python学习笔记
文章目录
一、pycharm基础使用
1.修改主题
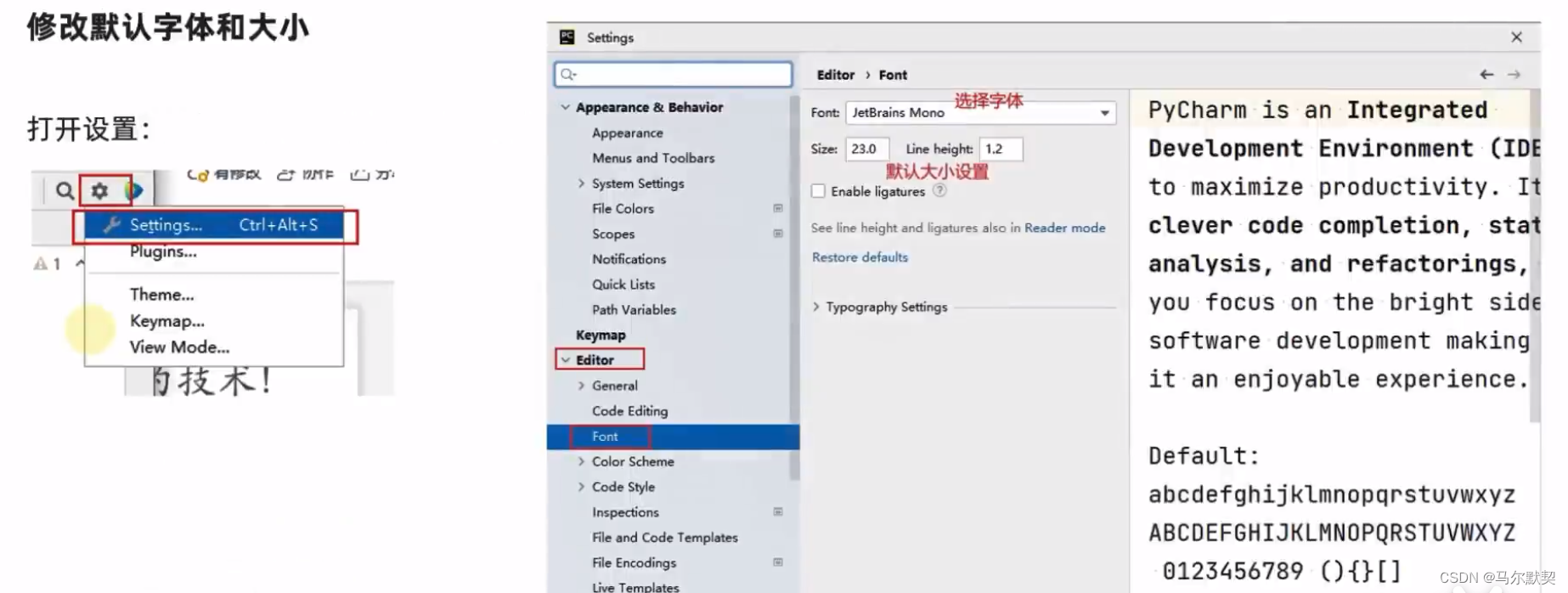
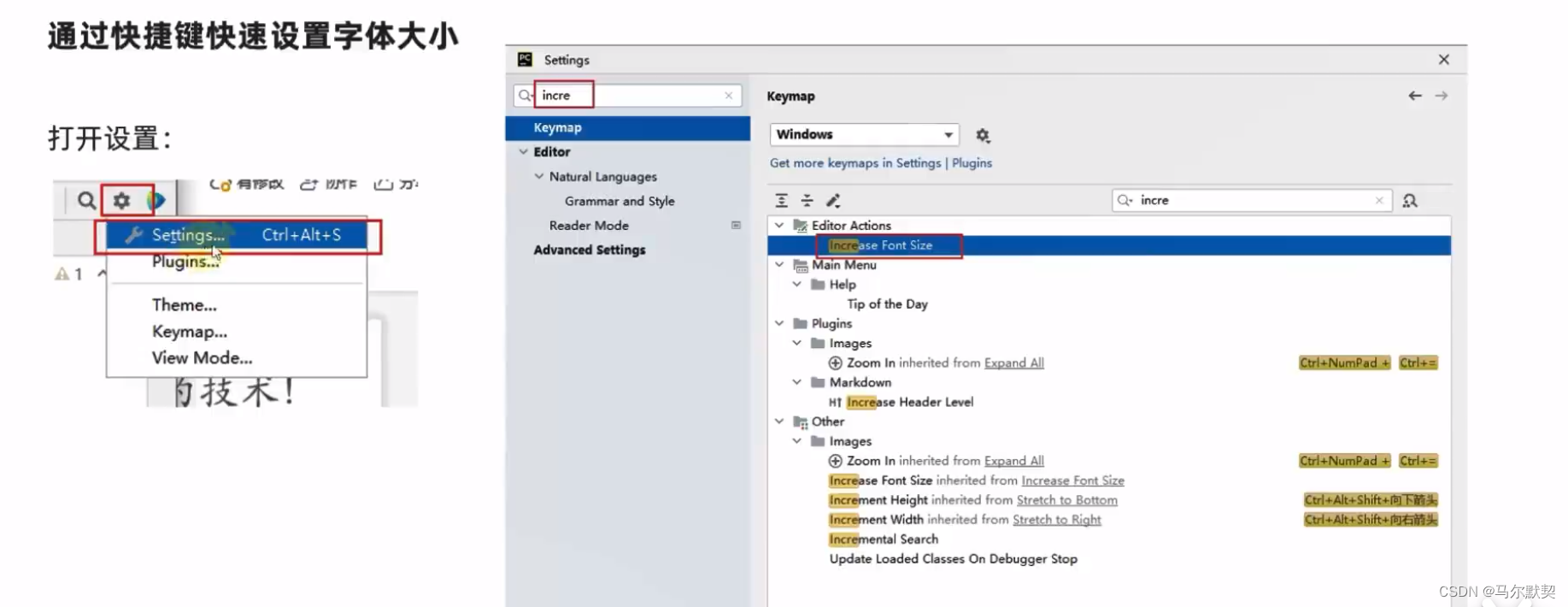
2.修改默认字体和大小
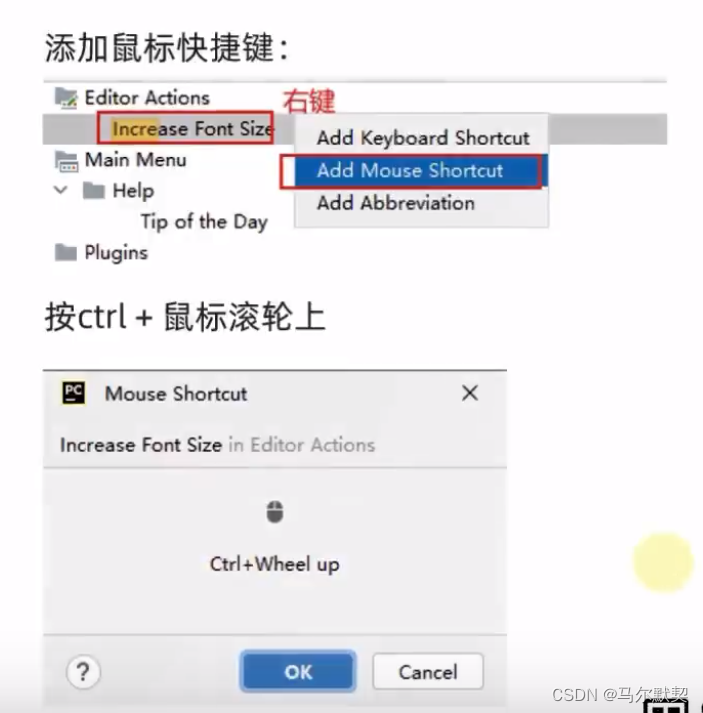
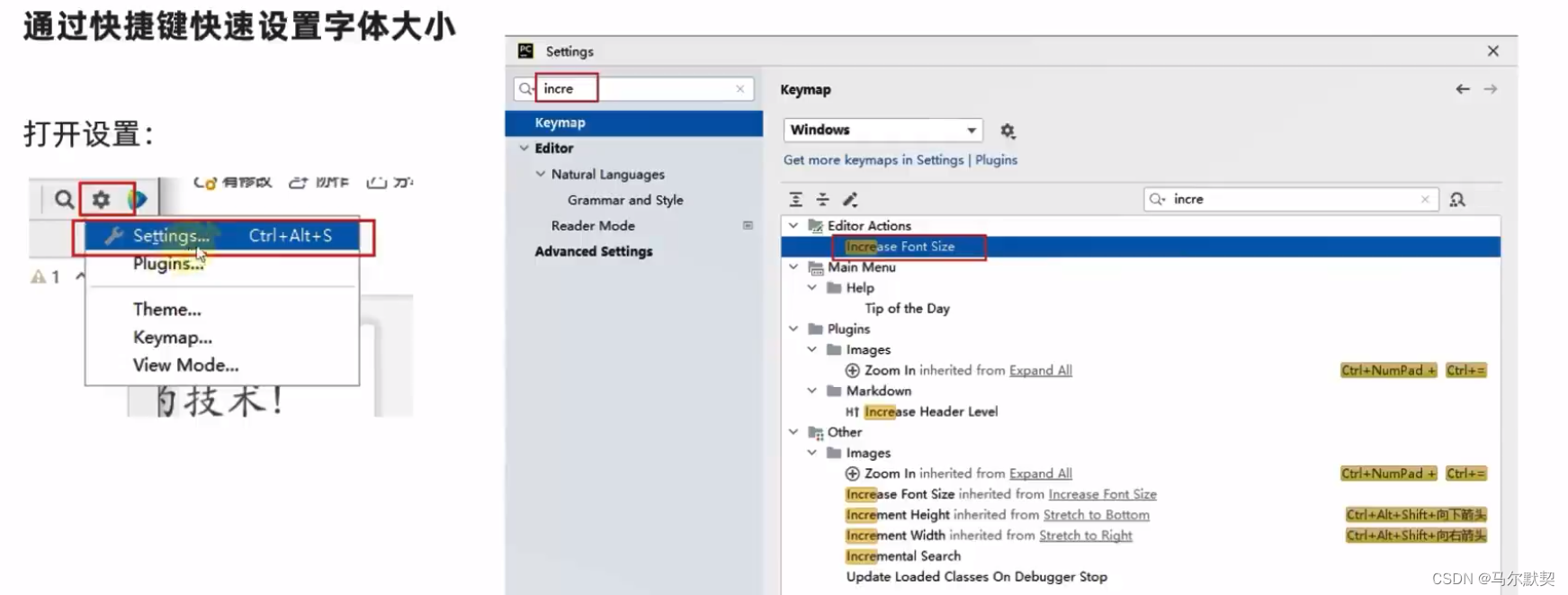
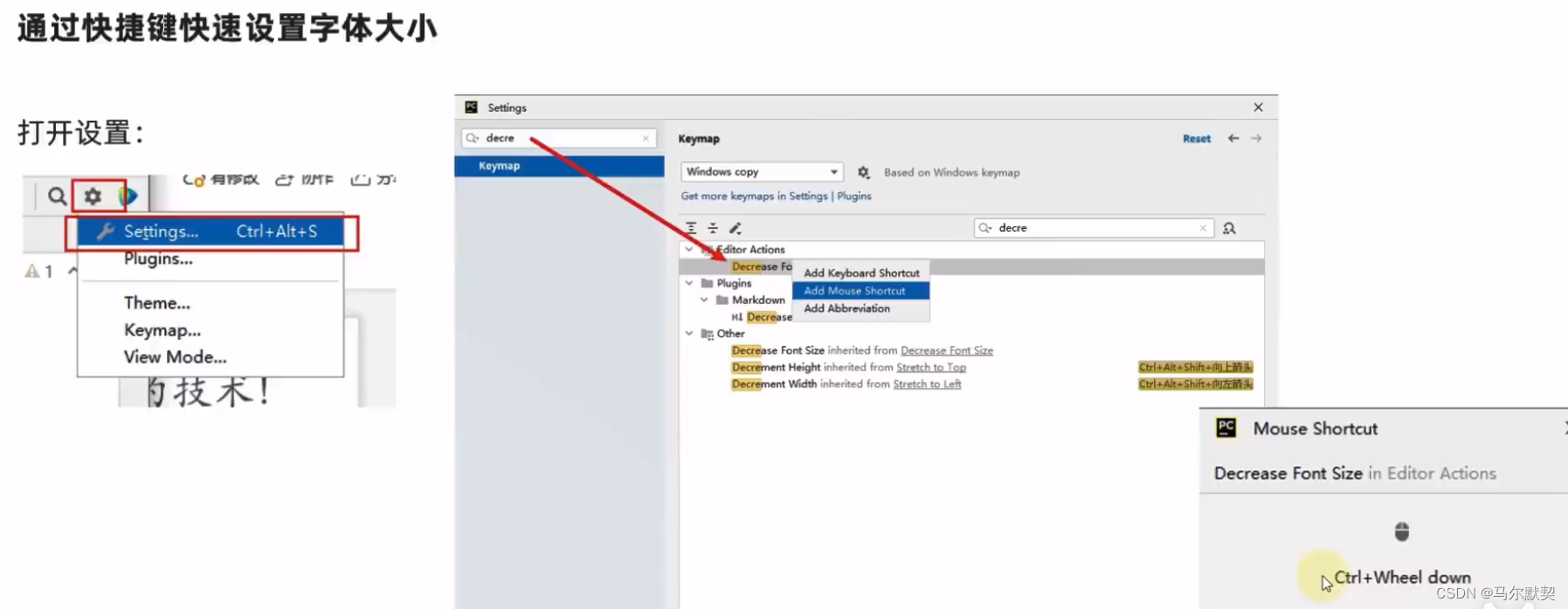
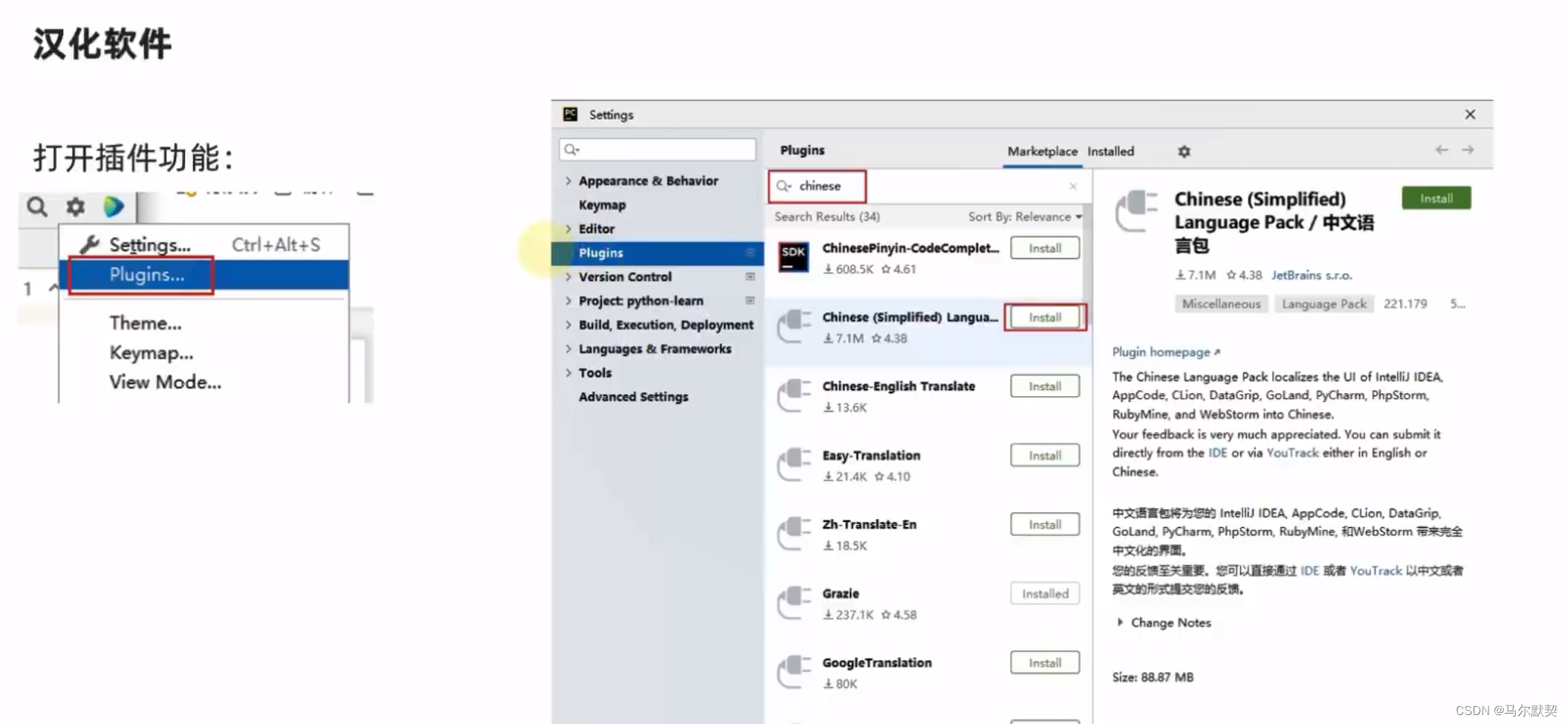
3.汉化软件(插件)
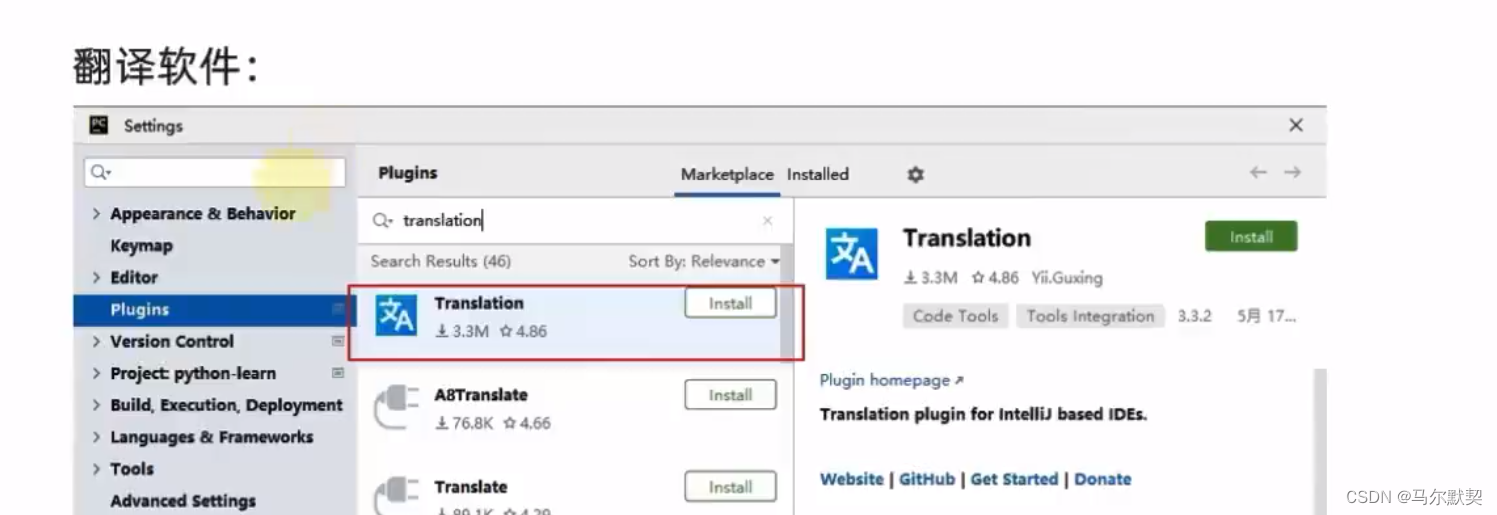
4.翻译软件(插件)
5.常用快捷键

- ctrl+/ :行注释,取消注释
- shift+alt+向上/向下: 一行代码上/下移
- ctrl+alt+L :快速校准代码格式
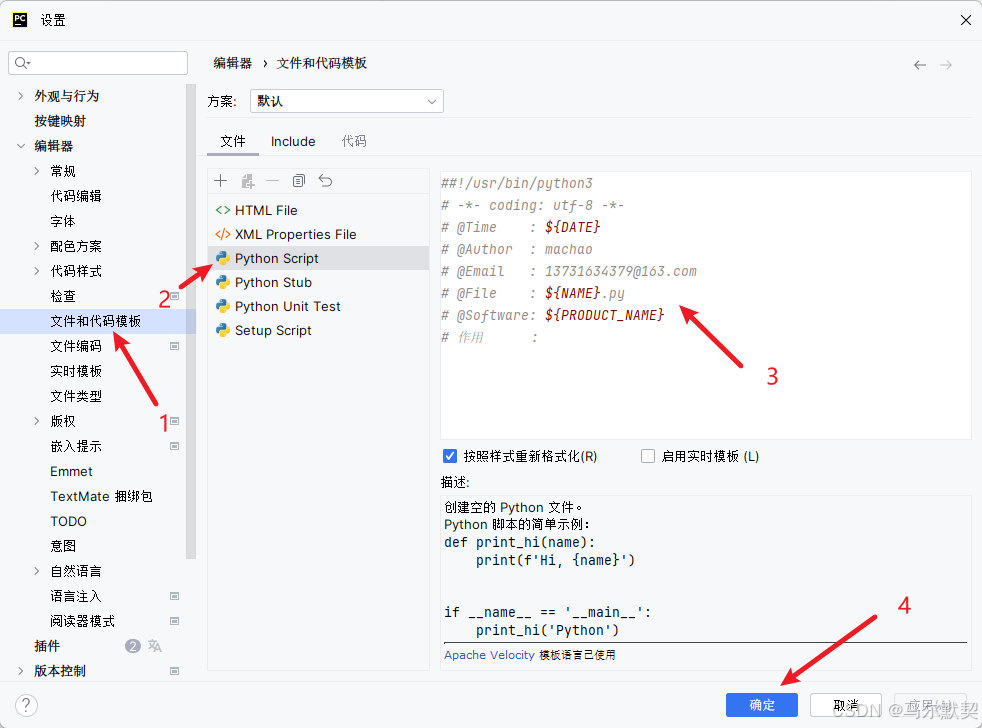
6.自动生成代码
新建文件自动生成文件介绍(作者,时间,功能)
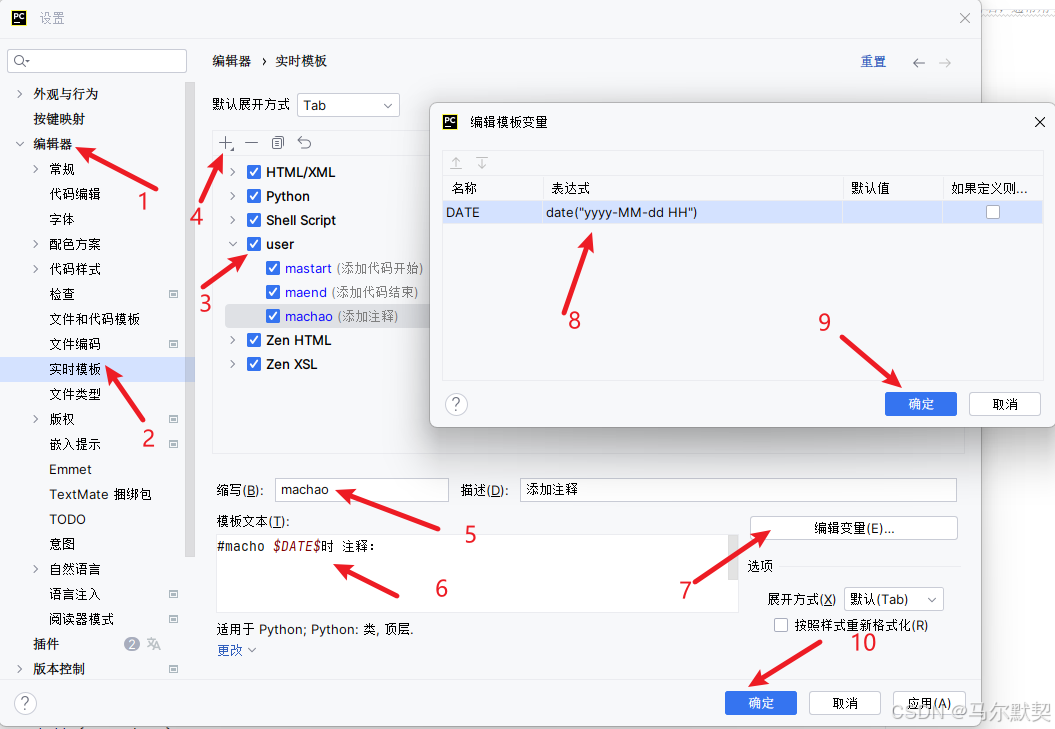
7.自动补齐代码
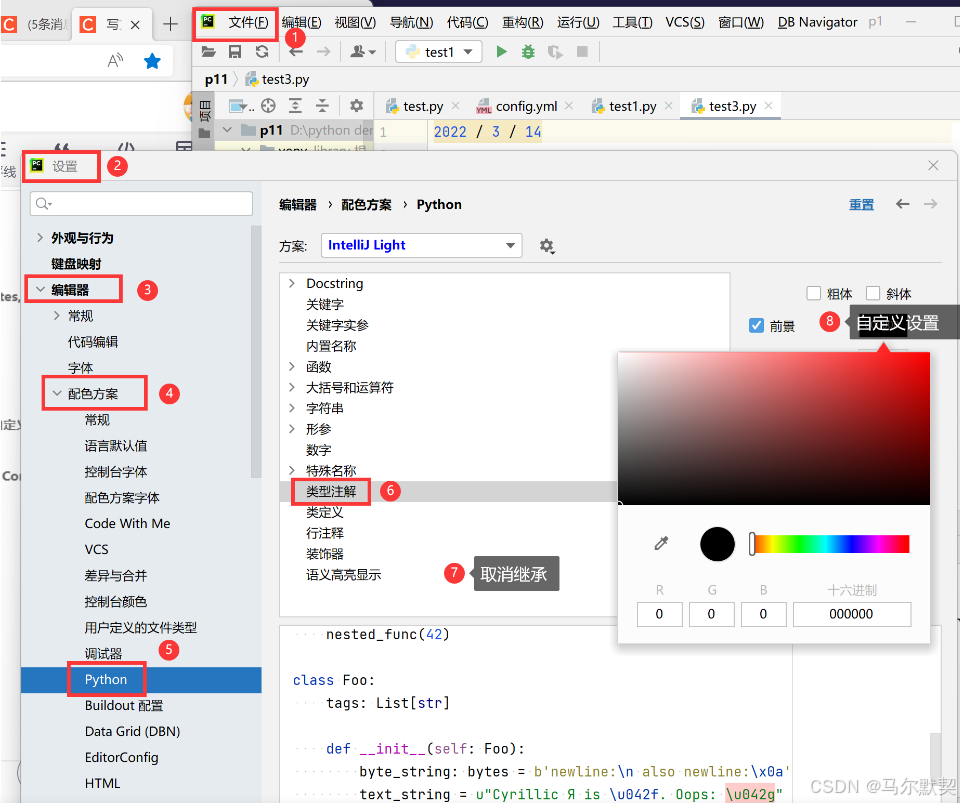
8.修改注释颜色
二、基础语法
1.字面量
1.含义
在代码中,被写下来的固定的值
2.常见类型
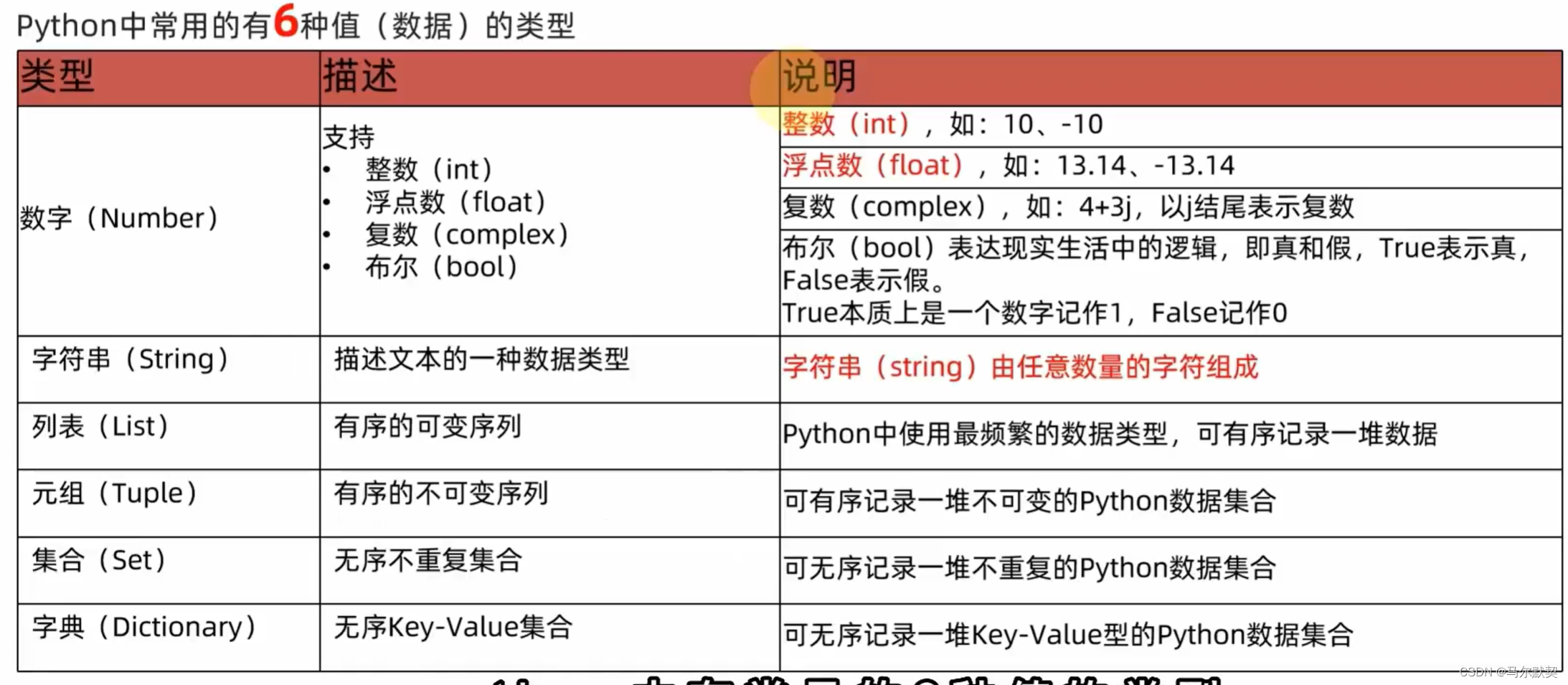
3.输出
6661
13.14
"字符串"
print(666)
print(13.14)
print("字符串")
2.注释
1.单行注释
以 # 开头
快捷键:ctrl+/
- 建议:#和注释的内容以一个空格隔开
2.多行注释
以一对三个双引号(“”“注释内容”“”)引起来的内容
快捷键:shift+" 按三次

3.变量


money=50
print("钱包还有",money)
特征:变量的值可以改变
4.数据类型
1.type()语句
使用方法:type(被查看类型的数据)
print(type(666))
print(type(3.14))
print(type("你好!"))
运行结果:

- 图中str是字符串string的缩写
int_type=666
float_type=3.14
string_type="你好!"
print(int_type)
print(float_type)
print(string_type)
//输出结果与上图一样
name="马超"
name_type=type(name)
print(name_type)
运行结果:
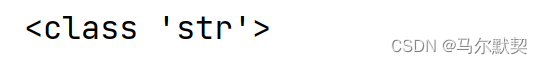
2.变量无类型而数据有类型

5.数量类型转换
运行结果:
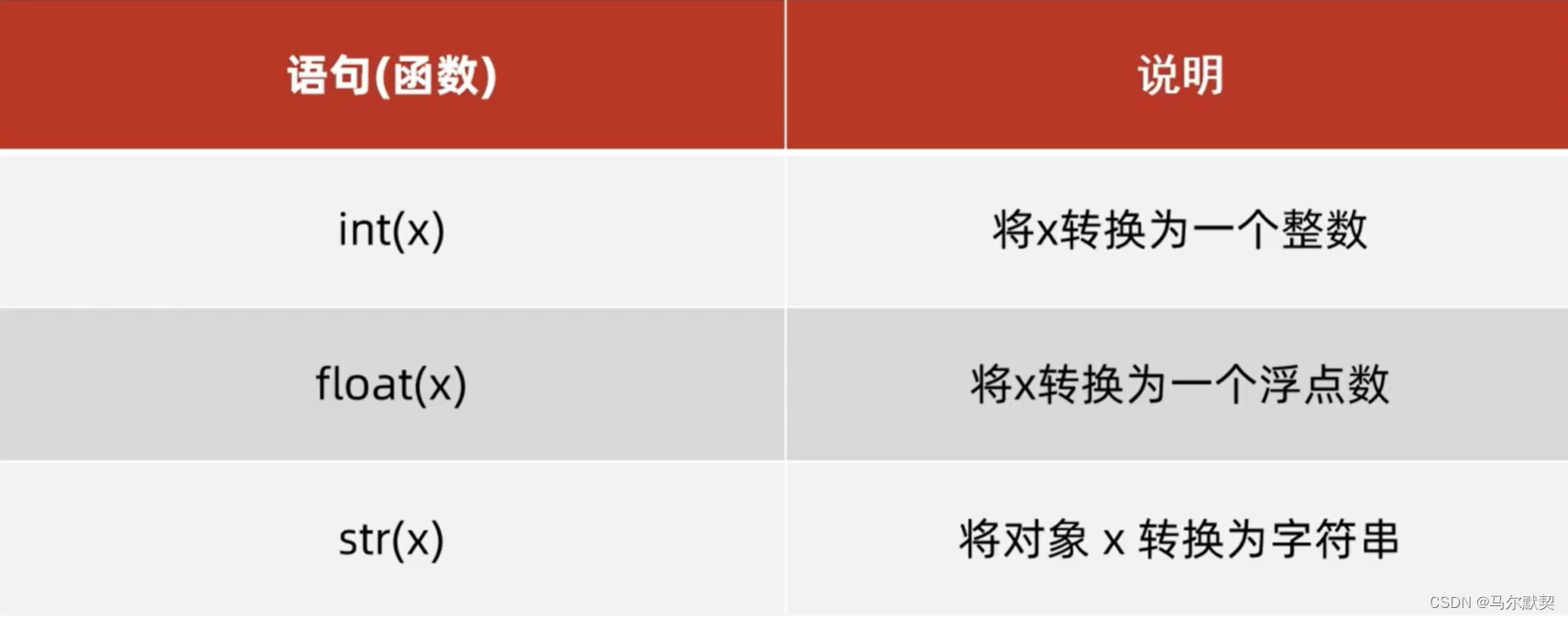
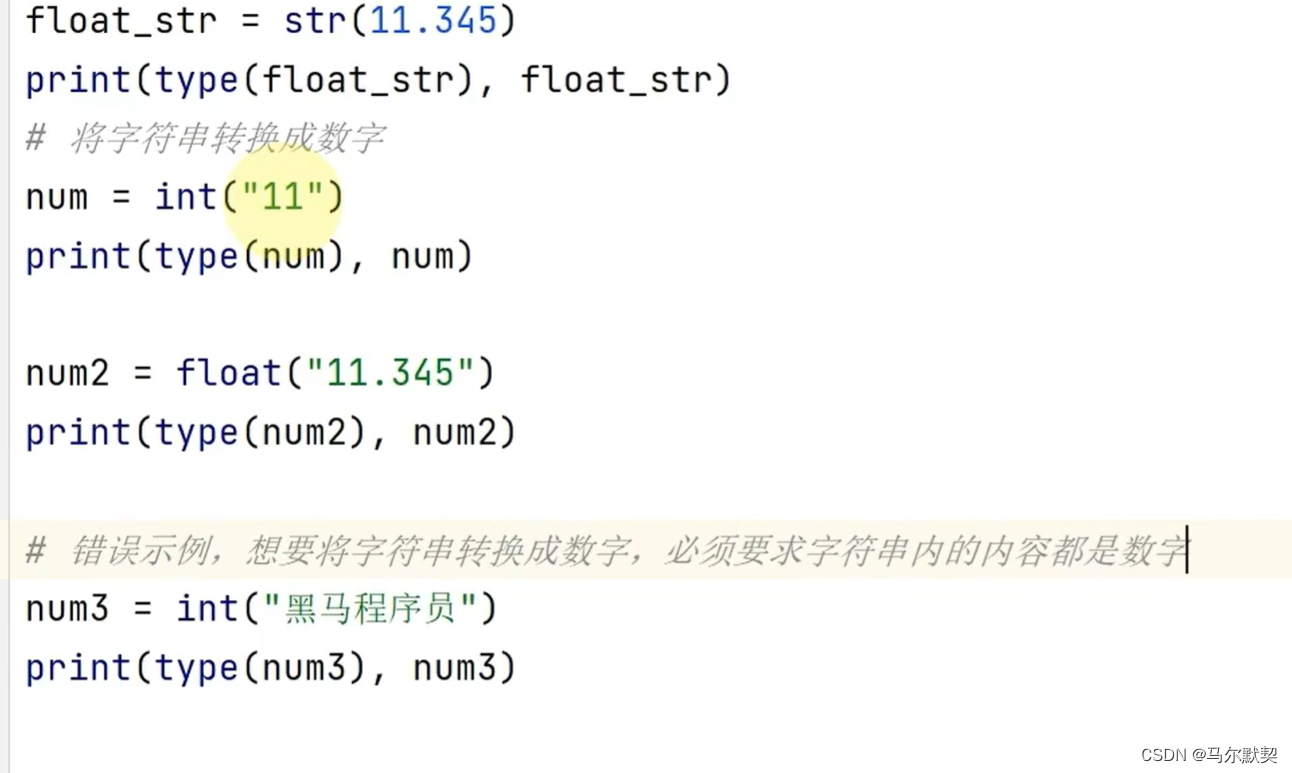
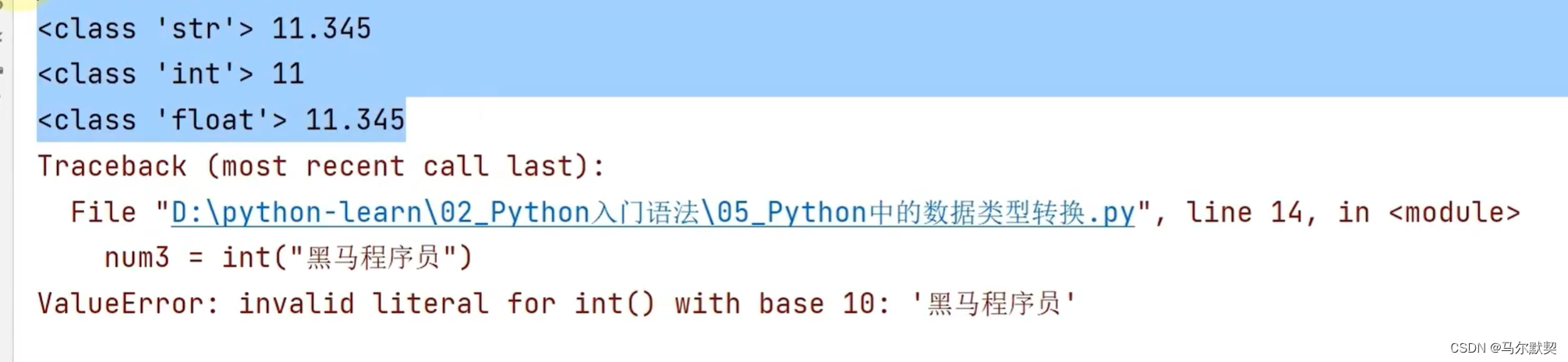
- 万物皆可转字符串但字符串转数字,要确保字符串内容全是数字才可以转
运行结果:


- 浮点数转整数会丢失精度
6.标识符
1.命名规则
- 1.只允许出现英文,中文,数字,下划线(_)这四类元素
不推荐使用中文
数字不可以用在开头- 2.大小写敏感
分别以大小写开头的变量是两个变量- 3.不可使用关键字(部分关键字如下图)
关键字同样大小写敏感

2.命名规范
规则强制要求,规范不强制要求,仅仅是建议
1.变量名
- 1.见名知意:简洁,明了
- 2.下划线命名法:多个单词组合变量名,使用下划线做分割
- 3.英文字母全小写
2.类名
3.方法名
7.运算符
1.算术(数学)运算符
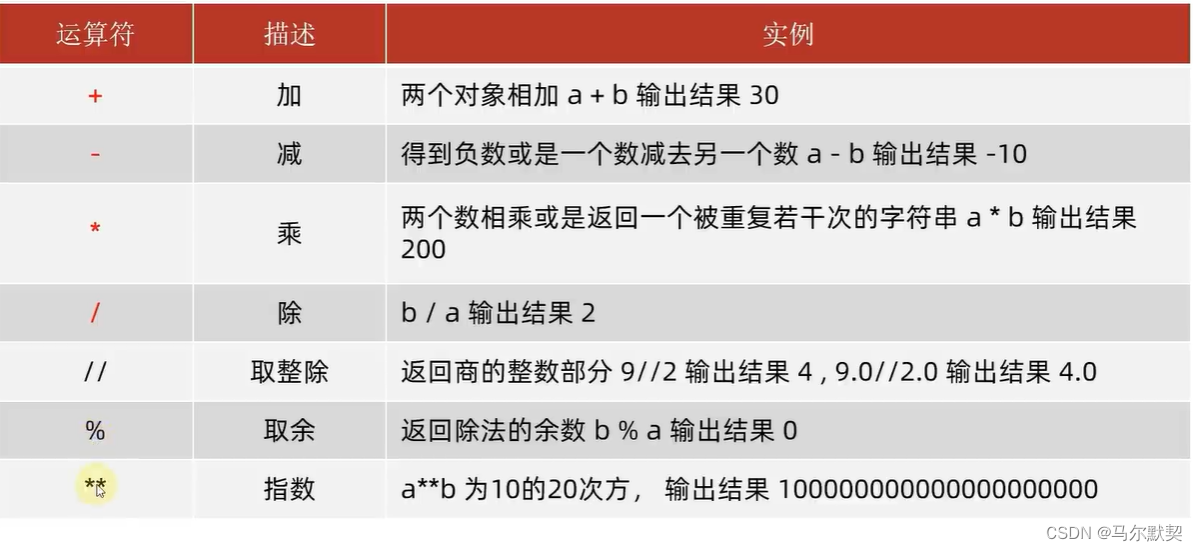
print("10/3=",10/3)
print("10//3=",10//3)
print("10%3=",10%3)
print("10**3=",10**3) #计算10的3次方
运行结果:
10/3= 3.3333333333333335
10//3= 3
10%3= 1
10**3= 1000
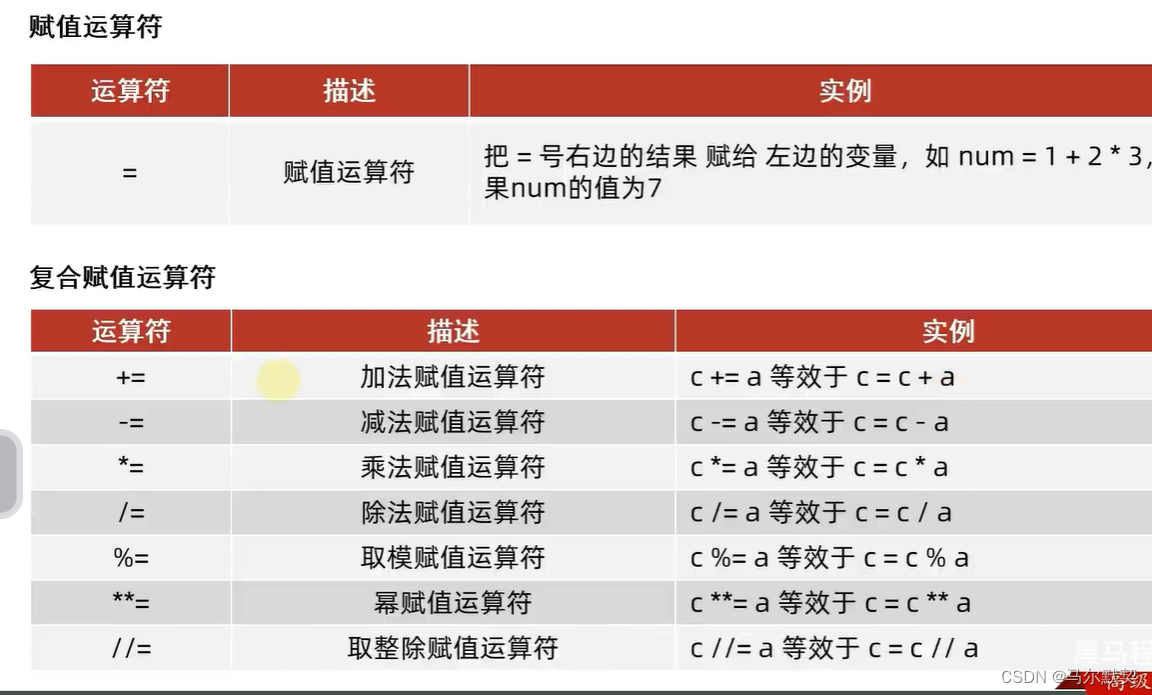
2.赋值运算符
8.字符串扩展
1.三种定义方式
字符串包含引号(引号嵌套)解决方法:


2.拼接
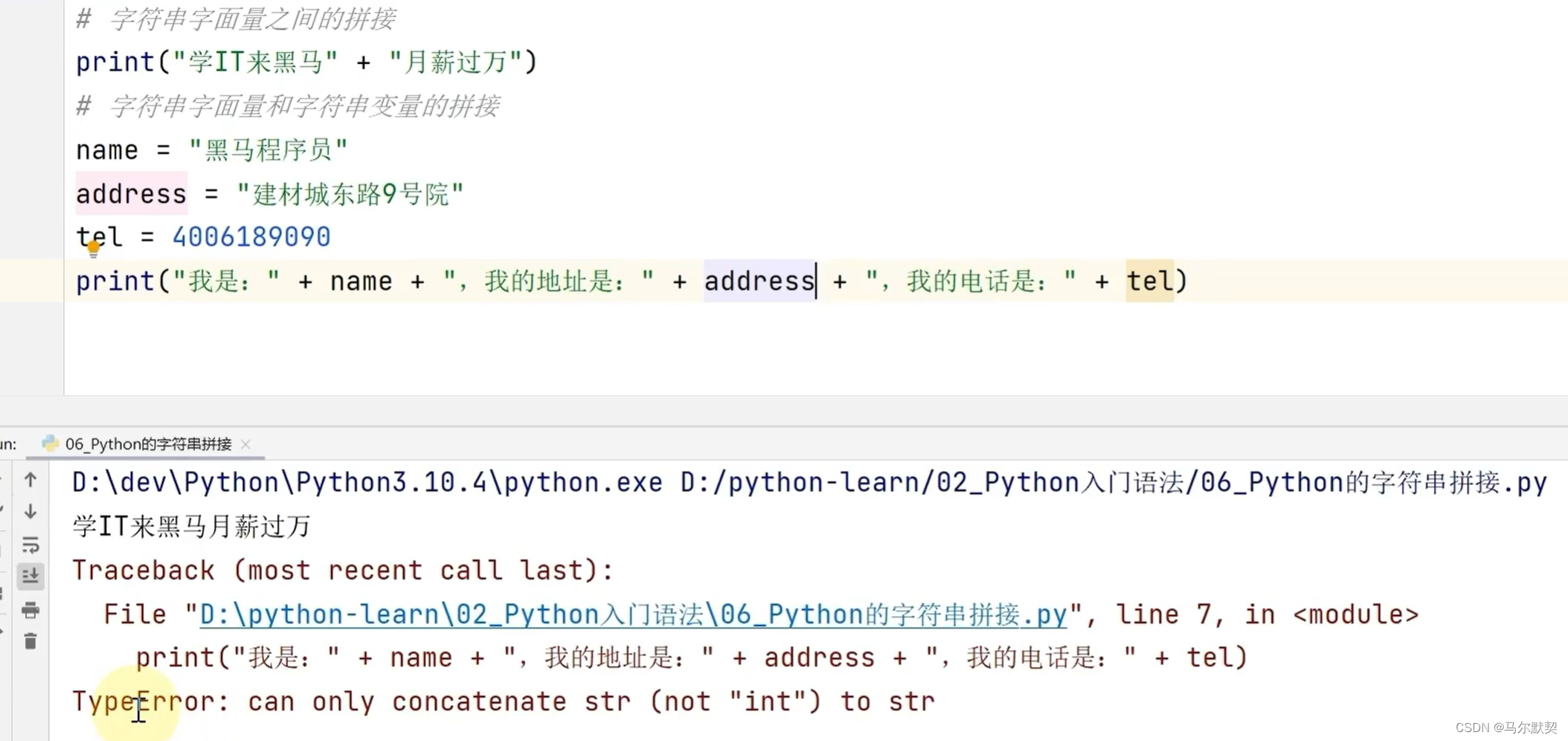
- 字符串无法使用“+”与整数,浮点数进行拼接
- 使用“+”进行拼接,只适用于字符串类型本身,无法和非字符串类型进行拼接
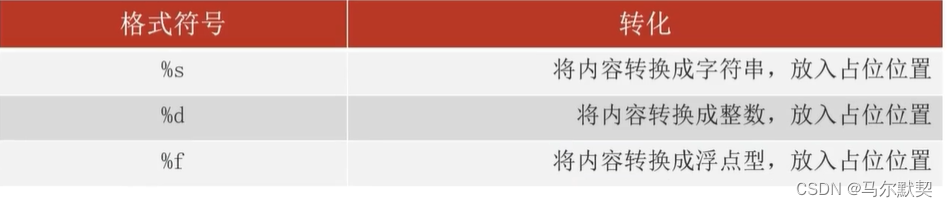
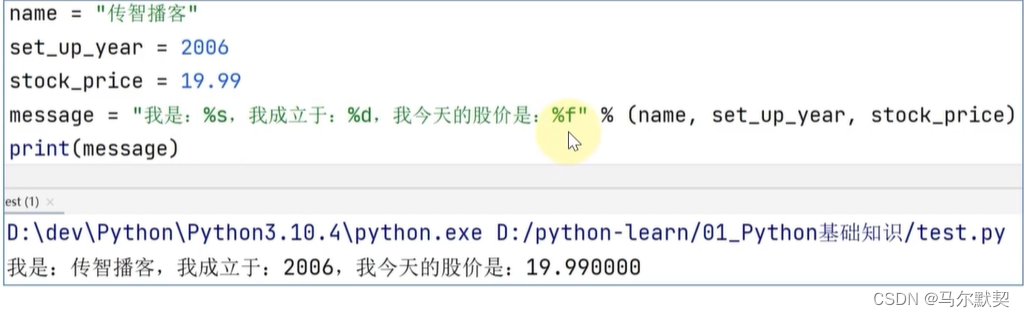
3.格式化
字符串格式化:通过占位的形式拼接字符串
此处使用%s进行占位,意思是将数据转换为字符串,然后放到%s所占位置中去

4.精度控制
数字精度控制

5.格式化方式2

- 此方法不限数据类型,也不做精度控制
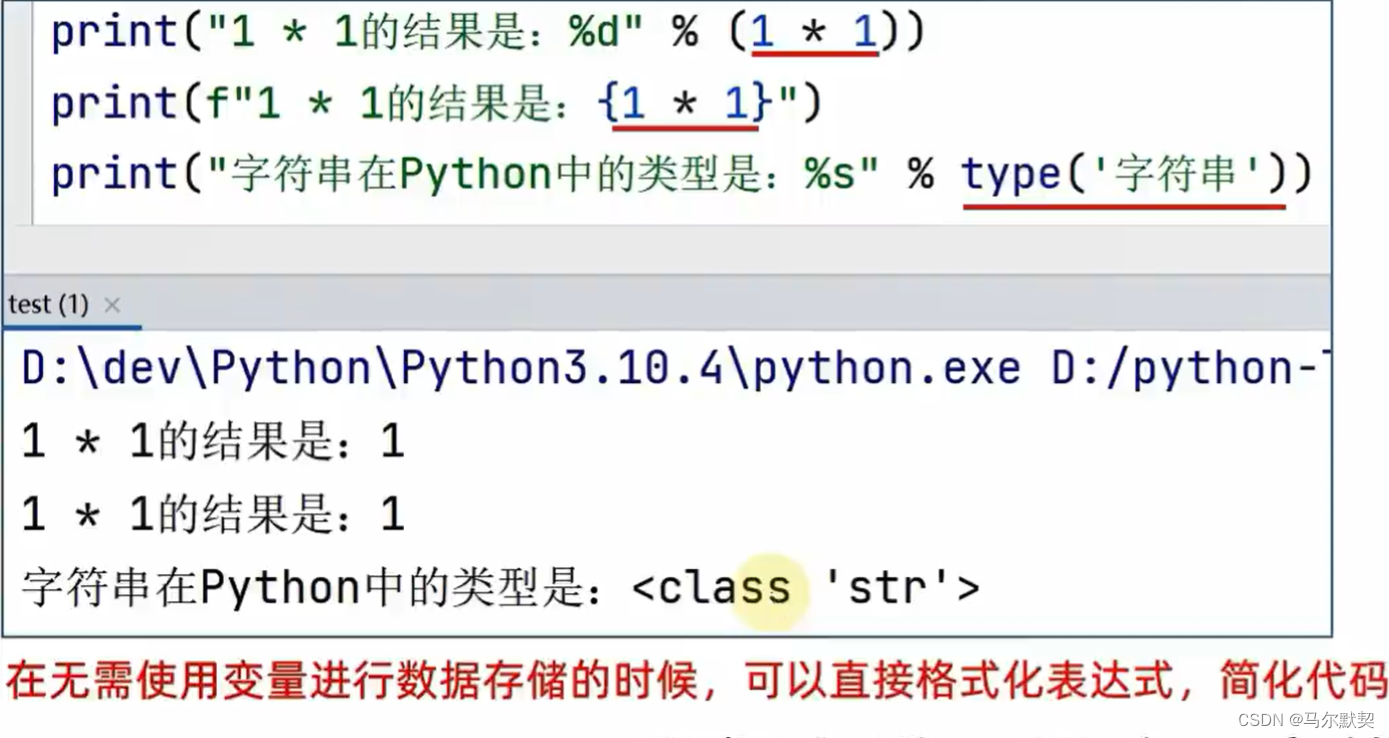
6.对表达式进行格式化
- 表达式:一条具有明确执行结果的代码语句
9.数据输入
input语句
data=input("选择排序数据规模(int):")
# 或
print("输入姓名:")
name=input()
- 无论键盘输入什么类型数据,input()接收的数据永远都是str类型,如果需要其他类型数据,需要进行转换
三、判断语句
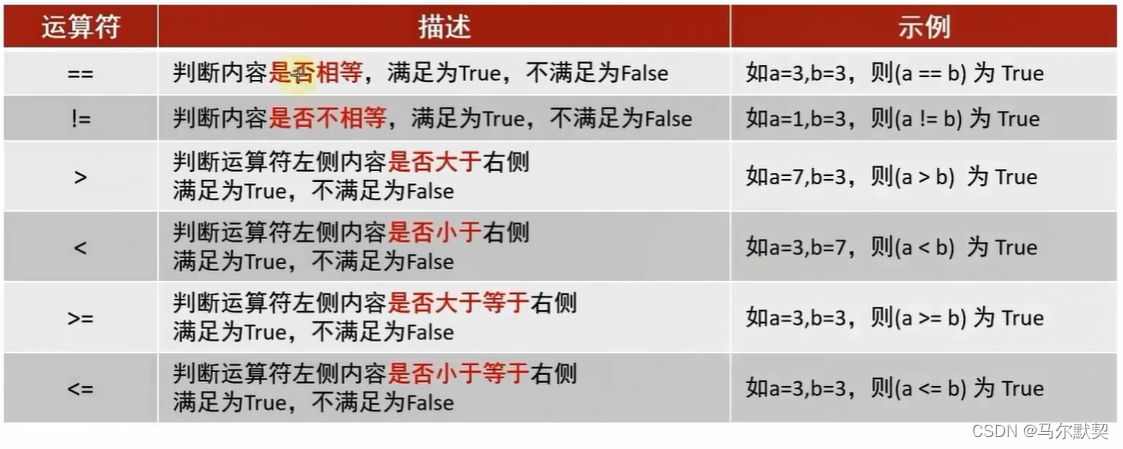
1.布尔类型和比较运算符
2.if语句

- 判断条件后面有冒号
- 执行语句为多行,前面要有缩进(四个空格(较之if所在列));若无缩进,会和if同级,不受if判断结果影响
3.if…else…语句

- else后面有冒号
- else要和if同级(else前没有四个空格的缩进)
4.if…elif…else语句
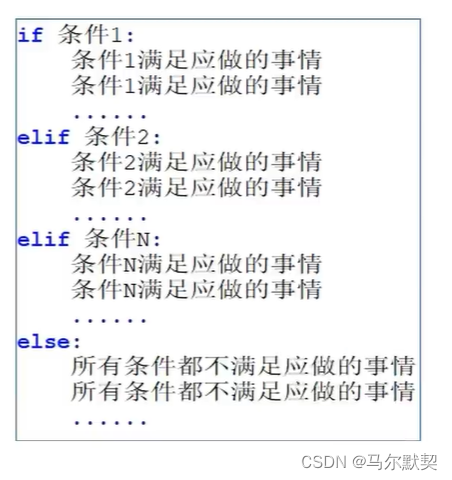
- elif后面要有判断条件和冒号
- elif要和if同级
5.语句嵌套
- 嵌套的关键点在于空格缩进
- 通过空格缩进来决定语句之间的层次关系
四、循环语句
1.while循环

- while后面有条件语句,条件语句后面有冒号
- 通过空格缩进来决定层级和归属,即条件成立后的执行语句较于while关键字要向后空格四个字符(缩进)
- 嵌套要注意条件控制,避免无限循环
- 多层嵌套,依靠空格缩进来确定层级关系
2.for循环
1.基础语法

- for末尾有卖号
- for循环无法构建无限循环

2.range语句


3.变量作用域

3.循环中断
1.continue


2.break


3.return
跳出所有循环
函数体中代码一旦遇到return,其后面的语句就全部不在执行,且结束当前函数体
五、函数
1.介绍

2.定义
1.函数的定义

- 有冒号,有空格缩进
- 函数必须先定义后使用
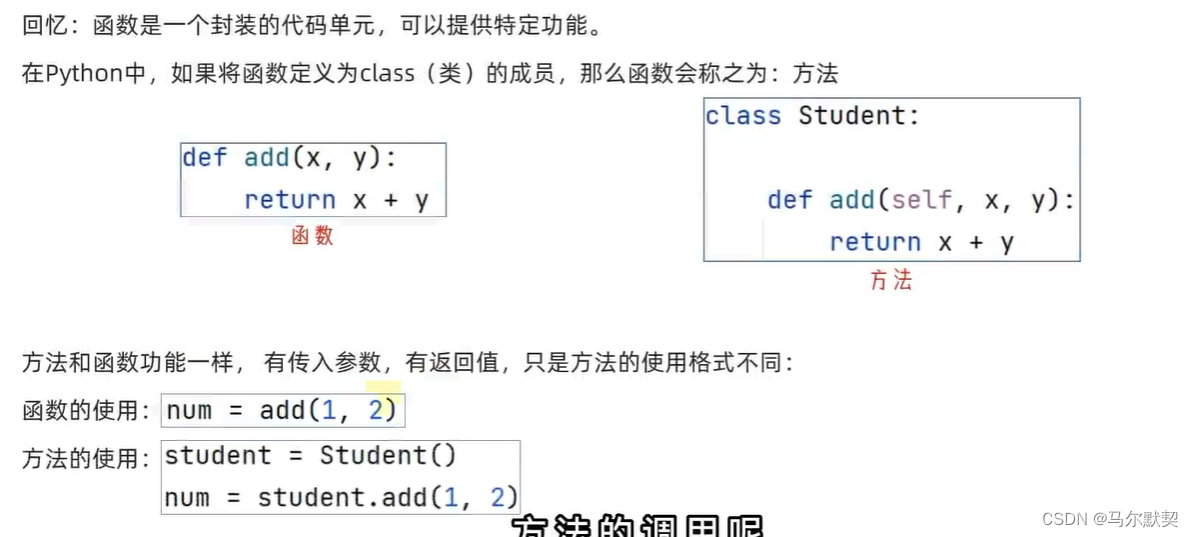
2.方法的定义
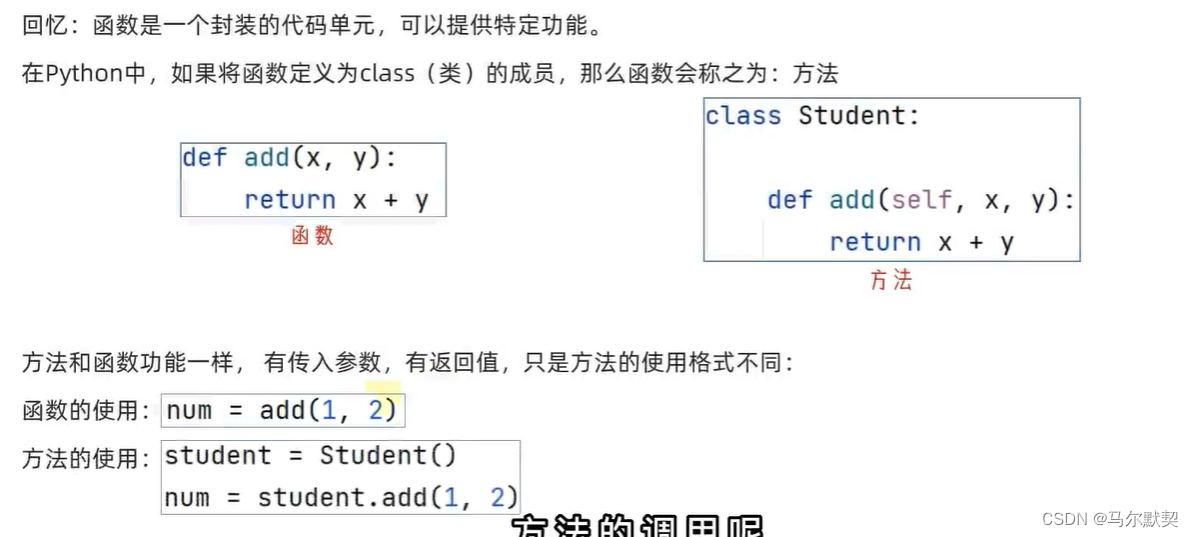
3.参数



4.返回值



5.说明文档
通过注释对函数进行解释说明

6.变量作用域
1.局部变量
在函数体内部的变量,即只在函数体内部生效
2.全局变量
在函数体内、外都能生效的变量
3.global关键字
num=200
def test_a():
print("a:{num}" #输出200
def test_b():
num=500 #局部变量 是新定义的变量,与前面定义的num变量没关系,该变量只在test_b()中使用
print("b:{num}") #输出500
test_a()
test_b()
print("main:{num}") #输出200
- test_b()中的修改操作没有在主函数中生效,因为在test_b()中的num变成局部变量了
- test_b()中的num变量是新定义的变量,与前面定义的num变量没关系,该变量只在test_b()中使用

六、数据容器
1.list(列表)
1.定义

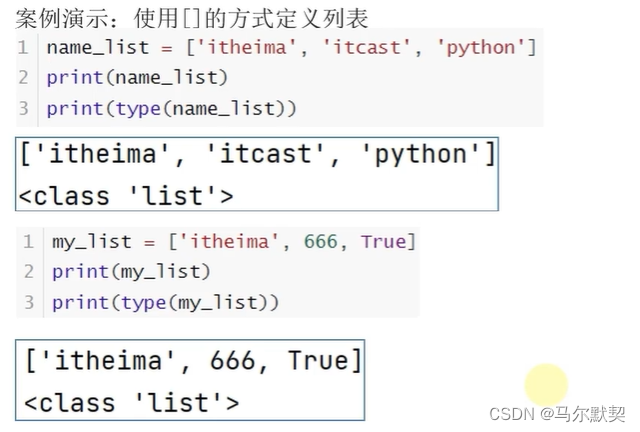
- 可以存储不同类型数据,支持嵌套
2.下标索引

- 正向:下标索引从0开始
- 反向:下标索引从-1开始
- 注意:下标索引的取值范围不要超出取值范围,否则会报错

2.常用操作
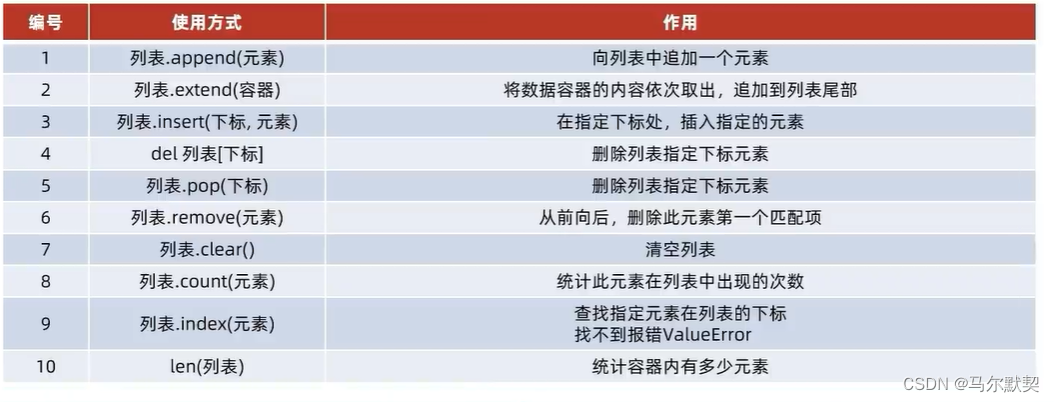




mylist=["as","sg","ht"]
element=mylist.pop(1) #element的值为sg,此时mylist中只剩2个元素


3.遍历
1.while循环

2.for循环


2.tuple(元组)

- 列表可以修改
1.定义格式

2.特点
- 元组内元素可以是不同类型
- 若定义的元组中仅一个元素,在该元素后要加一个逗号,否则定义的就不是元组类型的变量
- 元组中可以嵌套元组

3.操作


4.修改


- 元组的元素是不可以修改的,所以list没有变,但我们修改的是list内部的内容,所以两次输出内容发生了变化
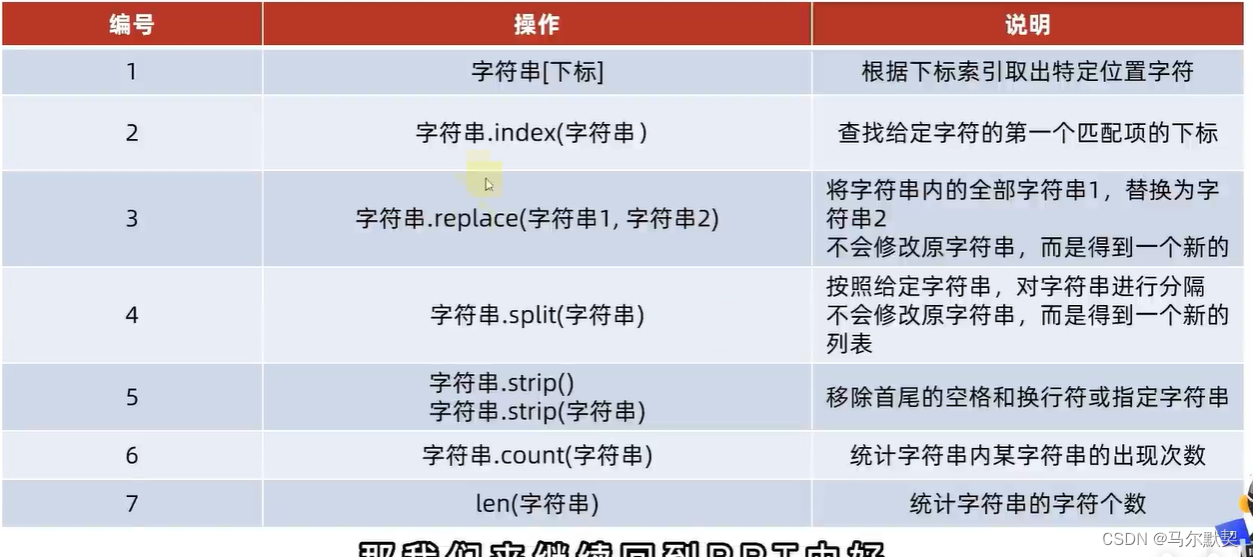
3.str(字符串)

- 字符串无法进行修改
以上操作均无法实现- 若非要做,只能得到一个新的字符串,老的字符串是无法修改的





4.序列的切片
1.序列
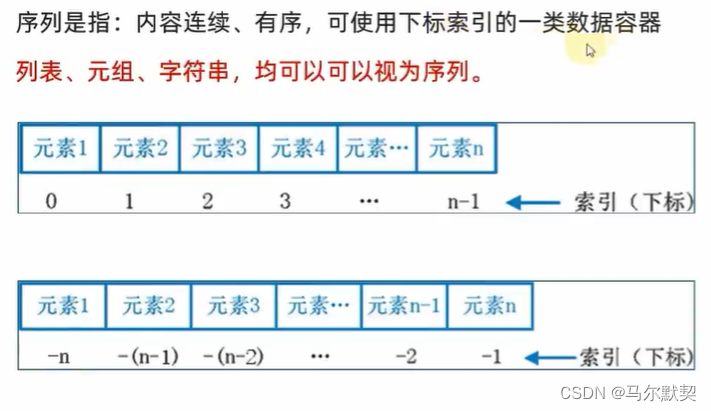
2.操作——切片

- 切片操作并不会影像序列本身,而是会得到一个新的序列(因为元组和字符串是不可修改的)
5.set(集合)
1.定义格式

2.特点
- 不支持内部元素重复
- 内容无序
- 不是序列,无法进行切片操作
3.操作
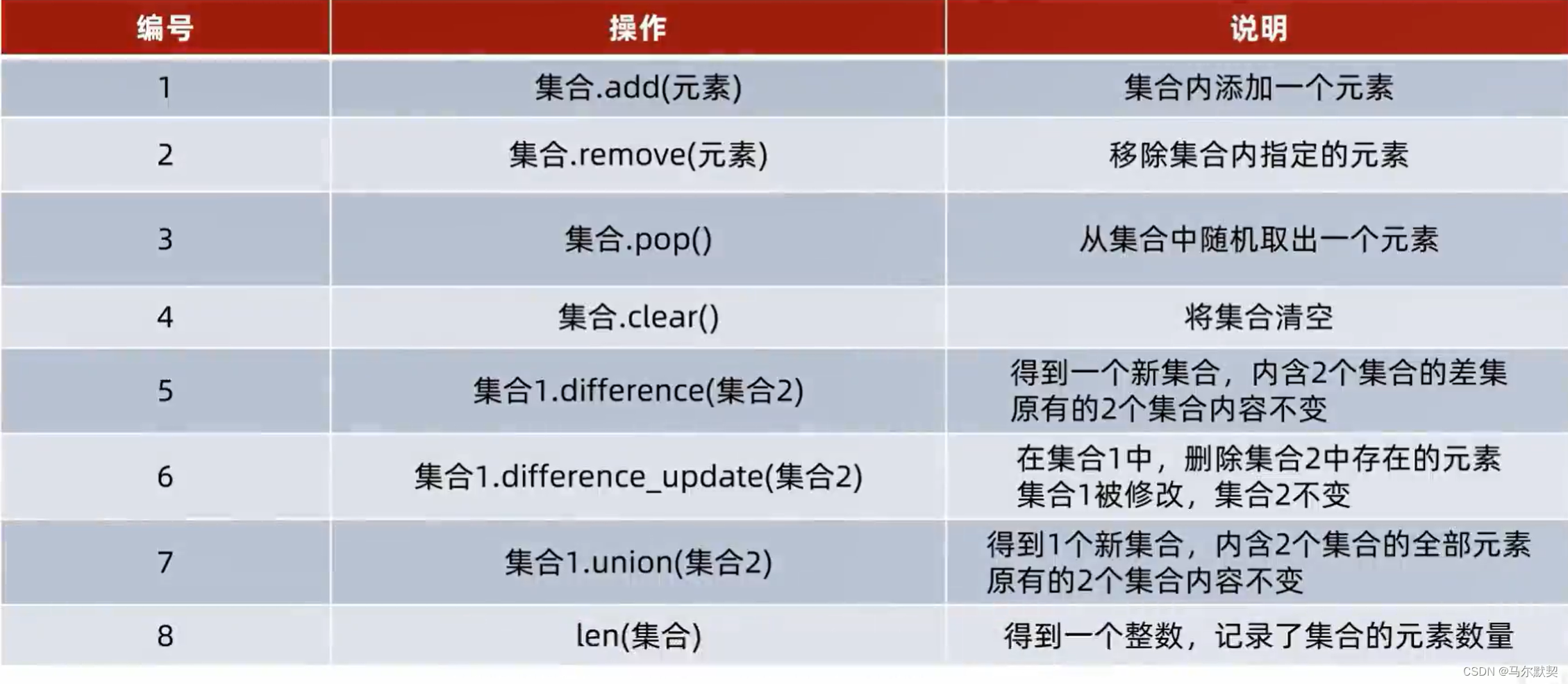
- 因为无序,所以不支持下标索引访问
- 允许修改
- 若添加的元素在集合中本就有,则此次添加操作不会报错,但重复的元素也无法添加进集合中(保证不会出现重复元素)


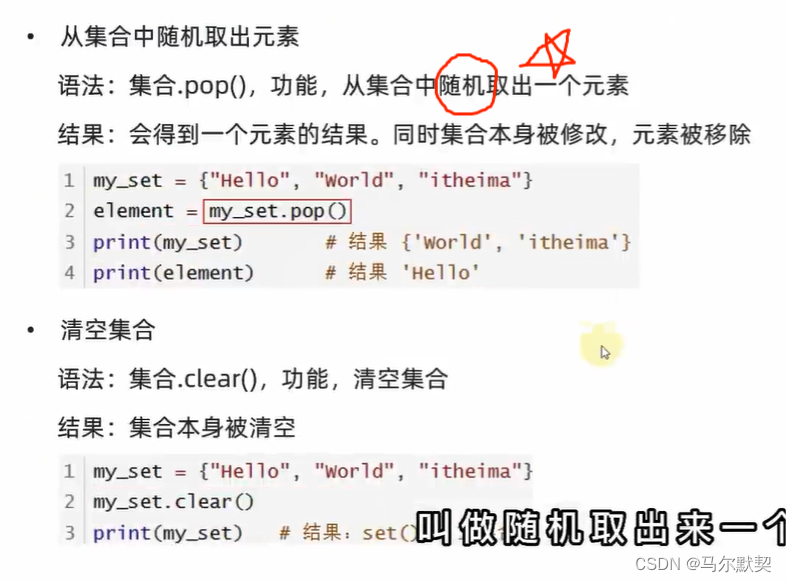


- 合并操作,默认会去重

- 遍历操作
- 集合不支持下标索引,所以无法使用while循环
- 但是可以使用for循环进行遍历

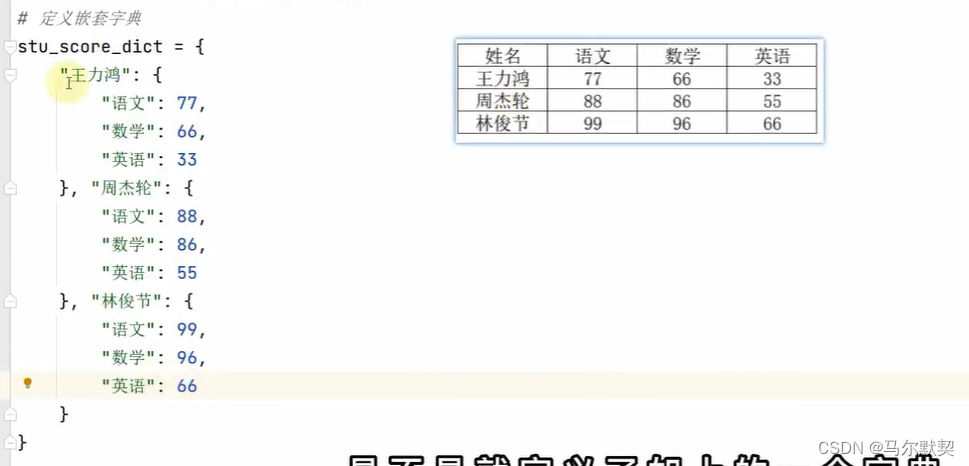
6.dict(字典)
1.定义

- key不允许重复
- 不支持使用下标索引,但可以通过key值来获取对应的value


2.操作
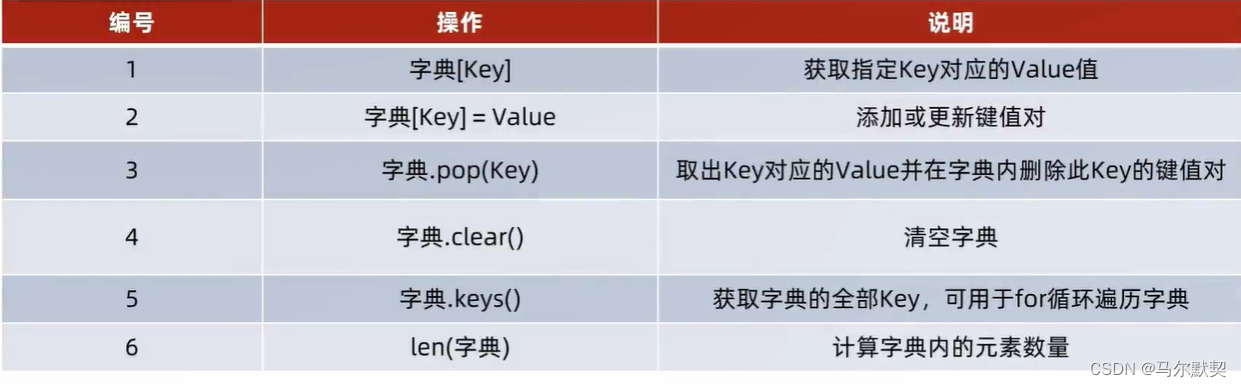
- 两种操作语法一样,区别在于:
若key值在字典中不存在,则此次操作是新增元素;
若key值在字典中已存在,则此次操作是修改key对应的value的值



- 遍历
- 方式一:通过获取到全部的key来完成遍历
- 方式二:直接对字典进行for循环,每一次循环都是直接得到key
- 字典不支持下标索引,索引无法使用while循环进行遍历操作


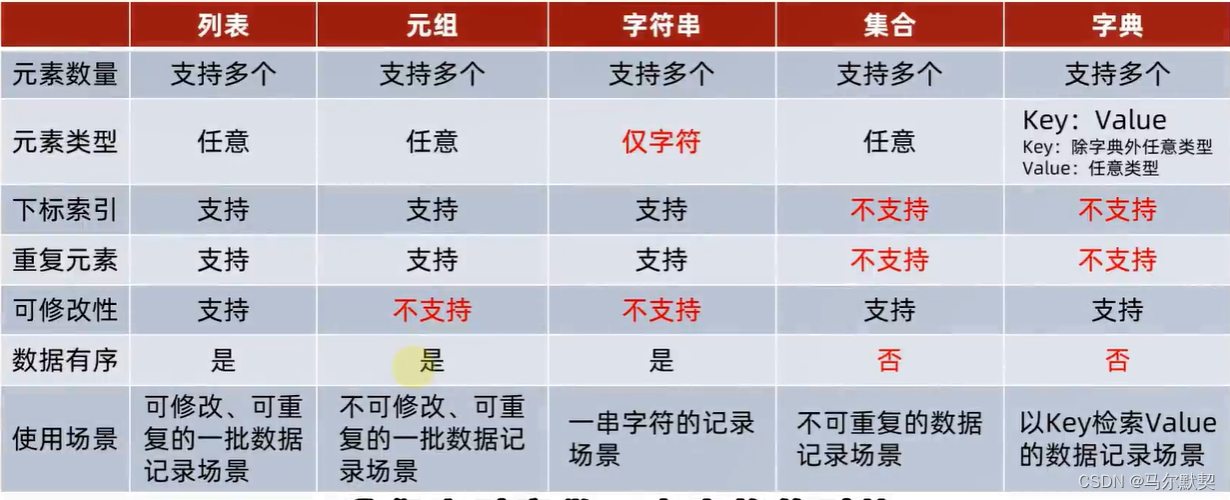
7.比较

8.通用操作
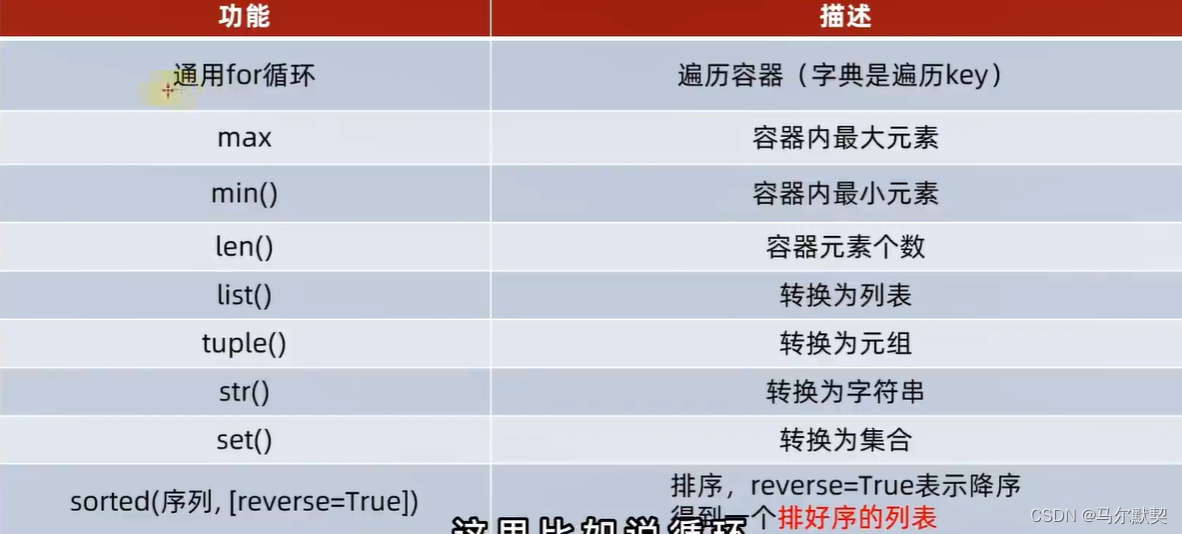


- 字典转其他(除str):将value抛弃,只保留了key

- 排序结果会全部转为列表类型
- 字典排序会丢失value
- 正向排序:sorted(容器)
反向排序:sorted(容器,reverse=True)

7.字符串比大小

七、函数进阶
1.多返回值

2.多种传参方式
1.位置参数

2.关键字参数

3.缺省参数

- 缺省参数在定义时,应放在其他参数之后
4.不定长参数



3.匿名函数
1.函数作为参数传递

2.lambda匿名函数


八、文件
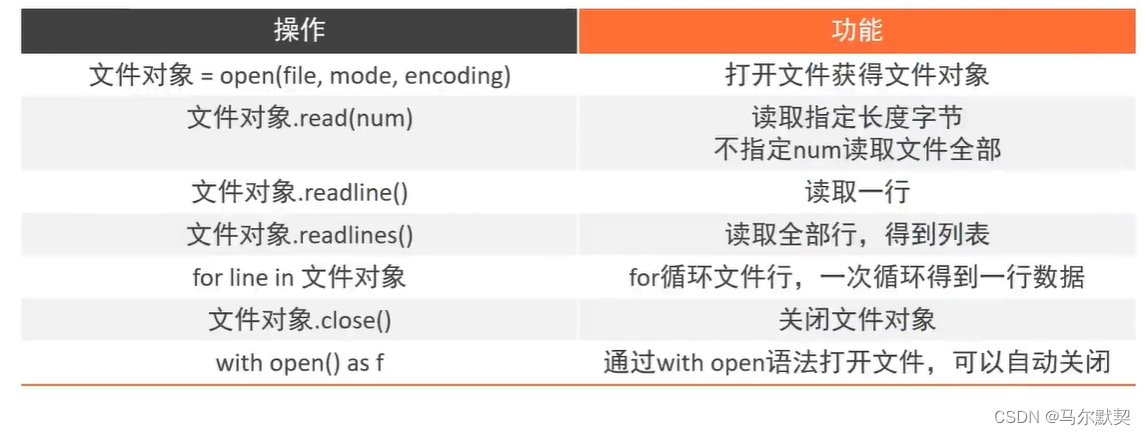
1.编码

- UTF-8是目前全球通用的编码格式
2.打开与关闭
1.打开



2.关闭
- f.close()
- f为需要关闭的文件

3.读取
- 读取文件的操作,会续接上次读取操作的结尾处接着再读
- 使用read()函数,第二次使用read函数去读取,会从第一次读取的结尾位置开始继续去读
- 使用readlines()函数,如果在使用该函数前有read或readlines函数已执行,则此次读取操作会在之前的读取操作的结尾位置开始继续读取,而不是从文件开头处进行读取
- readlines()函数会读取到换行字符“\n”



4.写入

- close()方法 内置了flush()的功能,即用了write()后直接使用close,写的内容也会真正的写入到文件中
- 以 w模式(open("文件名“,“w”,“UTF-8”))打开文件:使用write函数,新写的内容会覆盖文件中原先存在的数据(原文件内容清空,再写入新内容);原文件若不存在,则会先创建文件,再打开

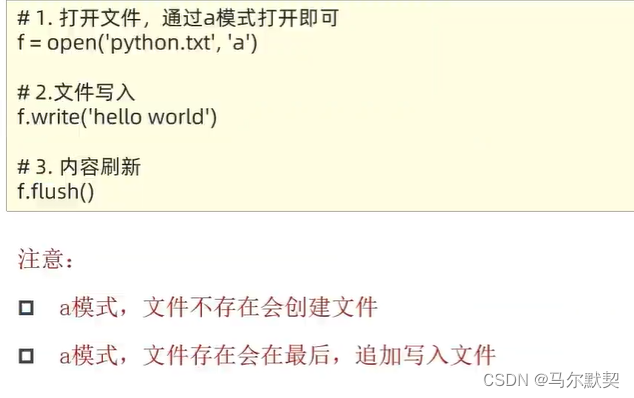
5.追加
- 与文件写入类似,只是在打开文件时将 w模式改为a模式w模式改为a模式即可
- 无论是写入还是追加,可以在要写入的内容中添加“\n”符号实现文本换行
九、异常、模块、包
1.了解异常


2.异常的捕获方法


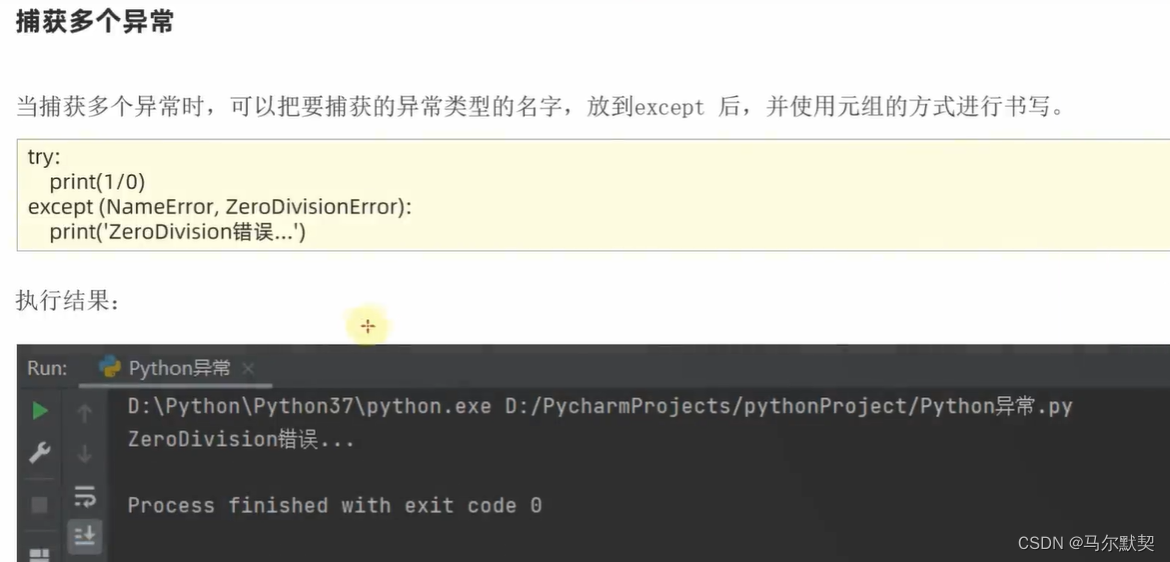

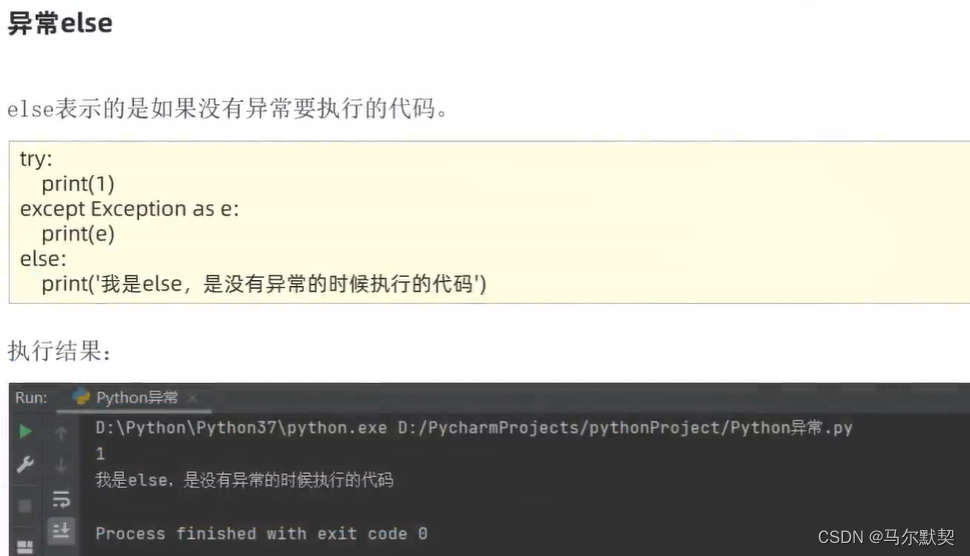

3.异常的传递

4.python模块
1.导入模块



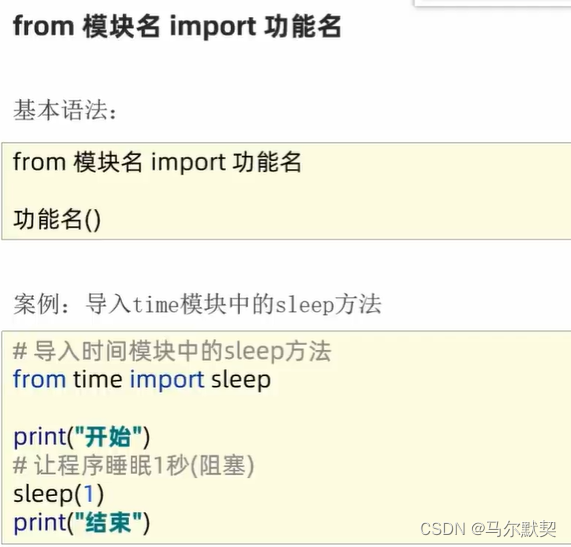
- 此处使用*,意思是导入time模块中的所有功能,使用时无序像import导入的模块那样使用:模块名.功能名(如time.sleep(3))来进行调用,可以直接使用功能名(如sleep(5))进行调用


2.自定义模块
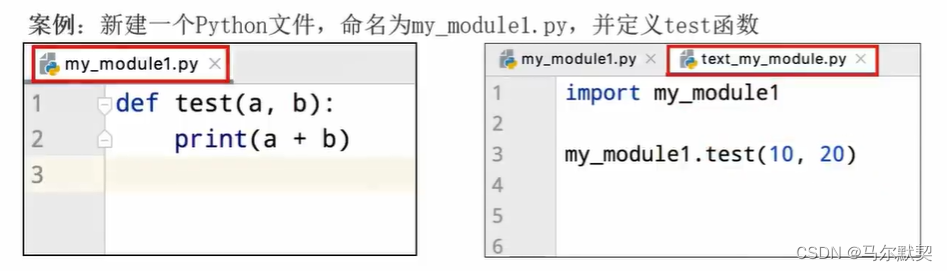
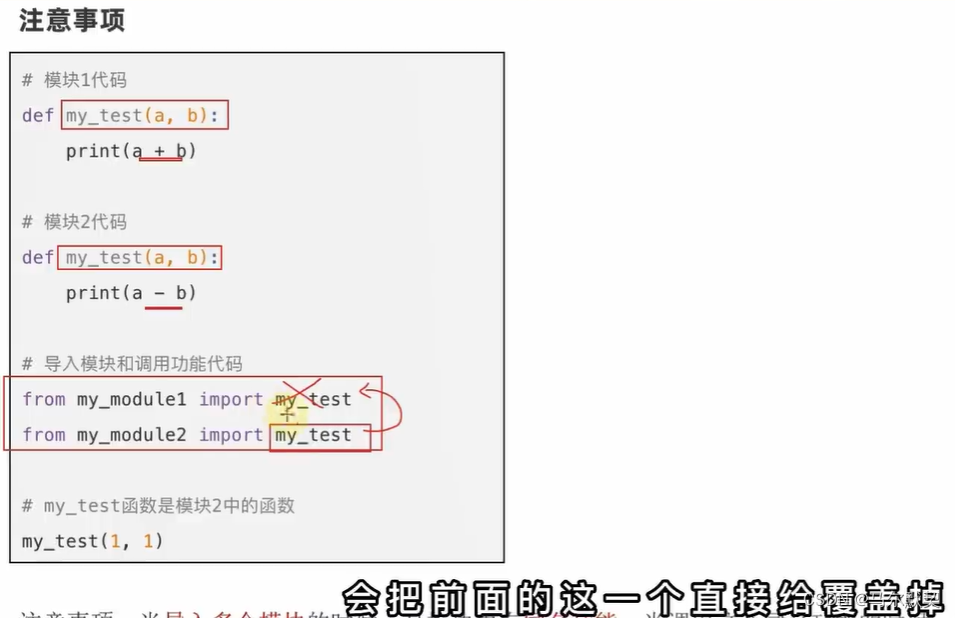
3.测试模块__main__


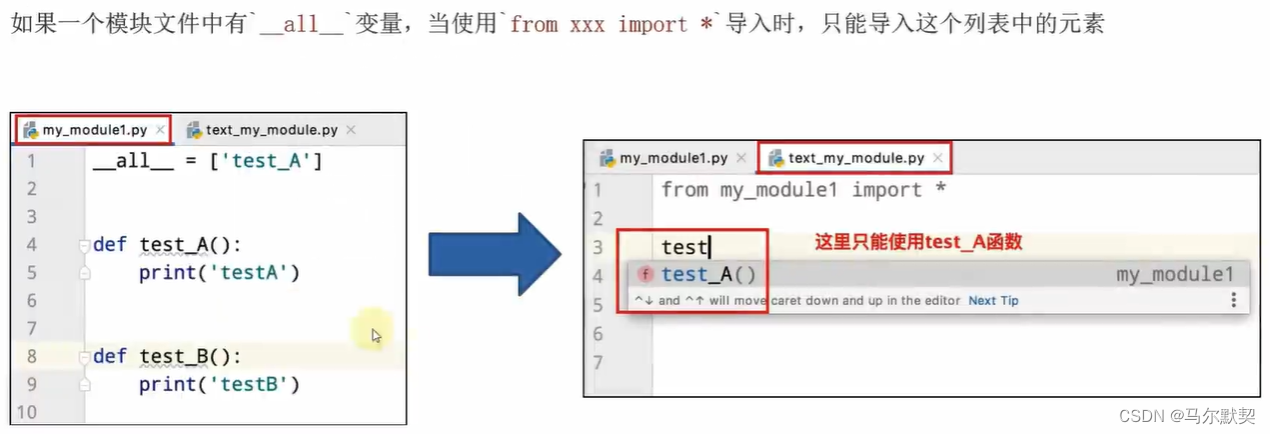
4.__all__变量
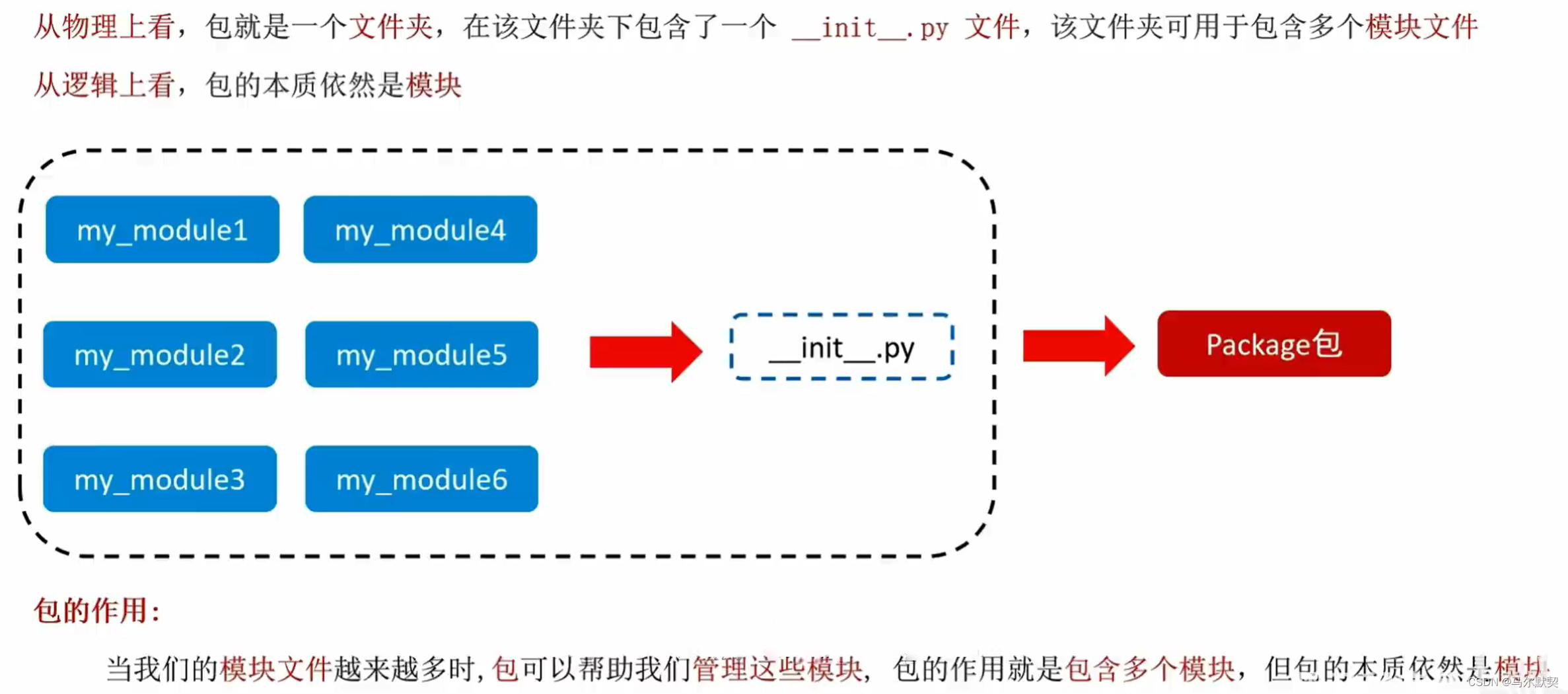
5.python包
- 文件夹内有__init__.py文件,该文件夹就是包;无__init__.py文件,该文件夹就只是一个文件夹
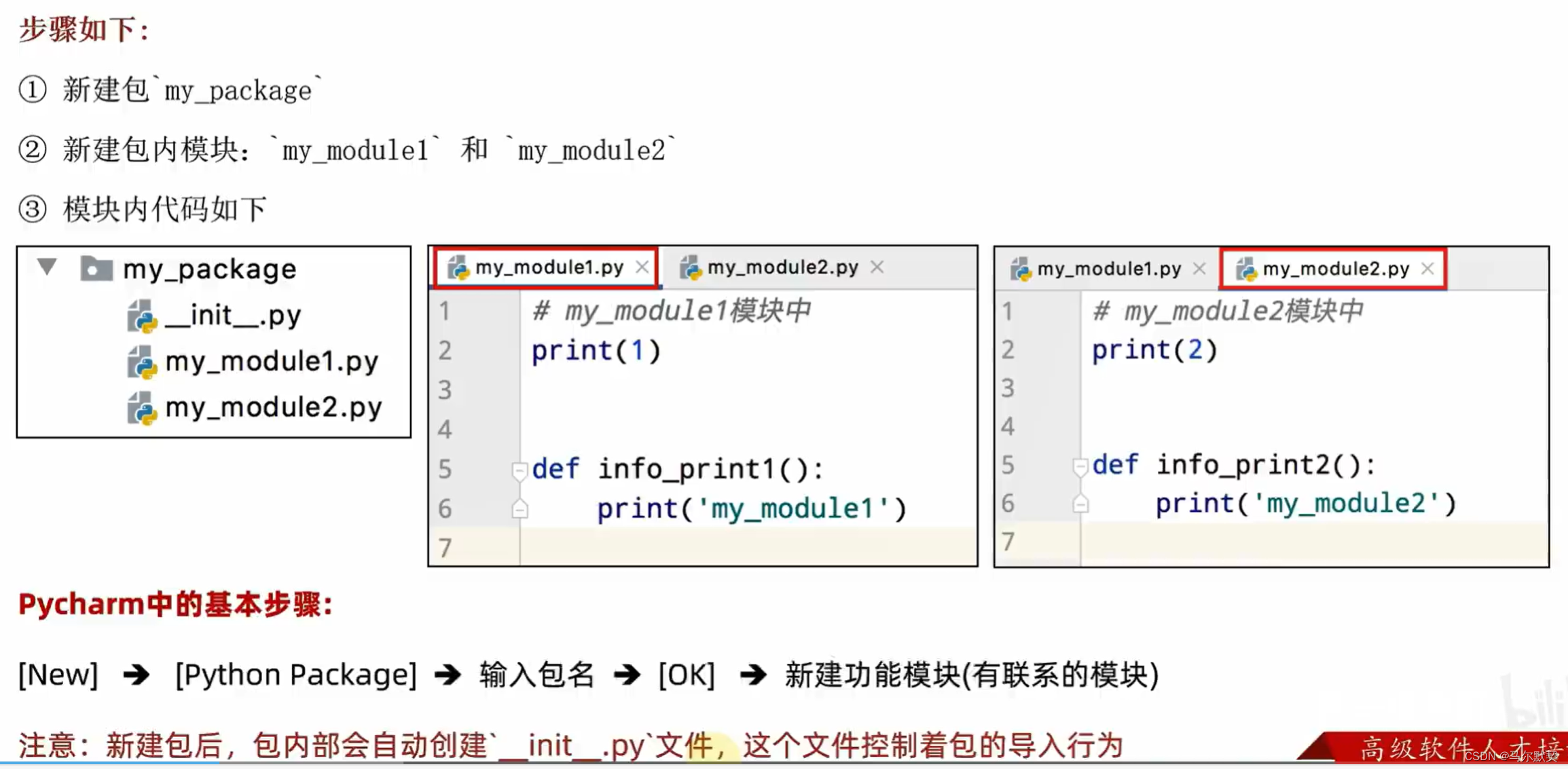
1.自定义包
方法二:
方法三:
方法四:
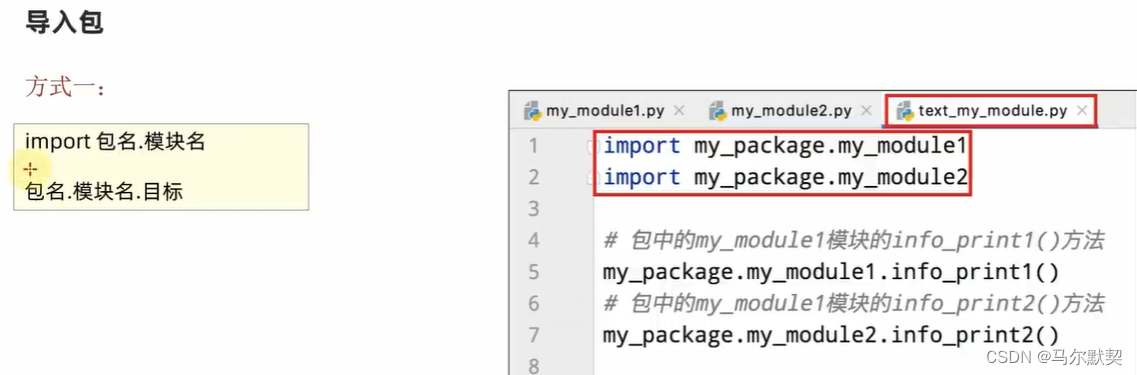

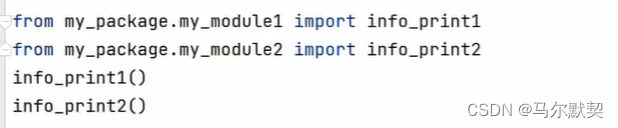

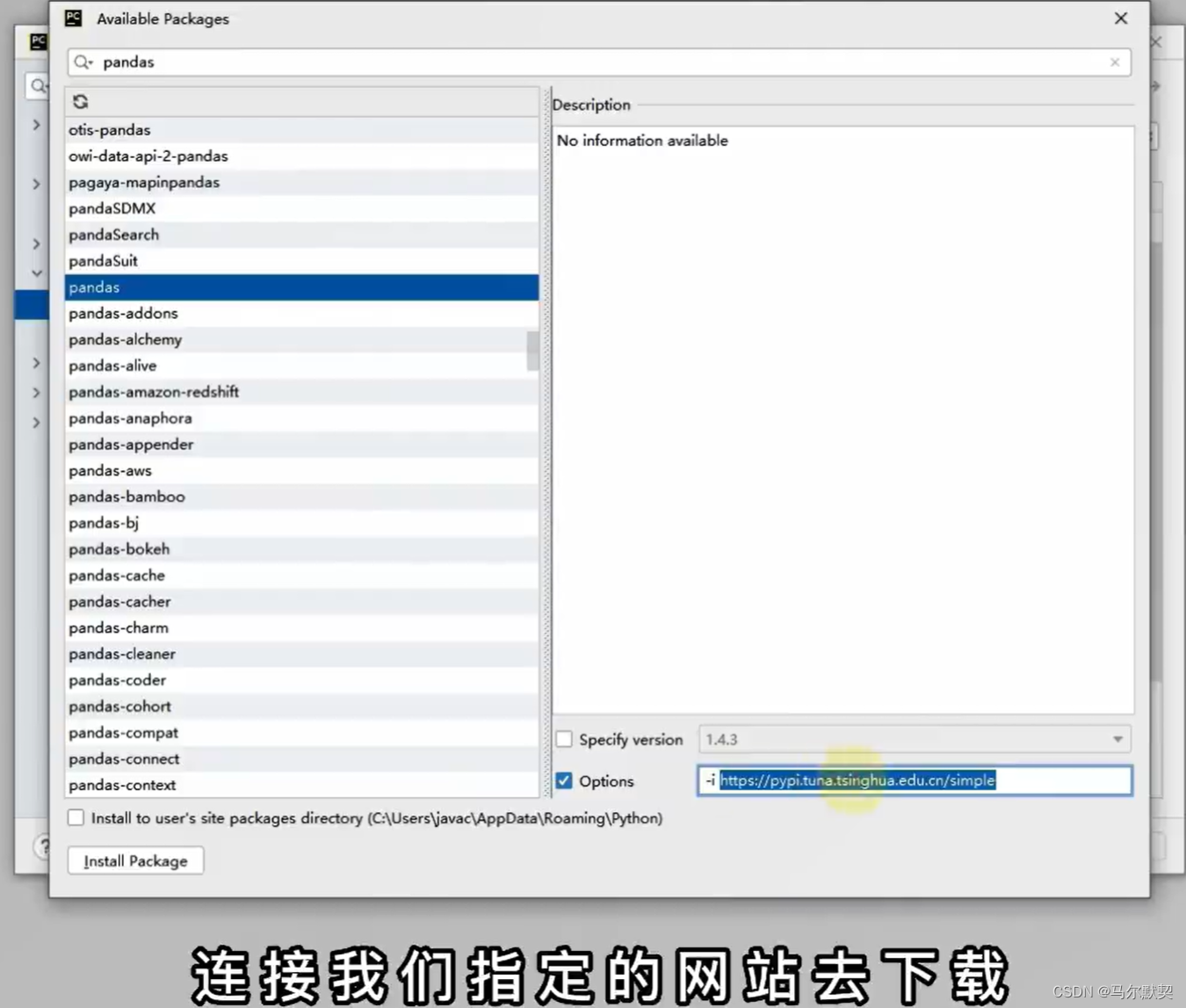
2.安装第三方python包

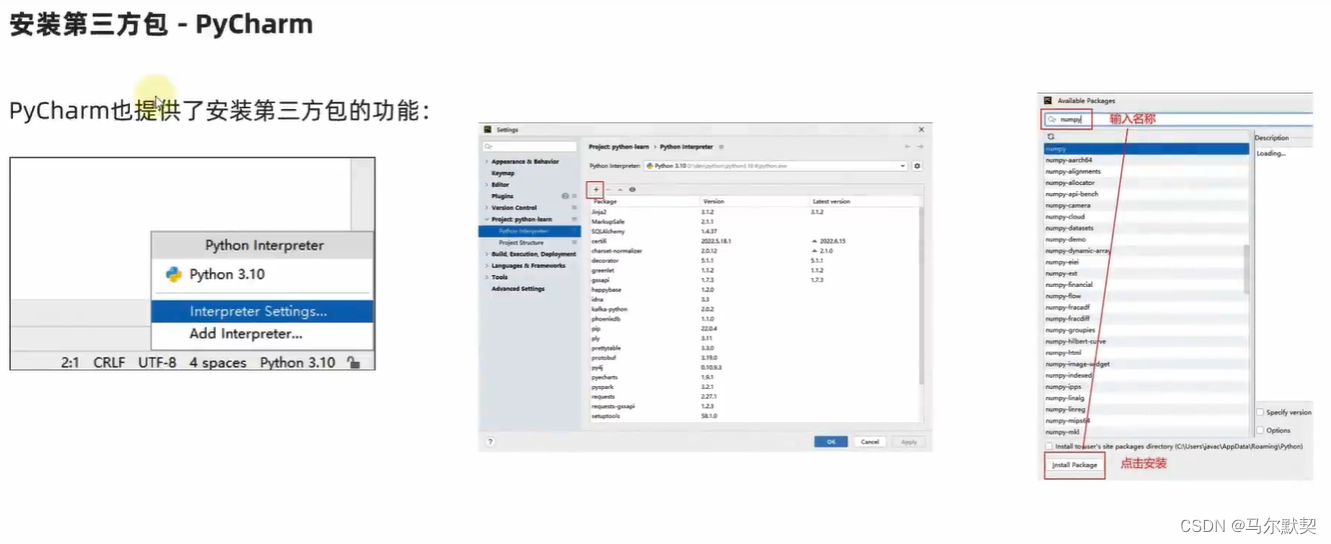
- 安装第三方包不成功,可能是网速或直接访问国外网站导致超时等原因。此时需要在国内的豆瓣镜像进行安装,命令如下
pip install XXX -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com(XXX是我们需要安装的包名称)- 常用的镜像有清华、中科大、豆瓣等等

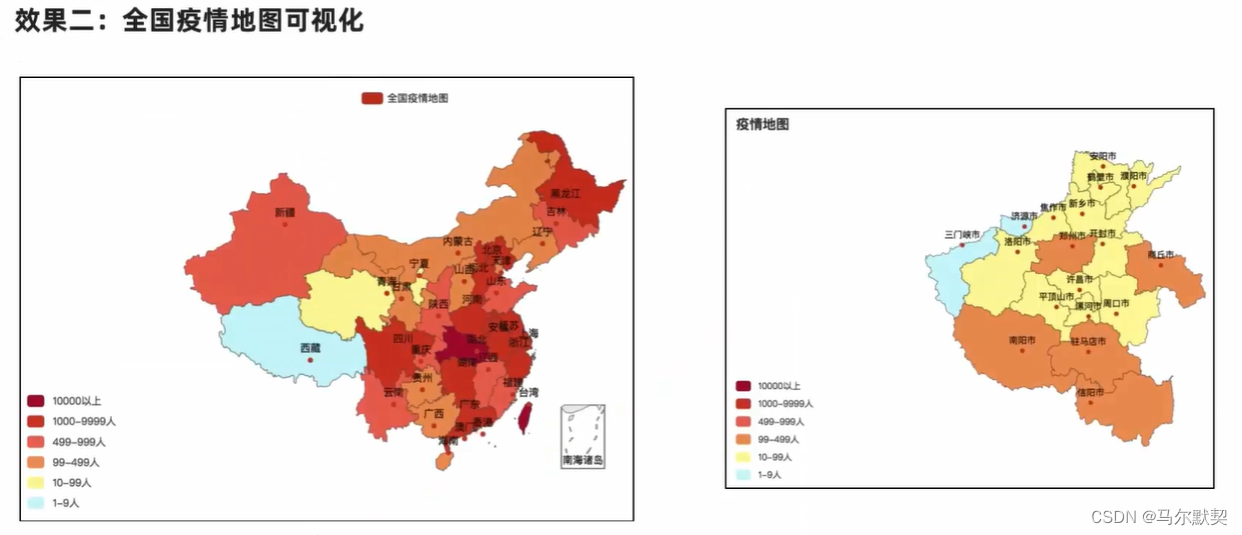
十、案例——数据可视化

1.折线图
2.地图数据可视化
3.柱状图
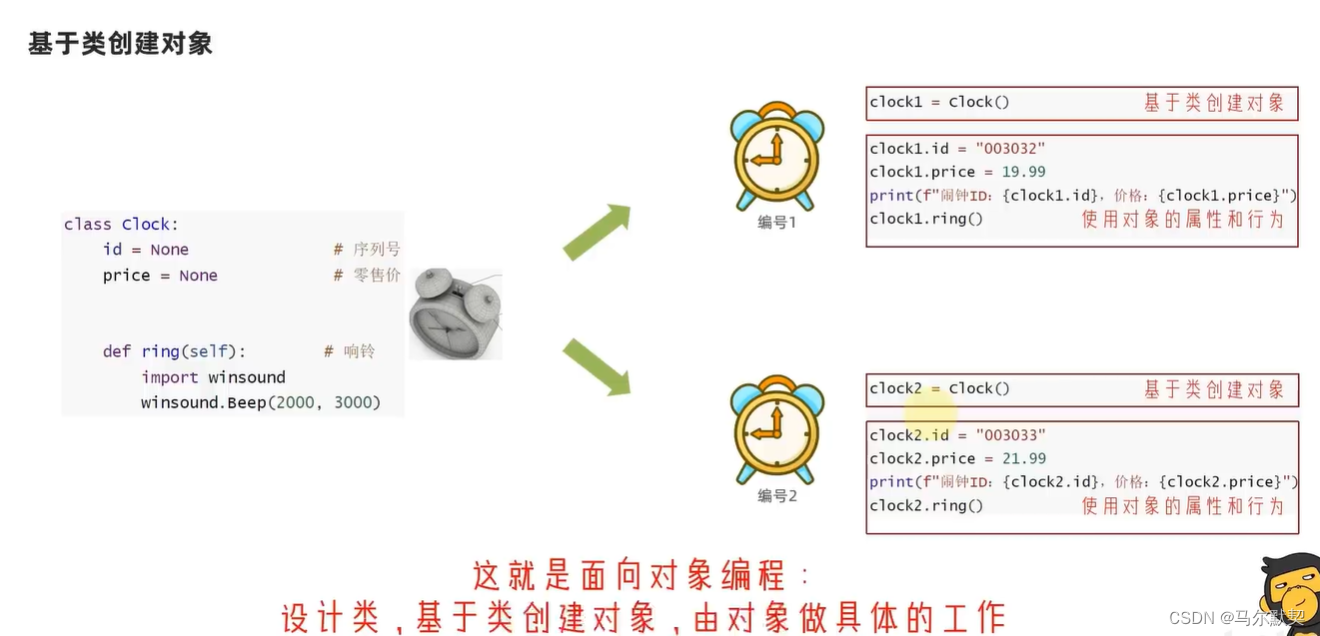
十一、 面向对象
1.对象

2.成员方法
1.类