电影票房很好" → [0.8, 0, 0, 0.5, 0]这就属于 低维数据(5 维)。
但如果你的语料库有 10,000 个不同的单词:
["电影", "演员", "导演", ..., "爆米花", "电影院"]那么向量就变成 10,000 维:
"电影票房很好" → [0.8, 0, 0, 0.5, 0, ..., 0, 0, 0]其中大部分值都是 0,所以叫高维稀疏数据。

2. 模型假设
-
朴素贝叶斯的独立性假设:虽然朴素贝叶斯假设特征之间独立,但在文本分类任务中,词语之间的独立性假设可能并不会显著影响性能。
-
SVM 的间隔最大化:SVM 的目标是找到一个最优超平面,最大化两类数据之间的间隔。如果数据分布复杂或非线性可分,SVM 的性能可能会下降。
如何判断文本数据是否线性可分?
(1)训练一个线性 SVM
- 先用 线性核(linear)训练 SVM 。
- 观察 SVM 训练后的 准确率:
- 如果准确率很高(接近 100%),说明数据可能是线性可分的。
- 如果准确率很低,说明数据可能是非线性可分的。
在本例中显然是非线性可分的。
(2)降维 + 可视化
- 使用 PCA(主成分分析) 或 t-SNE 降维,把高维数据降到 2D 或 3D 。
- 画出 2D/3D 散点图,看不同类别的数据点是否能被一条直线分开。
- 如果数据点看起来分布在两侧,可能是线性可分的。
- 如果数据点是复杂分布,缠绕在一起,就是非线性可分。
在本例中我使用了两种方法分析,得到的结果如下:
从这两个降维图来看,数据可能不是完全线性可分的。

3. 类别分布
-
类别分布均衡:如果数据集的类别分布较为均衡,朴素贝叶斯的性能可能会更好。
-
类别不平衡:如果数据集的类别分布不均衡,SVM 的性能可能会受到影响。