〔更多精彩AI内容,尽在「魔方AI空间」公众号,引领AIGC科技时代〕
本文作者:猫先生
引 言
本文是LLM基础入门系列的第5篇。在这之前,猫先生已经学习并整理归纳了四篇大模型系列文章,这对于入门LLM,并熟练掌握它至关重要!前四篇文章链接地址如下:
在第3篇和第4篇文章中,详细介绍了Transformer架构,但我觉得有必要从另一个层面再写一篇文章来探讨它,这有助于我们认识并掌握它!
让我们开始吧!!
定义数据集
用于创建 ChatGPT 的数据集为570 GB**。在这里,**我们将使用非常小的数据集来直观地执行数值计算。

整个数据集仅包含三句话,全部都是从电视节目中摘录的对话。虽然我们的数据集已经过清理,但在 ChatGPT 创建等现实场景中,清理 570 GB 的数据集需要付出巨大努力。
确定词汇量
词汇量决定了数据集中唯一单词的总数。可以使用以下公式计算,其中N是数据集中的单词总数。
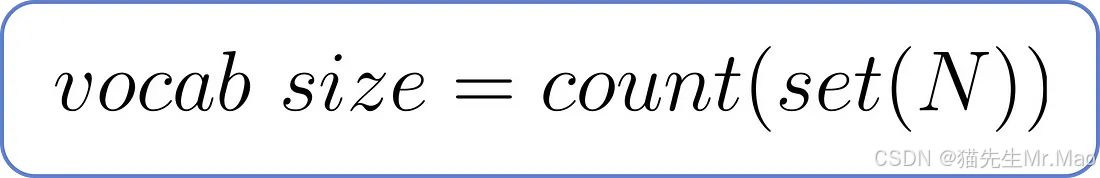
为了找到 N,我们需要将数据集分解成单个单词。

得到N之后,我们进行集合运算,去除重复项,然后统计唯一单词的数量,就可以确定词汇量。

因此,词汇量为23 ,因为我们的数据集中有23 个唯一单词。
编码
现在,我们需要为每个唯一的单词分配一个唯一的编号。
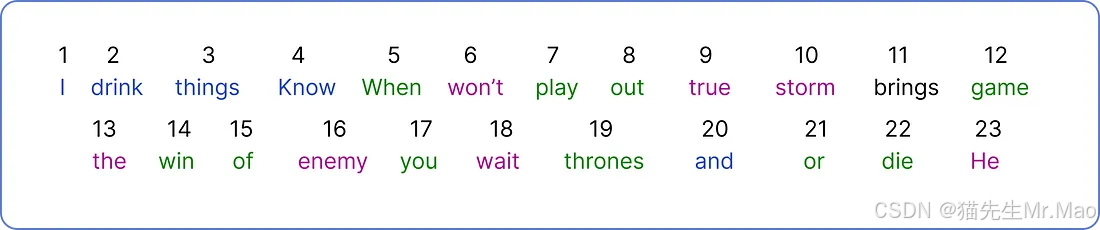
由于我们将单个标记视为单个单词并为其分配一个数字,因此 ChatGPT 使用以下公式将单词的一部分视为单个标记:1 Token = 0.75 Word
在对整个数据集进行编码之后,就该选择我们的输入并开始使用 Transformer 架构了。
计算嵌入
从语料库中选择一个句子,该句子将在我们的 Transformer 架构中进行处理。
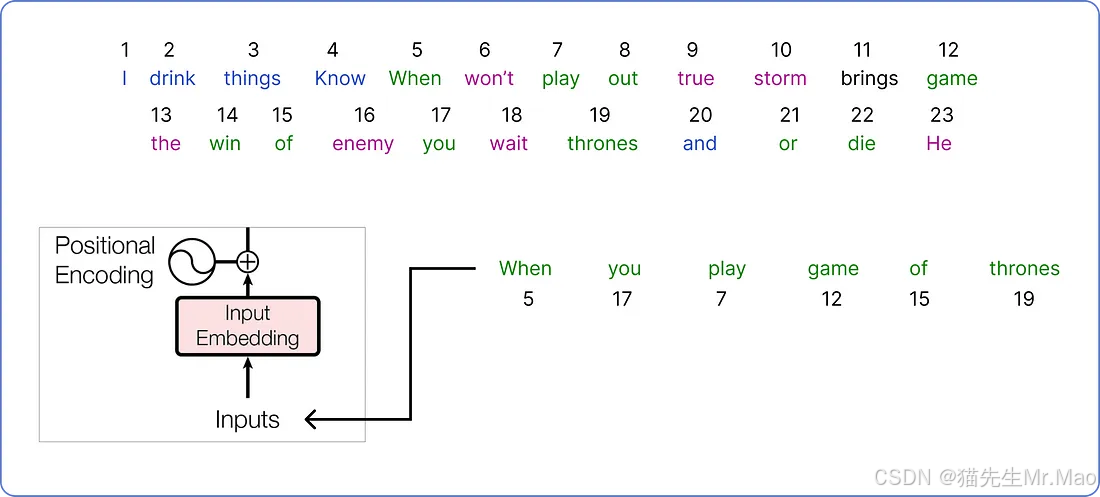
我们已经选定了输入,接下来需要为它找到一个嵌入向量。原始论文为每个输入词使用一个512 维的嵌入向量。
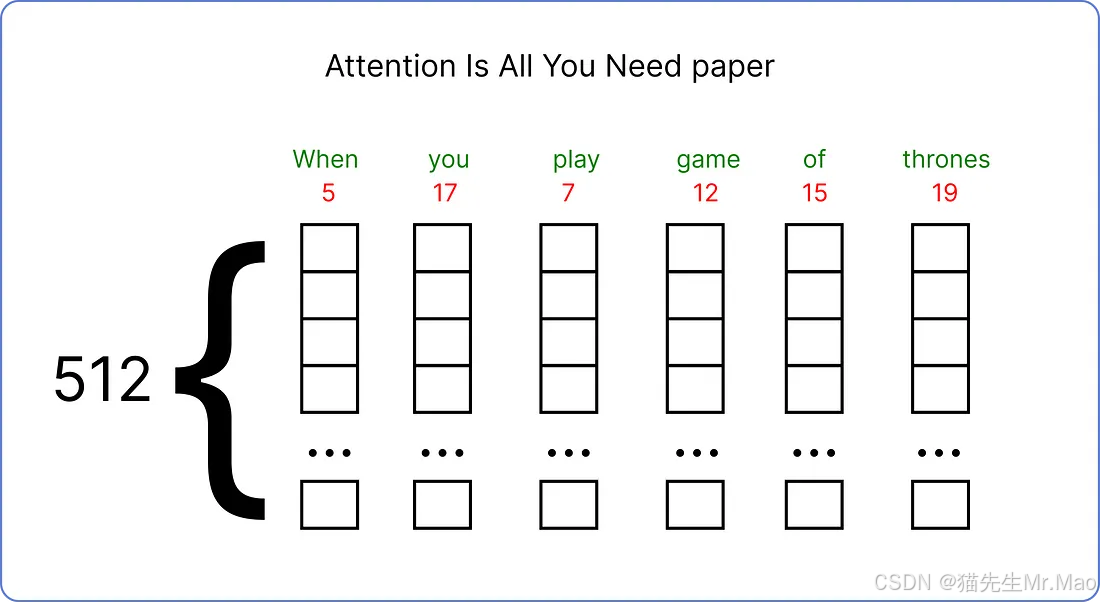
在本文中,我们将使用较小维度的嵌入向量来可视化计算的方式。因此,我们将使用6嵌入向量的维度。
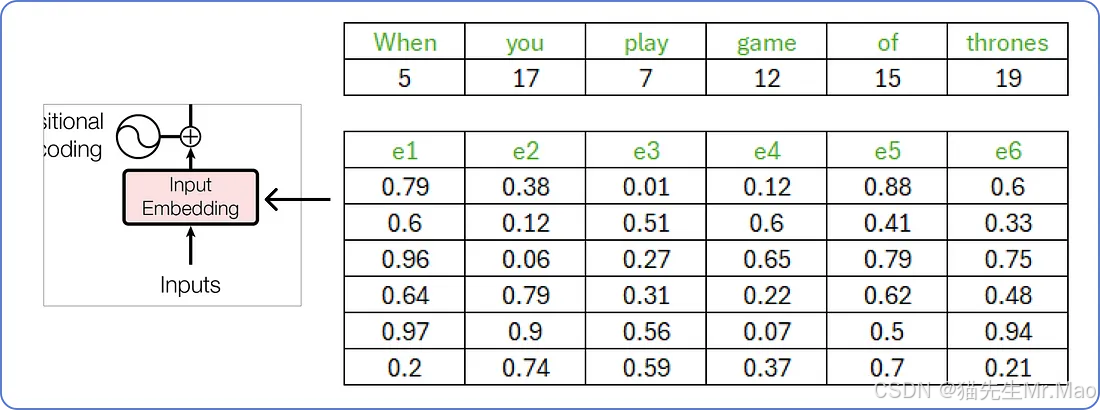
输入的嵌入向量
嵌入向量的这些值介于 0 和 1 之间,并且在开始时是随机填充的。随着我们的 Transformer 开始理解单词之间的含义,它们将被更新。
计算位置嵌入
现在我们需要为输入找到位置嵌入。位置嵌入有两个公式,具体取决于每个单词的嵌入向量第 i 个值的位置。

位置嵌入公式
例如,输入句子是“when you play the game of thrones”,起始词是“when”,起始索引(POS)值为0,维度(d)为6。对于i从0 to 5,我们计算输入句子第一个单词的位置嵌入。
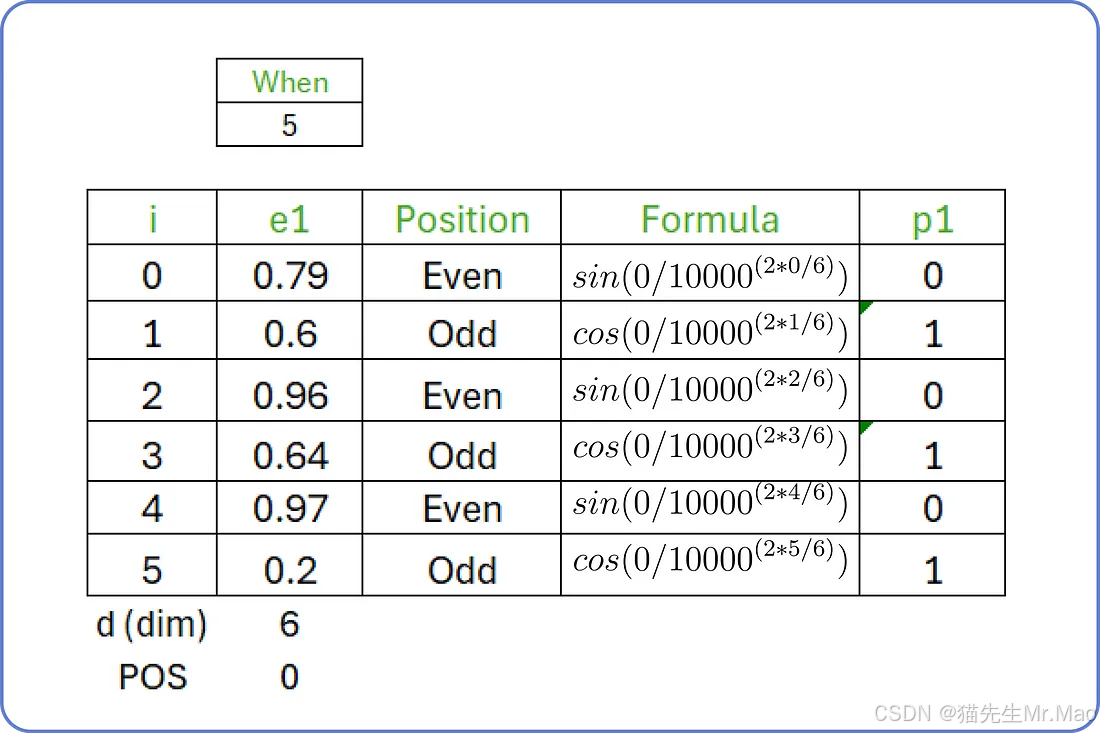
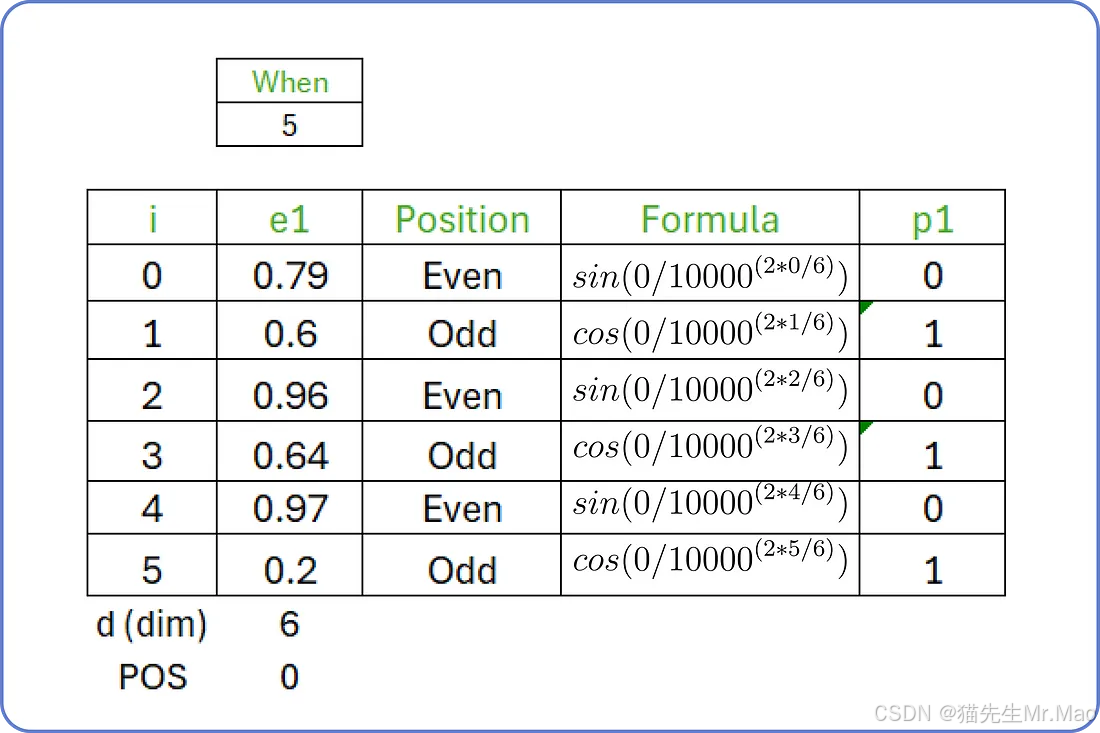
类似地,我们可以计算输入句子中所有单词的位置嵌入。
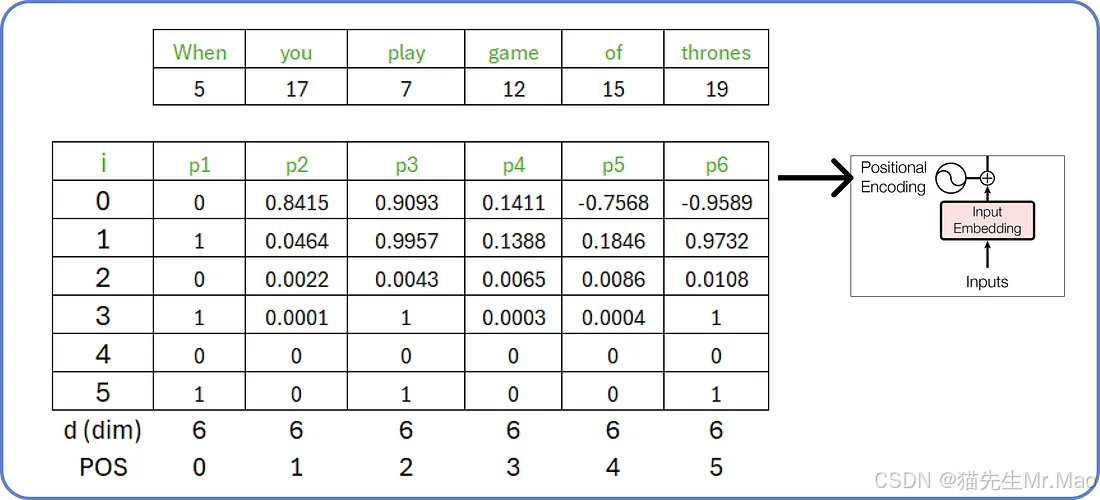
连接位置嵌入和词嵌入
在计算出位置嵌入之后,我们需要将词嵌入和位置嵌入相加。
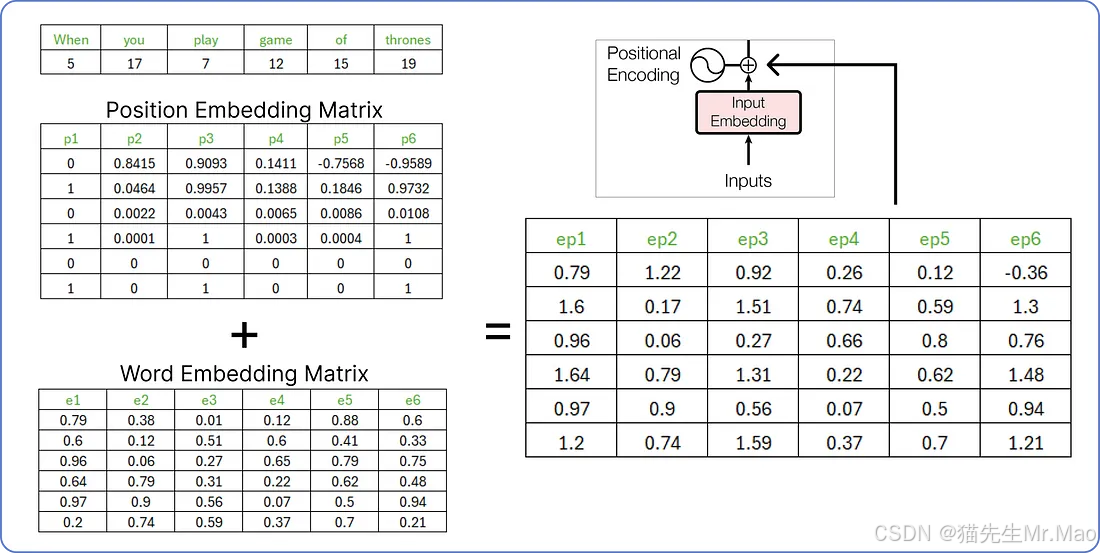
由两个矩阵(词嵌入矩阵和位置嵌入矩阵)组合得到的矩阵将被视为编码器部分的输入。
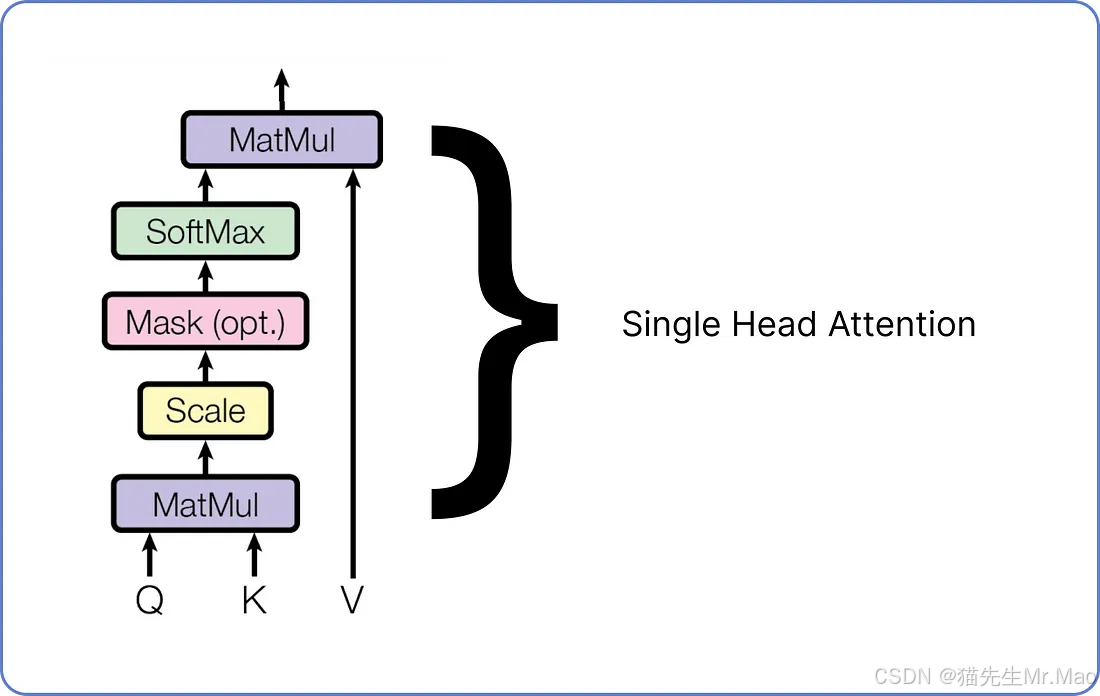
多头注意力
多头注意力由许多单头注意力组成。我们需要组合多少个单头注意力取决于我们自己。例如,Meta 的 LLaMA LLM 在编码器架构中使用了 32 个单头注意力。下面是单头注意力的示意图。
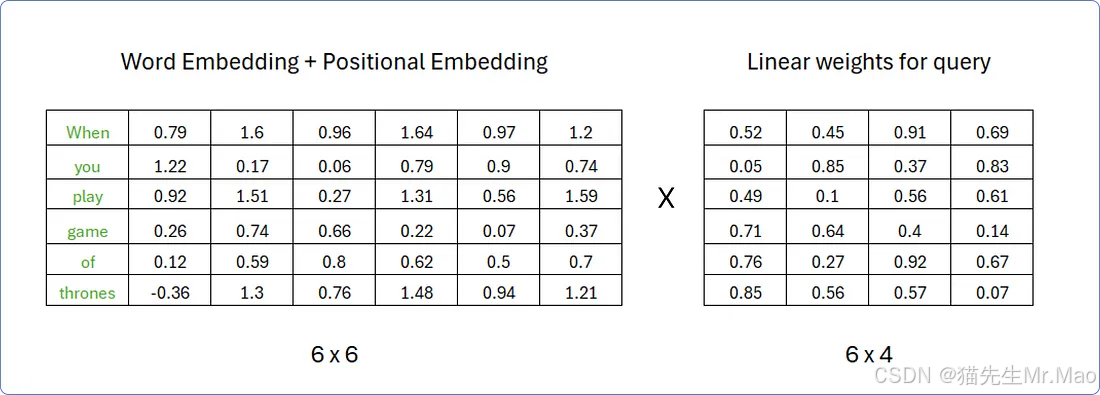
有三个输入:查询、键和值。每个矩阵都是通过将我们之前通过添加词嵌入和位置嵌入矩阵计算出的同一矩阵的转置与不同的权重矩阵集相乘而获得的。
假设,为了计算查询矩阵,权重矩阵的行数必须与转置矩阵的列数相同,而权重矩阵的列数可以是任意的;例如,假设权重矩阵中的列4。权重矩阵中的值是随机的0 and 1,当我们的Transformer开始学习这些单词的含义时,这些值将会更新。
类似地,可以使用相同的程序计算键和值矩阵,但权重矩阵中的值必须不同。

因此,矩阵相乘后,得到了结果查询、键和值:

现在我们有了所有三个矩阵,让我们开始逐步计算单头注意力。
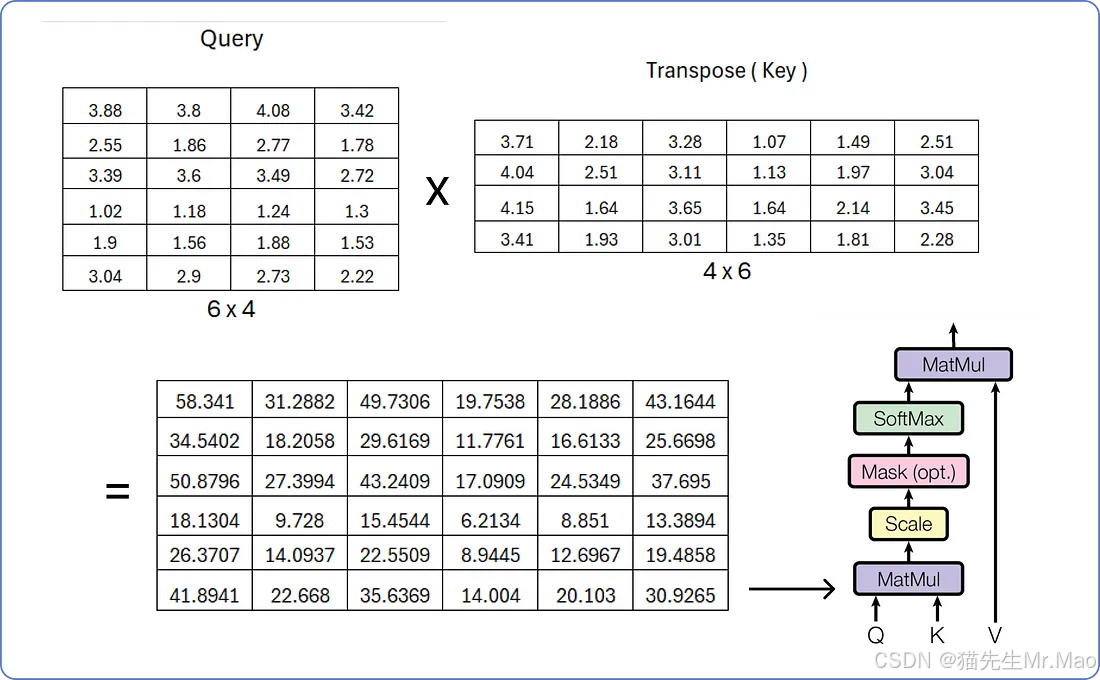
为了缩放结果矩阵,我们必须重用嵌入向量的维度,即6。

下一步是掩码,这是可选的,我们不会对其进行计算。掩码就像告诉模型只关注在某个时间点之前发生的事情,而不是在确定句子中不同单词的重要性时窥视未来。它可以帮助模型逐步理解事物,而不会通过向前看来作弊。
所以现在我们将在缩放的结果矩阵上应用softmax操作。
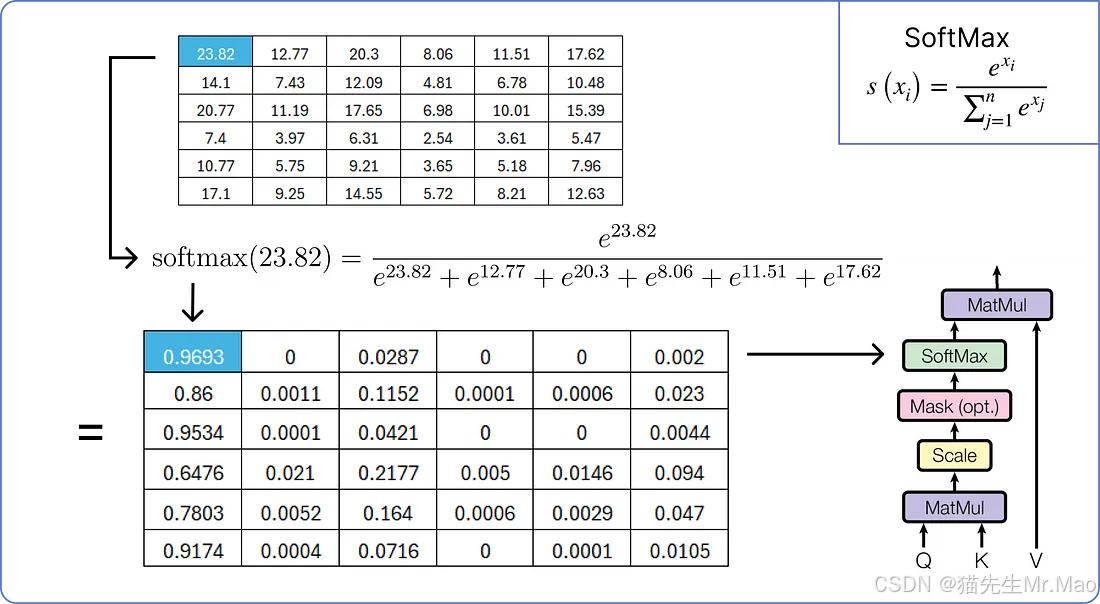
执行最后的乘法步骤以获得单头注意力的结果矩阵。
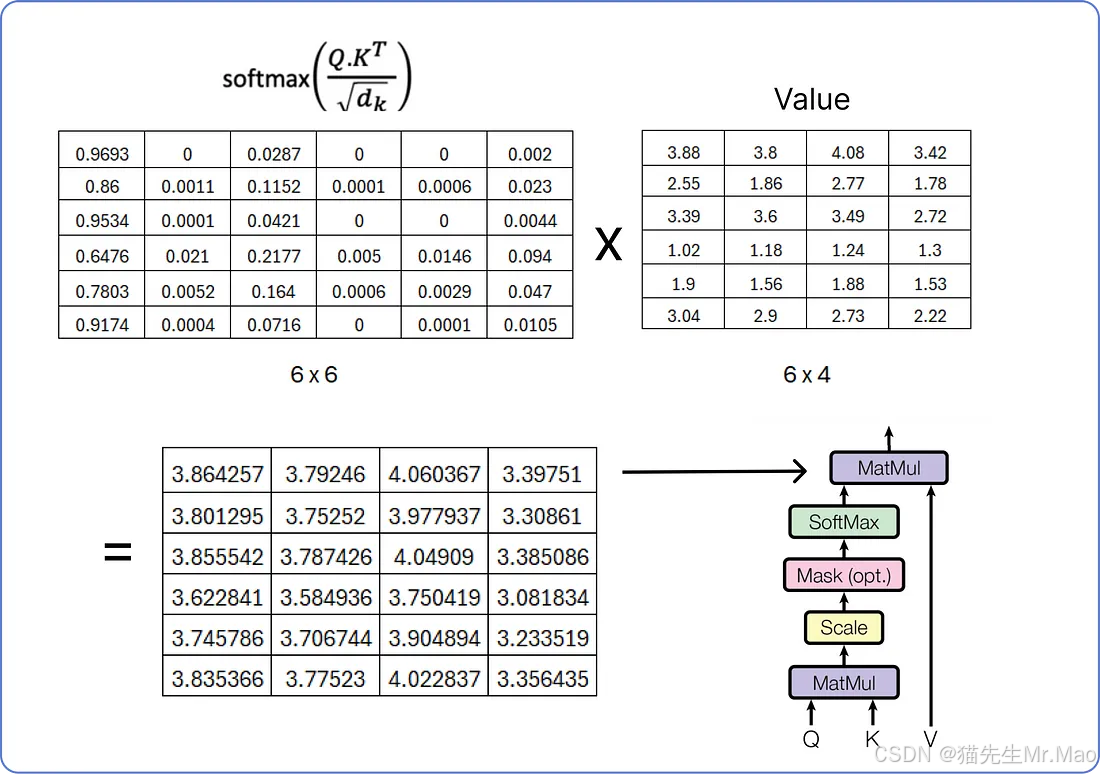
我们已经计算了单头注意力,而多头注意力由多个单头注意力组成,正如我之前所说。下面是它的视觉效果:
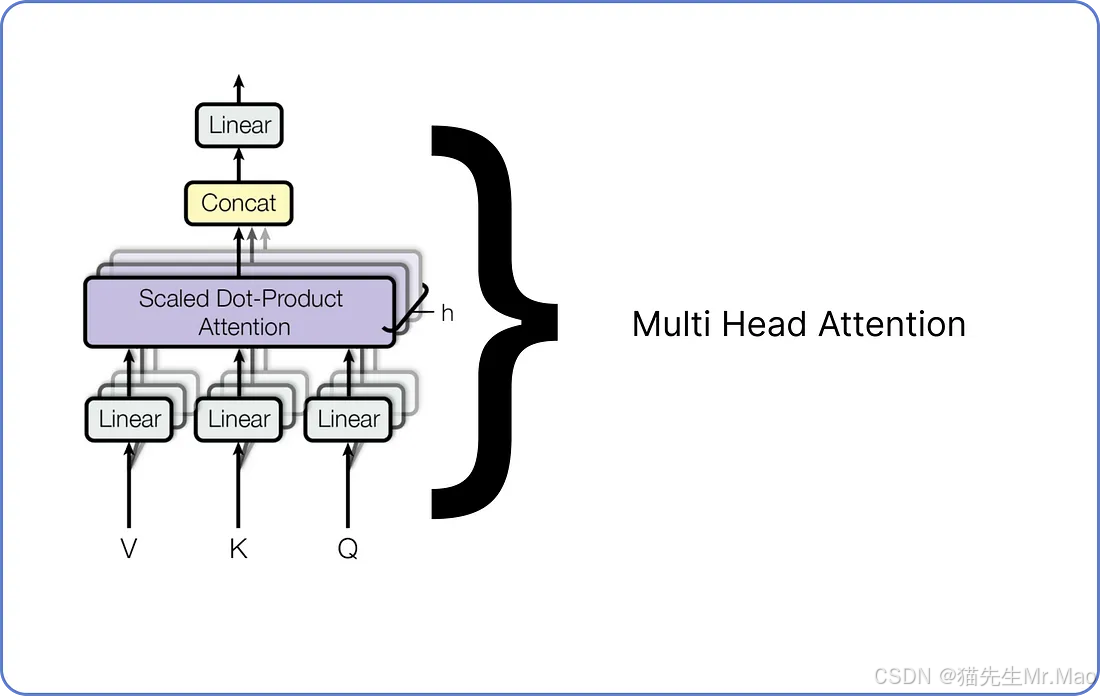
每个单头注意力机制有三个输入:查询、键和值,每三个都有一组不同的权重。一旦所有单头注意力机制输出其结果矩阵,它们将全部连接起来,最终的连接矩阵将再次通过将其与一组用随机值初始化的权重矩阵相乘来进行线性变换,这些权重矩阵稍后将在 Transformer 开始训练时进行更新。
因为在本例中,我们正在考虑单头注意力,但如果我们使用多头注意力,它看起来就会是这样。
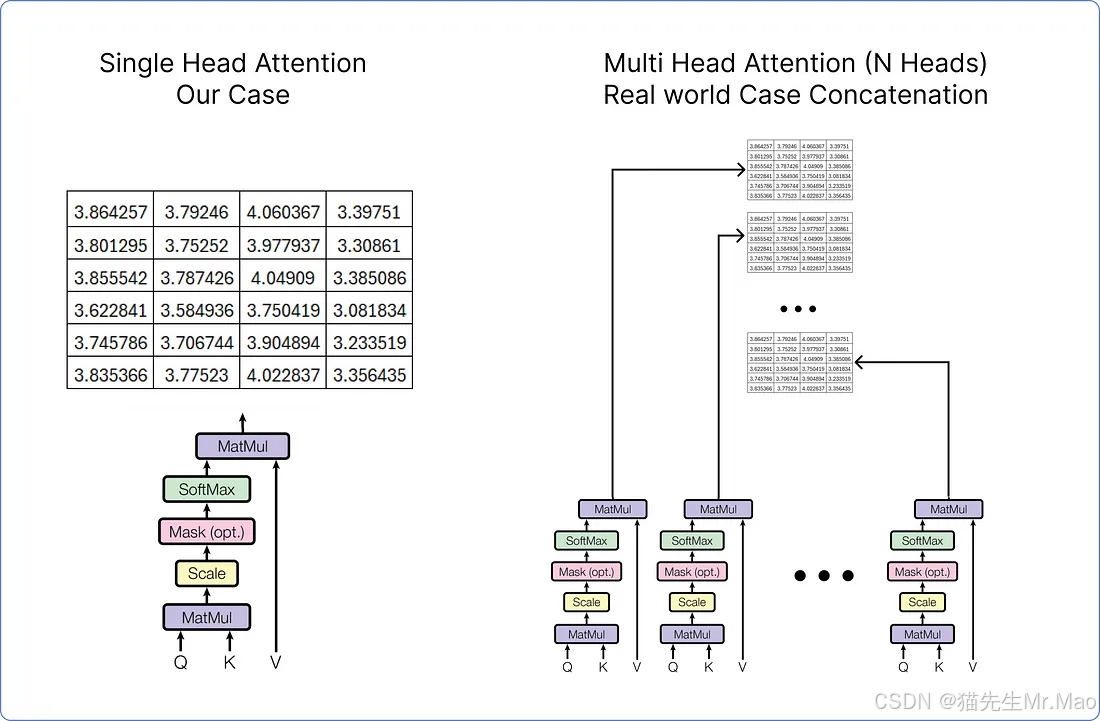
无论是单头注意力还是多头注意力,结果矩阵都需要通过乘以一组权重矩阵再次进行线性变换。
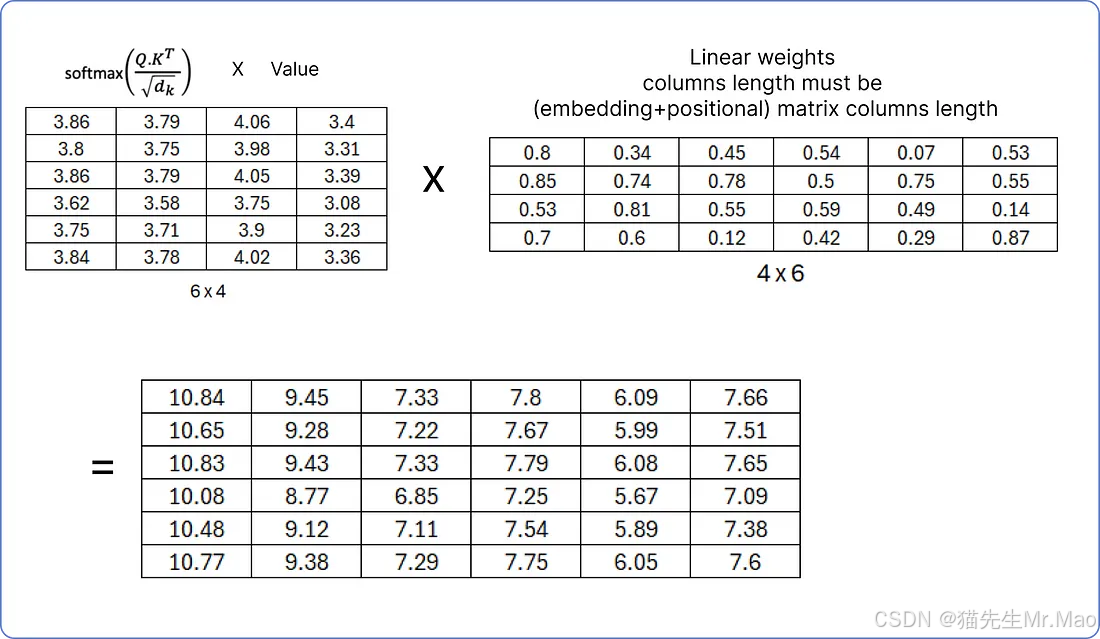
确保线性权重矩阵的列数必须等于我们之前计算的矩阵(词嵌入+位置嵌入)矩阵的列数,因为下一步,我们将把结果的规范化矩阵与(词嵌入+位置嵌入)矩阵相加。
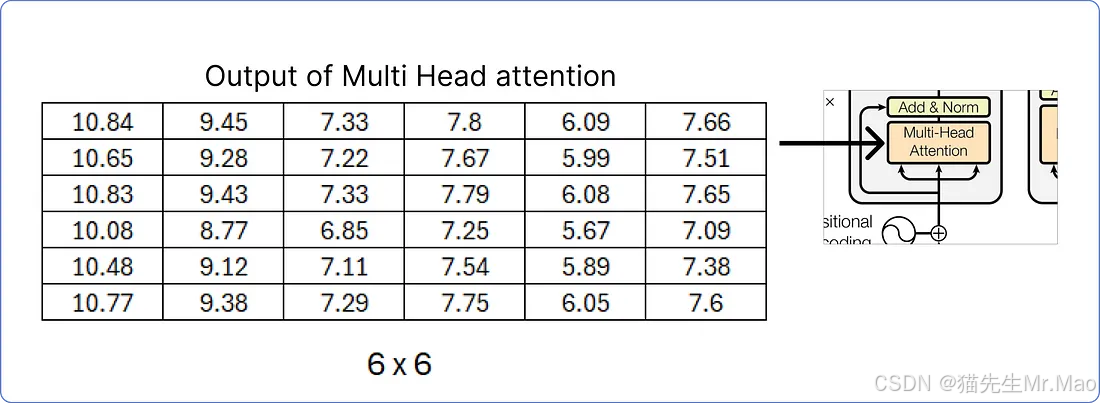
由于我们已经计算出了多头注意力的结果矩阵,接下来,将致力于添加和规范化步骤。
加法和归一化
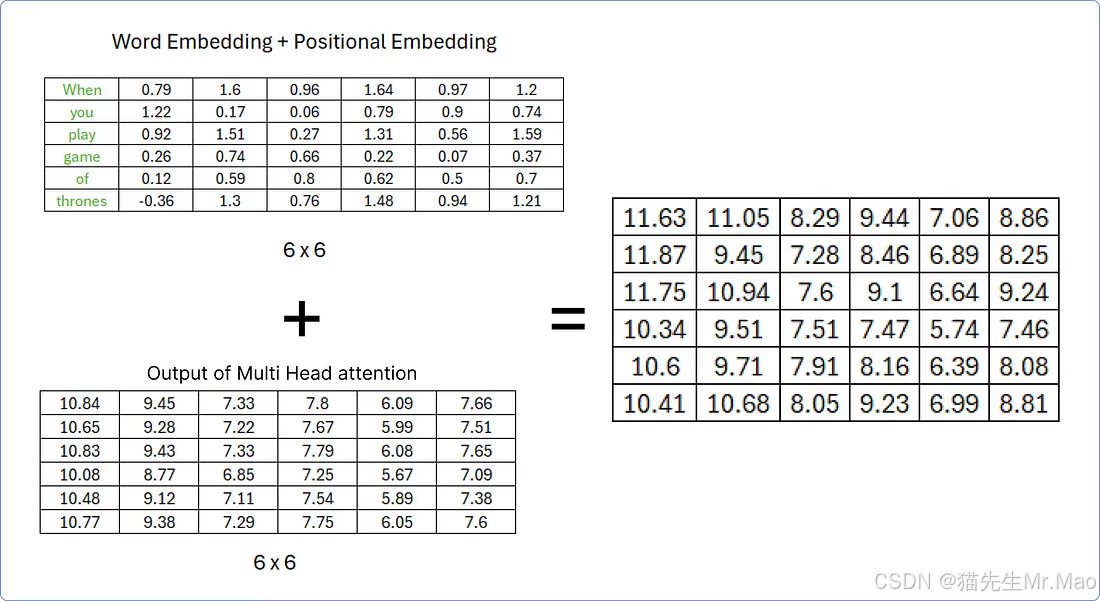
一旦从多头注意力机制中获得了结果矩阵,我们就必须将其添加到原始矩阵中。
为了归一化上述矩阵,我们需要逐行计算每一行的平均值和标准差。
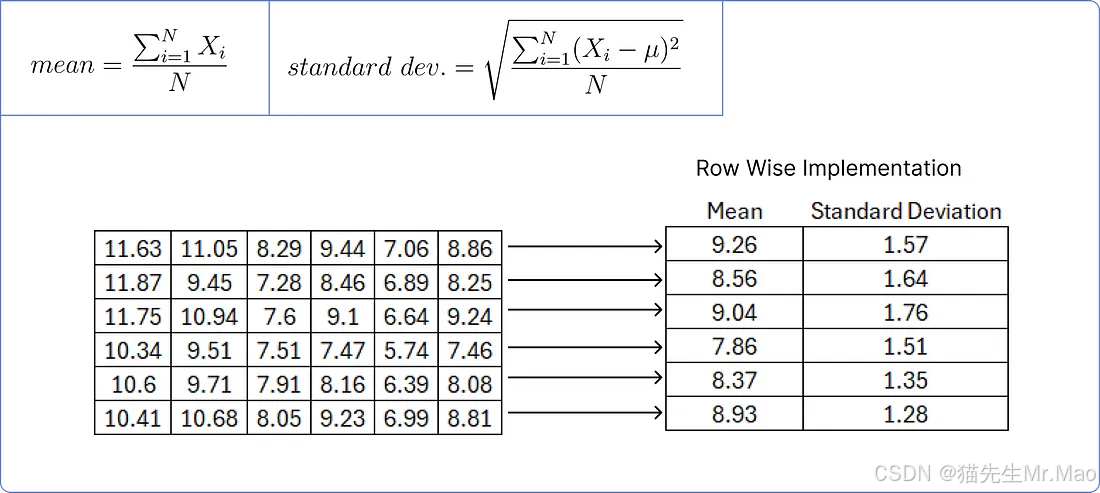
我们用矩阵的每个值减去相应的行平均值,然后除以相应的标准差。
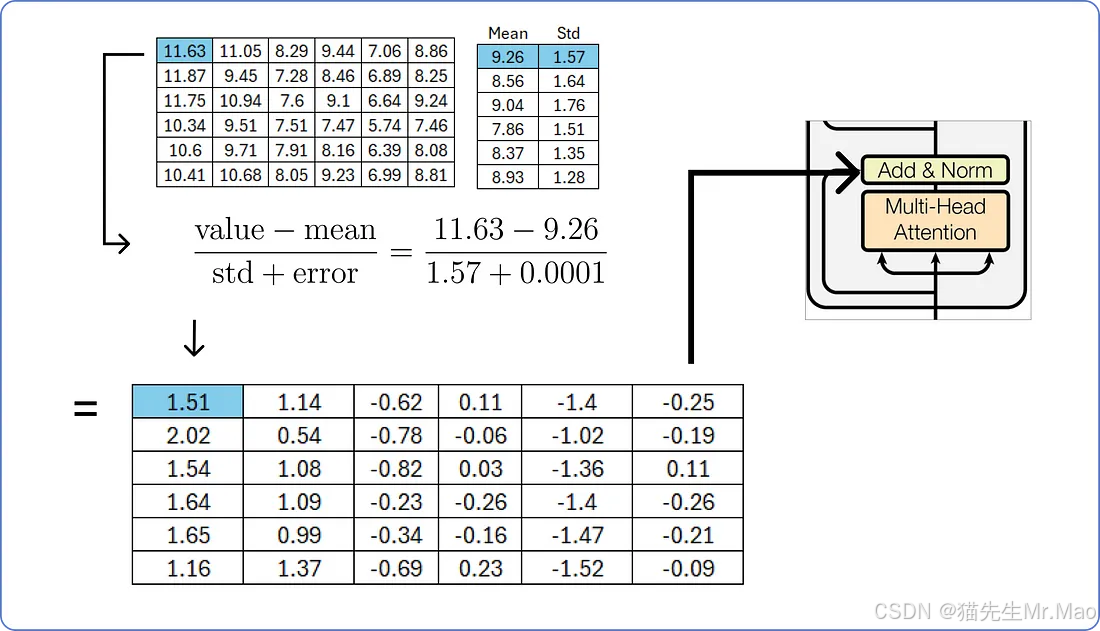
添加一个小的误差值可以防止分母为零,并避免使整个项无穷大。
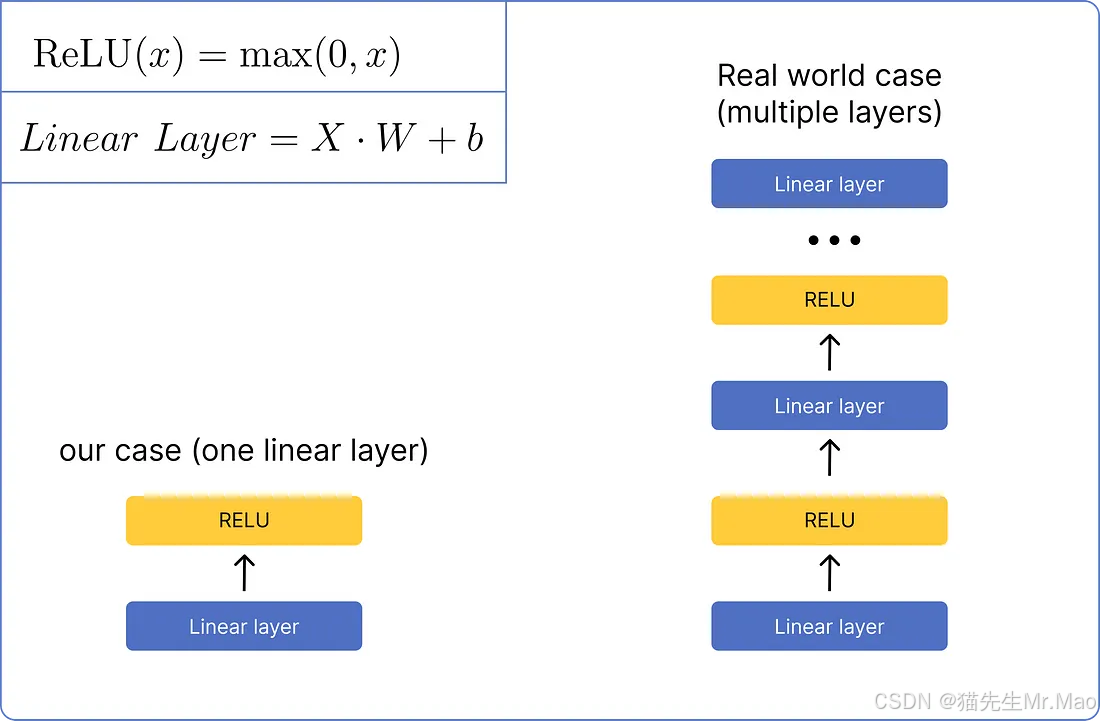
前馈网络
矩阵标准化后,将通过前馈网络进行处理。将使用一个非常基本的网络,该网络仅包含一个线性层和一个 ReLU 激活函数层。它在视觉上看起来是这样的:
首先,需要通过将最后计算的矩阵与一组随机的权重矩阵相乘来计算线性层,该权重矩阵将在 Transformer 开始学习时更新,然后将结果矩阵添加到同样包含随机值的偏差矩阵中。
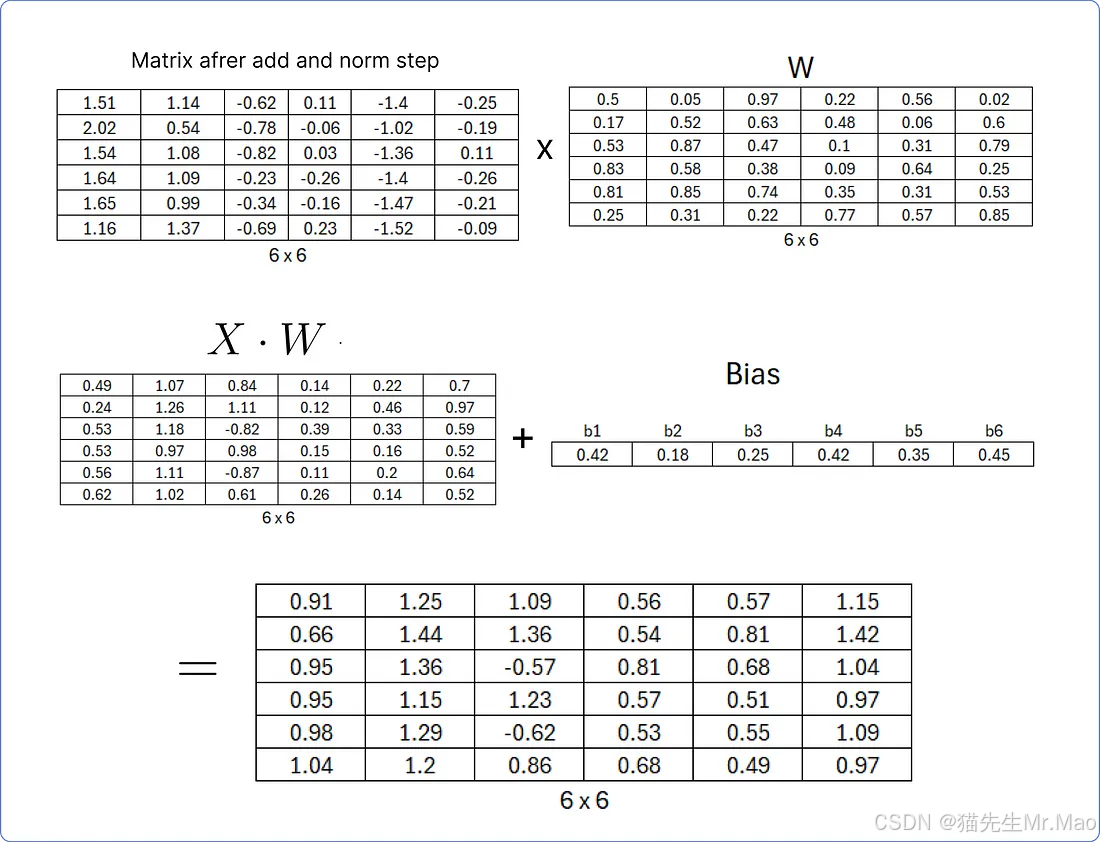
计算完线性层之后,我们需要将其穿过ReLU层,并利用其公式。

再次加法和归一化
一旦我们从前馈网络获得结果矩阵,我们就必须将其添加到从前面的加法和归一化步骤获得的矩阵中,然后使用行平均值和标准差对其进行归一化。
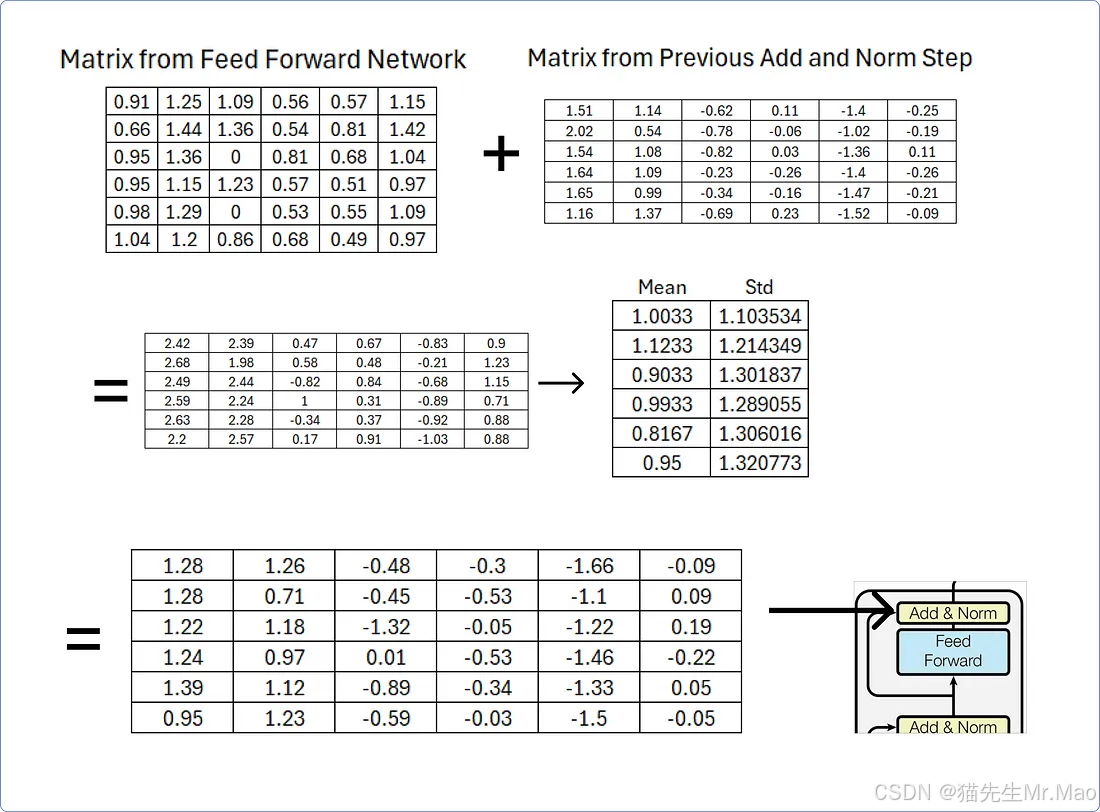
该添加和规范步骤的输出矩阵将作为解码器部分中存在的多头注意力机制之一中的查询和键矩阵,可以通过从添加和规范向外追踪到解码器部分来轻松理解它。
解码器部分
至止,我们已经计算了编码器部分, 我们执行的所有步骤,从编码数据集到将矩阵传递给前馈网络,都是独一无二的。这意味着我们之前没有计算过它们。但从现在开始,所有即将到来的步骤,即 Transformer 的剩余架构(解码器部分),都将涉及类似的矩阵乘法。
看一下我们的 Transformer 架构。到目前为止我们已经涵盖了什么以及我们还需要涵盖什么:
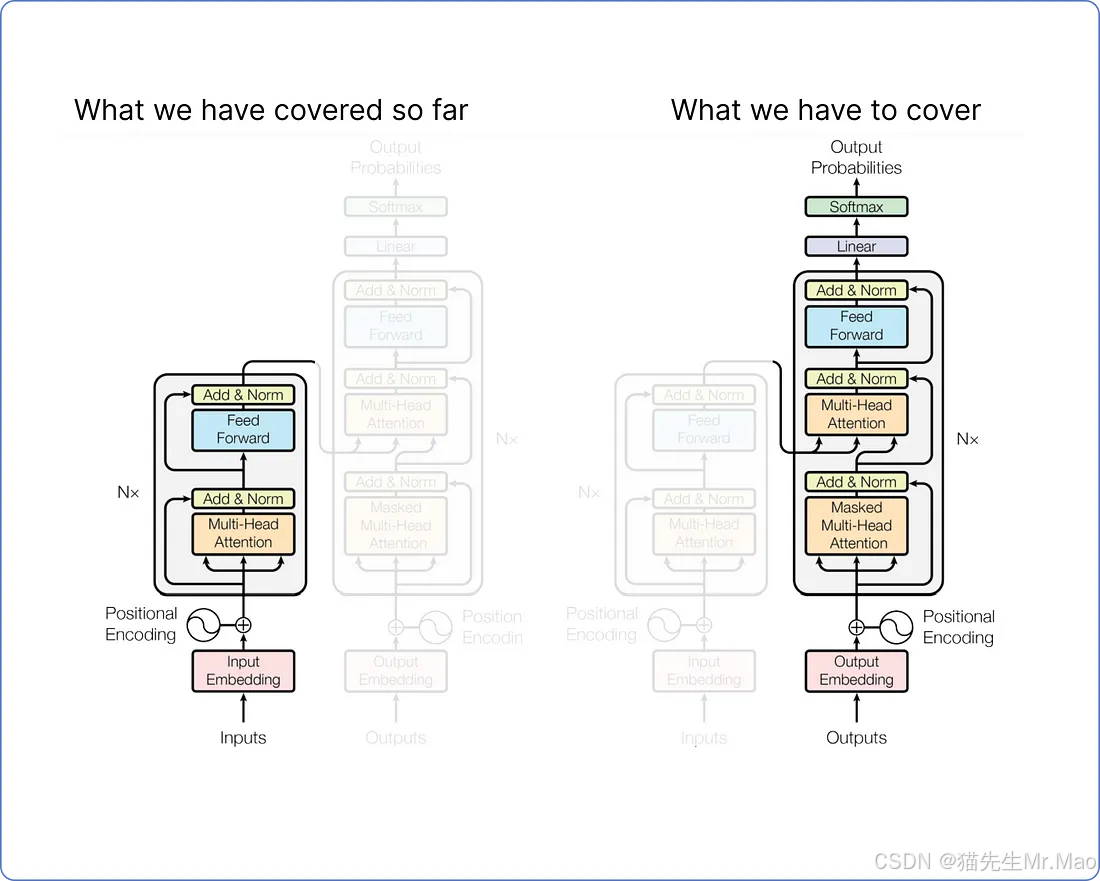
我们不会计算整个解码器,因为其大部分内容与我们在编码器中已经完成的计算类似。详细计算解码器只会因重复步骤而使本文冗长。因而,我们只需关注解码器的输入和输出的计算。
训练时,解码器有两个输入。一个来自编码器,其中最后一个加法和范数层的输出矩阵作为查询和键用于解码器部分的第二个多头注意层。以下是它的可视化效果:

而值矩阵则来自解码器经过第一次加法和范数步骤之后的结果。
解码器的第二个输入是预测文本。如果你还记得的话,我们对编码器的输入是,when you play game of thrones所以解码器的输入是预测文本,在我们的例子中是you win or you die。
但是预测的输入文本需要遵循标准的标记包装,以使 Transformer 知道从哪里开始和在哪里结束。
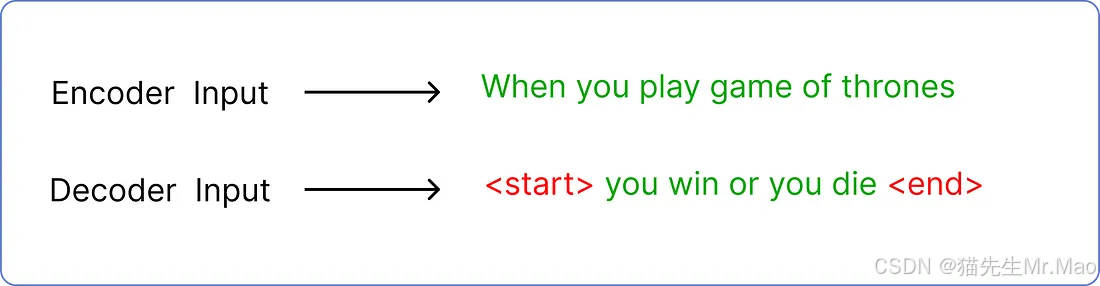
其中<start>和<end>是引入的两个新token。此外,解码器每次只接受一个token作为输入。这意味着<start>将作为输入,并且you必须是它的预测文本。
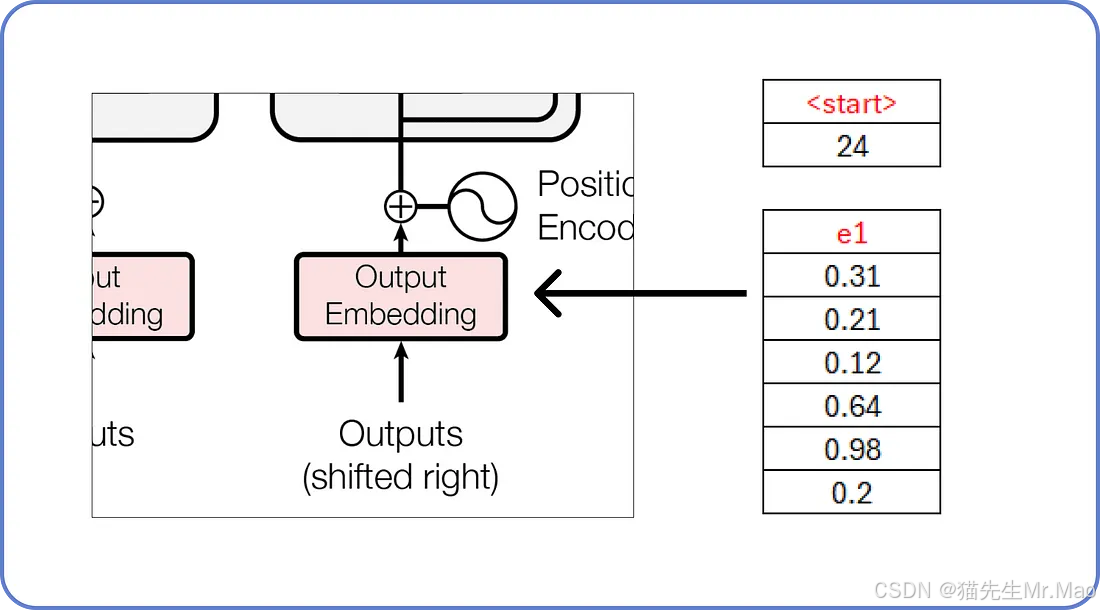
我们已经知道,这些嵌入填充了随机值,这些随机值将在训练过程中更新。
按照我们之前在编码器部分计算的相同方式计算其余块。
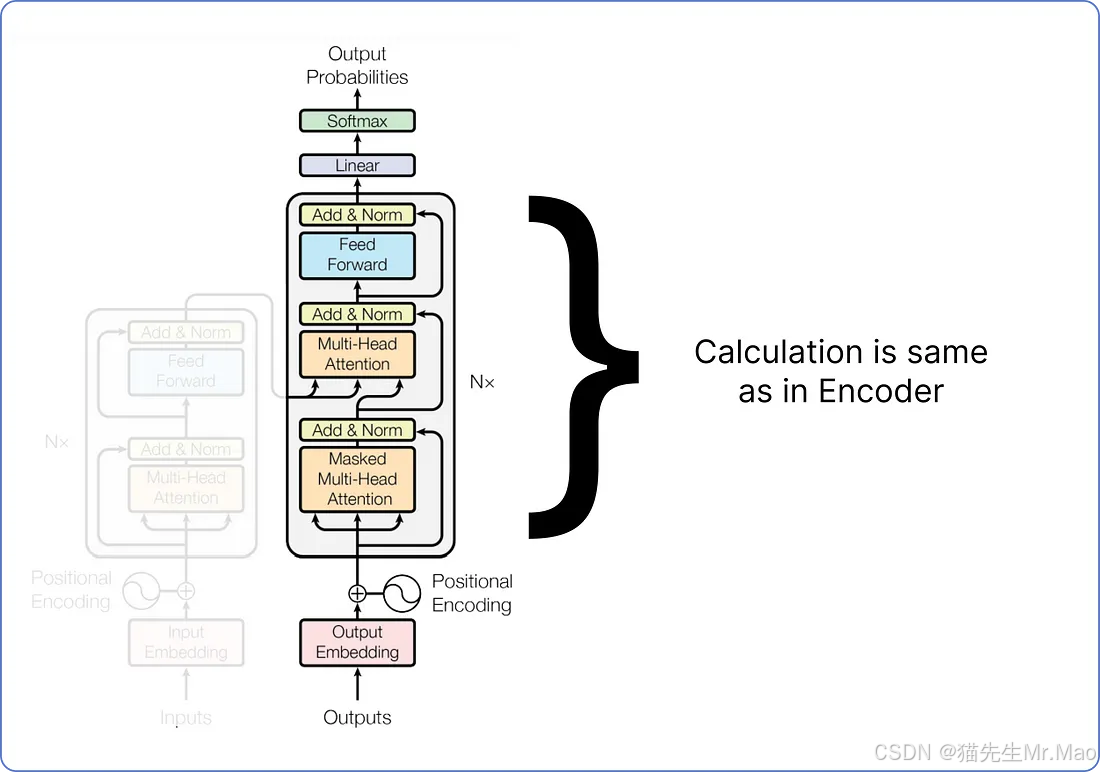
在深入探讨更多细节之前,我们需要先用一个简单的数学例子来了解什么是掩码多头注意力。
了解 Masked 多头注意力机制
在 Transformer 中,掩码多头注意力就像一个聚光灯,模型用它来聚焦句子的不同部分。它很特别,因为它不会让模型通过查看句子后面的单词来作弊。
这有助于模型逐步理解和生成句子,这在交谈或将单词翻译成另一种语言等任务中非常重要。
假设有以下输入矩阵,其中每行代表序列中的一个位置,每列代表一个特征:
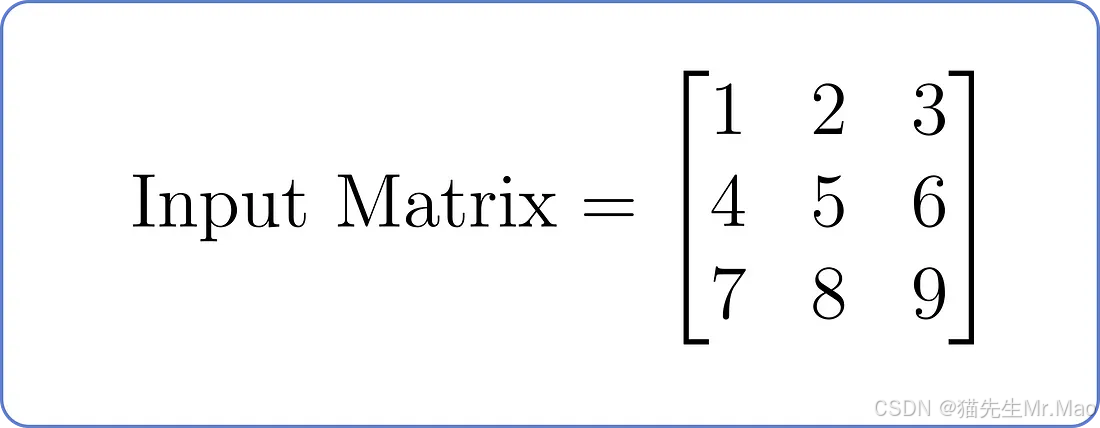
现在,让我们了解一下具有两个头的掩码多头注意力组件:
-
线性投影(查询、键、值):假设每个头部的线性投影:Head1:*Wq* 1、*Wk* 1、*Wv* 1 和Head2:*Wq* 2、*Wk* 2、*Wv* 2
-
计算注意力分数:对于每个头部,使用查询和键的点积计算注意力分数,并应用掩码以防止关注未来的位置。
-
应用Softmax:应用softmax函数来获得注意力权重。
-
加权总和(值):将注意力权重乘以值以获得每个头部的加权和。
-
连接和线性变换:连接两个头的输出并应用线性变换。
我们来做一个简单的计算:
假设两个条件
-
Wq 1 = Wk 1 = Wv 1 = Wq 2 = Wk 2 = Wv 2 = I,单位矩阵。
-
Q = K = V =输入矩阵

连接步骤将两个注意力头的输出组合成一组信息。假设你有两个朋友,他们各自就一个问题给你建议。连接他们的建议意味着将两条建议放在一起,这样你就能更全面地了解他们所建议的内容。在 Transformer 模型的上下文中,此步骤有助于从多个角度捕获输入数据的不同方面,从而为模型提供更丰富的表示,以供进一步处理。
计算预测单词
解码器的最后一个加法和范数块的输出矩阵必须包含与输入矩阵相同的行数,而列数可以是任意的。这里我们使用6。
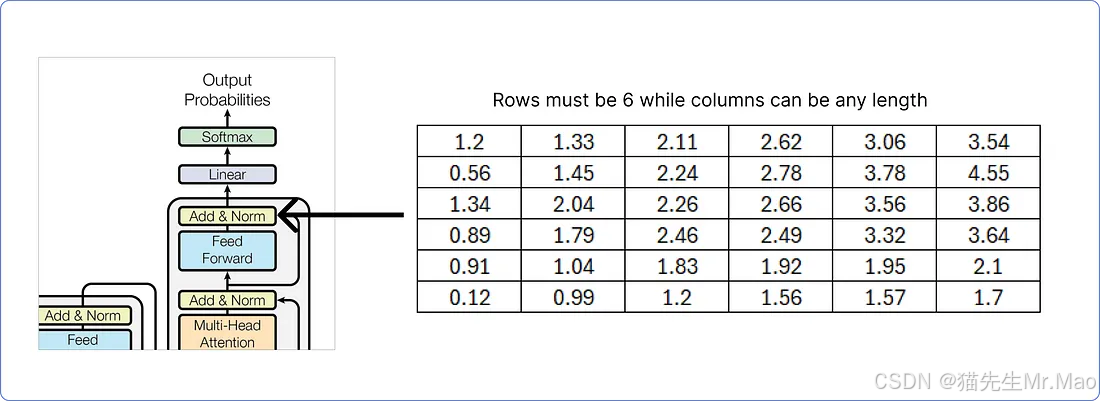
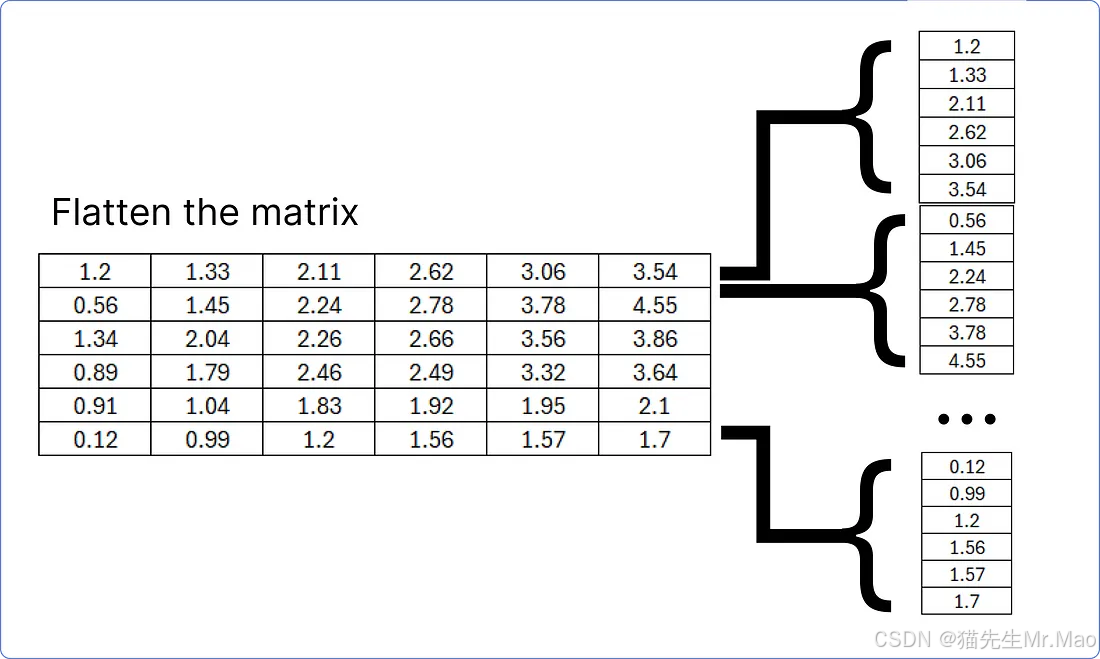
解码器的最后一个加法和归一块结果矩阵必须被平坦化,以便将其与线性层匹配,以找到我们的数据集(语料库)中每个唯一单词的预测概率。
该扁平层将通过线性层来计算数据集中每个唯一单词的logit (分数)。

一旦获得了logits,我们就可以使用softmax函数对它们进行规范化,并找到包含最高概率的单词。
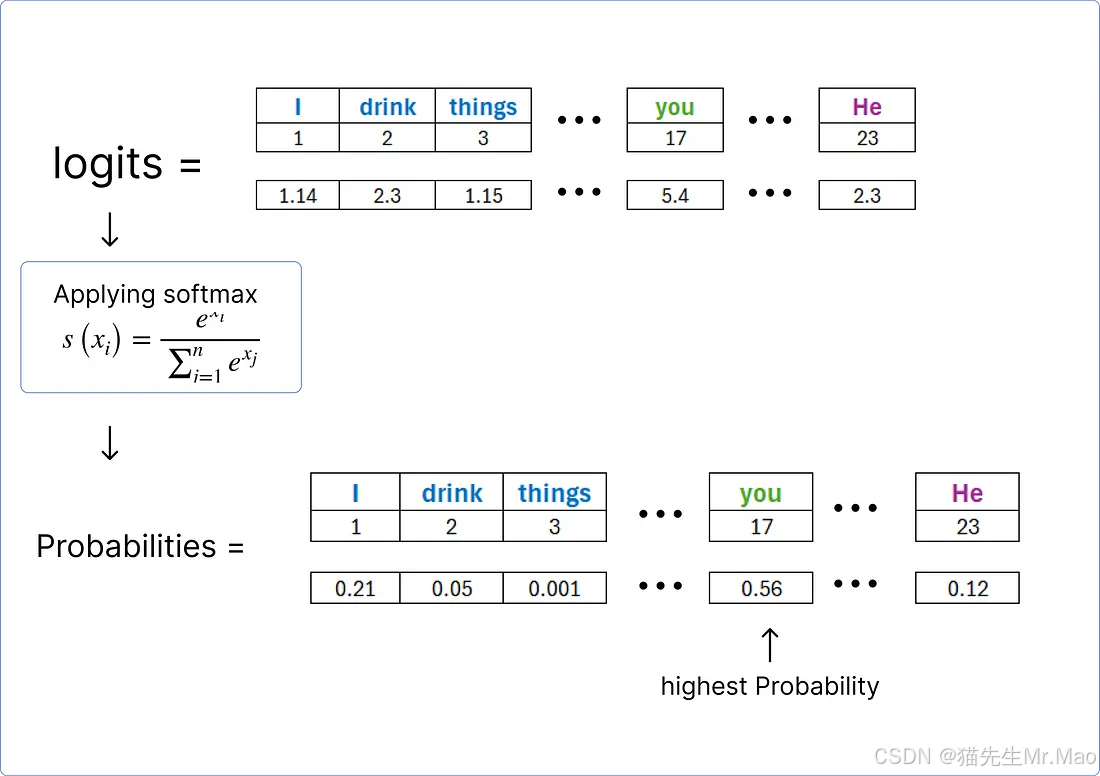
因此根据计算,解码器预测的单词是you。
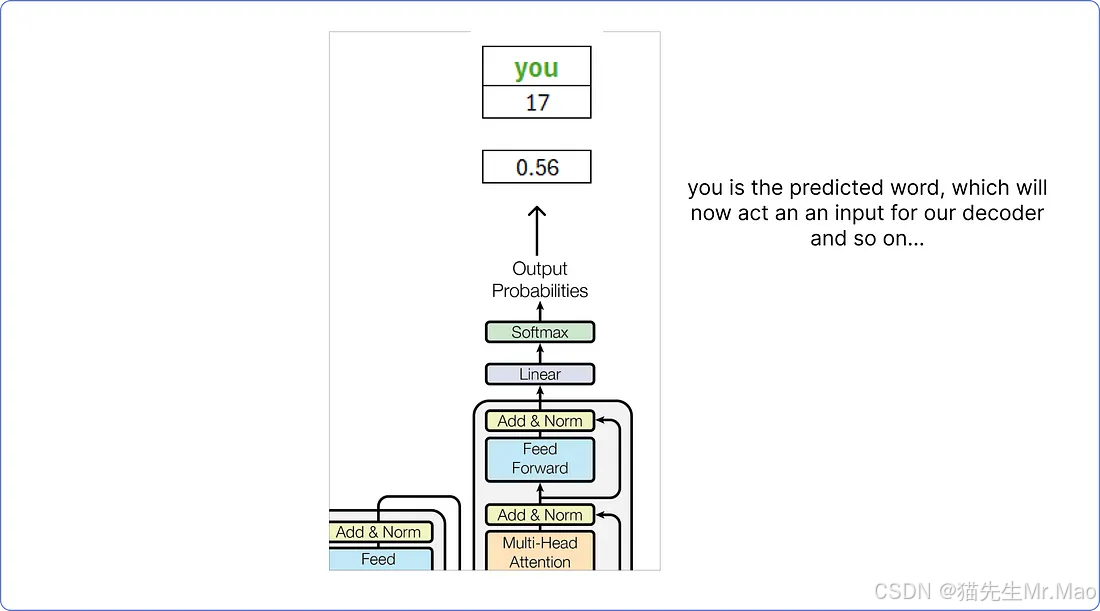
这个预测的词you将被视为解码器的输入词,这个过程一直持续到<end>预测出 token 为止。
重点
-
上面的例子非常简单,因为它不涉及时期或任何其他只能使用 Python 等编程语言来实现可视化的重要参数。
-
它仅显示了直到训练为止的过程,而使用这种矩阵方法无法直观地看到评估或测试。
-
可以使用掩蔽的多头注意力来防止变压器观察未来,从而有助于避免过度拟合模型。
结论
在这篇博文中,介绍了使用矩阵方法进行数学运算的非常基本的方法。我们应用了位置编码、softmax、前馈网络,最重要的是多头注意力。
技术交流
加入 「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在 「魔方AI空间」,关注了解全栈式 AIGC内容!!
技术交流
加入「AIGCmagic社区」群聊,一起交流讨论,涉及 AI视频、AI绘画、Sora技术拆解、数字人、多模态、大模型、传统深度学习、自动驾驶等多个不同方向,可私信或添加微信号:【m_aigc2022】,备注不同方向邀请入群!!
更多精彩内容,尽在「魔方AI空间」,关注了解全栈式 AIGC内容!!
